文章目录
- [多线程 IO:突破单线程的吞吐瓶颈](#多线程 IO:突破单线程的吞吐瓶颈)
- [客户端缓存:减少 Redis 访问](#客户端缓存:减少 Redis 访问)
-
- [Tracking 的工作模式](#Tracking 的工作模式)
- [两种 Tracking 模式](#两种 Tracking 模式)
- 适合用客户端缓存的场景
- ACL:精细化权限控制
-
- [ACL 的实践场景](#ACL 的实践场景)
- [RESP3 协议:表达力更强的协议](#RESP3 协议:表达力更强的协议)
- 其他改进
-
- [Cluster Proxy](#Cluster Proxy)
- [SSL/TLS 支持](#SSL/TLS 支持)
- 跨集群复制(CRDB)
- [升级到 6.0 的考虑](#升级到 6.0 的考虑)
- 实践建议
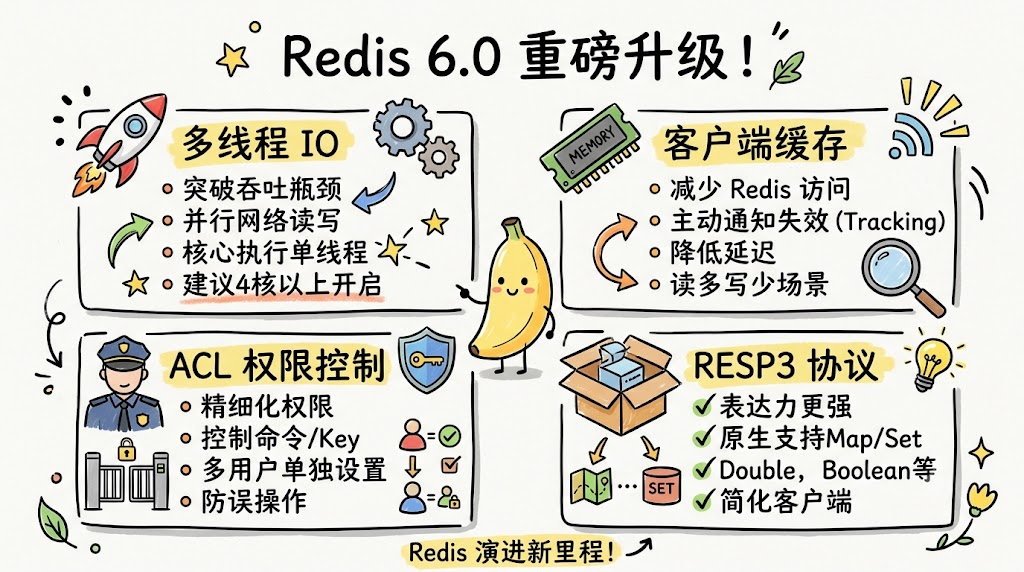
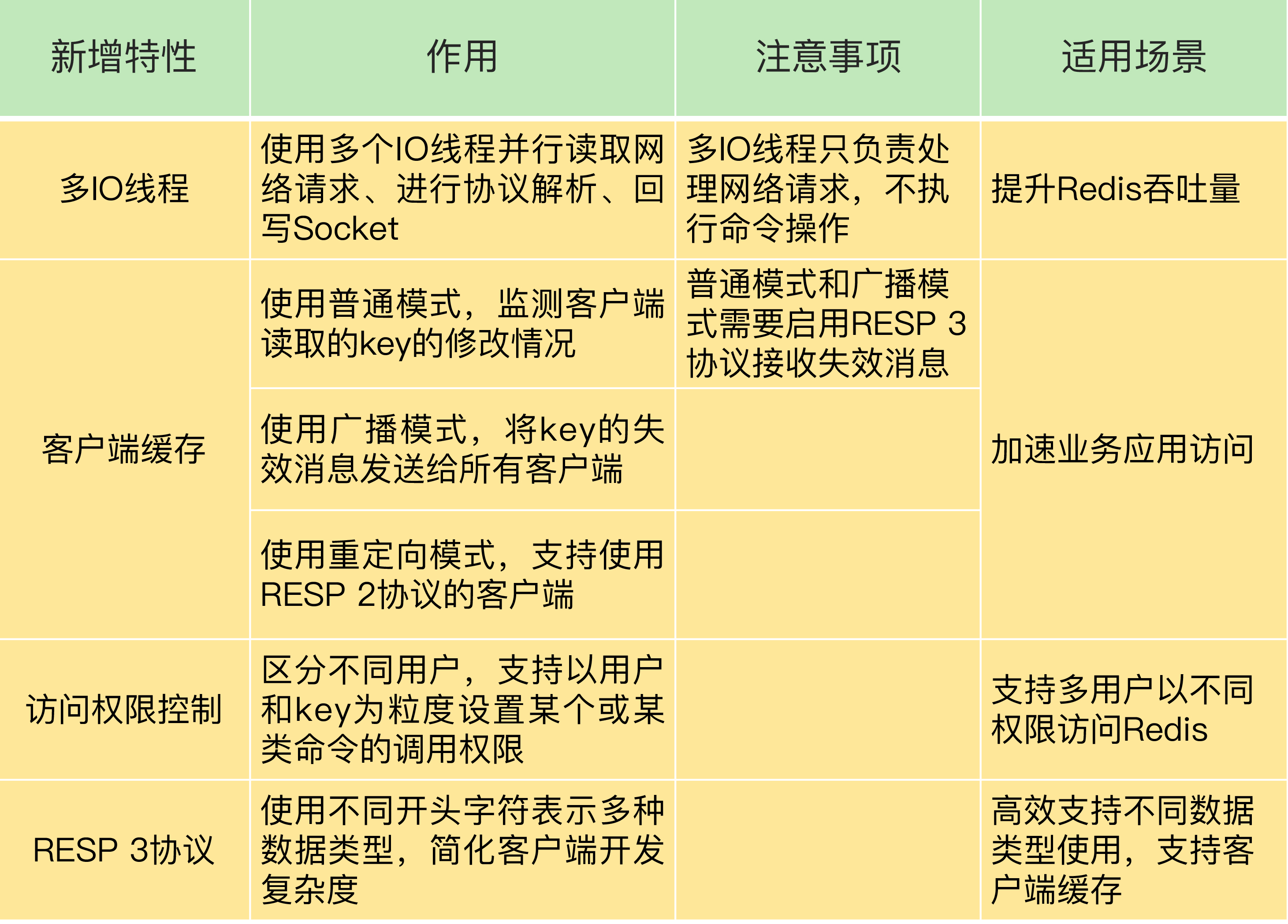
Redis 6.0 是一次相当重要的版本升级。从 1.0 一路发展到 5.x,单线程几乎是 Redis 的"招牌"。6.0 第一次在网络 IO 层引入了多线程,配合客户端缓存、ACL 权限、RESP3 协议等新特性,让 Redis 在性能、安全和易用性上都迈出了一大步。理解这些新特性背后的设计动机,能帮我们判断什么时候该升级、怎么用好它们。
多线程 IO:突破单线程的吞吐瓶颈
Redis 一直坚持单线程的核心理由是:内存访问已经够快,多线程带来的复杂度(锁、原子操作、上下文切换)反而拖慢性能。但随着网络速度的提升和客户端数量增长,单线程处理 IO 的能力开始成为瓶颈。
实测数据:单线程 Redis 在 10Gbps 网络下,QPS 在 10-20 万左右就触顶,瓶颈不在命令处理,而在网络 IO。
6.0 多线程的设计
6.0 的多线程只用在网络 IO 层:读取请求、解析协议、回写响应。命令的实际执行还是单线程。这样既享受了多线程的吞吐提升,又不破坏 Redis 的单线程心智模型。
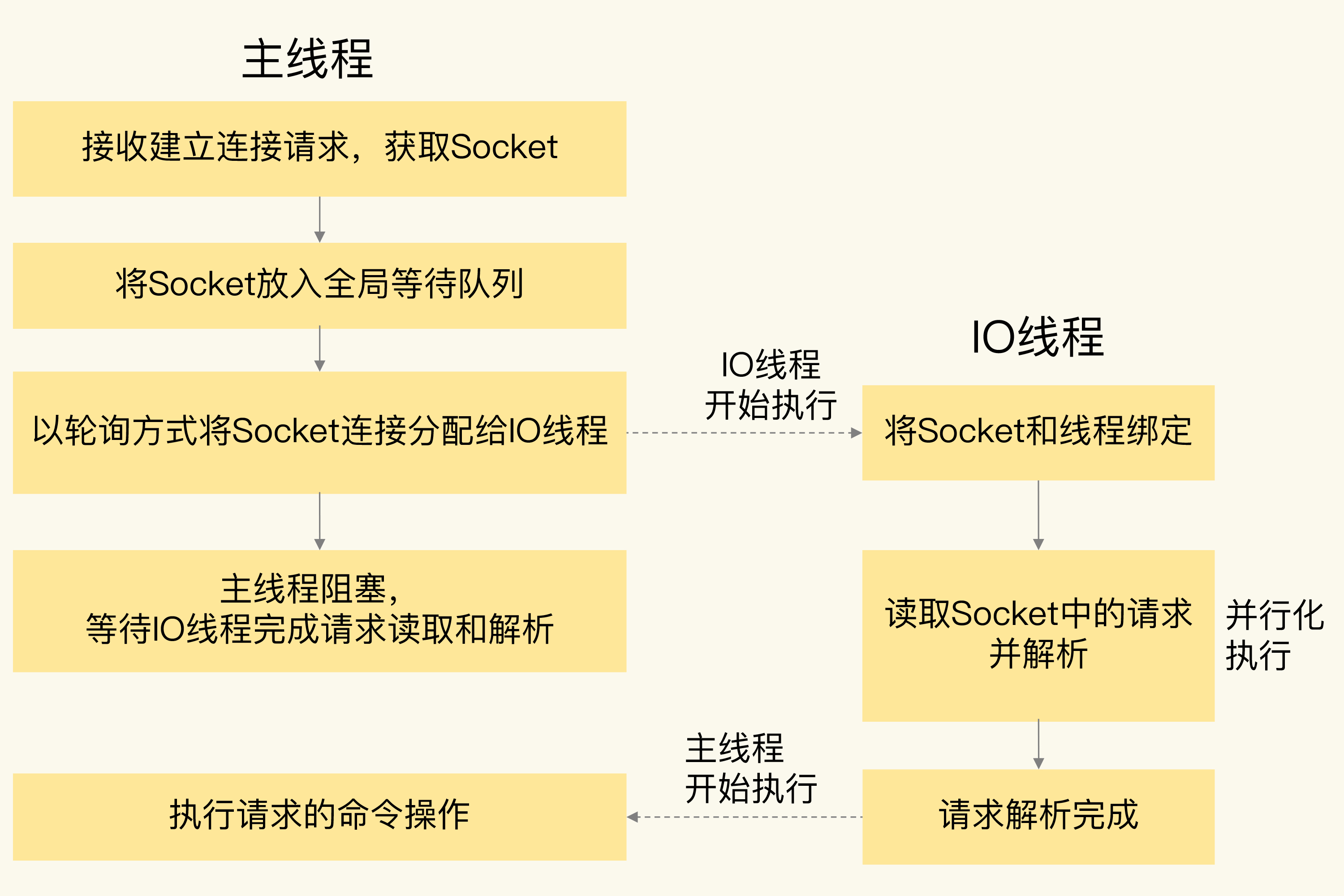
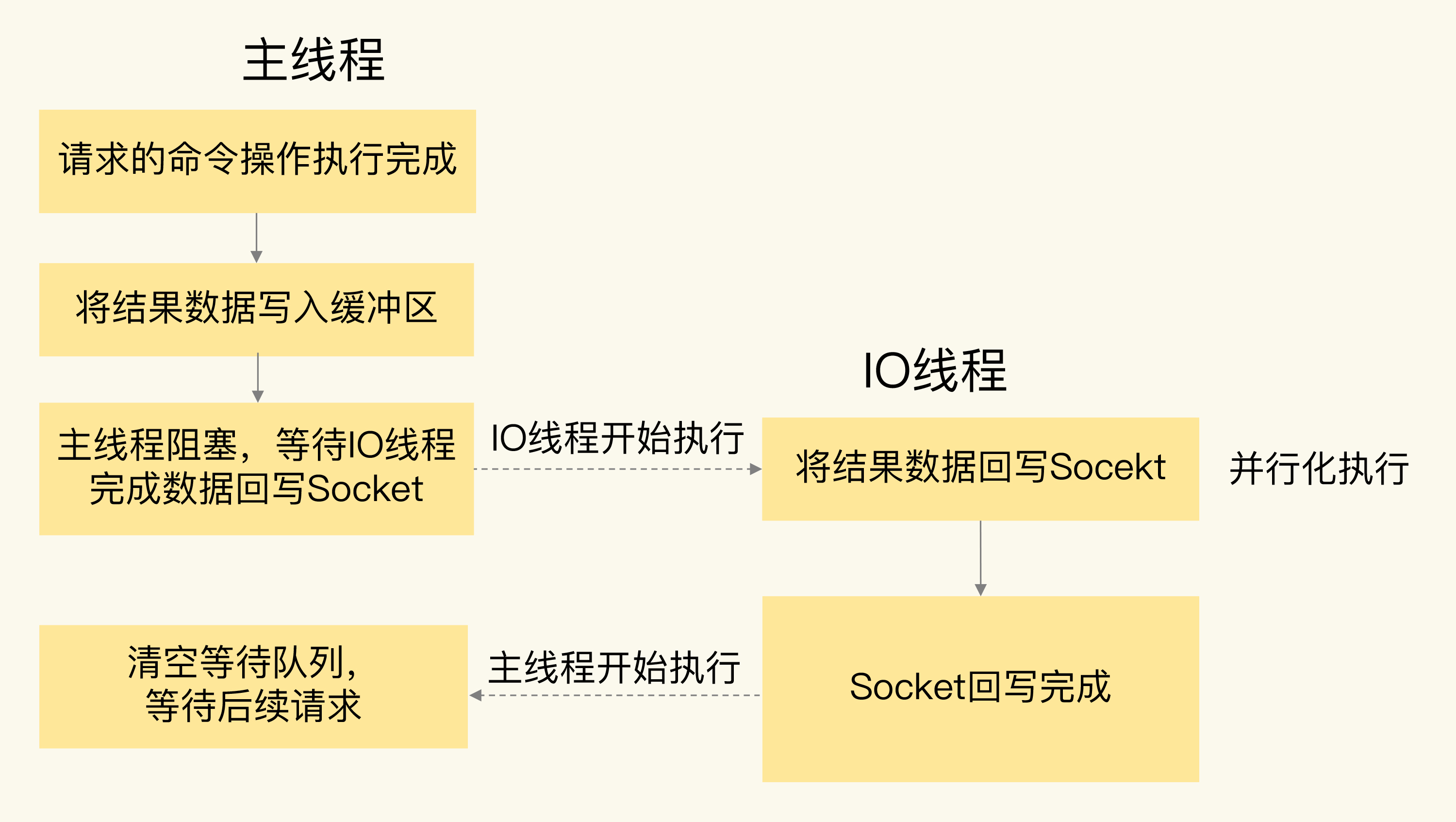
工作流程:
java
主线程:accept 连接,把就绪的客户端任务分配给 IO 线程
↓
IO 线程:并行读取请求、解析协议
↓
主线程:单线程串行执行命令
↓
IO 线程:并行回写响应
↓
主线程:清理状态主线程仍然是命令执行的"独木桥",但前后的 IO 工作被并行化了。
配置开关
conf
io-threads 4 # IO 线程数
io-threads-do-reads yes # 是否用多线程做读io-threads 一般设置为 CPU 核数的一半到核数本身。Redis 官方建议:4 核机器设 2-3,8 核设 4-6。
io-threads-do-reads 默认 no,只在写回响应时启用多线程。如果想读也并行,设为 yes。
什么时候开多线程
不是所有场景都该开。判断标准:
- 请求量大、value 小:QPS 高但单次处理快,IO 比例高,开了有明显收益。
- value 大:网络读写本身就慢,多线程能并行处理。
- 请求量小:开了反而引入线程切换开销,不划算。
- 单核机器:完全没必要。
实测一般在 4 核以上的机器,IO 密集场景,开多线程能带来 50%-100% 的吞吐提升。
客户端缓存:减少 Redis 访问
应用层做本地缓存能大幅减轻 Redis 压力,但难点在于"什么时候让本地缓存失效"。如果完全靠 TTL,要么过短失效频繁、要么过长读到旧数据。Redis 6.0 引入的 Tracking 机制解决了这个问题。
Tracking 的工作模式
服务端记住每个客户端读过哪些 key。当某个 key 被修改,服务端主动通知所有读过这个 key 的客户端"你的本地缓存过期了"。客户端收到通知后失效本地副本,下次读取重新拉。
java
CLIENT TRACKING ON
GET user:1001
# 服务端记录:客户端 X 读过 user:1001
# 另一个客户端
SET user:1001 "new value"
# 服务端推送给客户端 X
INVALIDATE user:1001两种 Tracking 模式
默认模式(精确跟踪)
服务端为每个客户端维护一份"读过哪些 key"的列表。这个列表叫 Invalidation Table,存在服务端,吃内存。
优点:精确,只通知真正读过这个 key 的客户端。
缺点:内存开销大,客户端越多、读的 key 越多,开销越大。
广播模式(Broadcast Mode)
客户端订阅特定 key 前缀,服务端不记录读取关系,key 变更时广播给所有订阅了对应前缀的客户端。
bash
CLIENT TRACKING ON BCAST PREFIX user:优点:服务端内存开销小,对前缀订阅的客户端共享通知。
缺点:客户端会收到自己没读过的 key 的失效通知,浪费一些处理开销。
适合用客户端缓存的场景
- 读多写少:变化不频繁的数据,缓存命中率高。
- 应用本地有充足内存:能放下缓存。
- 延迟敏感:避免每次 Redis 网络往返。
热点商品详情、用户配置、系统参数都是典型受益场景。
ACL:精细化权限控制
6.0 之前 Redis 只有一个全局密码(requirepass),一旦有人拿到密码就能做所有事。这在多租户、多业务共享一个 Redis 实例的场景下风险很大。
6.0 引入了 ACL(Access Control List),支持创建多个用户,每个用户可以单独设置:
- 密码
- 允许执行的命令(白名单或黑名单)
- 可以访问的 key 模式
- 可以订阅的 channel
bash
# 创建一个只读用户,只能访问 user:* 的 key
ACL SETUSER readonly_user on >password123 ~user:* +get +mget +exists -@all各部分含义:
on:启用此用户>password123:设置密码~user:*:只能访问匹配user:*的 key+get +mget +exists:允许这些命令-@all:禁止所有其他命令
ACL 的实践场景
- 微服务隔离:每个服务一个用户,只能访问自己的 key 前缀。
- 运维与开发分离:运维有完整权限,开发只能读写指定 key。
- 防止误操作 :业务用户禁用
FLUSHDB、FLUSHALL、KEYS等危险命令。
bash
# 业务用户:禁用危险命令
ACL SETUSER app on >secret ~* +@all -flushdb -flushall -keys -config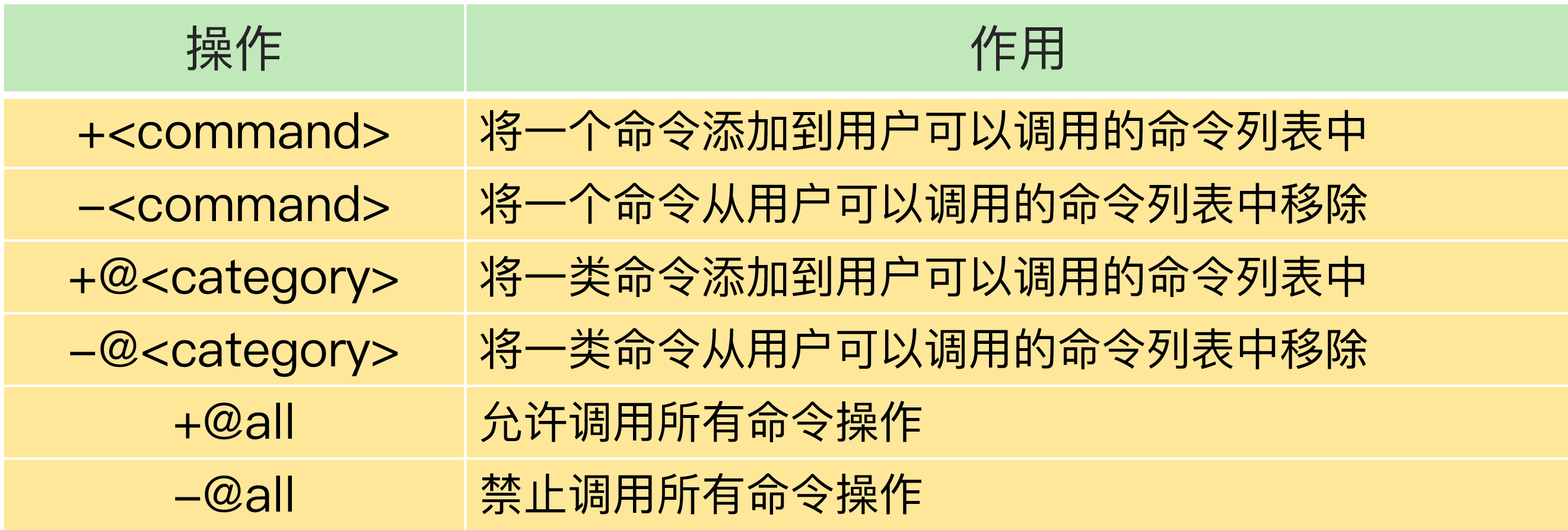
RESP3 协议:表达力更强的协议
RESP(Redis Serialization Protocol)从 1.0 用到 5.x,简单文本格式。但它的表达力有限------比如返回值只能是 String、Array、Number 这几种基础类型,复杂结构要在客户端解析。
RESP3 引入了更多原生类型:
- Map(键值对)
- Set
- Boolean
- Double
- Big Number
- Null
- Verbatim string(带格式的字符串)
这让 Redis 能直接返回结构化数据,客户端不用再做二次组装。
但 RESP3 是可选的,要客户端主动协商:
bash
HELLO 3老客户端继续用 RESP2,新客户端可以用 RESP3 享受更好的表达力。
其他改进
Cluster Proxy
6.0 后期版本提供了集群代理,让客户端不需要 Smart Client 就能访问 Cluster。这降低了 Cluster 的接入门槛。
SSL/TLS 支持
可以为 Redis 启用 TLS 加密通信,公网部署、跨机房部署时有用。
跨集群复制(CRDB)
商业版本提供,开源版本暂无。但社区已有讨论,未来值得关注。
升级到 6.0 的考虑
兼容性
6.0 在协议和命令层基本兼容 5.x,老应用可以平滑升级。但有几个点要注意:
- 配置文件多了一些新选项。
- 默认行为有些微调(比如
protected-mode)。 - 模块兼容性需要测试。
性能影响
不开新特性的情况下,6.0 的性能和 5.x 相当或略好。开了多线程 IO 后,QPS 有显著提升。
风险与回退
任何主版本升级都有风险,建议:
- 先在测试环境跑足够长的时间。
- 灰度上线,先在非核心业务试用。
- 准备好回退方案(5.x 的备份)。
实践建议
- 新项目直接上 6.x 或 7.x,享受新特性带来的红利。
- 多线程 IO 在 4 核以上才开,小机器开了反而慢。
- 客户端缓存选择广播模式,对服务端内存友好。
- 必用 ACL:哪怕是单用户场景,禁用危险命令也很值。
- 关注 RESP3 客户端支持情况,主流语言的客户端库都已支持。
- 持续关注 7.x 新特性:Function、Sharded Pub/Sub 等都是值得了解的演进方向。
Redis 6.0 标志着 Redis 从"简单 KV 存储"向"企业级数据平台"演进的转折点。多线程突破吞吐天花板、客户端缓存重新定义性能上限、ACL 提供安全保障------这些特性合在一起,让 Redis 能胜任更广泛、更严格的生产场景。
