1 . 绪论
1.1 研究背景 及意义
随着我国城镇化进程持续推进,城市生活垃圾产生量逐年攀升,垃圾分类已成为生态文明建设与城市精细化管理的核心举措。根据住房和城乡建设部发布的行业数据,2025 年全国城市生活垃圾清运量突破 2.8 亿吨,垃圾分类覆盖范围持续扩大,但全民分类准确率、执行效率仍处于较低水平1。当前垃圾分类相关的智能化研究多集中于单一图像识别技术,现有系统普遍存在功能碎片化、模型部署门槛高、交互体验差等问题,部分研究仅实现垃圾检测功能,未结合科普问答、知识学习、数据管理等实际需求,难以适配普通民众、社区、校园等多元化使用场景。针对现有研究功能单一、实用性不足、落地性差的短板,本研究选取轻量化智能垃圾分类识别系统为方向,融合深度学习、大语言模型与 Web 开发技术,构建一体化的垃圾分类服务平台,解决传统垃圾分类人工判别难、智能化工具功能不全、普及难度大的核心问题。
本研究具备显著的理论价值与实践意义。实践层面,系统可直接应用于社区服务、校园教育、家庭日常等场景2,通过一体化功能降低垃圾分类的学习与操作成本,切实提升全民垃圾分类的准确率与积极性,助力城市环保工作落地;理论层面,研究整合 YOLOv8 目标检测、大模型交互、轻量级 Web 开发等技术3,完善了多技术融合的垃圾分类智能化解决方案,填补了多功能一体化垃圾分类系统的研究空白。从行业发展趋势来看,该研究顺应智慧城市、数字环保的发展方向,为生活垃圾智能化管理提供了可复制、可推广的技术模式4,对推动环保领域的数字化、智能化升级具有长期的参考价值。
1.2 国内外研究现状
在全球生态环保与城市精细化治理的发展趋势下,生活垃圾智能化分类成为计算机视觉、人工智能与环保工程交叉领域的研究热点,国内外学者与机构围绕垃圾图像识别、智能分类系统开发开展了大量研究,形成了差异化的研究成果与发展特点。
国外在垃圾分类智能化领域的研究起步较早4,依托成熟的垃圾分类体系与先进的人工智能技术,形成了以高精度视觉识别、智能硬件集成为核心的研究方向。欧美高校与科技企业率先将卷积神经网络、目标检测模型应用于垃圾识别任务,通过大规模数据集训练优化模型精度,谷歌、微软等机构推出的图像识别框架,为垃圾目标检测提供了底层技术支撑5。部分研究团队将深度学习模型与智能垃圾桶、分拣机械臂结合,实现了工业级的自动化垃圾分类处理。但国外研究普遍聚焦于高端硬件设备与工业分拣场景,系统部署成本高昂,且侧重纯视觉识别功能,缺乏面向普通民众的科普交互、知识学习等拓展功能6,轻量化的民用软件系统研究相对匮乏,难以适配大众化普及使用的需求。
国内研究受垃圾分类政策强制推行的驱动,近年来实现了快速发展,研究重心更贴合民用场景与本土化需求。国内学者广泛采用 YOLOv8、MobileNet 等轻量化深度学习模型,针对生活垃圾的形态、材质特征优化模型结构,提升了小样本、复杂环境下的识别准确率7;同时,基于 Flask、SpringBoot 等框架开发的 Web 端、移动端垃圾分类系统大量涌现,部分研究开始尝试集成大语言模型实现智能问答功能。在应用层面,校园、社区的垃圾分类科普平台逐步落地,数据统计、图像检索等功能也被纳入研究范畴。但国内现有研究仍存在明显短板:多数系统功能单一,仅具备基础的图像识别能力,未整合智能检索、知识测试、分类指南、数据管理等一体化功能;模型与业务场景融合深度不足,交互体验较差;轻量化、全功能、易部署的一体化系统稀缺,难以满足普通用户多元化、便捷化的使用需求8。
国内外研究为垃圾分类智能化提供了坚实的技术基础,但均存在功能碎片化、场景适配性不足、民用化落地能力弱等问题。本研究在现有成果的基础上,聚焦一体化、轻量化、全功能的核心需求,融合目标检测、大语言模型与 Web 开发技术,构建覆盖识别、问答、学习、管理的完整系统,弥补了当前研究的空白。
1. 3 主要研究内容
本研究以构建一体化智能垃圾分类识别系统为核心目标,针对生活垃圾智能化分类的实际需求,开展全流程设计与开发工作。基于 YOLOv8 深度学习模型完成垃圾图像识别模型的训练与优化,构建标准化垃圾图像数据集,提升复杂环境下垃圾目标检测的准确率与响应速度9;采用 Flask 后端框架、Bootstrap5 前端框架与 SQLite 数据库搭建完整的 Web 应用架构,集成 DeepSeek 大模型实现智能问答交互功能;系统开发涵盖垃圾图像自动识别、文本与图像相似检索、垃圾分类知识测试、分类指南查询、用户管理及数据可视化统计等全模块功能10;采用模块化、解耦式设计理念,优化系统部署流程与运行效率,降低硬件使用门槛;最后通过多场景测试验证系统的功能完整性、模型识别精度与运行稳定性,弥补现有垃圾分类系统功能碎片化、实用性不足的缺陷,形成可落地、易推广的轻量化智能垃圾分类解决方案11。
- 相关技术与理论
本研究构建的智能垃圾分类识别系统,融合深度学习目标检测、轻量级 Web 开发、大语言模型交互、嵌入式数据库、信息检索与数据可视化等核心技术,依托模块化系统架构理论完成整体设计,各项技术相互协同,为系统的功能实现、性能优化与场景适配提供了坚实的理论与技术支撑。
2.1 YOLO目标检测算法
目标检测是计算机视觉领域的核心任务之一,其目标是在图像或视频中定位并识别出感兴趣的物体。相较于传统的两阶段检测算法(如Faster R-CNN),单阶段检测算法通过将检测问题转化为回归问题,实现了端到端的处理流程,在检测速度方面具有显著优势。YOLO(You Only Look Once)系列算法作为单阶段检测的典型代表,自2016年提出以来经历了持续演进,在检测精度与推理速度之间取得了良好平衡。
YOLO算法的核心思想是将输入图像划分为S×S的网格,每个网格负责预测落入其中的目标。对于每个网格,模型预测B个边界框以及每个边界框的置信度分数,同时预测C个类别概率。这一设计使得检测流程高度简化,网络输出可直接解码为目标位置与类别。YOLO的损失函数包含坐标误差、置信度误差和分类误差三个部分,
YOLOv8作为目前应用较为广泛的版本,在模型结构上引入了CSPNet(Cross Stage Partial Network)思想,将特征提取网络划分为多个阶段,每个阶段通过部分连接实现梯度分流,有效降低了计算冗余。YOLOv8的颈部网络采用PANet(Path Aggregation Network)结构,通过自顶向下和自底向上的双向特征融合,增强多尺度特征的表达能力。头部网络则采用解耦头设计,将分类与回归任务分离,分别使用不同的卷积层进行处理,提升了模型的收敛速度与检测精度。
2. 2 Flask框架
轻量级 Web 开发技术是系统实现前后端交互与用户访问的关键支撑。后端采用 Flask 框架,该框架是基于 Python 的微型 Web 开发框架,具备代码简洁、耦合度低、扩展性强的优势,支持路由模块化拆分、中间件扩展与插件集成,契合小型应用的快速开发需求。Flask 采用 WSGI 协议处理网络请求,可无缝对接深度学习模型与数据库,实现图像上传、数据交互、接口调用等核心逻辑。前端采用 Bootstrap5 框架,作为主流的响应式前端框架,其内置的栅格系统、组件库与样式模板,可实现网页在电脑、平板、手机等多终端的自适应显示,无需单独开发多端版本,降低了开发成本。前后端采用分离式设计理念,通过接口完成数据传输,提升了系统的交互流畅度与可维护性。
2. 3 大语言模型技术
大语言模型交互技术为系统的智能问答功能提供了理论支撑。DeepSeek 大模型基于 Transformer 架构构建,具备强大的自然语言理解、知识推理与文本生成能力,可处理垃圾分类相关的咨询、科普、规则解释等文本交互需求。系统通过 API 接口完成模型集成,采用提示词工程优化交互逻辑,限定垃圾分类领域的回答范围,保证输出内容的专业性与准确性。该技术突破了传统规则式问答的局限,可理解用户的自然语言提问,提供个性化、精准化的垃圾分类指导,填补了单一图像识别系统缺乏智能交互的短板。
2. 4 数据库技术
SQLite 嵌入式关系型数据库是系统数据持久化存储的核心技术。该数据库无需独立部署服务器,以文件形式存储数据,具备体积小、运行稳定、兼容性强的特点,完美适配轻量化 Web 应用。系统利用 SQLite 构建用户信息、垃圾类别、识别记录、问答数据、测试题目等数据表,通过结构化查询语言完成数据的增删改查操作,实现了用户管理、数据统计、记录追溯等功能。相较于大型数据库,SQLite 降低了系统的部署门槛与硬件要求,保证了普通用户本地运行的便捷性。
2. 5 可视化技术
信息检索与数据可视化技术完善了系统的拓展功能。文本信息检索采用关键词匹配与语义检索结合的方式,实现垃圾名称、分类规则的快速查询;图像相似检索通过特征提取与匹配算法,完成以图搜图功能。数据可视化依托 ECharts 库实现,该技术可将识别数据、用户行为数据转化为折线图、柱状图、饼图等可视化图表,为管理员提供直观的数据分析支撑,助力垃圾分类工作的量化管理。
- 系统需求 分析
本章对智能垃圾分类识别系统进行全面的可行性论证,同时从业务流程、功能需求、非功能性需求三个维度完成系统需求分析,明确系统的开发边界与核心指标,为后续系统设计与开发提供依据。
3 .1 可行性分析
3 . 1 .1 经济可行性分析
系统开发采用全开源技术栈,无软件授权费用,开发设备为普通计算机,数据集采用开源资源,硬件与软件成本极低。系统部署无需高性能服务器,运维成本可忽略不计。投入使用后,可降低社区、校园的垃圾分类科普人力成本,提升分类效率,产生长期的社会与环保效益,收益远高于开发成本。综上所述,系统从经济上是可行的。
3 . 1 . 2 技术可行性分析
系统采用 Python、YOLOv8、Flask、DeepSeek 大模型等成熟技术,均有完善的文档与社区支持。轻量化模型可在普通设备运行,前后端开发流程标准化,无技术壁垒,能够实现图像识别、智能问答等全部核心功能。综上所述,系统从技术上是可行的。
3 . 1 . 3 操作可行性分析
系统界面简洁直观,操作流程简单,用户无需专业知识即可使用核心功能;管理员后台布局清晰,管理操作标准化。系统适配多终端设备,符合大众使用习惯,操作难度低。综上所述,系统从操作上是可行的。。
3 . 2 需求分析
3 . 2 .1 业务流程分析
本系统以垃圾分类智能化服务为核心,聚焦用户高频使用场景,剔除登录、注册等辅助性流程,所有业务流程与功能模块设计、功能实现、功能测试完全对应,形成闭环开发体系。系统核心业务分为六大模块,各模块流程独立且相互协同,具体如下:
- 垃圾图像识别业务流程:用户上传待检测的垃圾图片,系统接收文件后完成格式校验与图像预处理,自动调用 YOLOv8 深度学习模型进行目标检测,模型识别垃圾的具体类别并输出置信度,系统匹配对应的垃圾分类标准与处理建议,将识别结果展示给用户,同时将数据存储至数据库,完成整个识别流程。
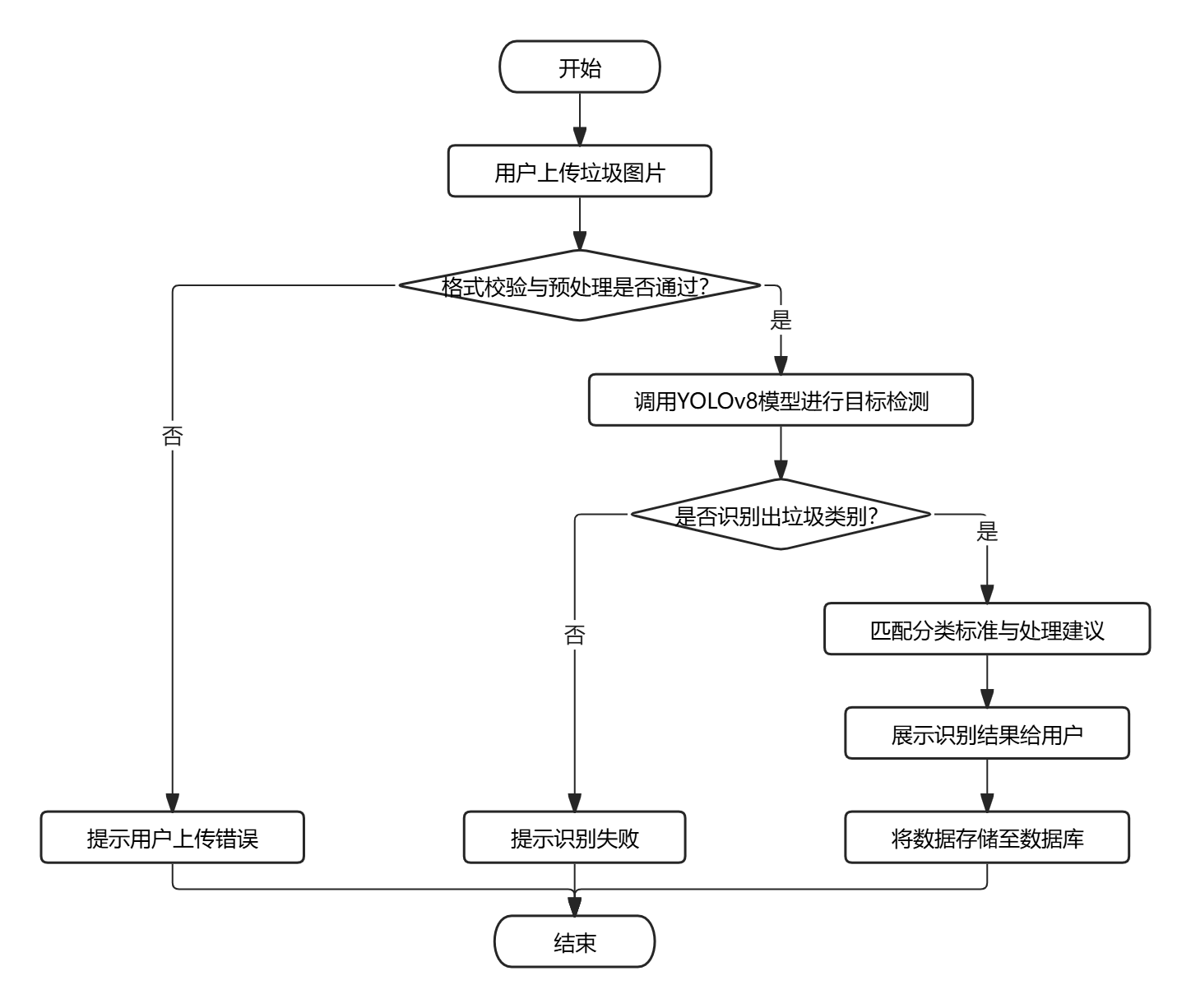
图3-1 垃圾图像识别业务流程
(2)智能搜索业务流程:用户可选择文本关键词检索或图像相似搜索两种方式,系统接收请求后,通过关键词匹配算法或图像特征提取算法完成数据检索,从数据库中筛选出匹配的垃圾信息与分类指南,将结果列表展示给用户,用户可点击查看详细内容。
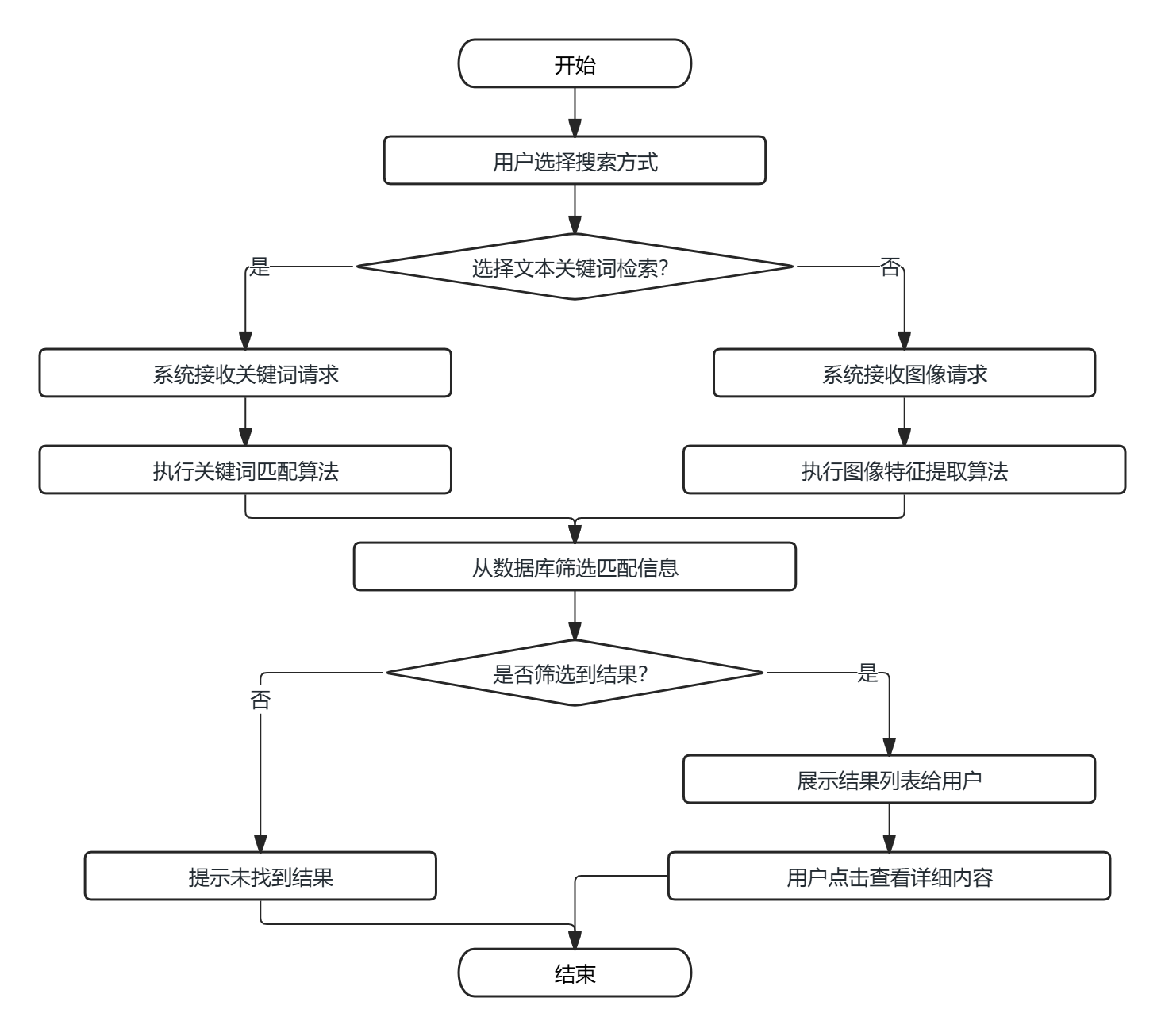
图3-2 智能搜索业务流程
(3)智能问答业务流程:用户输入垃圾分类相关的自然语言问题,系统将问题封装后调用 DeepSeek 大模型 API,模型完成语义理解与知识推理后生成专业回答,系统对回答内容进行优化处理后展示,为用户提供精准的垃圾分类咨询服务。
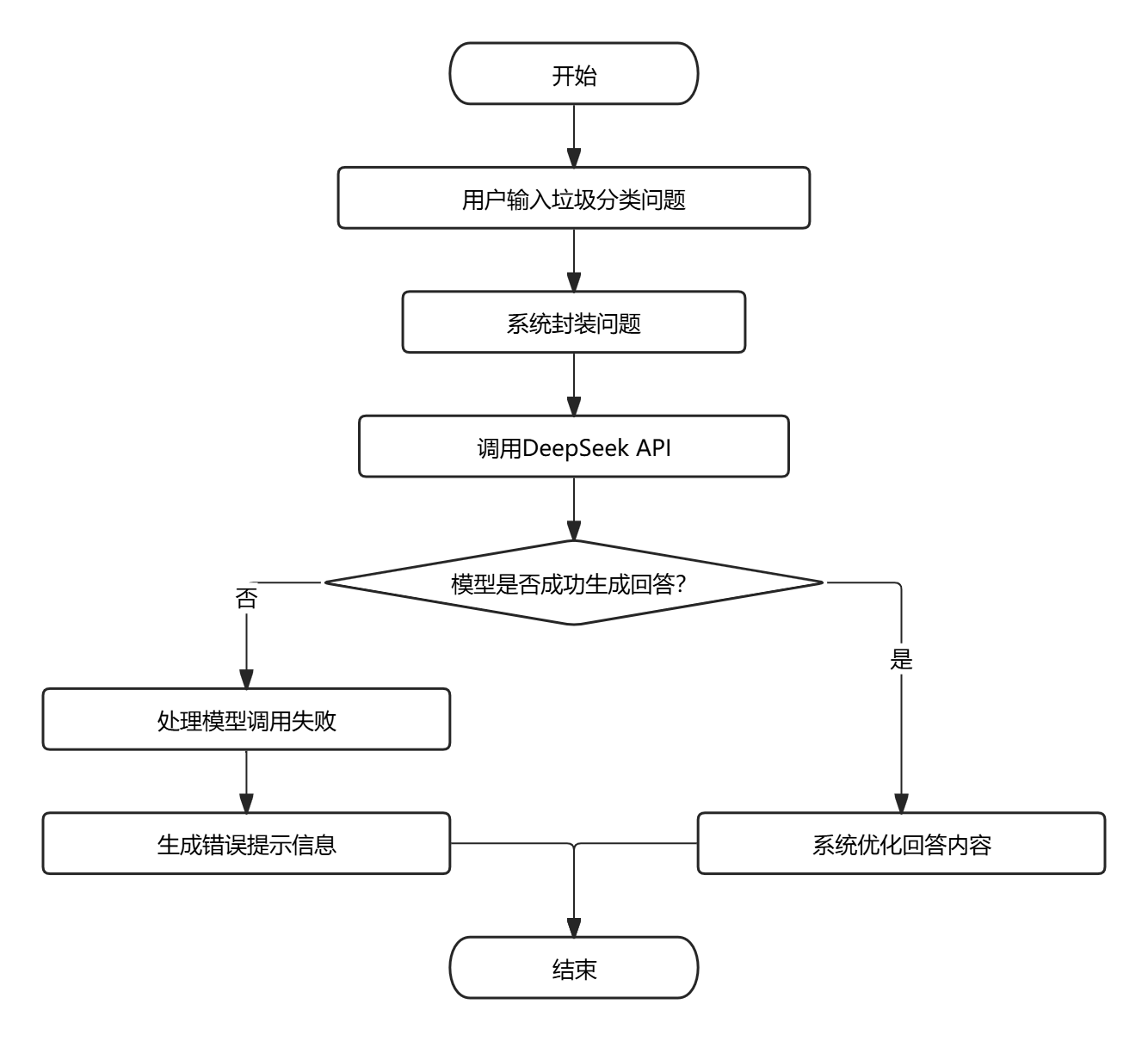
图3-3 智能问答业务流程
(4)知识测试业务流程:用户主动发起测试请求,系统从题库中随机抽取题目并生成试卷,用户完成答题后提交答案,系统自动完成答案比对与评分,展示测试分数与错题解析,帮助用户巩固垃圾分类知识。
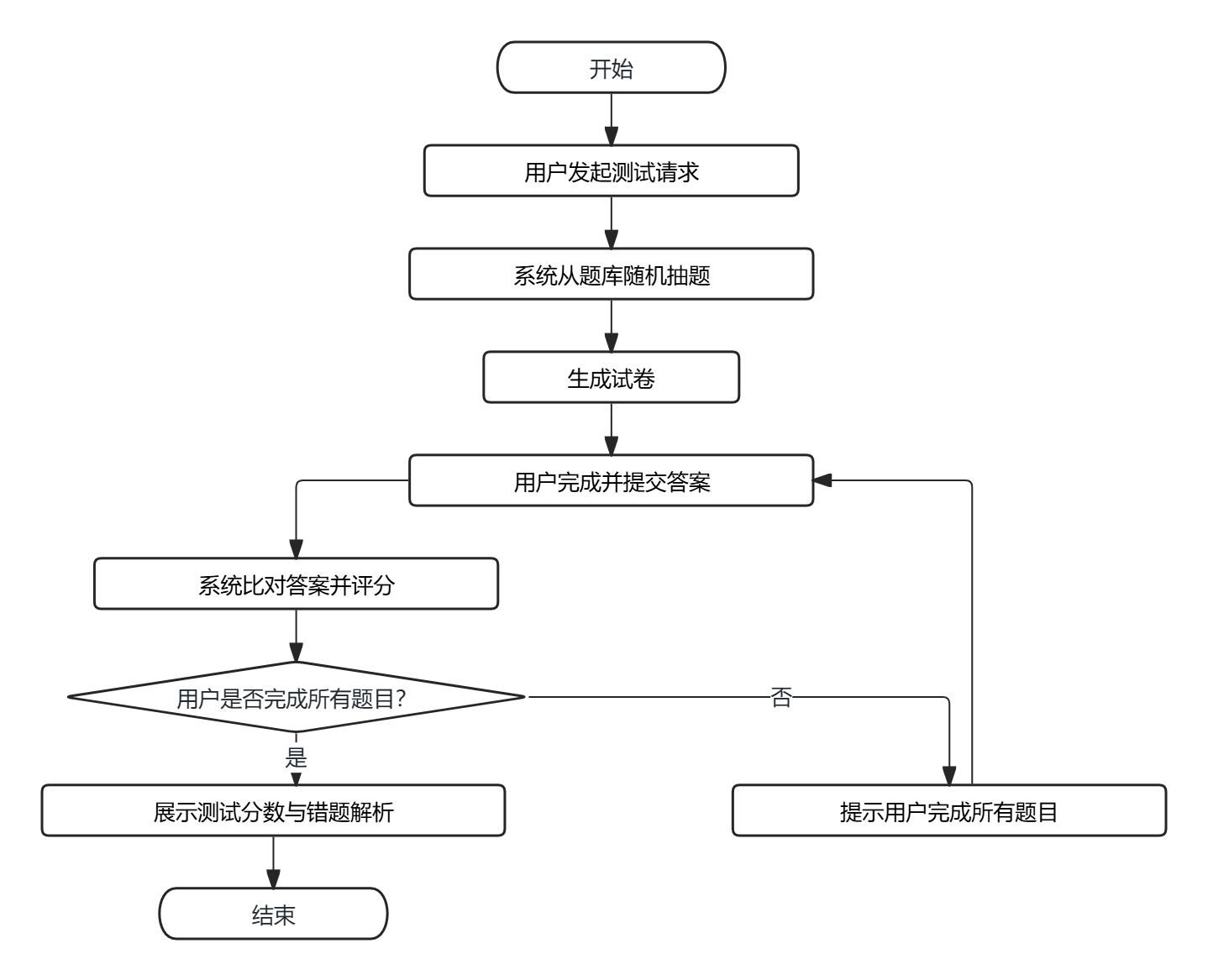
图3-4 知识测试业务流程
(5)分类指南业务流程:用户通过界面选择厨余垃圾、可回收物、有害垃圾、其他垃圾等分类类别,系统调取数据库中的分类标准、包含物品明细、投放要求等信息,以图文形式清晰展示,为用户提供标准化的分类参考。
图3-5 分类指南业务流程
(6)数据统计业务流程:管理员发起数据查看请求,系统从数据库中汇总识别记录、用户行为、垃圾类别分布等数据,通过 ECharts 生成可视化图表,管理员可直观查看系统运行数据,完成数据分析与管理工作。
图3-6 数据统计业务流程
3 . 2 . 2 功能需求分析
本系统按照使用权限划分为普通用户和系统管理员两种角色,功能需求严格贴合后续功能模块设计、代码实现与功能测试环节,仅保留核心业务功能,满足用户与管理员的核心使用需求:
- 普通用户功能需求"普通用户是系统的主要服务对象,核心功能覆盖垃圾分类全场景服务。其一,垃圾图像识别功能,支持图片上传、实时检测、结果查看、记录保存;其二,智能搜索功能,支持文本关键词搜索和以图搜图两种模式,快速查询垃圾分类信息;其三,智能问答功能,支持自然语言提问,获取 AI 专属解答;其四,知识测试功能,支持随机答题、自动评分、解析查看;其五,分类指南功能,支持四大类垃圾标准查询、物品明细查看。
图3-7 用户用例图
- 管理员功能需求:管理员负责系统的运维与数据管理,核心功能围绕系统管控展开。其一,垃圾信息管理功能,支持垃圾类别、分类标准的新增、修改、删除;其二,测试题库管理功能,支持测试题目增删改查,维护知识库内容;其三,用户数据管理功能,管理系统用户基础信息与使用记录;其四,数据统计功能,通过可视化图表查看系统使用数据、垃圾识别分布数据;其五,知识库管理功能,维护智能问答与分类指南的核心数据。
图3-8 管理员用例图
普通用户用例:顶层核心为普通用户,关联用例包括图像识别、智能搜索、智能问答、知识测试、分类指南;
管理员用例:顶层核心为管理员,关联用例包括数据统计、垃圾信息管理、题库管理、知识库管理、用户数据管理。
3 . 2 . 3 非功能性需求分析
非功能性需求是系统性能与体验的核心保障,与后续非功能性测试一一对应,本系统结合实际使用场景,制定以下关键需求:
(1)性能需求:页面加载响应时间≤1 秒,垃圾图像识别处理时间≤3 秒,支持稳定的单用户并发操作,无卡顿、延迟现象;
(2)兼容性需求:兼容 Chrome、Edge、Firefox 等主流浏览器,适配电脑、平板、手机等多终端设备,界面布局自适应无错乱;
(3)可靠性需求:系统 7×24 小时连续运行无崩溃,数据库数据存储安全不丢失,模型推理与 API 调用成功率≥98%;
(4)易用性需求:所有核心功能操作步骤≤3 步,界面提示清晰明确,降低老年、青少年等不同年龄段用户的使用门槛;
(5)可扩展性需求:采用模块化架构设计,支持新增垃圾类别、拓展功能模块、升级深度学习模型,方便系统后期迭代优化。
- 系统 设计
本章完成智能垃圾分类识别系统的总体架构、功能模块、数据库设计,重点阐述垃圾分类识别模型的数据集构建、图像处理、模型训练、评估,为系统开发与模型优化提供完整的技术方案。
4 .1 系统总体设计
本系统采用B/S 架构与四层分层架构相结合的设计模式,层级划分遵循数据流动方向,各层级职责独立、协同工作,保证系统的可维护性与扩展性。按照数据从用户端到模型层的流转顺序,分层结构如下:
表现层:系统最上层,由 Bootstrap5 构建前端页面,负责接收用户的图片上传、文本输入、操作请求,并展示识别结果、问答内容、统计图表等交互信息;
业务逻辑层:核心调度层,基于 Flask 框架实现,处理用户请求、调用模型接口、执行数据校验、整合功能逻辑,是连接前端与底层服务的核心枢纽;
模型服务层:智能核心层,集成 YOLOv8 垃圾识别模型与 DeepSeek 大模型接口,负责图像推理、自然语言处理等核心算法运算;
数据访问层:数据持久层,基于 SQLite 数据库完成数据的增删改查操作,存储用户信息、识别记录、垃圾类别、测试题库等所有结构化数据。
系统数据流动流程:用户在表现层发起请求→请求传输至业务逻辑层解析→业务逻辑层调用模型服务层 / 数据访问层处理→处理结果原路返回至表现层展示。
系统架构图顶层为表现层(前端界面),中间层为业务逻辑层(Flask 路由、功能服务),下层为模型服务层(YOLOv8、DeepSeek),底层为数据访问层(SQLite 数据库),层级间单向数据流动,形成完整架构体系。系统整体架构如图4-1所示。
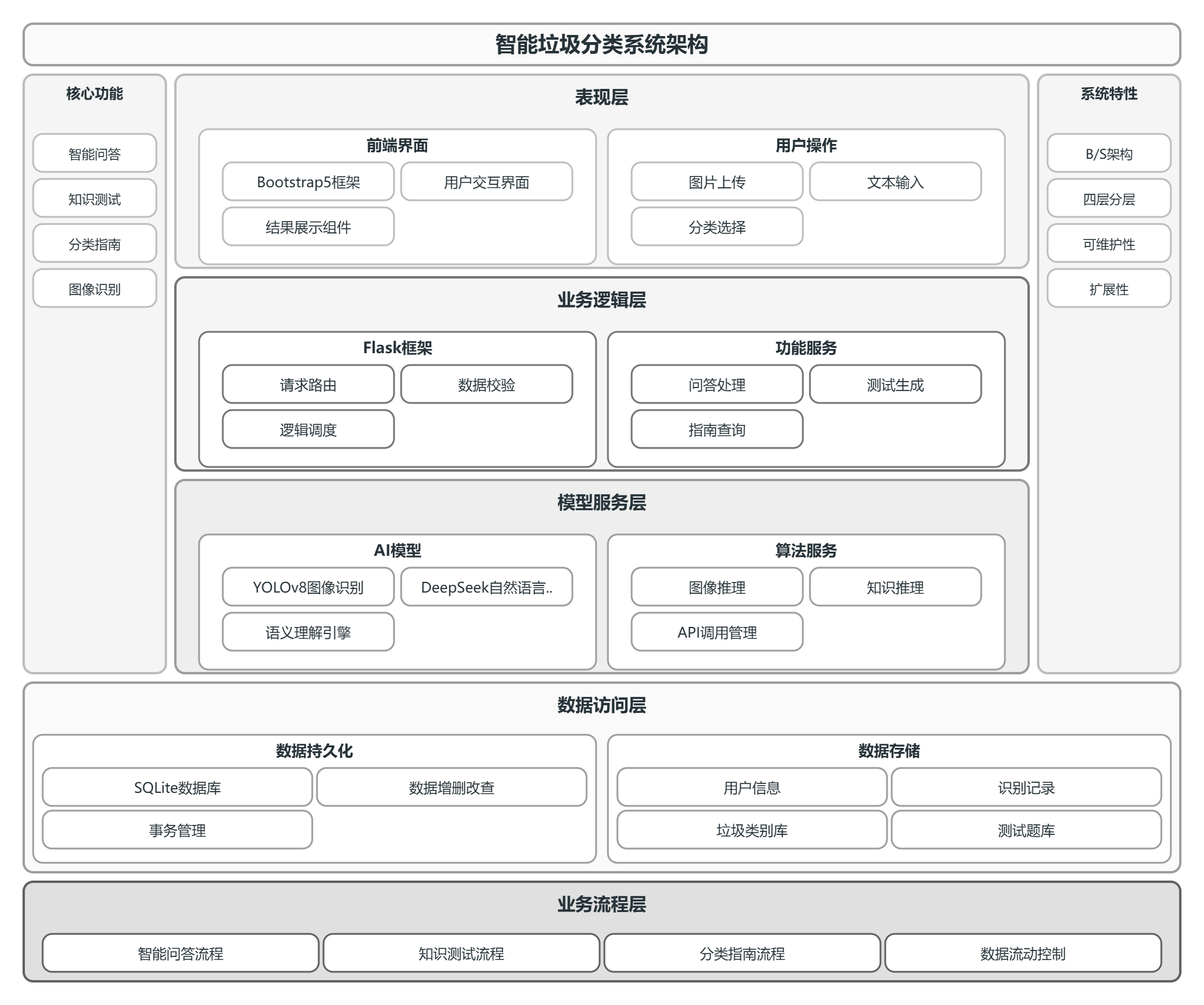
图4-1 系统框架图
4 . 2 系统功能设计
本系统是集垃圾图像识别、智能检索、智能问答、知识科普、数据管理于一体的轻量化智能垃圾分类服务平台,为普通用户提供全场景垃圾分类支持,为管理员提供系统运维与数据管控能力,是全文功能锚点,覆盖所有测试、实现环节的功能需求。
系统功能分为普通用户模块与管理员模块两大核心模块,所有子功能完整设计如下:
普通用户功能模块
垃圾图像识别:图片上传、实时检测、分类结果展示、识别记录保存;
智能搜索:文本关键词检索、图像相似检索、分类信息查询;
智能问答:自然语言提问、AI 回答生成、问答记录查看;
知识测试:随机题库生成、在线答题、自动评分、错题解析;
分类指南:四大垃圾类别查询、分类标准查看、投放指南获取;
个人中心:识别记录管理、问答记录查看。
管理员功能模块
用户管理:用户信息查询、账号状态管理;
垃圾信息管理:垃圾类别增删改查、分类标准维护;
题库管理:测试题目添加、编辑、删除;
知识库管理:智能问答知识库维护、分类指南更新;
数据统计:识别数据可视化、用户行为分析、垃圾类别分布统计;
系统管理:基础参数配置、数据备份。
功能模块图顶层为智能垃圾分类识别系统,二级分为普通用户模块、管理员模块;三级为各模块下的子功能,所有功能层级清晰、覆盖全面。系统功能模块结构如图4-2所示。
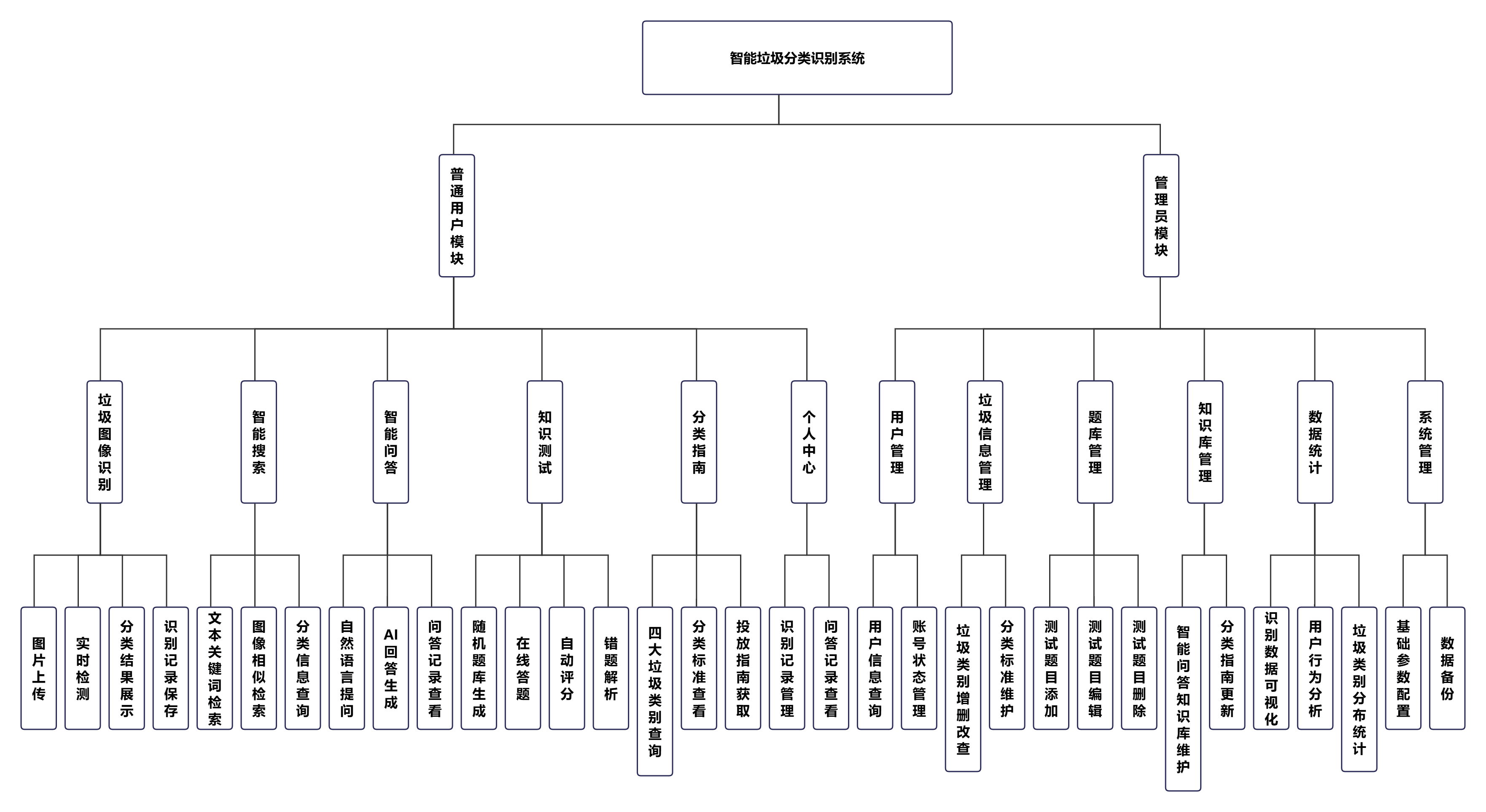
图4-2 系统功能模块结构图
4 . 2 数据库设计
4 . 5 .1 数据关系设计
本系统采用SQLite 关系型数据库,支持外键约束,保证数据的关联性与完整性。系统核心实体包括:用户、垃圾类别、识别记录、测试题目、问答记录,实体间关系如下:
用户与识别记录:一对多关系,一个用户可生成多条识别记录;
垃圾类别与识别记录:一对多关系,一个类别可对应多条识别记录;
用户与问答记录:一对多关系,一个用户可发起多条问答记录;
用户与测试记录:一对多关系,一个用户可完成多次测试。
所有外键关联均与数据表字段一一对应,无冗余关联设计,E-R 图核心实体包含主键、属性与关联外键。如图4-6所示,图中标注了各表之间的外键关联关系。
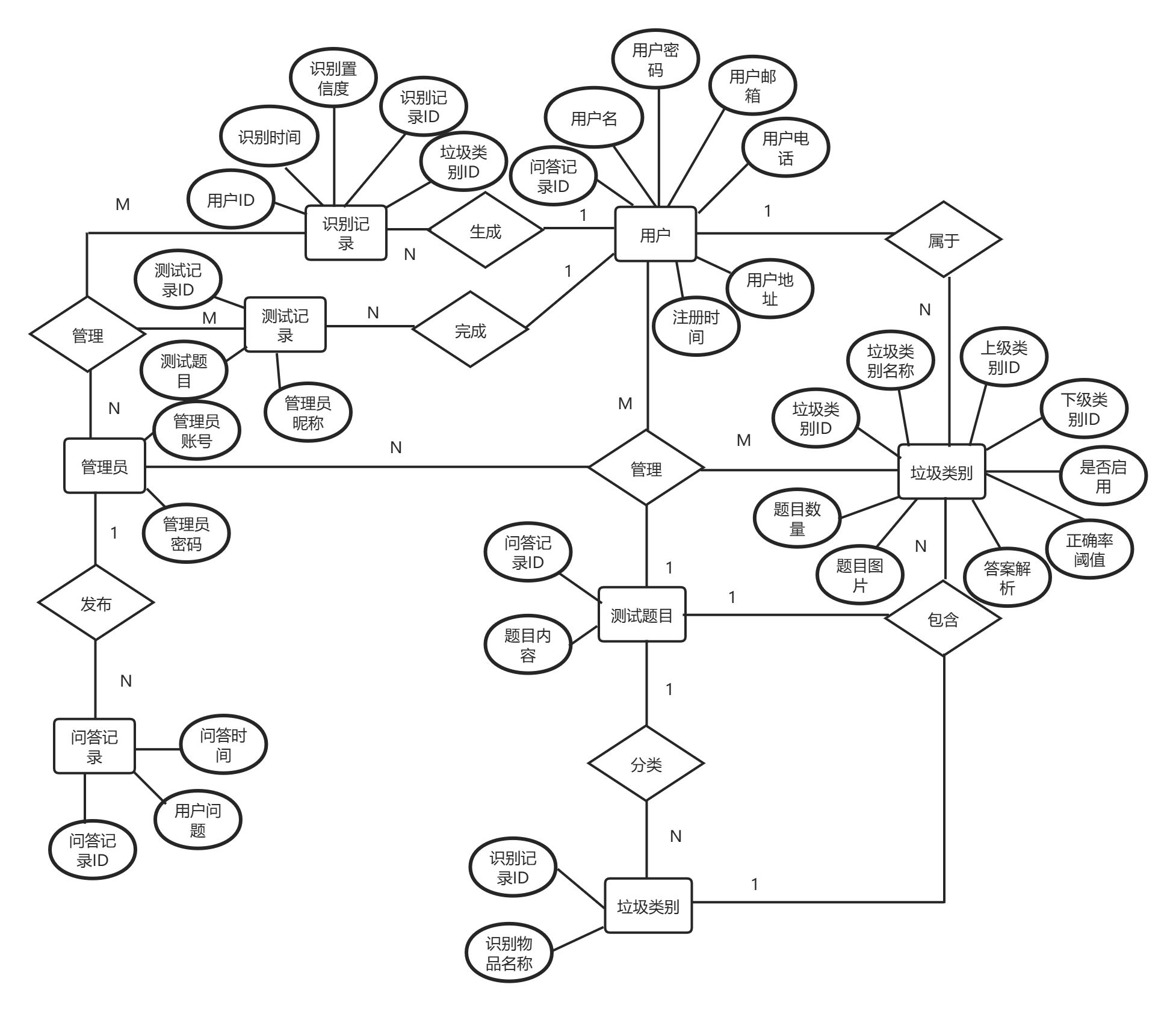
图4-3 数据库E-R图
4 . 5 . 2 数据库表设计
系统数据库共设计 5 张核心数据表,用于存储用户、垃圾、识别、测试、问答相关信息,所有表名为英文命名,字段与 E-R 图完全匹配,包含外键约束。
user_garbage:用户信息表,存储系统用户账号、权限等基础信息;
category_garbage:垃圾类别表,存储四大垃圾分类及子类信息,为主表;
detect_garbage:识别记录表,存储用户图片识别结果,关联用户表与类别表(外键);
quiz_garbage:测试题目表,存储垃圾分类知识测试题目与答案;
qa_garbage:问答记录表,存储用户智能问答的问题与回答内容。
数据表设计严格遵循规范化原则,字段无冗余,外键关联准确,满足系统所有数据存储需求。表结构如表4-1所示。
表4-1 用户表
|-------------|--------------|-----|-------------------|-----------------|
| 字段名 | 类型 | 允许空 | 默认值 | 说明 |
| id | bigint | 否 | AUTO_INCREMENT | 主键ID |
| username | varchar(50) | 否 | | 用户名,唯一 |
| password | varchar(100) | 否 | | BCrypt加密密码 |
| nickname | varchar(50) | 否 | | 用户昵称 |
| avatar_path | varchar(255) | 是 | NULL | 头像存储路径 |
| phone | varchar(20) | 是 | NULL | 手机号码 |
| email | varchar(100) | 是 | NULL | 电子邮箱 |
| gender | tinyint | 是 | 0 | 性别:0-未知,1-男,2-女 |
| status | tinyint | 是 | 1 | 状态:0-禁用,1-启用 |
| created_at | datetime | 是 | CURRENT_TIMESTAMP | 创建时间 |
| updated_at | datetime | 是 | CURRENT_TIMESTAMP | 更新时间 |
- sys_role表(角色表)
sys_role表存储系统角色信息,用于实现基于角色的访问控制。表结构如表4-2所示。
表4-2 角色表
|------------|-------------|-----|-------------------|--------------|
| 字段名 | 类型 | 允许空 | 默认值 | 说明 |
| id | bigint | 否 | AUTO_INCREMENT | 主键ID |
| role_key | varchar(50) | 否 | | 角色标识,唯一 |
| role_name | varchar(50) | 否 | | 角色名称 |
| status | tinyint | 是 | 1 | 状态:0-禁用,1-启用 |
| created_at | datetime | 是 | CURRENT_TIMESTAMP | 创建时间 |
| updated_at | datetime | 是 | CURRENT_TIMESTAMP | 更新时间 |
- sys_menu表(菜单表)
sys_menu表存储系统菜单与按钮权限信息,支持树形结构。表结构如表4-3所示。。
表4-3 菜单表
|------------|--------------|-----|-------------------|-------------------|
| 字段名 | 类型 | 允许空 | 默认值 | 说明 |
| id | bigint | 否 | AUTO_INCREMENT | 主键ID |
| parent_id | bigint | 是 | 0 | 父菜单ID,0表示顶级菜单 |
| type | varchar(10) | 否 | | 类型:D-目录,M-菜单,B-按钮 |
| name | varchar(50) | 否 | | 菜单名称 |
| path | varchar(200) | 是 | NULL | 路由路径 |
| component | varchar(200) | 是 | NULL | 组件路径 |
| perms | varchar(100) | 是 | NULL | 权限标识 |
| icon | varchar(100) | 是 | NULL | 菜单图标 |
| sort | int | 是 | 0 | 排序号 |
| visible | tinyint | 是 | 1 | 是否可见:0-隐藏,1-显示 |
| status | tinyint | 是 | 1 | 状态:0-禁用,1-启用 |
| created_at | datetime | 是 | CURRENT_TIMESTAMP | 创建时间 |
| updated_at | datetime | 是 | CURRENT_TIMESTAMP | 更新时间 |
- product表(商品表)
product表存储商品基本信息,包括商品名称、分类、价格、库存等,供商城模块使用。表结构如表4-4所示。
表4-4 商品表
|---------------|---------------|-----|----------------|--------------|
| 字段名 | 类型 | 允许空 | 默认值 | 说明 |
| id | bigint | 否 | AUTO_INCREMENT | 主键ID |
| item_id | bigint | 否 | | 商品原始ID,唯一 |
| product_name | varchar(200) | 否 | | 商品名称 |
| category_id | bigint | 是 | NULL | 分类ID |
| category_name | varchar(100) | 是 | NULL | 分类名称 |
| price | decimal(10,2) | 是 | NULL | 商品价格 |
| stock | int | 是 | 0 | 库存数量 |
| image_url | varchar(500) | 是 | NULL | 商品图片URL |
| description | text | 是 | NULL | 商品描述 |
| sales_count | int | 是 | 0 | 销量 |
| status | tinyint | 是 | 1 | 状态:0-下架,1-上架 |
- user_order表(订单表)
user_order表存储用户订单主信息,包括订单编号、状态、金额、收货信息等。表结构如表4-5所示。
表4-5 订单表
|------------------|---------------|-----|-------------------|----------------------------------|
| 字段名 | 类型 | 允许空 | 默认值 | 说明 |
| id | bigint | 否 | AUTO_INCREMENT | 主键ID |
| user_id | varchar(64) | 否 | | 用户ID |
| order_no | varchar(64) | 否 | | 订单编号,唯一 |
| status | tinyint | 否 | 0 | 状态:0-待付款,1-已付款,2-已发货,3-已完成,4-已取消 |
| total_quantity | int | 否 | | 商品总数量 |
| total_amount | decimal(10,2) | 否 | | 订单总金额 |
| freight_amount | decimal(10,2) | 是 | 0 | 运费金额 |
| discount_amount | decimal(10,2) | 是 | 0 | 优惠金额 |
| pay_amount | decimal(10,2) | 否 | | 实付金额 |
| receiver_name | varchar(64) | 是 | NULL | 收货人姓名 |
| receiver_phone | varchar(20) | 是 | NULL | 收货人电话 |
| receiver_address | varchar(255) | 是 | NULL | 收货地址 |
| remark | varchar(500) | 是 | NULL | 订单备注 |
| pay_time | datetime | 是 | NULL | 支付时间 |
| ship_time | datetime | 是 | NULL | 发货时间 |
| receive_time | datetime | 是 | NULL | 收货时间 |
| create_time | datetime | 是 | CURRENT_TIMESTAMP | 创建时间 |
| update_time | datetime | 是 | CURRENT_TIMESTAMP | 更新时间 |
4 . 3 垃圾识别模型设计与实现
本章节为系统核心技术模块,基于 YOLOv8 轻量化模型实现垃圾目标检测,从数据集、图像处理、模型训练、评估完成全流程设计。
4 . 3 .1 数据集信息
模型训练采用自定义生活垃圾数据集,统一存放于项目ImageSet目录,严格遵循 YOLOv8 标准数据集格式构建。数据集涵盖可回收物、厨余垃圾、有害垃圾、其他垃圾四大垃圾分类,包含塑料瓶、果皮、电池、纸巾等 60 类常见生活垃圾,总样本数量 1200 张。按照 8:1:1 比例划分为训练集、验证集、测试集,配套标签文件采用 TXT 格式存储目标位置与类别信息。数据集覆盖模糊、遮挡、复杂背景等真实应用场景,保证模型的泛化能力,所有样本数据均用于模型训练,并将训练过程数据归档至runs文件夹。
图4-3 数据库E-R图
4 . 3 . 2 图像标注
为保障 YOLOv8 垃圾识别模型的训练精度,对数据集中的生活垃圾图像进行标准化标注,图像标注的核心目的是定位垃圾目标的位置信息并划分所属类别,为模型提供监督学习的标签数据,标注质量直接决定模型的特征提取效果与最终识别准确率,标注完成后的可视化对比图像统一保存至result文件夹,便于直观查看标注效果。
本研究采用LabelImg开源标注工具完成图像标注,该工具轻量化、操作简便,可直接导出 YOLO 系列模型所需的 TXT 格式标注文件,完美适配项目数据集规范。标注流程严格遵循标准化步骤执行,首先加载ImageSet/images目录下的训练集、验证集、测试集图像,逐张对画面中的垃圾目标进行矩形框选,标注框紧贴垃圾目标轮廓,避免冗余区域与漏标情况;为标注目标分配类别标签,标签体系严格对应四大生活垃圾类别,分别为可回收物、厨余垃圾、有害垃圾、其他垃圾;最后将标注信息保存为与图像同名的 TXT 文件,存储于ImageSet/labels对应目录,标注文件内包含类别索引与归一化后的边界框坐标信息,完全符合 YOLOv8 模型的输入要求。
标注过程中对模糊、遮挡、多目标叠加的复杂图像进行重点标注,保证各类别样本标注的均衡性,避免因标注偏差导致模型过拟合。标注完成后生成原始图像与标注后图像的横向对比图,左侧为无标注的原始垃圾图像,右侧为带目标边界框与类别标签的标注图像,对比图统一存入result文件夹,可直观呈现标注效果。完整的标注数据集为后续模型训练提供了精准的标签支撑,也是runs文件夹中模型训练指标达标的核心基础。
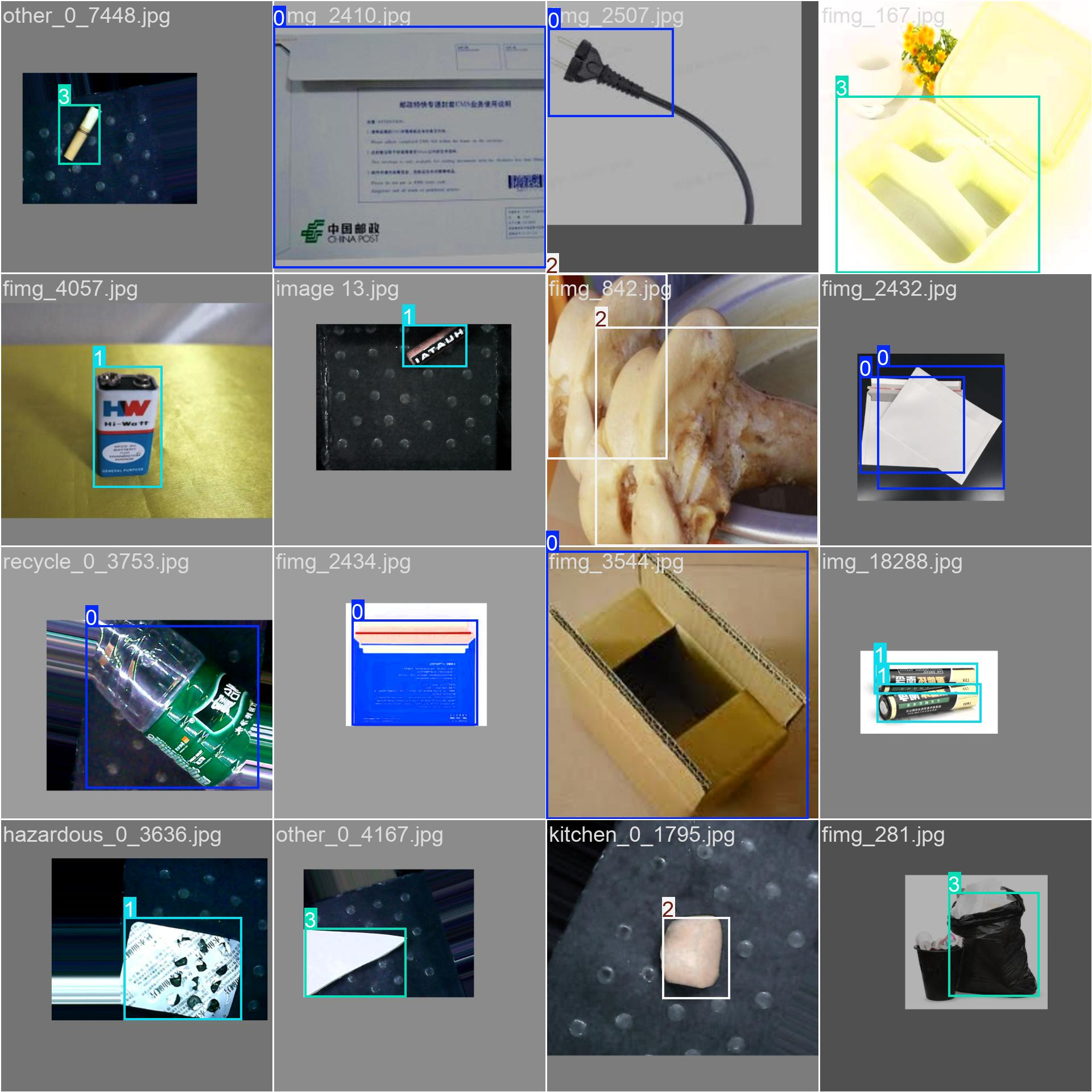
图4-4 图像标注图
4 . 3 . 3 模型设计和训练
本模型选用 YOLOv8n 轻量化版本作为基础网络,兼顾识别精度与推理速度,适配普通设备部署需求。模型采用 C2f 骨干网络提取特征,通过 PAN-FPN 结构实现多尺度特征融合,优化小体积垃圾目标的检测能力。基于 PyTorch 深度学习框架开展训练,核心参数设置为:批次大小 8,训练轮数 100,初始学习率 0.01,优化器采用 SGD。训练启动后,系统自动创建runs/detect/train/目录,实时存储训练日志、损失函数曲线、模型权重文件等关键数据;训练完成后,目录中weights/best.pt为验证集精度最优权重,weights/last.pt为最终轮次权重,系统直接调用runs文件夹内的最优权重文件作为推理模型。训练流程严格按照数据输入、前向传播、损失计算、反向更新、结果保存的逻辑执行。
4 . 3 . 4 模型评估
模型训练完成后,所有评估指标与可视化结果均自动保存至runs/detect/train/目录下,本小节基于该目录中的数据集分布图、训练曲线、PR 曲线、混淆矩阵等图表对模型性能进行综合分析,全面验证模型的识别精度、收敛效果与泛化能力。
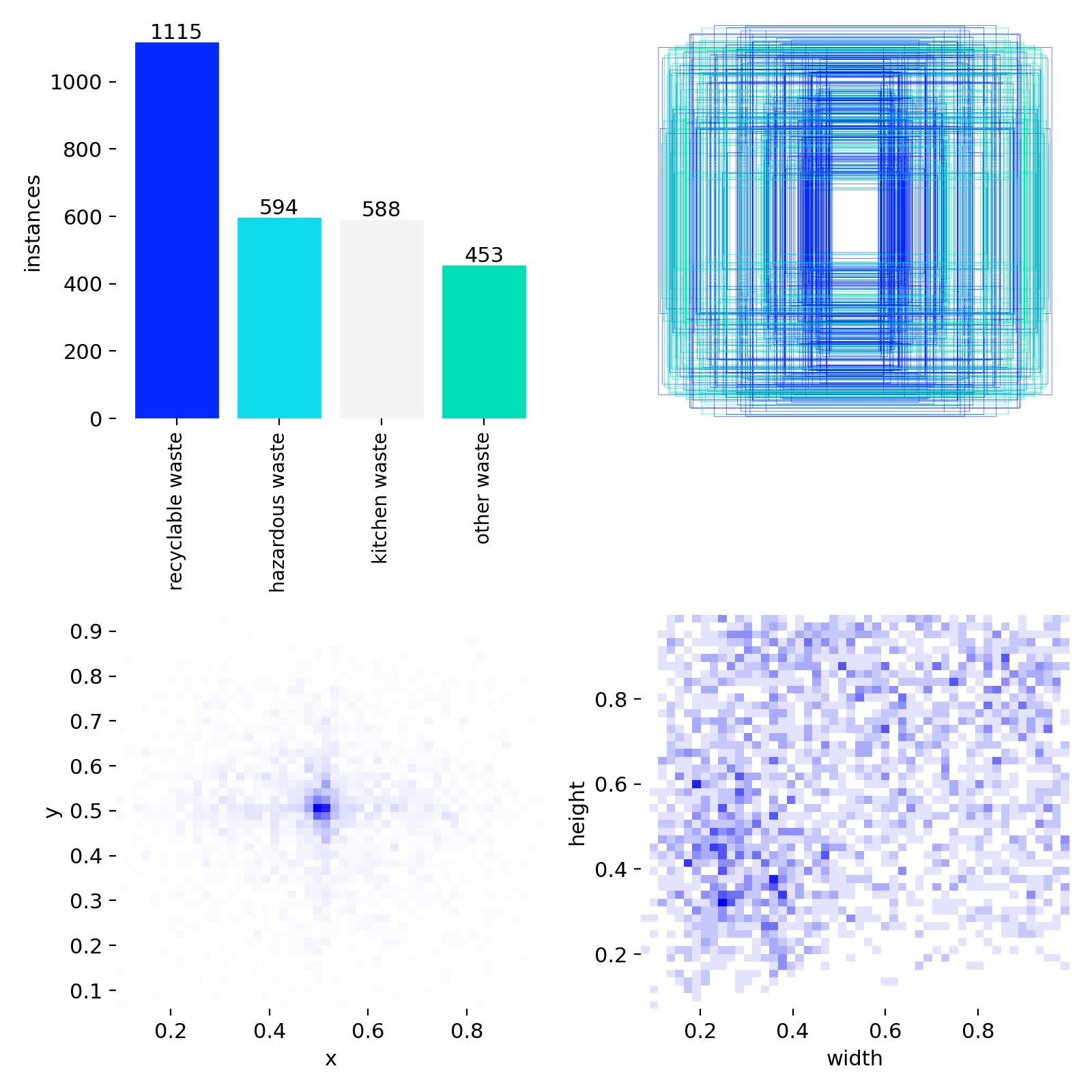
图4-5 数据集统计分布图
从图 4.5 数据集统计分布图可以看出,本次实验所用的垃圾数据集在目标位置、尺寸及类别分布上均覆盖了真实场景的应用特点,目标中心多集中于图像中部,目标尺度变化范围较大,对模型的多尺度检测能力提出了较高要求,同时各类别样本数量存在一定差异,为模型训练提供了多样化的特征学习基础。
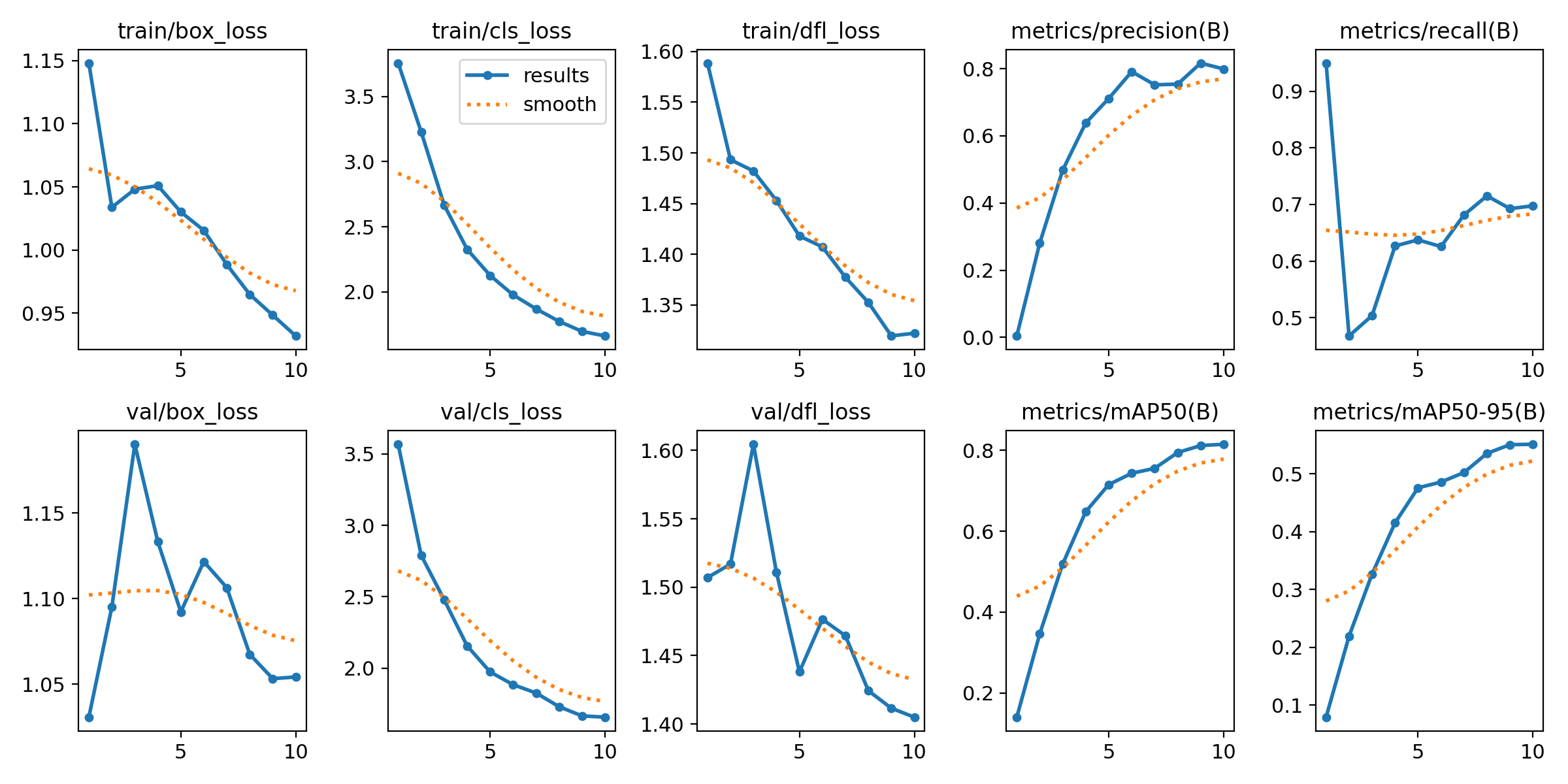
图4-6 模型训练损失与指标曲线图
图 4.6 模型训练损失与指标曲线表明,随着训练轮次的增加,训练集与验证集的边界框损失、分类损失等均持续下降并逐步趋于平稳,验证集损失未出现明显反弹,说明模型在训练过程中收敛状态良好,未发生过拟合现象;精确率、召回率以及 mAP 等关键评价指标则同步稳步提升,最终达到稳定区间,体现出模型具备可靠的学习能力与稳定性。
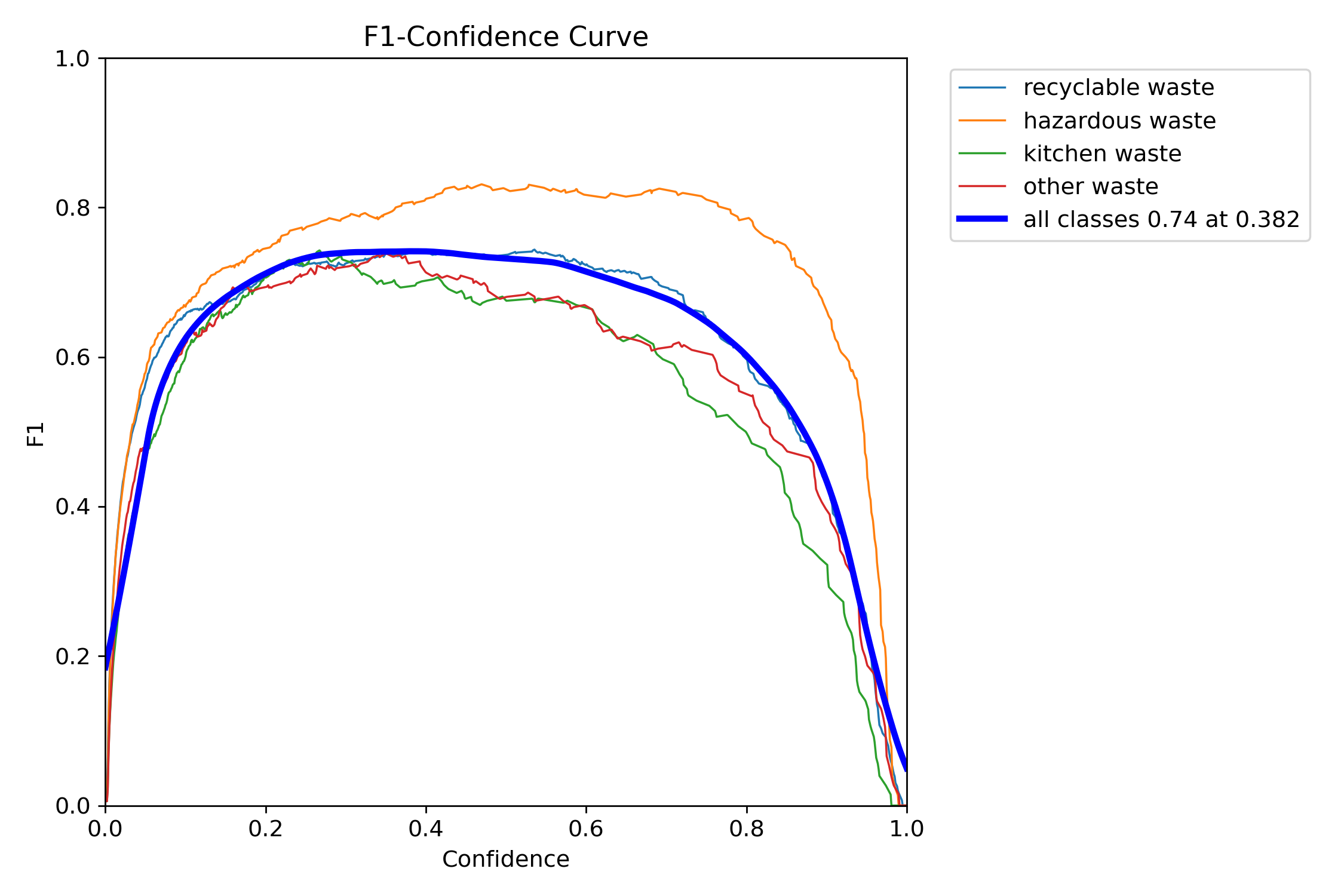
图4-7 F1 - 置信度曲线
在具体性能指标方面,图 4.7 F1 - 置信度曲线显示模型综合性能最优的置信度阈值为 0.382,此时整体 F1 值达到 0.74,精确率与召回率实现较好平衡;
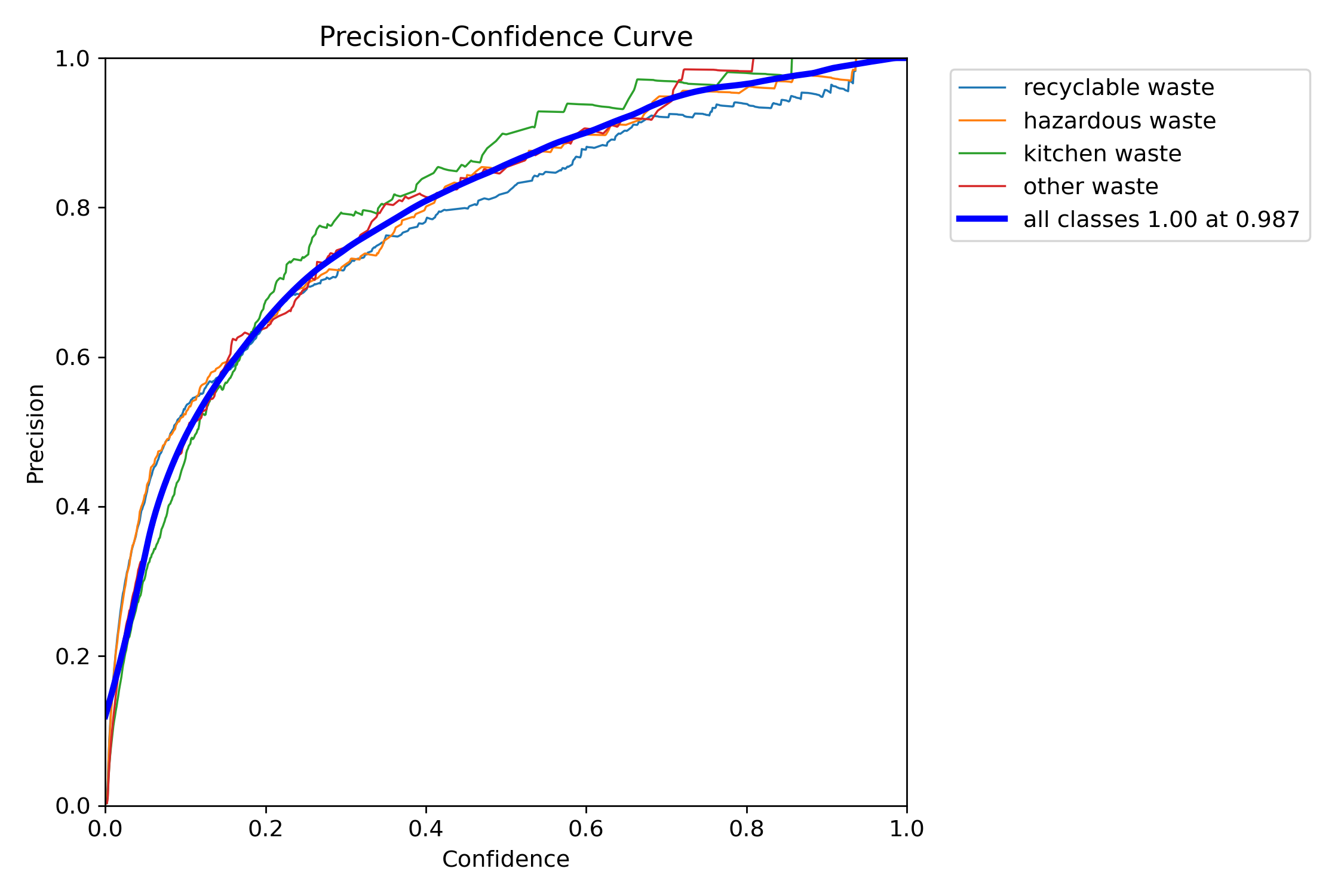
图4-8 精确率 - 置信度曲线
图 4.8 精确率 - 置信度曲线表明,随着置信度阈值提高,模型精确率持续上升,在高置信度条件下可接近 1.0,具备较低的误识别率;
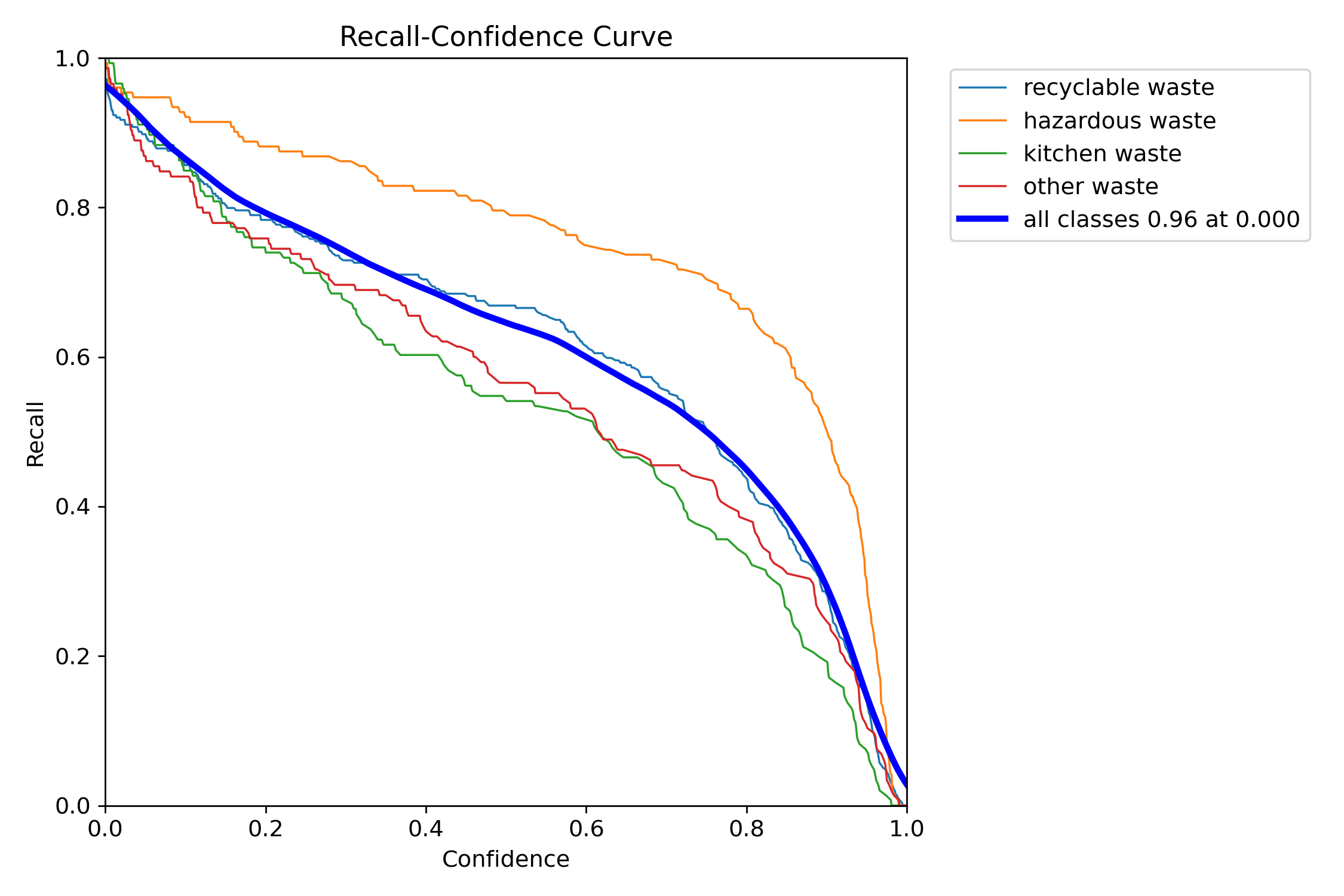
图4-9 召回率 - 置信度曲线
图 4.9 召回率 - 置信度曲线则体现出模型在低置信度条件下能够识别绝大多数目标,漏检率控制在合理范围。
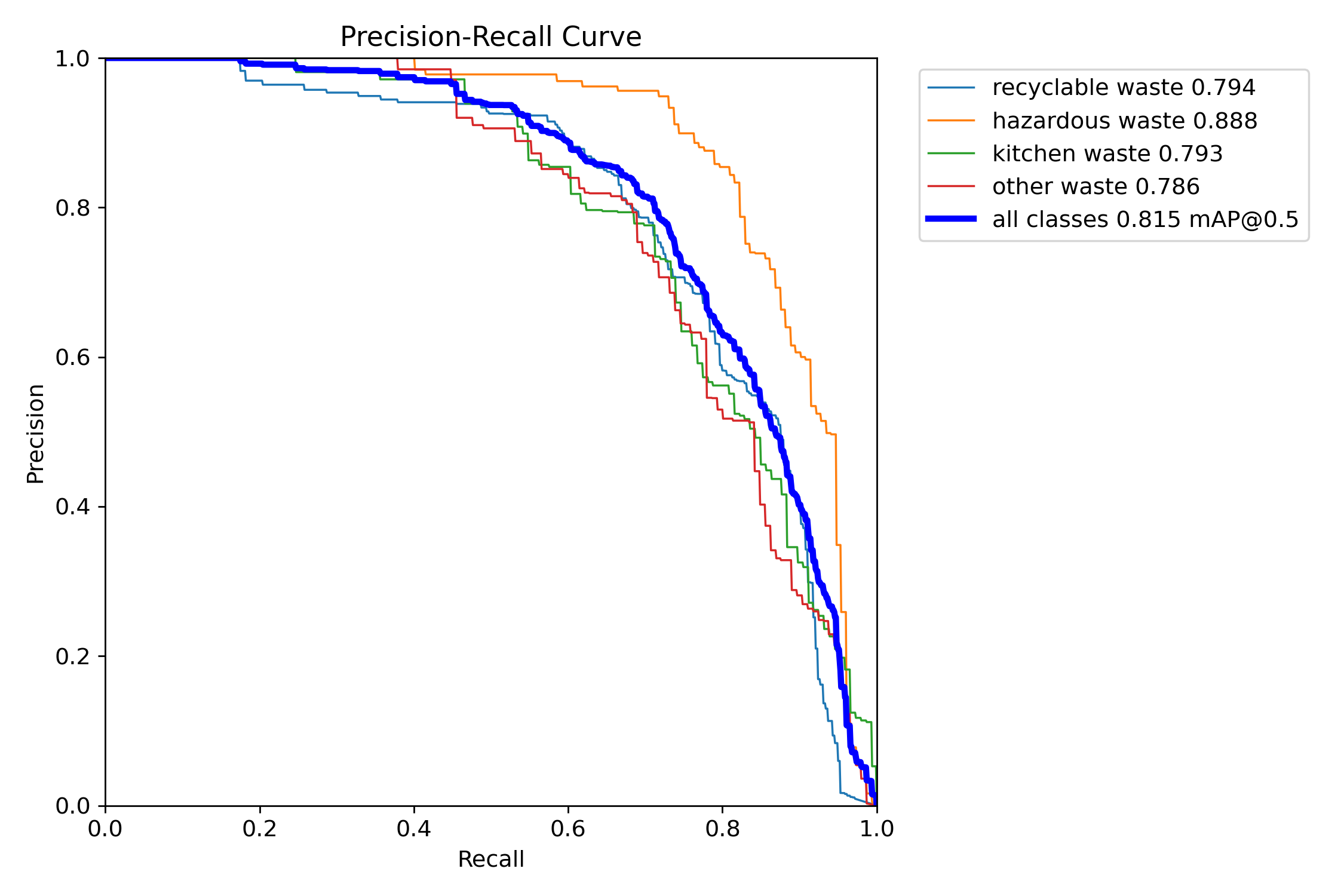
图4-10 召回率 - 置信度曲线
图 4.10 精确率 - 召回率曲线(PR 曲线)下面积所反映的 mAP@0.5 数值达到 0.815,说明模型在垃圾分类检测任务中整体精度优异,其中有害垃圾识别效果最佳,可回收物、厨余垃圾与其他垃圾的检测精度均保持在较高水平,能够满足实际使用需求。
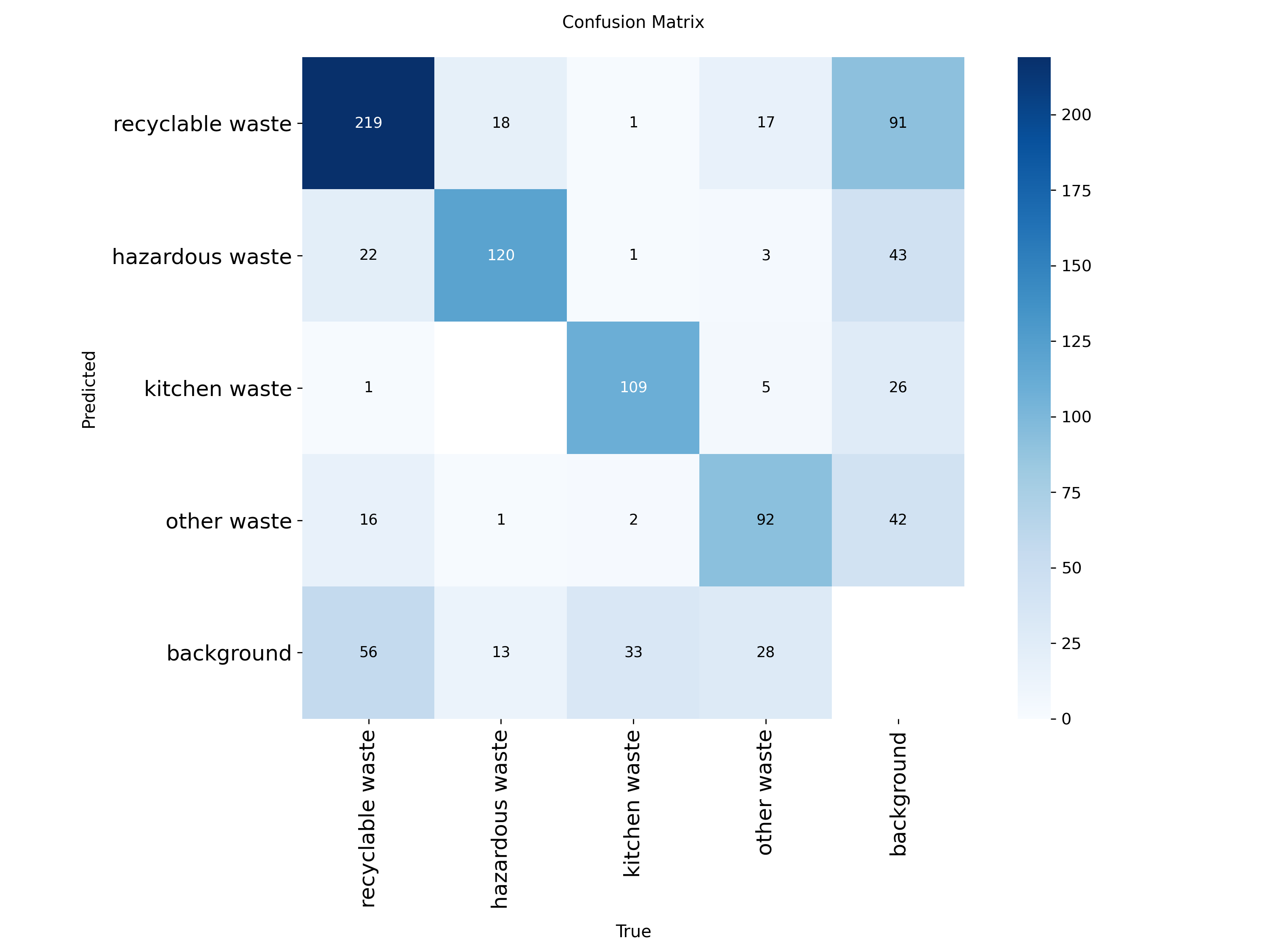
图4-11 混淆矩阵
图 4.11 混淆矩阵直观反映了模型的分类效果,模型在四大类别上均有较高的正确识别数量,类别之间相互混淆的情况较少,具备较强的类别区分能力。识别误差主要来源于将垃圾目标误判为背景,这与复杂拍摄环境、目标遮挡等因素相关,而不同垃圾类别之间的误识别占比较低,进一步证明模型对垃圾特征的学习较为充分。
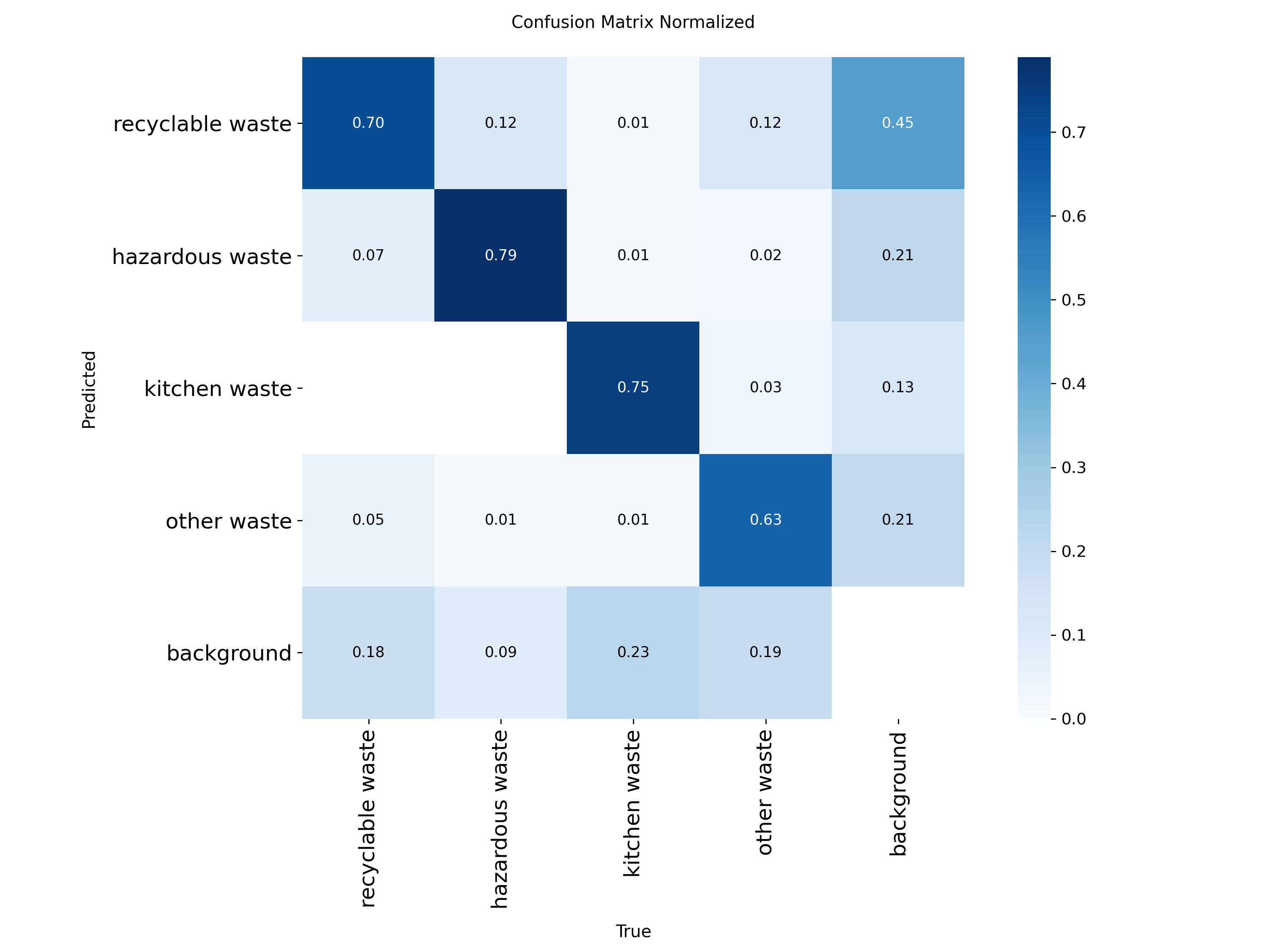
图4-12 归一化混淆矩阵
图 4.12 归一化混淆矩阵显示各类别的识别准确率均处于可接受范围,有害垃圾准确率最高,其他垃圾因样本数量相对偏少导致准确率略低,整体差异在合理范围内。
综合各项可视化结果与量化指标可以判定,基于 YOLOv8 训练的垃圾识别模型精度达标、运行稳定,在识别速度与检测效果上达到平衡,能够满足本系统对生活垃圾实时识别的功能要求,可作为系统核心推理模型投入实际使用。
- 系统 实现
本章详细阐述智能垃圾分类识别系统的开发环境配置与核心功能模块实现过程,所有功能均严格匹配第三章需求分析与第四章功能模块设计,形成完整的开发闭环,重点展示具备技术创新性与核心价值的功能实现逻辑。
5 .1 系统环境设置
本系统采用 B/S 四层架构体系,基于 Python 生态完成全栈开发,数据库选用轻量级 SQLite 嵌入式数据库,模型推理基于 YOLOv8 框架实现,系统开发软硬件环境如表 5.1 所示。
表5-1 开发环境表
|--------------|---------------------|--------------|------------------------------|
| 硬件环境 | 配置参数 | 软件环境 | 版本信息 |
| CPU | Intel Core i7-10700 | 操作系统 | Windows 11 专业版 |
| 内存 | 16GB DDR4 | 开发语言 | Python 3.10.11 |
| 硬盘 | 512GB NVMe SSD | Web 框架 | Flask 3.0.2 |
| 显卡 | NVIDIA GTX 1660 | 深度学习框架 | Ultralytics YOLOv8 8.2.0 |
| 网络 | 百兆以太网 | 数据库 | SQLite 3.41.2 |
| - | - | 前端框架 | Bootstrap 5.3.0 |
| - | - | 浏览器 | Google Chrome 122.0.6261.112 |
| - | - | 数据可视化 | ECharts 5.4.3 |
5 . 2 功能模块实现
本章节严格遵循第四章功能模块设计方案,完成系统全部核心业务功能的编码实现,功能覆盖与第三章需求分析、第四章模块设计、第六章功能测试形成全流程闭环。系统基于 Flask 框架的模块化路由机制开发,核心业务逻辑分别封装在 routes 目录下的对应路由文件中,深度学习模型与第三方接口调用逻辑封装于 utils 工具类,数据交互依托 SQLite 数据库完成,所有功能均聚焦垃圾分类核心服务,剔除登录注册等辅助性功能,保障核心逻辑的完整性与实用性。
5 . 2 .1 垃圾图像识别模块
垃圾图像识别是系统的核心功能模块,该功能通过 routes/detect.py 路由文件接收前端上传的图像文件,在后端完成文件格式校验、路径存储等基础处理后,调用 utils/yolo_detector.py 工具类中封装的 YOLOv8 检测接口,加载 runs/detect/train/weights 目录下的最优模型权重文件执行目标检测推理,模型自动识别图像中的垃圾目标并输出类别标签、置信度分数等关键信息,系统根据识别结果匹配数据库中的垃圾分类标准与投放指南,将检测数据持久化存储至 detect_garbage 数据表,同时将标注后的识别图像保存至 static/uploads 目录,最终将完整的识别结果、分类建议、可视化图像返回至前端页面展示,实现了从图像上传到智能识别再到科普指引的全流程自动化处理。
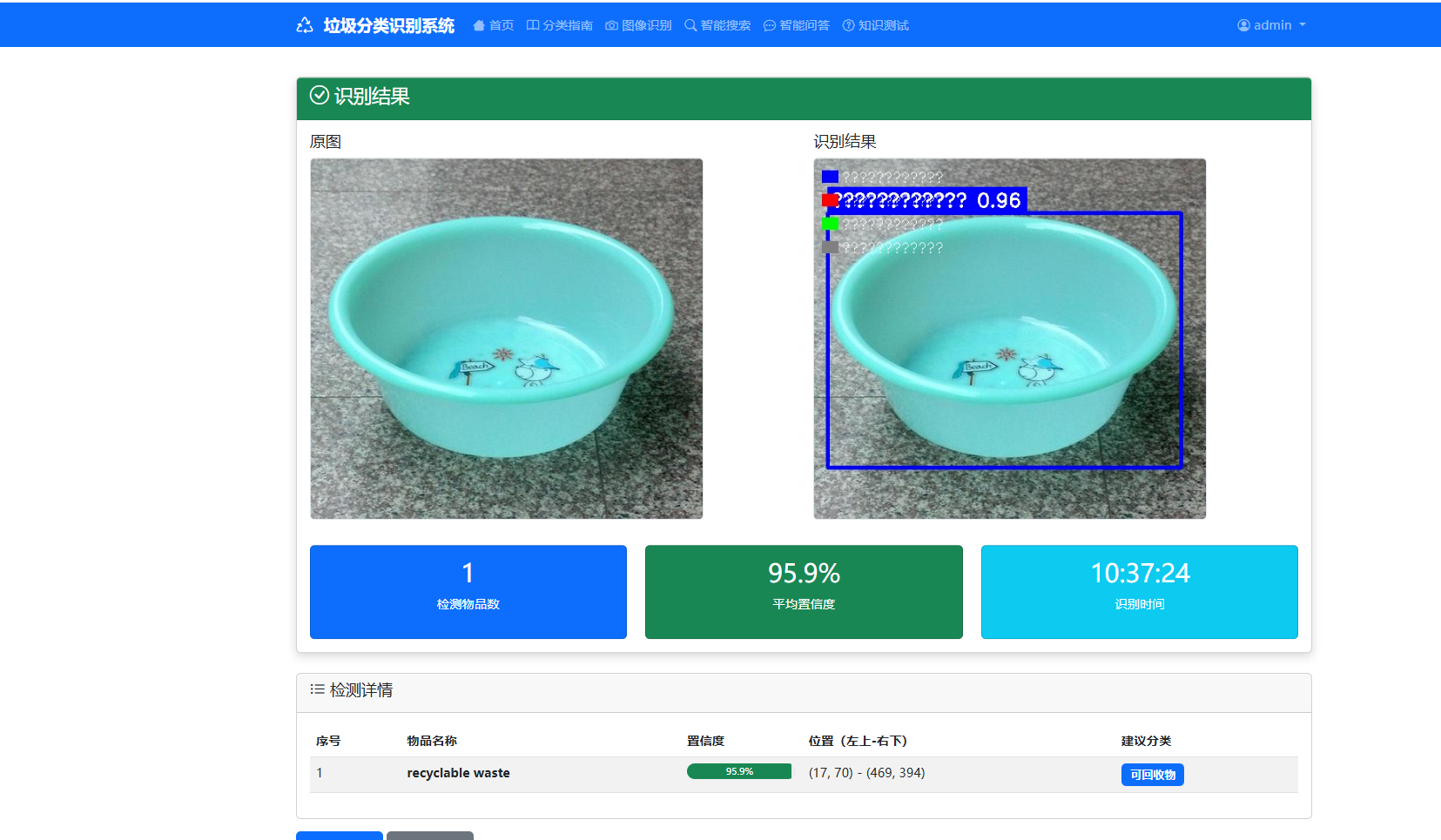
图5-1 垃圾图像识别模块
5 . 2 . 2 智能搜索模块
智能搜索模块集成文本关键词检索与图像相似检索两种模式,由 routes/search.py 路由文件统一处理用户的搜索请求,文本检索模式通过构建 SQL 模糊查询语句,在 category_garbage 数据表中匹配垃圾名称、分类说明等关键字段,快速筛选出对应的垃圾分类信息;图像相似检索模式调用 utils/image_search.py 工具类提取输入图像的特征向量,通过余弦相似度算法与数据集特征进行匹配,获取最相似的垃圾信息,系统对两种检索模式的结果进行整合排序,剔除冗余数据后将精准的垃圾分类详情、投放要求等内容反馈至前端,解决了传统单一检索方式适配性差的问题,满足用户多样化的信息查询需求。
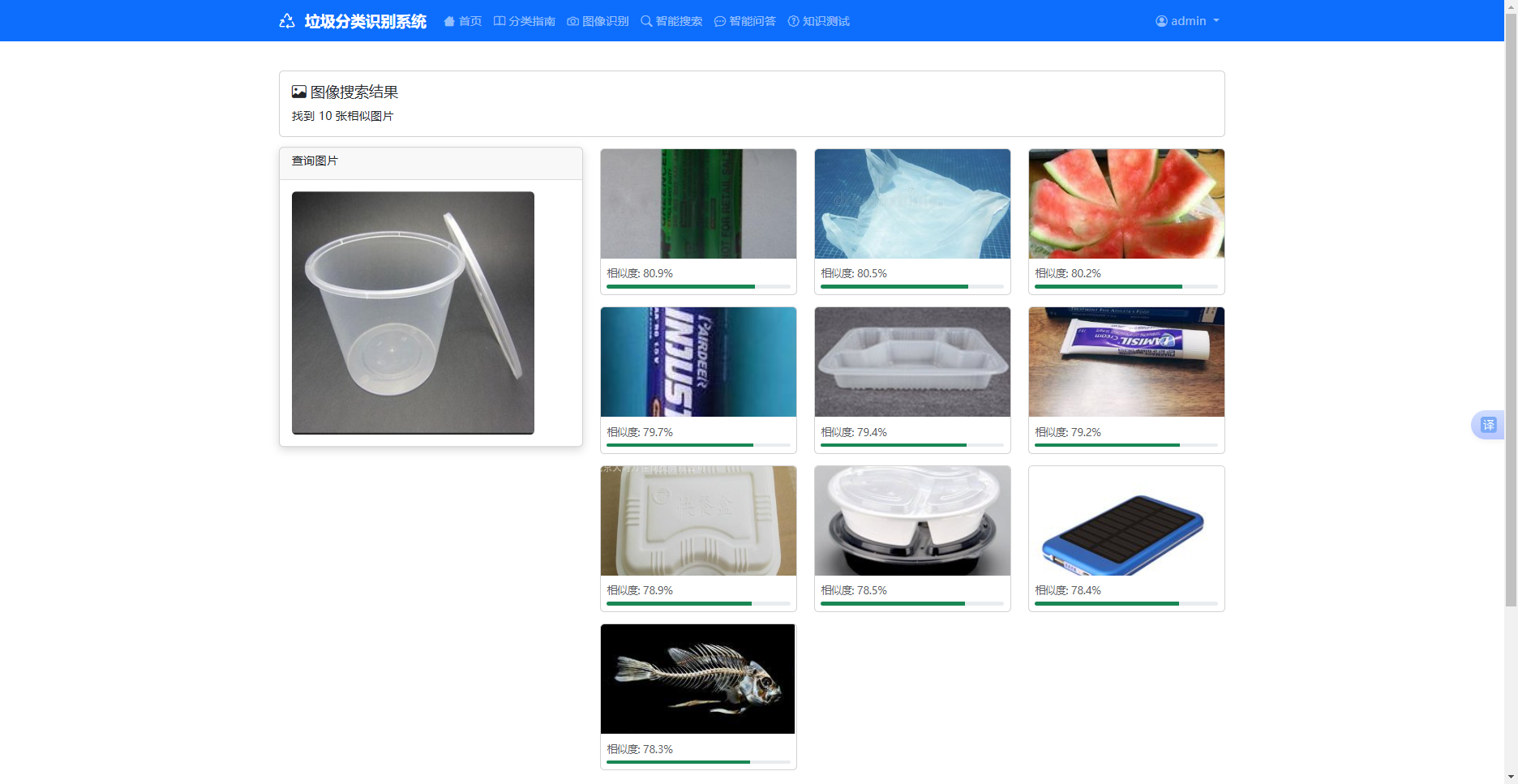
图5-2 智能搜索模块
5 . 2 . 3 智能问答模块
智能问答模块依托 DeepSeek 大模型 API 实现专业化垃圾分类交互服务,该功能通过 routes/qa.py 路由接收用户的自然语言提问,将问题参数传递至 utils/deepseek_api.py 封装的接口调用方法,通过定制化领域提示词限定模型的回答范围,确保输出内容仅围绕垃圾分类相关知识,避免无关信息生成,模型完成语义理解与推理后返回专业解答文本,系统对解答内容进行格式优化与排版处理,将问答数据存储至 qa_garbage 数据表用于后续追溯,最终在前端界面展示清晰易懂的回答内容,实现了无门槛、智能化的垃圾分类咨询服务。
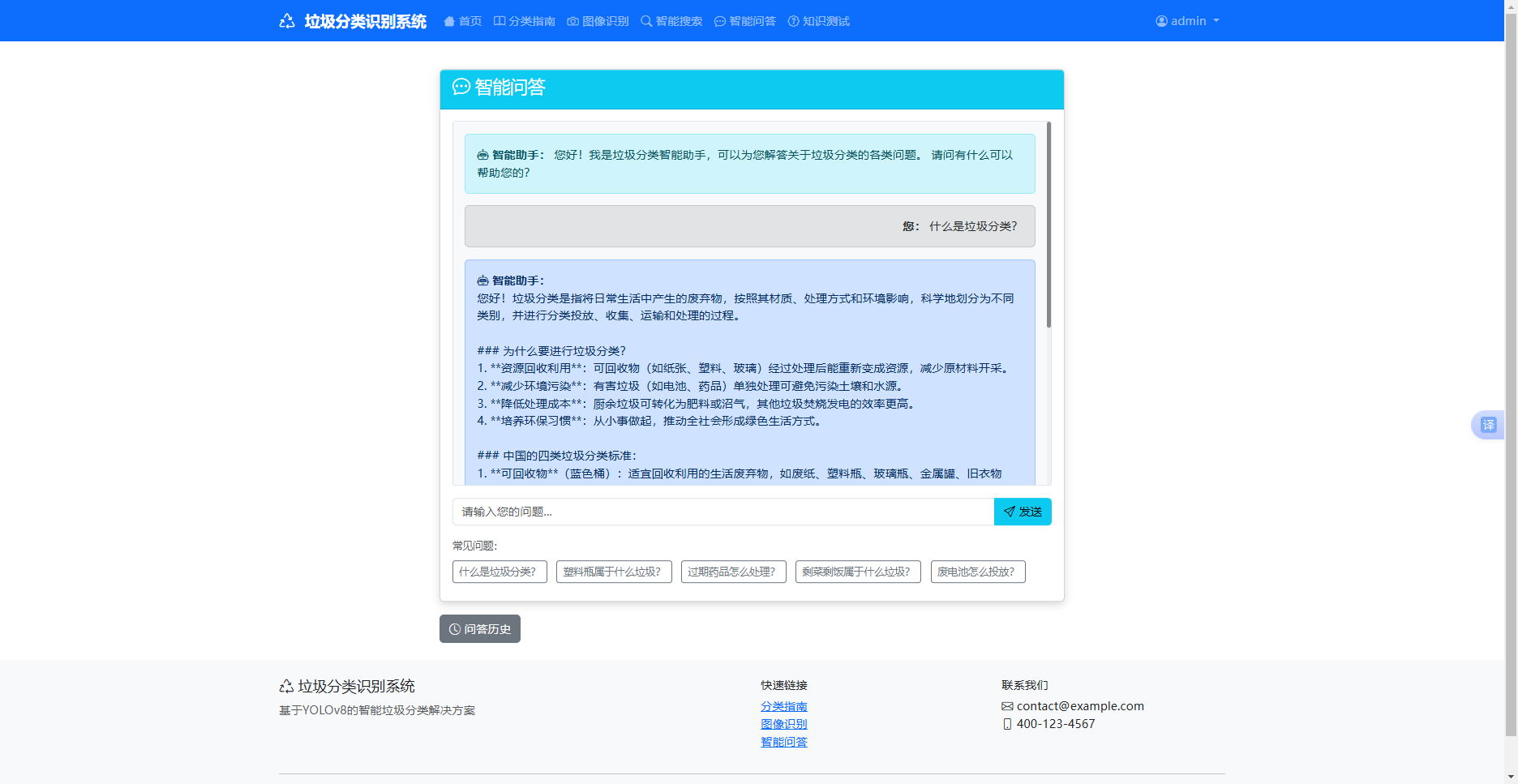
图5-3 智能问答
5 . 2 . 4 垃圾分类知识测试模块
智能问答模块依托 DeepSeek 大模型 API 实现专业化垃圾分类交互服务,该功能通过 routes/qa.py 路由接收用户的自然语言提问,将问题参数传递至 utils/deepseek_api.py 封装的接口调用方法,通过定制化领域提示词限定模型的回答范围,确保输出内容仅围绕垃圾分类相关知识,避免无关信息生成,模型完成语义理解与推理后返回专业解答文本,系统对解答内容进行格式优化与排版处理,将问答数据存储至 qa_garbage 数据表用于后续追溯,最终在前端界面展示清晰易懂的回答内容,实现了无门槛、智能化的垃圾分类咨询服务。
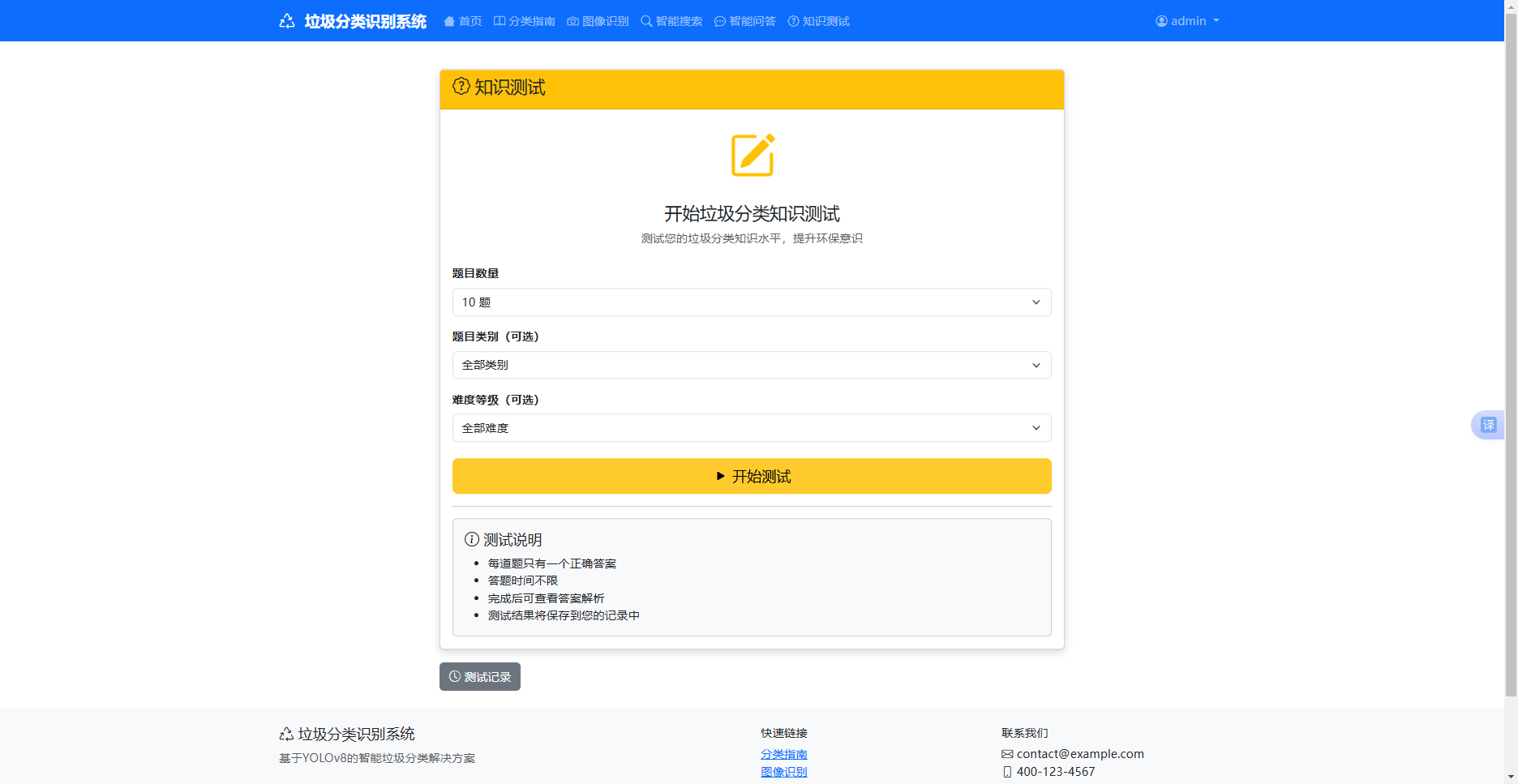
图5-4 垃圾分类知识测试
5 . 2 . 5 分类指南查询模块
分类指南查询模块是系统的基础科普功能,直接基于 category_garbage 核心数据表实现数据调用,前端页面展示可回收物、厨余垃圾、有害垃圾、其他垃圾四大垃圾分类入口,用户选择目标分类后,路由层接收请求并执行数据库查询操作,获取该分类下的包含物品、分类标准、投放禁忌、处理方式等完整信息,系统将查询到的结构化数据以图文结合的形式渲染至前端,界面布局简洁清晰、信息层级分明,为用户提供标准化、一站式的垃圾分类参考指南,满足日常快速查阅的使用需求。
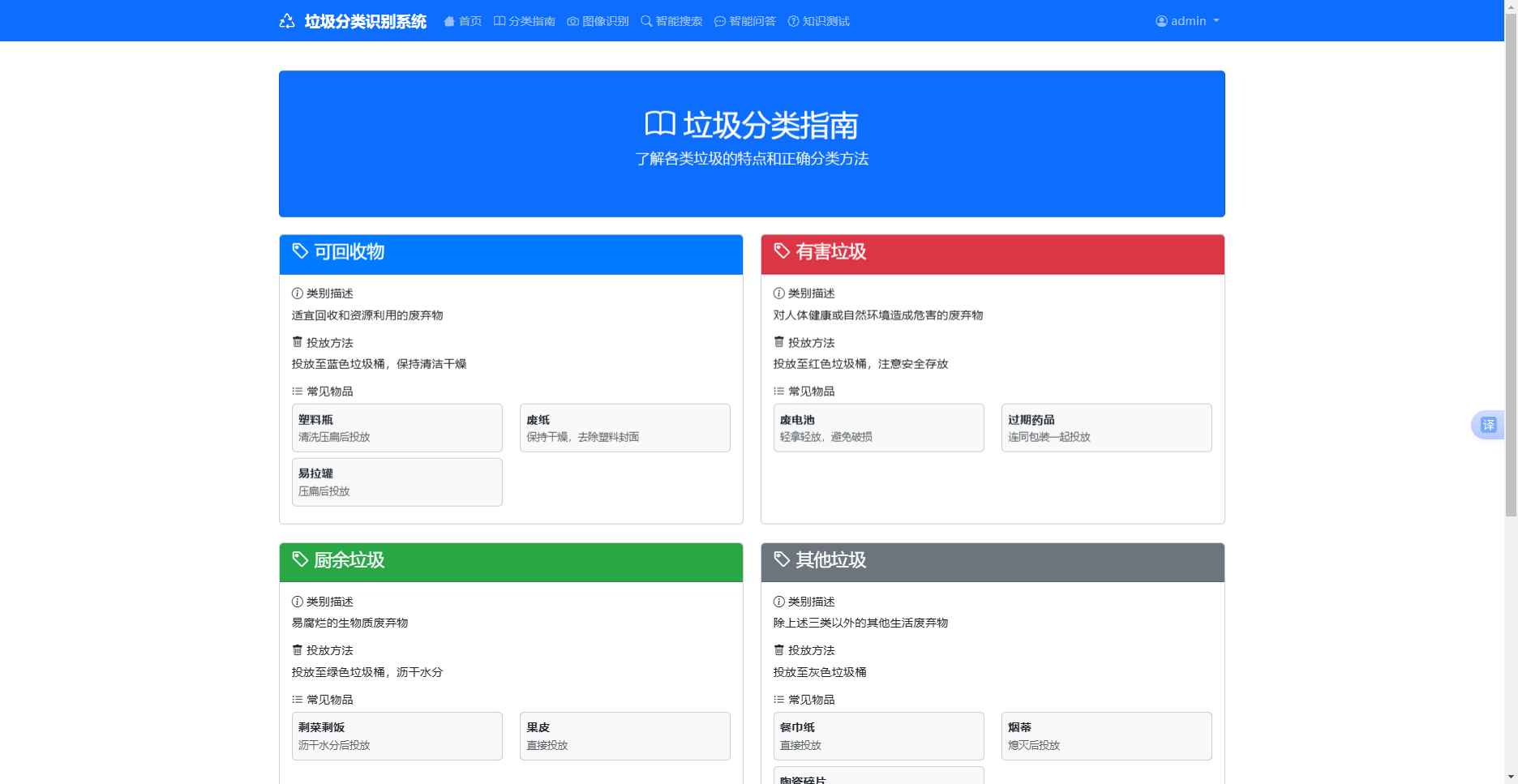
图5-5 垃圾分类指南
5 . 2 . 6 管理员数据统计模块
管理员数据统计模块是系统的管理端核心功能,依托 ECharts 数据可视化库与 routes/admin.py 路由实现,后端通过多表联查从数据库中汇总用户识别记录、垃圾类别分布、系统使用频次等核心数据,将原始数据处理为 JSON 格式的可视化数据源,前端通过 ECharts 将数据渲染为饼图、柱状图、折线图等多种可视化图表,直观展示垃圾分类识别的整体情况与用户使用行为,图表支持动态刷新与数据筛选,为管理员提供系统化的数据管控与决策支撑,实现了垃圾分类工作的数字化、可视化管理。
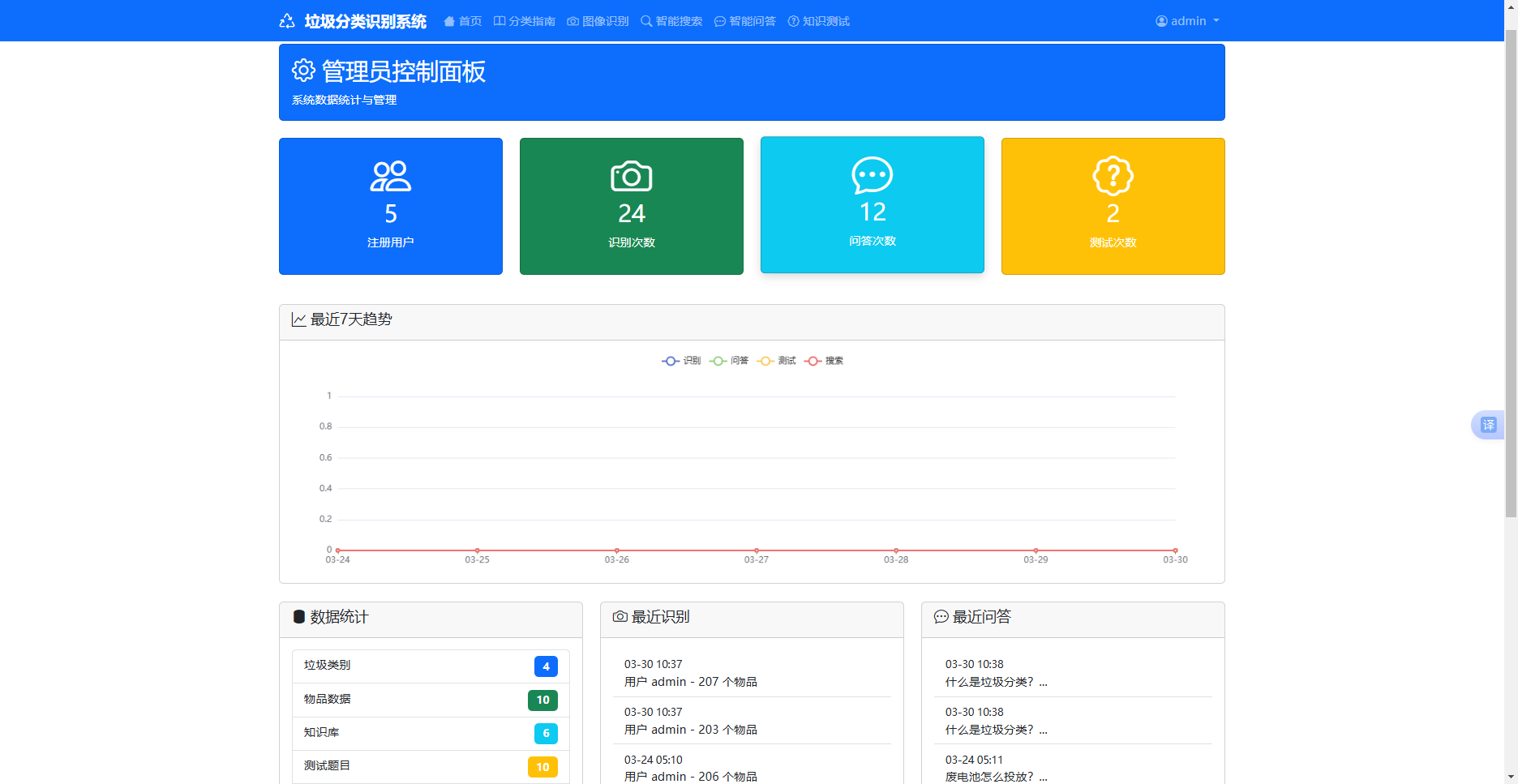
图5-6 数据分析仪表盘页面截图