分为纯内部推理(无工具交互)、工具交互循环推理、规划型推理、反思纠错推理、多路径搜索推理、多智能体协同推理六大类
覆盖工程落地全部常用范式
纯内部推理(仅模型思考,不调用工具)
CoT 思维链 Chain-of-Thought
CoT线性推理链
核心:线性分步推导,强制输出中间思考步骤,不依赖外部工具
零样本 CoT:提示词加 Let's think step by step
少样本 CoT:提供带推理步骤的示例
适用:数学计算、逻辑题、法条分析、简单多步骤推理
缺点:单条路径,一步错全程错,无法回溯
Self-Consistency 自洽采样(自我一致性)
基于 CoT 升级:生成多条独立 CoT 推理链,投票选出现最多的答案
优势:降低单条路径偶然错误,大幅提升准确率
缺点:推理成本 3~5 倍,延迟高
适用:高精度数学、竞赛推理、对错敏感场景
Self-Ask 自问自答
复杂问题拆解为子问题,模型主动向自己提问、逐层解答
例:问「马云毕业院校」→ 自问「马云是谁?」→ 自问「马云大学?」
适合多层级事实问答、信息检索前置拆解
单纯 CoT 和 "带外部工具交互" 的核心差异
CoT:只有思考,无行动、无外部反馈,纯文本脑内推演
ReAct:思考→动手调用工具→读取外部真实结果→再思考,是带外部世界交互的闭环,加上 "观察",一眼就能和纯内部推理 CoT 做区分
工具交互循环推理(Agent 最常用,思考 + 调用外部能力)
ReAct(Reason + Act)思考 - 行动 - 观察循环
标准闭环是三段:思考 (Reason) → 行动 (Act) → 观察 (Observation)
论文命名只取前两个核心动作叫 ReAct,但完整执行链路必须带上 "观察" 才能循环,所以中文翻译 ReAct 会补全第三步
标准 Agent 基础范式,闭环:
Thought(思考需要什么) → Action(调用工具/API/检索) → Observation(接收结果) → 下一轮Thought
特点:边思考边调用,动态根据返回结果调整下一步
适用:通用工具 Agent、天气查询、网页检索、数据库查询(比如 date-weather-skill 就是典型 ReAct)
短板:长任务容易循环、迷路、重复调用
执行流程
- Thought(思考):用户要xx地方的天气、日期、xx地方的限行,我先查日期
- Action(行动):调用日期工具
- Observation(观察):拿到结果「2026 年 06 月 21 日 星期日」
- 回到新 Thought:已有日期,下一步查xx地方的天气
- Action:调用天气接口
- Observation:晴天 29℃
- 回到新 Thought:还差限行,调用限行工具
- Action:查限行
- Observation:今日不限行
全部信息集齐,整合回答
优点:灵活,中途如果查到异常可以立刻改路线(比如天气接口挂了,直接只输出日期,不用走完全部流程)
短板:串行排队,3 次工具就要来回 3 轮 LLM 思考;长任务容易来回重复调用,陷入循环
ReWOO(Reasoning Without Observation)
先一次性完整规划全部子任务,批量执行所有工具,最后汇总观察结果
减少多轮 LLM 调用,降低 token 开销,适合多工具批量查询场景
执行流程
- 一次性思考完整规划:我需要调用 3 个工具,顺序:日期、xx地方的天气、xx地方的限行
- 一次性批量发起 3 个工具调用
- 等三个工具全部返回结果,统一观察所有数据
- 拿到全部结果后,仅最后一轮 LLM 整合输出
关键特点
全程只做两次 LLM 调用:一次写计划、一次汇总结果
ReAct 要多轮思考,ReWOO 大幅节省 token,速度更快
局限
中途无法动态调整:如果天气接口报错,它也会硬执行完剩下所有工具,不能中途中断简化逻辑
ReWOO 原生论文默认是线性串行列表执行(批量串行)
ReWOO 的 Planner 输出是有序步骤列表,像这样:
- #E1 = 获取今日日期
- #E2 = 查询xx地方的天气,参数依赖 #E1
- #E3 = 查询xx地方的限行
Worker 原生逻辑是按顺序挨个跑,跑完 #E1 拿到结果,填充占位符再跑 #E2,再跑 #E3
这就是很多资料写「批量串行」的来源:
批量:所有工具调用,一次性规划完毕,只两轮 LLM(规划 + 汇总),不像 ReAct 多轮来回思考
串行:工具调用默认排队执行,一步等一步
ReWOO 能不能并发?可以,但属于工程扩展,不是原生核心设计
Worker 本身无 LLM,只是调度脚本,开发者可以自己解析计划里的依赖:
完全无依赖的步骤(比如同时查天气、限行,互不引用),手动改成并发请求
存在数据依赖的步骤(第二步要用第一步结果),依旧必须串行阻塞
重点:并发只是附加优化,不是 ReWOO 的标志性特征
ReWOO 真正核心优势和命名由来是:推理阶段完全看不到工具返回值(Without Observation),提前写完完整计划,和并不并行无关
LLM Compiler 编译器式并行推理
把任务拆解为可并行执行的子步骤,生成类代码执行 DAG,多工具并发调用
适合多 API、多数据源并行拉取数据的复杂业务 Agent
LLM Compiler:拆解成可并行执行的代码 DAG,多工具同时跑
把任务翻译成一段伪代码逻辑,能并行的任务直接并发调用,不用排队
执行流程,LLM 编译生成执行逻辑(DAG 有向无环图):
python
# 两个分支可以并行同时执行,互不依赖
task1 = 并发调用日期工具
task2 = 并发调用xx地方的天气+限行工具
# 等待两个并行任务全部完成后合并数据
merge(task1, task2)系统同时并发拉取日期、天气、限行三个接口,不用等一个结束再跑下一个
所有接口数据全部返回后,一次性整理答案
适用场景
多独立 API、多数据源查询,追求耗时最短;
比如同时查天气、路况、新闻、汇率,全部互不依赖,并行拉取,大幅缩短等待时间
短板
依赖工具之间无依赖关系,如果 A 工具结果决定 B 要不要执行,就没法并行,不适合强依赖场景
对比

前置规划型推理(先整体方案,再分步执行)
Plan-and-Execute / Plan-and-Solve 规划 - 执行两阶段
规划阶段:一次性输出完整任务拆解方案、执行顺序、所需工具
执行阶段:严格按规划逐条执行,中间可微调但不重写整体方案
优势:流程可控、日志清晰、便于管控调用次数、适合长流程
劣势:环境变化时计划容易失效,灵活性弱于 ReAct
适用:旅行规划、报表生成、工单处理、标准化业务流程
开工前一次性把完整步骤全部想好,后面只按清单机械执行,中途只微调、不推翻全盘计划
两个细分小区别
Plan-and-Solve:纯文本推理,不用外部工具,纯逻辑拆解(做数学题、写回答框架)
Plan-and-Execute:带工具调用,计划里写明每一步要调用什么 API / 检索 / 数据库
完整流程举例(需求:做一份xx地区一日旅游报表)
阶段 1:规划(只跑 1 次 LLM,一次性出全流程)
调用工具查xx地区今日天气
搜索市区热门景点、开放时间
查询景点人均消费、交通路线
汇总数据,整理成表格报表
补充出行注意事项,输出完整文档
阶段 2:执行(逐条按计划走)
执行步骤 1 拿到天气
执行步骤 2 拿到景点列表
执行步骤 3 拿到费用交通信息
执行步骤 4 生成表格
执行步骤 5 补充文案
优势
流程固定、日志清晰、LLM 调用次数少、长任务不容易乱跑;标准化工单、报表、旅行规划都用它
短板
计划是提前写死的,如果执行中出现意外(景点全部闭园),原始计划直接失效,很难灵活改路线;灵活性远不如 ReAct(走一步看一步)
和 ReAct 最大差异
ReAct:做完一步,看结果再想下一步
Plan-and-Execute:全部步骤提前定死,后面不用反复思考
Reflexion,反思 / 自省纠错推理(自我批改,迭代优化)
reflexion rɪˈflekʃ(ə)n n. 反射;沉思;映象
Reflexion 反思型推理
闭环:初次执行输出 → 自我批判找漏洞/错误 → 修正重跑
两层反思:过程反思(工具调用逻辑错)、结果反思(答案错误、缺失信息)
适用:代码生成、文案写作、高精度数据分析、法律文书
衍生:Self-Correct、Critic-Agent(生成器 + 评审器双模型)
不管用 ReAct 还是规划执行做完任务,全部结束后,自己当评审挑错、复盘漏洞,然后重新修正,多轮迭代直到合格
它不是独立的任务流程,是一套「事后纠错增强机制」,可以叠加在任何推理模式上
两层反思(论文定义)
过程反思:工具调用逻辑出错(比如漏查数据、调用错误接口、步骤顺序颠倒)
结果反思:最终答案有漏洞、数据缺失、逻辑矛盾、存在幻觉、计算错误
完整闭环举例(需求:写一段数据分析报告)
初次执行:调用数据库拉取数据,生成初稿报告(底层用 Plan-and-Execute)
自我批判(反思环节)
逐条自查:数据年份缺失、同比对比没计算、结论无数据支撑、存在主观臆断幻觉
写出错误原因:缺少 2025 年数据,未做增长率计算,结论无原始数据佐证
修正重跑:根据反思指出的问题,重新调取缺失数据、补全计算,生成第二版报告
循环校验:可多次反思修正,达到最大迭代次数或无错误再输出最终结果
衍生概念说明
Self-Correct 自修正:轻量化 Reflexion,只修正当前输出,不记录长期经验
Critic-Agent(生成器 + 评审器双模型)
拆分两个独立 AI:
生成 Agent:负责写代码、写文案、执行工具
评审 Critic Agent:专门挑错、打分、给出修改意见(工业落地最常用的 Reflexion 架构,纠错能力更强)
Reflexion 独有能力:记忆沉淀
每次反思的失败原因、修正经验会存入记忆,下一次同类任务做规划时,自动避开之前踩过的坑,相当于 AI 学会复盘积累经验
对比

多路径搜索式推理(多分支探索、回溯择优)
ToT 思维树 Tree of Thoughts
consistency kənˈsɪstənsi n. 一致性,连贯性;黏稠度,平滑度
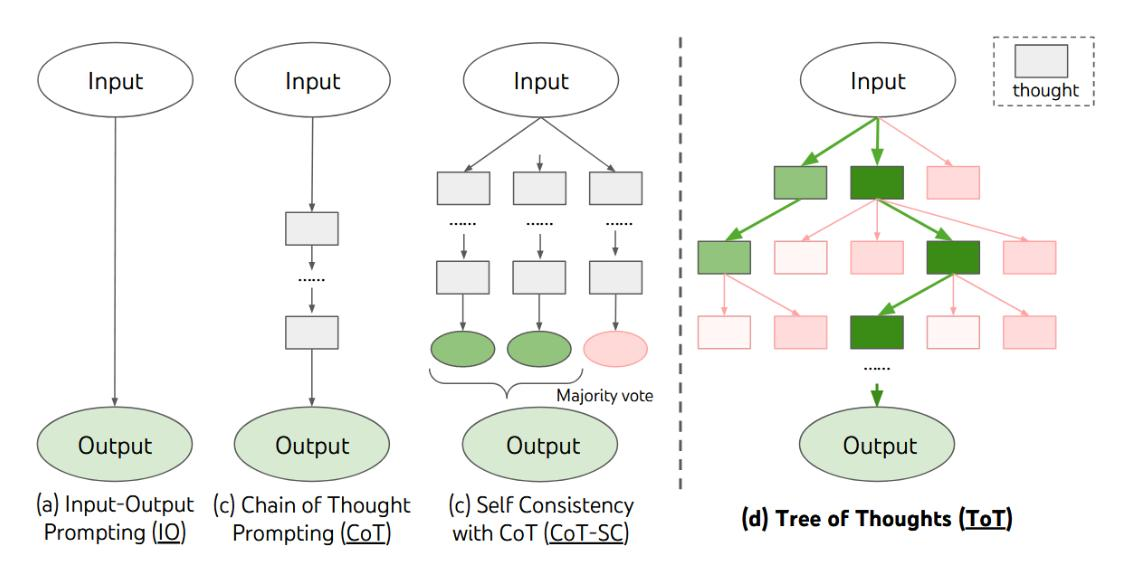
CoT 单链升级为树结构,每一步生成多条候选思路,评估每条分支优劣,DFS/BFS 搜索最优路径,支持回溯放弃错误分支
适用:解谜、战略决策、创意写作、复杂博弈
缺点:计算量大,多轮 LLM 调用,成本高
LATS 大语言搜索树( Language Agent Tree Search,语言智能体树搜索)
结合强化学习价值评估的 ToT 优化版,给每条思维分支打分,优先探索高分路径,减少无效分支
Search:蒙特卡洛树搜索 MCTS
对比
ToT(Tree of Thoughts):纯文本内部推理树,没有工具交互、没有环境反馈
LATS:融合 MCTS + ReAct 工具循环 + 价值评估 + 自省反思,专门给带工具调用的 Agent 设计,能回溯、打分、择优探索多条行动路径
多智能体协同推理(多角色分工思考)
Debate 多 Agent 辩论推理
多个独立 Agent 持不同视角对同一问题推理、互相反驳,最终综合统一结论
适合有争议、多维度分析(市场研判、风险评估、方案评审)
Role-based Multi-Agent 角色分工推理
拆分专业角色:规划 Agent、检索 Agent、计算 Agent、评审 Agent,流水线协同推理
复杂企业级 Agent 系统主流架构
对比
ToT(思维树)分支优劣评估完整机制
ToT 把单条 CoT 拆成多分支树,评估分支只用 LLM 自身做启发式打分,不需要额外训练模型
论文定义两大类标准评估方案,再加上工程补充方案
方案 1:独立单节点打分(Value 独立估值,论文原生第一种)
核心逻辑
每条分支单独发给 LLM,让模型判断「这条思路离正确答案有多远」,输出分数 / 三分类标签,转化成数值作为分支价值分
两种输出形式:
数值分:1~10 分,越高越值得继续深挖
分类标签:sure(可行)/likely(一般)/impossible(作废),映射成固定分值(sure=9,likely=5,impossible=1)
24 点场景:
一副扑克牌去大小王,随机抽4 个数,只用 + - × ÷ 和括号,每个数字必须用、只能用 1 次,算出结果 24 就算成功
提示词模板示例:
text
当前数字:3,4,6,8,分支思路:3+4=7
判断这条路径算出 24 的可能性,只输出 1-10 数字可选增强,前瞻模拟打分:
模型在打分时快速推演 1~2 步预判,如果几步内明显无解,直接打低分剪枝
分 3 次调用 LLM,每条互不相见,各自打分
第一次提问只给 A:
现在数字 3,4,6,8,思路:3+4=7。这条路径算出 24 的可能性,输出 1~10 分
模型返回:2
第二次提问只给 B:
现在数字 3,4,6,8,思路:8-6=2。这条路径算出 24 的可能性,输出 1~10 分
模型返回:8
第三次提问只给 C:
现在数字 3,4,6,8,思路:3×4=12。这条路径算出 24 的可能性,输出 1~10 分
模型返回:9
特点:
LLM 看不到其他分支,只凭自身经验给这条路径一个绝对分数
分数是孤立值,模型不会横向对比 A/B/C 谁更好
缺点:容易出现整体打分虚高 / 虚低。比如模型今天保守,所有分支都只打 3~5 分,相对好坏只能靠程序对比数字
分支 A:3+4=7 → LLM 打分 2(只剩 6、8,7、6、8 很难凑 24 → 打分 2 分,直接剪枝丢弃)
分支 B:8-6=2 → LLM 打分 8 (剩余 3、4,2×3×4=24,可行性极高 → 打分 8 分,保留继续深挖)
分支 C:3×4=12 → LLM 打分 9 ((12-8)×6=24 → 打分 9 分,保留深挖)
系统按分数排序,只保留高分 B、C 继续向下扩展,直接丢弃低分 A
优缺点
实现简单、每个分支独立调用,逻辑清晰
只做绝对打分,无法横向对比多条分支相对好坏,容易出现模型统一虚高 / 虚低偏差
方案 2:多分支联合投票对比(Vote 相对评估,论文原生第二种)
核心逻辑
把当前所有候选分支一次性丢给 LLM,让模型横向对比所有思路,选出最优 1 条 / 多条,类似多选投票,适合主观、难量化的场景
(写作、方案规划)
只调用 1 次 LLM,三条思路全部同时给模型,让它互相比较选出最优。提示词模板示例:
text
现有三条解题思路:
A:3+4=7
B:8-6=2
C:3×4=12
对比三条路径,选出最有可能算出 24 的编号,只输出字母对比全部路径,选出最有可能算出 24 的一条,只输出编号
模型输出:C
特点:
LLM 同时掌握所有候选方案,直接横向对比优劣
不需要数字分数,直接输出相对排名
优势:不受全局打分松紧影响,天然区分好坏
适合方案、写作、规划这类没有客观标准答案的场景
对比~独立单节点打分和多分支联合投票对比
独立打分:分开问,每条单独打分,得到绝对分值
联合投票:一起问,多条放一块对比,得到相对优劣
变种:多次投票自洽(自我一致性)
像 Self-Consistency 一样,重复投票 N 次,得票最多的分支判定为最优,降低单次判断误差
每次发给 LLM 的内容都完全相同:
text
现有三条解题路径:
A:3+4=7
B:8-6=2
C:3×4=12对比全部路径,选出最有可能算出 24 的一条,只输出编号
第一次发这段文字 → 输出 C
第二次原封不动再发一遍 → 输出 C
第三次一模一样再发 → 输出 B(随机失误)
第四次同样内容再发 → 输出 C
第五次同样内容再发 → 输出 C
为什么不能只问一遍?
LLM 采样存在随机性(温度参数带来的波动),相同输入,每次输出不完全稳定
复杂逻辑对比时,模型单次容易漏看细节、误判优劣,属于偶发错误,不会反复出现
为什么是 5 次,不是 100 次?
次数太少(1/2 次):容错能力弱,还是容易踩中随机错误
次数太多(几十上百次):大量重复调用 LLM,token 成本、耗时暴涨
工程常用 3~5 次,在「准确率提升」和「调用成本」之间做平衡
适用场景
创意写作、方案设计、开放式规划;这类任务没有明确对错,相对对比比单独打分更准
补充工程方案 3:硬规则校验器(Deterministic Checker)
不需要 LLM,写固定规则快速筛掉明显错误分支,前置过滤减少 LLM 调用成本
24 点:当前数字总和小于 24,直接判定 impossible
数学题:等式左右不相等,直接剪枝
填字游戏:单词不符合字母长度,直接丢弃
评估完怎么用分数 / 投票结果(搜索策略配合)
打分只是中间值,还要搭配搜索算法筛选分支:
BFS 广度优先(论文标配)
每层所有分支打分,只保留 Top-K 高分分支向下拓展,低分直接剪枝,控制树的规模,避免指数爆炸
例:每层只保留前 2 名高分分支继续生成子思路
DFS 深度优先
优先走最高分分支一路深挖;挖到死胡同(打分永久 impossible)就回溯,切换次高分分支重新探索
MCTS 蒙特卡洛树搜索(LATS 用这套)
不止单次 LLM 打分,每条分支多次模拟推演,综合「胜率 + 平均分」计算价值,比原生 ToT 评估更精细
ToT vs LATS 的评估区别
原生 ToT:单次 LLM 启发式打分,静态评估
LATS(Language Agent Tree Search):基于 MCTS,每条分支多次 rollout 模拟,累计统计胜率作为评估值,适合带工具交互的复杂 Agent,评估精度更高、开销更大
多 Agent 辩论推理(Multi-Agent Debate,MAD)
多个独立 LLM 智能体,各自给出推理,互相质疑、反驳、修正,多轮交锋后统一输出结论
和 Self-Consistency 最大区别:Self-Consistency 只看最终答案投票;辩论会交换完整推理逻辑,互相挑错、自我修正,不是简单投票
两类架构
对抗式辩论(两方对立)
正方 Agent、反方 Agent,立场天然相反,互相驳斥,搭配裁判 Agent 收尾;适合有争议、正反观点的问题。
协作式辩论(多方互评)
3~5 个中立 Agent,各自独立思考,看完所有人的思路后修正自己答案,达成共识;适合数学、严谨推理、消除幻觉。
标准完整四步流程
- 初始化:分配角色 + 下发问题
系统把同一个问题发给所有辩论 Agent,每个 Agent 有独立人设 / 提示词,保证思考差异化:
- 对抗版:Agent1 = 支持方,Agent2 = 反对方
- 协作版:AgentA = 逻辑推演、AgentB = 事实校验、AgentC = 风险审查
-
第一轮:独立立论(互不干扰)
每个 Agent 只看原始问题,单独输出完整推理链 + 答案,看不到别人的观点
举例题目:3、4、6、8能否算出24
Agent1:3×8×(6−4)=24,可以
Agent2:所有组合试过,无法凑 24,不行
Agent3:(3×4−8)×6=24,可以
-
多轮辩论迭代(核心环节,循环执行)
每一轮规则:
把上一轮所有人完整推理全部发给当前 Agent,Agent 逐条挑别人漏洞、指出逻辑错误、补充缺失条件,结合别人反驳,重写自己新推理和答案
记录完整辩论历史,进入下一轮
上面例子第二轮交互:
Agent2 看完 Agent1、3 的算式,发现自己漏了减法组合,修正观点:确实可以算出 24
Agent1 检查 Agent3 步骤,确认计算无误,维持原有结论
Agent3 补充两种解法,完善逻辑
循环终止条件(满足其一就停):
- 所有 Agent 答案完全一致,达成共识
- 达到预设最大轮次(一般 3~5 轮,控制成本)
- 裁判 Agent 判定无新观点、不再有修正空间
- 汇总输出(两种收尾方式)
共识输出:所有人观点统一,直接输出统一推理
投票 / 裁判裁决:观点仍有分歧,裁判 Agent 综合全部辩论记录给出最终结论,或多数投票选出最优答案
生活化完整例子(对抗两方 + 裁判)
问题:未来 3 年 AI 会不会大量替代程序员
第一轮立论
正方 Agent:AI 提升效率,初级编码岗位会被大规模替代
反方 Agent:需求持续扩张,AI 是工具,只会重构岗位不会替代
第二轮互辩
正方反驳:大量外包、CRUD 工作已被 AI 完成,初级岗招聘缩减
反方反驳:AI 无法理解业务上下文、做系统架构,高端人才需求上涨
第三轮修正
双方吸收对方论据,统一共识:初级编码岗位缩减,复合型开发岗位增加
裁判汇总辩论全程,输出完整综合结论
核心优势
解决单模型「思维固化」:单个 LLM 一旦认准错误思路,很难自我推翻;多个 Agent 互相打脸,强制暴露漏洞
不止投票,还修正推理:Self-Consistency 只是多次采样投票,不会主动改错;辩论 Agent 看完别人逻辑会主动修改自身思路
减少幻觉:事实校验类 Agent 专门挑虚假信息,多方交叉验证
复杂决策更全面:同时保留多种视角,不会漏掉关键维度