开场暴击:Agent 工程师正在血洗招聘市场
先聊点刺激的。
这两年冒出来一个岗位叫 Agent 工程师,直接把传统软件工程师的薪资天花板给捅穿了。企业抢人抢到疯------不是因为他们会写更漂亮的代码,而是因为他们能把 AI 变成真正能干活的数字员工。
你手机上那些 App,扒开皮看看:Cursor 不是编辑器,是一个能读你代码库、自己写代码、自己改 bug 的 Agent。豆包不是聊天框,是能调日历、搜邮件、帮你写周报的 Agent。飞书 CLI 更狠,直接在命令行里塞了个会操作电脑的 AI。Claude、OpenClaw、Hermes、悟空、Workbody......名字千奇百怪,内核一模一样。
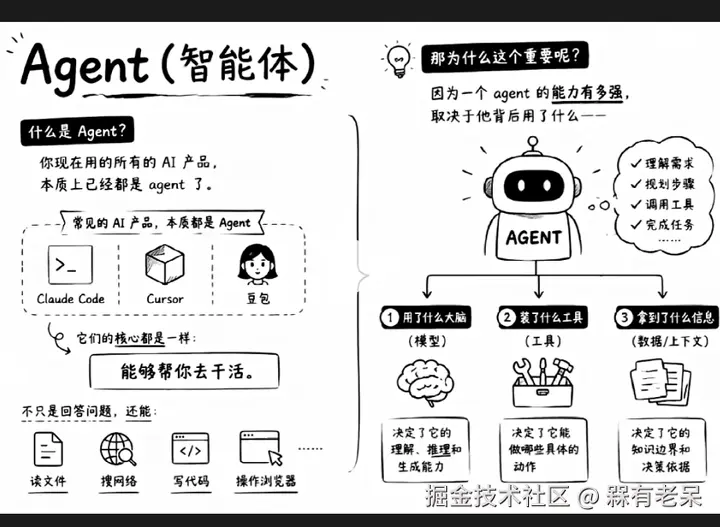
一个 Agent 强不强,取决于三样东西:用了什么脑子、装了哪些工具、拿到了什么情报。
就这么简单。三样凑齐了,AI 就是你的数字分身。缺一样,它就只是个高级版小爱同学。
LLM 不是万能的神,它只是一个没有手脚的大脑
豆包背后是字节的模型,Claude 背后是 Anthropic。LLM 是 Agent 的大脑,这一点没人搞错。
但搞反的是------很多人以为 LLM 什么都能干。
真相是:LLM 只会两件事,推理 和生成。它没有手脚,碰不到外部世界。你让它查股价,它脑子里没有纽交所的实时数据。你让它发邮件,它连 SMTP 服务器长什么样都不知道。
那为什么 Cursor 能改你代码?因为 LLM 推理出 "用户想重构这个函数",然后调了一个叫 edit_file 的工具。为什么豆包能查日历?因为 LLM 判断出 "明天下午三点有空",然后调了日历 API。
LLM 是大脑,但它需要手和脚。手和脚,就是 Tool。
Tool:一顿操作猛如虎,全靠工具补
没有 Tool 的 AI,就像一个被关在玻璃房里的天才------满脑子想法,啥也执行不了。
来段代码,直观感受一下。假设你问 AI:"青岛啤酒的收盘价是多少?" 没有工具的情况下,AI 要么说"我无法获取实时数据",要么直接编一个数字糊弄你(这更可怕)。
有工具的情况下,流程是这样的:
 第一步,LLM 自己推理:用户问的是实时股价,我脑子里的训练数据没有这个,但我工具箱里有个
第一步,LLM 自己推理:用户问的是实时股价,我脑子里的训练数据没有这个,但我工具箱里有个 get_closing_price,恰好能查。第二步,它生成一个 tool_call,参数填上"青岛啤酒"。第三步,你的代码执行这个函数,拿到 67.92。第四步,LLM 再把这个数字裹上一句人话丢给用户。
看代码。先把工具定义好:
javascript
import client from "./client.mjs";
const tools = [
{
type: "function",
function: {
name: "get_closing_price",
// ⚠️ 注意这里!description 是 LLM 理解工具的唯一入口
// 写烂了,LLM 就不知道该什么时候调它
description: "获取指定股票的收盘价",
parameters: {
type: "object",
properties: {
name: {
type: "string",
description: "股票名称" // 别写 "string类型的证券标识符",LLM 看不懂人话之外的鬼东西
}
},
required: ["name"]
}
}
}
];工具函数长这样,朴实无华:
javascript
function get_closing_price(name) {
if (name === '青岛啤酒') return "67.92";
if (name === '贵州茅台') return "1488.21";
return "未找到股票";
}然后把工具挂到请求里,tool_choice: 'auto' 的意思是 "你自己看着办,该调就调,不该调就别瞎调":
javascript
const send_message = async (messages) => {
return await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages,
tools,
tool_choice: 'auto'
});
};
const main = async () => {
let messages = [
{ role: 'user', content: "青岛啤酒的收盘价是多少?" }
];
const response = await send_message(messages);
const message = response.choices[0].message;
console.log(message); // 你会看到 tool_calls,不是胡编乱造的价格
};
main();这里面有一个无数人踩过的坑:工具的 description 不是写给程序员看的,是写给 LLM 看的。 你写 "获取指定股票的收盘价",LLM 秒懂。你写 "本接口通过 RESTful 风格调用证券数据源返回 JSON 格式的收盘价",LLM 直接懵逼。参数 description 同理,"股票名称" 四个字比 "string 类型,符合 ISO 证券编码规范" 有效一百倍。
Reasoning:掀开 LLM 的天灵盖,看看它在想什么
LLM 每次回复你之前,其实脑子里都嘀咕了一大段。只是平时被藏起来了,你只能看到最终答案。
DeepSeek 良心,给了个参数叫 reasoning_effort,设成 'high' 之后模型会花更多 Token 做深度思考------而且,它把思考过程通过 reasoning_content 完整暴露给你。
javascript
import client from './client.mjs';
const main = async () => {
const result = await client.chat.completions.create({
model: 'deepseek-v4-flash',
reasoning_effort: 'high', // 别手软,设 high
messages: [
{
role: 'system',
content: '你是一个足球领域的专家,请尽量帮我回答与足球相关的问题'
},
{
role: 'user',
content: 'C罗是哪个国家的足球运动员?'
},
{
role: 'assistant',
content: 'C罗是葡萄牙的足球运动员'
},
{
role: 'user',
content: '内马尔呢?'
}
]
});
console.log('思考过程:');
console.log(result.choices[0].message.reasoning_content);
// ↑ 这里面你会看到模型的内心戏:
// "用户先问了C罗,答案是葡萄牙。现在又问内马尔,
// 结合上下文应该也是在问国籍。内马尔我记得是巴西的......"
console.log('最终答案:');
console.log(result.choices[0].message.content);
// "内马尔是巴西的足球运动员。" ------ 干净利落
};
main();这玩意儿有什么用?三个字:可解释性。
以前 LLM 输出一个莫名其妙的结果,你只能挠头------它到底怎么想的?Prompt 哪里写劈了?现在你把 reasoning_content 打出来一看,哦,原来它在第三步的推理跳步了,原来它把一个不相关的上下文硬扯进来了。定位问题、调优 Prompt 的效率直接翻倍。
一张图把四个概念串起来
以上聊了四个东西,单独看容易忘,串起来才是完整链路:
ini
messages(多轮对话上下文)
↓
LLM 接收,开启 reasoning_effort='high'
↓
推理过程中产出生 reasoning_content(思考过程,流式输出)
↓
判断:需要调工具吗?
├── 不需要 → 直接生成 content 输出
└── 需要 → 找到对应 tool → 填参数 → 执行函数 → 拿到结果
↓
再做一次 completion
↓
输出 content就这么一条线。Agent 靠 LLM 做推理,靠 Tool 做执行,靠 messages 记上下文。你把这三样拼好,再拿 reasoning_content 当调试窗口,基本上一个能打的 AI 应用就立起来了。
多说两句
市面上 AI 教程铺天盖地,但大部分都在教你怎么写 Prompt。Prompt 当然重要,但它只是 messages 里的一部分。
真正拉开差距的是两件事:你会不会给 LLM 装工具,你能不能看懂它的推理过程。
前者决定了 AI 能做多少事。后者决定了你多快能定位到它做错了什么。
这两个东西玩明白了,剩下的都是体力活。