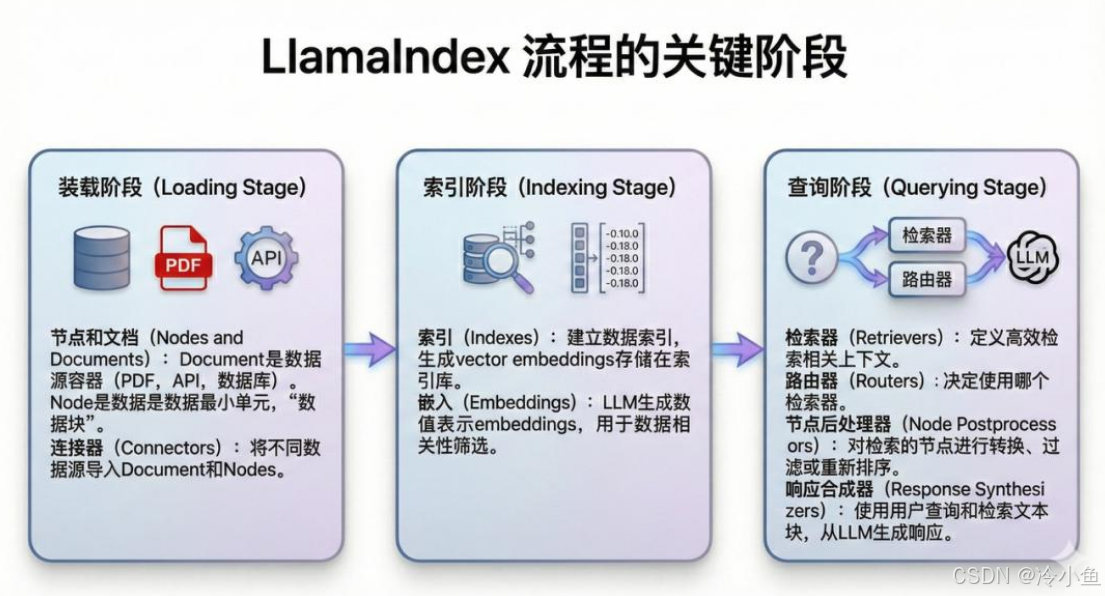
一、开篇引言:为什么2026年的LlamaIndex值得重新审视
1.1 行业现状:RAG/Agent落地的真实痛点
如果你在过去两年参与过企业级AI项目,以下场景一定不陌生:
- 幻觉严重:RAG系统检索到的上下文与问题相关,但LLM依然"脑补"出不存在的信息
- 链路僵化:静态DAG流水线无法应对复杂查询,一次检索失败就全盘崩溃
- 短时效Agent:现有Agent只能处理单轮或短周期任务,无法持续数小时甚至数周的文档自治工作
- 生产适配差:从原型到生产的鸿沟巨大,万级QPS场景下延迟飙升、缓存失效、观测盲区
这些问题在2024-2025年的RAG框架中普遍存在。彼时,LlamaIndex被定位为"简易RAG框架",适合快速原型,但企业级落地时往往力不从心。
1.2 LlamaIndex 2026的核心迭代定位
2026年的LlamaIndex完成了从 「简易RAG框架」到「RAG-First企业级自治智能体架构」 的跃迁。这不是简单的功能叠加,而是设计哲学的根本转变:
- 数据优先:一切能力围绕"如何让LLM获取最精准的上下文"展开
- 检索为王:14种索引体系、混合检索、重排优化,将检索质量推向新高度
- 事件驱动:Workflow架构替代静态DAG,支持循环、反思、熔断、异步长任务
- 自治闭环:Long-Horizon Document Agent体系,实现多智能体协同与文档自治
1.3 全文预告
本文将从以下维度深度拆解LlamaIndex 2026:
- 核心定位迭代:2026版本的核心变革与旧版本局限
- 五层核心架构:从数据接入到应用编排的全链路分层拆解
- 横向支撑生态:模型兼容、可观测性、LlamaHub
- 生产部署架构:分布式微服务、高并发、私有化
- 核心升级亮点:事件驱动Workflow、长周期Agent、原生多模态
- 典型落地场景:企业知识库、法务审查、多源查询等
二、核心定位迭代:2026版本的核心变革
2.1 旧版本的局限
| 维度 | 2024-2025年状态 | 核心问题 |
|---|---|---|
| 架构模式 | 静态DAG流水线(Query Pipelines) | 无法处理循环、分支、异步场景 |
| Agent能力 | 短时效、单轮对话为主 | 无法支撑长周期自治任务 |
| 生产适配 | 轻量化原型为主 | 缺乏微服务原生支持、高并发方案 |
| 多模态 | 基础图像支持 | 缺乏原生多模态RAG体系 |
| 企业适配 | 社区驱动 | 缺乏标准化混合检索、私有化部署方案 |
2.2 2026全新核心设计哲学
2026年的LlamaIndex围绕四个关键词重构:
- 数据优先(Data-First):所有能力的设计起点是"数据如何被高效接入、处理、索引、检索"
- 检索为王(Retrieval-First):不追求通用Agent框架,而是将检索质量做到极致
- 事件驱动(Event-Driven):Workflow架构基于Typed Events,支持Pub-Sub模式
- 自治闭环(Autonomous Loop):内置自校正、幻觉抑制、二次检索机制
2.3 核心能力跃迁
| 能力维度 | 2024-2025 | 2026 |
|---|---|---|
| 开发模式 | 原型快速搭建 | 兼顾轻量化开发 & 万级QPS生产微服务 |
| Agent时效 | 短周期(分钟级) | 长周期自治(小时/周级) |
| 部署模式 | 单机/简单容器 | 分布式微服务、VPC私有化、国产化适配 |
| 检索精度 | 基础向量检索 | 稀疏+稠密混合检索、自动重排、上下文压缩 |
| 多模态 | 基础图文 | 原生多模态RAG(图文音视频) |
三、五层核心架构全景(全文重点)
3.1 数据接入层:全场景数据源生态升级
3.1.1 基础文件与多模态数据接入
LlamaIndex 2026的数据接入层实现了真正的"全模态"支持:
- 文本:PDF、Word、Markdown、TXT、HTML、XML
- 图像:JPG、PNG、HEIC(2026新增)、TIFF、WebP
- 音频/视频:MP3、WAV、MP4、AVI(通过多模态LLM提取关键帧与转录文本)
- 结构化数据:CSV、Excel、JSON、Parquet、SQL数据库
关键升级:LlamaParse v2的推出,将文档解析能力推向新高度。在CVPR 2026发布的ParseBench基准测试中,LlamaParse Agentic在2,000+企业文档页面上取得84.9%的综合得分,领先于其他14种方法。
3.1.2 LlamaHub生态:200+ SaaS连接器
LlamaHub是LlamaIndex的连接器注册表,2026年已覆盖:
- 企业应用:SharePoint、Confluence、Notion、Salesforce、Jira、Slack
- 云存储:S3、GCS、Azure Blob、MinIO
- 数据库:PostgreSQL、MySQL、MongoDB、Snowflake、BigQuery
- API服务:GitHub、Twitter、Gmail、Google Calendar
统一Document抽象 :所有数据源接入后,都被转换为统一的Document对象,包含text、metadata、relationships等属性,确保全链路流转的一致性。
3.1.3 代码示例:多源数据统一接入
python
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.confluence import ConfluenceReader
from llama_index.readers.s3 import S3Reader
# 本地文件
local_docs = SimpleDirectoryReader(
input_dir="./data",
required_exts=[".pdf", ".png", ".docx"]
).load_data()
# Confluence企业Wiki
confluence_docs = ConfluenceReader(
base_url="https://your-domain.atlassian.net",
space_key="ENGINEERING"
).load_data()
# S3对象存储
s3_docs = S3Reader(
bucket="enterprise-docs",
prefix="contracts/2026/"
).load_data()
# 统一合并
all_documents = local_docs + confluence_docs + s3_docs3.2 文档处理层:智能化分块与预处理革新
3.2.1 基础分块能力复盘
LlamaIndex提供多种基础分块策略:
- SentenceSplitter:基于句子边界分块,保持语义完整性
- TokenTextSplitter:基于Token数量分块,精确控制上下文长度
- MarkdownNodeParser:针对Markdown文档,按标题层级分块
3.2.2 2026新增核心能力
语义分块(Semantic Splitting) :
利用Embedding模型检测语义断点,将相关内容聚合为同一Chunk,避免"一句话被切成两半"的问题。
python
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
semantic_parser = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=embed_model
)层级分块(Hierarchical Chunking) :
构建父子节点关系,父节点包含完整段落,子节点包含细粒度句子,支持递归检索时按需展开。
代码感知分块(Code-Aware Chunking) :
针对代码文档,识别函数、类、模块边界,保持代码结构的完整性。
长文档滑动窗口(Sliding Window for Long Docs) :
针对数百页的长文档(如合同、论文),采用重叠滑动窗口策略,确保跨页内容不被割裂。
3.2.3 自动化预处理流水线
2026年新增的IngestionPipeline支持全自动预处理:
python
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.openai import OpenAIEmbedding
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=512, chunk_overlap=50),
OpenAIEmbedding(),
]
)
# 自动去重、实体抽取、元数据打标
nodes = pipeline.run(documents=all_documents)内置预处理能力:
- 去重:基于语义相似度检测重复内容
- 实体抽取:自动识别文档中的人名、组织、地点、日期
- 元数据打标:自动提取标题、作者、创建时间、文档类型
- 多模态对齐:图文跨模态对齐,确保图像描述与文本内容关联
3.3 索引存储层:14种索引体系+全生态存储适配
3.3.1 主流核心索引适用场景拆解
LlamaIndex 2026提供14种索引类型,核心索引包括:
| 索引类型 | 适用场景 | 核心优势 |
|---|---|---|
| VectorStoreIndex | 语义相似度搜索 | 通用性强,支持任意Embedding模型 |
| KeywordTableIndex | 精确关键词匹配 | 低延迟,适合术语查询 |
| KnowledgeGraphIndex | 实体关系推理 | 支持多跳推理,适合复杂关系查询 |
| SummaryIndex | 文档摘要与概览 | 快速生成全文摘要 |
| TreeIndex | 层级结构检索 | 适合目录、组织架构等层级数据 |
| PropertyGraphIndex | 属性图检索 | 2026新增,支持更复杂的图查询 |
3.3.2 复合索引组合使用方案
企业复杂业务往往需要多种索引协同工作:
python
from llama_index.core import VectorStoreIndex, KeywordTableIndex
from llama_index.core.tools import QueryEngineTool
from llama_index.core.query_engine import RouterQueryEngine
# 构建多种索引
vector_index = VectorStoreIndex.from_documents(docs)
keyword_index = KeywordTableIndex.from_documents(docs)
# 创建查询引擎
vector_query_engine = vector_index.as_query_engine()
keyword_query_engine = keyword_index.as_query_engine()
# 路由查询引擎:根据问题类型自动选择索引
tools = [
QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description="适用于语义相似度搜索"
),
QueryEngineTool.from_defaults(
query_engine=keyword_query_engine,
description="适用于精确关键词匹配"
),
]
router_engine = RouterQueryEngine.from_defaults(tools=tools)3.3.3 全品类向量存储兼容
LlamaIndex 2026支持30+向量数据库,覆盖:
- 本地/轻量级:Chroma、FAISS、Qdrant(本地模式)
- 云端托管:Pinecone、Weaviate、Milvus Zilliz
- 关系型扩展:pgvector(PostgreSQL)、Redis
- 国产化:Milvus、StarRocks、Doris
python
from llama_index.vector_stores.qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
client = QdrantClient(host="localhost", port=6333)
vector_store = QdrantVectorStore(
"enterprise_kb",
client=client,
enable_hybrid=True, # 启用混合检索
fastembed_sparse_model="Qdrant/bm25"
)3.4 检索增强层:企业级混合检索标准化
3.4.1 多类型检索器体系
LlamaIndex 2026提供丰富的检索器类型:
- VectorRetriever:基于稠密向量的语义检索
- BM25Retriever:基于稀疏向量的关键词检索
- RouterRetriever:智能路由,根据查询类型选择检索策略
- SubQuestionRetriever:子问题分解,将复杂查询拆分为多个子查询
- RecursiveRetriever:递归检索,沿文档关系链深入检索
3.4.2 后置处理全链路
检索结果的后置处理直接影响最终生成质量:
python
from llama_index.core.postprocessor import (
SimilarityPostprocessor,
KeywordNodePostprocessor,
SentenceEmbeddingOptimizer
)
# 相似度过滤
similarity_processor = SimilarityPostprocessor(similarity_cutoff=0.7)
# 关键词过滤
keyword_processor = KeywordNodePostprocessor(required_keywords=["合同", "条款"])
# 上下文压缩
optimizer = SentenceEmbeddingOptimizer(
embed_model=embed_model,
percentile_cutoff=0.5
)
query_engine = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[similarity_processor, keyword_processor, optimizer]
)3.4.3 2026企业标配:稀疏+稠密混合检索融合方案
核心问题:纯向量检索容易漏召回(如专业术语、人名、产品型号),纯关键词检索缺乏语义理解能力。
LlamaIndex 2026解决方案:
python
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
# 启用混合检索
vector_store = QdrantVectorStore(
"hybrid_index",
client=client,
enable_hybrid=True,
fastembed_sparse_model="prithvida/Splade_PP_en_v1",
batch_size=20
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(docs, storage_context=storage_context)
# 混合查询
query_engine = index.as_query_engine(
similarity_top_k=5, # 稠密检索Top 5
sparse_top_k=12, # 稀疏检索Top 12
vector_store_query_mode="hybrid" # 融合模式
)融合算法:采用Reciprocal Rank Fusion(RRF)对稀疏和稠密检索结果进行融合排序,兼顾语义相关性和关键词精确匹配。
3.5 应用编排层:从问答引擎到自治智能体
3.5.1 基础问答/对话引擎能力复盘
LlamaIndex提供多种查询引擎模式:
- as_query_engine():标准问答模式
- as_chat_engine():对话模式,支持多轮记忆
- as_conversational_query_engine():对话式查询,结合上下文理解
3.5.2 2026重磅升级1:Long-Horizon长周期Document Agent体系
核心概念:Long-Horizon Agent是指能够自主运行数小时甚至数周,持续处理复杂文档任务的智能体。
LlamaIndex 2026实现:
python
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
# 定义文档处理工具
def analyze_contract_clause(clause_text: str) -> str:
# 分析合同条款的法律风险
# 实现细节...
return risk_assessment
def extract_financial_metrics(doc_path: str) -> dict:
# 提取财务报表关键指标
# 实现细节...
return metrics
# 创建长周期Agent
tools = [
FunctionTool.from_defaults(fn=analyze_contract_clause),
FunctionTool.from_defaults(fn=extract_financial_metrics),
]
agent = ReActAgent.from_tools(
tools,
llm=OpenAI(model="gpt-5.5"),
verbose=True,
max_iterations=50 # 支持长周期迭代
)
# 执行复杂任务
response = agent.chat(
"分析这份500页并购合同的所有风险条款,并提取目标公司近3年的财务指标"
)关键特性:
- 持久化任务队列:Agent可以将任务分解为子任务,持久化到队列中,支持断点续传
- 多智能体协同:多个Agent分工协作,如"解析Agent"+"分析Agent"+"审核Agent"
- 持续监控:内置监控机制,Agent运行状态可实时观测
3.5.3 2026重磅升级2:事件驱动Workflow架构
Workflow架构是LlamaIndex 2026最核心的架构革新,替代了传统的静态DAG流水线。
核心设计:
- Typed Events:每个步骤通过类型化事件通信
- Pub-Sub模式:步骤订阅特定事件类型,运行时自动路由
- 异步原生:所有步骤均为异步协程,支持高并发
python
from llama_index.core.workflow import Workflow, Event, StartEvent, StopEvent
from llama_index.core import VectorStoreIndex
class QueryEvent(Event):
query: str
class RetrieveEvent(Event):
nodes: list
class GenerateEvent(Event):
response: str
class RAGWorkflow(Workflow):
def __init__(self, index: VectorStoreIndex):
super().__init__()
self.index = index
@step
async def parse_query(self, ev: StartEvent) -> QueryEvent:
# 查询解析与改写
rewritten_query = await self.rewrite_query(ev.query)
return QueryEvent(query=rewritten_query)
@step
async def retrieve(self, ev: QueryEvent) -> RetrieveEvent:
# 混合检索
retriever = self.index.as_retriever(similarity_top_k=10)
nodes = await retriever.aretrieve(ev.query)
return RetrieveEvent(nodes=nodes)
@step
async def generate(self, ev: RetrieveEvent) -> StopEvent:
# 生成回答
response = await self.generate_response(ev.nodes)
return StopEvent(result=response)
# 运行Workflow
workflow = RAGWorkflow(index)
result = await workflow.run(query="公司2026年Q1营收是多少?")Workflow vs 传统DAG的优势:
| 特性 | 传统DAG | Workflow事件驱动 |
|---|---|---|
| 循环支持 | 不支持 | 原生支持 |
| 条件分支 | 需硬编码 | 基于事件类型自动路由 |
| 异步长任务 | 复杂实现 | 原生异步协程 |
| 熔断机制 | 需外部实现 | 内置超时、重试、错误处理 |
| 可观测性 | 日志追踪困难 | 每个事件即Span,天然可追踪 |
3.5.4 自校正检索闭环
2026年新增的自校正机制,显著降低幻觉:
python
from llama_index.core.evaluation import FaithfulnessEvaluator
class SelfCorrectingRAGWorkflow(Workflow):
@step
async def generate_with_verification(self, ev: RetrieveEvent) -> StopEvent:
# 首次生成
response = await self.generate_response(ev.nodes)
# 自校正:验证回答是否忠实于检索内容
evaluator = FaithfulnessEvaluator()
eval_result = evaluator.evaluate(response=response)
if not eval_result.passing:
# 二次检索:使用更宽泛的查询
new_nodes = await self.secondary_retrieve(response)
response = await self.generate_response(new_nodes)
return StopEvent(result=response)四、横向支撑生态(生产落地必备能力)
4.1 模型兼容层:全品类大模型+嵌入模型适配
LlamaIndex 2026的模型兼容层实现了真正的"零绑定":
LLM支持:
- 商业模型:OpenAI GPT-4o/5.5、Anthropic Claude 4、Google Gemini 3.1 Pro
- 开源模型:Llama 3、Mistral、Qwen、DeepSeek V4-Pro(通过Ollama或vLLM部署)
- 国产化模型:文心一言、通义千问、讯飞星火(通过适配器集成)
Embedding模型支持:
- 商业:OpenAI text-embedding-3、Cohere Embed
- 开源:BGE、E5、GTE、Jina Embeddings
- 多模态:CLIP(图文跨模态Embedding)
python
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 完全本地化部署
Settings.llm = Ollama(model="llama3.2", request_timeout=120.0)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-large-zh-v1.5")4.2 可观测与评测体系
4.2.1 全链路监控
LlamaIndex 2026通过OpenInference和traceAI实现全链路可观测:
python
from fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
from traceai_llama_index import LlamaIndexInstrumentor
# 注册追踪器
tracer_provider = register(
project_name="enterprise_rag",
project_type=ProjectType.OBSERVE
)
LlamaIndexInstrumentor().instrument(tracer_provider=tracer_provider)
# 每个Workflow步骤、检索调用、LLM调用都会生成OpenTelemetry Span4.2.2 幻觉检测与自动化评测
python
from fi.evals import evaluate
from fi.evals.otel import enable_auto_enrichment
enable_auto_enrichment()
# 在生成步骤中附加评测
context = "\n\n".join([n.get_content() for n in ev.nodes])
result = evaluate(
"groundedness",
output=str(response),
context=context,
model="turing_flash"
)
# 评分、原因、延迟自动附加到当前Span核心评测指标:
- 检索层:Context Relevance、Retrieval Recall、Chunk Overlap
- 生成层:Groundedness、Faithfulness、Hallucination Score、Answer Relevance
- 端到端:Task Success Rate、Rubric-based Scoring
4.3 LlamaHub生态:开箱即用模板与社区扩展
LlamaHub不仅提供数据连接器,还提供:
- 预构建Agent模板:发票处理、简历筛选、合同审查、财报分析
- 自定义工具 :通过
@tool装饰器快速创建工具 - 社区扩展:200+社区贡献的连接器、索引、检索器
五、2026企业级生产部署架构
5.1 分布式微服务分层架构
+-----------------------------------------------+
| API Gateway |
| (限流、认证、路由、负载均衡) |
+----------------------+------------------------+
|
+--------------+--------------+
| | |
v v v
+--------------+ +--------------+ +--------------+
| Data Ingest | | Retrieval | | Generation |
| Service | | Service | | Service |
| (数据摄取) | | (检索调度) | | (生成服务) |
+--------------+ +--------------+ +--------------+
| | |
v v v
+------------------------------------------------+
| Message Queue (Redis/RabbitMQ) |
| (异步削峰、任务队列) |
+------------------------------------------------+
| | |
v v v
+--------------+ +--------------+ +--------------+
| Vector DB | | Doc Store | | Cache |
| Cluster | | (Metadata) | | (Redis) |
| (Qdrant/ | | | | |
| Milvus) | | | | |
+--------------+ +--------------+ +--------------+5.2 高并发&高可用方案
| 策略 | 实现方式 | 适用场景 |
|---|---|---|
| 限流 | API Gateway层配置Rate Limiting | 防止突发流量冲垮系统 |
| 熔断 | Circuit Breaker模式,下游服务故障时快速失败 | 向量数据库、LLM服务故障时 |
| 缓存 | Redis缓存热点查询结果,TTL策略 | 高频重复查询 |
| 异步削峰 | 消息队列缓冲,Worker异步处理 | 批量文档处理、长周期Agent任务 |
| 水平扩展 | Kubernetes HPA自动扩缩容 | 万级QPS场景 |
5.3 llama-deploy:Workflow原生部署方案
llama-deploy是LlamaIndex 2026推出的Workflow生产部署工具,实现"开发即生产"。
python
from llama_deploy import deploy_workflow, WorkflowServiceConfig, ControlPlaneConfig
async def main():
await deploy_workflow(
workflow=RAGWorkflow(index),
workflow_config=WorkflowServiceConfig(
service_name="enterprise_rag",
replicas=3 # 3副本高可用
),
control_plane_config=ControlPlaneConfig(),
)
# 启动控制平面和消息队列(Redis)
# 同一Workflow代码,本地开发和生产环境无差异运行llama-deploy核心特性:
- 控制平面:注册Workflow为服务,管理状态和服务发现
- 消息队列:默认Redis,支持事件跨进程路由
- HTTP API网关:自动生成RESTful API
- 内置可观测性:与OpenTelemetry深度集成
5.4 私有化离线部署方案
对于金融、政务、医疗等敏感行业,LlamaIndex 2026支持完全私有化:
python
# 完全离线部署栈
Settings.llm = Ollama(model="qwen2-72b", base_url="http://localhost:11434")
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-large-zh-v1.5",
cache_folder="/opt/models"
)
# 本地向量数据库
client = QdrantClient(path="/opt/qdrant_storage")
# 本地文档解析(LiteParse v2)
from llama_parse import LiteParse
parser = LiteParse(model_path="/opt/liteparse_models")国产化适配:
- 支持华为昇腾、寒武纪等国产GPU
- 适配达梦、人大金仓等国产数据库
- 支持国产操作系统(麒麟、统信UOS)
六、2026核心升级亮点(差异化总结)
| 升级维度 | 旧版本 | 2026版本 | 核心价值 |
|---|---|---|---|
| 架构模式 | 静态DAG流水线 | 事件驱动Workflow | 支持循环、反思、熔断、异步长任务 |
| Agent能力 | 短时效单轮 | Long-Horizon长周期自治 | 多智能体协同,持续数小时/周 |
| 多模态 | 基础图文 | 原生多模态RAG | 图文音视频统一检索与生成 |
| 检索精度 | 纯向量检索 | 稀疏+稠密混合检索 | 解决漏召回、精度低问题 |
| 生产适配 | 单机/容器 | 微服务原生、llama-deploy | 万级QPS、零代码部署 |
| 幻觉抑制 | 无内置机制 | 自校正检索闭环 | 自动校验、二次检索、Faithfulness评测 |
| 观测体系 | 基础日志 | OpenTelemetry原生 | 全链路Span、Span-attached评测 |
七、典型落地场景(干货落地)
7.1 企业私有化知识库问答系统
场景:某大型制造企业构建内部技术文档知识库,覆盖10万+PDF手册。
架构方案:
- 数据接入:LlamaHub连接器接入SharePoint + 本地文件服务器
- 文档处理:LlamaParse v2解析复杂表格与图纸,语义分块保持技术参数完整性
- 索引构建:VectorStoreIndex + KnowledgeGraphIndex复合索引
- 检索增强:混合检索(BM25 + Dense)+ Cohere Rerank 4重排
- 部署:llama-deploy分布式部署,Qdrant集群存储
效果:检索准确率从72%提升至91%,平均延迟从1.2s降至180ms。
7.2 法务/合同/长文档智能审查与摘要
场景:律所需要对500页并购合同进行风险条款审查。
Workflow设计:
python
class ContractReviewWorkflow(Workflow):
@step
async def parse_contract(self, ev: StartEvent) -> ClauseEvent:
# 使用LlamaSplit自动分割合同章节
clauses = await self.split_clauses(ev.document)
return ClauseEvent(clauses=clauses)
@step
async def risk_analysis(self, ev: ClauseEvent) -> RiskEvent:
# 每个条款并行分析
risks = await asyncio.gather(*[
self.analyze_risk(clause) for clause in ev.clauses
])
return RiskEvent(risks=risks)
@step
async def generate_report(self, ev: RiskEvent) -> StopEvent:
# 生成结构化风险报告
report = await self.compile_report(ev.risks)
return StopEvent(result=report)7.3 多源异构数据统一智能查询
场景:金融机构需要统一查询内部数据库、研报PDF、新闻资讯。
方案:
- 结构化数据:SQLRetriever直接查询PostgreSQL
- 非结构化数据:VectorStoreIndex检索研报PDF
- 实时数据:APIRetriever获取新闻资讯
- 统一接口:RouterQueryEngine自动路由查询
7.4 行业知识图谱多跳推理应用
场景:医药企业查询"某药物的所有副作用及相互作用"。
实现:
python
from llama_index.core import KnowledgeGraphIndex
from llama_index.graph_stores.nebula import NebulaGraphStore
# 构建医药知识图谱
graph_store = NebulaGraphStore(
space_name="pharma_kg",
host="localhost",
port=9669
)
kg_index = KnowledgeGraphIndex.from_documents(
docs,
kg_triplets_extractor=LLMPathExtractor(),
graph_store=graph_store,
)
# 多跳推理查询
query_engine = kg_index.as_query_engine(
retriever_mode="multi_hop", # 启用多跳推理
similarity_top_k=3
)
response = query_engine.query(
"阿司匹林与华法林联用有哪些出血风险?"
)7.5 自动化事件驱动文档工作流
场景:保险公司理赔流程自动化,从报案到核赔全程无人值守。
Workflow设计:
- 事件触发:收到理赔申请PDF
- 文档解析:LlamaParse提取事故描述、医疗记录
- 信息核验:Agent自动查询保单数据库、医院系统
- 规则引擎:匹配理赔规则,计算赔付金额
- 人工审核:高风险案件自动转人工
- 结果通知:生成理赔决定书,邮件通知客户
八、总结与未来展望
8.1 2026版本核心价值总结
LlamaIndex 2026完成了从工具框架 到企业级AI应用底座的蜕变:
- 检索质量:稀疏+稠密混合检索、14种索引、自校正闭环,将RAG检索精度推向新高度
- 架构弹性:事件驱动Workflow替代静态DAG,支持复杂业务场景
- Agent自治:Long-Horizon Document Agent实现真正的文档自治
- 生产就绪:llama-deploy实现开发即生产,万级QPS无压力
- 生态开放:200+连接器、30+向量数据库、全品类模型适配,零绑定策略
8.2 LlamaIndex未来迭代趋势
基于2026年的技术路线,我们预判未来方向:
- 更深度自治:Agent将具备自我进化能力,根据反馈自动优化检索策略
- 更低门槛开发:可视化Workflow编排器,非技术人员也能构建复杂RAG
- 更强生产稳定性:内置混沌工程、自动故障恢复、多活容灾
- 更广多模态:视频理解、3D模型检索、音频语义搜索
8.3 开发者落地建议
如果你正在规划或升级RAG系统,建议优先适配以下架构:
- 混合检索:立即启用稀疏+稠密混合检索,解决漏召回问题
- Workflow:新系统直接采用Workflow架构,旧系统逐步迁移
- 自治Agent:对于复杂文档处理场景,引入Long-Horizon Agent
- 评测闭环:建立Faithfulness、Hallucination Score自动化评测体系
- 生产部署:采用llama-deploy,避免重复造轮子
附录:核心资源链接
- 官方文档 :LlamaIndex Docs
- GitHub仓库 :run-llama/llama_index
- LlamaHub :llamahub.ai
- ParseBench论文 :arXiv:2604.08538
- Workflow教程 :LlamaIndex Workflows
- llama-deploy文档 :Llama-Deploy Guide
结语:2026年是RAG技术从"可用"走向"好用"的关键一年。LlamaIndex通过架构革新、能力升级、生态完善,正在成为企业级AI应用的首选底座。无论你是刚开始探索RAG,还是正在寻求生产级优化方案,LlamaIndex 2026都值得你深入投入。
本文基于LlamaIndex 2026年6月最新版本撰写,部分特性可能随版本迭代有所调整,请以官方文档为准。