基于通义千问实现医疗多轮对话与意图识别系统
本文基于阿里云 DashScope + qwen-max 模型,构建一个支持多轮对话的医疗意图识别系统。通过提示词工程实现结构化 JSON 输出,利用对话历史注入实现上下文记忆,覆盖意图分类、症状提取、科室推荐、紧急评估四大核心能力。
一、核心概念:医疗意图识别是什么?
医疗意图识别是智能问诊系统的第一步:从患者的自然语言描述中,提取出结构化信息,供后续流程使用。
| 能力 | 说明 | 示例 |
|---|---|---|
| 意图分类 | 判断患者咨询的目的 | "头疼得厉害" → 症状咨询 |
| 症状提取 | 从描述中提取症状关键词 | "头疼、发烧" → 头痛, 发热 |
| 科室推荐 | 根据症状推荐就诊科室 | 头痛 → 神经内科 |
| 紧急评估 | 判断是否需要紧急就医 | 胸痛+呼吸困难 → 紧急 |
为什么需要多轮对话? 真实场景中,患者往往不会一次性说清所有症状。系统必须能"记住"之前说过的内容,才能正确理解后续的追问。
二、系统架构
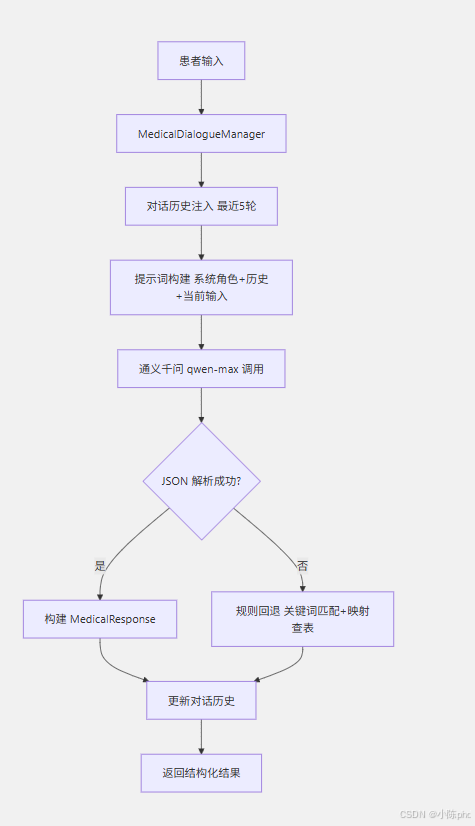
核心组件:
| 组件 | 职责 |
|---|---|
MedicalIntentRecognizer |
维护症状关键词库、科室映射、紧急规则 |
PromptTemplateManager |
生成结构化提示词模板 |
MedicalDialogueManager |
对话管理器,串联 LLM 调用与历史记忆 |
三、环境准备
3.1 技术栈
| 组件 | 选型 | 说明 |
|---|---|---|
| 大模型 | DashScope qwen-max | 结构化输出能力强 |
| API 客户端 | openai SDK | DashScope 兼容 OpenAI 格式 |
| 环境管理 | python-dotenv | 安全管理 API 密钥 |
3.2 配置环境变量
env
DASHSCOPE_API_KEY=sk-your-api-key-here
BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1四、步骤详解
步骤 1:数据结构定义
用枚举和数据类定义系统的核心数据结构,确保类型安全:
python
from enum import Enum
from dataclasses import dataclass
from typing import List
class UrgencyLevel(Enum):
EMERGENCY = "紧急"
URGENT = "较急"
NORMAL = "一般"
NON_URGENT = "不急"
class IntentType(Enum):
SYMPTOM_INQUIRY = "症状咨询"
DEPARTMENT_RECOMMENDATION = "科室推荐"
EMERGENCY_ASSESSMENT = "紧急评估"
MEDICATION_INQUIRY = "用药咨询"
APPOINTMENT_BOOKING = "预约挂号"
HEALTH_EDUCATION = "健康教育"
OTHER = "其他"
@dataclass
class MedicalResponse:
intent: IntentType # 意图类型
symptoms: List[str] # 识别到的症状
recommended_department: str # 推荐科室
urgency_level: UrgencyLevel # 紧急程度
analysis: str # 症状分析
suggestions: List[str] # 建议措施
follow_up_questions: List[str] # 后续追问设计要点:
- 用
Enum约束意图和紧急程度的取值范围,避免 LLM 返回非法值 - 用
dataclass定义响应结构,字段清晰、易于序列化
步骤 2:症状知识库与规则引擎
python
class MedicalIntentRecognizer:
def __init__(self):
self.symptom_keywords = self._load_symptom_keywords()
self.department_mapping = self._load_department_mapping()
self.urgency_rules = self._load_urgency_rules()
def _load_symptom_keywords(self):
return {
"头痛": ["头痛", "头疼", "偏头痛", "头晕"],
"发热": ["发烧", "发热", "体温高", "高烧"],
"胸痛": ["胸痛", "胸闷", "胸口疼"],
"呼吸困难": ["呼吸困难", "气短", "喘不过气"],
# ... 更多症状
}
def _load_department_mapping(self):
return {
"头痛": "神经内科",
"发热": "内科",
"胸痛": "心内科",
"呼吸困难": "呼吸内科",
# ... 更多映射
}作用: 作为 LLM 失败时的回退方案,也用于验证 LLM 输出的合理性。
步骤 3:提示词工程------让 LLM 输出结构化 JSON
提示词工程是本系统的核心。好的提示词能让 LLM 稳定输出可解析的 JSON:
python
def _get_system_prompt(self) -> str:
return """你是一个专业的医疗AI助手,具备丰富的临床医学知识。你的任务是:
1. 准确识别患者的咨询意图
2. 从描述中提取症状关键词
3. 推荐合适的就诊科室
4. 评估紧急程度
5. 给出专业的分析和建议
请始终以JSON格式返回分析结果,确保结构完整。"""
def _build_full_analysis_prompt(self, user_input: str) -> str:
return f"""请对以下患者咨询进行全面分析:
患者咨询:"{user_input}"
请按照以下JSON格式返回分析结果:
{{
"intent_type": "意图类型(症状咨询/科室推荐/紧急评估/...)",
"symptoms": ["症状1", "症状2"],
"department": "推荐科室",
"urgency_level": "紧急程度(紧急/较急/一般/不急)",
"analysis": "症状分析(50-100字)",
"suggestions": ["建议1", "建议2"],
"follow_up_questions": ["追问1", "追问2"]
}}
请只输出JSON,不要包含其他内容。"""提示词设计原则:
| 原则 | 说明 |
|---|---|
| 角色定义 | "专业的医疗AI助手" → 引导 LLM 用专业视角回答 |
| 输出格式约束 | 明确 JSON 模板 → 确保可解析 |
| 枚举值列举 | 列出所有合法意图 → 减少幻觉 |
| 紧急评估标准 | 给出具体判断标准 → 提高准确性 |
| "只输出JSON" | 末尾强调 → 避免多余文本 |
步骤 4:多轮对话------注入历史上下文
这是本系统最关键的增强。LLM 本身是无状态的,每次调用互相独立。要实现多轮对话,必须将历史注入到 messages 中:
python
def _process_with_llm(self, user_input: str) -> MedicalResponse:
# 1. 构建 messages,包含对话历史
messages = [{"role": "system", "content": self._get_system_prompt()}]
# 2. 注入历史对话上下文(最近 5 轮)
history_window = self.conversation_history[-5:]
if history_window:
history_text = ""
for h in history_window:
history_text += f"患者: {h['user_input']}\n"
history_text += f"助手: 意图={h['response']['intent']}, "
history_text += f"症状={','.join(h['response']['symptoms'])}, "
history_text += f"科室={h['response']['department']}, "
history_text += f"紧急={h['response']['urgency']}\n"
messages.append({
"role": "system",
"content": f"以下是之前的对话历史,请结合上下文理解当前咨询:\n{history_text}"
})
# 3. 添加当前用户输入
messages.append({"role": "user", "content": self._build_full_analysis_prompt(user_input)})
# 4. 调用 LLM
response = _llm_client.chat.completions.create(
model="qwen-max",
messages=messages,
temperature=0.3
)
# 5. 解析并记录
parsed = self._parse_llm_response(response.choices[0].message.content)
# ... 构建 MedicalResponse
# 6. 记录到对话历史
self.conversation_history.append({
"user_input": user_input,
"response": {"intent": ..., "symptoms": ..., "department": ..., "urgency": ...}
})多轮对话的核心原理:
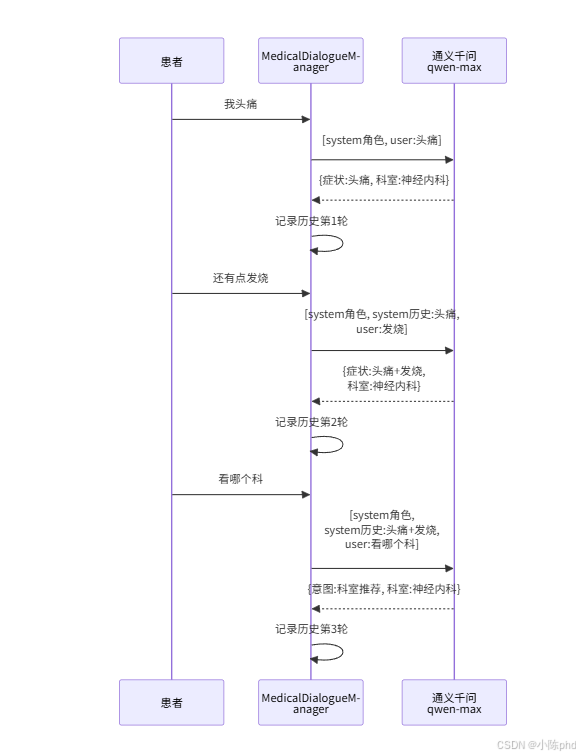
关键设计:
- 滑动窗口:只保留最近 5 轮,避免 token 超限
- 摘要式历史:不传原始回复,只传结构化摘要(意图、症状、科室、紧急度),节省 token
- 双 system 消息:第一个定义角色,第二个注入历史,职责分离
步骤 5:JSON 解析容错
LLM 有时会返回带 markdown 代码块或额外文本的 JSON,需要容错解析:
python
def _parse_llm_response(self, text: str) -> Dict:
text = text.strip()
# 1. 移除 markdown 代码块标记
if text.startswith("```json"):
text = text[7:]
if text.startswith("```"):
text = text[3:]
if text.endswith("```"):
text = text[:-3]
text = text.strip()
# 2. 尝试直接解析
try:
return json.loads(text)
except json.JSONDecodeError:
# 3. 从文本中提取 JSON 块
match = re.search(r'\{[\s\S]*\}', text)
if match:
try:
return json.loads(match.group())
except:
pass
# 4. 返回默认结构
return {"intent_type": "症状咨询", "symptoms": [], ...}步骤 6:规则回退机制
当 LLM 调用失败时,系统自动回退到规则匹配,保证可用性:
python
def process_user_input(self, user_input: str) -> MedicalResponse:
if self.use_llm:
return self._process_with_llm(user_input)
else:
return self._process_with_rules(user_input)
def _process_with_rules(self, user_input: str) -> MedicalResponse:
intent = self._classify_intent(user_input) # 关键词匹配
symptoms = self._extract_symptoms(user_input) # 症状库匹配
department = self._recommend_department(symptoms) # 映射查表
urgency = self._assess_urgency(symptoms, user_input) # 规则评估
# ...五、运行结果展示
执行命令:
bash
conda activate llmops
python week_01/medical_intent_recognition.py5.1 单轮意图识别
【测试案例 3】
患者咨询:胸口疼,呼吸困难,这严重吗?
[LLM 调用中...]
意图类型:症状咨询
识别症状:胸口疼, 呼吸困难
推荐科室:心内科
紧急程度:紧急
症状分析:胸痛伴随呼吸困难可能是心脏疾病如心绞痛或心肌梗塞的症状...5.2 多轮对话(核心演示)

多轮对话的关键表现:
- 第 2 轮:LLM 记住了第 1 轮的"头痛",并新增"发烧"
- 第 3 轮:患者只说"看哪个科",LLM 结合历史正确推荐科室
- 第 4 轮:LLM 理解"需要马上去医院吗"是在问紧急程度
- 第 5 轮:LLM 识别"去挂神经内科"为预约挂号意图
六、核心技术点总结
| 技术点 | 实现方式 | 作用 |
|---|---|---|
| 结构化输出 | 提示词中给出 JSON 模板 | 确保 LLM 返回可解析的结构化数据 |
| 多轮记忆 | 滑动窗口注入最近 5 轮历史 | 让 LLM 理解上下文关联 |
| 摘要式历史 | 只传意图/症状/科室/紧急度 | 节省 token,避免冗余 |
| 枚举约束 | Enum 定义合法取值 | 防止 LLM 返回非法值 |
| JSON 容错 | 移除 markdown + 正则提取 | 兼容 LLM 的各种输出格式 |
| 规则回退 | 关键词匹配 + 映射查表 | LLM 失败时保证可用性 |
| 双 system | 角色定义 + 历史注入分离 | 职责清晰,互不干扰 |
七、延伸思考
- 更长的记忆窗口:当前只保留 5 轮,可以用摘要压缩历史来支持更长对话
- 流式输出 :使用
stream()实现打字机效果,提升用户体验 - 意图路由:根据识别到的意图调用不同的专业模型(如用药咨询用专门的药物模型)
- 知识图谱:接入 ICD-10 疾病编码库,提高症状-疾病映射的准确性
- 安全护栏:添加免责声明,避免 LLM 给出具体的诊断和处方