note
- 基准内置12种独立任务题型,覆盖基础视觉→时序动态→高阶综合推理全维度:
- 时序行为、运动模式、多目标跨帧追踪、时序先后推理、事件因果推导、长视频摘要、跨模态信息融合、多语言视频理解、细节定位、空间关系推理、抽象剧情理解、多线索综合问答
文章目录
- note
- 一、Video-MME
- [二、Video MME 12类任务体系](#二、Video MME 12类任务体系)
- [三、Video MME关键实验结果](#三、Video MME关键实验结果)
- Reference
一、Video-MME
论文:Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
- 项目主页(榜单、数据集、任务说明):https://video-mme.github.io/home_page.html
- GitHub评测代码仓库:https://github.com/BradyFU/Video-MME
arXiv论文:https://arxiv.org/pdf/2604.05015
二、核心优化点
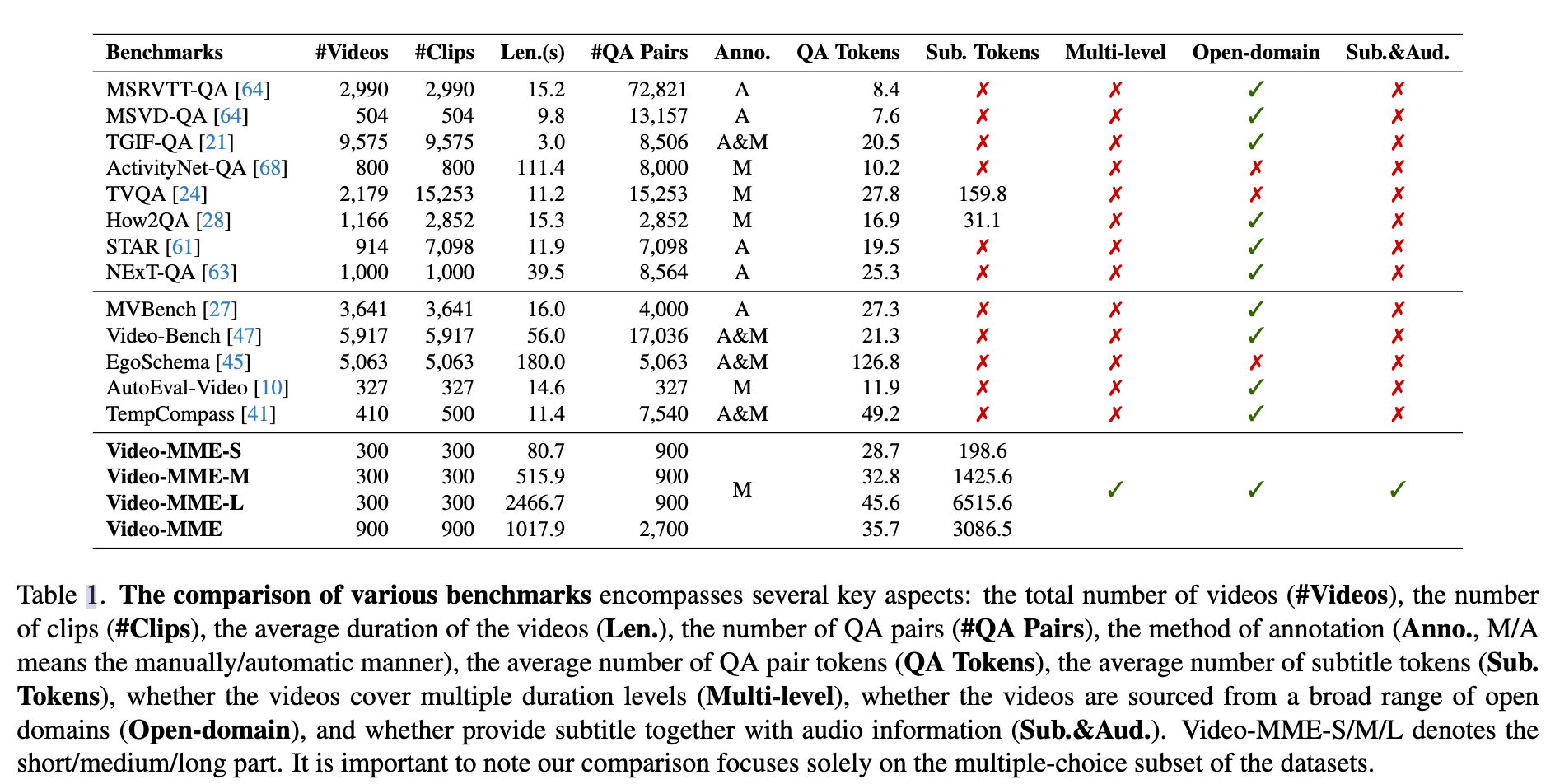
- 研究痛点:过往多模态评测基准仅聚焦静态图像,缺少覆盖长短时序、音视文多模态融合的标准化视频评测集,无法统一衡量时序记忆、跨帧推理、多线索联合理解能力。
-
四大核心设计
◦ 场景全覆盖:6大主领域(知识科普、影视、体育、舞台艺术、日常记录、多语言),30个细分子场景;
◦ 完整时序跨度:视频时长11秒~1小时,分短/中/长视频,专门测试长上下文记忆;
◦ 多模态输入范式:支持纯画面、画面+字幕、画面+音频三种评测模式,量化音/文本对视频理解的增益;
◦ 高质量人工标注:900段视频(总254小时)、2700道选择题,全程人工校验,无机器生成脏数据。
-
核心创新:构建12类分层视频理解评测任务体系,从底层视觉感知到高层综合推理全覆盖,形成完整能力分层评测标准。
二、Video MME 12类任务体系
基准内置12种独立任务题型,覆盖基础视觉→时序动态→高阶综合推理全维度:
-
画面物体识别:识别画面内物体、属性、场景基础视觉感知
-
动作识别:区分人物/物体动态行为、运动模式
-
多目标跨帧追踪:持续定位多物体在不同时间戳的位置变化
-
时序先后推理:判断事件、动作发生的时间先后顺序
-
事件因果推导:基于时序上下文分析事件发生的因果逻辑
-
长视频摘要:提取数十分钟长视频核心主线、关键情节
-
跨模态信息融合:联合画面、字幕、音频信息完成统一推理
-
多语言视频理解:适配带多语种字幕/语音的跨语言视频问答
-
细节定位:精准定位特定物体、台词、动作出现的时间片段
-
空间关系推理:判断物体间远近、方位、遮挡等空间约束
-
抽象剧情理解:解读隐喻、人物情绪、剧情伏笔、叙事逻辑
-
多线索综合问答:融合时序、空间、音文多条线索做多跳推理
三、Video MME关键实验结果
Video MME关键实验结果(2025年版):
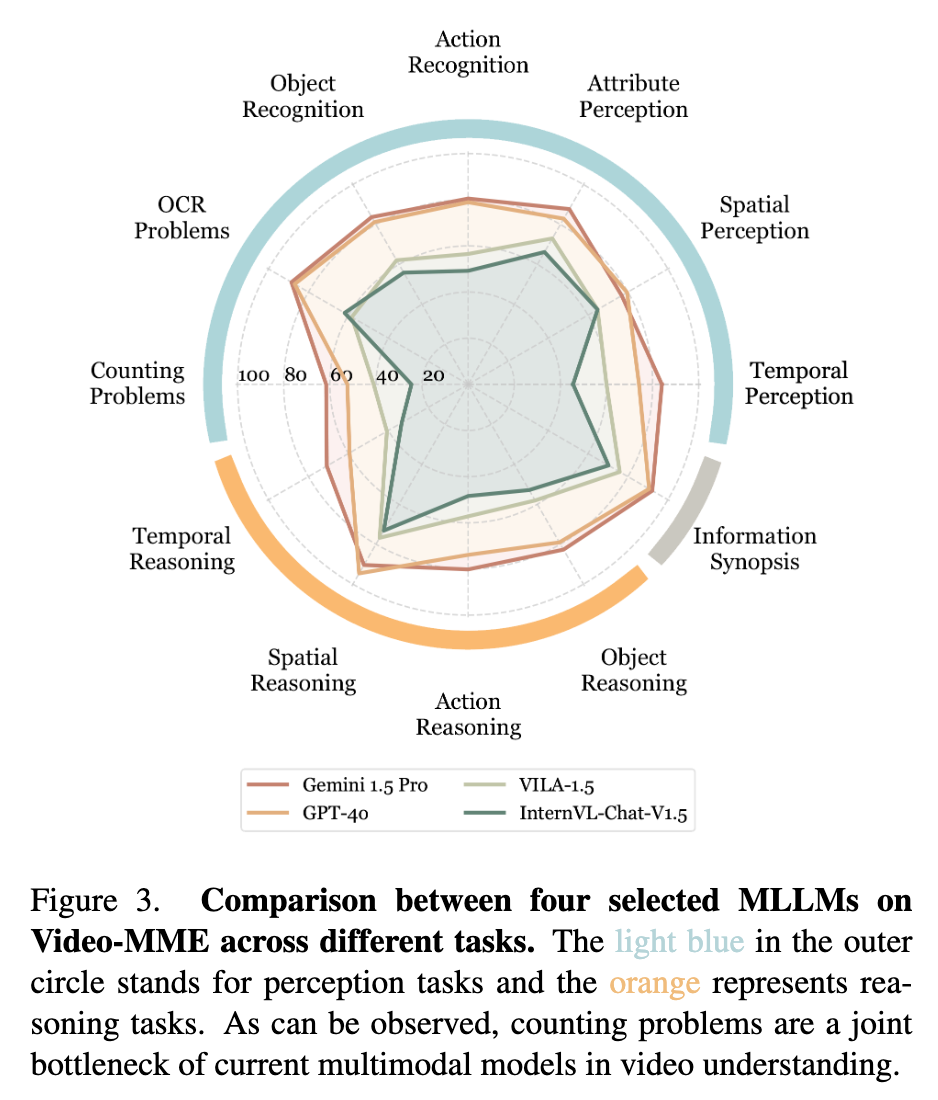
- 闭源模型性能:Gemini 1.5 Pro平均精度75%,高于GPT-4o(71.9%),为初代榜单最优;
- 时序衰减规律:所有模型准确率随视频时长拉长持续下降,开源模型长时序短板显著大于闭源;
- 模态增益结论:叠加字幕/音频输入后,模型整体准确率提升8%~15%,单帧视觉不足以支撑复杂推理;
- 任务分层差距:12类任务性能分化明显,抽象剧情、长视频摘要、多线索综合问答是所有模型普遍弱项。
Reference
1 Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis