文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 环境准备](#2.1 环境准备)
-
- [2.1.1 环境要求](#2.1.1 环境要求)
- [2.1.2 查看环境](#2.1.2 查看环境)
- [2.2 创建并进入工作目录](#2.2 创建并进入工作目录)
-
- [2.2.1 创建工作目录](#2.2.1 创建工作目录)
- [2.2.2 进入工作目录](#2.2.2 进入工作目录)
- [2.3 创建容器编排配置文件](#2.3 创建容器编排配置文件)
- [2.4 启动Flink集群](#2.4 启动Flink集群)
-
- [2.4.1 启动集群](#2.4.1 启动集群)
- [2.4.2 检查状态](#2.4.2 检查状态)
- [2.5 进入 SQL Client 实战](#2.5 进入 SQL Client 实战)
-
- [2.5.1 进入Docker容器](#2.5.1 进入Docker容器)
- [2.5.2 启动 SQL Client](#2.5.2 启动 SQL Client)
- [2.5.3 执行 SQL 任务](#2.5.3 执行 SQL 任务)
-
- [2.5.3.1 创建数据库并使用](#2.5.3.1 创建数据库并使用)
- [2.5.3.2 创建数据源表](#2.5.3.2 创建数据源表)
- [2.5.3.3 创建结果表](#2.5.3.3 创建结果表)
- [2.5.3.4 提交流式聚合任务](#2.5.3.4 提交流式聚合任务)
- [2.5.3.5 退出Flink SQL](#2.5.3.5 退出Flink SQL)
- [2.5.3.6 退出容器](#2.5.3.6 退出容器)
- [2.5.4 查看TaskManager日志](#2.5.4 查看TaskManager日志)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本实战教程详细介绍基于Docker Compose部署Flink 2.2.0集群环境,通过创建词频统计案例演示Flink SQL的核心功能。涵盖环境准备、容器编排配置、SQL Client操作等完整流程,实现从数据源到结果输出的端到端实时流处理任务。
2. 实战步骤
2.1 环境准备
2.1.1 环境要求
- 部署前请确保服务器或本地机器已安装 Docker Engine 24.0+ 及 Docker Compose v2.20+(推荐使用 docker compose 命令)。此外,由于 Flink 运行时较为消耗资源,建议至少为 Docker 分配 4GB 以上的内存,以保障集群稳定运行。
2.1.2 查看环境
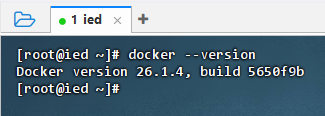
- 执行命令:
docker --version
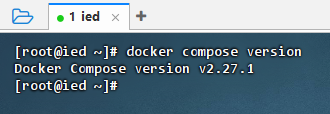
- 执行命令:
docker compose version
2.2 创建并进入工作目录
2.2.1 创建工作目录
- 执行命令:
mkdir FlinkSQLWork
2.2.2 进入工作目录
- 执行命令:
cd FlinkSQLWork
2.3 创建容器编排配置文件
-
执行命令:
vim docker-compose.yml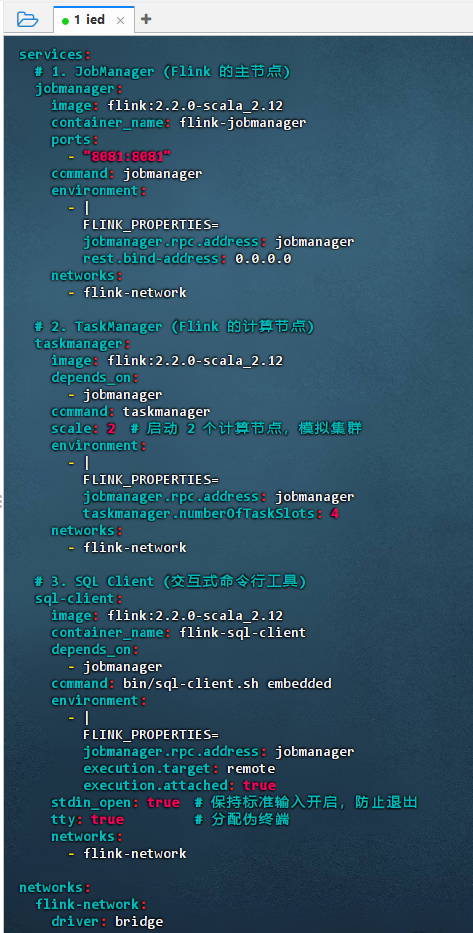 yaml
yamlservices: # 1. JobManager (Flink 的主节点) jobmanager: image: flink:2.2.0-scala_2.12 container_name: flink-jobmanager ports: - "8081:8081" command: jobmanager environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager rest.bind-address: 0.0.0.0 networks: - flink-network # 2. TaskManager (Flink 的计算节点) taskmanager: image: flink:2.2.0-scala_2.12 depends_on: - jobmanager command: taskmanager scale: 2 # 启动 2 个计算节点,模拟集群 environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager taskmanager.numberOfTaskSlots: 4 networks: - flink-network # 3. SQL Client (交互式命令行工具) sql-client: image: flink:2.2.0-scala_2.12 container_name: flink-sql-client depends_on: - jobmanager command: bin/sql-client.sh embedded environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager execution.target: remote execution.attached: true stdin_open: true # 保持标准输入开启,防止退出 tty: true # 分配伪终端 networks: - flink-network networks: flink-network: driver: bridge
2.4 启动Flink集群
2.4.1 启动集群
- 执行命令:
docker compose up -d,后台启动所有服务
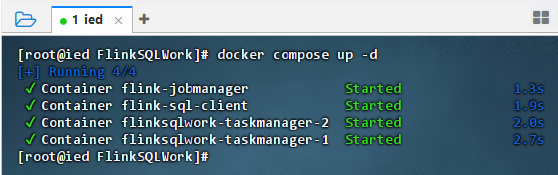
2.4.2 检查状态
- 执行命令:
docker compose ps

docker compose ps显示 Flink 集群已成功启动。JobManager、SQL Client 及两个 TaskManager 状态均为 Up,且 JobManager 的 8081 端口已正确映射至宿主机。这表明环境部署完成且运行健康,现在可以通过浏览器访问 Web UI 监控,或使用docker exec进入 SQL Client 容器开始开发。
2.5 进入 SQL Client 实战
- Flink SQL Client 是交互式查询的神器。我们需要进入 JobManager 容器内部来启动它。
2.5.1 进入Docker容器
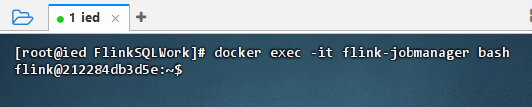
- 执行命令:
docker exec -it flink-jobmanager bash
2.5.2 启动 SQL Client
- 执行命令:
cd /opt/flink,进入Flink安装目录
- 执行命令:
./bin/sql-client.sh

2.5.3 执行 SQL 任务
2.5.3.1 创建数据库并使用
- 执行命令:
CREATE DATABASE IF NOT EXISTS test_db;
- 执行命令:
USE test_db;
2.5.3.2 创建数据源表
-
Datagen生成器:Datagen 是 Flink 内置的数据生成连接器,专用于本地测试与调试。它支持随机和序列两种生成模式,可灵活控制数据速率与字段范围,无需依赖外部系统。虽不支持复杂类型,但能高效生成模拟数据流,便于快速验证 SQL 逻辑与窗口计算。
-
执行语句
sqlCREATE TABLE word_count_source ( word STRING, cnt INT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '5', 'fields.word.length' = '5', 'fields.cnt.min' = '1', 'fields.cnt.max' = '100' );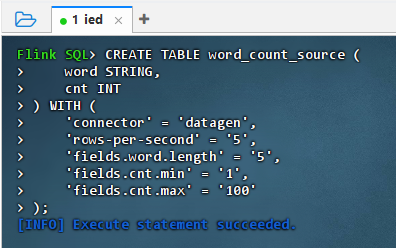
-
执行命令:
SELECT * FROM word_count_source;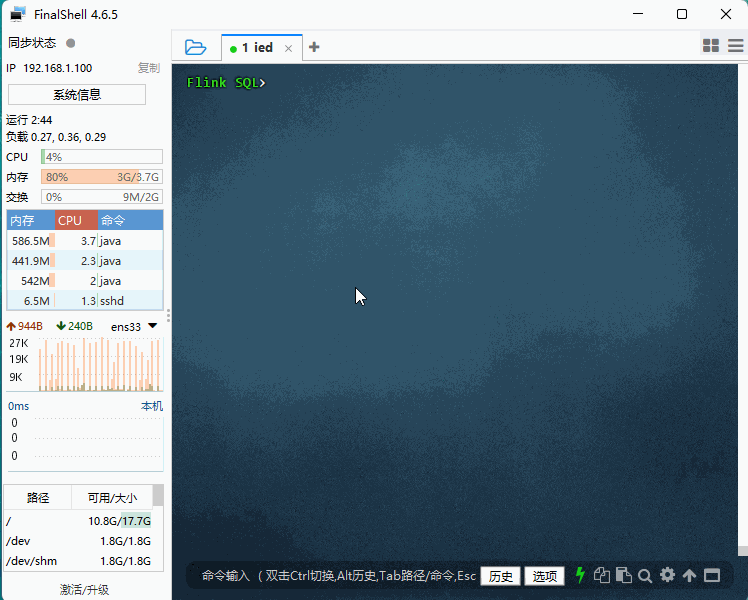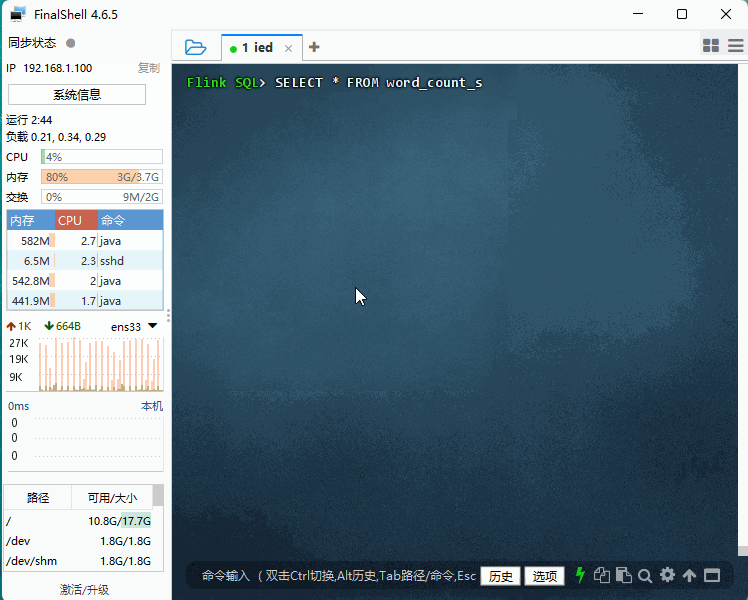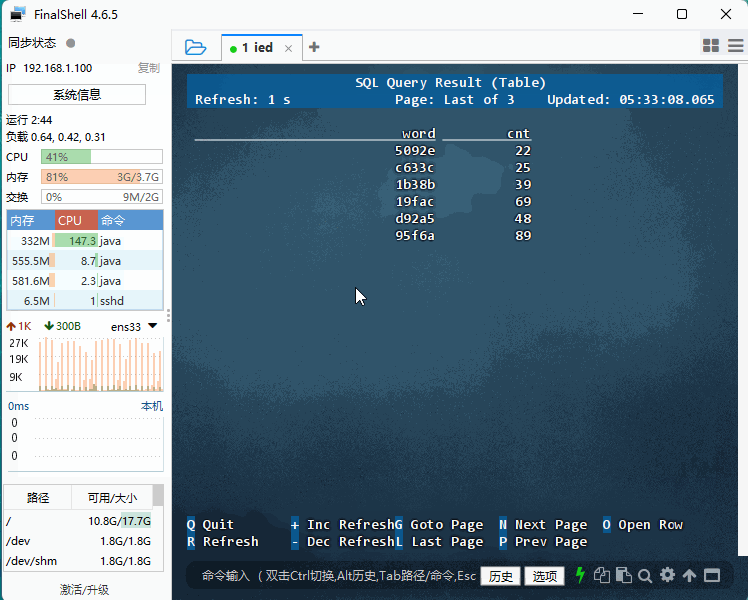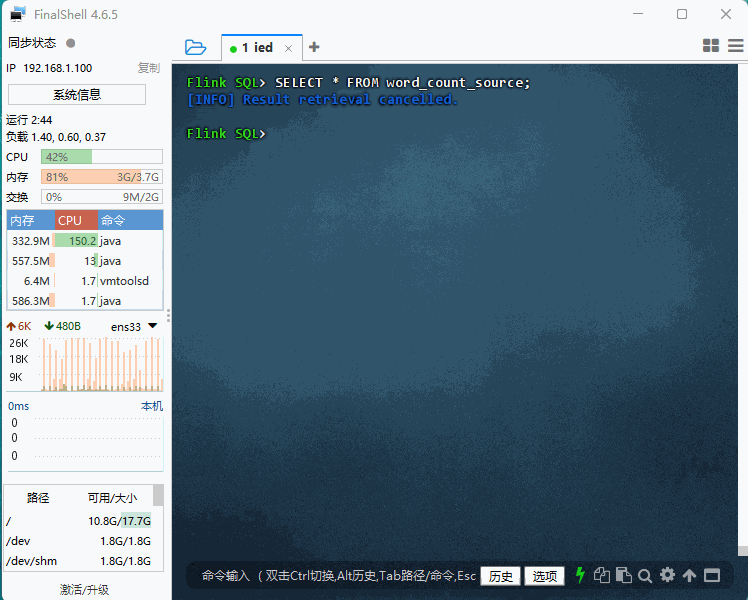
2.5.3.3 创建结果表
-
Print 连接器,用于在控制台打印
-
执行语句
sqlCREATE TABLE word_count_sink ( word STRING, total_cnt BIGINT ) WITH ( 'connector' = 'print' );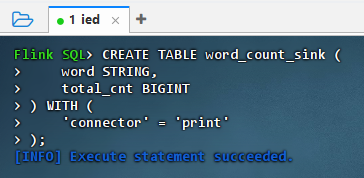
2.5.3.4 提交流式聚合任务
-
执行语句
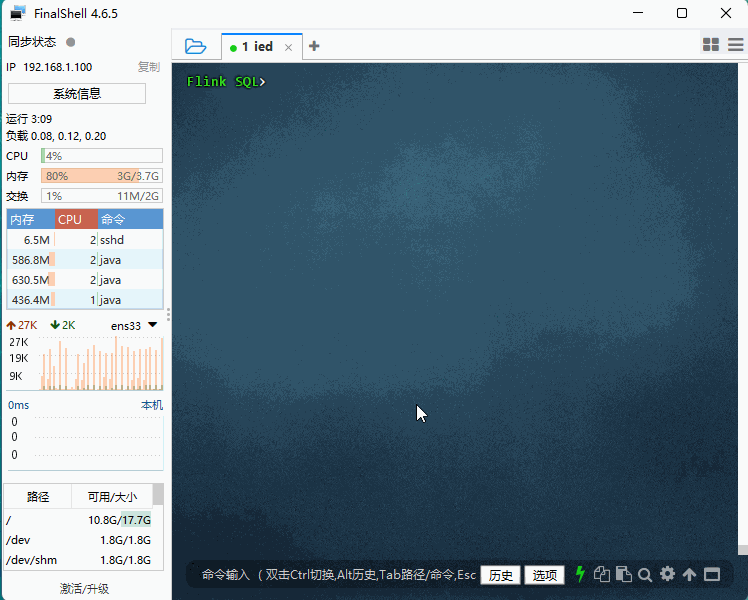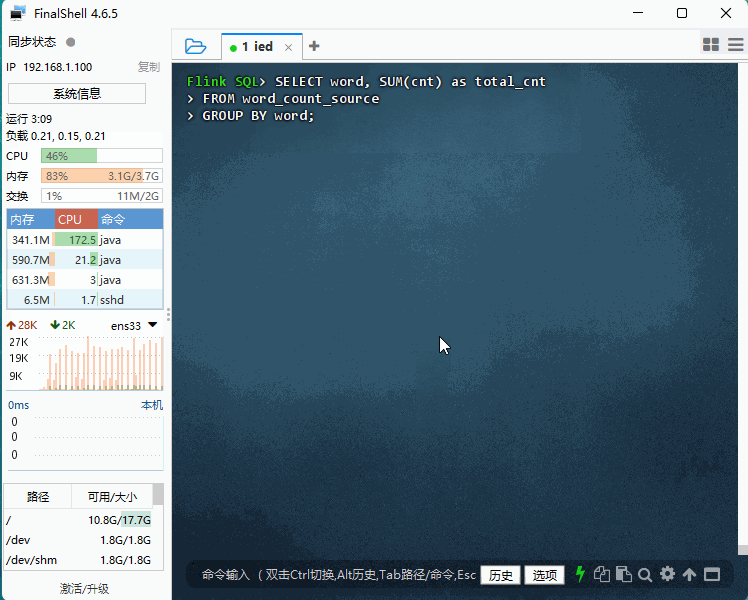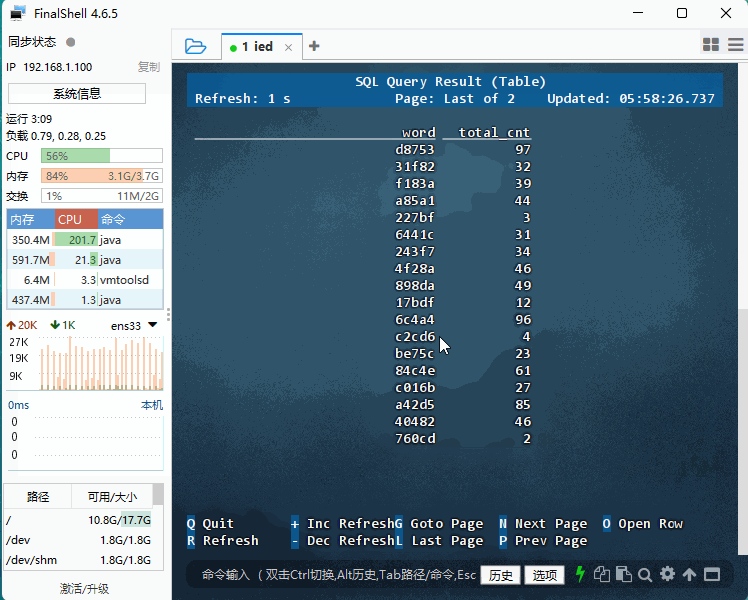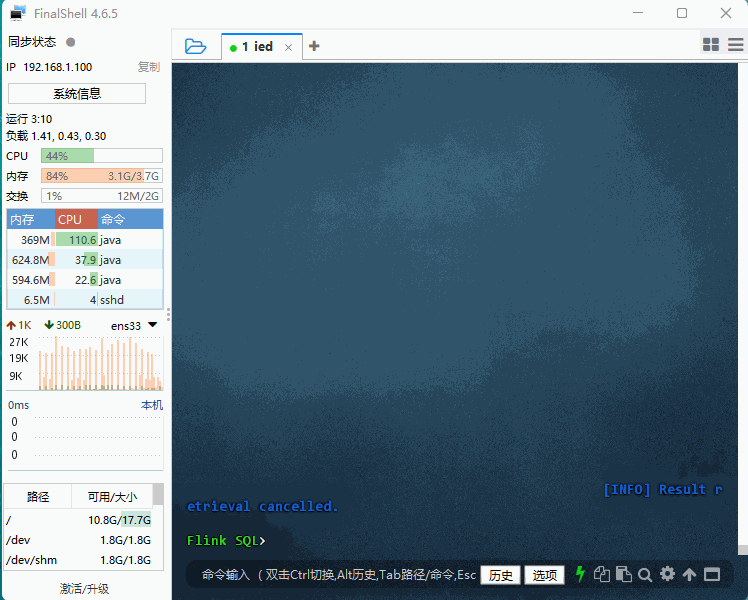
sqlSELECT word, SUM(cnt) as total_cnt FROM word_count_source GROUP BY word;
-
执行语句
sqlINSERT INTO word_count_sink SELECT word, SUM(cnt) as total_cnt FROM word_count_source GROUP BY word;
2.5.3.5 退出Flink SQL
- 执行命令:
EXIT;
2.5.3.6 退出容器
- 执行命令:
exit
2.5.4 查看TaskManager日志
- 执行命令:
docker logs flinksqlwork-taskmanager-1 2>&1 | tail -20 | grep -v "WARNING"
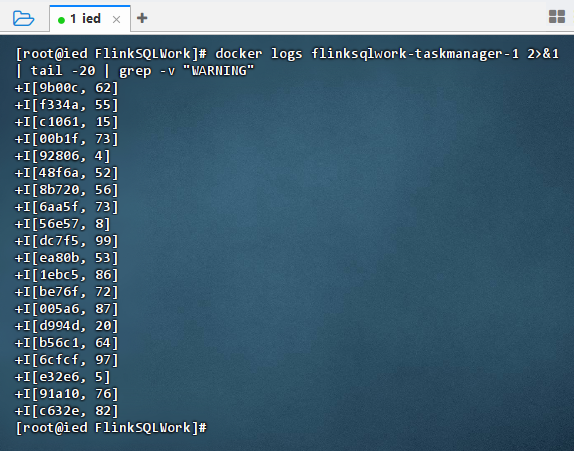
- Flink 词频统计任务运行正常,日志持续输出聚合结果。但第一列显示的
+I[hex, count]格式表明,数据源生成的"单词"实际上是 5位十六进制随机字符串 (如9b00c),而非真实英文单词。这是因为 Flink SQL 的datagen连接器在生成定长字符串时,默认采用随机字符模式。虽然统计逻辑正确(第二列为频次),但数据缺乏语义。若需演示真实词频,建议改用 CSV 文件作为数据源,或在 SQL 中通过自定义函数将随机串映射为预设字典中的单词。
3. 实战总结
-
本次Flink SQL实战演示了一个完整的流处理项目部署与开发过程。首先通过Docker Compose构建了包含JobManager、TaskManager和SQL Client的Flink集群环境,其中JobManager作为主节点负责协调,TaskManager作为计算节点处理数据,SQL Client提供交互式查询界面。
-
实战中使用datagen连接器创建了数据源表word_count_source,该连接器能够生成模拟数据流用于测试,配置了每秒5行数据的生成速率。通过Print连接器创建了结果表word_count_sink用于输出聚合结果。核心业务逻辑实现了词频统计功能,对随机生成的5位十六进制字符串进行分组聚合计算,使用SUM函数累计计数。
-
整个流程展现了Flink SQL强大的流处理能力,包括实时数据接入、流式聚合计算和结果输出。通过Web UI可以监控任务执行状态,日志分析确认了任务正常运行。这种基于SQL的流处理方式大大降低了大数据实时计算的门槛,使开发者能够快速构建和部署流处理应用。