Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第七章 Classes and Interfaces(类与接口)
作为一种面向对象编程语言,Python 支持各种特性,如继承、多态和封装。在 Python 中完成任务通常需要编写新的类,并定义它们如何通过接口和关系进行交互。
类与继承机制使得用对象来表述 Python 程序的预期行为变得十分简便。它们使您能够随着时间的推移不断完善和扩展功能。在需求不断变化的环境中,这些机制提供了灵活性。熟练掌握类与继承的使用方法,有助于您编写易于维护的代码。
Python 也是一种多范式语言 ,它鼓励采用函数式编程 风格。函数对象属于第一类,这意味着它们可以像普通变量一样被传递。Python 还允许你在同一程序中使用混合的面向对象风格与函数式风格特性,这种方式可能比各自独立使用任何一种风格都更为强大。
Item 54:考虑使用混合类来构建功能模块
Python 是一种面向对象的语言,内置了使多重继承变得易于处理的功能(参见 Item 53:"使用 super 初始化父类")。不过,最好完全避免使用多重继承。
如果你发现自己希望拥有多重继承所带来的便利性和封装性,但同时又希望避免由此可能带来的麻烦,不妨考虑编写一个混合类 。混合类是一种类,它仅定义一小部分额外的方法,供其子类提供使用。混合类本身并不定义自身的实例属性,也不要求其子类的 __init__ 构造函数被调用。
编写混合类十分简单,因为 Python 使得检查任何对象的当前状态变得轻而易举,而无论其类型如何。动态检查意味着你只需在混合类中编写一次通用功能代码,而后便可将其应用于众多其他类中。混合类可通过组合和分层的方式实现,以最大程度减少重复代码并提高复用性。
例如,假设我想要具备将一个 Python 对象从其内存表示形式 转换为已准备好进行序列化的字典 的能力。为什么不将此功能以通用形式 编写出来,以便我能够将其应用于所有类呢?
在此处,我定义了一个混合类示例,它通过新增一个公共方法来实现这一目标。该方法会被添加到任何从其继承的类中。实现细节非常简单明了,主要依赖于使用 hasattr 进行动态属性访问、使用 isinstance 进行动态类型检查,以及访问实例字典 __dict__ :
class ToDictMixin:
def to_dict(self):
return self._traverse_dict(self.__dict__)
def _traverse_dict(self, instance_dict):
output = {}
for key, value in instance_dict.items():
output[key] = self._traverse(key, value)
return output
def _traverse(self, key, value):
if isinstance(value, ToDictMixin):
return value.to_dict()
elif isinstance(value, dict):
return self._traverse_dict(value)
elif isinstance(value, list):
return [self._traverse(key, i) for i in value]
elif hasattr(value, "__dict__"):
return self._traverse_dict(value.__dict__)
else:
return value在此处,我定义了一个示例类,该类利用混合方法来实现二叉树的字典表示形式:
class BinaryTree(ToDictMixin):
def __init__(self, value, left=None, right=None):
self.value = value
self.left = left
self.right = right将大量相关的 Python 对象翻译成字典变得很容易:
tree = BinaryTree(
10,
left=BinaryTree(7, right=BinaryTree(9)),
right=BinaryTree(13, left=BinaryTree(11)),
)
print(tree.to_dict())
>>>
{'value': 10,
'left': {'value': 7,
'left': None,
'right': {'value': 9, 'left': None, 'right': None}},
'right': {'value': 13,
'left': {'value': 11, 'left': None, 'right': None},
'right': None}}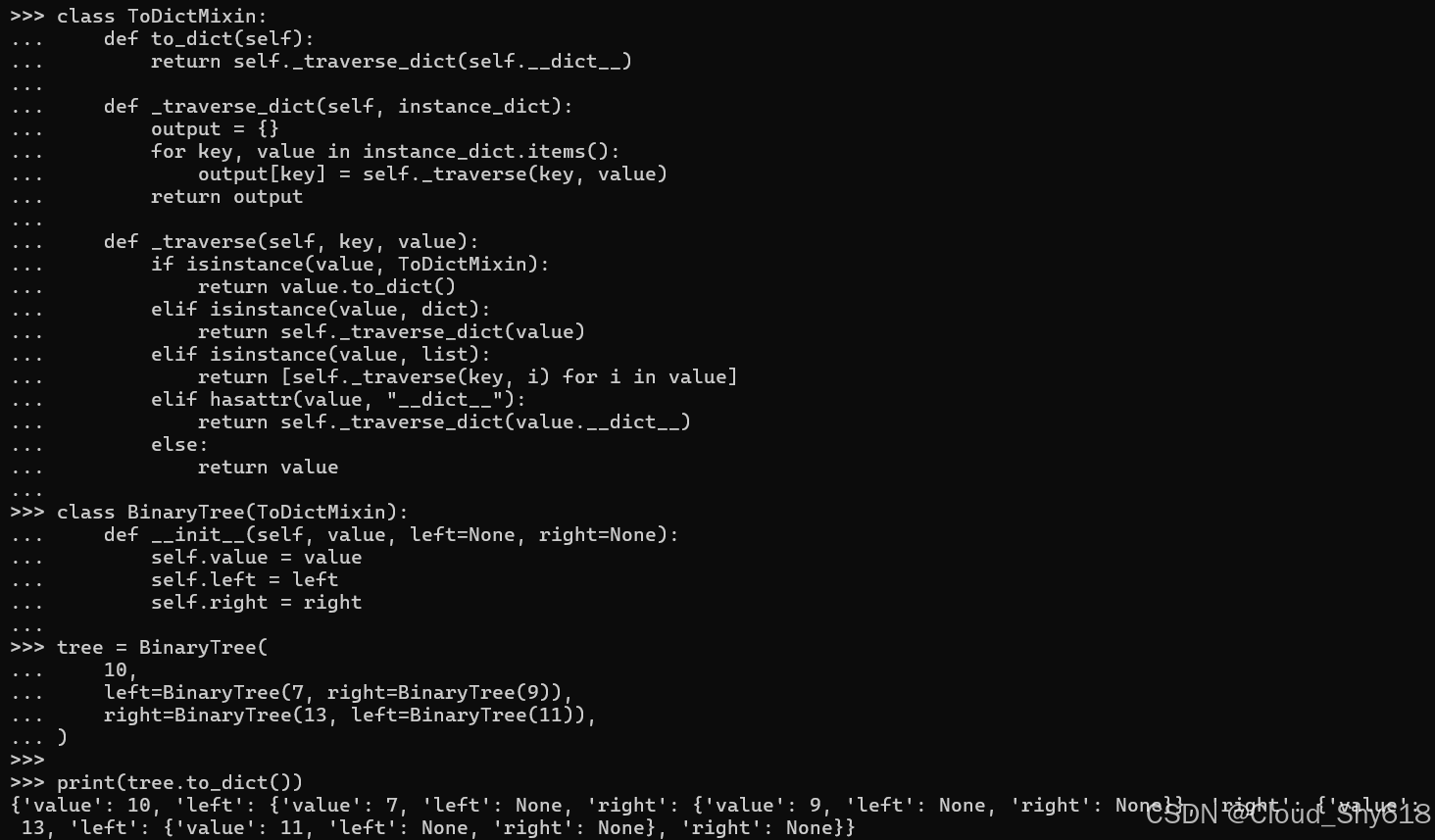
混合类最棒的一点在于,你能够使它们的一般功能具备可插拔性,这样便可在需要时对行为进行重写。例如,这里我定义了一个 BinaryTree 类的子类,该类持有对其父类的引用。这种循环引用会导致 ToDictMixin.to_dict 默认实现函数无休止地循环。解决方案是覆盖 BinaryTreeWithParent.traverse 方法,来仅处理那些重要的值,从而避免因混合而产生的循环。在此情况下,_traverse 函数覆盖插入父级的数值,否则通过使用 super 内置函数遵循混合类的默认实现:
class BinaryTreeWithParent(BinaryTree):
def __init__(
self,
value,
left=None,
right=None,
parent=None,
):
super().__init__(value, left=left, right=right)
self.parent = parent
def _traverse(self, key, value):
if (
isinstance(value, BinaryTreeWithParent)
and key == "parent"
):
return value.value # Prevent cycles
else:
return super()._traverse(key, value)调用 BinaryTreeWithParent.to_dict 方法时一切正常,因为并未遵循循环引用的属性:
root = BinaryTreeWithParent(10)
root.left = BinaryTreeWithParent(7, parent=root)
root.left.right = BinaryTreeWithParent(9, parent=root.left)
print(root.to_dict())
>>>
{'value': 10,
'left': {'value': 7,
'left': None,
'right': {'value': 9,
'left': None,
'right': None,
'parent': 7},
'parent': 10},
'right': None,
'parent': None}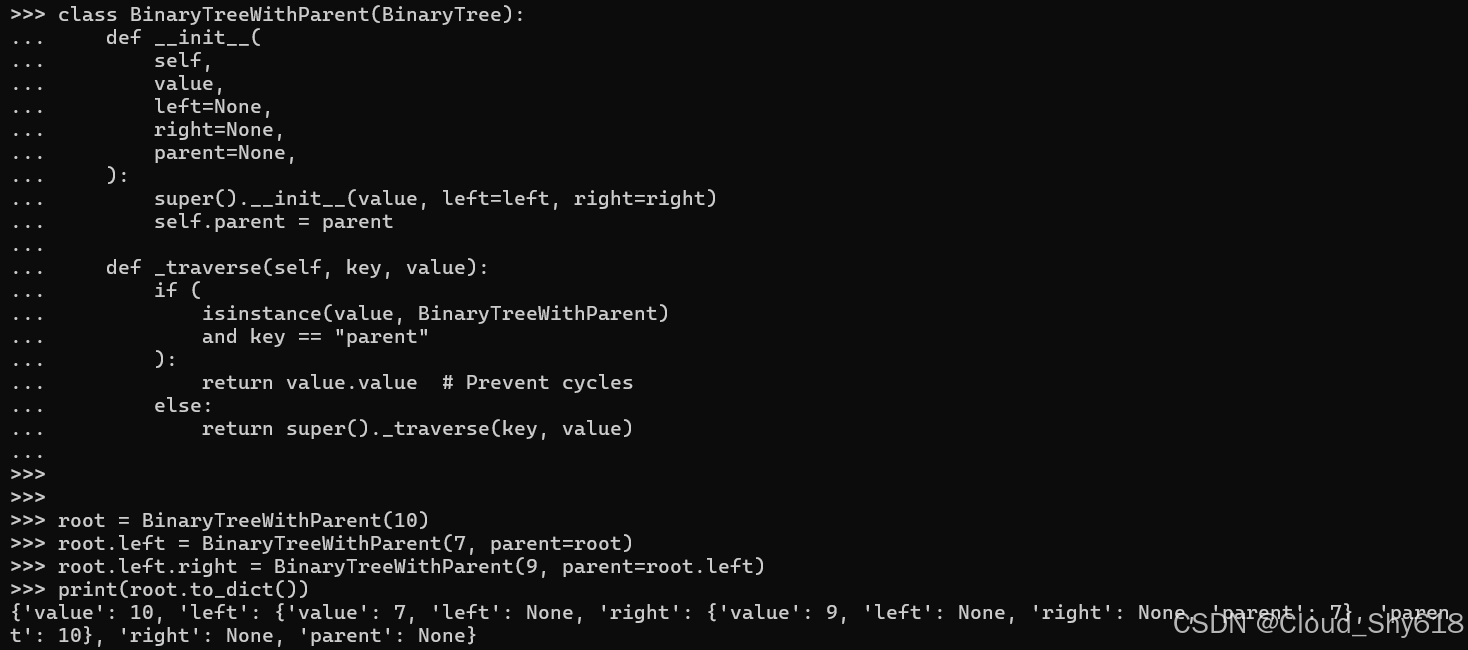
通过定义 BinaryTreeWithParent._traverse 方法,我还使得任何拥有 BinaryTreeWithParent 类型属性的类都能自动与 ToDictMixin 配合使用:
class NamedSubTree(ToDictMixin):
def __init__(self, name, tree_with_parent):
self.name = name
self.tree_with_parent = tree_with_parent
my_tree = NamedSubTree("foobar", root.left.right)
print(my_tree.to_dict()) # No infinite loop
>>>
{'name': 'foobar',
'tree_with_parent': {'value': 9,
'left': None,
'right': None,
'parent': 7}}
混合类也可以被组合在一起。例如,假设我想要一个提供通用 JSON 序列化功能的混合类,适用于任何类。我可以通过假定一个类提供了 to_dict 方法(该方法可能由 ToDictMixinclass 类提供也可能不提供)来实现这一目标:
import json
class JsonMixin:
@classmethod
def from_json(cls, data):
kwargs = json.loads(data)
return cls(**kwargs)
def to_json(self):
return json.dumps(self.to_dict())请注意 JsonMixinclass 如何同时定义了实例方法和类方法。混合类使您能够将这两种行为类型添加到子类中(有关类似功能的详情,请参阅 Item 52:"使用 @classmethod 泛型构建对象")。在此示例中,JsonMixin 子类的唯一要求是提供 to_dict 方法,并为 __init__ 方法接受关键字参数(详情请参阅 Item 35:"通过关键字参数提供可选行为")。
这种混合类使得创建实用类层次结构变得十分简便,这些层次结构可以轻松地进行序列化和反序列化,且无需过多冗余代码。例如,这里我有一组代表数据中心拓扑结构各部分的类层次结构:
class DatacenterRack(ToDictMixin, JsonMixin):
def __init__(self, switch=None, machines=None):
self.switch = Switch(**switch)
self.machines = [
Machine(**kwargs) for kwargs in machines]
class Switch(ToDictMixin, JsonMixin):
def __init__(self, ports=None, speed=None):
self.ports = ports
self.speed = speed
class Machine(ToDictMixin, JsonMixin):
def __init__(self, cores=None, ram=None, disk=None):
self.cores = cores
self.ram = ram
self.disk = disk将这些类序列化并反序列化为 JSON 非常简单。在此示例中,我验证了数据通过序列化和反序列化过程能够实现往返传输:
serialized = """{
"switch": {"ports": 5, "speed": 1e9},
"machines": [
{"cores": 8, "ram": 32e9, "disk": 5e12},
{"cores": 4, "ram": 16e9, "disk": 1e12},
{"cores": 2, "ram": 4e9, "disk": 500e9}
]
}"""
deserialized = DatacenterRack.from_json(serialized)
roundtrip = deserialized.to_json()
assert json.loads(serialized) == json.loads(roundtrip)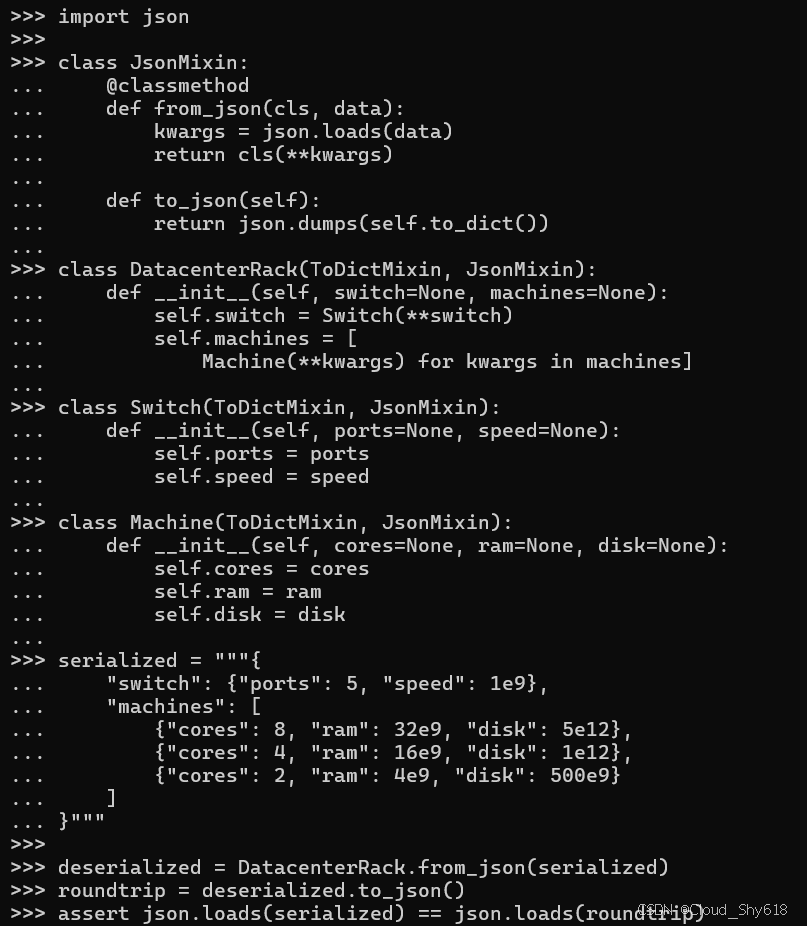
当你使用此混合类时,如果你所应用的类已继承自位于类层次结构更高级别的 JsonMixin 之上,那么也无妨。由于基类行为的影响,生成的类将表现出相同的行为方式。
注意:
- 避免使用多重继承与实例属性和
__init__结合的情况,如果混合类能够达成相同效果的话。 - 在实例级别使用可插拔式行为模式,以便在混合类可能有此需求时提供针对特定类别的定制化功能。
- 混合类可以包含实例方法或类方法,具体取决于你的需求。
- 编写混合类,以从简单行为中创建复杂功能。
Item 55:更偏好公共属性而非私有属性
在 Python 中,一个类属性的可见性类型只有两种:公共和私有:
class MyObject:
def __init__(self):
self.public_field = 5
self.__private_field = 10
def get_private_field(self):
return self.__private_field公共属性可通过在对象上使用点运算符来由任何人访问:
foo = MyObject()
assert foo.public_field == 5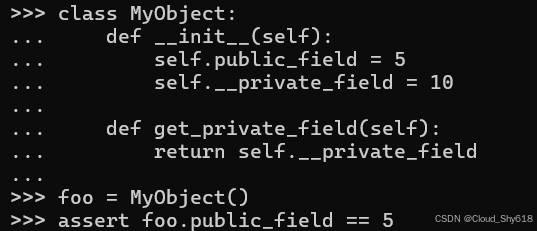
私有字段是通过在属性名称前加上双下划线来指定的。它们可通过所属类的方法直接进行访问:
assert foo.get_private_field() == 10然而,从类的外部直接访问私有字段会引发异常:
foo.__private_field
>>>
Traceback ...
AttributeError: 'MyObject' object has no attribute
➥'__private_field'
类方法也能够访问私有属性,因为它们在所属的类块内被声明:
class MyOtherObject:
def __init__(self):
self.__private_field = 71
@classmethod
def get_private_field_of_instance(cls, instance):
return instance.__private_field
bar = MyOtherObject()
assert MyOtherObject.get_private_field_of_instance(bar) == 71正如人们所预料的,对于私有字段而言,子类无法访问其父类的私有字段:
class MyParentObject:
def __init__(self):
self.__private_field = 71
class MyChildObject(MyParentObject):
def get_private_field(self):
return self.__private_field
baz = MyChildObject()
baz.get_private_field()
>>>
Traceback ...
AttributeError: 'MyChildObject' object has no attribute
➥'_MyChildObject__private_field'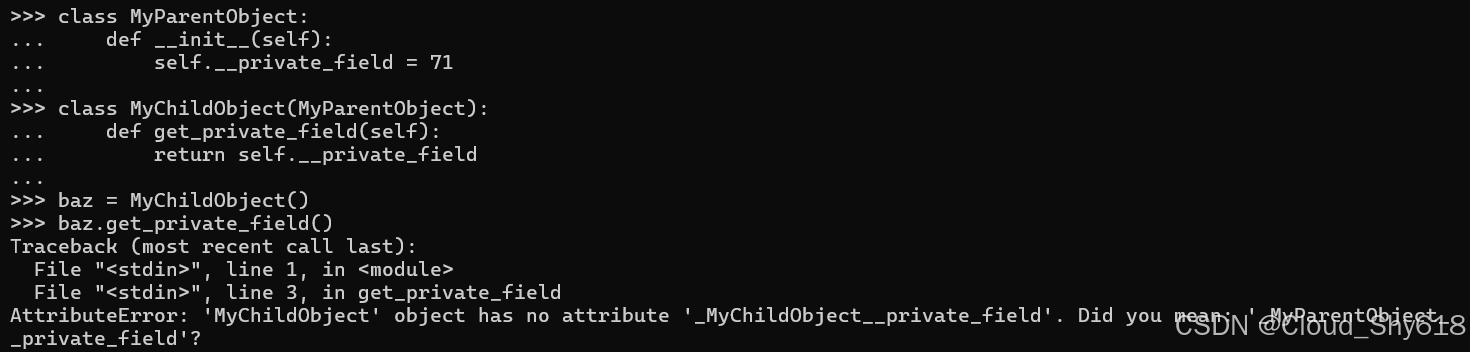
私有属性行为是通过属性名称的简单转换来实现的。当 Python 编译器在 MyChildObject.get_private_field 等方法中看到私有属性访问时,它会将 __private_field 属性访问转换为使用名称 _My Child Object__private_field。 上面的例子中,__private_field 仅在 MyParentObject.__init__中定义,这意味着私有属性的真实名称是 _MyParentObject__private_field。
从子类访问父类的私有属性失败只是因为转换后的属性名称不存在(_MyChildObject__private_field 而不是 _MyParentObject__private_field)。了解了这个方案,您可以轻松地从子类或外部访问任何类的私有属性,而无需请求许可:
assert baz._MyParentObject__private_field == 71如果查看对象的属性字典,您可以看到私有属性实际上是与转换后出现的名称一起存储的:
print(baz.__dict__)
>>>
{'_MyParentObject__private_field': 71}
为什么私有属性的语法实际上没有强制执行严格的可见性?最简单的答案是 Python 的一句经常被引用的座右铭:"我们都是成年人,双方都是自愿的" 这意味着我们不需要语言来阻止我们做我们想做的事情。根据我们的意愿扩展功能并承担此类风险的后果是我们个人的选择。Python 程序员相信,开放性(默认情况下允许类的计划外扩展)的好处大于坏处。
除此之外,能够挂钩诸如属性访问之类的语言功能(请参阅 Item 61:"使用 __getattr__、__getattribute__ 和 __setattr__ 作为惰性属性")使您可以随时修改对象的内部结构。如果你能做到这一点,那么 Python 尝试阻止私有属性访问的价值是什么?
为了最大限度地减少因无意中访问内部而造成的损害,Python 程序员遵循样式指南中定义的命名约定(请参阅 Item 2:"遵循 PEP 8 样式指南")。名称以单个下划线为前缀的任何字段(如 _protected_field)均受约定保护,这意味着该类的外部用户应谨慎操作。
然而,刚接触 Python 的程序员可能会考虑使用私有字段来指示不应被子类或外部访问的内部 API:
class MyStringClass:
def __init__(self, value):
self.__value = value
def get_value(self):
return str(self.__value)
foo = MyStringClass(5)
assert foo.get_value() == "5"这是错误的做法。不可避免地,有人(甚至可能是您)想要对您的类进行子类化以添加新行为或解决现有方法中的缺陷(例如,MyStringClass.get_value 始终返回字符串的方式)。通过选择私有属性,您只会使子类覆盖和扩展变得麻烦和脆弱。当您的潜在子类化者绝对需要时,他们仍然会访问私有字段:
class MyIntegerSubclass(MyStringClass):
def get_value(self):
return int(self._MyStringClass__value)
foo = MyIntegerSubclass("5")
assert foo.get_value() == 5但是,如果上面的类层次结构发生更改,这些类将会中断,因为私有属性引用不再有效。这里,MyIntegerSubclassclass 的直接父类 MyStringClass 添加了另一个父类,称为 MyBaseClass:
class MyBaseClass:
def __init__(self, value):
self.__value = value
def get_value(self):
return self.__value
class MyStringClass(MyBaseClass):
def get_value(self):
return str(super().get_value()) # Updated
class MyIntegerSubclass(MyStringClass):
def get_value(self):
return int(self._MyStringClass__value) # Not updated_valueattribute 现在分配在 MyBaseClassparent 类中,而不是 MyStringClassparent 中。 这会导致私有变量引用 self._My StringClass__value 在 MyIntegerSubclass 中中断:
foo = MyIntegerSubclass(5)
foo.get_value()
>>>
Traceback ...
AttributeError: 'MyIntegerSubclass' object has no attribute
➥'_MyStringClass__value'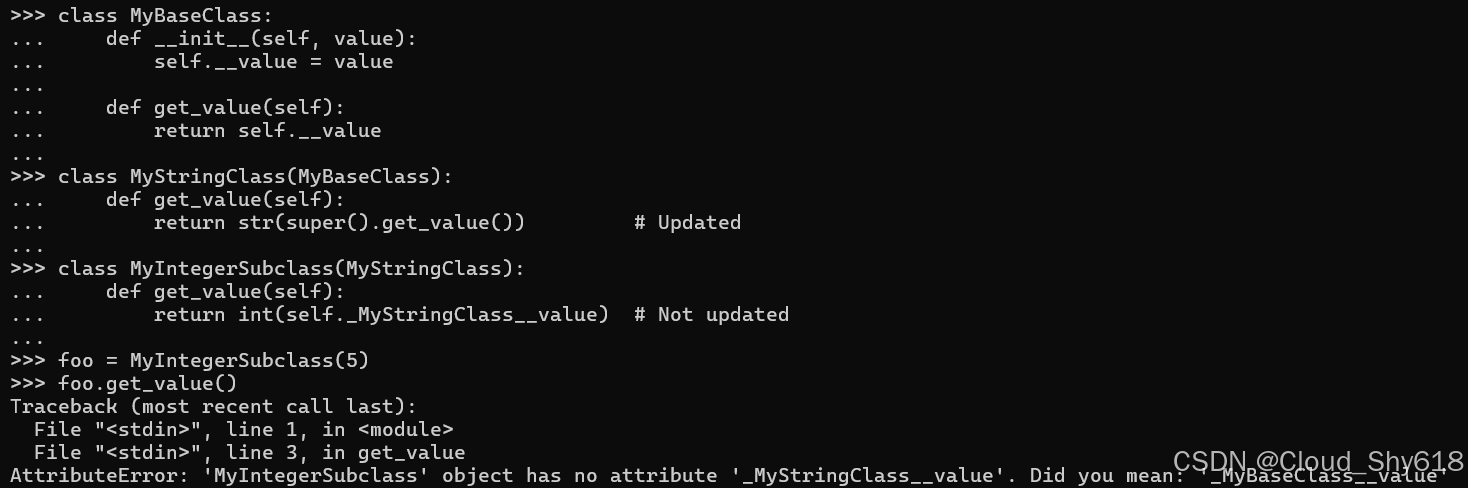
一般来说,最好允许子类通过使用受保护的属性来做更多的事情。记录每个受保护的字段,并解释哪些字段是内部 API 可用于子类,哪些字段应该完全保留。这既是对其他程序员的建议,也是对未来的你如何安全地扩展自己的代码的指导:
class MyStringClass:
def __init__(self, value):
# This stores the user-supplied value for the object.
# It should be coercible to a string. Once assigned in
# the object it should be treated as immutable.
self._value = value
def get_value(self):
return str(self._value)
class MyIntegerSubclass(MyStringClass):
def get_value(self):
return self._value
foo = MyIntegerSubclass(5)
assert foo.get_value() == 5唯一认真考虑使用私有属性的时候是当您担心子类之间的命名冲突时。当子类无意中定义了其父类已定义的属性时,就会出现此问题:
class ApiClass:
def __init__(self):
self._value = 5
def get(self):
return self._value
class Child(ApiClass):
def __init__(self):
super().__init__()
self._value = "hello" # Conflicts
a = Child()
print(f"{a.get()} and {a._value} should be different")
>>>
hello and hello should be different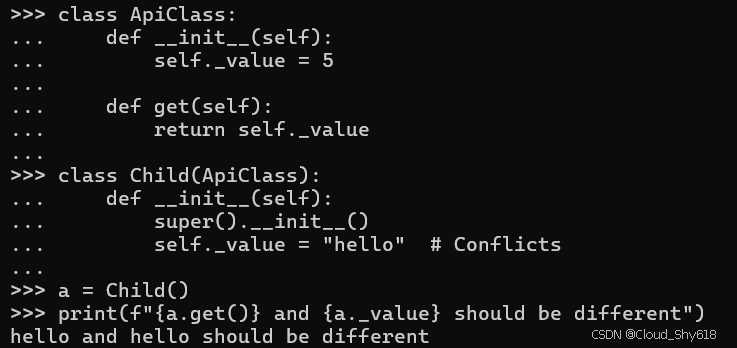
这主要是与属于公共 API 一部分的类有关;子类超出了您的控制范围,因此您无法重构来解决问题。对于非常常见的属性名称(如值),这种冲突尤其可能发生。为了降低发生此问题的风险,可以在父类中使用私有属性来确保不存在与子类重叠的属性名称:
class ApiClass:
def __init__(self):
self.__value = 5 # Double underscore
def get(self):
return self.__value # Double underscore
class Child(ApiClass):
def __init__(self):
super().__init__()
self._value = "hello" # OK!
a = Child()
print(f"{a.get()} and {a._value} are different")
>>>
5 and hello are different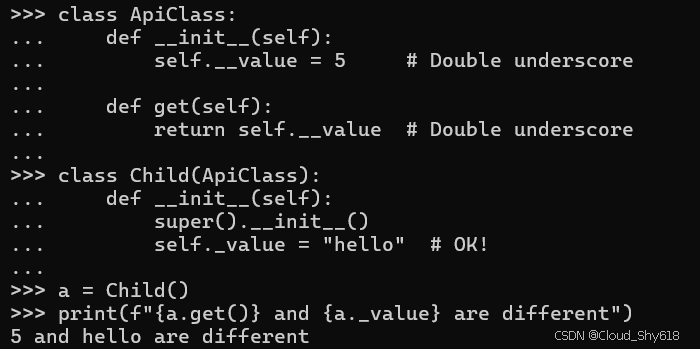
注意:
- Python 编译器并未严格强制执行私有属性。
- 从一开始就计划允许子类使用内部 API 和属性执行更多操作,而不是选择将它们锁定。
- 使用受保护字段的文档来指导子类,而不是尝试使用私有属性强制进行访问控制。
- 仅考虑使用私有属性以避免与您无法控制的子类发生命名冲突。