目录
[四、省 Token 还是费算力?本地部署的争议](#四、省 Token 还是费算力?本地部署的争议)
[六、如何用上 GLM-5.2?](#六、如何用上 GLM-5.2?)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 GLM-5.2 上线并开源
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在过去的一年里,大模型写代码已经不是什么新鲜事了。随便找个 AI,让它写一段贪吃蛇游戏或者生成一个静态网页,基本都能对答如流。但如果你是一个真正的程序员,你肯定知道,日常工作里最折磨人的根本不是"写一个独立的函数",而是接手一个几万行的老项目,在错综复杂的数据库、前端组件和后端接口中,小心翼翼地加一个新功能,同时还得保证不把原来的系统搞崩溃。
**这就是目前 AI 编程面临的最大高山:长程任务(Long-context tasks)。**当一个 AI 能够不知疲倦地跨越数小时甚至数天,去阅读、理解、修改并测试一个完整的软件工程时,它才算真正从一个"代码补全工具"进化成了一个"数字打工人"。
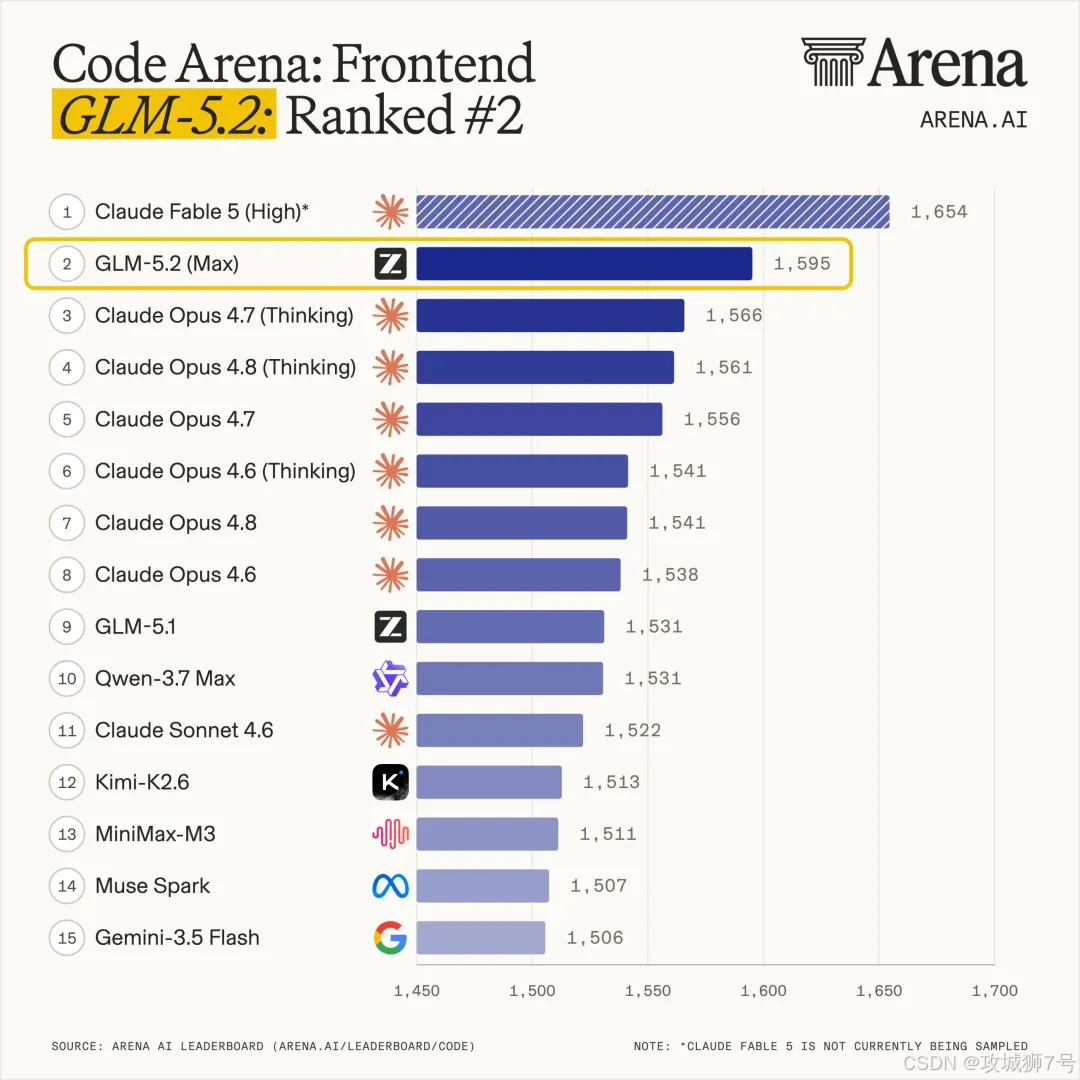
**2026年6月17日,智谱交出了他们面对这座高山的答卷------GLM-5.2。**这个模型一经发布,不仅在盲测平台 Code Arena 上拿下了全球第一,甚至连全球最流行的前端框架 Next.js 的创始人 Guillermo Rauch 都在社交平台上惊呼:"真的被震惊到了,这改变了游戏规则。"
那么,这个被海外技术大牛惊叹、在国内开发者圈子里引发热议的 GLM-5.2,到底强在哪里?它在真实的开发环境里,用起来究竟是什么感觉?本文将抛开那些枯燥的跑分,带你通俗易懂地看懂 GLM-5.2 的真实实力。
一、100万上下文:不仅是容量大,更是"记性好"
提到 GLM-5.2,最绕不开的一个核心指标就是 1M(100万)上下文。
**很多人对 100万上下文没有直观概念。**简单来说,它能一次性吞下 74万条服务器日志帮你找 Bug,或者把一个包含几十个文件、几万行代码的完整工程全部塞进它的脑子里。
以前,很多模型也宣称自己支持超长上下文,但往往是"看得多、忘得快"。一旦上下文超过几十万 tokens,模型就开始变傻,前面刚定好的变量名,后面写着写着就忘了。为了解决这个问题,智谱花了几个月时间,专门扩展了 1M Coding Agent 的训练环境,覆盖了自动化研究、性能优化等多个领域。这意味着 GLM-5.2 的 1M 上下文是"Solid(扎实)"的无损上下文。
在实际体验中,有开发者让 GLM-5.2 从零开始,完成了一个覆盖 Web、移动端与小程序的多端应用。从开发、联调、测试到打包上线,整个过程累计处理了 88万 tokens,几乎把 100万的窗口用满了。在过去,这种规模的工程需要一个开发团队协作好几周,而现在,GLM-5.2 在一次长程对话中就能跑完。
更夸张的是,有硬核开发者用 Rust 语言,从零开始重构了当年人类登月时的飞控计算机程序。整整 65000 行老代码,一字未改地移植为 Rust,整个过程全部由 GLM-5.2 作为一个 Agent(智能体)自主走完。这种对超大型重构工程的把控力,正是 1M 扎实上下文带来的底气。
二、真实干活体验:慢,但稳得让人害怕
跑分再高,也不如拉出来溜溜。为了测试 GLM-5.2 的真实水平,有资深开发者没有用简单的算法题去测它,而是直接给它上了一个真实的业务需求:在一个基于 FastAPI 和 Vue3 的全栈系统里,给"我的文章"模块加一个"批量重写"功能。
这个需求听起来简单,但真要落地,需要改数据库表结构、写一个类似生产者消费者的并发队列、改后端接口、改前端列表和编辑页,最后还得补上单元测试。这是一个典型的牵一发而动全身的全栈长程任务。
GLM-5.2 接到任务后,自己把工作拆成了 9 个子任务,然后一口气干了一个半小时(86分钟)。在这个过程中,它展现出了极其惊艳的"工程判断力",完全不像一个只会死板敲代码的机器人:
**(1)主动避开"删库跑路"的坑:**项目里有一个老旧的测试文件,如果直接跑,会清空真实数据库里的数据。GLM-5.2 在动手前就发现了这个问题,主动在思考过程中提出:"这个测试会清空真实表,太危险了,绝不能照搬。我改用纯单元测试,用 mock(模拟)数据来验证逻辑。"它甚至没等人类踩坑,自己就先绕开了。
**(2)客串 DBA(数据库管理员)去救火:**在修改数据库结构时,迁移报错了,因为表里有个以前遗留的"孤儿列"挡了路。换作其他 AI 工具,多半就卡在这里弹红字等人类来修了。但 GLM-5.2 自己去查了表结构,翻了 MySQL 的连接列表,发现是一堆僵尸连接卡住了。它自己把这些连接 KILL 掉,删掉孤儿列,然后重新跑了迁移。整个救火过程花了 9 分钟,没向人类求助一句。
**(3)主动修复产品体验(UX)Bug:**在任务收尾时,它突然发现前端列表行的点击事件会和复选框的点击产生冲突(误触发)。人类根本没提这个 Bug,它自己发现并顺手修好了。
在这个长达一个半小时的测试中,GLM-5.2 修改了 20 多个文件。最难能可贵的是,从头到尾,它使用的字段名(如 rewrite_status、batch_id)在所有文件里都严丝合缝,没有出现任何前后矛盾的情况。最终,9 个子任务全部完成,15 条测试用例一把过。
三、为什么它这么慢?"谋士"般的思考代价
看到这里,你可能会问:既然这么强,为什么一个任务要跑 86 分钟?是不是太慢了?
确实,GLM-5.2 的速度算不上快。在上述测试中,它一共消耗了 116万输入 tokens,37.8万输出 tokens,但它的"缓存读取(cache_read)"高达惊人的 3240万 tokens。
它慢的原因主要有三个:
首先,这是 GLM 家族的"老传统"。它习惯在动手前把问题想透彻。在 86 分钟里,它光是"思考过程"就写了 6万字的 tokens,最长的一段思考足足有 2.3万字。它在"想"上花的时间,一点都不比写代码少。
其次,100万上下文是一个沉重的包袱。任务越往后,上下文越长。它每进行一轮对话,都要把前面几十轮的历史记录重新捋一遍,确保自己没有忘记之前的约定。最后 10 分钟,它光是读取缓存就烧掉了 1000多万 tokens。
最后,它非常谨慎。遇到脏数据或报错,它会反复去查日志、查表结构,不断试错。
这种"慢",换来的是一种类似中国古代"谋士"般的体验。比如,有用户让它帮忙写一个脚本,去除视频角落的"AI生成"水印。它没有像其他 AI 那样直接甩出一段代码,而是先分析需求,然后给出了"上、中、下三策":
-
上策:用 AI 逐帧修复,效果最完美,但耗时极长;
-
中策:用 FFmpeg 做模糊覆盖,效果和效率最平衡;
-
下策:直接裁剪画面,最简单粗暴但会损失画面。
它不仅列出了每种方案的优劣势和适用场景,还主动为你推荐了最适合的方案。这种先分析局势、评估选项、再推荐最优路径的做事风格,让它彻底摆脱了"听令办事的下属"的标签,更像是一个能帮你统筹全局的架构师。
四、省 Token 还是费算力?本地部署的争议
GLM-5.2 的这种"深度思考"模式,也在开源社区引发了一些争议。
在 Reddit 上,有不少本地部署(LocalLLaMA)的玩家抱怨,GLM-5.2 引入了思考档位(effort level)控制,虽然官方表示它能在相近的 token 预算下达到比肩 Claude Opus 4.8 的水平,但对于使用老旧硬件(比如老 Xeon 处理器)的本地用户来说,这简直是一场算力噩梦。
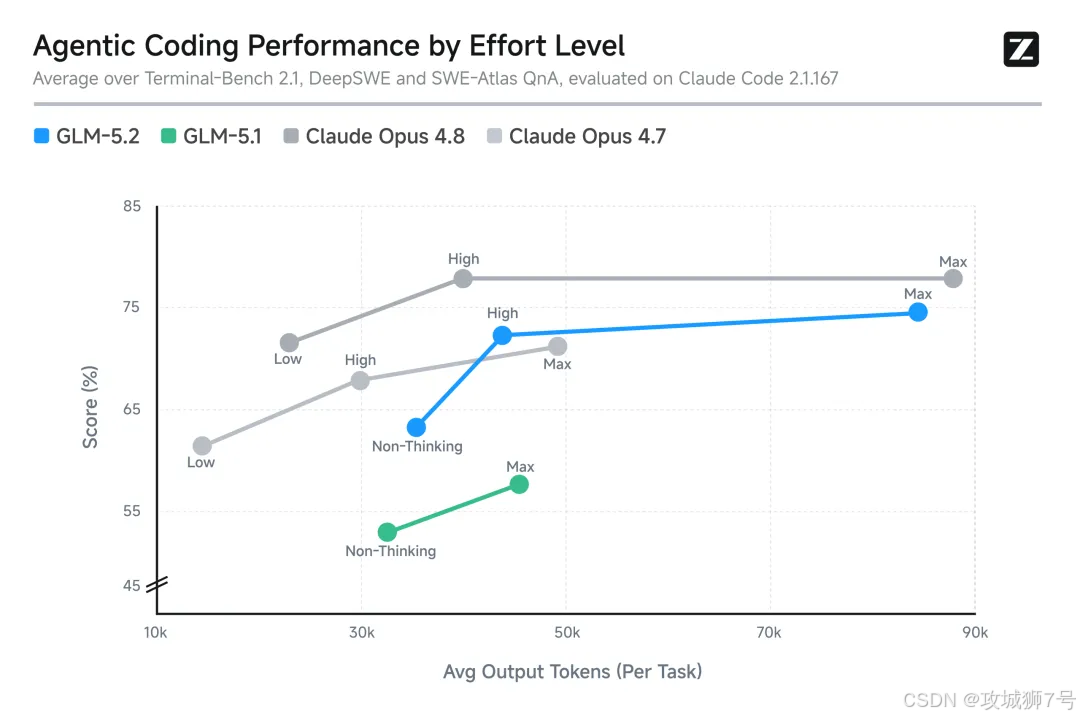
有用户反馈,为了省 token 开启了量化模式(Q4 quant)加高思考档位,结果等了 6000 个 tokens 才憋出一个答案,甚至有时候会让机器卡死 12 个小时无响应。
这其实揭示了当前大模型发展的一个现实矛盾:AI 变聪明了,并不意味着使用成本下降了。为了达到 98% 的顶级智能,模型需要进行极长的推理链条。对于普通打工人来说,如果只是想写个简单的脚本,这种动辄几万 token 的深度思考反而成了一种负担。因此,GLM-5.2 更适合那些真正需要处理复杂逻辑、长程任务的场景,而不是用来做简单的日常问答。
五、极致的底层优化与彻底的开源精神
为了支撑如此庞大的计算量,智谱在底层基础设施(Infra)上做到了极致。
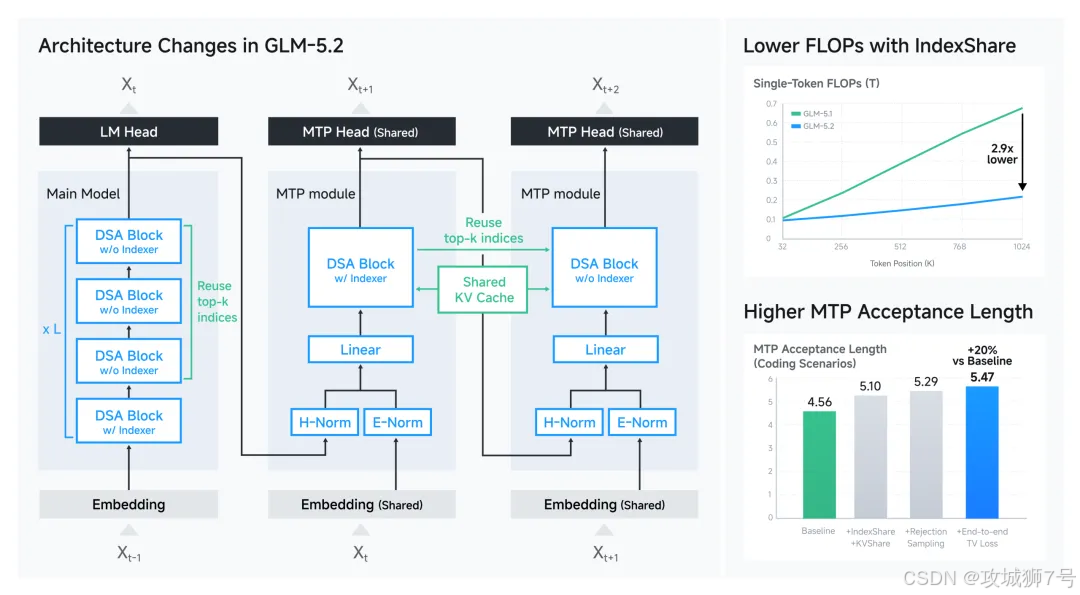
GLM-5.2 提出了一个叫 IndexShare 的技术,在每四层稀疏注意力层之间复用同一个索引器。这个硬核的技术创新,让它在 100万上下文长度下,将单位 token 的计算量(FLOPs)大幅降低到了原来的 2.9分之一。此外,它还改进了用于投机解码的 MTP 层,将接受长度最多提升了 20%。
**更让人振奋的是,GLM-5.2 是一颗纯正的"中国芯"驱动的大模型。**它在发布的第一天(Day 0),就已经完成了与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、海光、壁仞等几乎所有主流国产算力平台的推理适配。在国产芯片集群上,它实现了高吞吐、低延迟的大并发稳定运行。这证明了,即使在算力受限的大环境下,中国 AI 依然能通过架构创新和软硬件协同,跑出世界顶级的水平。
在商业策略上,智谱选择了最彻底的开源。GLM-5.2 在 Hugging Face、GitHub 和 ModelScope 上同步开源,模型权重遵循了最高权限的 MIT 协议。这意味着,无论是个人开发者还是企业,都可以自由下载、部署,甚至在它的基础上进行修改和商业化变现,没有任何地域限制。
正如智谱在发布时所说:"前沿智能不应只属于少数人,也不应被少数规则随时收回。它应该开放、可用、可构建,并服务于每一位开发者。"在某国际大厂突然封禁部分地区 API 的大背景下,GLM-5.2 的彻底无国界开源,无疑是对"技术平权"最好的诠释。
六、如何用上 GLM-5.2?
如果你是一个开发者,想要体验 GLM-5.2 的强大能力,目前有多种方式:
**(1)开源下载:**你可以直接去 GitHub、Hugging Face 或国内的 ModelScope 下载模型权重,使用 vLLM、SGLang 等主流框架进行本地部署。
**(2)API 调用:**智谱的 BigModel 开放平台已经上线了 GLM-5.2 的 API。如果你使用 Claude Code,只需要在配置文件里把接口地址指向智谱的 Anthropic 兼容接口,并在模型名后加上 `1m` 后缀(如 `glm-5.21m`),就能瞬间解锁百万上下文的编程助手。
**(3)在线体验与 Agent:**普通用户可以直接通过智谱清言 App 或网页版体验。针对办公和代码场景,智谱还推出了 AutoClaw 和 ZCode 等专属工具。
值得一提的是,官方目前还有限时福利:非高峰期(避开每日 14:00~18:00)调用 API 仅按 1 倍抵扣额度,性价比极高。
结语
**GLM-5.2 并不完美。**它思考得太深导致速度偏慢,在某些极度复杂的推理场景下,距离最顶尖的闭源模型可能还有微小的差距,也不适合对响应速度有严格要求的实时交互场景。
但是,如果你手里有一个几万行的祖传代码库需要重构,或者需要跨越几十个文件去排查一个深藏不露的 Bug,那么 GLM-5.2 绝对是你目前能找到的最靠谱的开源帮手。它不会中途遗忘,不会胡编乱造,它会像一个老练的工程师一样,一步一个脚印地帮你把坑填平。
**当 Next.js 的创始人惊呼"这改变了游戏规则"时,他看到的不仅仅是一个跑分很高的模型,而是一个真正能够胜任"软件工程师"这个职业的数字员工的雏形。**在通往 AGI(通用人工智能)的路上,GLM-5.2 让我们看到,国产大模型已经不再是跟在别人身后亦步亦趋的模仿者,而是真正站在了牌桌上,开始制定属于自己的规则。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!