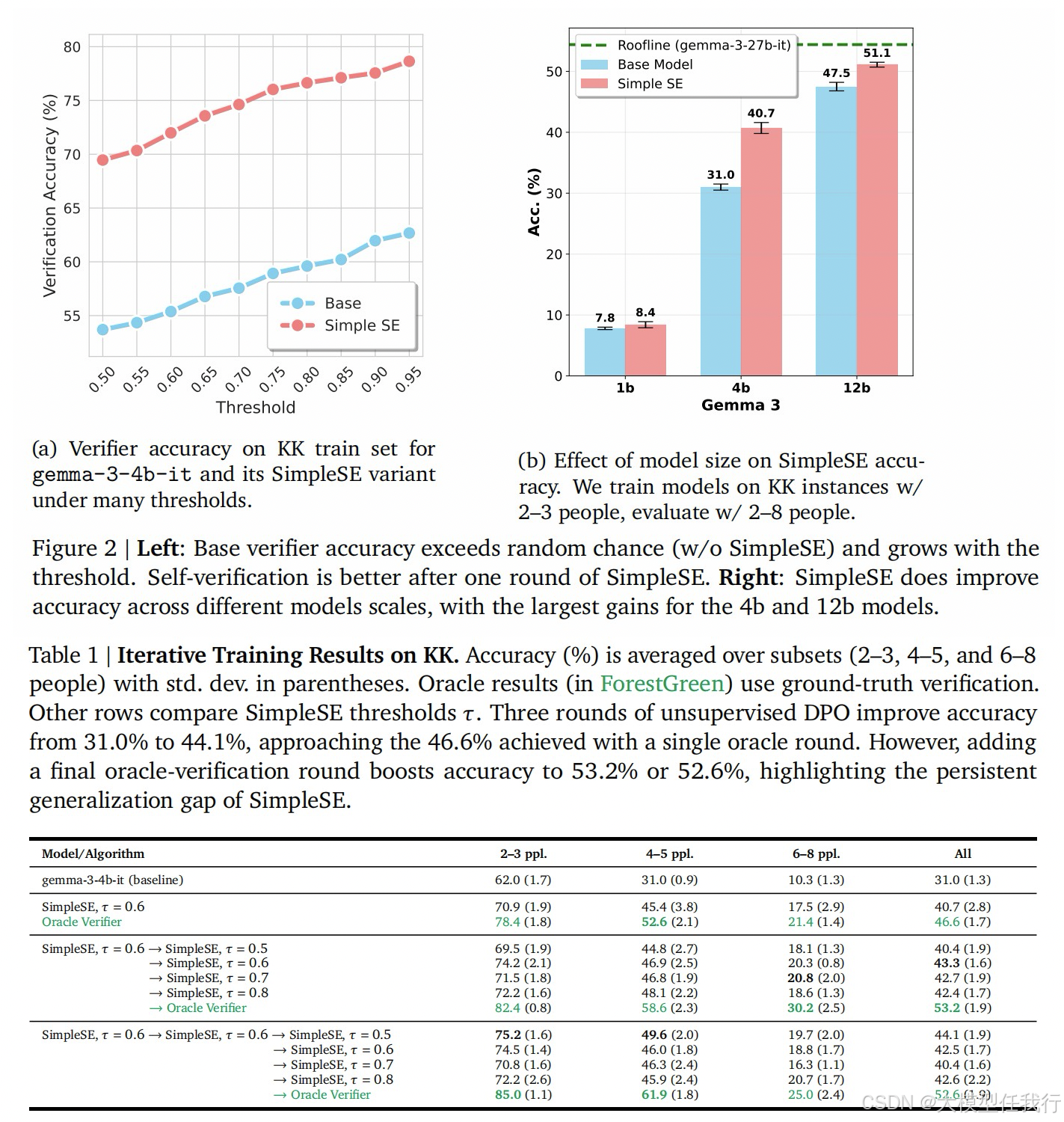
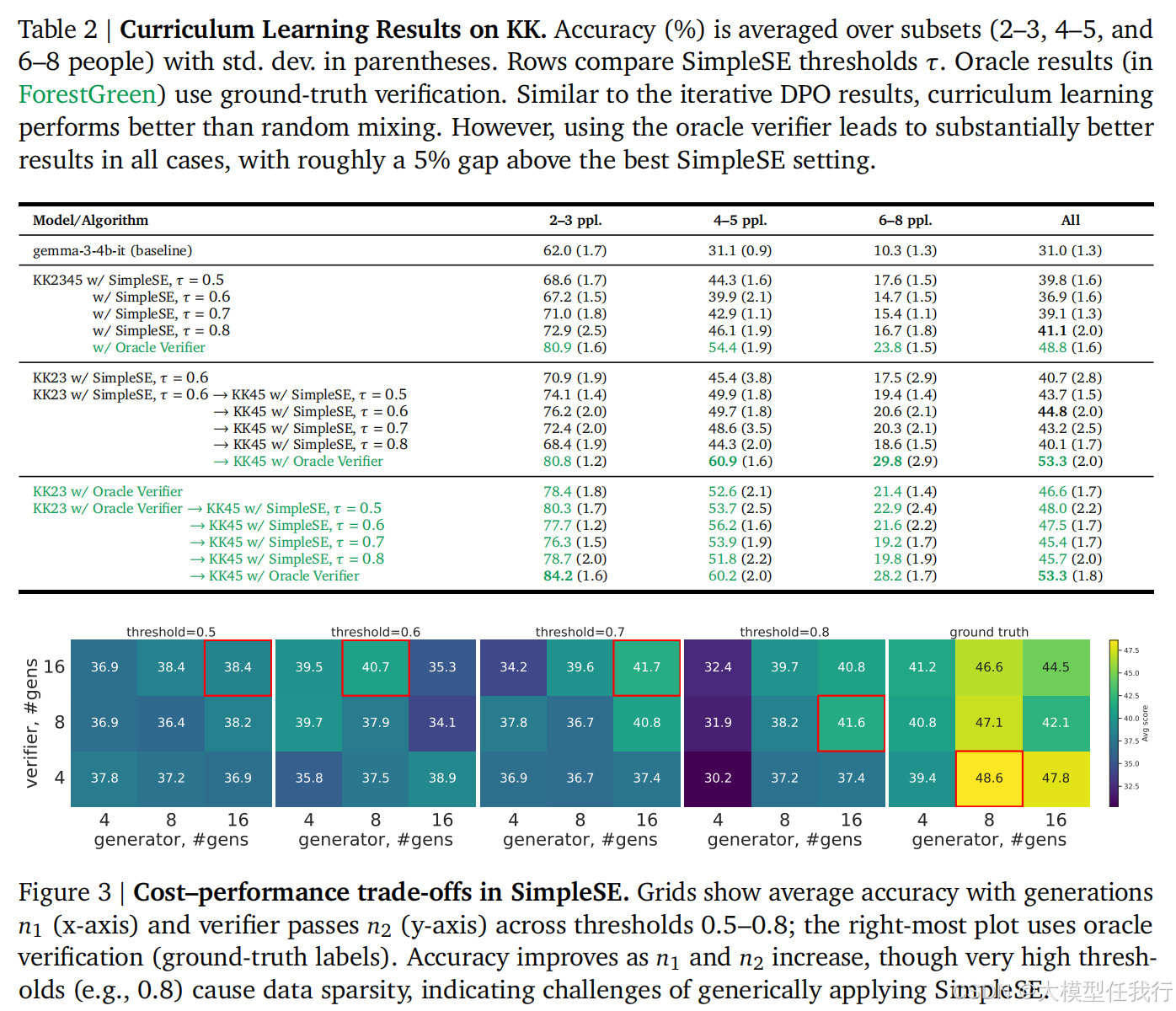
📖标题:On the Generalization Gap in Self-Evolving Language Model Reasoning
🌐来源:arXiv, 2606.01075v2
🛎️文章简介
🔸研究问题:探讨大模型在严格的闭环设定下,完全依靠内部生成的信号进行自我评估和微调,能在多大程度上逼近拥有真实标签监督训练的效果?
🔸主要贡献:论文评估了四种闭环自进化策略,揭示了内部监督与真实标签监督间存在持续性泛化差距,并发现多轮反馈机制在大模型上可显著缩小该差距。
📝重点思路
🔸构建统一离线框架:将多种自进化机制整合进"生成器与验证器"架构中,并利用直接偏好优化算法进行离线微调训练,保证模型训练的稳定性。
🔸采用可控核心测试床:采用"骑士与无赖"逻辑推理任务。利用其拥有确定性答案、且能通过改变问题复杂程度来控制难度的特点,精确衡量模型从简单到复杂的泛化能力。
🔸设计阈值过滤噪声:在单轮验证中,采用基于置信度阈值的多数投票机制,让验证器多次打分,提取高置信度的偏好数据,以缓解模型自身评估不准的问题。
🔸引入多轮修订机制:设计了多轮反馈策略,验证器给出自然语言反馈,生成器据此迭代修改。仅当最初错误的答案被成功修改为正确时,才提取为训练用的偏好数据。
🔸泛化性拓展验证:除逻辑任务外,在真实的数学与推理测试集中进行扩展验证,评估开放性问题中自进化的表现及局限。
🔎分析总结
🔸存在能力天花板:闭环自进化能带来一致的性能提升,但在投入大量算力后会遭遇瓶颈,难以抹平与真实标签监督训练的显著泛化差距。
🔸多轮修订效果最佳:百亿参数级别的大模型在使用多轮修订策略后,性能几乎追平了真实标签监督训练的效果,这表明强大的内在验证和修订能力是闭环自进化成功的关键。
🔸能力门槛效应显著:十亿参数级别的小模型无法有效进行自进化。小模型验证器的召回率低,且多轮修改容易将正确答案改错,从而引入过多噪声。
🔸本质是"锐化"而非"拓荒":自进化主要提高了模型对已有正确解题路径的确信程度,表现为单次采样准确率显著提升,而多次生成准确率基本不变。它很难拓展出全新的推理能力或实现跨域泛化。
🔸算力分配性价比:在构建数据时,增加验证器的验证次数比单纯增加生成器的候选答案数量,能够取得更高的性价比。
💡个人观点
论文打破了模型能够无限自我提升的迷思,用控制变量法探明了纯闭环自进化的理论天花板。核心启示在于,自进化机制本质上是一种"能力锐化"工具,在构建复杂的自动化技能流时,用高质量外部数据跨越模型的基础能力门槛是不可替代的。只有在模型具备了合格的自我判别能力后,再引入多轮反馈的自进化策略,才是兼顾研发成本与模型最终效果的最优解。