前言
26年6月初,来自1清华大学 2Galbot Inc. 3上海交通大学 4北京大学 5上海启智研究院的研究者提出了Humanoid-GPT,这是一种 GPT 风格的 Transformer 模型,采用因果注意力机制,并在十亿级规模的动作语料上进行训练,用于全身控制
- 不同于以往受限于数据稀缺,且在灵活性与泛化能力之间存在权衡的浅层 MLP 跟踪器,Humanoid-GPT 在一个 20 亿帧的重定向语料上进行了预训练,该语料将所有主流动作捕捉(mocap)数据集与大规模自有录制数据统一到一起
- 作者宣称,他们通过同时扩展数据规模和模型容量,获得了一个单一的生成式Transformer,它既能跟踪高度动态的行为,又能在前所未见的动作与控制任务上实现前所未有的零样本泛化
第一部分 Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
1.1 引言、相关工作、扩展人形动作数据规模
1.1.1 引言
如原论文所说,针对具身智能体的通用AGI本质上是一个泛化问题:一个人形机器人应当能够在未见过的任务、风格和环境下,稳健地执行全身行为 32,3,12,13
-
在语言和视觉领域,实现泛化最可靠的路径是"规模化"------更大规模的数据、更大规模的模型,以及精心设计的训练目标 32,28,1,13,35,30,15
规模化不仅仅是获得更高平均性能的配方;它往往还能解锁新的能力,并呈现出可预测的趋势 38
-
而此前的人形运动追踪并没有沿着这一发展轨迹前进。目前的追踪器通常是基于小规模动作语料训练的浅层 MLP。即便是被广泛使用的数据集 24,9,17,其包含的运动轨迹数量也只有约 10^4 级别的轨迹(约 720 万帧)
这种规模上的不匹配导致了一种长期存在的失败模式:敏捷性与泛化性之间的权衡
对域内高敏捷动作追踪效果出色的追踪器,在面对未见过的动作风格时往往会失效;
比如最新研究结果清楚地揭示了这一张力:
对此,来自清华、银河通用的研究者们认为,这种权衡并非根本性的问题,而是规模不足和训练设计不匹配的症状。仅仅在同一流水线上简单增加运动片段的数量是不够的
当规模提升几个数量级时,三个问题变得至关重要:
- 应该在什么数据上进行训练,以及如何处理大规模且噪声较多的数据?
- 什么样的模型结构既符合在线跟踪约束,又能随着规模的扩大持续提升性能?
- 当数据集从数百万帧扩展到数十亿帧时,什么样的训练方案仍能保持稳定?
因此,作者提出了Humanoid-GPT------一种围绕"规模科学"构建的通用在线人形运动追踪器

- 其论文地址为:Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
- 其项目地址为:qizekun.github.io/Humanoid-GPT
其github地址为:github.com/GalaxyGeneralRobotics/Humanoid-GPT
简言之,以往的工作,要么是在有限的动作时长上应用 Transformer 控制器8,要么是在数亿帧的数据上扩展基于 MLP 的策略23,作者宣称,据他们所知,Humanoid-GPT是第一个
- 将一个大型的强化学习动作专家库蒸馏为单一的 GPT 风格跟踪器
- 在一个精心筛选的 20 亿帧语料库上进行训练
- 系统性地刻画了数据规模、模型规模和多样性平衡如何共同决定在真实人形机器人硬件上进行零样本敏捷运动追踪的能力
具体而言
第一,对于数据规模
-
作者在一个全新的尺度范式下构建了用于追踪的运动语料库。且汇集了所有广泛可用的动作捕捉(mocap)数据源,包括 Lafan1 9、AMASS24、Motion-X++ 43、PHUMA 16 和MotionMillion 7,并补充了一个大规模的内部采集数据集,以覆盖真实世界场景
-
经过严格的筛选、分段和数据增强后,作者获得了 20 亿个经过 G1 重定向的运动帧/token,比以往的追踪器训练集大 200倍以上
如此规模迫使作者必须面对那些小型系统可以忽略的问题:
比如重新设计了关键奖励组件,并为了保持训练过程的稳定,需要适当设置超参数
更为关键的是,作者首次系统性地证明:当模型规模和训练集规模得到恰当扩展时,基于视频估计的运动信息可以在实质上提升跟踪效果
------------
可能有读者疑问,那sonic没做到么?
1 sonic用的MLP控制器,数据规模的增长容易导致MLP很快趋于饱和;
2 sonic无法兼顾敏捷性和泛化性;
3 sonic的数据规模是 100M(1亿帧),而Humanoid-GPT 直接拉高了 20 倍,达到了 2.0B(20亿帧) 的规模
第二,对于模型规模,即用于在线跟踪的现代结构
- 用于控制的运动跟踪本质上是因果的:在测试时,策略无法访问未来的观测。许多现有的跟踪器仍然依赖非因果的建模选择或容量受限的 MLP
- 作者则采用可扩展的 Transformer,并使用类 GPT 的因果注意力机制。该模型通过因果时间注意力为每个关节预测 PD 目标,这种设计从一开始就与部署时的约束相一致
与在早期就出现性能饱和的浅层 MLP 和非因果变体不同,这种结构还能随着数据量和模型规模的增大而平滑扩展
第三,对于平衡的多样性至关重要
-
更多数据并不自动意味着更好的泛化效果
在大型动作语料库中,常见风格占据主导,而稀有但重要的行为则淹没在长尾中 -
作者提出谐波运动嵌入(Harmonic MotionEmbedding,HME),作为一种表征学习工具,能够直接从原始动作数据中度量并组织动作多样性
HME 使得在训练过程中可以进行关注多样性、分布均衡的采样
作者认为,他们的分析揭示了一个简单但有力的洞见:多样性与平衡二者缺一不可。只有多样性而没有平衡,仍然会对高频模式过拟合;只有平衡而缺乏多样性,则会限制模型能力上限
1.1.2 相关工作
第一,对于大规模运动数据
-
大规模动作数据集已成为学习具有良好泛化能力的人体运动跟踪所不可或缺的基础
早期的数据集提供了高质量但受限于摄影棚环境的动作数据,从而在多样性上受到限制9,24,17
借助基于视频的重建技术和大规模合成数据生成,近期的数据集大幅扩展了动作覆盖范围,引入了多种多样的活动、风格和人物主体,并配合多模态监督信号
20,43,7,25
-
更近一步,16 提供了在物理上自洽的动作数据,包含接触建模、关节约束以及减小脚部滑动等机制,相比纯运动学数据源在稳定性方面具有优势
总体而言,这些日益多样化且具有物理基础的数据集为动作形态提供了更加丰富的变化形式和更强的物理先验,构成了构建统一且鲁棒的人体运动跟踪系统的关键基础
第二,学习人体运动追踪
-
基于物理的追踪旨在从参考动作中生成在时间上连贯且在动力学上可行的全身控制
早期工作在仿真环境中建立了这样一种范式:将模仿学习与具备接触感知能力的稳定性控制相耦合21,22,6,44
而后续的工作流程 则将这一范式扩展到在特定平台上的现实世界部署
8,10,5,14,40,39,18,29,42,45
-
近期的工作重心正逐渐转向提升泛化能力
GMT 4采用带自适应采样的专家混合(Mixture-of-Experts)方法;
UniTracker 41 则采用基于 CVAE的师生框架------二者都在一定程度上提升了覆盖率,但仍受限于较小的运动尺度SONIC 23 利用 MLP控制器扩展到 1 亿帧的数据规模,然而随着数据增多,MLP 的容量趋于饱和
HumanPlus 8 引入了Transformer 控制器,却仍使用标准 PPO 进行训练,从而未能充分发挥 Transformer 所固有的并行优势
如表1所示

现有方法要么依赖精心整理的动作集合,要么采用在扩展性方面表现不佳的架构。Humanoid-GPT 将跟踪问题重新表述为类似 GPT 的序列建模:即将数百个强化学习专家蒸馏到一个在20 亿帧数据上训练的因果 Transformer 中,从而在同规模的 MLP 出现性能平台期的情况下,依然实现了强大的零样本泛化能力
1.1.3 扩展类人动作数据规模:包含数据整理和谐波运动嵌入
如原论文所说,作者首先收集并整理大规模人类动作数据,以确保动作动力学的真实性,然后将这些动作重定向到人形机器人的关节空间
首先,对于数据整理
-
构建高质量的动作数据集对于在零样本人形体动作跟踪中保证运动动力学的真实性和多样性至关重要
现有的数据集 24,9,20,25往往只包含有限类别的动作捕捉序列,或者在物理合理性与空间对齐方面存在不一致,这限制了它们在复杂的全身跟踪场景中的泛化能力
近期在大规模动作生成 7 和物理约束动作过滤 16 方面的进展,带来了丰富且高质量的动作先验,从而大幅拓展了动作分布的覆盖范围
为充分利用这些可用资源,作者通过聚合 AMASS 24、LAFAN19、MotionMillion 7 和 PHUMA 16,构建了一个大规模动作语料库,如图 2(a)所示,涵盖了广泛的人体活动种类,为Humanoid-GPT 提供了基础
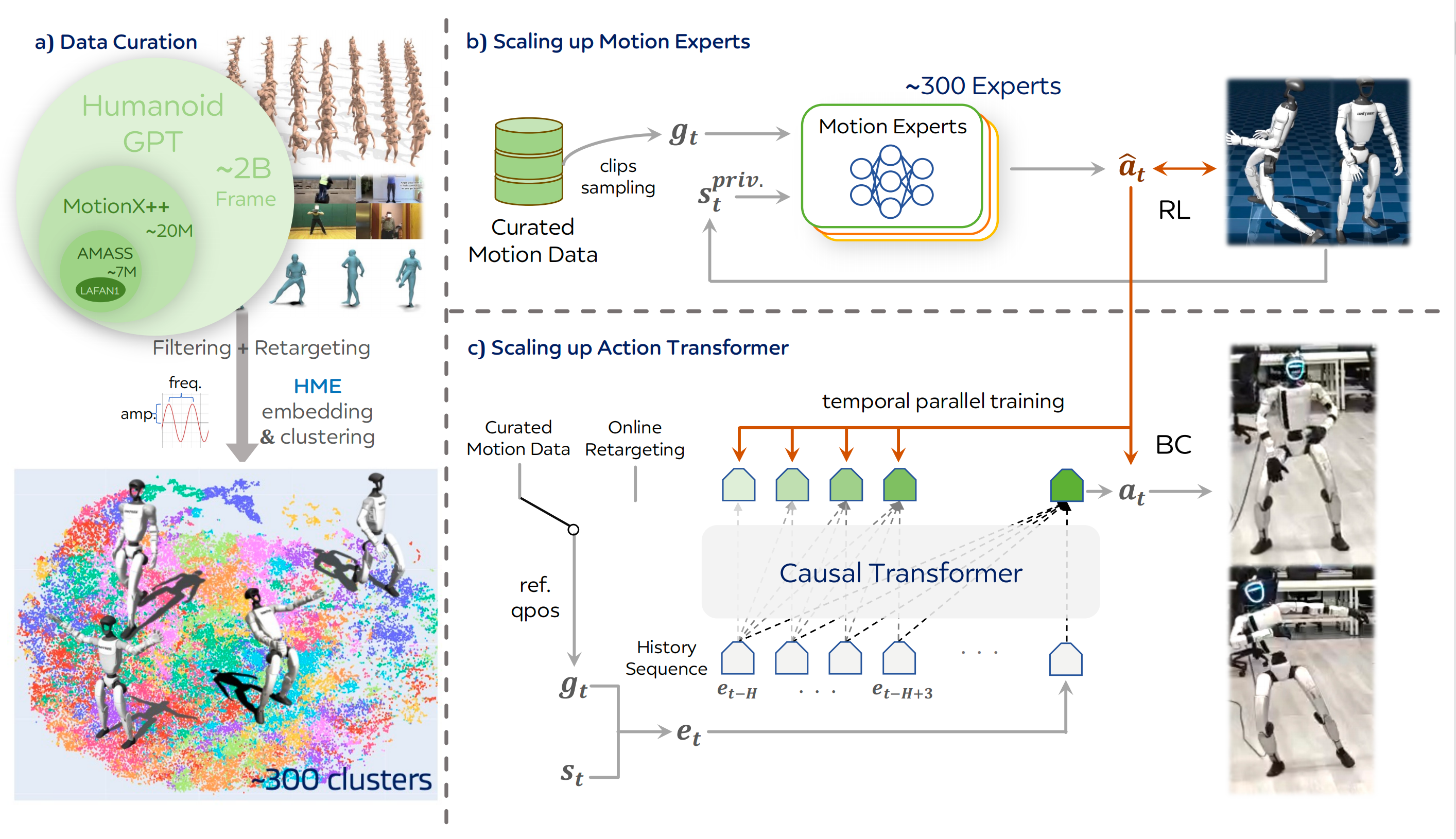
-
在将各个数据集汇总为一个统一语料库之后,作者采用现成的运动重定向框架
2-Retargeting matters: Generalmotion retargeting for humanoid motion tracking
详见本博客中的解读《GMR------人形动作追踪的通用动作重定向:在不做复杂奖励和域随机化的前提下,缓解或消除重定向带来的伪影(含PHC的详解)》将每一段人体运动序列映射到 Unitree-G1 仿人机器人具有 29 自由度(29-DoFs)的关节空间中
在这一过程中,作者进一步滤除包含显式物体交互的序列------例如坐在椅子上、游泳或上下楼梯------以确保生成的运动在空旷场景下与人形机器人的驱动能力兼容
为了进一步丰富时间层面的多样性并提升对运动速度变化的鲁棒性,作者对每一段序列施加运动时间扭曲(time-warping)增强 ,通过统一地加速和减速,最终将数据集规模扩充至原来的约五倍
由此得到的数据集干净、物理一致且多样性良好,适用于后续基于强化学习的专家策略训练
其次,对于谐波运动嵌入
-
为在运动覆盖度与训练效率之间取得平衡,作者将完整的运动语料划分为多个簇,并让每个专家在一个特定的运动子集上进行训练
为在潜在空间中直接对运动进行聚类,作者提出了一种新的嵌入表示,称为谐波运动嵌入(Harmonic Motion Embedding,HME)
-
具体而言,作者首先在不同的数据划分上训练多个周期自编码器(Periodic Autoencoders)33,以从每个动作序列中提取出各关节的周期性振幅和频率
对于每个序列,作者对这些关节级谐波特征的均值和标准差进行聚合,从而获得其 HME 向量,进而为整个语料库生成一种紧凑且具有描述性的嵌入表示
最后,作者在所有 HME 嵌入上应用K-Means 聚类,并以成对距离作为相似度度量,大致生成 300 个运动簇
每个簇包含约 1k--2k 个序列,在保持较强簇内一致性的同时,又能较好地覆盖整体运动分布
2.1 可扩展生成式跟踪器
Humanoid-GPT 框架通过两阶段流程构建:
- 首先训练基于强化学习的运动专家
- 然后进行 Transformer 蒸馏
作者声称,他们的模型使得人形机器人在无需任何微调的情况下即可跟踪任意人类动作
2.1.1 训练运动专家
为使 Humanoid-GPT 具备多样化的运动先验,作者训练了多个运动专家网络,使其共同覆盖数据集中所呈现的动态分布
在每个簇上,作者训练一个基于PPO 的策略来跟踪该簇内的所有序列,如图2(b) 所示
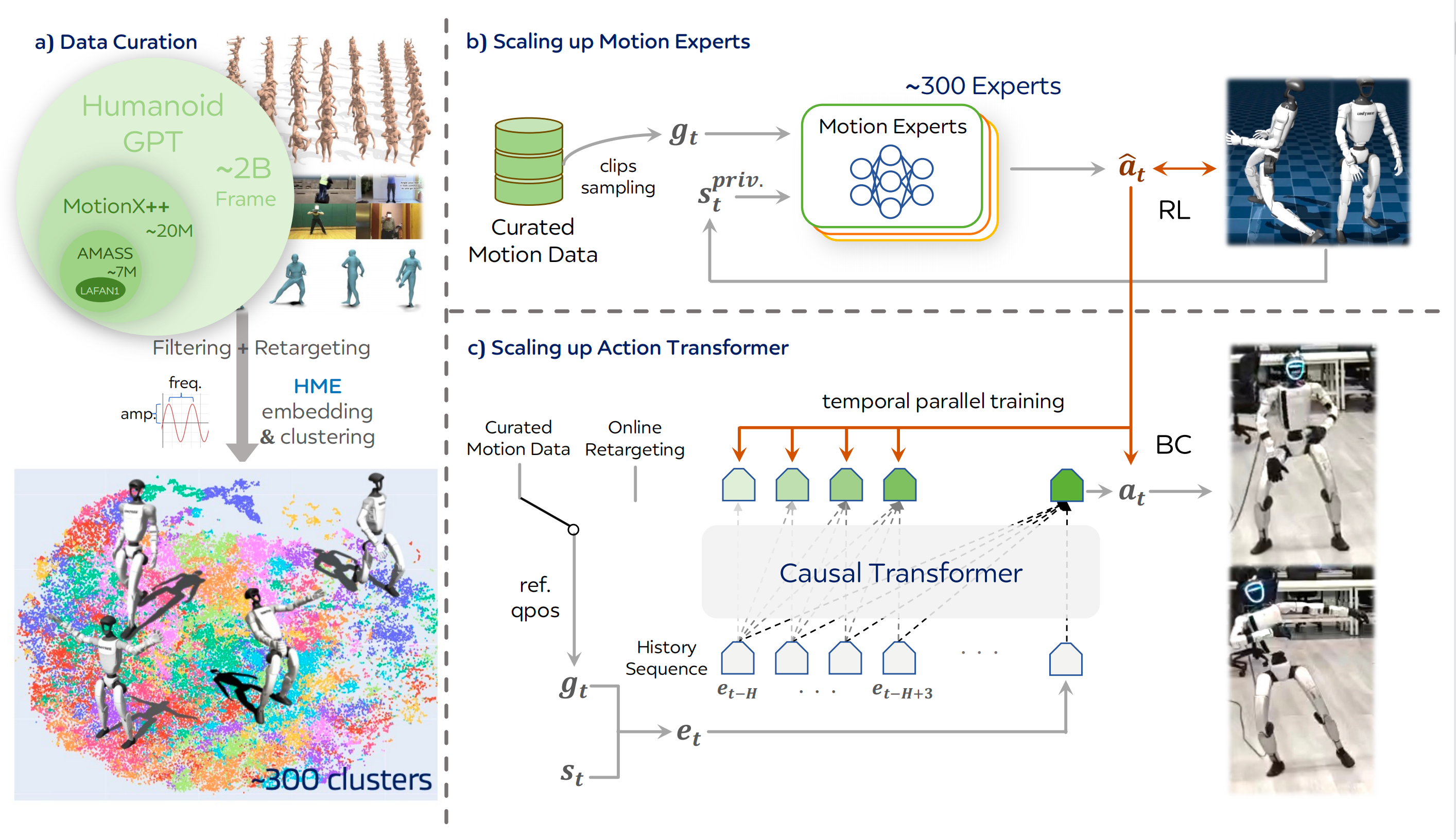
该策略被表述为,其将输入的参考关节和机器人本体感受观测映射到低层电机动作
在每个时间步 ,策略接收当前**特权机器人状态
**以及从运动片段中提取的目标参考姿态
- ***状态
- 策略输出逐关节动作
- 运动跟踪的目标是驱使机器人的状态去匹配:目标姿态
为了实现物理上扎实的跟踪,奖励在身体关键点层面进行计算,包括对身体关键部位(例如手臂、髋部、脚、骨盆)的位置和速度一致性项
令 表示被跟踪的身体关键点集合
- 对于时间
- 并令
给定正的关键点权重 和缩放因子
,抽象关键点奖励被形式化为
指数形式在所有身体关键点上柔和地惩罚位置、朝向和速度的偏差,而由若干惩罚项组成,如自接触和平滑性,从而促进全局精确但局部稳定的运动跟踪
- 在训练过程中,作者随机采样短时运动片段作为跟踪目标,并分别使用根姿态误差、速度误差以及稳定跟踪时长来评估每个专家
这些度量指标确保每个聚类中的运动复现过程都能收敛到物理一致的结果 - 训练完成后,作者仅保留那些在高保真度和长时间稳定性方面表现优异的专家,由此构建出一个多样化的运动先验库,为 Humanoid-GPT 在异质运动模式下提供具备物理约束的初始化
2.1.2 构建零样本基础级跟踪器
前文训练的运动专家能够在各自簇内精确复现具有物理约束的运动,但在遇到分布外的运动目标时性能往往急剧下降
为弥合不同运动域之间的差距并整合它们的专业知识,作者引入了一种如图 2(c) 所示的蒸馏阶段,将所有专家 的行为转移到一个统一的策略中,并采用DAgger 31 框架,将所有运动专家的知识蒸馏到单一的通用策略中
-
为了高效地提炼专家行为,作者将蒸馏过程重新表述为一个序列建模问题,并采用基于Transformer36 的通用跟踪器
-
在每个时间步
长度为
前向传播后,所有输出位置的动作都会由对应的教师
在推理过程中,作者维护一个最多包含 H 个历史token 的队列作为 transformer 的输入,并将输出序列中最后一个位置的结果作为当前的控制目标
总之,Humanoid-GPT 模型的这种设计,自然地利用了 Transformer 在并行序列监督和自回归时间预测方面的内在优势
此外,由于不同位置的 token 会关注不同长度的历史上下文,训练后的模型会隐式地学习到位置不变的时间预测能力,从而即使在一个 episode的开端------历史信息十分匮乏的情况下------也能够输出稳定且物理一致的控制目标
// 待更