当OpenBMB 开源社区发布 Ultra-FineWeb-L3 与 UltraData-SFT-2605,两份面向 MiniCPM5-1B 训练链路的核心数据集时,一个更值得中文 AI 社区关注的问题浮出水面:高质量模型能力的背后,正在形成怎样的数据基础设施?
这不是一次简单的数据集上新。它更像是一次信号:大模型竞争正在从"谁能堆更多数据",走向"谁能更系统地治理数据、验证数据、复用数据"。
在这套数据治理体系中,OpenCSG Chinese Corpus 以及 Chinese FineWeb 系列数据被相关研究使用、引用和纳入讨论。对于 OpenCSG 来说,这意味着我们的中文数据工作不只是一个独立发布的数据集,而是在更大的开源大模型训练生态中,成为中文高质量语料工程的一块重要底座。
MiniCPM5-1B 核心数据公开:两类关键数据支撑完整训练链路
Part.1
1 OpenBMB 发布两大 MiniCPM5-1B 核心数据集
2026 年5月28日,面壁智能联合清华大学、OpenBMB 开源社区发布并开源两大最新数据集:Ultra-FineWeb-L3 与 UltraData-SFT-2605。两者均属于 OpenBMB 的 UltraData Collection,并已在 MiniCPM5-1B 的训练流程中得到验证,覆盖从预训练退火到后训练 SFT 的关键环节。
Ultra-FineWeb-L3面向预训练退火阶段,官方介绍其包含高质量中文与英文网页合成数据,总量超过 600B tokens,其中英文 400B+ tokens,中文 200B+ tokens。它的目标不是简单扩大网页语料规模,而是把网页文本从"可读"进一步转化为"好学",提升单位 token 对模型能力的贡献。
UltraData-SFT-2605面向后训练 SFT 阶段,是 MiniCPM5-1B-SFT 使用的核心领域 SFT 数据。根据官方介绍,它是千万级规模、同时包含深思考与非思考标注的 SFT 数据集,覆盖数学、代码、知识、指令遵循等核心方向。
这次发布可以抓住三个关键词:
**01预训练退火:**Ultra-FineWeb-L3 为模型训练后期提供更高密度的网页合成数据。
02后训练 SFT:UltraData-SFT-2605 为模型补充指令遵循、推理、代码、数学等核心能力。
03端侧验证:两份数据均在 MiniCPM5-1B 训练链路中完成验证,说明高质量数据已经成为 1B 级小模型能力跃迁的关键变量。
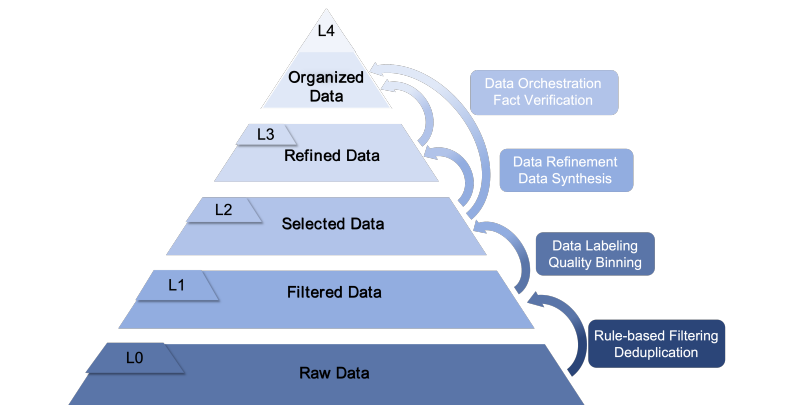
2 Ultra-FineWeb-L3:把网页文本从"可读"变成"好学"
Ultra-FineWeb-L3 是 UltraData 分级治理体系在通用网页数据上的 L3 实践。
传统网页语料处理,更多解决的是"能不能读"的问题:文本是否完整,语言是否正确,重复是否过多,噪声是否明显。但对大模型训练来说,仅仅可读还远远不够。模型真正需要的是结构清晰、信息密度高、任务信号明确、容易被学习的数据。
Ultra-FineWeb-L3 的核心思路,就是以 L2 精筛后的高质量网页数据 Ultra-FineWeb 为种子,通过问答对生成、多风格改写、知识提取等方式,把普通网页文本转化为更具训练价值的合成数据。换句话说,它不是把网页数据简单"洗干净",而是进一步把文本加工成更适合模型吸收的知识材料。
可读是基础,好学才是模型训练真正需要的高阶属性。
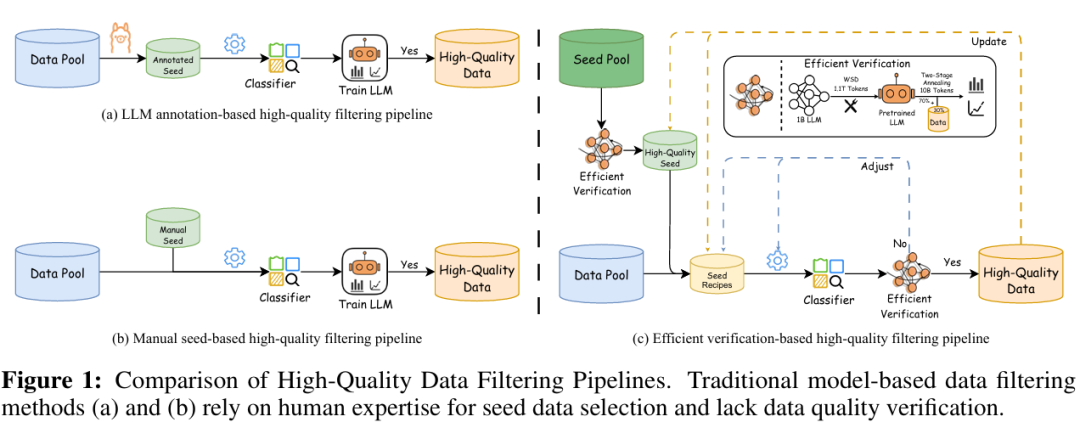
在 Ultra-FineWeb 技术报告中,研究团队提出了高效的数据过滤和验证策略。传统模型驱动的数据过滤方法往往依赖人工经验选择种子数据,且缺少及时的数据质量验证机制。Ultra-FineWeb 则引入高效验证策略,用更低成本评估数据对模型训练的实际影响,并据此优化正负样本选择和分类器训练。
这一方法被应用于 FineWeb 与 Chinese FineWeb 等预训练语料,形成更高质量的 Ultra-FineWeb 数据集。需要注意的是,技术报告中的 Ultra-FineWeb 包含约 1T 英文 tokens 与 120B 中文 tokens;而此次 Ultra-FineWeb-L3 是在 UltraData 框架下进一步精炼后的 L3 数据,规模为 600B+ tokens,其中中文 200B+ tokens。
从实验结果看,高质量数据带来的提升并不是停留在概念层面。Ultra-FineWeb 技术报告显示,在英文与中文多个基准任务上,Ultra-FineWeb 相比 FineWeb、FineWeb-edu 等数据集取得了更好的平均表现,并且随着训练推进,高质量数据的优势持续显现。
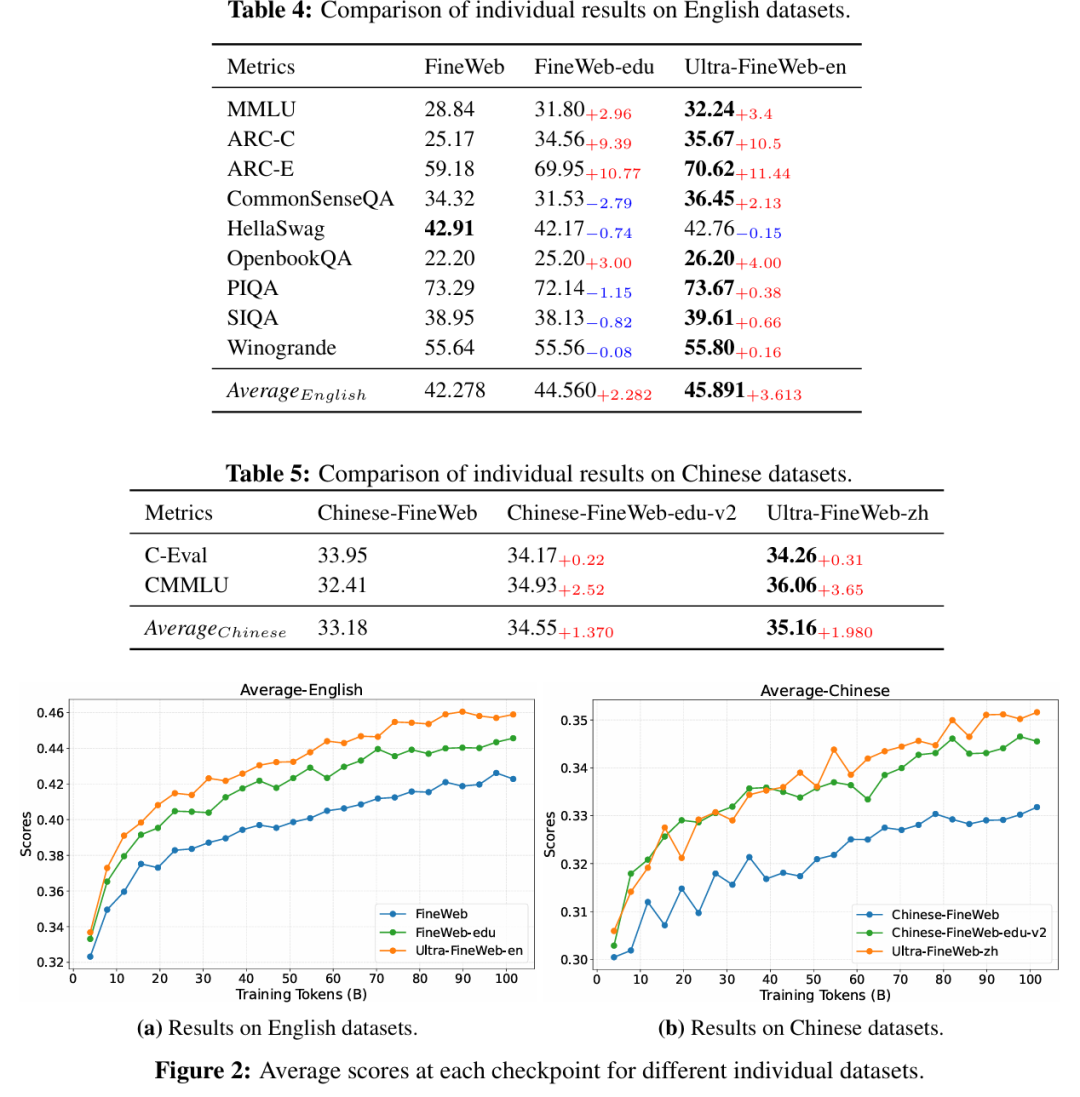
这说明,在模型训练后期,数据的"质量密度"比单纯规模更加关键。对小模型尤其如此:参数规模有限时,每个 token 都要尽可能携带更多有效信号,才能帮助模型在有限训练预算下获得更强能力。
3 UltraData-SFT-2605:让小模型同时学会快答与深思考
如果说 Ultra-FineWeb-L3 解决的是预训练退火阶段"学什么、怎么学得更有效"的问题,那么 UltraData-SFT-2605 解决的是后训练阶段"如何回答、如何推理、如何遵循指令"的问题。
SFT 数据决定了模型从知识记忆走向任务执行的能力。一个模型可能在预训练中见过大量知识,但如果缺少高质量 SFT,它仍然可能无法稳定遵循指令,无法把复杂问题拆解成可执行步骤,也无法在不同场景中选择合适的回答方式。
UltraData-SFT-2605 的特点,可以概括为"两类信号 + 一条治理链":
**01非思考数据:**面向快速响应场景,训练模型直接给出简洁、准确、可用的回答。很多真实应用并不需要长篇推理链,用户需要的是低延迟、低成本、直接有效的结果。
**02深思考数据:**面向复杂任务场景,训练模型进行推理、规划、验证和多步骤求解。对于数学、代码、知识问答、复杂指令遵循等任务,模型需要的不只是答案,还需要更稳定的问题分析和推演能力。
**03质量治理链路:**从 Query 构造与筛选,到 Answer 质量控制,再到 benchmark 去污与训练验证,尽可能确保进入训练的数据干净、有效、可追溯。
这种双能力设计,对端侧小模型尤其重要。端侧模型既要轻量高效,又要在关键任务上具备足够强的推理能力。UltraData-SFT-2605 通过同时提供快答与深思考训练信号,为 MiniCPM5-1B 这样的 1B 级端侧模型补足后训练能力。
这与 UltraData 的整体思想是一致的:数据不是一次性消耗品,而是需要被评估、被组织、被验证的战略资产。
科学与技术OpenCSG Chinese FineWeb:从中文数据基石到 AI 数据基础设施
Part.2
1全OpenCSG Chinese Corpus:进入更大数据生态的中文基础设施
在这次 UltraData 相关工作中,OpenCSG 的意义并不在于"参与发布 UltraData",而在于 OpenCSG Chinese Corpus 和 Chinese FineWeb 系列数据作为高质量中文数据基础,被相关技术报告和论文使用、引用、纳入讨论。
Ultra-FineWeb 技术报告明确提到,其过滤流程被应用于 FineWeb 与 Chinese FineWeb 等预训练语料,并引用了 OpenCSG Chinese Corpus 论文。《Data Science and Technology Towards AGI Part I: Tiered Data Management》也在开源数据基础的整理中,将 Chinese FineWeb-edu / OpenCSG Chinese Corpus 纳入相关讨论。

OpenCSG Chinese Corpus 论文系统提出了一系列面向 LLM 训练的高质量中文数据集,包括 Fineweb-edu-chinese、Fineweb-edu-chinese-v2、Cosmopedia-chinese 和 Smoltalk-chinese,覆盖预训练、后训练和微调等不同阶段。
其中,Fineweb-edu-chinese 系列聚焦高质量中文网页文本。它从多源中文语料出发,引入教育价值打分机制,使用 Qwen 系列模型对样本进行评分,再训练 BERT-based scorer 对大规模语料进行过滤,并通过 MinHash 等方法进行去重。论文显示,Fineweb-edu-chinese v1 包含约 8900 万条高质量样本,约 200B tokens;v2 进一步扩展到超过 1.8 亿条样本,约 420B tokens。
Cosmopedia-chinese 面向知识密集型训练,基于高质量种子数据生成教材式、章节式内容,增强模型对结构化知识的学习能力。Smoltalk-chinese 面向多轮对话与指令微调,通过系统提示词和强中文模型生成多样化对话数据,并结合自动评分、分类和去重流程降低重复与风格偏差。
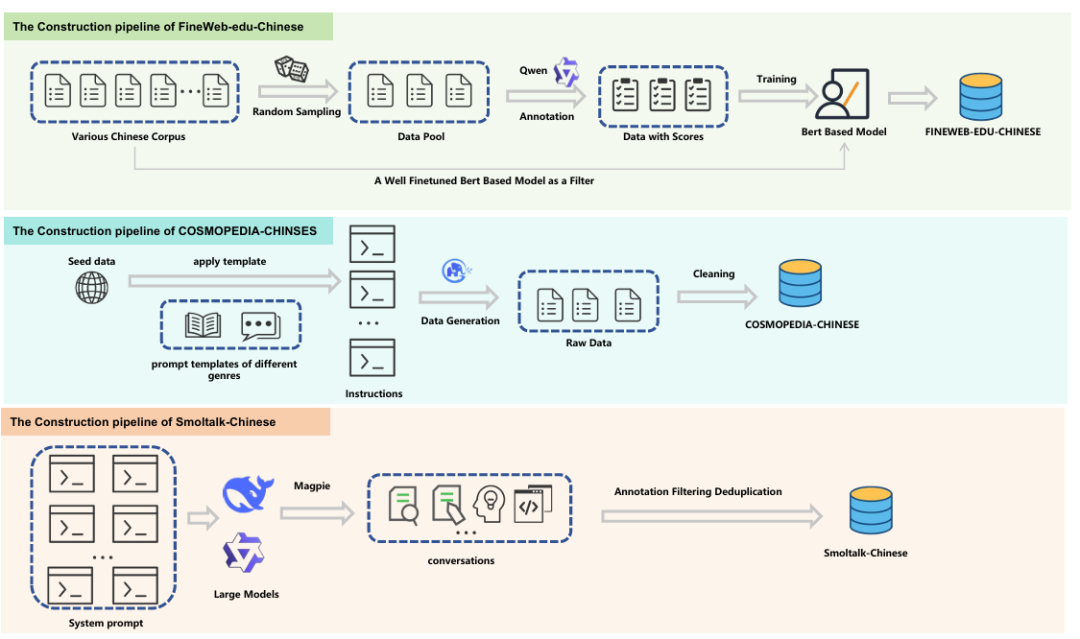
从这张流程图可以看到,OpenCSG Chinese Corpus 并不是单一形态的数据集合,而是覆盖多条数据生产链路:
**01网页过滤:**面向预训练,提供大规模高质量中文网页语料。
**02教材式合成:**面向知识密集型学习,生成更结构化、更连贯的中文知识文本。
**03多轮对话构建:**面向指令微调和对齐,提供多样化任务与会话数据。
这正是 OpenCSG Chinese Corpus 的核心价值:它服务的不是某一个孤立任务,而是中文大模型训练的多个关键阶段。
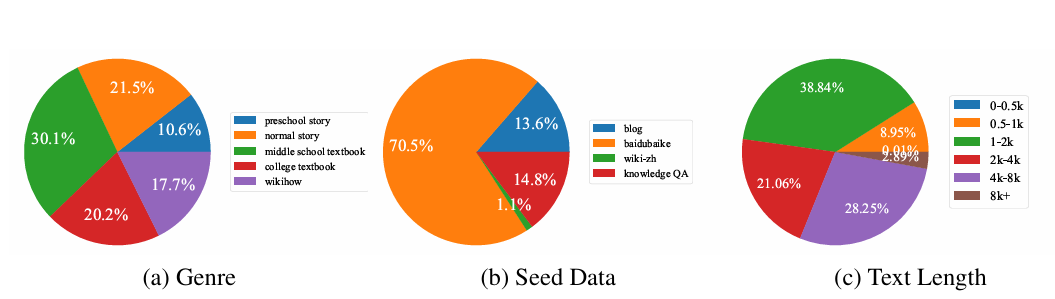
2为什么 Chinese FineWeb 能成为中文数据链路的基础层?
在分级数据管理框架中,L1 层看似不如 L3 精炼数据"高级",但它的作用非常关键。它向下连接原始互联网数据,向上支撑模型精选、合成增强和训练验证。如果 L1 层质量不稳,后续 L2 分类器会在大量噪声中消耗成本,L3 合成也容易被低质量种子污染。
Chinese FineWeb 的价值,正是在中文 Web 数据领域提供了这样一层地基。中文互联网文本有其特殊复杂性,OpenCSG Chinese FineWeb 系列针对这些问题进行了系统处理:
**01语言与编码复杂:**中英混杂、繁简混用、编码错误会影响模型学习,数据需要经过语言过滤与格式规范化。
**02网页噪声复杂:**广告、模板、导航、低质页面会稀释训练信号,需要进行质量评估和低质内容剔除。
**03重复形态复杂:**完全重复、近似重复、模板化重复都很常见,需要通过 MinHash 等方法降低冗余。
**04来源分布复杂:**不同中文语料来源的风格和质量差异明显,需要在规模、质量、多样性之间取得平衡。
3从"一个数据集"到"中文 AI 数据基础设施"
OpenCSG Chinese Corpus 的价值,远不止提供几份可下载的数据集。更准确地说,它正在把中文数据能力沉淀为一套可复用的基础设施。
**01降低重复工程成本。**中文 Web 数据清洗涉及语言识别、编码处理、广告过滤、近重复去除、格式规范化、质量评分等环节。OpenCSG 将这些数据工作开放出来,让研究者和开发者可以在更高起点上继续构建。
**02提供可参考的质量基线。**当越来越多研究工作使用或引用 Chinese FineWeb / OpenCSG Chinese Corpus,中文数据质量评估就不再只是各自为战,而能逐步形成可比较、可复现的共同参考。
**03连接多个训练阶段。**Fineweb-edu-chinese 系列提供网页基础语料,Cosmopedia-chinese 提供知识密集型合成文本,Smoltalk-chinese 提供对话和指令数据。它们组合起来,构成了一套更完整的中文 LLM 数据体系。
**04输出开源数据治理方法论。**OpenCSG 不只是释放结果,也通过论文和数据说明披露构建思路、处理流程与技术选择,让社区能够理解这些数据是如何被生产出来的,并在此基础上继续改进。
这也是为什么我们认为,OpenCSG Chinese Corpus 提供的不是一批孤立数据,而是中文高质量语料工程的一块底座。
4高质量中文数据,
正在成为小模型能力跃迁的关键燃料
MiniCPM5-1B 所代表的端侧小模型路线,对数据质量提出了更高要求。
大模型可以在参数规模和训练 token 上获得一定冗余,而小模型没有太多浪费空间。它必须在更有限的参数、更有限的训练预算下,尽可能学到高密度知识、通用能力和任务执行方式。因此,端侧小模型的能力提升,比以往更依赖高质量数据。
Ultra-FineWeb-L3 和 UltraData-SFT-2605 的开源,正好说明了这一点:**预训练退火需要更"好学"的网页合成数据,后训练 SFT 需要同时覆盖快答与深思考的指令数据。**模型能力的提升,不只是模型结构或训练技巧的胜利,也是数据治理能力的胜利。
而 OpenCSG Chinese Corpus 和 Chinese FineWeb 系列进入相关研究和数据生态,也说明中文数据基础设施正在被更多前沿工作看见。中文 AI 的发展,不能长期依赖闭源语料和不可复现流程。真正可持续的生态,需要开放、透明、可验证、可复用的数据基础。
当 UltraData 把数据治理推向 L3,当 MiniCPM5-1B 用完整训练链路验证这些数据,OpenCSG Chinese Corpus 所代表的中文数据基础设施,也正在证明自己的长期价值。
行业标杆地位的验证
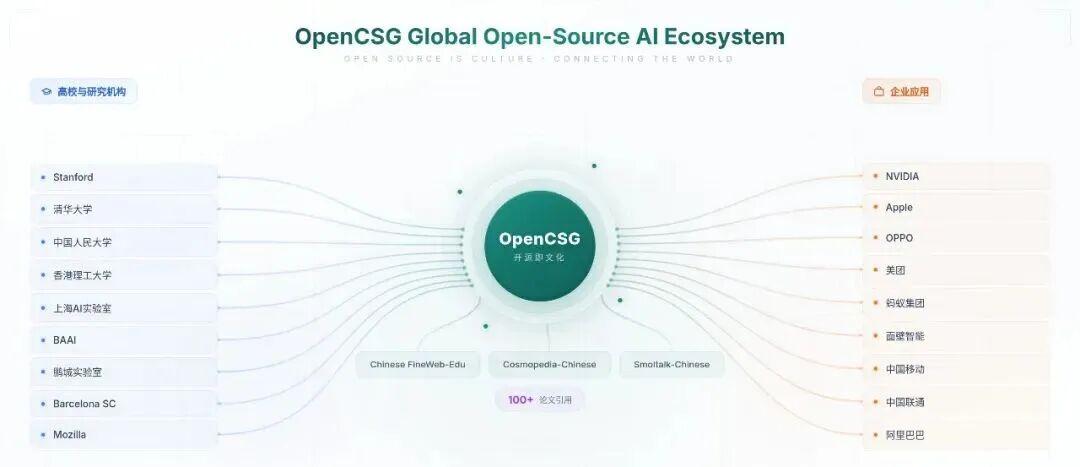
OpenCSG发布的FineWeb-Edu-Chinese作为全球下载量排名前三的中文预训练数据集,累计下载超百万次,其价值已经得到业界广泛认可:
- 学术领域: 被斯坦福大学、清华大学、中国人民大学高瓴人工智能学院、上海人工智能实验室、北京智源研究院 等 20 余家顶尖机构的论文引用。旗下 Chinese Fineweb Edu 已成为中文 NLP 研究的核心数据资源,被 100 + 篇学术论文引用,在 NeurIPS、ACL、EMNLP、ICLR 等国际顶会及 Nature 子刊、JMLR 等权威期刊中作为核心实验数据集,支撑大模型预训练、指令微调等前沿研究,合作机构还包括鹏城实验室、西南电子技术研究所、西班牙国家级超算中心(Barcelona Supercomputing Center)及 Mozilla Data Collective等全球顶尖科研单位。
- 产业应用: 支撑 Llama3-Chinese、DeepSeek 等知名模型训练,并被中国移动、中国联通、英伟达(NVIDIA)、苹果公司(Apple Inc.)、OPPO、美团、阿里巴巴、蚂蚁集团、面壁智能(ModelBest)、Krafton等领军企业采用。Chinese Fineweb Edu 已从实验室走向产业场景,为创业公司到头部企业的研发团队提供可靠支撑,切实推动中文 NLP 应用从理论落地到生产实践。
- 生态影响: 下载数量累计超百万次,数据体量达 2.42TB,覆盖 9.57 亿条高质量文本,已孵化出 10 余个垂直领域微调模型。同时,OpenCSG 通过开源打分模型和完整工具链,输出数据治理方法论,带动行业从 "模型参数内卷" 转向 "数据基建完善",显著降低中小开发者与研究机构的入门门槛。
- 开源生态 :OpenCSG 坚持**"开源即文化"**的理念,通过透明、共创、共享的社区文化,与全球开发者、工程师和 AI 原生企业共同构建智能体生态。
结语:数据基础设施,是中文 AI 的隐形竞争力
过去,大模型行业最容易被看见的是参数规模、榜单成绩和应用演示。但真正支撑这些能力的,往往是更底层、更长期的数据工程。
高质量数据不是模型训练的配角,而是模型能力跃迁的关键燃料。尤其在中文场景下,公开、高质量、可复现的数据基础设施仍然稀缺。谁能持续建设这样的基础设施,谁就能为整个中文 AI 生态提供更稳定的创新土壤。
OpenCSG Chinese FineWeb 被相关前沿研究使用和引用,并不是偶然。它代表的是开源社区、学术研究和产业实践之间的一次连接:社区提供可复用的数据基础,研究团队在此基础上验证新的数据治理方法,模型训练再反过来证明高质量数据的价值。
这或许正是 OpenCSG 持续建设中文数据集的意义所在:不是只做一次发布,而是为中文 AI 提供可以长期生长的数据底座。
未来,OpenCSG 将继续围绕中文高质量数据建设,推动更多覆盖预训练、后训练、微调和行业场景的数据资源开放,与社区共同构建面向下一代大模型的中文数据基础设施。
论文链接:
arXiv:2505.05427 --- Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
arXiv:2602.09003 --- Data Science and Technology Towards AGI Part I: Tiered Data Management
Ultra-FineWeb-L3数据集:
https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3
UltraData-SFT-2605数据集:
https://huggingface.co/datasets/openbmb/UltraData-SFT-2605
Chinese-Fineweb-Edu数据集:
https://opencsg.com/datasets/OpenCSG/Fineweb-Edu-Chinese-V2.2
https://huggingface.co/datasets/opencsg/Fineweb-Edu-Chinese-V2.2
关于OpenCSG
OpenCSG是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。