自定义中间件规则
多个中间件执行顺序
我们已经掌握了自定义中间件的编写方式,接下来继续讲解自定义中间件的核心规则,重点讲解多个中间件同时存在时的执行顺序。
我们之前写的代码,无论是类方式还是装饰器方式创建的中间件,大多都只有一个中间件、单个钩子。哪怕装饰器写法定义了多个钩子,在同一个执行阶段也只会存在一个钩子逻辑。
现在我们思考一个核心问题:如果在同一个执行阶段,挂载了多个中间件、多个钩子,它们的执行顺序是怎样的?
我们分两种风格讲解:节点风格、包装风格。
节点风格
回顾 Agent 的完整执行链路:用户输入 → Agent 执行 → 模型调用 → 最终输出 。整条链路在节点风格下分为四个核心钩子阶段:before_agent、before_model、after_model、after_agent。
假设我们配置了三个中间件 M1、M2、M3,且三个中间件都实现了相同阶段的节点钩子。它们在同一个执行阶段的触发顺序遵循以下固定规则:
则【节点风格】的中间件执行顺序如下图所示:
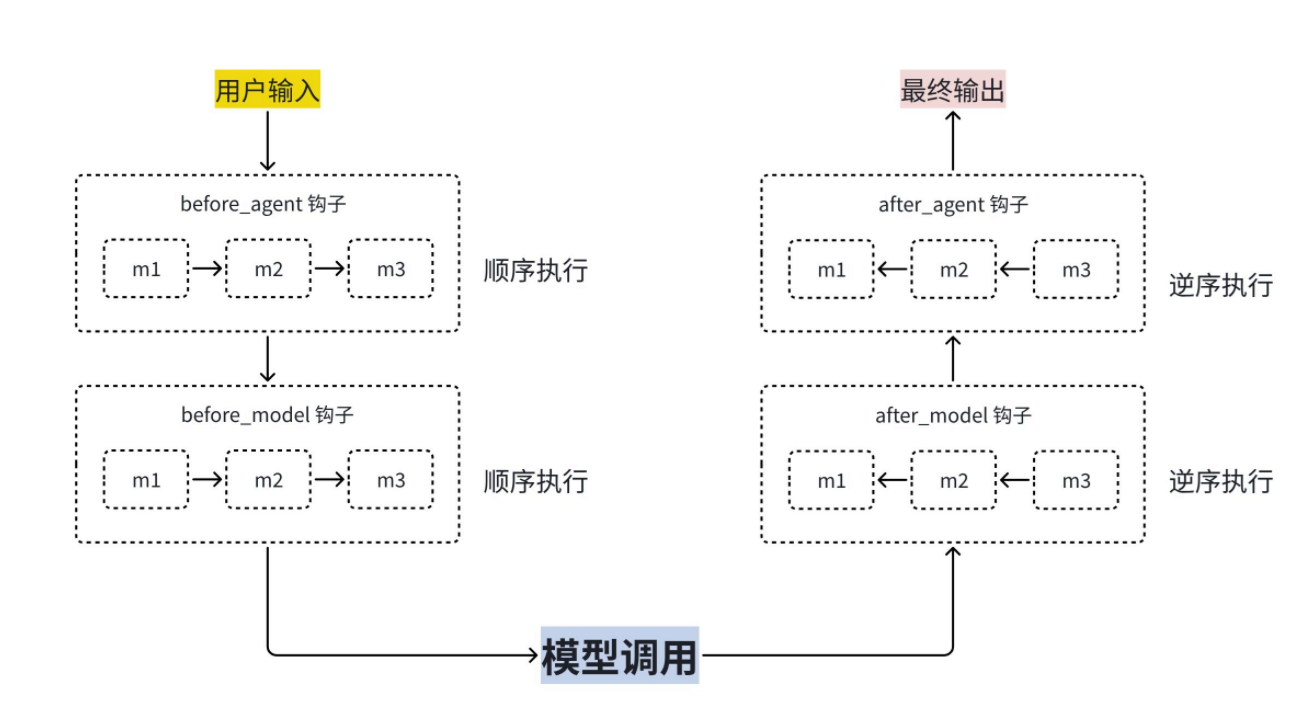
1. 前置阶段:正序执行(注册顺序)
before_agent 和 before_model 属于流程前置钩子,会严格按照我们在 middleware 列表中从上到下的注册顺序正序执行。即:
python
before_agent: M1 → M2 → M3
before_model: M1 → M2 → M32. 后置阶段:逆序执行(与注册顺序相反)
after_model 和 after_agent 属于流程后置钩子,执行顺序完全反转 ,按照注册顺序的逆序执行。即:
python
after_model: M3 → M2 → M1
after_agent: M3 → M2 → M13. 完整执行流程示意
以三个中间件为例,完整的节点风格执行顺序如下:
python
┌─────────────────────────────────────────────────────────────────┐
│ 步骤1: before_agent → M1 → M2 → M3(正序) │
│ 步骤2: before_model → M1 → M2 → M3(正序) │
│ 步骤3: 【执行核心模型调用】 │
│ 步骤4: after_model → M3 → M2 → M1(逆序) │
│ 步骤5: after_agent → M3 → M2 → M1(逆序) │
└─────────────────────────────────────────────────────────────────┘4. 核心设计原则
这种"前置正序、后置逆序"的设计,与栈的"先进后出"(LIFO,Last In First Out)原则保持一致。其目的是确保多个中间件在叠加时,前置逻辑按预期顺序叠加,后置逻辑按相反顺序收尾,形成对称、可预测的执行模型。
需要注意的是 :节点风格的钩子方法(如 before_agent、after_model)是线性执行 的,每个钩子独立触发,彼此之间不会嵌套或包裹。这与下文要讲的"包装风格"(wrap_model_call、wrap_tool_call)有本质区别。
包装风格
与节点风格不同,包装风格 指的是中间件中的 wrap_model_call 和 wrap_tool_call 方法。这类钩子不是 在某个节点插入一段逻辑,而是将整个核心调用(模型调用或工具调用)完全包裹起来,形成类似"洋葱"的多层嵌套结构。换句话说,每个包装器都在核心调用外面包了一层,可以在调用前后插入逻辑,甚至可以控制是否执行调用、是否重试、是否替换结果。
【包装风格】的中间件执行顺序如下所示,以模型调用举例:
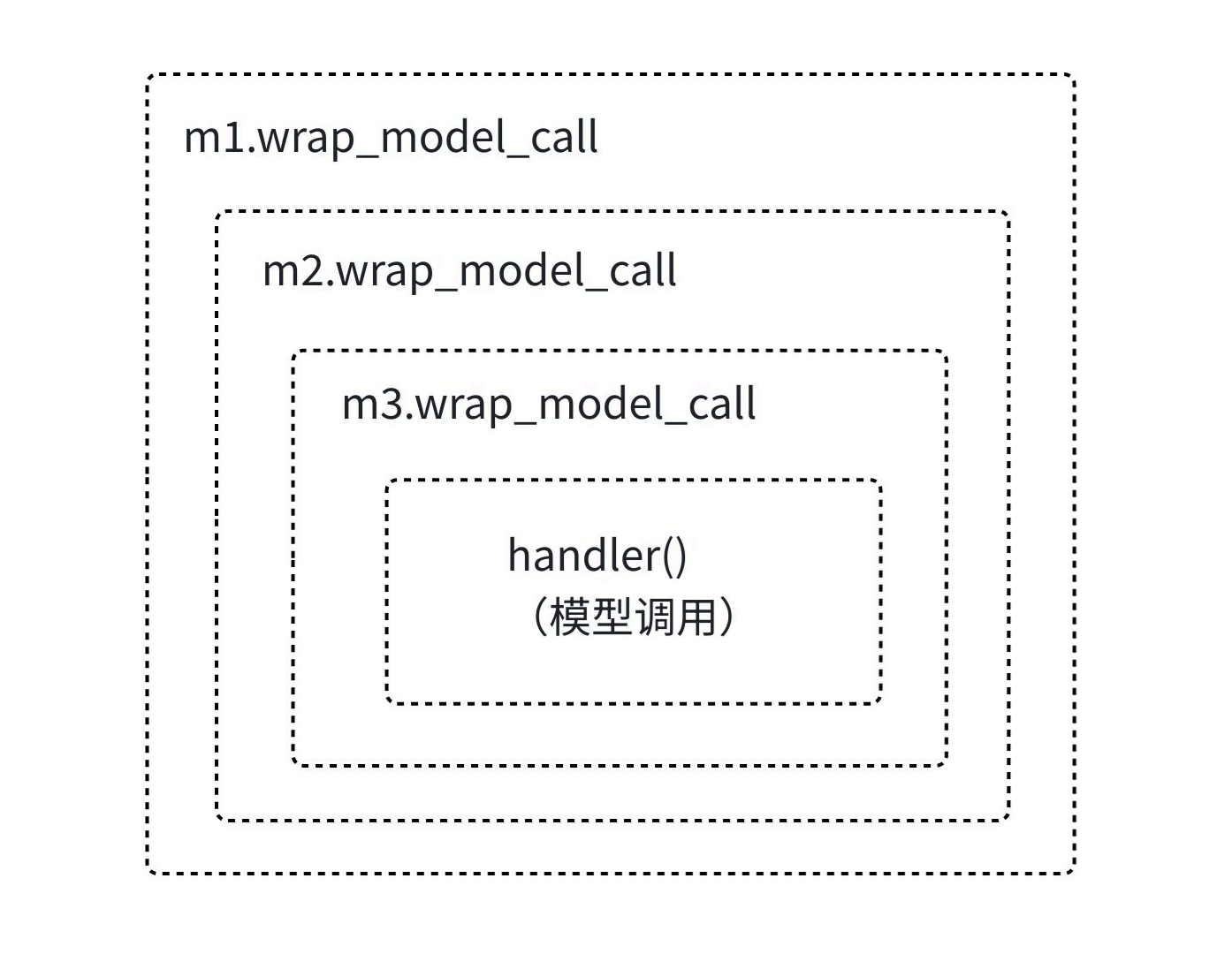
假设我们配置了三个中间件 M1、M2、M3 ,且三个中间件都实现了 wrap_model_call 方法。它们在同一个执行阶段的触发顺序遵循以下固定规则:
1. 请求阶段:逆序执行(洋葱模型由外向内)
当请求进入包装器链时,最后注册的中间件最先拦截请求 。即按照 middleware 列表中从下到上的顺序执行包装器的前置逻辑。
python
wrap_model_call(请求阶段): M3 → M2 → M12. 核心调用:最内层执行
当所有包装器的前置逻辑执行完毕后,最终由最内层的包装器(即最先注册的 M1)负责调用真正的核心逻辑(模型调用或工具调用)。
3. 响应阶段:正序执行(洋葱模型由内向外)
核心调用返回结果后,最先注册的中间件最先处理响应 ,即按照 middleware 列表中从上到下的顺序执行包装器的后置逻辑。
python
wrap_model_call(响应阶段): M1 → M2 → M34. 完整执行流程示意
以三个中间件为例,完整的包装风格执行顺序如下:
python
┌─────────────────────────────────────────────────────────────────────────────┐
│ 请求阶段(外层 → 内层) │
│ M3.wrap 前置逻辑(后注册,最外层) │
│ → M2.wrap 前置逻辑(中间层) │
│ → M1.wrap 前置逻辑(先注册,最内层) │
│ → 【执行核心模型调用】 │
│ 响应阶段(内层 → 外层) │
│ ← M1.wrap 后置逻辑 │
│ ← M2.wrap 后置逻辑 │
│ ← M3.wrap 后置逻辑 │
└─────────────────────────────────────────────────────────────────────────────┘这种执行模型被称为 "洋葱模型"(Onion Model),因为每个包装器就像洋葱的一层,请求从外层进入,经过所有层到达核心,响应再从内层逐层返回。
具体过程:
-
请求阶段(从外向内) :
Middleware2.wrap_model_call先拿到请求,调用其内部的handler,这个handler实际上是Middleware1.wrap_model_call。于是控制权转入Middleware1。 -
核心调用 :
Middleware1调用其handler,也就是真正的核心模型调用。 -
响应阶段(从内向外) :核心调用返回结果
response,这个结果作为Middleware1中handler的返回值,被Middleware1拿到。Middleware1可以修改这个response,然后将其作为自己的返回值返回。 -
外层接收 :
Middleware2中调用的handler的返回值,就是经过Middleware1处理后的response。Middleware2可以继续处理,再返回给上层。
5. 核心设计原则
包装风格的核心设计原则如下:
| 执行阶段 | 执行方向 | 设计意图 |
|---|---|---|
| 请求阶段(进入核心前) | 逆序(后注册先执行) | 最外层的包装器最先拦截请求,可以优先做鉴权、日志等前置处理 |
| 响应阶段(核心返回后) | 正序(先注册先返回) | 最内层的包装器最先处理原始响应,外层逐层封装或转换结果 |
6. 包装风格与节点风格的核心区别
| 对比维度 | 节点风格 | 包装风格 |
|---|---|---|
| 执行方式 | 线性执行,各自独立 | 嵌套执行,形成洋葱模型 |
| 前置执行方向 | 正序(先注册先执行) | 逆序(后注册先执行) |
| 后置执行方向 | 逆序(后注册先执行) | 正序(先注册先返回) |
| 能否控制核心调用 | 否(仅在节点插入逻辑) | 是(可以决定是否调用、重试、替换结果) |
| 典型方法 | before_agent、after_model |
wrap_model_call、wrap_tool_call |
实际上在一个 Agent 中,【节点风格】和【包装风格】可以同时存在。钩子的执行顺序与 Agent 关联的中间件顺序有关。
为了直观验证节点风格与包装风格在多个中间件同时存在时的执行顺序,我们编写了一个包含两个中间件的测试用例:LoggingMiddleware(标记为【1】)和 Logging2Middleware(标记为【2】)。两个中间件都实现了 before_model、after_model 节点钩子,以及 wrap_model_call、wrap_tool_call 包装钩子。
预期执行顺序:
-
before_model节点钩子:按注册顺序正序执行 → 【1】→ 【2】 -
wrap_model_call包装钩子(请求阶段):按注册顺序逆序执行 → 【2】→ 【1】 -
after_model节点钩子:按注册顺序逆序执行 → 【2】→ 【1】
python
from typing import Callable, Any
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import (
before_model,
wrap_model_call,
ModelRequest,
ModelResponse,
after_model,
before_agent,
after_agent,
wrap_tool_call,
AgentMiddleware
)
from langchain.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import ToolMessage
from langgraph.prebuilt.tool_node import ToolCallRequest
from langgraph.runtime import Runtime
from langgraph.types import Command
# ============================================
# 1. 定义工具
# ============================================
@tool
def get_weather_for_location(city: str) -> str:
"""获取指定城市的天气信息。"""
return f"{city}总是阳光明媚!"
# ============================================
# 2. 配置模型
# ============================================
model = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# ============================================
# 3. 定义中间件(两个中间件,便于观察执行顺序)
# ============================================
# --------------------------------------------
# 3.1 Logging2Middleware(标记为 【2】)
# --------------------------------------------
class Logging2Middleware(AgentMiddleware):
"""第二个中间件,所有日志标记为【2】"""
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("【2】before_model:即将调用模型(节点钩子)")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("【2】after_model:调用模型完成(节点钩子)")
return None
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
print("【2】wrap_model_call:请求阶段(包装器-外层)")
for attempt in range(3):
print(f" 【2】尝试调用模型 (第 {attempt + 1} 次)")
try:
result = handler(request)
print("【2】wrap_model_call:响应阶段(包装器-外层)")
return result
except Exception as e:
if attempt == 2:
raise
print(f" 【2】模型调用错误,将重试: {e}")
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command],
) -> ToolMessage | Command:
print(f"【2】wrap_tool_call:执行工具: {request.tool_call['name']}")
print(f" 【2】参数: {request.tool_call['args']}")
try:
result = handler(request)
print("【2】wrap_tool_call:工具执行成功")
return result
except Exception as e:
print(f"【2】wrap_tool_call:工具执行失败: {e}")
raise
# --------------------------------------------
# 3.2 LoggingMiddleware(标记为 【1】)
# --------------------------------------------
class LoggingMiddleware(AgentMiddleware):
"""第一个中间件,所有日志标记为【1】"""
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("【1】before_model:即将调用模型(节点钩子)")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("【1】after_model:调用模型完成(节点钩子)")
return None
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
print("【1】wrap_model_call:请求阶段(包装器-内层)")
for attempt in range(3):
print(f" 【1】尝试调用模型 (第 {attempt + 1} 次)")
try:
result = handler(request)
print("【1】wrap_model_call:响应阶段(包装器-内层)")
return result
except Exception as e:
if attempt == 2:
raise
print(f" 【1】模型调用错误,将重试: {e}")
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command],
) -> ToolMessage | Command:
print(f"【1】wrap_tool_call:执行工具: {request.tool_call['name']}")
print(f" 【1】参数: {request.tool_call['args']}")
try:
result = handler(request)
print("【1】wrap_tool_call:工具执行成功")
return result
except Exception as e:
print(f"【1】wrap_tool_call:工具执行失败: {e}")
raise
# ============================================
# 4. 创建 Agent(注意中间件注册顺序)
# ============================================
agent = create_agent(
model=model,
tools=[get_weather_for_location],
system_prompt="你是一位乐于助人的助手。",
middleware=[LoggingMiddleware(), Logging2Middleware()],
# 注册顺序:【1】先注册 → 【2】后注册
)
# ============================================
# 5. 执行 Agent
# ============================================
print("=" * 60)
print("开始执行 Agent - 多中间件执行顺序验证")
print("注册顺序:【1】→ 【2】")
print("=" * 60 + "\n")
response = agent.invoke({
"messages": [{"role": "user", "content": "北京的天气如何?"}]
})
print("\n" + "=" * 60)
print("最终响应结果")
print("=" * 60)
print(f"助手回复:{response['messages'][-1].content}")
print("\n" + "=" * 60)
print("完整消息列表")
print("=" * 60)
for i, msg in enumerate(response['messages']):
msg_type = type(msg).__name__
content_preview = msg.content[:80] + "..." if len(msg.content) > 80 else msg.content
has_tool_calls = hasattr(msg, 'tool_calls') and bool(msg.tool_calls)
print(f" [{i}] {msg_type}: {content_preview} (tool_calls={has_tool_calls})")运行上述代码后,观察日志输出可以清晰看到多个中间件在同一执行阶段的执行顺序:
python
============================================================
开始执行 Agent - 多中间件执行顺序验证
注册顺序:【1】→ 【2】
============================================================
【1】before_model:即将调用模型(节点钩子)
【2】before_model:即将调用模型(节点钩子)
【1】wrap_model_call:请求阶段(包装器-内层)
【1】尝试调用模型 (第 1 次)
【2】wrap_model_call:请求阶段(包装器-外层)
【2】尝试调用模型 (第 1 次)
【2】wrap_model_call:响应阶段(包装器-外层)
【1】wrap_model_call:响应阶段(包装器-内层)
【2】after_model:调用模型完成(节点钩子)
【1】after_model:调用模型完成(节点钩子)
【1】wrap_tool_call:执行工具: get_weather_for_location
【1】参数: {'city': '北京'}
【2】wrap_tool_call:执行工具: get_weather_for_location
【2】参数: {'city': '北京'}
【2】wrap_tool_call:工具执行成功
【1】wrap_tool_call:工具执行成功
【1】before_model:即将调用模型(节点钩子)
【2】before_model:即将调用模型(节点钩子)
【1】wrap_model_call:请求阶段(包装器-内层)
【1】尝试调用模型 (第 1 次)
【2】wrap_model_call:请求阶段(包装器-外层)
【2】尝试调用模型 (第 1 次)
【2】wrap_model_call:响应阶段(包装器-外层)
【1】wrap_model_call:响应阶段(包装器-内层)
【2】after_model:调用模型完成(节点钩子)
【1】after_model:调用模型完成(节点钩子)
============================================================
最终响应结果
============================================================
助手回复:北京的天气是**阳光明媚**的!☀️
这是一个好天气,适合外出活动。不过如果您需要更具体的温度、湿度或风力等信息,也可以告诉我,我可以进一步帮您查询。有什么其他需要帮忙的吗?
============================================================
完整消息列表
============================================================
[0] HumanMessage: 北京的天气如何? (tool_calls=False)
[1] AIMessage: 好的,我来查询一下北京的天气情况。 (tool_calls=True)
[2] ToolMessage: 北京总是阳光明媚! (tool_calls=False)
[3] AIMessage: 北京的天气是**阳光明媚**的!☀️
这是一个好天气,适合外出活动。不过如果您需要更具体的温度、湿度或风力等信息,也可以告诉我,我可以进一步帮您查询。有什么其... (tool_calls=False)第一次 wrap_model_call 调用
当第一次调用 wrap_model_call 时,执行顺序是:
框架调用外层 【2】 ,打印 【2】请求阶段
【2】调用 handler(request),进入内层 【1】
【1】打印 【1】请求阶段
【1】调用 handler(request),调用真正的模型
模型返回结果(带 tool_calls)
【1】打印 【1】响应阶段
返回到 【2】 ,【2】打印 【2】响应阶段
这个顺序应该是:
【2】请求 → 【1】请求 → 核心调用 → 【1】响应 → 【2】响应但日志是:
【1】请求 → 【2】请求 → 【2】响应 → 【1】响应真正的原因:DeepSeek 的 tool_calls 处理逻辑
在日志中,第一次 wrap_model_call 被调用了两次 ,而不是一次:
第一次 wrap_model_call(模型返回 tool_calls)
- 这次调用在 handler(request) 内部可能没有立即返回完整响应 ,而是触发了工具执行,然后重新调用了 wrap_model_call
第二次 wrap_model_call(模型返回最终答案)
- 这次才是真正完成模型调用
关键观察 :【1】请求 先打印,然后 【2】请求 打印,说明 在 handler(request) 内部,模型调用(可能包含工具调用)被多次递归或重试 ,导致内层包装器先执行完,然后外层才执行。
日志不是因为执行顺序错误 ,而是因为 DeepSeek 模型在处理工具调用时,内部的 handler(request) 可能不是一次性返回,而是递归调用了多次 ,导致打印顺序看起来"错乱"。
实际执行顺序依然是:
框架 → 【2】→ 【1】→ 核心调用 → 【1】→ 【2】→ 框架但由于核心调用可能内部触发了工具调用并再次进入 wrap_model_call ,导致日志的顺序变得复杂。
代码本身没有问题,这是正常行为。 如果换成 OpenAI 模型,可能会看到不同的日志顺序,因为 OpenAI 和 DeepSeek 在工具调用的内部实现上确实存在差异。
| 钩子类型 | 执行方向 | 实际观察结果 | 是否符合规则 |
|---|---|---|---|
before_model(节点风格) |
正序(先注册先执行) | 【1】→ 【2】 | ✅ 符合 |
after_model(节点风格) |
逆序(后注册先执行) | 【2】→ 【1】 | ✅ 符合 |
wrap_model_call 请求阶段(包装风格) |
逆序(后注册先执行) | 【2】→ 【1】 | ✅ 符合 |
wrap_model_call 响应阶段(包装风格) |
正序(先注册先返回) | 【1】→ 【2】 | ✅ 符合 |
总结:节点风格钩子 (before_*、after_*)的执行是线性独立 的,before_* 按注册顺序正序执行,after_* 按注册顺序逆序执行。包装风格钩子 (wrap_model_call、wrap_tool_call)则形成洋葱模型,请求阶段逆序执行(后注册先包裹),响应阶段正序执行(先注册先返回)。两者共同构成了 LangChain 中间件完整且可预测的执行顺序体系。
更新状态
接下来我们继续学习自定义中间件的第二条核心规则:更新 Agent 状态。
自定义状态结构
之前说过,AgentState 是 Agent 的默认状态。这个默认状态的载体就是 AgentState。我们不仅能直接使用原生默认状态,还可以基于 AgentState 派生子类,扩展属于中间件专属的自定义状态字段,用来在多个钩子之间共享业务数据。
我们举两个业务场景,分别定义两套独立的自定义状态:
-
场景一: 统计整套
Agent运行过程中大模型的调用总次数 ,创建TrackingState; -
场景二: 记录每一轮模型调用产生的令牌消耗数量 ,创建
UsageTrackingState。
python
from typing import NotRequired
from langchain.agents import AgentState
# ============================================
# 定义自定义状态(用于中间件间传递数据)
# ============================================
class TrackingState(AgentState):
"""
追踪中间件执行次数的状态。
用途:记录模型调用次数,便于在中间件中统计和日志输出。
"""
# NotRequired 表示该字段在状态中是可选的
# 首次调用时可能不存在,中间件需要做空值判断
model_call_count: NotRequired[int]
class UsageTrackingState(AgentState):
"""
追踪令牌使用情况的状态。
用途:记录最后一次模型调用消耗的令牌数,
便于进行成本监控或触发摘要策略。
"""
last_model_call_tokens: NotRequired[int]1. 定义模型调用计数状态 TrackingState
直接继承父类 AgentState,新增字段 model_call_count,类型标记为 NotRequired[int],代表非必填整型,用来累计模型调用次数。 这个子类会完整继承 AgentState 原生自带的全部字段,比如消息列表、结构化输出参数等,我们新增的只是拓展字段,原有默认属性不受影响。
2. 定义令牌消耗追踪状态 UsageTrackingState
同样继承 AgentState,新增字段 last_model_call_tokens,用来保存最近一次模型调用的 token 消耗数值。
这里解释为什么要拆分多个独立状态类: 这个逻辑和 LangGraph 私有状态的设计思路完全一致。Agent 全局存在基础主状态,但是在不同钩子、不同执行阶段,我们可以定义多套私有状态,仅在对应节点 / 钩子内使用,各司其职、互不干扰,因此我们可以根据业务拆分多个独立状态类。
接下来我们不要忘记了需要在钩子中通过 state_schema 参数绑定!【具体往下看】
状态更新
中间件可以修改 Agent 的状态(state),机制因钩子类型而异。
对于节点风格:当想要进行简单状态更新(计数、标志等)时使用。可直接返回字典
对于包装风格 :当需要在模型调用或工具调用过程中基于请求 / 响应逻辑更新状态时(如记录使用量、触发摘要等)使用。通过 ExtendedModelResponse 或 Command 更新状态
-
在
wrap_model_call中返回ExtendedModelResponse,其中包含Command(update={...})来注入状态更新。 -
在
wrap_tool_call中直接返回Command。
节点风格钩子:返回字典更新状态(after_model 示例)
1. 场景选型分析
统计模型调用次数,最合适的钩子是 after_model,也就是每一次大模型执行完成后 执行计数 + 1 操作,时机精准。 我们使用装饰器 @after_model 实现节点风格钩子,这里补充一个之前没详细讲解的关键点: 所有节点风格钩子的装饰器,都必须增加 state_schema 参数,把我们自定义的状态类传入,框架才会识别我们要操作的拓展字段,否则无法读写自定义状态。
2. 方法参数与返回值规则
节点风格钩子方法固定两个入参:
state:我们指定的自定义状态实例(本例是TrackingState),可以读取状态里所有字段;runtime:全局运行时上下文。
返回值有两种规范:None 或者 字典 。 之前演示时我们统一返回 None,没有讲解字典的作用,这里重点说明:返回的字典,就是我们需要更新的状态键值对 ,和 LangGraph 节点返回字典更新状态的机制完全同源,很好理解。
python
# --------------------------------------------
# after_model 钩子:计数模型调用次数
# --------------------------------------------
@after_model(state_schema=TrackingState)
def add_counter(state: TrackingState, runtime: Runtime) -> dict[str, Any] | None:
"""
在每次模型调用后,将调用次数加 1。
执行流程:
1. 从 state 中读取当前的 model_call_count,若不存在则默认为 0
2. 加 1 后返回更新字典,框架会自动合并到 state 中
返回的字典会与 Agent 状态合并,更新 model_call_count 字段。
"""
# state.get() 安全读取,避免字段不存在时报错
current_count = state.get("model_call_count", 0)
new_count = current_count + 1
print(f"【计数器】模型调用次数: {current_count} → {new_count}")
return {"model_call_count": new_count}每一轮模型执行完毕,钩子自动触发,读取当前计数、自增 1,通过返回字典完成状态更新。 如果把计数逻辑放到其他钩子阶段,时机不合适,会出现统计偏差,after_model 是这个场景的最优选择。
包装风格钩子:通过 ExtendedModelResponse + Command 更新状态(wrap_model_call 示例)
1. 场景选型分析
读取模型返回的 token 消耗数据,必须拿到模型响应结果,因此只能使用包装风格 @wrap_model_call,包裹完整模型调用流程,才能拿到 handler 返回的完整模型响应对象,提取 token 用量元数据。
2. 包装风格更新状态核心区别
节点风格靠返回字典更新状态,但包装风格钩子不能直接返回字典,必须使用框架提供的专用结构完成状态更新:
-
外层返回 ExtendedModelResponse(扩展模型响应对象);
-
对象内部携带 Command 指令,Command 的 update 参数接收字典,用来写入 / 修改状态字段。
同样,包装装饰器也必须配置 state_schema,绑定令牌追踪专用状态 UsageTrackingState。
3. 完整逻辑拆解
调用 handler(request) 执行原生模型调用,拿到完整 ModelResponse 响应对象;
从响应中提取最新一条 AI 消息,读取 response_metadata 里的 token_usage,取出本次完成消耗的 completion_tokens 数值;
构造 ExtendedModelResponse:
-
**第一个参数
model_response:**传入原生模型返回的完整结果; -
第二个参数
command: 实例化Command,传入update={自定义状态字段: 提取到的token数值};
将构造好的扩展响应对象作为钩子返回值,框架自动解析 Command,完成状态更新。
python
# --------------------------------------------
# wrap_model_call 钩子:追踪令牌使用情况
# --------------------------------------------
@wrap_model_call(state_schema=UsageTrackingState)
def track_usage(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ExtendedModelResponse:
"""
在模型调用前后追踪令牌使用情况。
执行流程:
1. 执行 handler 调用真正的模型
2. 获取响应后,构造 ExtendedModelResponse
3. 通过 Command(update=...) 更新状态中的 last_model_call_tokens
注意:此处使用固定值 150 作为演示,
实际项目中应从 response.usage_metadata 中提取真实令牌数。
"""
# 执行实际的模型调用
response = handler(request)
# 从响应中提取令牌使用情况(实际项目)
# 示例:tokens = response.usage_metadata.get("total_tokens", 0)
tokens_used = 150 # 模拟令牌数(演示用)
print(f"【用量追踪】本次调用消耗令牌: {tokens_used}")
# 返回 ExtendedModelResponse,包含:
# - model_response: 原始模型响应
# - command: 用于更新 Agent 状态
return ExtendedModelResponse(
model_response=response,
command=Command(update={"last_model_call_tokens": tokens_used}),
)补充:如果是
wrap_tool_call工具包装钩子,逻辑更简化,可直接返回Command对象完成状态更新,不需要外层包裹扩展响应。
复用之前的天气查询工具 get_weather_for_location;
定义两个装饰器钩子 add_counter、track_usage;
创建 create_agent 实例,将两个钩子全部放入 middleware 列表注册;
调用 agent.invoke() 发起用户提问:「北京的天气如何?」;
invoke 执行完成后,方法返回完整更新后的全局状态,我们可以直接调用 .get() 读取自定义拓展字段:
-
response.get("model_call_count"):读取模型调用总次数; -
response.get("last_model_call_tokens"):读取最后一轮模型的 token 消耗。
python
from typing import NotRequired, Callable
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import (
after_model,
wrap_model_call,
ModelRequest,
ModelResponse,
ExtendedModelResponse,
)
from langchain.tools import tool
from langchain_deepseek import ChatDeepSeek
from langgraph.types import Command
from langgraph.runtime import Runtime
# ============================================
# 1. 统一状态定义(合并两个状态)
# ============================================
class TrackingState(AgentState):
"""统一追踪状态:同时记录调用次数和令牌使用情况"""
model_call_count: NotRequired[int]
last_model_call_tokens: NotRequired[int]
# ============================================
# 2. 定义工具
# ============================================
@tool
def get_weather_for_location(city: str) -> str:
"""获取指定城市的天气信息。"""
return f"{city}总是阳光明媚!"
# ============================================
# 3. 配置模型
# ============================================
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0
)
# ============================================
# 4. 定义中间件钩子
# ============================================
@after_model(state_schema=TrackingState)
def add_counter(state: TrackingState, runtime: Runtime) -> dict[str, int]:
"""
在每次模型调用后,将调用次数 + 1。
执行流程:
1. 从 state 中读取当前的 model_call_count,如不存在则默认为 0
2. 加 1 后返回更新字典,框架会自动合并到 state 中
"""
current_count = state.get("model_call_count", 0)
new_count = current_count + 1
print(f"【计数器】模型调用次数: {current_count} -> {new_count}")
return {"model_call_count": new_count}
@wrap_model_call(state_schema=TrackingState)
def track_usage(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ExtendedModelResponse:
"""
在模型调用前后追踪令牌使用情况。
执行流程:
1. 执行 handler 调用真正的模型
2. 从响应的 response_metadata 中安全提取令牌数
3. 通过 Command(update=...) 更新状态中的 last_model_call_tokens
"""
response = handler(request)
# 安全提取令牌数(避免链式访问崩溃)
try:
# 获取最后一条消息的元数据
last_message = response.result[-1] if response.result else None
if last_message and hasattr(last_message, 'response_metadata'):
token_usage = last_message.response_metadata.get("token_usage", {})
tokens_used = token_usage.get("completion_tokens", 0)
else:
tokens_used = 0
except (IndexError, AttributeError, KeyError):
tokens_used = 0
print(f"【用量追踪】本次调用消耗令牌: {tokens_used}")
return ExtendedModelResponse(
model_response=response,
command=Command(update={"last_model_call_tokens": tokens_used})
)
# ============================================
# 5. 创建 Agent
# ============================================
agent = create_agent(
model=model,
tools=[get_weather_for_location],
system_prompt="你是一位乐于助人的助手。",
state_schema=TrackingState, # ✅ 统一使用同一个状态模式
middleware=[add_counter, track_usage],
)
# ============================================
# 6. 执行 Agent
# ============================================
print("=" * 60)
print("开始执行 Agent - 状态追踪演示")
print("=" * 60 + "\n")
response = agent.invoke({
"messages": [{"role": "user", "content": "北京的天气如何?"}]
})
print("\n" + "=" * 60)
print("最终状态数据")
print("=" * 60)
print(f"model_call_count: {response.get('model_call_count')}") # 2
print(f"last_model_call_tokens: {response.get('last_model_call_tokens')}") # 实际令牌数本次执行打印出模型调用次数为 2,原因是 Agent 完整执行两轮模型推理:
python
============================================================
开始执行 Agent - 状态追踪演示
============================================================
【用量追踪】本次调用消耗令牌: 53
【计数器】模型调用次数: 0 -> 1
【用量追踪】本次调用消耗令牌: 49
【计数器】模型调用次数: 1 -> 2
============================================================
最终状态数据
============================================================
model_call_count: 2
last_model_call_tokens: 49第一次模型调用:解析用户问题,判断需要调用天气工具;
工具执行完成后,第二次模型调用:整合工具返回的天气数据,生成最终自然语言回答; 两次模型执行都会触发 after_model 计数钩子,因此最终计数等于 2,同时成功打印出最新一轮的 token 消耗数值,证明两套状态更新逻辑全部生效。
通用规则与补充注意事项
节点风格通用规范 所有节点钩子(before_agent/before_model/after_model/after_agent)更新状态逻辑完全一致:返回字典即可更新,唯一强制要求是装饰器配置 state_schema 绑定对应自定义状态类;原生消息列表 messages 等内置字段也可以通过返回字典修改。
包装风格通用规范
-
wrap_model_call:返回ExtendedModelResponse,内部携带Command(update={...}); -
wrap_tool_call:直接返回Command(update={...}); 状态更新依靠Command对象实现,无法直接返回字典。
多中间件状态覆盖 / 累加规则(兼容 LangGraph Reducer 机制) 当多个中间件同时修改同一个状态字段时,分两种处理逻辑:
-
非 Reducer 自定义字段(我们本次写的 model_call_count、last_model_call_tokens):外层中间件覆盖内层 ,后执行的外层中间件数值最终生效【外层中间件胜出】;
-
Reducer 内置字段(原生 messages 消息列表):采用追加累加策略,不会覆盖原有消息,新消息直接追加到列表尾部。
我们自定义的拓展字段默认都是覆盖型逻辑,如果同时挂载多个修改同一字段的中间件,列表靠后的中间件(外层)结果会覆盖前面的数值。
到这里,自定义中间件「更新状态」这条规则就全部讲解完毕。
提前退出
接下来我们讲自定义中间件最后一条核心规则:提前退出(节点跳转)。
它的作用是: 当代码执行到某一个钩子逻辑时,如果判定不需要继续走完完整的 Agent 流程,就可以主动终止整个流程;除了直接结束 Agent,还支持执行流程跳转,跳转到工具节点、模型节点这类指定环节。
具体用法是在节点样式钩子(before_agent、before_model、after_model、after_agent)中,返回一个包含 jump_to 键的字典,即可将执行跳转到指定节点。
可用目标:
-
"end":直接结束Agent(会触发after_agent钩子) -
"tools":跳到工具节点 -
"model":跳到模型节点(会触发before_model钩子)
通过 @hook_config(can_jump_to=[...]) 装饰器声明允许的跳转目标(未声明的跳转会被忽略)。
注意: 跳转、提前退出功能仅节点风格钩子可用 (before_agent、before_model、after_model、after_agent),包装风格钩子不支持 (wrap_model_call、wrap_tool_call 无法实现跳转逻辑)。 不管是直接结束流程、跳转工具节点、跳转模型节点,全部只能写在节点样式钩子中。
具体用法:实现跳转的两个核心步骤
1. 新增 @hook_config 装饰器声明允许的跳转目标
在节点钩子原有装饰器上方,额外添加 @hook_config 钩子配置装饰器,通过参数 can_jump_to 传入列表,提前声明当前钩子允许跳转到哪些节点。 列表里填写你需要用到的跳转目标,支持三类固定值:
-
"end": 直接结束整套Agent执行; -
**
"tools":**跳转到工具执行节点; -
**
"model":**跳转到大模型调用节点。 只有在列表里声明过的目标,后续跳转才会生效;未声明的跳转目标会直接被框架忽略,不会执行跳转。
2. 返回带 jump_to 键的字典,指定实际跳转目的地
我们之前讲节点钩子时提到,返回字典可以更新 AgentState 全局状态;现在实现跳转,只需要在返回的字典中新增 jump_to 键,键的值填写本次实际要跳转的目标。 对应规则:
-
想直接终止
Agent:"jump_to": "end"; -
想直接去执行工具:
"jump_to": "tools"; -
想重新调用大模型:
"jump_to": "model"。
示例:检测到敏感词后直接结束
python
# ============================================
# 1. 导入必要的模块
# ============================================
from typing import Any, NotRequired
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model, hook_config
from langchain.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage
from langgraph.runtime import Runtime
# ============================================
# 2. 定义工具
# ============================================
@tool
def get_weather_for_location(city: str) -> str:
"""获取指定城市的天气信息。"""
return f"{city}总是阳光明媚!"
# ============================================
# 3. 配置模型
# ============================================
model = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
# ============================================
# 4. 定义内容检查中间件
# ============================================
@after_model
@hook_config(can_jump_to=["end"])
def check_for_blocked(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""
在模型生成回复后,检查是否包含敏感词。
执行流程:
1. 获取模型生成的最后一条回复消息
2. 检查回复内容中是否包含敏感词(示例:敏感词)
3. 如果包含敏感词:
a. 用预设的安全回复替换原始回复
b. 通过 jump_to 跳转到 "end" 节点,提前终止对话
4. 如果不包含敏感词,返回 None,流程正常继续
注意:
- @after_model 表示在模型调用之后执行此钩子
- @hook_config(can_jump_to=["end"]) 允许该钩子跳转到 end 节点
- 返回的字典会与 Agent 状态合并,其中 jump_to 用于控制流程跳转
"""
# 获取模型生成的最后一条消息
last_message = state["messages"][-1]
# 检查是否包含敏感词
if "敏感词" in last_message.content:
print(f"【内容审核】检测到敏感词,已拦截回复")
# 返回拦截结果:
# - messages: 追加安全回复(替换原始回复)
# - jump_to: 跳转到 end 节点,终止流程
return {
"messages": [AIMessage("抱歉,检测到内容包含敏感信息,无法回答该问题。")],
"jump_to": "end"
}
# 未检测到敏感词,正常继续
return None
# ============================================
# 5. 创建 Agent
# ============================================
agent = create_agent(
model=model,
tools=[get_weather_for_location],
system_prompt="你是一位乐于助人的助手。",
middleware=[check_for_blocked], # 应用内容审核中间件
)
# ============================================
# 6. 执行 Agent(测试正常对话)
# ============================================
print("=" * 60)
print("【测试1】正常对话(不含敏感词)")
print("=" * 60)
response1 = agent.invoke({
"messages": [{"role": "user", "content": "北京的天气如何?"}]
})
print(f"助手:{response1['messages'][-1].content}\n")
# ============================================
# 7. 执行 Agent(测试敏感词拦截)
# ============================================
print("=" * 60)
print("【测试2】敏感词拦截(含敏感词)")
print("=" * 60)
response2 = agent.invoke({
"messages": [{"role": "user", "content": "请帮我写一段包含敏感词的内容"}]
})
print(f"助手:{response2['messages'][-1].content}")示例钩子写在 @after_model(模型执行完成后的节点钩子):
先读取状态里最新一条消息,也就是大模型刚生成的 AIMessage;
判断消息内容里是否包含预设敏感词;
如果检测到敏感词:
-
往消息列表追加一条回复:"无法回答该问题";
-
在返回字典中设置
"jump_to": "end",流程直接终止,不再执行后续逻辑;
如果没有敏感词,返回 None,流程正常往下走。
python
============================================================
【测试1】正常对话(不含敏感词)
============================================================
助手:北京的天气总是阳光明媚!☀️
============================================================
【测试2】敏感词拦截(含敏感词)
============================================================
【内容审核】检测到敏感词,已拦截回复
助手:抱歉,检测到内容包含敏感信息,无法回答该问题。这个场景就是典型的提前退出: 检测到违规内容后,直接截断整个 Agent 流程,不再执行工具、二次模型调用等剩余步骤。
这个规则既可以叫提前退出,也可以称之为流程节点跳转,两种叫法都没问题。 整体逻辑以配置为主,没有复杂业务计算,我们后面可以自行修改代码测试跳转效果,下面不再完整运行演示。
总结核心逻辑:
-
can_jump_to列表:预先声明当前钩子允许跳转的全部节点; -
返回字典内的
jump_to字段:决定本次执行实际要跳转到哪一个节点。
中间件总结
| 使用 / 定义原则 | 描述 |
|---|---|
| 单一职责 | 每个中间件只做一件事 |
| 优雅降级 | 避免中间件异常导致 Agent 崩溃 |
| 选择合适钩子 | - 日志、计数 → 节点风格- 重试、缓存、动态切换 → 包装风格 |
| 自定义状态 | 明确字段含义 |
| 独立测试 | 单独测试中间件逻辑后再集成 |
| 注意顺序 | 关键中间件(如安全校验)放在列表前面 |
| 优先使用内置中间件 | https://reference.langchain.com/python/langchain/middleware |
除了 LangChain 内置的中间件外,自定义中间件除了我们已演示的工具调用监控功能外,还能实现一系列其他功能,如下一章 Agents 核心能力中所述的【动态模型】、【动态工具】、【动态提示词】等。