以下内容参考https://www.rethink.fun/
常见任务
在LLM诞生之前,NLP是分成多个任务研究的,常见任务有:
- 文本分类,最后输出每类的概率
- 文本回归,最后输出一个连续的分数,类似于一般的回归任务
- 翻译,改写,经典的序列到序列任务,输入输出都是序列
- 实体识别(Named Entity Recognition,NER),输出和输入等长,输出标记每个token属于什么实体,最后一般能提取出一句话的所有名词
- 文本蕴含,输入两个序列,输出一个分类结果,表示两个序列是否有蕴含关系,也就是逻辑上一个能否推出另一个
- 语言模型,也就是现在最火的对话式模型,输出一个序列,但输出并没有严格的格式限制,可以模型随意发挥
分词
输入的自然语言,想要通过计算处理它,必须转化成数据,这分为两步,第一步是划分token,第二步是把token映射到数据。第一步就是分词(tokenizer),第二步则是词嵌入(embedding)
我们先来看分词,对于中文,除了标点,一句内是没有划分标志的,所以中文断句是个很大的问题。英文虽然有空格断句,但是也需要分词,不能直接按照空格,因为英文的造词法决定了词是很多的,如果每个词都单独划出一个token,词典会太大,比如一个词的各个时态显然可以划分成原型+各个时态的标志(ing,ed)。
这里介绍一个最常见的分词方式,BPE(Byte Pair Encoding)分词,BPE 的核心思想是"贪心自底向上合并":从字符级别开始,不断找出语料库中出现频率最高的两个连续字符对,把它们合并成一个新的子词,直到词表达到预设的大小。
简化案例:假设我们的训练语料库里只有 3 个词,它们出现的次数如下:hug (出现 5 次)pug (出现 5 次)pun (出现 12 次)
- 第 0 步:初始化词表将所有词拆成单个字母,并在结尾加上结束符 。此时基础词表为:h, u, g, p, n, 。
- 第 1 轮迭代:找最高频的组合统计所有相邻字母对的频率:u 和 g 组合:在 hug 出现 5 次,pug 出现 5 次 →\rightarrow→ 共 10 次。u 和 n 组合:在 pun 出现 12 次 →\rightarrow→ 共 12 次。p 和 u 组合:在 pug(5) 和 pun(12) 出现 →\rightarrow→ 共 17 次。(注:这里简化的最高频假设为 u 和 n) 经过统计,u 和 n 连续出现的次数最多(12次),于是我们将它们合并为新子词 un。词表更新为:h, u, g, p, n, , un
- 第 2 轮迭代:继续合并接着统计,发现 p 和 un 的组合(在 pun 中)出现了 12 次,又是最高,于是合并为 pun。词表更新为:h, u, g, p, n, , un, pun
- 第 3 轮迭代:接下来发现 u 和 g 组合出现了 10 次,合并为 ug。词表更新为:h, u, g, p, n, , un, pun, ug这个过程会一直重复(比如循环 32000 次),直到词表里包含了足够多的高频词和子词。
这个算法的强大之处在于,能划分原型词根,也能划分前后缀,最后的词典会包含happy这样的词根,也会有ful,un这样的前后缀,当前后缀和词根作为两个token连续出现,可以表示单词的变形。
前面我们说的是BPE的训练过程,训练出来之后,实际分词时,还是先把序列拆成字符,然后每次把当前序列里出现的词对中,在字典中优先级最高的进行合并,一直合并直到不存在字典中的待合并词对,这类似一个链表的合并过程,n个节点的话,n-1个间隙,有n-1个可合并词对,每次选一个合并,元素个数-1。字典中的优先级就是在训练过程中的合并顺序,训练中出现频率越高的词对合并会越早。
BPE的推理过程很像算法竞赛题,这里展开说一下,大概流程就是:
- 初始一个链表,每个节点是一个词,n个节点,n-1个相邻对,可合并
- 初始一个map词典,记录每个词对的优先级。
- 构造一个优先队列,保存每个相邻对的他们的优先级,按照优先级排序。
- 每次取出优先级最高的相邻对,在链表上进行合并,不妨设abcd,我们合并bc,合并后,原有的相邻对(a,b),(b,c),(c,d)失效,形成新的相邻对(a,bc)(bc,d),更新单调队列,把失效的删除,新增的相邻对,如果在词典中存在,则查询优先级,插入优先队列。
- 重复上述过程,直到队列为空。注意token为空,可能是合并到只剩一个节点了,也可能是新的相邻对不在词典里,没有插入队列
下面是个简单的模拟实现
c
#include <iostream>
#include <string>
#include <vector>
#include <queue>
#include <unordered_map>
#include <map>
#include <iomanip>
using namespace std;
// 定义 BPE 规则的优先级(Rank 值越小,优先级越高)
// Key: 相邻的两个 Token 字符串对, Value: Rank
map<pair<string, string>, int> bpe_ranks;
// 双向链表节点定义
struct Node {
string token;
int prev;
int next;
bool is_valid; // 标记节点是否有效(是否已被合并销毁)
};
// 优先队列(堆)中存储的元素
struct PairItem {
int left_idx;
int right_idx;
int rank;
// 小顶堆比较函数:Rank 越小越优先
bool operator>(const PairItem& other) const {
return rank > other.rank;
}
};
// 打印当前链表状态的辅助函数
void print_current_tokens(const vector<Node>& list, int head) {
cout << "当前序列: ";
int curr = head;
while (curr != -1) {
cout << "[" << list[curr].token << "] ";
curr = list[curr].next;
}
cout << endl;
}
// BPE 推理核心函数
vector<string> bpe_tokenize(const string& word) {
if (word.empty()) return {};
// 1. 初始化双向链表:将单词拆成单个字符
vector<Node> nodes;
for (size_t i = 0; i < word.length(); ++i) {
Node node;
node.token = string(1, word[i]);
node.prev = (i == 0) ? -1 : (int)i - 1;
node.next = (i == word.length() - 1) ? -1 : (int)i + 1;
node.is_valid = true;
nodes.push_back(node);
}
int head = 0; // 链表头指针
// 2. 初始化优先队列(小顶堆)
priority_queue<PairItem, vector<PairItem>, greater<PairItem>> pq;
// 辅助函数:尝试将相邻对推入堆中
auto try_enqueue_pair = [&](int left, int right) {
if (left == -1 || right == -1) return;
pair<string, string> p = {nodes[left].token, nodes[right].token};
if (bpe_ranks.count(p)) {
pq.push({left, right, bpe_ranks[p]});
}
};
// 初始把所有相邻对放进堆
for (size_t i = 0; i < nodes.size() - 1; ++i) {
try_enqueue_pair(i, i + 1);
}
cout << "=== 开始 BPE 合并推理 ===" << endl;
print_current_tokens(nodes, head);
// 3. 核心循环:不断合并最高优先级的对
while (!pq.empty()) {
PairItem top = pq.top();
pq.pop();
int l = top.left_idx;
int r = top.right_idx;
// 延迟删除检查(Lazy Deletion):
// 如果左节点或右节点已经失效,或者它们在链表中已经不相邻了,说明这个对是过期的
if (!nodes[l].is_valid || !nodes[r].is_valid || nodes[l].next != r) {
continue;
}
// 命中有效合并!
string merged_token = nodes[l].token + nodes[r].token;
cout << "\n> [合并动作]: 命中规则 ('" << nodes[l].token << "', '" << nodes[r].token
<< "') -> '" << merged_token << "' (Rank: " << top.rank << ")" << endl;
// 执行合并:把新内容写入左节点
nodes[l].token = merged_token;
// 销毁右节点
nodes[r].is_valid = false;
// 调整双向链表指针
int next_of_r = nodes[r].next;
nodes[l].next = next_of_r;
if (next_of_r != -1) {
nodes[next_of_r].prev = l;
}
print_current_tokens(nodes, head);
// 形成新的相邻对,推入堆中
int prev_of_l = nodes[l].prev;
try_enqueue_pair(prev_of_l, l); // 新的左侧邻居对
try_enqueue_pair(l, next_of_r); // 新的右侧邻居对
}
// 4. 收集最终结果
vector<string> result;
int curr = head;
while (curr != -1) {
result.push_back(nodes[curr].token);
curr = nodes[curr].next;
}
return result;
}
int main() {
// 构造一些预训练好的 BPE 规则
// 这里的数字代表 Merge 顺序(Rank 越小越优先)
bpe_ranks[{"e", "s"}] = 1;
bpe_ranks[{"es", "t"}] = 2;
bpe_ranks[{"h", "i"}] = 3;
string input_word = "highest";
cout << "输入原始字符串: " << input_word << "\n" << endl;
vector<string> tokens = bpe_tokenize(input_word);
cout << "\n=== 最终 Tokenization 结果 ===" << endl;
for (const string& t : tokens) {
cout << "\"" << t << "\" ";
}
cout << endl;
return 0;
}词嵌入
词嵌入这个名字看着奇怪,但这是由他的英文embedding翻译来的,实际上问题是我们需要把token映射到数据,有很多种映射方法,其中一种方法叫词嵌入
one-hot编码
映射有很多种方式,最无脑就是one-hot,词典大小为n,则把每个词都映射到一个长度n的向量,第i个token,映射后第i位为1,其余位置为0
这样的好处编码简单,但缺点是:
- 词典有几万个词是正常的,那一个编码维度就上万,太大了
- 如果用余弦相似度衡量两个token的相似度,任意两个token都是正交的,没有任何关系。但有些token之间的关系显然应该更近,比如西红柿和番茄。
embedding词嵌入
词嵌入解决了one-hot的两个问题。解决方法是降低编码维度,通常就128,256维向量,每个维度都可以有值,这个值是训练出来的。
优点是:
- 编码维度低,便于计算存储
- 训练中,会使得语义上相关的token,各个维度更加接近,也就是token编码方式就包含了一些知识在里面
词嵌入训练方法 CBOW
CBOW的思想是,token的含义要从上下文推断,所以训练过程中,每个词的嵌入,计算方法为相邻token的平均值,然后把这个平均值套一个线性层,映射到各个token,相当于一个分类任务,用交叉熵计算loss,反向传播更新这个token的嵌入。
比如这张图就是I love natural language processing输入,训练natural这个token嵌入的前向传播流程。训练时每一轮遍历所有token,都做类似的操作。
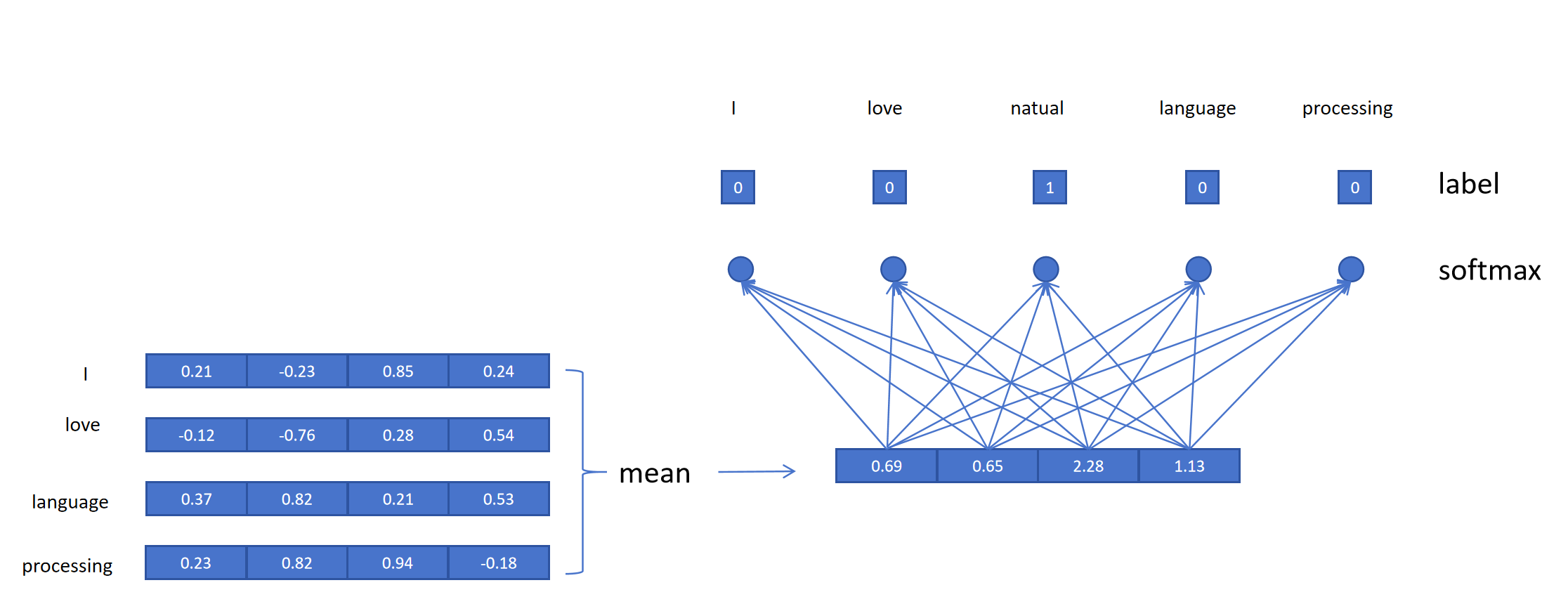
最后我们得到的数据是一个矩阵,每一行是一个token的嵌入向量。想得到低i个token的词嵌入,就用这个token的one-hot表示左乘这个矩阵,如图
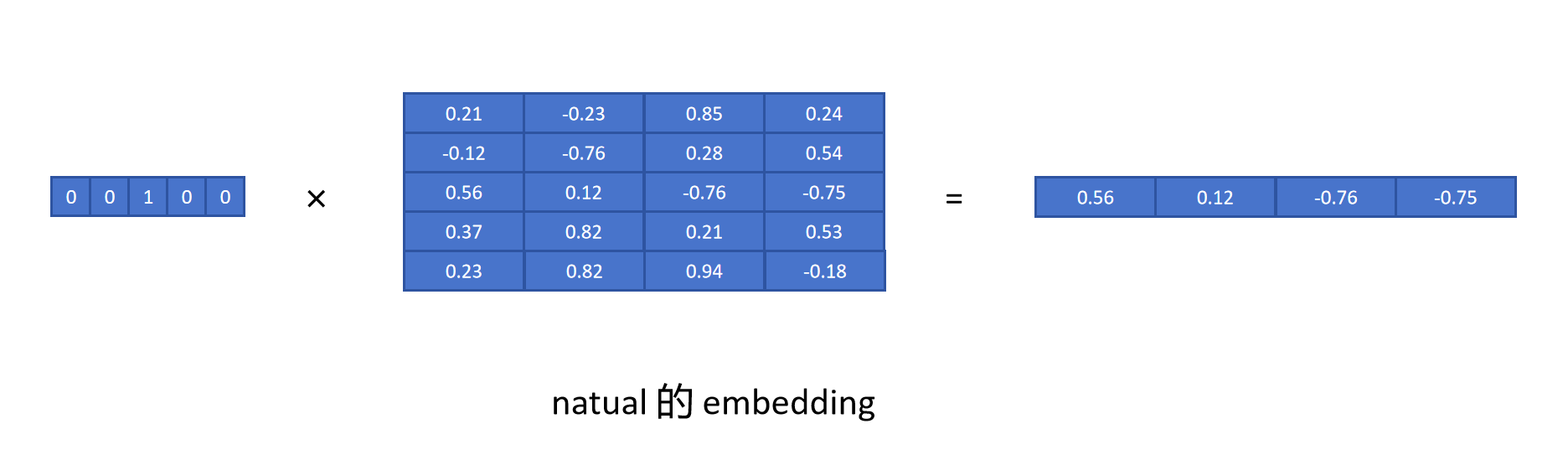
简单示例
py
import torch
import torch.nn as nn
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
# 1. 词嵌入层:将词索引转换为低维稠密向量
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 2. 输出线性层:将聚合后的上下文特征映射回词表空间
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, inputs):
"""
inputs: 形状为 [batch_size, context_size] 的张量,包含上下文词的索引
"""
# 提取上下文词的 embedding -> 形状: [batch_size, context_size, embedding_dim]
embeds = self.embeddings(inputs)
# 在 context_size 维度上求平均,代表"词袋"聚合 -> 形状: [batch_size, embedding_dim]
context_mean = torch.mean(embeds, dim=1)
# 投影到词表分类空间 -> 形状: [batch_size, vocab_size]
out = self.linear(context_mean)
return out
# === 极简前向传播测试 ===
if __name__ == "__main__":
VOCAB_SIZE = 1000
EMBEDDING_DIM = 128
BATCH_SIZE = 2
CONTEXT_SIZE = 4 # 比如窗口大小为 2,左边 2 个词 + 右边 2 个词
model = CBOW(VOCAB_SIZE, EMBEDDING_DIM)
loss_fn = nn.CrossEntropyLoss()
# 模拟输入:2 个样本,每个样本有 4 个上下文词
dummy_context = torch.tensor([[3, 5, 12, 9],
[42, 8, 19, 55]], dtype=torch.long)
# 模拟标签:目标中心词索引
dummy_target = torch.tensor([7, 23], dtype=torch.long)
# 前向传播
logits = model(dummy_context)
loss = loss_fn(logits, dummy_target)
print(f"输入形状: {dummy_context.shape}")
print(f"输出形状 (Logits): {logits.shape}") # 应该是 [2, 1000]
print(f"当前 Loss: {loss.item():.4f}")词嵌入训练方法 Skip-gram
类似的,仍然基于:一个词的语义要看上下文这一点。但是反过来,遍历所有token,用当前枚举token去更新周围上下文token。由于只用到当前token一个数据,不用取平均,直接把这个token表示套一个线性层,还是做分类,映射到每个token,交叉熵训练分类。
模型采样
先跳过架构和训练,那都是重头戏,后面讲。剩下的基础知识是模型如何采样。模型现在只会输出词典中每个token出现在下一个位置的概率,我们要怎么根据这个概率输出一段话?
贪心采样
最基础的就是贪心采样,每一步都选当前概率最大的token
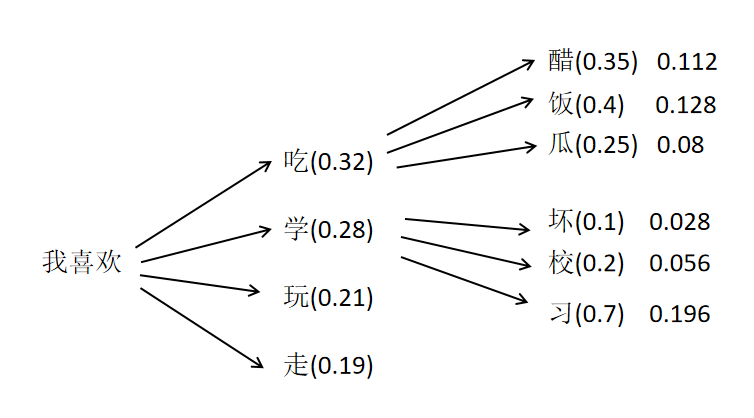
但是,问题是我们想要的是生成的文本,联合概率最大,也就是路径上每一步选中的token概率乘积最大。这会出现贪心算法经典的问题,每一步都是局部最优,加起来不一定是全局最优,比如上面这个例子,贪心会输出:我喜欢吃饭,但实际联合概率最大的路径是:我喜欢学习。
可能的算法优化?
这个问题抽象出来,看起来似乎就是DAG上找一条乘积最大的路径,那能否DP?注意到一点,一个状态,下一个token的概率,和这个状态的序列整体有关,而不是和结束token有关,如果只和末尾几个token有关,状态不多,还可以DP,但和整体有关想DP就必须把整个序列都保存下来!那任何一个状态都只对应搜索树上一种方案,DP退化到DFS了。
而DFS,状态空间几乎等于factor(词典大小)factor(词典大小)factor(词典大小),完全不可行。
Beam Search 束搜索
既然只能搜索,那加速只能做一些搜索剪枝了。
Beam搜素的思想就是BFS,但每一层只保留几个概率最大的路径,例如Beam=2的话,搜索结果如图。
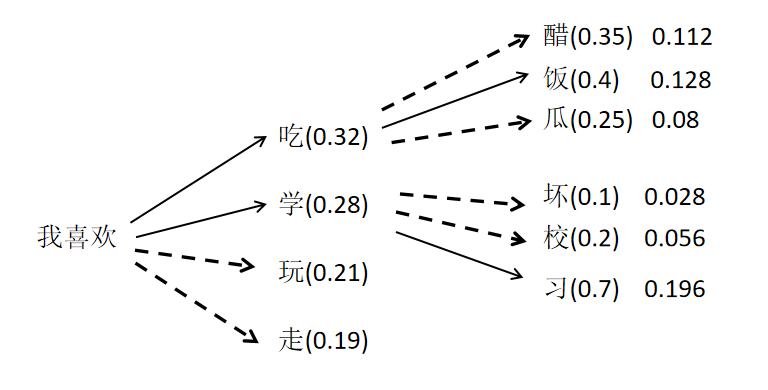
这在实现上就是限制队列大小,使用优先队列的逐层BFS。当然由于我们是逐层的,可以用排序替换优先队列,常数更小
c
#include <iostream>
#include <vector>
#include <cmath>
#include <algorithm>
using namespace std;
// 模拟模型预测:输入当前路径,返回每个 Token 的对数概率 log(p)
vector<double> get_log_probs(const vector<int>& path, int vocab_size) {
vector<double> log_probs(vocab_size);
int last_token = path.empty() ? 0 : path.back();
for (int i = 0; i < vocab_size; ++i) {
// 简单模拟不同的概率,实际中由神经网络输出
double p = (sin(last_token + i) * 0.45 + 0.5);
log_probs[i] = log(max(p, 1e-6));
}
return log_probs;
}
// 核心的路径表示
pair<vector<int>, double> 代表一条路径:{Token序列, 累计得分}
typedef pair<vector<int>, double> Beam;
int main() {
int beam_size = 3;
int max_len = 4;
int vocab_size = 5;
// 1. 初始化池子:只有一条初始路径,分数为 0
vector<Beam> current_beams = { {{1}, 0.0} }; // 假设 1 是起始 Token <SOS>
// 2. 步步推进生成序列
for (int step = 0; step < max_len; ++step) {
vector<Beam> all_candidates;
// 展开当前池子里的每一条路径
for (const auto& beam : current_beams) {
vector<int> path = beam.first;
double score = beam.second;
// 拿到当前路径下一步所有 Token 的 log 概率
vector<double> log_probs = get_log_probs(path, vocab_size);
// 每一个可能的新 Token 都拼上去,形成新的候选
for (int token = 0; token < vocab_size; ++token) {
vector<int> new_path = path;
new_path.push_back(token);
double new_score = score + log_probs[token]; // 概率对数相加
all_candidates.push_back({new_path, new_score});
}
}
// 3. 把所有扩展出来的候选按分数从大到小排序
sort(all_candidates.begin(), all_candidates.end(), [](const Beam& a, const Beam& b) {
return a.second > b.second;
});
// 4. 贪心切片:只保留分数最高的前 beam_size 个,作为下一轮的池子
current_beams.clear();
for (int i = 0; i < min(beam_size, (int)all_candidates.size()); ++i) {
current_beams.push_back(all_candidates[i]);
}
}
// 5. 打印最终的最优前 3 个结果
cout << "=== 精简版 Beam Search 结果 ===" << endl;
for (int i = 0; i < beam_size; ++i) {
cout << "得分: " << current_beams[i].second << " | 路径: ";
for (int token : current_beams[i].first) cout << token << " ";
cout << endl;
}
return 0;
}随机生成
前面的贪心和束搜索都是确定策略,如果希望每次生成都可能不一样,就要引入随机性。
有topk和topp两种随机策略。
- topk:选出概率最大的topk个token,重新在这k个token里重新softmax,计算概率,然后根据概率随机抽样。
- topp:从大到小选任意个,直到概率加起来超过p。接下来的采样和topk一样
这两个方法都可以附加一个参数tempurature温度,作用是,做softmax前,先对所有logits概率除以温度,这样温度越大,logits被除之后越小,经过softmax,映射后的概率差距越小,token间概率差距变小了,也就是随机性变大了。如下图
