摘要
本文深入介绍了二分类模型的评估方法与逻辑回归的进阶应用。文章首先讲解了混淆矩阵、精确率、召回率、F1-score等评估指标,并通过代码示例对比了不同模型的性能差异。随后阐述了ROC曲线与AUC指标的原理及其在类别不平衡场景下的优势。最后通过电信客户流失案例,展示了从数据预处理(独热编码)、可视化分析到模型训练与评估的完整流程。
Abstract
This article delves into evaluation methods for binary classification models and advanced applications of logistic regression. It first explains evaluation metrics including confusion matrix, precision, recall, and F1-score, comparing different models through code examples. It then describes the principles of ROC curves and AUC, along with their advantages in imbalanced classification scenarios. Finally, it demonstrates a complete workflow from data preprocessing (one-hot encoding) and visualization analysis to model training and evaluation through a telecom customer churn case.
一.分类问题评估
接上篇内容,最后提到只靠预测准确率是不能够满足各种场景需求的。所以下面开始对深入讲解混淆矩阵、精确率、召回率、F1-score等评估指标进行了解。
1.混淆矩阵
混淆矩阵中四个值分别是:TP(真正例)------实际为正例且预测为正例;TN(真负例)------实际为负例且预测为负例;FP(假正例)------实际为负例但预测为正例(误报);FN(假负例)------实际为正例但预测为负例(漏报)。其中TP和TN表示预测正确,FP和FN表示预测错误。混淆矩阵具体如下表:
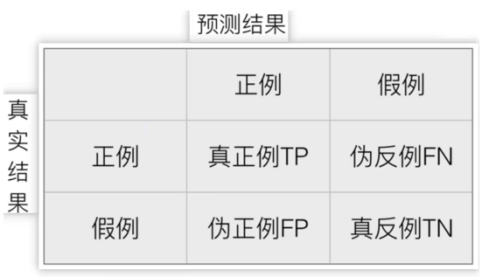
2.精确率(Precision)
精确率是指在所有被模型预测为正例的样本中,实际为正例的比例,计算公式为 TP / (TP + FP)。它衡量的是模型"预测为正例的结果"有多准,关注的是不误报。例如在垃圾邮件检测中,高精确率意味着被判定为垃圾邮件的邮件里,真正是垃圾邮件的占比很高,正常邮件被误判的情况很少。
例如有10个样本,有6个垃圾邮件,4个正常邮件,这里以垃圾邮件为正例(则可知TP:6, FN:0,FP:3,TN=1)。在模型A中如果预测对了6个垃圾邮件,1个正常邮件,则模型A精确率则为6/(6+3)=66.7%。
3.召回率(Recall)
召回率是指在所有实际为正例的样本中,被模型正确预测为正例的比例,计算公式为 TP / (TP + FN)。它衡量的是模型"找出正例"的能力有多强,关注的是不漏报。例如在癌症筛查中,高召回率意味着绝大多数真正的癌症患者都被模型识别出来了,漏诊(把病人误判为健康)的情况很少,即使可能伴随一些误报(把健康人误判为病人)。
同样的以精确率中的邮件为例,则模型A召回率为6/(6+0)=100%。
4.F1-score
F1-score是精确率和召回率的调和平均数,计算公式为 2 × (精确率 × 召回率) / (精确率 + 召回率)。它综合了精确率和召回率两者的表现,当这两个指标需要同时兼顾时(比如在类别不平衡的数据集中,单一指标容易失真),F1-score能提供一个更平衡、更全面的评价。它的取值范围在0到1之间,值越高说明模型越稳健,既不容易漏报(高召回率),也不容易误报(高精确率)。
则以以精确率中的邮件为例,则模型A的F1-score为2*0.667*1/(0.667+1)=80%。
5.代码实现
下面是对于上述四个属性进行简单的代码实现:
python
# 需求:已知有10个样本,6个垃圾邮件(正例),4个正常邮件
# 模型A预测结果为:预测对了3个垃圾邮件,预测对了4个正常邮件
# 模型B预测结果为:预测对了6个垃圾邮件,预测对了1个正常邮件
# 根据上述数据,搭建 混淆矩阵,并分别计算模型A和模型B的准确率、召回率、F1值
# 导包
import pandas as pd
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score # 混淆矩阵,精确率,召回率,F1值
# 1定义变量,记录样本数据
y_train = ['垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '正常', '正常', '正常', '正常']
# 2.定义变量,记录模型A的预测结果
y_pre_a = ['垃圾', '垃圾', '垃圾', '正常', '正常', '正常', '正常', '正常', '正常', '正常']
# 3.定义变量,记录模型B的预测结果
y_pre_b = ['垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '垃圾', '正常']
# 4.用标签标记 正例,反例
label = ['垃圾', '正常']
df_label = ['垃圾(正例)', '正常(反例)']
# 5.对于真实值y_train,和模型A的预测结果y_pre_a,进行混淆矩阵
cm_a = confusion_matrix(y_train, y_pre_a, labels=label)
# 6.将上述结果转成Dataframe
df_A = pd.DataFrame(cm_a, index=df_label, columns=df_label)
print(f'混淆矩阵A:\n{df_A}')
# 7.对于真实值y_train,和模型B的预测结果y_pre_b,进行混淆矩阵
cm_b = confusion_matrix(y_train, y_pre_b, labels=label)
# 8.将上述结果转成Dataframe
df_B = pd.DataFrame(cm_b, index=df_label, columns=df_label)
print(f'混淆矩阵B:\n{df_B}')
# 9.计算模型A的准确率、召回率、F1值
print(f'模型A的准确率:{precision_score(y_train, y_pre_a, pos_label="垃圾")}') # 参数1:真实值,参数2:预测结果,参数3:正例标签
print(f'模型A的召回率:{recall_score(y_train, y_pre_a, pos_label="垃圾")}')
print(f'模型A的F1值:{f1_score(y_train, y_pre_a, pos_label="垃圾")}')
# 10.计算模型B的准确率、召回率、F1值
print(f'模型B的准确率:{precision_score(y_train, y_pre_b, pos_label="垃圾")}')
print(f'模型B的召回率:{recall_score(y_train, y_pre_b, pos_label="垃圾")}')
print(f'模型B的F1值:{f1_score(y_train, y_pre_b, pos_label="垃圾")}')得到的结果如下:
混淆矩阵A:
垃圾(正例) 正常(反例)
垃圾(正例) 3 3
正常(反例) 0 4
混淆矩阵B:
垃圾(正例) 正常(反例)
垃圾(正例) 6 0
正常(反例) 3 1
模型A的准确率:1.0
模型A的召回率:0.5
模型A的F1值:0.6666666666666666
模型B的准确率:0.6666666666666666
模型B的召回率:1.0
模型B的F1值:0.8
二.ROC曲线与AUC指标
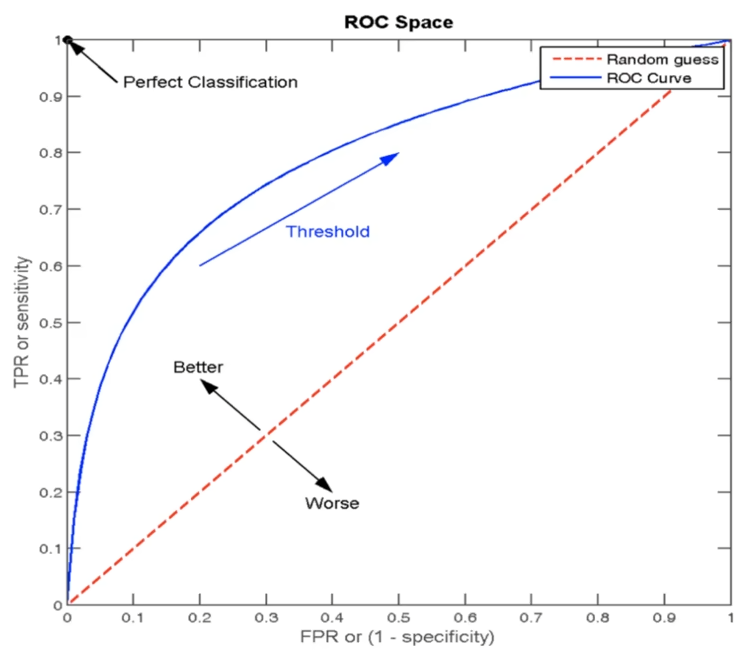
在了解前,首先看上图中的x,y坐标,其中TPR(真正率)是指正样本中被预测为正样本的概率,FPR(假正率)是指负样本中被预测为正样本的概率。
1.ROC曲线(Receiver Operating Characteristic Curve)
ROC曲线是评估二分类模型性能的重要工具。它以假正率FPR为横轴,真正率TPR为纵轴,通过绘制不同分类阈值下模型的表现,直观反映模型的分类能力。
2. 曲线下面积(AUC,Area Under the Curve)
AUC是指ROC曲线下的面积,它量化了二分类模型将正样本排在负样本前面的能力。AUC的取值范围在0.5到1之间:0.5表示模型完全没有区分能力(等同于随机猜测),1.0表示模型能完美区分所有正负样本。通常情况下,AUC值越大,模型的分类性能越好。与传统准确率不同,AUC对类别不平衡不敏感,因此当数据集中正负样本数量差异较大时,AUC是比准确率更可靠的评估指标。
三.电信客户流失案例
案例需求:
已知:用户个人,通话,上网等信息。
需求:通过分析特征属性确定客户流失原因,以及哪些因素可能导致用户流失。建立预测模型来判断用户是否流失,并提出用户流失预警策略。
首先是进行导包:
python
# 导包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 混杂度矩阵,准确度,精确度,召回率,F1值,分类报告
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score,classification_report其次是对于数据进行导入并经行预处理:
python
def data_preprocess():
# 读取数据集
churn_df = pd.read_csv('./data/churn.csv')
# 将Churn和gender的数据类型转换成数值型
# 用到独热编码
churn_df = pd.get_dummies(churn_df, columns=['Churn', 'gender'])
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True) # 也可在创建独热编码时括号中添加drop_first=True
# 修改数据列名
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
# churn_df.info()
return churn_df得到结果如下:
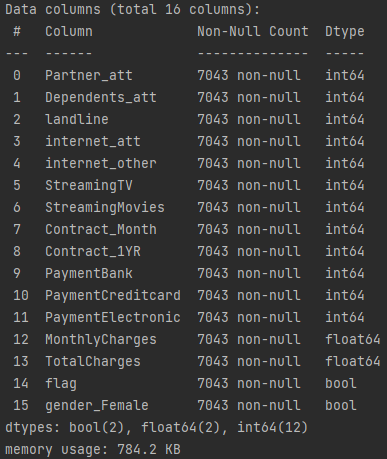
再对于这个数据进行可视化:
python
def data_visualize():
# 获取处理后的数据集
churn_df = data_preprocess()
# 绘制数据可视化
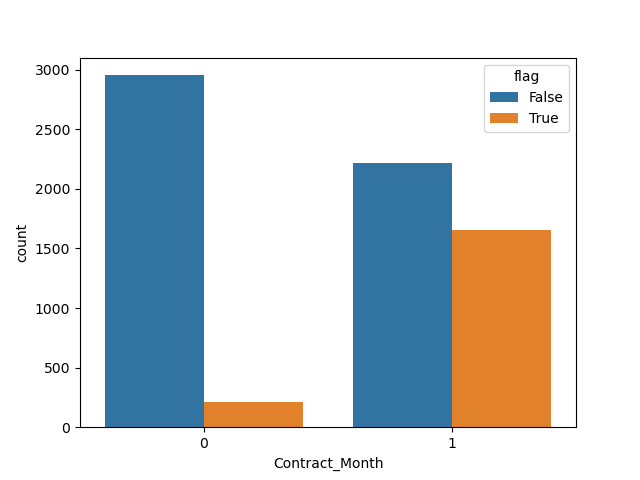
# 参1:数据集,参2:x轴数据(月度会员),参数3:分组数据
sns.countplot(data=churn_df, x='Contract_Month', hue='flag')
plt.show()结果如下:
最后经行模型训练:
python
def logistic_regression():
# 获取处理后的数据集
churn_df = data_preprocess()
# 提取特征和标签
# x的特征列:月度会员,其他网络,电子支付
x = churn_df[['Contract_Month','internet_other','PaymentElectronic']]
y = churn_df['flag'] # False-不流失 True-流失
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 特征工程
# 模型训练
# 创建模型
estimator = LogisticRegression()
# 训练
estimator.fit(x_train, y_train)
# 模型预测
y_pre = estimator.predict(x_test)
print(f'预测值:{y_pre}')
# 模型评估
print(f'准确度:{estimator.score(x_test, y_test)}') # 预测前
print(f'准确度:{accuracy_score(y_test, y_pre)}') # 预测后
print(f'精确度:{precision_score(y_test, y_pre)}')
print(f'召回率:{recall_score(y_test, y_pre)}')
print(f'F1值:{f1_score(y_test, y_pre)}')
# 分类报告
# macro avg:宏平均,即不考虑样本权重,直接计算所有类别的准确度,然后求平均,适用于数据均衡的情况
# weighted avg:加权平均,即考虑样本权重,将所有类别的准确度乘以样本权重,然后求平均,适用于数据不平衡的情况
print(f'分类报告:{classification_report(y_test, y_pre)}')得到结果如下:
预测值:False False False ... False False False
准确度:0.7693399574166075
准确度:0.7693399574166075
精确度:0.5892116182572614
召回率:0.3858695652173913
F1值:0.4663382594417077
|--------------|-----------|--------|----------|---------|
| 分类报告 | precision | recall | f1-score | support |
| False | 0.81 | 0.90 | 0.85 | 1041 |
| True | 0.59 | 0.39 | 0.47 | 368 |
| accuracy | | | 0.77 | 1409 |
| macro avg | 0.70 | 0.65 | 0.66 | 1409 |
| weighted avg | 0.75 | 0.77 | 0.75 | 1409 |
总结
本文系统讲解了二分类模型的评估体系与逻辑回归的实践应用。混淆矩阵提供了TP、TN、FP、FN四个基础维度;精确率关注"预测为正例中有多少是对的",召回率关注"真实正例中有多少被找出",F1-score则综合平衡两者。ROC曲线与AUC指标对类别不平衡不敏感,是比准确率更可靠的评估工具。通过电信客户流失案例,演示了独热编码处理类别特征、特征筛选、模型训练及分类报告输出的完整流程,为处理实际二分类问题提供了实践参考。