FAISS 的核心场景、数据量级与工程选型:从 RAG 到千万级向量检索
先说结论
FAISS 的核心场景不是"存储数据",而是"高效地做向量相似度检索"。
更准确地说,它解决的是这样一个问题:给定一个查询向量,从大量已有向量中,快速找出最相似的 TopK 个结果。
这个能力看起来简单,但它是很多 AI 应用的底层能力。RAG 知识库、语义搜索、推荐召回、相似图片检索、相似问题合并、日志聚类、代码片段检索,本质上都可以抽象成同一件事:
text
对象 -> embedding 向量 -> 相似度检索 -> TopK 候选FAISS 正是为这类问题设计的。
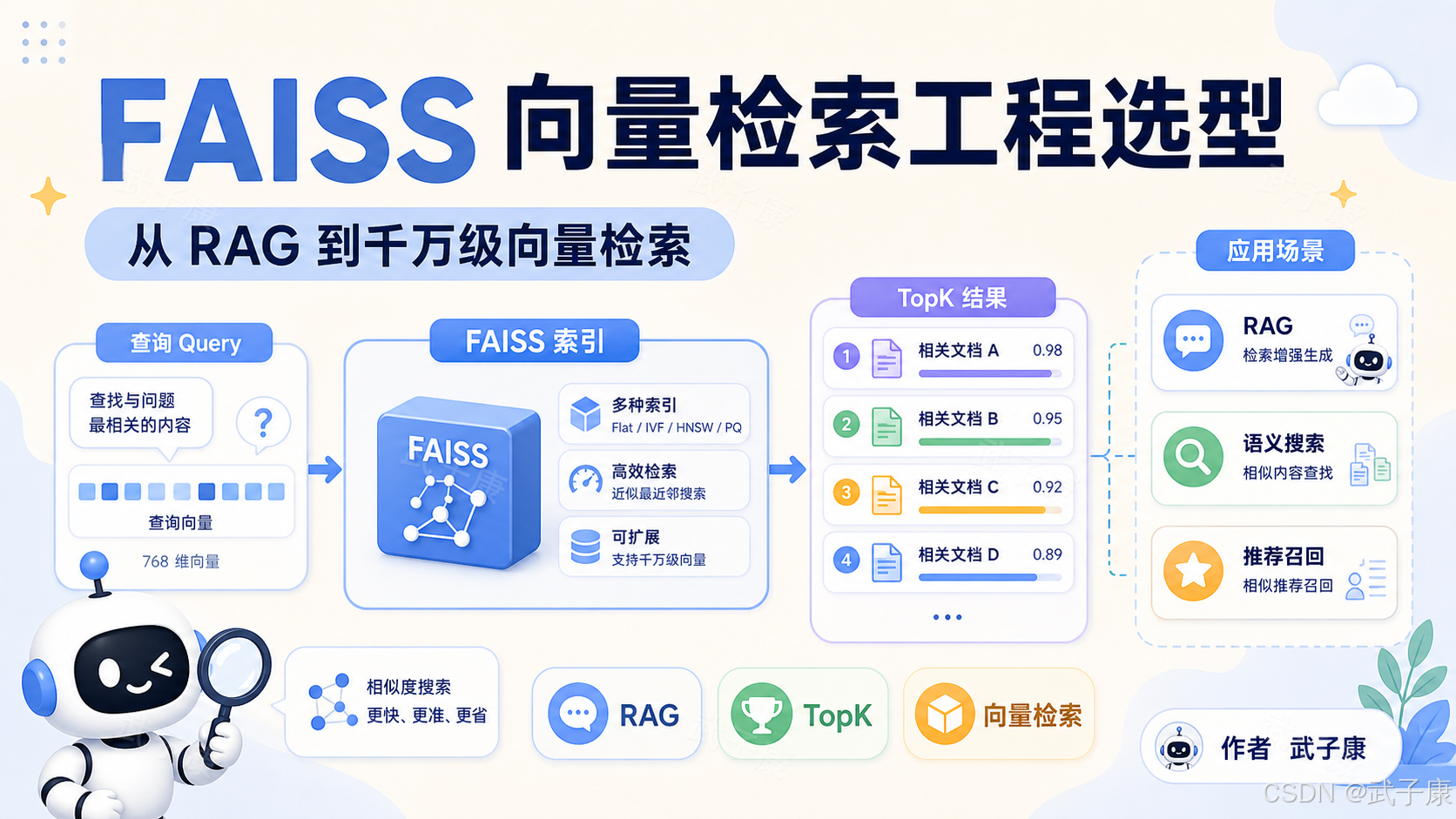
它适合的不是传统关键词检索,而是向量空间里的近邻搜索。关键词检索关心的是"字面上有没有出现某个词",向量检索关心的是"含义上是否接近"。
比如用户搜索"接口响应很慢怎么优化",关键词检索可能优先匹配包含"接口""响应""慢"的文章;向量检索则可能召回 Redis 缓存优化、SQL 慢查询治理、异步化改造、网关超时配置、线程池阻塞排查等语义相关内容。
这也是 FAISS 在 LLM 应用时代重新变得重要的原因。
LLM 负责理解、生成和推理,但它不适合直接记住大量私有知识、企业文档、代码仓库和业务数据。RAG 通常会把外部知识切分成 chunk,再生成 embedding,存入向量索引。用户问题也会转成 embedding,通过 FAISS 找到最相关的文档片段,再交给 LLM 生成答案。
一句话概括:FAISS 是适合本地、自建、高性能向量检索的底层库。它不是完整数据库,不负责复杂权限、事务、在线多租户、复杂过滤和完整元数据治理。它更像一个高性能检索引擎内核。
FAISS 到底是什么?
FAISS,全称是 Facebook AI Similarity Search,是 Meta AI 开源的向量相似度搜索库。它主要用于高效搜索稠密向量集合,并支持多种索引结构、距离度量、压缩方式和 GPU 加速能力。
它和 MySQL、PostgreSQL、Elasticsearch、Milvus、Qdrant、Weaviate、pgvector 的定位不同。
MySQL 和 PostgreSQL 是通用关系型数据库,擅长结构化数据、事务、SQL 查询和一致性管理。
Elasticsearch 是搜索引擎,擅长倒排索引、关键词搜索、文本分析、过滤、聚合和日志检索。
Milvus、Qdrant、Weaviate 这类产品是向量数据库,通常包含向量索引、元数据过滤、服务化 API、分布式能力、持久化、权限、多租户和运维能力。
FAISS 更底层。它主要关注一件事:如何在向量集合中更快、更省内存地找到相似向量。
所以可以把 FAISS 理解成"向量检索内核",而不是"完整向量数据库"。
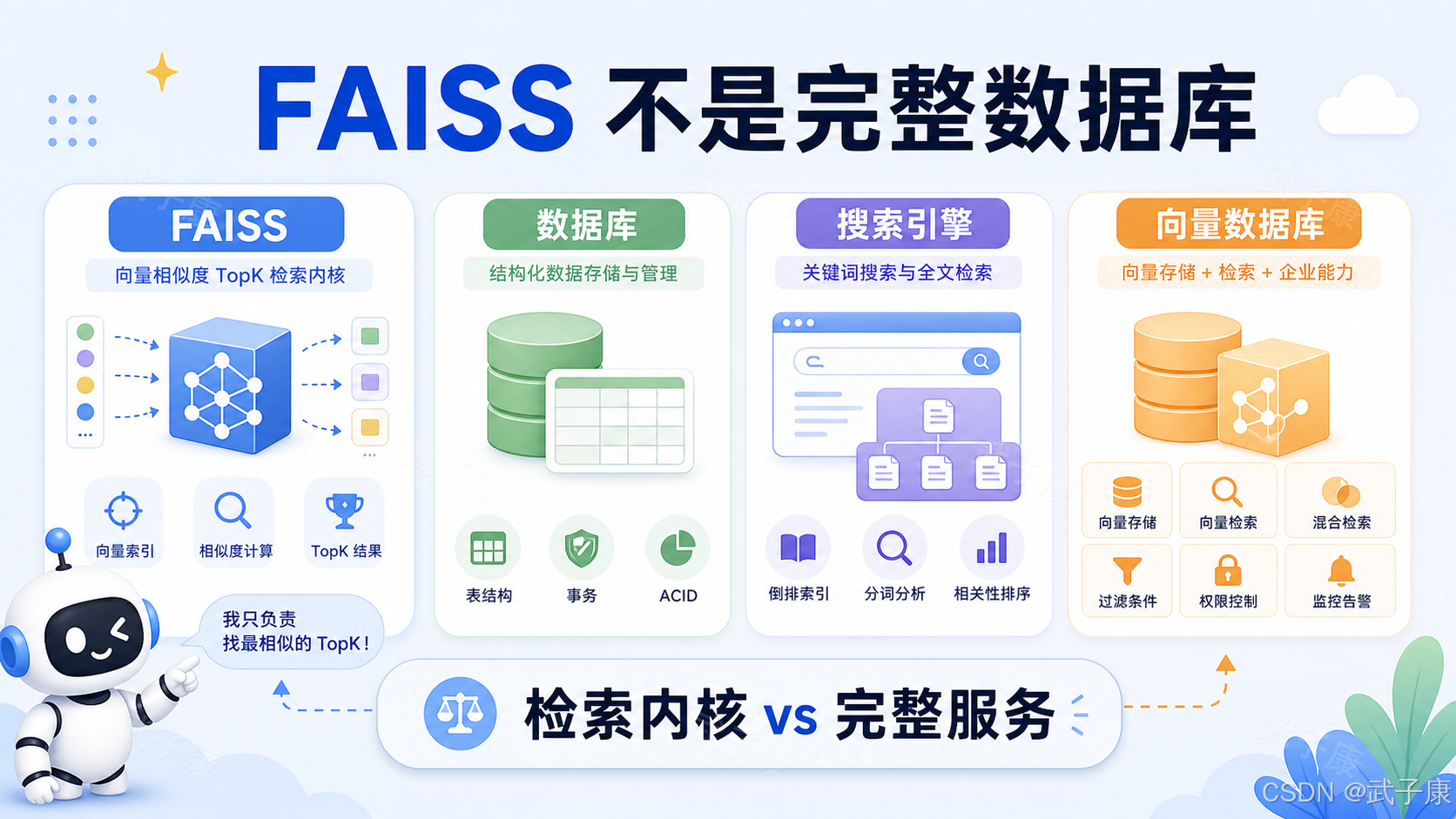
这一区分非常重要。很多人第一次接触 RAG 时,会把 FAISS 当成"向量数据库"。在小项目里问题不大,因为 LangChain、LlamaIndex 这类框架会把 FAISS 封装成 vector store,用起来像数据库。但从工程角度看,FAISS 本身并不负责完整数据库能力。
你通常不能只靠 FAISS 优雅地解决这些问题:
text
用户权限隔离
复杂元数据过滤
多租户管理
在线增删改查治理
分布式扩容
冷热数据分层
备份恢复
索引版本管理
查询审计
服务高可用更成熟的工程分工通常是:
text
FAISS:存向量和向量 ID,负责相似度检索
数据库:存原文、标题、标签、权限、时间、来源、业务字段
对象存储:存图片、音频、视频、文档原文件
业务服务:负责鉴权、过滤、编排、排序、重排、审计FAISS 负责快,数据库负责管,业务服务负责用。
最典型场景:RAG 知识库
现在最常见的 FAISS 使用场景就是 RAG,也就是 Retrieval-Augmented Generation,检索增强生成。
RAG 的基本逻辑是:LLM 不直接回答所有问题,而是先从知识库里检索相关内容,再基于检索内容回答。
典型流程如下:
text
1. 导入 PDF、Markdown、网页、接口文档、数据库说明
2. 清洗和切分文档,形成多个 chunk
3. 对每个 chunk 调用 embedding 模型,生成向量
4. 把向量写入 FAISS,同时保存 chunk_id
5. 把 chunk 原文、标题、来源、权限等信息保存到数据库
6. 用户提问时,把问题转成 query embedding
7. 用 FAISS 检索相似 chunk
8. 根据 chunk_id 回查原文
9. 拼接 prompt,交给 LLM
10. LLM 生成最终回答在这个流程里,FAISS 只负责第 4 步和第 7 步:写入向量索引,检索相似向量。
它不关心 chunk 原文是什么,也不关心文档属于谁、有没有权限、是否过期、来自哪个系统。这些都应该交给业务层或数据库处理。
FAISS 在 RAG 中的价值主要有三个:
第一,检索速度快。即使知识库里有几十万、几百万个 chunk,也可以通过合适索引结构快速召回 TopK。
第二,部署简单。对个人知识库、企业内部小规模知识库、代码库问答、博客问答系统来说,FAISS 不需要单独部署复杂向量数据库服务。
第三,成本低。FAISS 本身是库,不是托管服务。对中小规模 RAG 来说,它比单独维护 Milvus、Qdrant、Weaviate 更轻。
如果你的知识库规模是几百篇博客、几千个 Markdown、几万个文档 chunk、几十万个代码 chunk、百万以内向量集合,FAISS 通常很合适。
但如果系统涉及多用户 SaaS、复杂权限控制、在线频繁增删改、多租户隔离、复杂元数据过滤、大规模分布式部署,就不应该只用裸 FAISS。
语义搜索、推荐召回和多模态检索
FAISS 的第二个典型场景是语义搜索。
传统搜索是关键词搜索,用户输入一个词,系统找包含这个词的文档。它在日志搜索、订单号查询、错误码查询、标题搜索里很好用,但它不理解含义。
比如用户搜索"大模型回答太慢怎么办",语义相关内容可能包括首 token 延迟优化、流式输出、KV Cache、vLLM 推理优化、模型量化、Prompt 压缩、Function Calling 延迟、RAG TopK 过大等。这些内容不一定包含原句,但与问题高度相关。
更好的搜索架构通常是混合检索:
text
关键词检索:保证精确匹配
向量检索:保证语义召回
重排模型:重新排序结果
业务规则:处理权限、时间、热度、质量FAISS 在这个系统里负责语义召回。它不是最终排序系统,也不是搜索产品的全部。
推荐系统里,FAISS 通常放在召回层。你可以把文章、商品、视频、用户兴趣转成向量,然后用用户向量去 FAISS 里找相似内容,得到一批候选,再交给粗排、精排、重排。
多模态检索也类似。FAISS 不关心向量来自哪里。只要你能把图片、音频、视频片段转成 embedding,它就可以检索。
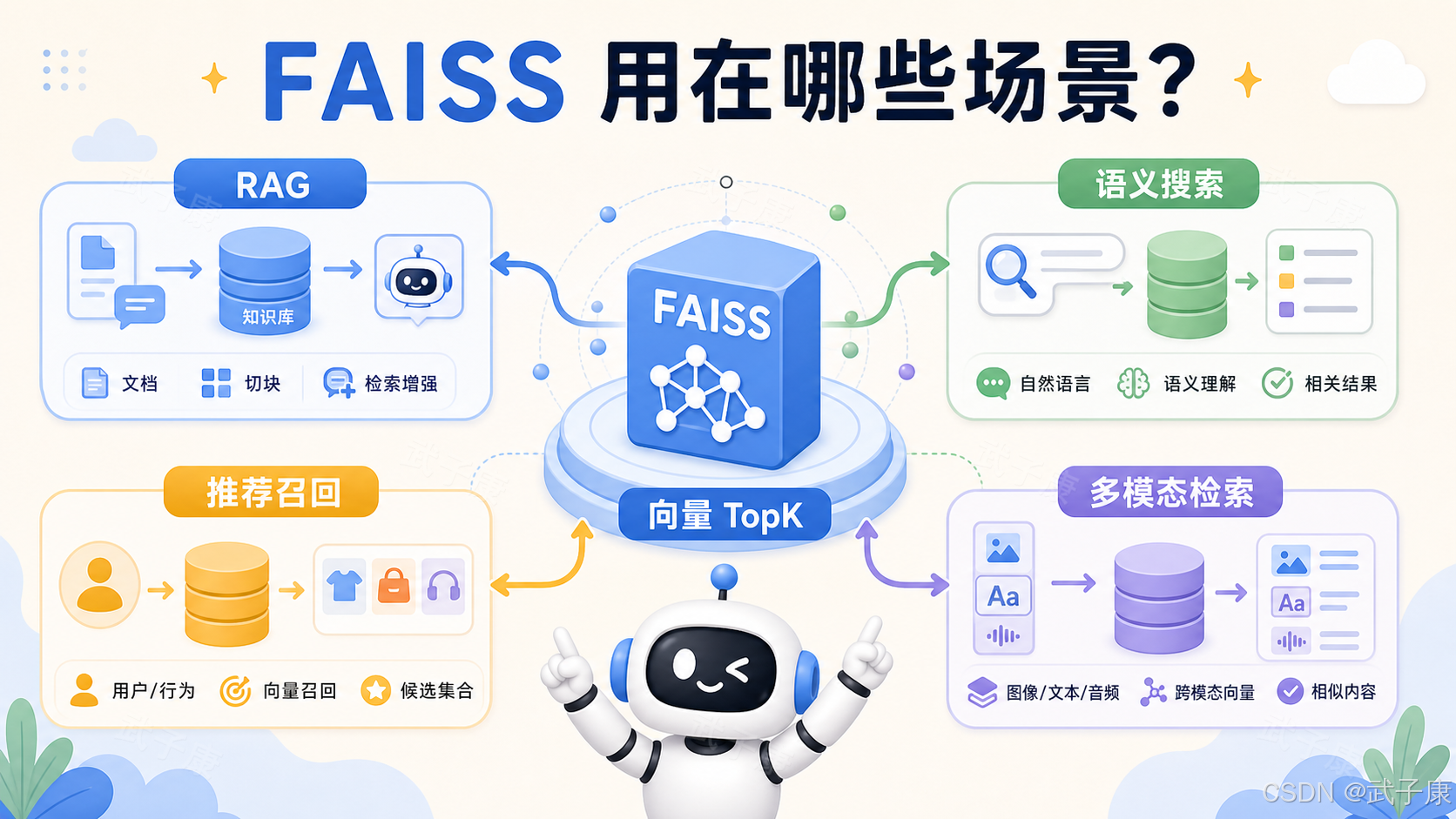
所以在多模态系统里,核心要分清:
text
embedding 模型决定语义空间质量
FAISS 决定检索效率
业务逻辑决定结果是否可用数据量级怎么判断?
判断 FAISS 能不能用,不能只看"有多少条数据",还要看向量数量、向量维度、数据类型、索引类型、召回率要求、查询延迟、QPS、在线更新、复杂过滤、机器内存和是否使用 GPU。
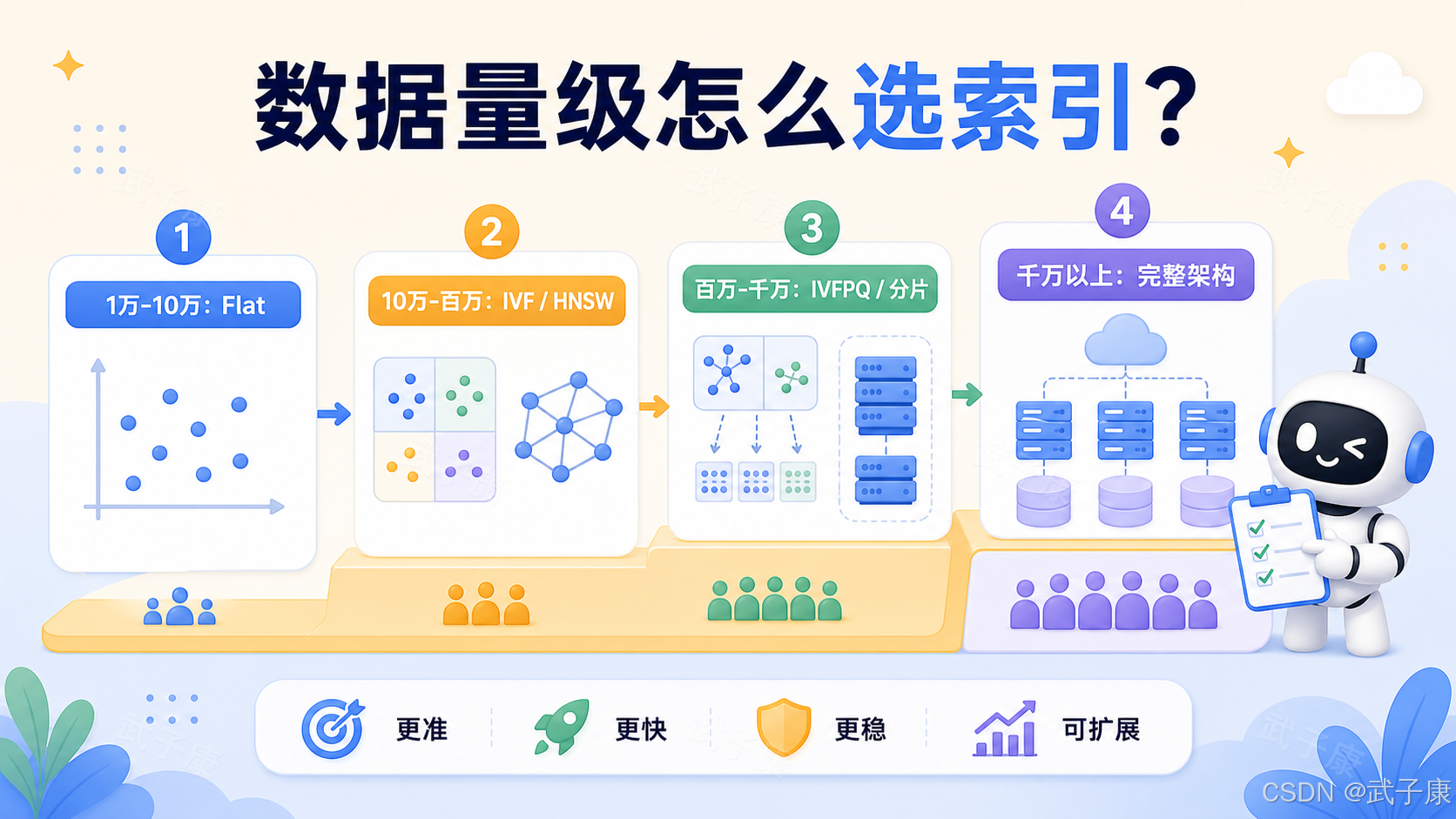
可以先用一个粗略分层。
几千条以内,不一定需要 FAISS。直接用 NumPy、PyTorch 或数据库暴力算 cosine similarity,很多情况下也能接受。真正影响效果的通常是 chunk 切分、embedding 模型、prompt 组织和回答质量。
1 万到 10 万条,FAISS 开始有意义。最简单的 IndexFlatIP 或 IndexFlatL2 通常就够。Flat 是精确搜索,不牺牲召回率,也不需要训练。对很多 RAG 第一版来说,这是正确起点。
10 万到 100 万条,是 FAISS 很舒服的区间。如果机器内存足够,Flat 仍然可以用;如果要求更低延迟、更高 QPS,可以考虑 IVF 或 HNSW。
100 万到 1000 万条,FAISS 仍然可以做,但工程复杂度明显上升。常见选择包括 IVFFlat、HNSW、IVFPQ、GPU 加速、分片和批量检索。此时核心问题已经不只是"能不能搜",而是索引怎么构建、内存是否放得下、更新怎么处理、故障怎么恢复、召回率怎么评估。
千万级以上,FAISS 不是不能用,但不应该轻描淡写地说"直接用 FAISS 就行"。如果是生产级在线系统,需要考虑分片、多机部署、向量压缩、冷热数据分层、离线构建、增量更新、高可用、监控告警和索引版本管理。
内存占用怎么估算?
向量检索的内存占用可以先粗略估算。
如果向量使用 float32,每个维度占 4 字节。单条向量大小是:
text
向量维度 × 4 bytes如果 embedding 维度是 768:
text
768 × 4 = 3072 bytes ≈ 3 KB
10 万条 ≈ 300 MB
100 万条 ≈ 3 GB
1000 万条 ≈ 30 GB如果 embedding 维度是 1536:
text
1536 × 4 = 6144 bytes ≈ 6 KB
10 万条 ≈ 600 MB
100 万条 ≈ 6 GB
1000 万条 ≈ 60 GB这只是原始向量本体,还没算向量 ID、索引结构、倒排列表、图结构、量化码本、元数据映射、Python 对象开销、服务进程开销和操作系统缓存。所以实际内存要留余量。
在 RAG 场景里,很多人会低估 chunk 数量。一本 200 页文档可能切成几百个 chunk,1000 份文档可能就是几十万 chunk。企业知识库、代码仓库、工单系统、Wiki 系统一合并,很容易到百万级。
设计向量库时不要只问"有多少文档",而要问最终会切成多少 chunk、每个 chunk 生成几个向量、向量维度是多少、是否保留多个版本、是否有多个 embedding 模型。
常见索引怎么选?
FAISS 的索引很多,但初学者先掌握几个就够。
IndexFlatL2 / IndexFlatIP 是最简单的索引。Flat 是精确搜索,不需要训练。它适合小规模知识库、原型验证、召回率要求高、数据量不大的场景。缺点是数据越大查询越慢,内存不压缩。
IndexIVFFlat 是倒排文件索引。它会先把向量分成多个聚类,查询时只搜索部分聚类,而不是全量扫描。关键参数是 nlist 和 nprobe。nprobe 越大,召回率越高,但查询越慢。IVF 的核心就是在速度和召回率之间做取舍。
IndexHNSWFlat 是图索引。它通过多层图结构快速导航到相似向量附近。HNSW 查询快,召回率通常不错,但内存占用更高。
IndexIVFPQ 是 IVF 和 PQ 的组合。IVF 负责缩小搜索范围,PQ 负责压缩向量。它适合大规模、内存紧张的场景,但精度会下降,训练和排查也更复杂。
对大多数 RAG 第一版来说,不要一上来就 IVFPQ。先用 Flat 验证效果,再根据规模和延迟要求优化。
FAISS 和向量数据库怎么选?
不要把问题简化成"FAISS 好还是 Milvus 好"。
正确问题应该是:我的系统需要的是底层向量检索库,还是完整向量数据库?
适合 FAISS 的情况:
text
本地知识库
单机部署
数据量中小
业务逻辑简单
主要做 TopK 检索
希望成本低
希望快速原型验证
不需要复杂权限和多租户适合向量数据库的情况:
text
生产级在线服务
多用户系统
复杂元数据过滤
需要服务化 API
需要高可用
需要分布式扩容
需要后台管理
需要监控运维
频繁在线更新适合 pgvector 的情况:
text
已经大量使用 PostgreSQL
数据规模不是特别大
希望向量和业务数据放在一起
需要 SQL 查询和事务
团队不想引入新系统适合 Elasticsearch / OpenSearch 向量检索的情况:
text
原本就有 ES 搜索体系
需要关键词 + 向量混合检索
需要过滤、聚合、日志检索
搜索业务强于纯向量业务如果你只是做个人知识库、公司内部小工具、代码库问答、博客搜索,FAISS 很合适。如果你要做商业化 SaaS、企业级知识库、多租户 Agent 平台,裸 FAISS 只是底层组件,不应该承担完整系统职责。
在 RAG 里用 FAISS 的推荐架构
一个比较稳的 RAG 架构可以这样设计:
text
对象存储:保存原始 PDF、Markdown、HTML、图片、附件
数据库:保存 document、chunk、source、权限、标签、版本、时间等元数据
Embedding 服务:负责把 chunk 转成向量
FAISS:保存 chunk_id 和 embedding 向量
检索服务:负责 query embedding、FAISS TopK、元数据回查、过滤、重排
LLM 服务:负责最终回答生成FAISS 里只存:
text
faiss_id -> vector不要把复杂业务信息硬塞进 FAISS。
查询时:
text
1. 用户输入问题
2. 生成 query embedding
3. FAISS search 得到 faiss_id 列表
4. 根据 faiss_id 找 chunk_id
5. 从数据库查 chunk 原文和元数据
6. 做权限过滤
7. 做相似度阈值过滤
8. 可选:用 reranker 重排
9. 拼接上下文给 LLM这里有一个关键点:权限过滤最好不要完全放在 FAISS 后面无脑做。如果不同用户权限差异很大,而你先全局召回 TopK,再过滤权限,可能过滤后没有结果。
常见处理方式包括按租户建立独立索引、按权限域建立多个索引、先做元数据候选过滤、FAISS 多召回再过滤,或者使用支持 metadata filter 的向量数据库。
RAG 效果差,很多时候不是 FAISS 的锅
很多 RAG 效果差,不是 FAISS 的问题,而是 chunk 切分的问题。
如果 chunk 太短,语义不完整;如果 chunk 太长,embedding 会被稀释,检索不准,还浪费上下文窗口。
常见经验是:
text
普通文档:300 - 800 中文字一个 chunk
技术文档:按标题、段落、代码块切分
代码库:按函数、类、文件结构切分
FAQ:一问一答作为基本单元
日志:按异常栈、事件窗口切分FAISS 只能检索你给它的向量。如果切分质量差,检索结果自然差。
embedding 模型也决定上限。中文知识库要用中文效果好的 embedding 模型;代码检索要考虑代码语义;多模态检索要用 CLIP 或其他多模态 embedding。FAISS 再快,也只是快速返回向量空间里的近邻。
TopK 也不是越大越好。更合理的流程是:
text
FAISS 召回 TopK=20
根据权限和阈值过滤
reranker 重排
取前 3 - 8 个 chunk 进入 prompt不要把所有召回结果都塞给 LLM。LLM 的上下文窗口不是垃圾桶。
在线更新、CPU/GPU 与工程边界
FAISS 可以 add 向量,但复杂生产场景里的更新问题要认真设计。
RAG 知识库常见变更包括新增文档、删除文档、更新文档、权限变化、文档过期、embedding 模型升级、chunk 策略变化。
如果只是新增文档,FAISS add 比较简单。但删除或更新文档要处理旧向量失效。常见做法是数据库标记 chunk 状态、检索后过滤 inactive chunk、定期重建 FAISS 索引、用 index_version 管理版本、重建完成后原子切换。
CPU 还是 GPU,要看场景。中小规模 RAG,CPU 通常足够。GPU 更适合大规模索引构建、高吞吐批量检索、离线召回任务、大规模实验。很多系统瓶颈其实不在 FAISS 查询,而在 embedding 调用、LLM 推理、reranker、数据库回查和网络传输。
FAISS 很强,但不适合直接承担完整数据库、复杂权限系统、多租户隔离、服务发现、分布式扩容、高可用切换、后台管理、业务审计和数据血缘。
如果你在严肃生产系统里用 FAISS,通常要自己补检索服务、索引版本、元数据表、重建流程、监控指标、召回率评估、回滚方案、权限过滤和数据清理。
最后总结
FAISS 的本质是高性能向量相似度检索库。
它最适合的场景是 RAG 知识库、语义搜索、推荐召回、相似图片检索、音频/视频片段检索、相似问题合并、日志聚类、代码片段检索、Agent 记忆召回。
它最舒服的数据量级通常是几万到几百万条向量。在这个区间里,FAISS 简单、直接、性能好、成本低,非常适合本地或自建系统。
如果是千万级以上,FAISS 仍然可以作为底层能力,但系统设计不能再停留在"一个库 + 一个文件"。你需要考虑索引压缩、分片、重建、版本管理、服务化、高可用和监控。
如果是多用户、多租户、复杂权限、复杂过滤、在线生产级服务,裸 FAISS 通常不够,需要向量数据库或自研服务层。
对大多数 AI 应用来说,正确路线不是一开始就上最复杂架构,而是:
text
第一阶段:FAISS + SQLite / PostgreSQL,快速跑通 RAG
第二阶段:加入 chunk 优化、embedding 评估、reranker、混合检索
第三阶段:做索引版本、权限过滤、重建流程、监控
第四阶段:数据量和业务复杂度上来后,再考虑向量数据库或分布式架构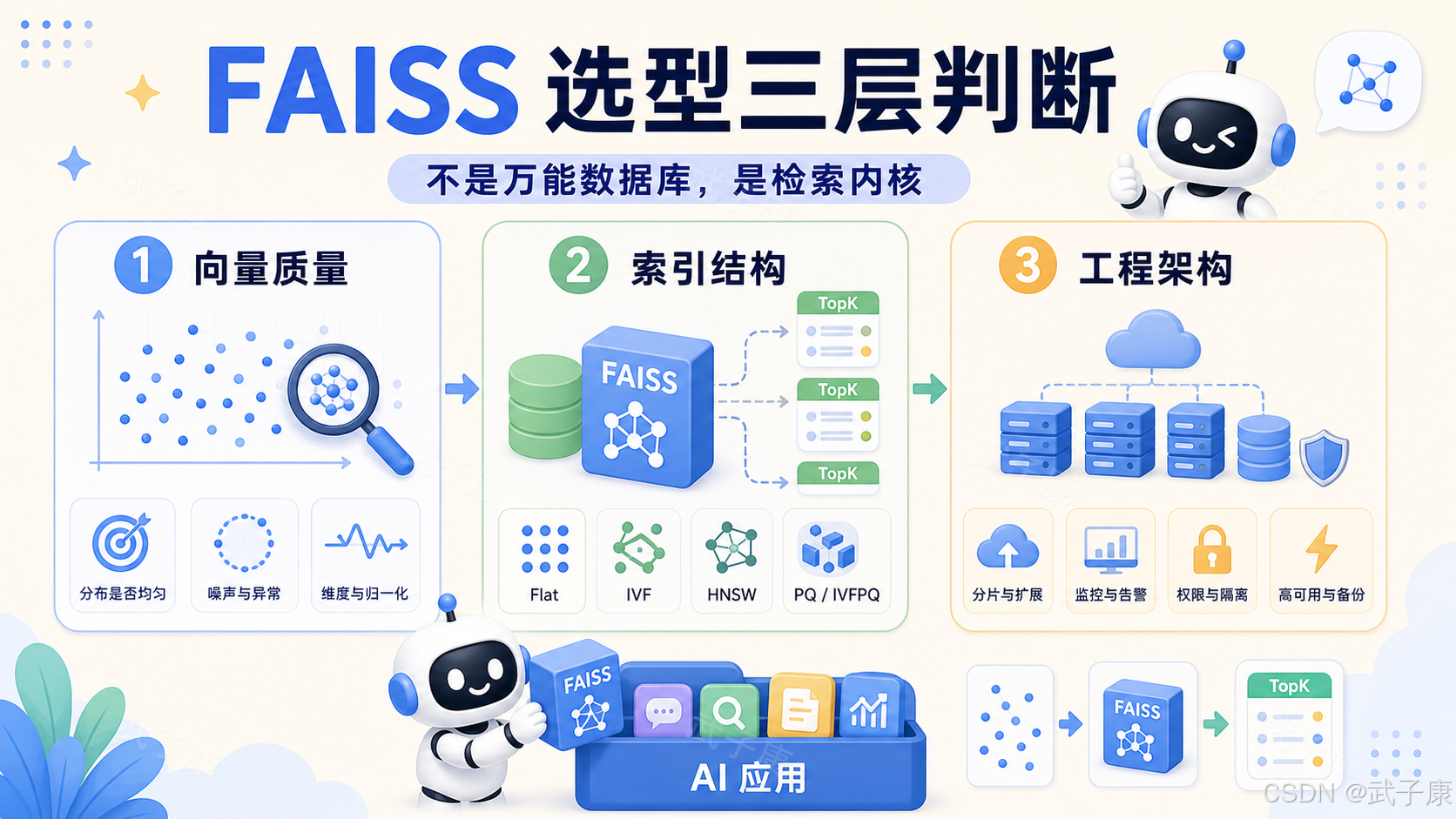
FAISS 不是万能数据库,也不是 RAG 效果的全部答案。它是一个非常强的向量检索内核。
用好它的关键,不是记住多少索引名字,而是明确三件事:
text
向量质量决定检索上限
索引结构决定性能和成本
工程架构决定系统能不能长期运行把这三层分清楚,FAISS 就会变成一个清晰、可控、低成本的 AI 应用基础组件。
参考资料
- FAISS GitHub: facebookresearch/faiss
- FAISS Documentation: faiss.ai
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 精确索引(IndexFlatL2 / IndexFlatIP) | ✅ 已验证 | FAISS 内置基础索引,暴力搜索无需训练,召回 100%,适合 1 万-10 万向量规模 |
| 倒排索引(IndexIVFFlat) | ✅ 已验证 | 通过 nlist / nprobe 参数平衡速度与召回率,适合 10 万-百万级 |
| 图索引(IndexHNSWFlat) | ✅ 已验证 | 多层图结构,查询快、召回高,内存占用高于 Flat,适合中小规模生产环境 |
| 量化压缩(IndexIVFPQ) | ✅ 已验证 | IVF + PQ 组合,内存占用大幅下降,精度有所损耗,适合百万-千万级 |
| GPU 加速(faiss-gpu) | ✅ 已验证 | CUDA 实现,构建与批量检索速度比 CPU 快 10-20 倍,显存受限于单卡 |
| 距离度量(METRIC_L2 / METRIC_INNER_PRODUCT) | ✅ 已验证 | 支持欧氏距离与内积,归一化后可等价于余弦相似度 |
| 索引持久化(write_index / read_index) | ✅ 已验证 | 支持将索引序列化到文件,进程重启后直接加载 |
| 动态增删(add / remove_ids) | ⚠️ 待验证 | add 简单可靠,remove_ids 需配合 IDSelector,复杂更新建议重建索引 |
| 复杂元数据过滤 | ❌ 不支持 | FAISS 本身不提供元数据过滤,需由业务层或向量数据库承担 |
| 多租户与权限控制 | ❌ 不支持 | 属于业务服务职责,FAISS 不提供 |
| 分布式扩容与高可用 | ❌ 不支持 | FAISS 是单机库,分布式能力需自建分片或多机架构 |
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| RAG 检索结果差,召回内容不相关 | chunk 切分过短或过长、embedding 模型不匹配 | 用同一个 query 调 embedding 模型并检查 top 命中是否包含答案 | 重新切分(300-800 中文字),切换更合适的 embedding 模型 |
| TopK 调大后 LLM 回答质量反而下降 | 上下文窗口被噪声稀释 | 看 prompt 中是否有大量不相关 chunk | 先 FAISS 召回 TopK=20,过滤后 reranker 重排,只取 3-8 个进 prompt |
IndexIVFFlat.train 报 AssertionError: not trained |
没有用与目标数据同分布的样本训练 | 打印 index.is_trained 检查 |
训练前用足够样本(建议 ≥ 30 × nlist)调用 index.train() |
IndexFlat 数据上百万后查询变慢、内存爆 |
Flat 索引不压缩,全量暴力搜索 | 用 index.ntotal × dim × 4 估算内存 |
改用 IVFFlat / HNSW,或 IVFPQ 压缩 |
| 更新文档后旧向量仍被召回 | FAISS 不支持原地更新,业务层未过滤 inactive chunk | 检索后看结果是否包含已删除文档 | 数据库标记 chunk 状态,检索后过滤 status='active',定期重建索引 |
| 不同用户检索结果混在一起,权限泄漏 | 全局召回后只过滤前 K 个 | 用户 A 看到用户 B 的文档 | 按租户建独立索引,或在元数据层先做权限候选过滤再检索 |
| 千万级向量单机内存放不下 | float32 原始向量 + 索引结构开销 | free -m 看进程 RSS |
改用 IVFPQ 量化压缩,或分片到多机 |
| GPU 索引构建报错 CUDA out of memory | 全部向量一次性塞进显存 | 打印 torch.cuda.memory_allocated() |
改用 index_cpu_to_gpu 配合 GpuResources,或分批 add |
| 归一化向量后内积结果不符合余弦相似度 | 内积 ≠ 余弦相似度(向量未归一化) | 检查向量 L2 范数 | 先 faiss.normalize_L2 再建索引,距离度量选 METRIC_INNER_PRODUCT |
| 多 embedding 模型混合使用后检索混乱 | 索引里混了不同维度 / 不同模型的向量 | 看 index.d 与实际向量维度是否一致 |
按模型分索引,或统一使用同一个 embedding 模型与维度 |
作者:武子康的个人博客