核心定位: UniLab 机器人 RL 异构架构 | 代码复现 | G1、Go2、灵巧手等
开源地址:https://github.com/unilabsim/UniLab/blob/main/README_zh.md
论文地址:UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
项目地址:https://unilabsim.github.io/

✨ UniLab简介与亮点
- 异构 RL 运行时: CPU 并行仿真通过共享内存流式传输 transition,而策略学习运行在 GPU 加速器上。
- 两套物理后端: MuJoCoUni 和 MotrixSim 通过后端专用适配器和任务 owner 配置接入。
- 统一训练 CLI:
uv run train和uv run eval覆盖PPO、MLX PPO、APPO、SAC、TD3 和 FlashSAC;额外的 HORA 与 HIM-PPO 路径以脚本级工作流文档化。 - 配置拥有的任务: Hydra owner YAML 会同时选择 task、reward、backend 和 algorithm;后端切换通过
task=<task>/<backend>表达。 - 跨平台安装路径: 仓库覆盖
Linux CUDA、Linux ROCm、Linux XPU,以及 Apple Silicon / macOS的安装流程。
代表性机器人RL训练系统对比 ,如下图所示:
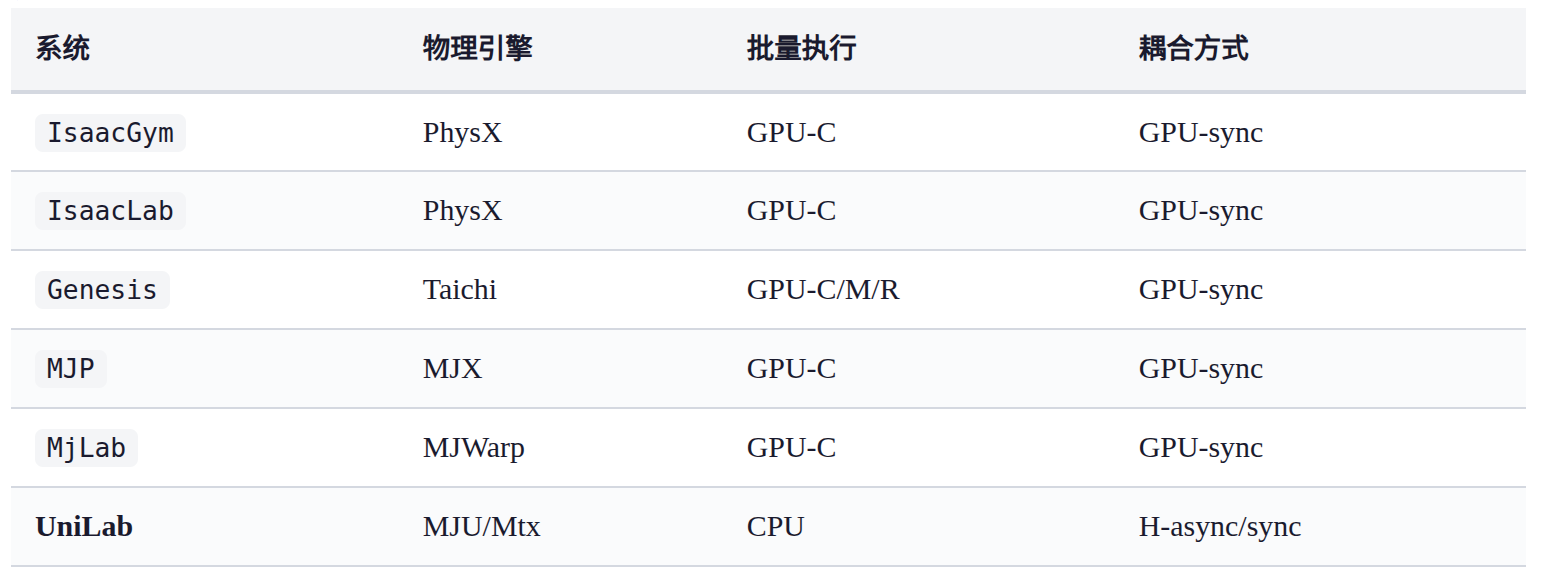
-
注:GPU-C/M/R: 基于 CUDA/Metal/ROCm 的 GPU 批量物理。
-
GPU-sync: 同步 GPU 仿真-学习;
-
H-async/sync: CPU 仿真 + GPU 学习。
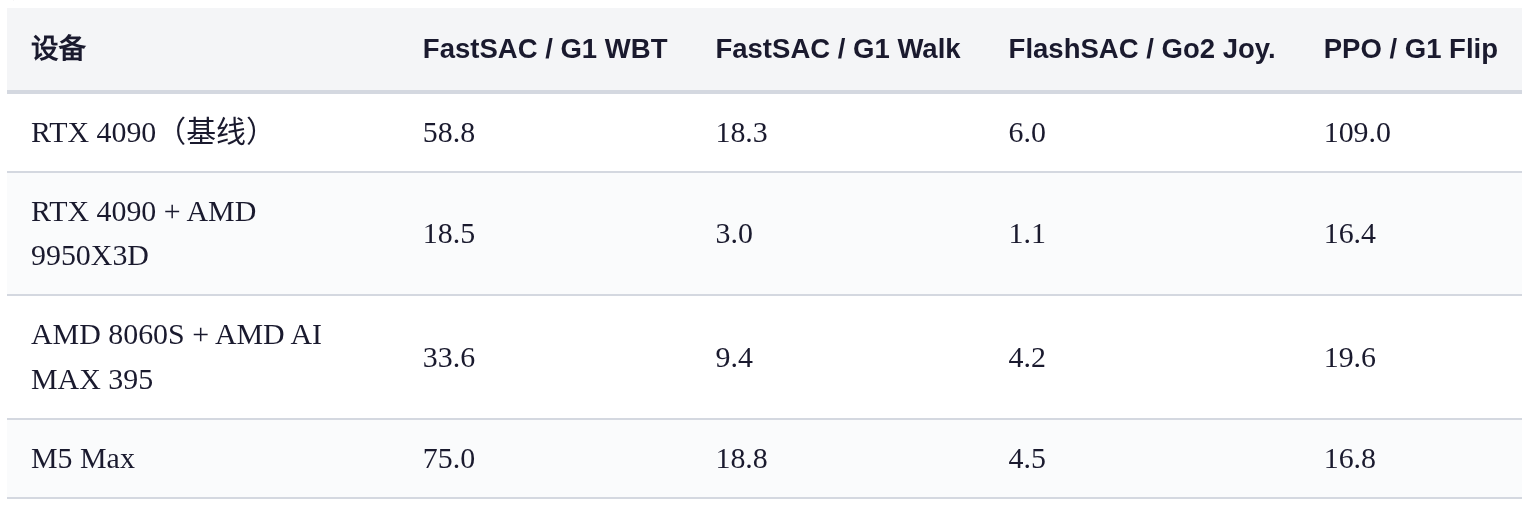
使用UniLab的训练时间 ,如下表所示:
整体速度还是很快的,不错不错~
一、环境搭建
主要参考下面几条指令,进行环境搭建:
bash
# 0. 如果还没有安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 1. 克隆仓库
git clone https://github.com/unilabsim/UniLab.git
cd UniLab
# 2. 安装依赖
# 选择合适的平台,对应的安装命令
# Linux CUDA 或 macOS
make setup-motrix
# 不使用 shell completion 设置时:uv sync --extra motrix
# 如果没有安装 `make`:uv sync --extra motrix && uv run --no-sync unilab-complete install
# Linux AMD / ROCm
# make sync-rocm
# Linux Intel Arc / iGPU
# make sync-xpu
# 3. 安装Play viser 可视化 依赖
uv sync --extra viser运行过程:
然后设置 Hugging Face 为国内源
动作、场景、机器人数据 和 demo checkpoint首次运行时会从 Hugging Face 拉取。
bash
export HF_ENDPOINT=https://hf-mirror.com二、效果演示
演示回放(首次运行会从 Hugging Face 拉取预训练检查点):
示例1:G1机器人跳舞
bash
# G1机器人跳舞的示例
uv run demo dance其中,可用的 demo 名称:teaser、dance、wallflip、boxtracking、locomani、inhandgrasp
运行效果
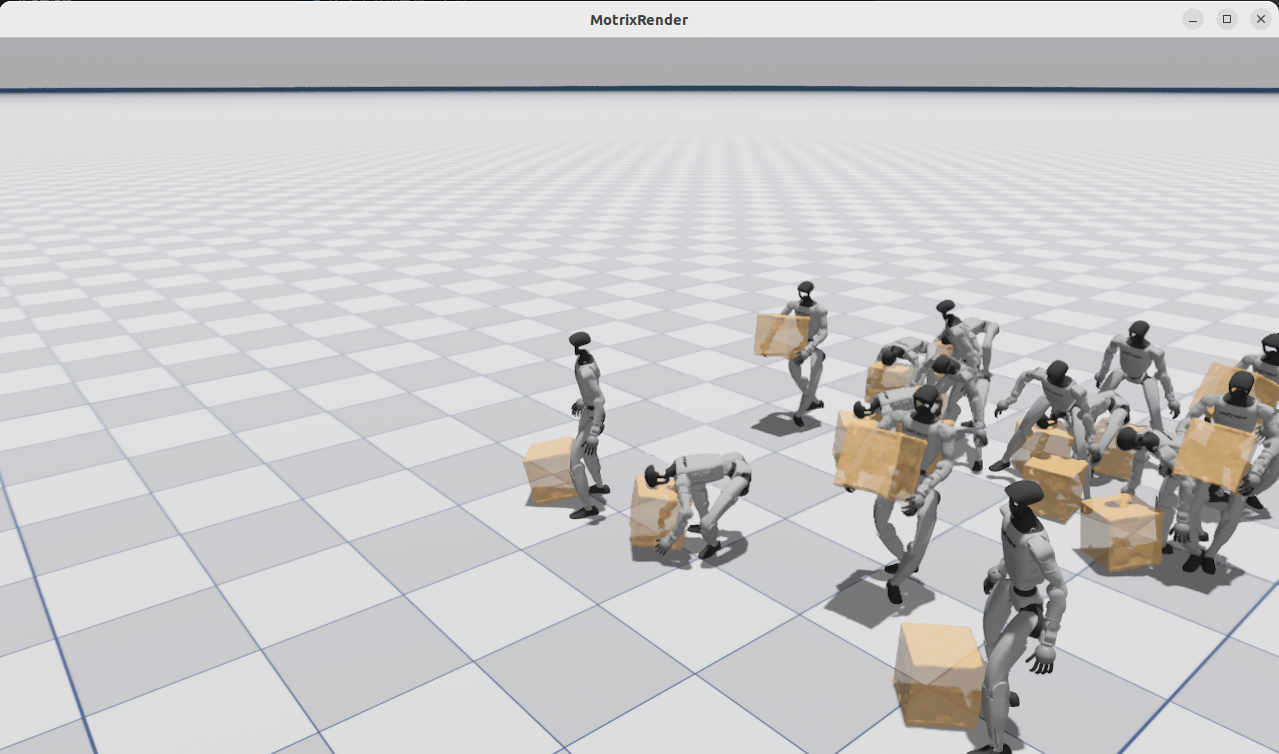
示例2:G1机器人搬箱子
bash
# G1机器人搬箱子
uv run demo dance运行效果
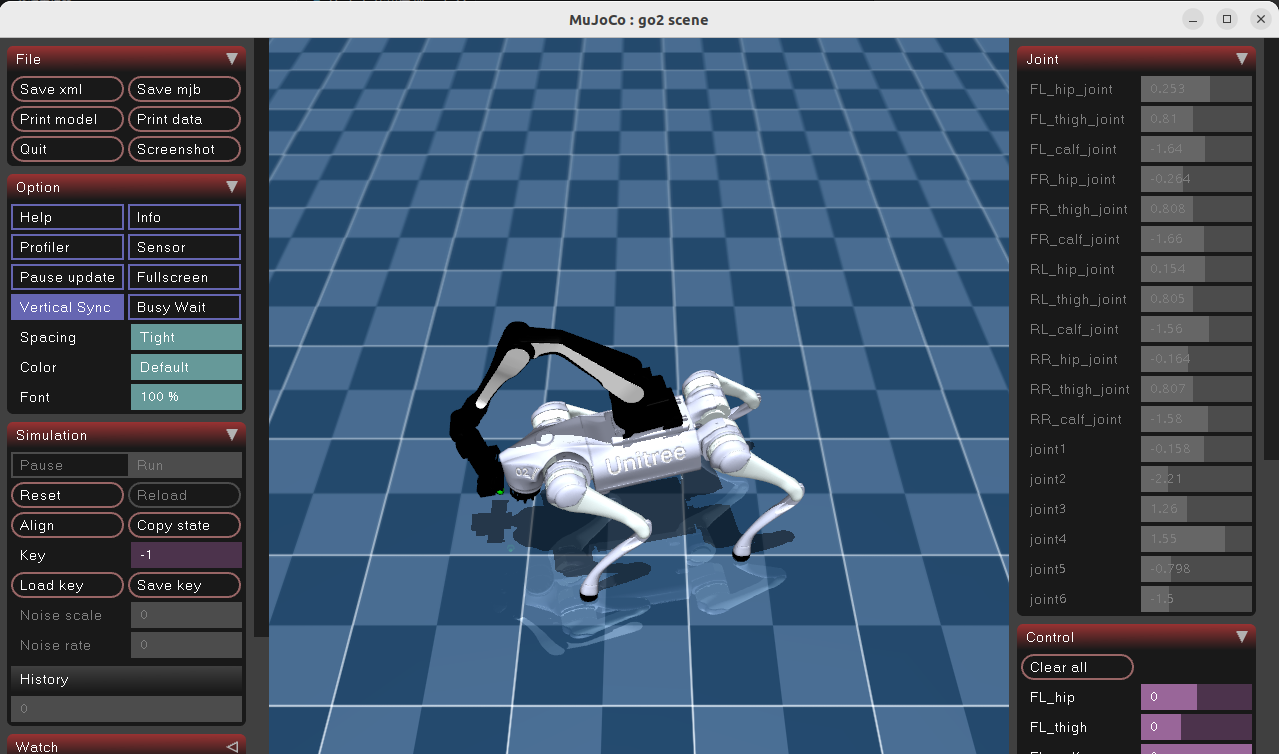
示例3:Go2机器狗 移动+操作
bash
# Go2机器狗 移动+操作
uv run demo locomani运行效果
三、机器人训练 与 评估
支持多种机器人、不同任务,参考链接:https://unilabsim.github.io/UniLab-doc/en/2-user_guide/4-tasks/0-index.html
训练和评估在UniLab中共享相同的算法实现基础,但通过配置参数和执行标志实现了功能分离
uv run train 命令
- 入口函数 :
cli.py中的train_main()函数 - 路由逻辑 :根据
--algo参数选择不同的训练脚本 - 具体脚本对应关系 :
--algo appo→scripts/train_appo.py--algo ppo→scripts/train_rsl_rl.py--algo sac/td3/flashsac→scripts/train_offpolicy.py--algo mlx_ppo→scripts/train_mlx_ppo.py
详细参考第四章节的算法说明
uv run eval 命令
- 入口函数 :
cli.py中的eval_main()函数 - 路由逻辑:与 train 相同,但会添加评估专用参数
- 具体脚本对应关系 :与 train 命令相同,但会设置
training. play_only=true - 其中,algo.load_run=-1 (加载最新训练结果)
代码执行路径差异
训练路径
python
# 入口:src/unilab/cli.py → train_main()
# 根据 --algo 参数路由到不同训练脚本:
# - appo → scripts/train_appo.py
# - ppo → scripts/train_rsl_rl.py
# - sac/td3/flashsac → scripts/train_offpolicy.py
# - mlx_ppo → scripts/train_mlx_ppo.py评估路径
python
# 入口:src/unilab/cli.py → eval_main()
# 实际仍调用相同的训练脚本,但设置特殊标志:
# training.play_only = True
# algo.load_run = -1 (加载最新训练结果)
# render_mode = "interactive" 或 "record"关键配置参数差异
| 参数 | 训练模式 | 评估模式 | 作用 |
|---|---|---|---|
training.play_only |
False |
True |
禁用策略更新,仅执行策略 |
algo.load_run |
通常为 None |
-1 (最新) 或指定run ID |
指定要加载的模型 |
render_mode |
通常为 none |
interactive/record |
控制可视化行为 |
num_envs |
多环境并行 (最大化吞吐量) | 通常为1 (便于观察) | 环境数量设置 |
headless |
通常为 True (无GUI) |
根据需求设置 | 是否显示GUI |
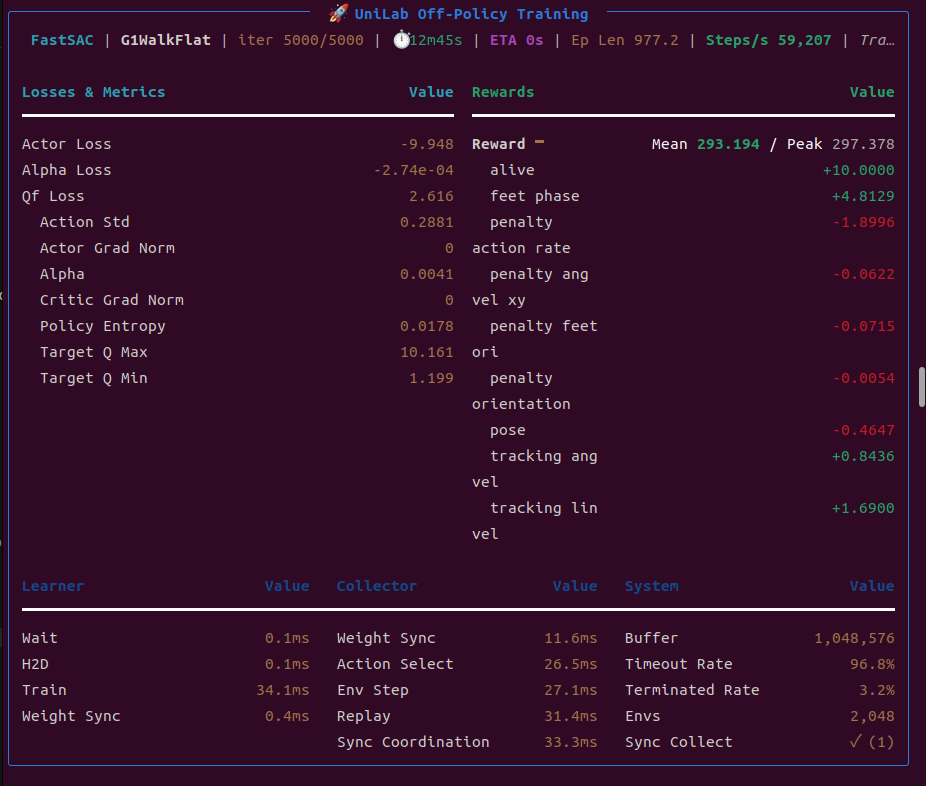
1、G1机器人 平地行走
对于G1机器人,进行训练与评估:
bash
# G1机器人在平面行走--训练
uv run train --algo sac --task g1_walk_flat --sim mujoco
# G1机器人在平面行走--验证,保存可视化结果
uv run eval --algo sac --task g1_walk_flat --sim mujoco --load-run -1训练结果:
训练好后,会保留模型权重(model_5000.pt)、可视化视频的
G1机器人在平面行走的效果:

如果 开着代理访问国内镜像站 hf-mirror.com 出现链路异常,可以参考下面进行修复:
bash
# 1. 彻底清空所有代理环境变量,排除代理干扰
unset http_proxy https_proxy all_proxy HTTP_PROXY HTTPS_PROXY ALL_PROXY no_proxy NO_PROXY
# 2. 重新设置 Hugging Face 国内镜像
export HF_ENDPOINT=https://hf-mirror.com
# 3. (可选)验证镜像站是否可通,正常会返回 200/302
curl -I https://hf-mirror.com
# 4. 重新执行训练
uv run train --algo sac --task g1_walk_flat --sim mujoco2、G1机器人 空翻
使用PPO的算法进行强化训练,默认训练2万轮,最终的效果比较稳定
bash
# G1机器人空翻--训练
uv run train --algo ppo --task g1_wall_flip_tracking --sim mujoco
# G1机器人空翻--验证,保存可视化结果
uv run eval --algo ppo --task g1_wall_flip_tracking --sim mujoco --load-run -1训练结果:
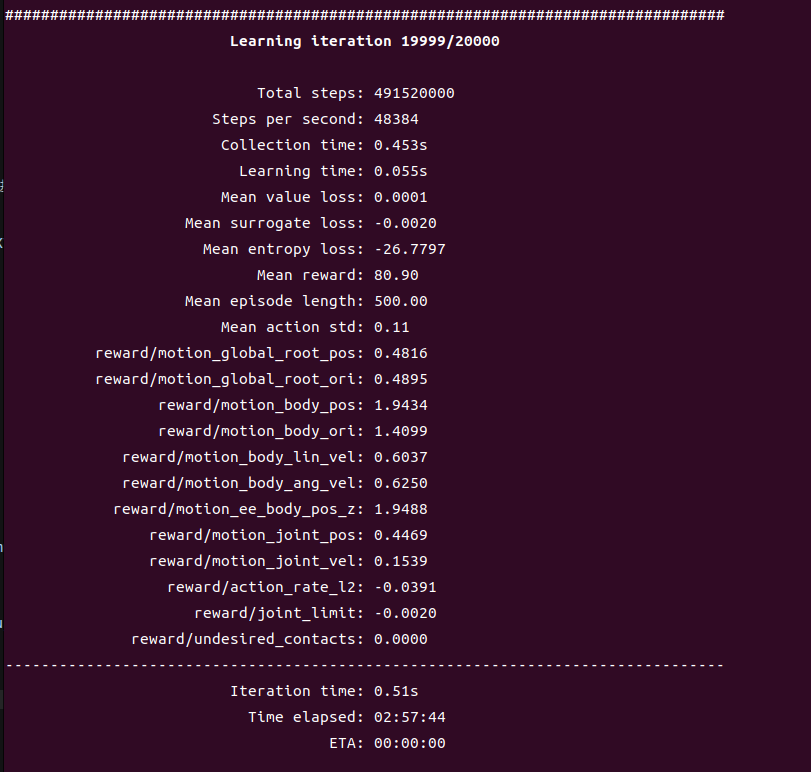
G1机器人空翻效果:


3、G1机器人 动作跟踪(舞蹈)
使用sac的算法进行强化训练,默认训练2.5万轮,最终的效果比较稳定
bash
# G1机器人动作跟踪--训练
uv run train --algo sac --task g1_motion_tracking --sim motrix
# G1机器人动作跟踪--验证,保存可视化结果
uv run eval --algo sac --task g1_motion_tracking --sim motrix --load-run -1训练结果:
bash
╭───────────────────────────────── 🚀 UniLab Off-Policy Training ─────────────────────────────────╮
│ FastSAC | G1MotionTrackingSAC | iter 0/25000 | ⏱ 0s | Warming up... │
│ │
╭───────────────────────────────── 🚀 UniLab Off-Policy Training ─────────────────────────────────╮
│ FastSAC | G1MotionTrackingSAC | iter 25000/25000 | ⏱ 1h01m33s | ETA 0s | Ep Len 264.0 | Steps/s... │
│ │
│ Losses & Metrics Value Rewards Value │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Actor Loss -9.425 Reward ━ Mean 27.937 / Peak 32.162 │
│ Alpha Loss 5.73e-05 action rate -0.2227 │
│ Qf Loss 3.907 l2 │
│ Action Std 0.1768 joint limit +0.0000 │
│ Actor Grad Norm 0.0094 motion body +0.3483 │
│ Alpha 7.84e-04 ang vel │
│ Critic Grad Norm 0.0338 motion body +0.8121 │
│ Policy Entropy -14.482 lin vel │
│ Target Q Max 9.818 motion body +0.8480 │
│ Target Q Min 5.634 ori │
│ motion body +1.9748 │
│ pos │
│ motion global +0.4823 │
│ root ori │
│ motion global +0.9764 │
│ root pos │
│ undesired +0.0000 │
│ contacts │
│ │
│ Learner Value Collector Value System Value │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Wait 0.1ms Weight Sync 12.4ms Buffer 1,048,576 │
│ H2D 0.1ms Action Select 32.1ms Timeout Rate 100.0% │
│ Train 22.2ms Env Step 32.5ms Terminated Rate 0.0% │
│ Weight Sync 0.4ms Replay 27.1ms Envs 2,048 │
│ Sync Coordination 49.2ms Sync Collect ✓ (1) │
╰───────────────────────────────────────────────────────────────────────────────────────────────────╯G1机器人舞蹈效果:
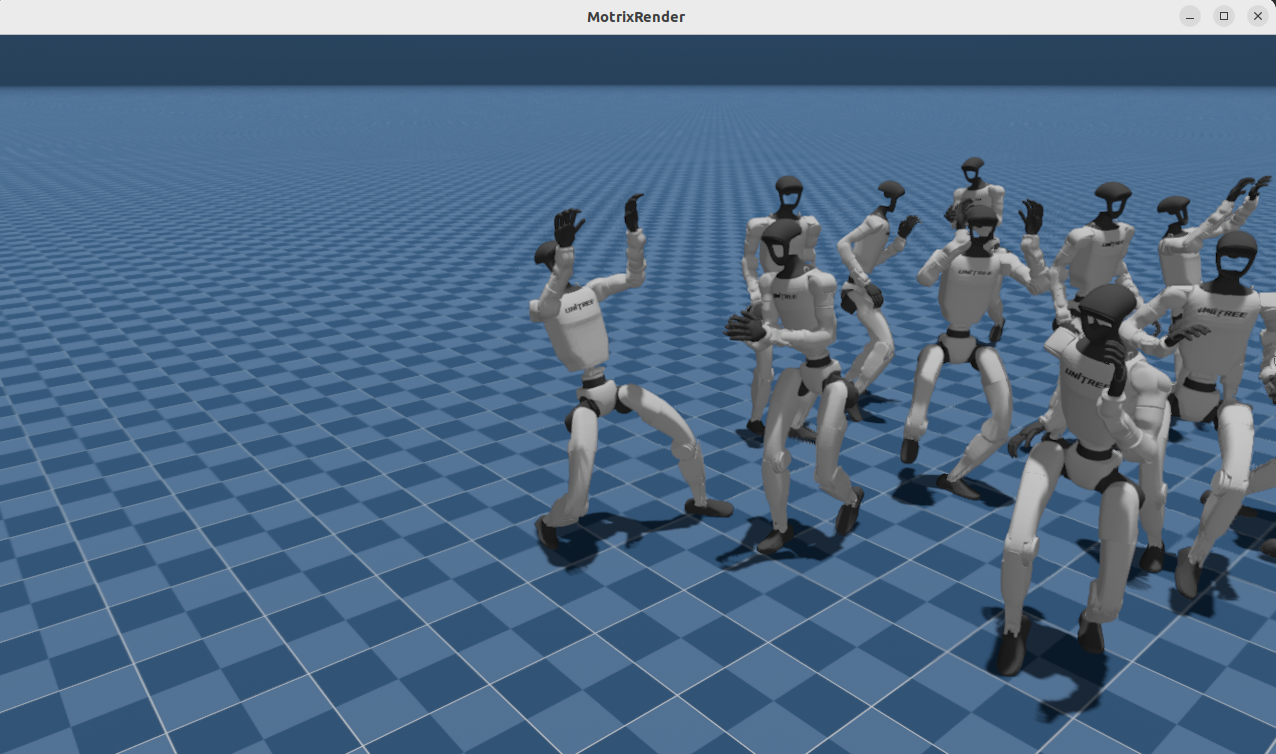
四、算法说明 与 模型推理
4.1、算法说明
bash
主要包含8种算法:
1-ppo
2-appo
3-sac
4-td3
5-flash_sac
6-him_ppo
7-hora
8-mlx_ppo这里描述每个算法:具体算法的内容入口、配置文件所在位置
| 算法 | 类型 | 入口 | 配置 |
|---|---|---|---|
| PPO | 同步 on-policy | scripts/train_rsl_rl.py |
conf/ppo/config.yaml |
| APPO | 异步 on-policy | scripts/train_appo.py |
conf/appo/config.yaml |
| SAC | off-policy | scripts/train_offpolicy.py |
conf/offpolicy/algo/sac.yaml |
| TD3 | off-policy | scripts/train_offpolicy.py |
conf/offpolicy/algo/td3.yaml |
| FlashSAC | off-policy | scripts/train_offpolicy.py |
conf/offpolicy/algo/flashsac.yaml |
| HIM-PPO | 高度估计器 PPO 路径 | scripts/train_him_ppo.py |
conf/ppo_him/config.yaml |
| HORA | teacher/student 蒸馏路径 | scripts/train_hora_distill.py |
conf/hora_distill/config.yaml |
| MLX PPO | 面向 Apple Silicon 的同步 on-policy | scripts/train_mlx_ppo.py |
conf/ppo/config_mlx.yaml |
不同算法使用示例:
bash
uv run train --algo ppo --task go2_joystick_flat --sim mujoco
uv run train --algo ppo --task go2_joystick_flat --sim motrix
uv run train --algo sac --task g1_walk_flat --sim mujoco- 常规用法下,使用 --task 和 --sim 选择 task 和 backend;
- 通过--algo 选择那一种算法,比如上面示例的ppo、sac。
4.2、模型推理、可视化验证
1、🎮 主要推理入口
scripts/play_interactive.py 是核心的实际推理代码,专为真实机器人部署设计:
核心功能:
-
多模式推理:
python# action_mode参数控制推理模式 action_mode = "policy" # 使用训练好的策略 action_mode = "zero" # 零动作(安全模式) action_mode = "keyboard" # 键盘控制(调试/演示模式) -
键盘控制接口:
python# 支持键盘速度命令(vx, vyaw) if keycode == _KEY_UP: commander.nudge(commander.AXIS_VX, +1.0) # 前进 if keycode == _KEY_DOWN: commander.nudge(commander.AXIS_VX, -1.0) # 后退 if keycode == _KEY_LEFT: commander.nudge(commander.AXIS_VYAW, +1.0) # 左转 if keycode == _KEY_RIGHT: commander.nudge(commander.AXIS_VYAW, -1.0) # 右转 -
真实机器人适配:
python# 检测是否为速度命令型locomotion任务 def _is_velocity_command_locomotion_task(env: Any) -> bool: # 验证任务名称是否包含"Joystick"、"Walk"等关键字 return any(marker in candidate for candidate in candidate_names for marker in ["Joystick", "Walk"])
play_interactive.py 是 UniLab 框架下专属 MuJoCo 物理后端的交互式策略回放调试工具,核心作用是加载训练完成的机器人强化学习策略,通过 MuJoCo 原生可视化窗口实现实时回放、交互控制与调试可视化。
具体核心功能如下:
- 多算法策略回放
支持PPO、APPO、SAC、FlashSAC、HORA多种算法的训练 checkpoint 加载与回放,兼容 rsl_rl 等训练框架的模型格式,自动解析模型输入维度与配置。 - 播放与交互控制
- 基础播放:空格暂停/继续、N 键单步执行、
+/-调节回放倍速、退格键重置环境 - 键盘遥操作:针对带速度指令的运动类任务,支持方向键下发线速度/角速度指令,回车键归零,直接控制机器人运动
- 基础播放:空格暂停/继续、N 键单步执行、
- 多层级调试可视化
运动目标叠加:显示参考运动的目标刚体位置、姿态坐标轴奖励调试叠加:同步渲染参考位姿、机器人力学位姿、运动目标位姿,支持速度向量、位姿误差连线、全局锚点的可视化速度指令箭头:运动任务中区分显示目标速度(绿色)与当前实际速度(蓝色),直观对比指令跟随效果
- 视角与渲染适配
- 自动跟随机器人基座,支持自定义相机距离、俯仰角、方位角、高度偏移
- 自动适配可视化模型,优先加载高画质渲染模型,失败时自动降级为回放模型
- 跨场景兼容
覆盖足式机器人运动、人形机器人运动跟踪、灵巧手操作等多类任务,自动匹配任务对应的环境、观测与奖励逻辑。
补充说明 :
play_interactive.py 是仅支持 MuJoCo 后端的交互式策略回放脚本,用于加载训练好的策略模型,在 MuJoCo 可视化窗口中实时推理、调试机器人行为。
即使你的模型是通过 Motrix 后端训练的,该脚本也可以读取对应后端的任务配置,但最终物理步进与渲染均使用 MuJoCo 完成。
模型推理------实践示例1
比如,上面用G1机器人进行了,运行跟踪,学习舞蹈,现在进行推理
训练指令:
bash
uv run train --algo sac --task g1_motion_tracking --sim motrix方式1:加载最新一次训练的模型(最常用)
使用 algo.load_run=-1 自动匹配最近一次完成的训练运行,加载其最新的 checkpoint:
bash
uv run scripts/play_interactive.py \
--algo sac \
--task g1_motion_tracking \
--sim motrix \
algo.load_run=-1 \
interactive.action_mode=policy运行效果:
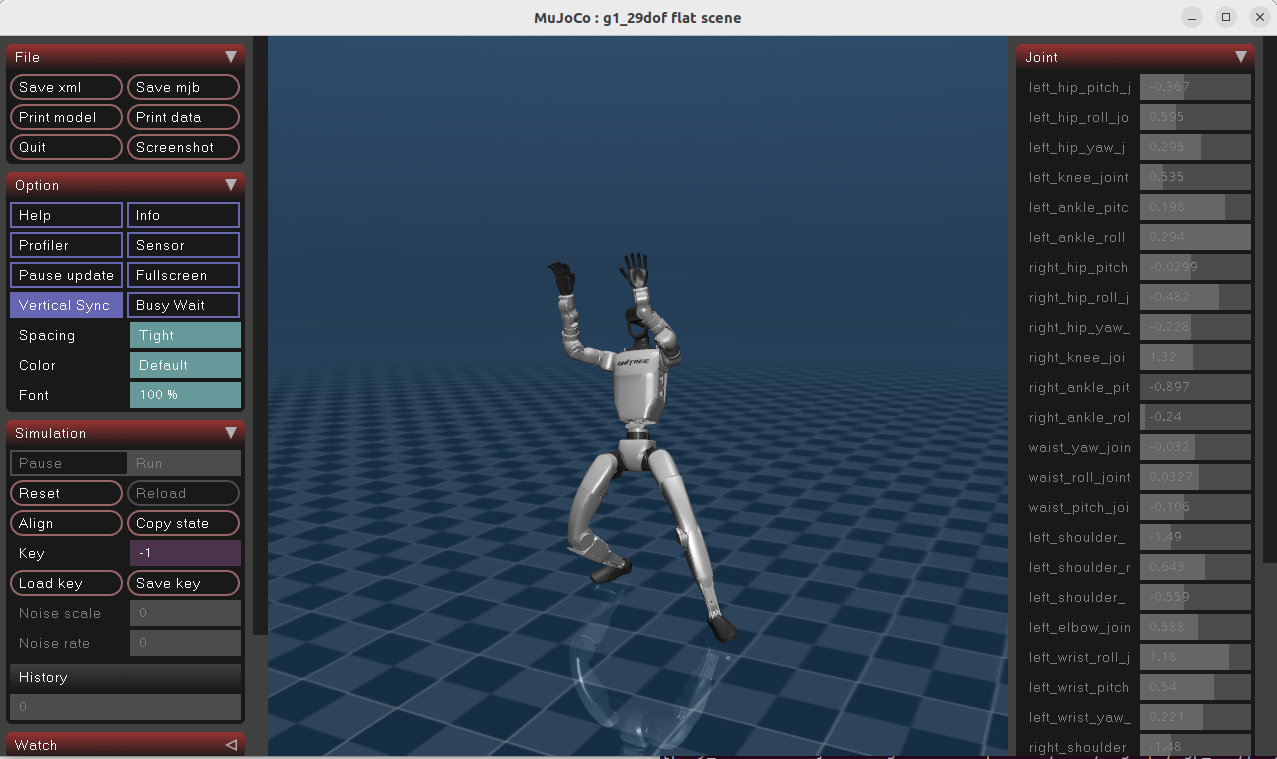
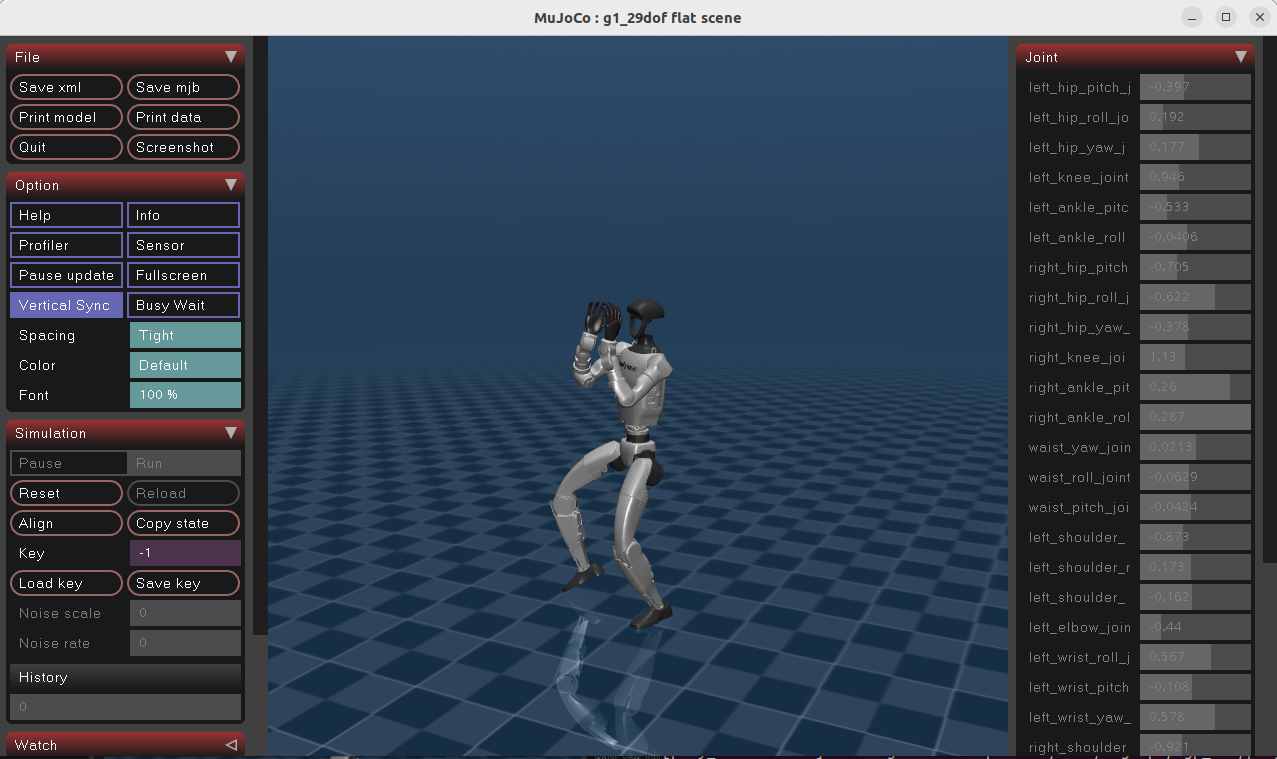
方式2:显示关节坐标系/奖励调试叠加层
显示关节坐标系/奖励调试叠加层
bash
uv run scripts/play_interactive.py \
--algo sac \
--task g1_motion_tracking \
--sim motrix \
algo.load_run=-1 \
interactive.action_mode=policy \
interactive.show_target_bodies=true \
interactive.target_show_axes=true \
interactive.show_reward_debug=true运行效果: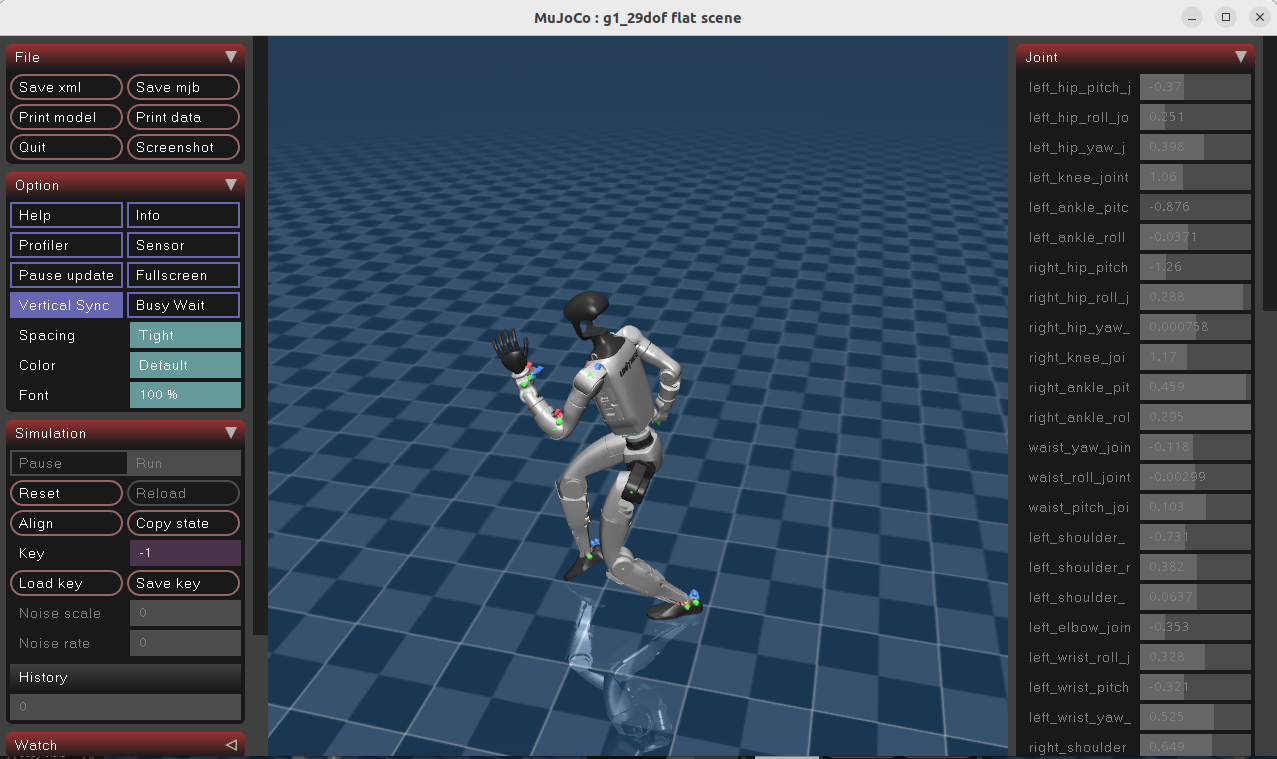
核心参数详解
| 参数分类 | 参数 | 说明 |
|---|---|---|
| 基础标识 | --algo |
必须与训练时的算法完全一致,支持 ppo/appo/sac/flashsac/hora_distill |
| 基础标识 | --task |
任务名,与训练命令保持一致 |
| 基础标识 | --sim |
训练时使用的物理后端(mujoco/motrix),用于读取对应任务配置 |
| 模型指定 | algo.load_run |
训练运行的编号:-1 表示最新一次运行,填数字则对应第N次训练 |
| 推理控制 | interactive.action_mode |
必须设为 policy 才会执行策略推理输出动作;否则为零动作回放,机器人不会运动 |
模型推理------实践示例2
比如,上面用G1机器人进行了空翻,现在进行推理
训练指令:
bash
uv run train --algo ppo --task g1_wall_flip_tracking --sim mujoco推理指令:
bash
uv run scripts/play_interactive.py \
--algo ppo \
--task g1_wall_flip_tracking \
--sim motrix \
algo.load_run=-1 \
interactive.action_mode=policy运行效果:
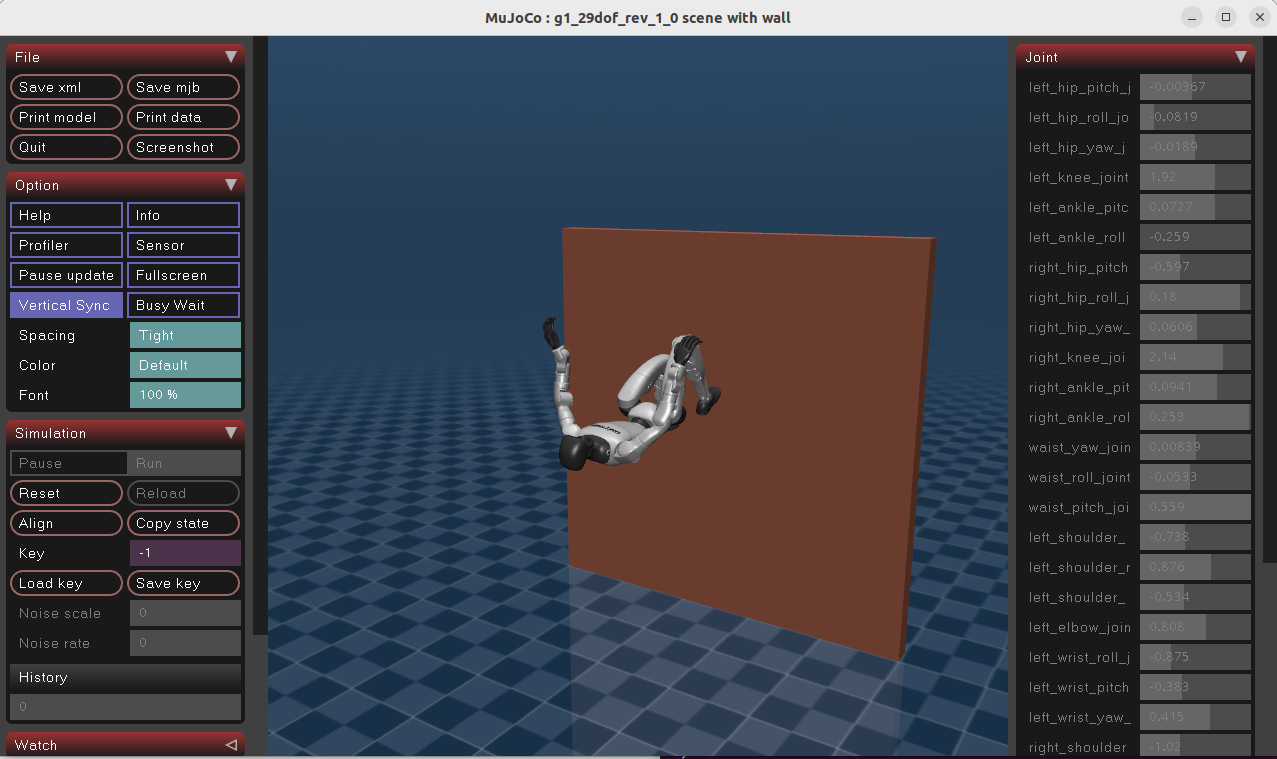
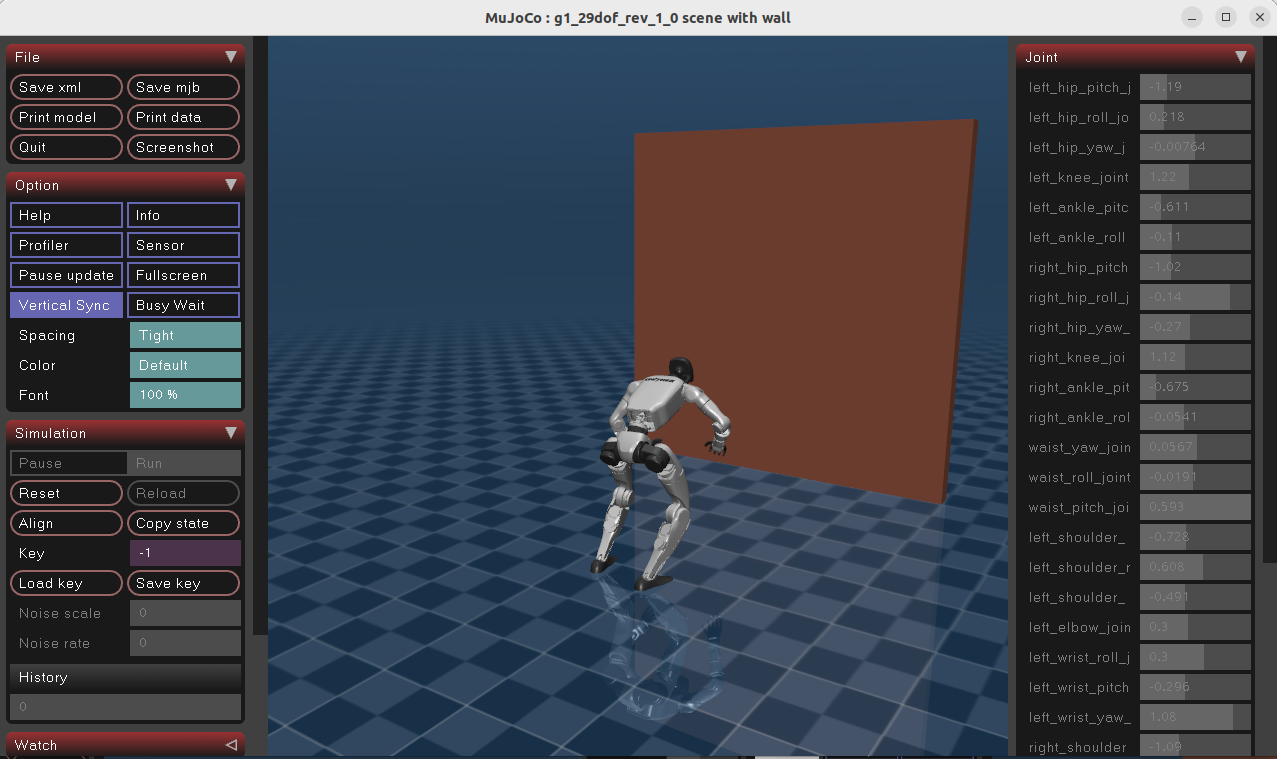
2、🌐 备选:Web可视化推理
scripts/play_viser.py 提供Web-based交互式推理,适合远程监控和调试:
bash
uv run scripts/play_viser.py task=go2_joystick_flat/mujoco \
interactive.action_mode=policy \
viser.port=8080- 通过浏览器访问
http://localhost:8080 - 支持多环境同时显示
- 无需本地图形界面,适合服务器部署
五、Sim2Real 部署指南
📁 关键部署脚本
项目中的 scripts/deploy 目录包含核心部署工具:
scripts/deploy/
├── export_deploy_config.py # 导出部署配置
├── export_motion_bin.py # 导出运动二进制文件
├── append_cooldown.py # 添加冷却阶段
├── prepend_warmup.py # 添加预热阶段
└── sim_prototype.py # 模拟原型测试5.1 仿真到真机总览
在 UniLab 中,一个可部署的策略是导出的策略加上所选任务 owner 使用的那套精确的观测与动作契约。G1 WBT 辅助路径将其物化为 policy.onnx、deploy_config.yaml 以及一个运动二进制文件;其他机器人需要一个等价的硬件侧运行时,它需要:
- 读取传感器 → 组装出策略在仿真中看到的同一个观测向量
- 通过一个支持所导出计算图的运行时来运行
policy.onnx - 将动作向量映射到环境
SimBackend所使用的同一套执行器接口
端到端流程:
#mermaid-svg-NDwMjH0D2AMqF52x{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-NDwMjH0D2AMqF52x .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-NDwMjH0D2AMqF52x .error-icon{fill:#552222;}#mermaid-svg-NDwMjH0D2AMqF52x .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-NDwMjH0D2AMqF52x .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-NDwMjH0D2AMqF52x .marker{fill:#333333;stroke:#333333;}#mermaid-svg-NDwMjH0D2AMqF52x .marker.cross{stroke:#333333;}#mermaid-svg-NDwMjH0D2AMqF52x svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-NDwMjH0D2AMqF52x p{margin:0;}#mermaid-svg-NDwMjH0D2AMqF52x .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-NDwMjH0D2AMqF52x .cluster-label text{fill:#333;}#mermaid-svg-NDwMjH0D2AMqF52x .cluster-label span{color:#333;}#mermaid-svg-NDwMjH0D2AMqF52x .cluster-label span p{background-color:transparent;}#mermaid-svg-NDwMjH0D2AMqF52x .label text,#mermaid-svg-NDwMjH0D2AMqF52x span{fill:#333;color:#333;}#mermaid-svg-NDwMjH0D2AMqF52x .node rect,#mermaid-svg-NDwMjH0D2AMqF52x .node circle,#mermaid-svg-NDwMjH0D2AMqF52x .node ellipse,#mermaid-svg-NDwMjH0D2AMqF52x .node polygon,#mermaid-svg-NDwMjH0D2AMqF52x .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-NDwMjH0D2AMqF52x .rough-node .label text,#mermaid-svg-NDwMjH0D2AMqF52x .node .label text,#mermaid-svg-NDwMjH0D2AMqF52x .image-shape .label,#mermaid-svg-NDwMjH0D2AMqF52x .icon-shape .label{text-anchor:middle;}#mermaid-svg-NDwMjH0D2AMqF52x .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-NDwMjH0D2AMqF52x .rough-node .label,#mermaid-svg-NDwMjH0D2AMqF52x .node .label,#mermaid-svg-NDwMjH0D2AMqF52x .image-shape .label,#mermaid-svg-NDwMjH0D2AMqF52x .icon-shape .label{text-align:center;}#mermaid-svg-NDwMjH0D2AMqF52x .node.clickable{cursor:pointer;}#mermaid-svg-NDwMjH0D2AMqF52x .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-NDwMjH0D2AMqF52x .arrowheadPath{fill:#333333;}#mermaid-svg-NDwMjH0D2AMqF52x .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-NDwMjH0D2AMqF52x .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-NDwMjH0D2AMqF52x .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-NDwMjH0D2AMqF52x .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-NDwMjH0D2AMqF52x .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-NDwMjH0D2AMqF52x .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-NDwMjH0D2AMqF52x .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-NDwMjH0D2AMqF52x .cluster text{fill:#333;}#mermaid-svg-NDwMjH0D2AMqF52x .cluster span{color:#333;}#mermaid-svg-NDwMjH0D2AMqF52x div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-NDwMjH0D2AMqF52x .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-NDwMjH0D2AMqF52x rect.text{fill:none;stroke-width:0;}#mermaid-svg-NDwMjH0D2AMqF52x .icon-shape,#mermaid-svg-NDwMjH0D2AMqF52x .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-NDwMjH0D2AMqF52x .icon-shape p,#mermaid-svg-NDwMjH0D2AMqF52x .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-NDwMjH0D2AMqF52x .icon-shape .label rect,#mermaid-svg-NDwMjH0D2AMqF52x .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-NDwMjH0D2AMqF52x .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-NDwMjH0D2AMqF52x .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-NDwMjH0D2AMqF52x :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-NDwMjH0D2AMqF52x .step>*{fill:#e6f7ff!important;stroke:#1890ff!important;}#mermaid-svg-NDwMjH0D2AMqF52x .step span{fill:#e6f7ff!important;stroke:#1890ff!important;} 核心验证点
iterate
训练收敛
训练收敛
跨后端验证
导出验证
延迟匹配
安全层
硬件启动
闭环验证
Train in UniLab
Curriculum + DR
Validate in alt backend
Export ONNX
Latency / lag injection
Safety layer
Hardware bringup
Closed-loop run
奖励稳定
成功判据稳定
MuJoCo & Motrix
ONNX校验
训练/部署同步
畸形观测过滤
传感器校准
动作轨迹比对
流程图说明:
- 纵向结构:从上到下展示完整流程,符合阅读习惯
- 关键验证点:每个环节标注核心验证要求(灰色子图)
- 迭代路径:闭环验证(H)后自动返回训练阶段(B),形成持续优化循环
- 视觉优化 :
- 蓝色节点突出核心步骤
- 箭头标注具体验证要求
- 闭环迭代路径用虚线明确标识
上机前检查清单:
- 一次收敛的训练运行,奖励稳定,且成功判据也稳定(运动跟踪误差、跌落次数等)
- 当 MuJoCo 与 Motrix 都支持该任务时,同一策略在两者中都能通过评估
- 域随机化范围足够大,使得在扫动 DR 强度时奖励平滑变化
- 环境中没有后端功能泄漏
- 一份你能在硬件上实现的观测规格
最常见的失败模式:
- 观测漂移:仿真与部署运行时之间的传感器预处理不同(单位、坐标系、滤波截止频率)
- 动作延迟:测量部署回路,并在硬件运行前让训练 owner 匹配该契约
- 摩擦/阻尼不匹配:尤其对于手内操作。在 DR 中扫动摩擦
- 复位瞬态:安全层必须在畸形观测与不安全动作到达电机驱动器之前将其拒绝
5.2 ONNX 运行时部署
UniLab 从既有的训练回放路径导出 ONNX 策略。使用产出该检查点的同一算法家族与任务 owner;回放代码加载检查点、导出 policy.onnx,并在该路径实现了 ONNX Runtime 检查时校验所导出的计算图。
导出路径:
| 算法路径 | 入口脚本 | 仓库中的导出行为 |
|---|---|---|
| PPO(torch) | scripts/train_rsl_rl.py | 脚本入口处 EXPORT_POLICY=True;回放调用 runner.export_policy_to_onnx(...) 与 runner.export_policy_to_jit(...) |
| HIM-PPO | scripts/train_him_ppo.py | 与 PPO 相同的脚本级导出模式 |
| APPO | scripts/train_appo.py | 回放写出 policy.onnx 并将 ONNX Runtime 输出与 PyTorch 比对校验 |
| SAC / TD3 / FlashSAC | scripts/train_offpolicy.py | 回放写出 policy.onnx;SAC 与 FlashSAC 在导出前使用 actor.as_export_module() |
| MLX PPO | scripts/train_mlx_ppo.py | 回放将 MLX actor 权重转换为 PyTorch 模块,写出 policy.onnx,并校验 ONNX Runtime 输出 |
导出命令:
bash
# PPO算法示例
uv run eval --algo ppo --task go2_joystick_flat --sim mujoco --load-run -1
# APPO算法示例
uv run eval --algo appo --task g1_motion_tracking --sim motrix --load-run -1
# SAC算法示例
uv run eval --algo sac --task g1_walk_flat --sim mujoco --load-run -15.3 G1 全身运动跟踪部署
硬件目标: Unitree G1 人形机器人(29 自由度变体)。假定关节顺序与 scripts/deploy/export_deploy_config.py 从 src/unilab/assets/robots/g1/scene_flat.xml 导出的顺序一致。
0. 验证你的仿真侧检查点
bash
uv run eval --algo ppo --task g1_motion_tracking --sim motrix --load-run -1 --render-mode record在视频中要关注:
- 被跟踪的各 body 跟随参考运动,没有大的不连续
- 关节速度与动作保持有限且在预期范围内
- 接触时序看起来与参考运动一致
1. 导出部署文件
bash
# 导出ONNX策略
uv run eval --algo ppo --task g1_motion_tracking --sim motrix --load-run -1
# 导出部署配置
uv run scripts/deploy/export_deploy_config.py --output logs/deploy/deploy_config.yaml
# 导出运动二进制
uv run scripts/deploy/export_motion_bin.py --output logs/deploy/dance1.bin部署侧原型消费如下文件:
runs/<run>/
└── policy.onnx
logs/deploy/
├── deploy_config.yaml
└── dance1.bin2. 观测契约
对于已提交的 G1 WBT 部署辅助工具,观测布局会作为 obs_layout 导出到 deploy_config.yaml:
| 分组 | 维度 | 硬件上的来源 |
|---|---|---|
| command_joint_pos | 29 | 运动参考帧的关节位置 |
| command_joint_vel | 29 | 运动参考帧的关节速度 |
| motion_anchor_ori_b | 6 | 来自参考帧与机器人躯干帧的锚点朝向项 |
| gyro | 每个历史步 3 | IMU 陀螺仪项 |
| joint_pos_rel | 每个历史步 29 | 测量到的关节位置减去 default_angles |
| dof_vel | 每个历史步 29 | 关节速度项 |
| last_actions | 29 | 上一步的原始 actor 输出 |
3. 执行器接口
G1 部署原型将 actor 输出严格映射为:
action * action_scale + default_angles然后钳制到 joint_lower / joint_upper,并应用来自 ema_alpha 的 EMA 平滑。
4. 参考运动同步
相位变量让策略能够跟踪一个外部提供的运动片段。在硬件上你需要一个墙钟 → 相位的映射,它必须:
- 单调 ------ 不向后跳跃
- 可重启 ------ 在通信抖动后仍能存活,不会在
(sinφ,cosφ)中产生阶跃式不连续 - 速率有界 ------ 将 dφ/dt 钳制到策略训练时所用的值
5. 安全层
硬件侧安全层要求:
- 在应用
action_scale之前拒绝非有限动作与形状不匹配 - 用
deploy_config.yaml中的joint_lower/joint_upper钳制生成的目标 - 把看门狗、姿态监控以及操作员停止阈值保留在部署控制器中
6. 闭环上机序列
- 支架上站立:机器人由龙门架吊挂。策略运行,但执行器关闭力矩。确认观测管线。
- 使能力矩、手扶:操作员护着机器人。策略指挥执行器。确认动作映射。
- 龙门架支撑步态:以半时间速率跟踪运动(dφ/dt 减半)。
- 自由站立:全速率,然后移除龙门架。
7. 验证与记录
为每一步记录完整的观测向量、完整的动作向量与墙钟。在硬件上机前,通过 MuJoCo 部署原型验证:
bash
uv run scripts/deploy/sim_prototype.py \
--onnx runs/<run>/policy.onnx \
--config logs/deploy/deploy_config.yaml \
--motion logs/deploy/dance1.binONNX 输入宽度与 deploy_config.yaml 的 obs_dim 之间的不匹配是部署契约 bug,而不是硬件调参问题。
5.4 部署验证与调试
关键验证点:
- ONNX 输入维度必须与部署配置中的
obs_dim完全匹配 - 动作映射必须与仿真中的执行器接口一致
- 传感器预处理必须在仿真和硬件之间保持一致
- 时序特性(延迟、采样率)必须在训练和部署之间匹配
调试建议:
- 从简单的开环测试开始,逐步过渡到闭环
- 记录完整的观测-动作轨迹,用于离线分析
- 使用仿真原型验证部署配置,避免硬件损坏
- 实现详细的日志记录,包括安全层触发事件
新增算法、新增不同地形,新增机器人任务,可以参考:https://unilabsim.github.io/UniLab-doc/zh_CN/4-developer_guide/0-index.html
分享完成~