Evo-Multi-SLM:用进化算法给小语言模型做对齐,告别梯度爆显存
目录
1. 为什么小模型做对齐这么难
2. Evo-Multi-SLM 核心思路
3. 方法拆解:LoRA + 差分进化 + 语义效率惩罚
4. 实验结果解读
5. 总结与思考
Evo-Multi-SLM 是 2026 年 ICSP(IEEE 11th International Conference on Intelligent Computing and Signal Processing)上的一篇论文,作者是澳洲纽卡斯尔大学的 倪立声 (第一作者兼容通讯作者) 和 徐昕蓬(第二作者)。这篇论文要解决的问题很实在:小语言模型(SLM)在资源受限的情况下,怎么做对齐(alignment)。它的思路也很有意思------完全抛弃梯度,用进化算法 + 多智能体来对齐模型。
论文 DOI:https://doi.org/10.1109/ICSP69961.2026.11540917
一、为什么小模型做对齐这么难
我们先搞清楚问题在哪。
大模型对齐主流是这两条路:
- RLHF(基于人类反馈的强化学习):先训一个奖励模型,再用强化学习去调整语言模型,让它向奖励模型打分高的方向走。
- DPO(直接偏好优化):跳过奖励模型这一步,把对齐问题直接转成一个分类损失,训练更简单更稳。
这两种方法都有一个共同点:都要算梯度,都要反向传播。反向传播这件事,对大模型来说不算什么,但对小模型(SLM)在资源受限的设备上跑,就很要命了:
- 存储一个 batch 的中间激活值,显存开销很大;
- 数据量不够的时候,梯度优化容易学不动,甚至学偏;
- 而且已经有研究发现(论文里引用了 67),用偏好优化训出来的模型,容易学会"说得很长很像样,但逻辑上并不严谨"的输出------也就是讨好评测指标,但不讲道理。
所以作者的思路是:既然梯度这条路在小模型上这么吃资源,那干脆不要梯度。
进化策略(Evolutionary Strategies, ES)这两年在对齐圈子里重新火起来,因为它有几个天然的优点:
- 高度可并行;
- 内存友好(不需要存梯度和激活值,只需要前向推理);
- 对稀疏奖励信号比较稳健;
- 对超参数不那么敏感。
但之前的工作(比如论文提到的 ESSA 8)基本都是单模型 的进化优化。作者觉得,既然多智能体系统已经证明"群体智能可以超过单个智能体",那为什么不让一群"各自都不完美但能一起探索"的小模型去合作对齐,而不是死磕一个模型让它自己变得完美?
这就是 Evo-Multi-SLM 的出发点。
二、Evo-Multi-SLM 核心思路
论文里提出了三个关键创新:
- 无梯度的多智能体进化框架:用 LoRA 把参数空间降维,再用差分进化(Differential Evolution, DE)在这个低维空间里搜索最优解,全程不用反向传播。
- 语义效率惩罚(Semantic Efficiency Penalty, SEP):这是个非线性的优化目标,专门用来治"啰嗦病"------逼着模型生成更短、逻辑链更紧凑的推理过程,而不是又臭又长的废话。
- 异质化多智能体协同进化:种群里的每个 agent 走不同的进化路径,靠种群多样性去探索整个对齐空间,而不是单打独斗。
整体架构如下图(来自架构图Fig.1):左边是"进化引擎"(种群 + DE 算子),中间是"双路径模型架构"(冻结的基座模型 + LoRA 适配器),右边是"评估反馈环"(正确性奖励 + 语义效率惩罚 → 适应度函数 → 选择)。
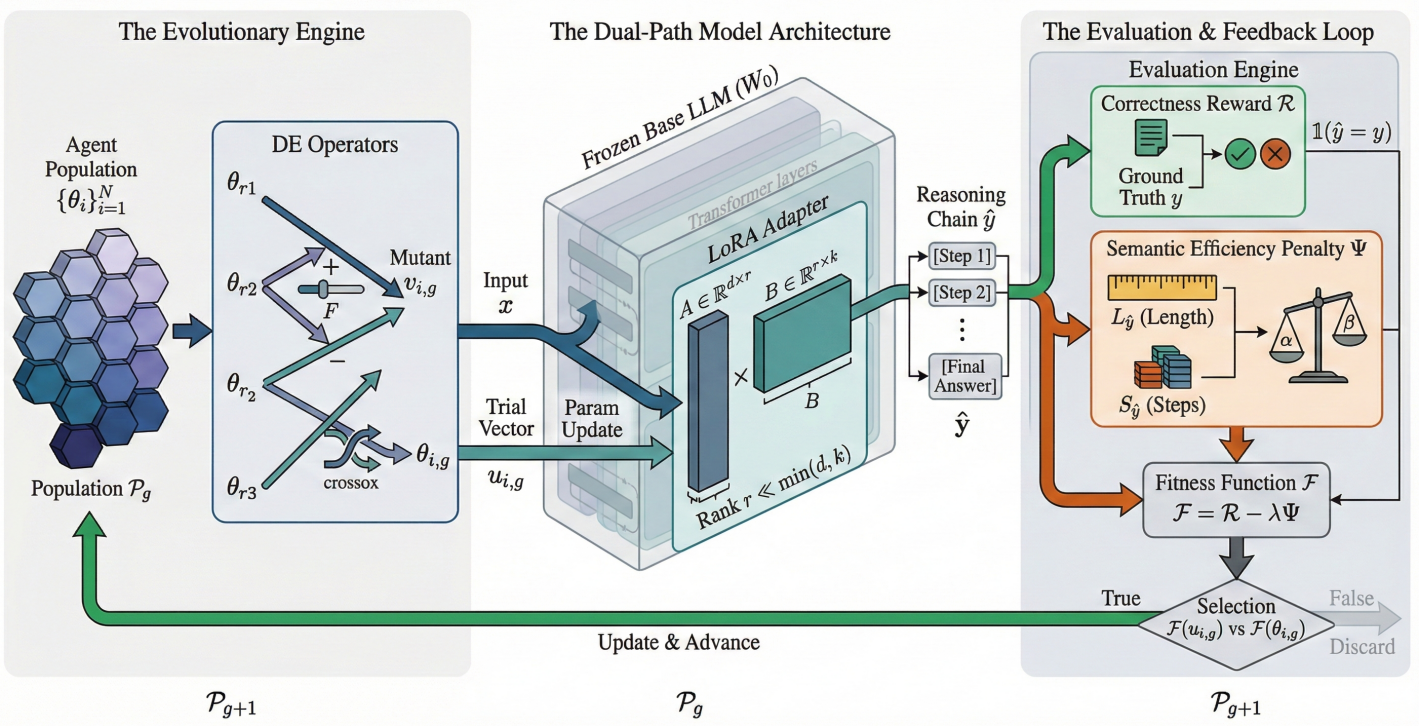
架构图Fig.1:小语言模型的进化逻辑对齐框架(Evo-Multi-SLMs)。
三、方法拆解:LoRA + 差分进化 + 语义效率惩罚
我们一步步把公式过一遍,这样才能真正理解模型在干什么。
3.1 用 LoRA 给参数空间"瘦身"
直接对整个模型做参数搜索是不现实的,维度太高了。所以第一步是用 LoRA(Low-Rank Adaptation)把要优化的参数压到一个低维空间。
对模型 MMM 中任意一个线性层,原本冻结的权重矩阵是 W0∈Rd×kW_0 \in \mathbb{R}^{d \times k}W0∈Rd×k,加上 LoRA 之后变成:
W=W0+ΔW=W0+γrAB(1)W = W_0 + \Delta W = W_0 + \frac{\gamma}{r}AB \tag{1}W=W0+ΔW=W0+rγAB(1)
这里:
- W0W_0W0:预训练好的、冻结不动的权重,保住模型本来的语言能力;
- A∈Rd×rA \in \mathbb{R}^{d \times r}A∈Rd×r,B∈Rr×kB \in \mathbb{R}^{r \times k}B∈Rr×k:两个低秩矩阵,这才是真正要优化的对象;
- rrr:秩,要求 r≪min(d,k)r \ll \min(d,k)r≪min(d,k),这样可训练参数才会少;
- γ\gammaγ:一个缩放系数,控制 LoRA 这部分的影响力。
所有层的 A,BA, BA,B 矩阵拼起来,就构成了一个 agent 的参数向量 θ\thetaθ。
在进化算法的某一代 ggg,种群里有 NNN 个候选 agent:
Pg={θi,g∣i=1,2,...,N}(2)\mathcal{P}g = \{\theta{i,g} \mid i = 1, 2, \ldots, N\} \tag{2}Pg={θi,g∣i=1,2,...,N}(2)
也就是说,每个 agent 其实就是一套 LoRA 权重的具体取值,整个种群就是一堆"不同配方的 LoRA"在同台竞技。
3.2 差分进化(DE):怎么"生小孩"
种群有了,接下来要让它进化。论文用的是经典的差分进化算法(Differential Evolution),核心是两步:变异(mutation)和交叉(crossover)。
变异 :对种群里第 iii 个目标 agent θi,g\theta_{i,g}θi,g,随机挑三个跟它不一样的 agent 索引 r1,r2,r3r_1, r_2, r_3r1,r2,r3,生成一个"变异向量":
vi,g=θr1,g+F⋅(θr2,g−θr3,g)(3)v_{i,g} = \theta_{r_1,g} + F \cdot (\theta_{r_2,g} - \theta_{r_3,g}) \tag{3}vi,g=θr1,g+F⋅(θr2,g−θr3,g)(3)
直观理解:拿一个随机 agent 当基底,再加上另外两个随机 agent 之间的"差异方向"乘以一个缩放系数 F∈0,2F \in 0,2F∈0,2。这个差异向量就相当于给基底注入了"探索方向",FFF 越大探索范围越广。
交叉 :变异向量生成之后,不能直接全盘接受,要跟原来的目标向量做个"杂交",生成试验向量 ui,gu_{i,g}ui,g,每一维独立判断要不要采用变异后的值:
uj,i,g={vj,i,g,if randj0,1≤CR or j=jrandθj,i,g,otherwise(4)u_{j,i,g} = \begin{cases} v_{j,i,g}, & \text{if } \mathrm{rand}j0,1 \le CR \text{ or } j = j{\text{rand}} \\ \theta_{j,i,g}, & \text{otherwise} \end{cases} \tag{4}uj,i,g={vj,i,g,θj,i,g,if randj0,1≤CR or j=jrandotherwise(4)
这里 CR∈0,1CR \in 0,1CR∈0,1 是交叉概率,控制有多少维度会被变异向量替换;jrandj_{\text{rand}}jrand 是强制保证至少有一维会被替换的随机索引(不然试验向量可能跟原来的一模一样,等于啥也没做)。
这一套操作的好处是:全程只需要前向推理去算适应度,完全不需要梯度。
3.3 语义效率惩罚(SEP):治啰嗦病的良方
这是整篇论文最有意思的部分。作者发现小模型在做推理对齐时容易"水字数"------答案是对的,但推理过程又长又绕。于是设计了一个适应度函数,把"啰嗦"也算进惩罚项里:
F(θ)=E(x,y)∈DR(y\^,y)−λ⋅Ψ(y\^)(5)\mathcal{F}(\theta) = \mathbb{E}_{(x,y)\in\mathcal{D}}\\mathcal{R}(\\hat{y}, y) - \\lambda \\cdot \\Psi(\\hat{y}) \tag{5}F(θ)=E(x,y)∈DR(y\^,y)−λ⋅Ψ(y\^)(5)
这里 y^=M(x;θ)\hat{y} = M(x;\theta)y^=M(x;θ) 是模型在当前参数 θ\thetaθ 下生成的推理序列,λ\lambdaλ 是平衡系数,决定"逻辑要对"和"别太啰嗦"这两件事谁的权重更大。
正确性奖励很直接,就是看模型抽取出来的答案对不对:
R(y^,y)=1(extract_ans(y^)=y)(6)\mathcal{R}(\hat{y}, y) = \mathbb{1}(\text{extract\_ans}(\hat{y}) = y) \tag{6}R(y^,y)=1(extract_ans(y^)=y)(6)
对了给 1,错了给 0。
效率惩罚才是重点:
Ψ(y^)=αln(Ly^+1)+βSy^(7)\Psi(\hat{y}) = \alpha \ln(L_{\hat{y}} + 1) + \beta S_{\hat{y}} \tag{7}Ψ(y^)=αln(Ly^+1)+βSy^(7)
拆开看:
- Ly^L_{\hat{y}}Ly^:生成序列的 token 总长度,用 ln(Ly^+1)\ln(L_{\hat{y}}+1)ln(Ly^+1) 做对数压缩,这样可以避免"线性惩罚"把必要的推理步骤也一棍子打死------也就是说,适度的长度增长惩罚很轻,但长度爆炸的时候惩罚会持续累积;
- Sy^S_{\hat{y}}Sy^:推理链里离散步骤的数量(比如按逻辑标记切分出来的"第一步、第二步......");
- α,β\alpha, \betaα,β:两个权重,分别管"别写太长"和"别绕太多步"。
所以整体逻辑就是:答案要对,过程要短,步骤要精。这跟我们平时写论文/写代码追求的"简洁但不失逻辑完整性"其实是一个道理。
3.4 选择机制:贪婪保留更优个体
每一代进化完,要决定谁能活到下一代。这里用的是标准的"贪婪选择":
θi,g+1={ui,g,if F(ui,g)>F(θi,g)θi,g,otherwise(8)\theta_{i,g+1} = \begin{cases} u_{i,g}, & \text{if } \mathcal{F}(u_{i,g}) > \mathcal{F}(\theta_{i,g}) \\ \theta_{i,g}, & \text{otherwise} \end{cases} \tag{8}θi,g+1={ui,g,θi,g,if F(ui,g)>F(θi,g)otherwise(8)
试验向量适应度更高就替换掉原来的,否则原地不动。整个循环只靠前向推理评估适应度,完全不需要存梯度和中间激活值,这正是显存能压得这么低的根本原因。
3.5 一个衡量"性价比"的指标:逻辑密度
论文还定义了一个很直观的指标,叫逻辑密度 ρ\rhoρ:
ρ=∑i=1NtestR(y^i,yi)∑i=1NtestLy^i(9)\rho = \frac{\sum_{i=1}^{N_{test}} \mathcal{R}(\hat{y}i, y_i)}{\sum{i=1}^{N_{test}} L_{\hat{y}_i}} \tag{9}ρ=∑i=1NtestLy^i∑i=1NtestR(y^i,yi)(9)
分子是测试集上所有正确答案的总数,分母是生成内容的总 token 数。ρ\rhoρ 越高,说明模型每吐一个 token,换来的"逻辑正确率"越高------本质上是在衡量模型有没有在"水字数"。
四、实验结果解读
4.1 实验设置
- 模型:Qwen2.5-0.5B-Instruct(一个很小的模型,0.5B 参数)
- 数据集:GSM8K(数学推理任务,需要严谨的多步逻辑链)
- 对比基线 :
- Vanilla Base:原始预训练模型,啥也没干
- Standard LoRA SFT:用 LoRA 做标准的监督微调
4.2 主实验结果
| 模型 | Pass@1 | Pass@k | Maj@k | Bayesian SR | 平均步数 | 平均 Token 数 |
|---|---|---|---|---|---|---|
| Vanilla Base | 0.4650 | 0.8300 | 0.2700 | 0.8267 | 6.50 | 49.55 |
| Standard LoRA SFT | 0.4650 | 0.8300 | 0.2700 | 0.8267 | 6.50 | 49.55 |
| Evo-Multi-SLM | 0.6200 | 0.9900 | 0.7800 | 0.9851 | 2.64 | 19.60 |
几个值得注意的点:
- LoRA SFT 跟 Vanilla Base 几乎一样。这说明在资源极度受限(数据少、计算少)的情况下,标准的梯度微调根本没学到东西------这恰好印证了论文一开头的论点:小数据 + 小算力的情况下,梯度优化很容易"练不动"。
- Evo-Multi-SLM 的 Pass@1 从 0.465 提升到 0.620,相对提升 33.3%。
- Pass@k 高达 0.99:意味着只要多采样几次,几乎总能采到一个对的答案------说明模型的"潜力"被进化算法充分挖出来了。
- Maj@k 从 0.27 飙到 0.78:这个提升尤其值得关注,说明多数投票(ensemble voting)在这个框架下效果特别好,侧面印证了"多智能体多样性探索"这个设计是有意义的。
- 平均推理步数从 6.5 降到 2.64,平均 token 数从 49.55 降到 19.60:这正是语义效率惩罚(SEP)发挥作用的地方------模型不仅答得更准,而且话讲得更短更精。
4.3 消融实验:拆开看每个组件的贡献
| 模型 | Pass@1 | Pass@k | Maj@k | Bayesian SR | 平均步数 | 平均 Token | 延迟 (ms) | 峰值显存 (GB) | 显存效率 |
|---|---|---|---|---|---|---|---|---|---|
| Evo-Multi-SLM(完整) | 0.6200 | 0.9900 | 0.7800 | 0.9851 | 2.64 | 19.60 | 24049.2 | 1.23 | 0.5043 |
| 去掉语义效率惩罚 | 0.6200 | 0.9900 | 0.7800 | 0.9851 | 2.64 | 19.60 | 35553.1 | 1.23 | 0.5043 |
| 去掉启发式算法(DE) | 0.6200 | 0.9900 | 0.7800 | 0.9851 | 2.64 | 19.60 | 42826.3 | 2.18 | 0.2840 |
这张表很值得细品。三行的准确率指标(Pass@1/Pass@k/Maj@k)完全一样 ------这不是bug,作者专门解释了原因:DE 启发式算法和 SEP 是两个"互补但分工不同"的组件,DE 负责搜索效率(怎么更快更省显存地找到好方案),SEP 负责约束输出形式(怎么让输出更精简),它们影响的是"收敛路径"(延迟、显存),而不是"收敛终点"(准确率)。换句话说:不管用哪种组合,进化搜索最终都能找到差不多准的方案,但找到这个方案的代价(时间、显存)天差地别。
具体来看:
- 去掉启发式算法(DE):延迟从 24049.2ms 飙升到 42826.3ms,峰值显存从 1.23GB 涨到 2.18GB,显存效率从 0.5043 暴跌到 0.2840。说明 DE 算法本身就是控制显存和效率的关键。
- 去掉语义效率惩罚(SEP):延迟从 24049.2ms 涨到 35553.1ms(虽然显存没变,因为 SEP 影响的是输出长度而不是参数搜索本身)。少了 SEP 的约束,模型生成的内容变长,自然推理耗时更久。
- 完整版本在所有效率指标上都是最优,验证了两个组件"协同作用"------DE 管搜索效率,SEP 管输出精简,两者缺一不可。
4.4 跟同类工作 ESSA 的关系
论文里也提到了一个重要的同类工作 ESSA(Evolutionary Strategies for Scalable Alignment)8------它也是用进化策略做 LLM 对齐,但是单模型优化器 ,没有多智能体的概念。Evo-Multi-SLM 在 ESSA 的基础上引入了异质化多智能体种群,让每个 agent 走不同的进化轨迹,靠种群多样性探索对齐空间。作者也坦诚地说明:由于实现和资源限制,本文没有跟 ESSA 做直接的实验对比,这个留作未来工作。
五、总结与思考
Evo-Multi-SLM 这篇论文给出的核心信号是:在资源极度受限的场景下,梯度优化未必是唯一解,进化算法 + 多智能体协同可能是一条性价比更高的路。
三个核心贡献串起来看:
- LoRA 降维解决了"进化算法怎么用在高维参数空间"的问题;
- 差分进化(DE) 提供了一种全靠前向推理、不需要反向传播的搜索机制,直接砍掉了存储梯度和激活值的显存开销;
- 语义效率惩罚(SEP) 则解决了"对齐之后模型变啰嗦"这个常见副作用,用对数尺度的惩罚项逼着模型学会"言简意赅地讲道理"。
当然论文也很坦诚地指出了局限:
- 目前只在 GSM8K 这一个数学推理任务上验证,没有覆盖对话对齐、安全对齐、价值对齐等更广泛的对齐维度;
- 没有跟 ESSA 等同类方法做直接对比;
- 种群里 agent 之间到底是怎么"分工互补"的,目前还没有量化分析,只是观察到了 Maj@k 大幅提升这个现象。
不过整体而言,这是一个挺有意思的方向------尤其是"用一群不完美的小模型协作探索,而不是死磕一个完美模型"这个思路,跟现在多智能体系统(multi-agent systems)的研究热点也是契合的。对做边缘设备部署、端侧小模型对齐的同学,这篇论文提供了一个值得参考的、不依赖梯度的替代方案。
以上就是 Evo-Multi-SLM 这篇论文的解读了,如果有哪里讲得不够清楚,欢迎在评论区交流讨论!论文原文可以通过 DOI 链接查阅:https://doi.org/10.1109/ICSP69961.2026.11540917 。如果我有理解错的地方,也欢迎大家指正,一起学习进步。科研路漫漫,咱们一起慢慢啃!