
过去很长一段时间里,网页数据采集都是工程团队的"脏活累活"。
业务团队想看竞品价格、新闻热度、广告落地页变化、社媒用户反馈、搜索结果排名、招聘市场动态、房源价格波动,最后往往都会变成一个技术问题:谁来写爬虫?谁来维护选择器?页面结构改了谁来修?IP、并发、失败重试、数据清洗、格式转换又由谁兜底?
很多采集需求看起来只是"拿几个字段",真正落地时却会被一串细节卡住:页面需要登录或地区定位,价格由 JS 动态渲染,列表页和详情页字段不一致,验证码偶尔出现,海外站点访问不稳定,同一套脚本在本地能跑、上线后失败,业务还希望每天定时拿到 JSON、CSV 或截图留档。
这也是为什么,越来越多企业开始把网页采集从"临时脚本"升级为"可持续的数据服务"。
从工具形态看,市面上大致有几类方案:一类是 Scrapy、Playwright、Puppeteer 这类自建爬虫框架,灵活但需要团队自己维护代理、渲染、调度和异常处理;一类是 Apify、Oxylabs 等云端采集平台,通常提供现成采集器、代理网络或 Web Unlocker 能力,适合把部分底层工程外包出去;还有一类是更偏业务交付的数据 API,把常见网站、通用网页访问、任务管理和结果下载整合到后台。
一个好的网页采集工具,应该更接近第三类思路:它不是只提供一个爬虫脚本,而是把搜索引擎数据采集、行业网站数据采集、通用采集 API、音视频下载和数据集服务放在同一个后台里。对于开发者来说,重点不再是从零搭一套采集工程,而是在已有入口里选择合适的采集方式,配置参数,拿到结构化结果、HTML 或 PNG。
一、开篇:传统网页采集的痛点
如果各位朋友接触过一个中小规模的爬虫项目,就会知道网页采集最难的地方通常不在"发起请求"。
真正的成本藏在请求之后。
新闻网站的标题可能在 h1 里,也可能包在复杂的文章模板中;电商平台的价格可能是首屏 HTML,也可能来自异步接口;社媒帖子的互动数、发布时间、作者信息经常散落在不同 DOM 节点里。开发者需要自己处理请求、解析 HTML、编写 XPath/CSS 选择器、模拟浏览器行为、处理分页和详情页跳转,还要把采回来的字段清洗成统一格式。
更麻烦的是,网页不是静态资产。
一次前端改版、一次反采集策略升级、一次字段位置调整,都可能让原本稳定的爬虫在第二天早上失效。工程师被迫在业务需求和页面变化之间来回救火:今天修商品价格,明天修新闻正文,后天排查为什么同样的脚本在某个地区访问失败。
对于企业而言,这类成本有三个典型后果:
- 数据获取周期长。业务团队提出需求后,往往要等待开发、联调、清洗、验收。
- 维护不可控。页面结构、访问策略、网络环境变化都会让脚本进入高维护状态。
- 数据难复用。一次性脚本通常只服务单个任务,难以沉淀为稳定的数据资产。
网页采集 API 的价值就在这里:把大量重复的底层工程封装起来,让开发者以"配置目标、调用接口、接收结构化结果"的方式获取数据。Dataify 后台展示的产品形态也很清晰:一类是 Amazon、Google、YouTube、Walmart、eBay 等行业网站的专用采集器;另一类是输入任意 URL 的通用采集 API,用于动态网页、SPA 页面和需要浏览器渲染的复杂采集场景。
二、网页采集 API 如何工作
从开发者视角看,Dataify 的网页采集 API 可以拆成两条路径:
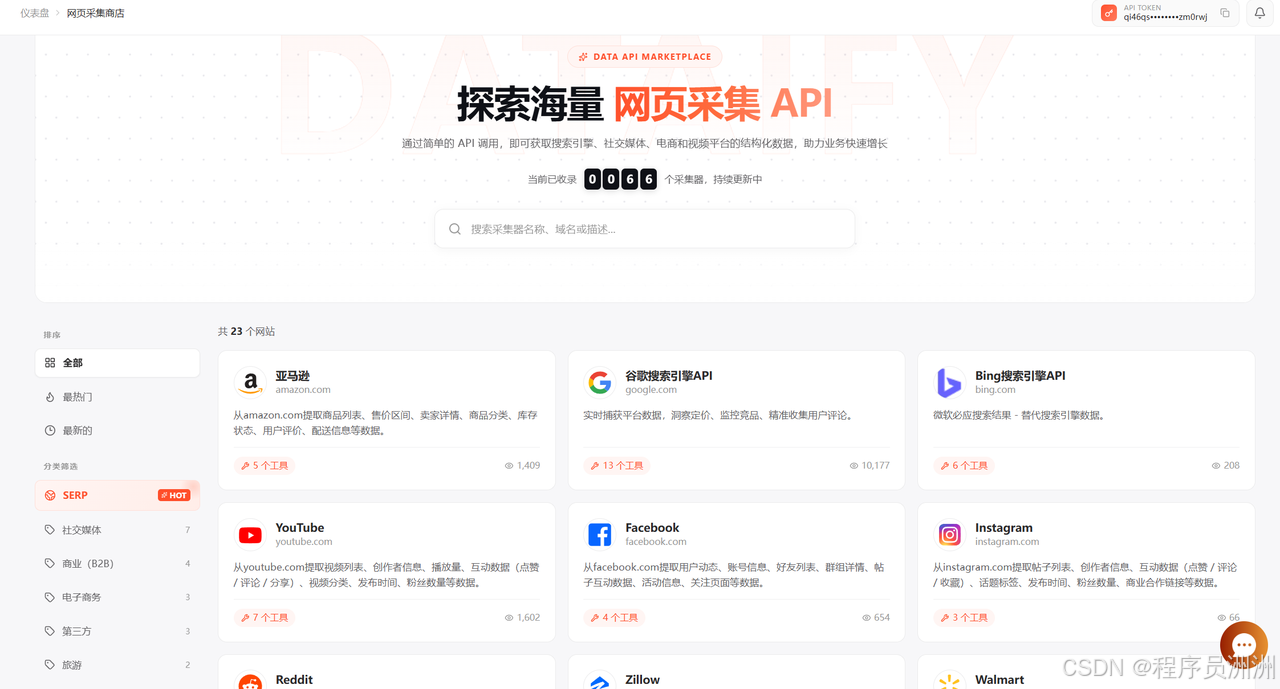
- 如果目标网站已经在网页采集商店中,例如 Amazon、Google、Bing、YouTube、Facebook、Instagram、Reddit、Zillow、Walmart、eBay、Booking、Indeed、LinkedIn、Glassdoor 等,就优先使用专用采集器。
- 如果目标页面更长尾、更非标,或者需要 CAPTCHA 识别、JS 渲染、HTML/PNG 输出,就使用通用采集 API。
后台的网页采集商店显示,当前已收录 23 个网站、66 个采集器,持续更新中。它更像一个"网页数据 API 市场":开发者不必从零写爬虫,而是从现成采集器中选择目标网站、选择采集方式,然后配置参数运行。
- 提交目标 URL 或目标参数
在 Dataify 后台,提交目标不一定只有 URL。
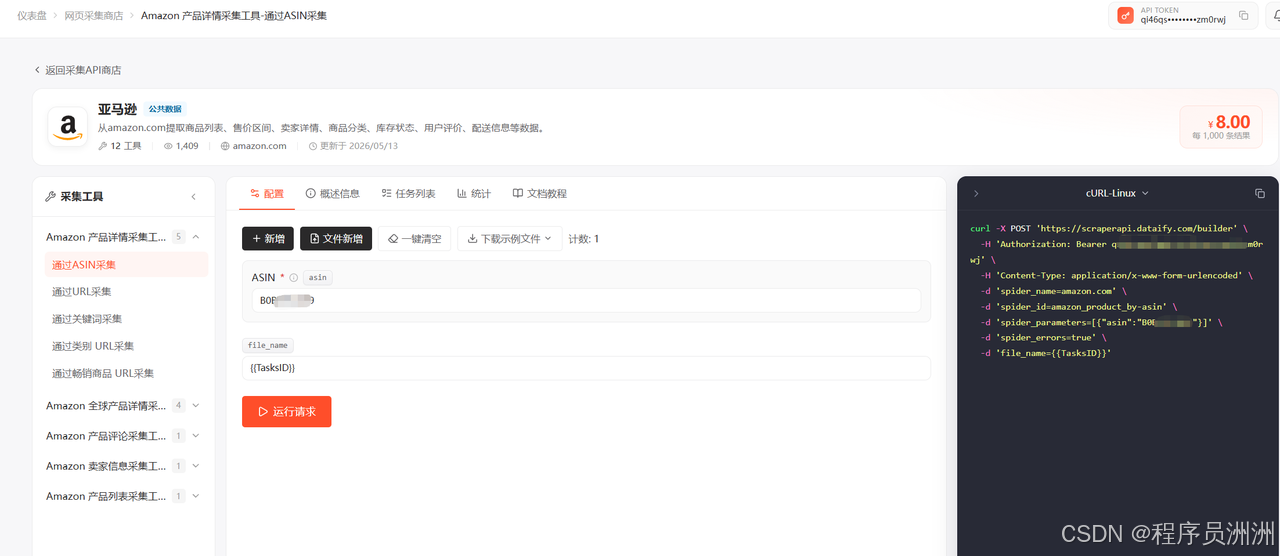
以 Amazon 产品详情采集为例,页面提供了多种采集方式:
- 通过 ASIN 采集
- 通过 URL 采集
- 通过关键词采集
- 通过类别 URL 采集
- 通过畅销商品 URL 采集
后台示例中,Amazon 产品详情采集工具的必填参数是 asin,默认示例值为 B0BZYCJK89,并支持 file_name={``{TasksID}} 这样的任务文件命名方式。
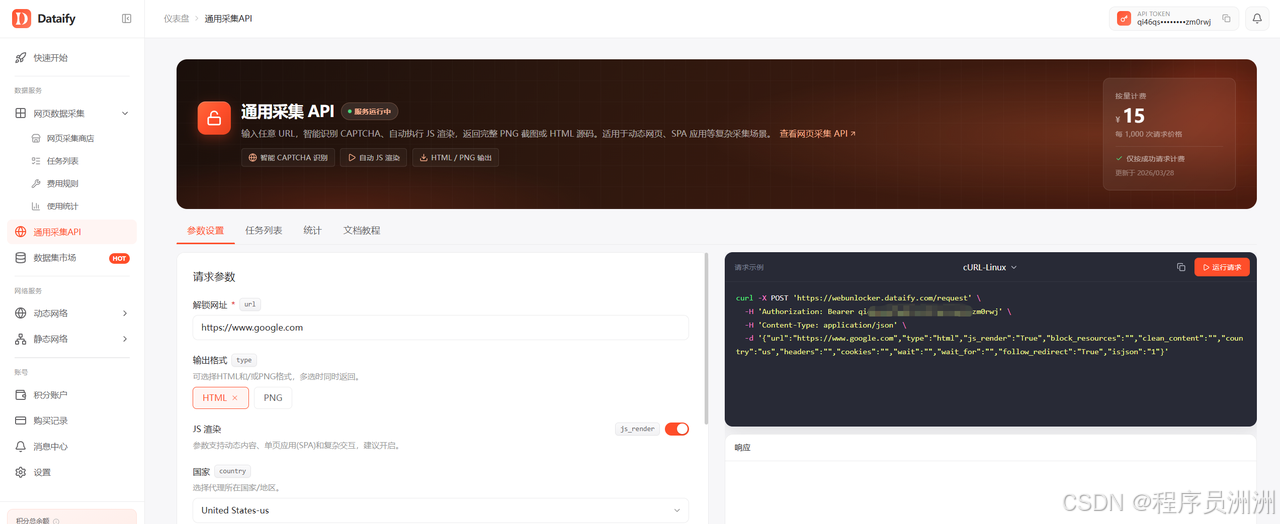
如果使用通用采集 API,则提交的是任意网页 URL。后台通用采集 API 页面显示,请求地址对应的接口为:
bash
https://webunlocker.dataify.com/request它适合动态网页、SPA 应用等复杂采集场景,可以自动执行 JS 渲染,并返回 HTML 或 PNG。
- 配置采集任务与运行参数
行业网站采集器的重点是"模板化参数"。
例如 Amazon 产品详情采集器可以围绕 ASIN、URL、关键词、类别 URL 等参数发起任务;这类专用采集器的价值在于,平台已经围绕目标网站封装了采集逻辑,开发者只需要传入业务参数。
通用采集 API 的重点是"网页访问与渲染参数"。
Dataify 后台显示的通用采集 API 参数包括:
| 参数 | 含义 |
|---|---|
| url | 需要解锁和采集的目标网址,必填 |
| type | 输出格式,可选择 HTML 和/或 PNG |
| js_render | 是否开启 JS 渲染,适合动态内容和 SPA 页面 |
| country | 代理所在国家/地区,例如 us |
| block_resources | 阻止加载指定资源,加快采集速度 |
| clean_content | 清理返回内容中的 JS 或 CSS 代码 |
| wait | 页面加载后额外等待的毫秒数 |
| wait_for | 等待指定 CSS 选择器出现后再返回内容 |
| follow_redirect | 是否自动跟随 301/302 重定向 |
| headers | 自定义请求 Headers |
| cookies | 自定义 Cookies |
这类参数看似普通,但它解决的是传统爬虫里最烦人的那一层:动态渲染、页面等待、重定向、Cookie/Header 注入、地区选择、输出格式控制。
- 返回结构化结果或页面快照
不同产品路径对应不同输出:
- 行业网站采集器更偏结构化结果,例如商品标题、价格、库存、评论、配送信息、卖家信息等。
- 通用采集 API 更偏页面解锁与内容获取,可以返回 HTML 源码或 PNG 截图。
例如一个商品详情页结果可以被整理成:
bash
{
"asin": "B0BZYCJK89",
"title": "Wireless Noise Cancelling Headphones",
"price": "$89.99",
"rating": "4.7",
"review_count": 1284,
"stock_status": "In Stock",
"source": "amazon.com"
}而通用采集 API 的结果,则更适合进入后续解析链路:
bash
{
"url": "https://www.google.com",
"type": "html",
"status": "success",
"html": "<html>...</html>"
}这也是两类 API 的分工:专用采集器负责把成熟场景做成结构化接口,通用采集 API 负责把复杂网页先稳定打开、渲染并取回。
- 支持任务化、批量化与成本可见
企业级网页采集与个人爬虫最大的差别,是任务化。
Dataify 后台为网页采集提供了任务列表、统计、费用规则等入口;快速开始页也展示了今日消耗、近 7 天消耗、近 30 天消耗等指标。对于企业团队来说,这意味着采集不再只是某个脚本,而是可监控、可计费、可追踪的服务。
从后台看到的价格口径看:
| 产品入口 | 后台描述 | 价格口径 |
|---|---|---|
| 搜索引擎数据采集 | Google、Bing 等主流搜索引擎结构化结果 | ¥10.00 / 千次请求 |
| 行业网站数据采集 | 电商、社交、新闻等网站专用采集接口 | ¥8.00 / 千条结果 |
| 通用采集 API | 任意网页通用采集,自动处理反爬与 JS 渲染 | ¥15.00 / 千次请求 |
| 音视频下载 | YouTube 等主流平台音视频数据采集 | ¥4.80 / GB |
| 数据集 | 覆盖音视频、文本等多领域的结构化数据集 | 按量计费 |
这套定价方式也解释了 Dataify 的产品逻辑:能用专用采集器的场景,用结构化结果计费;更非标、更依赖浏览器渲染的场景,用通用请求计费;音视频类则按流量计费。整体来看性价比很高。
三、Dataify 代码实战 1:用通用采集 API 监控竞品落地页
先看一个更贴近真实业务的场景:市场团队每天要巡检一批竞品落地页,关注页面是否能正常打开、首屏内容是否发生变化、促销文案是否更新,以及页面源码里是否出现新的价格、活动或注册入口。
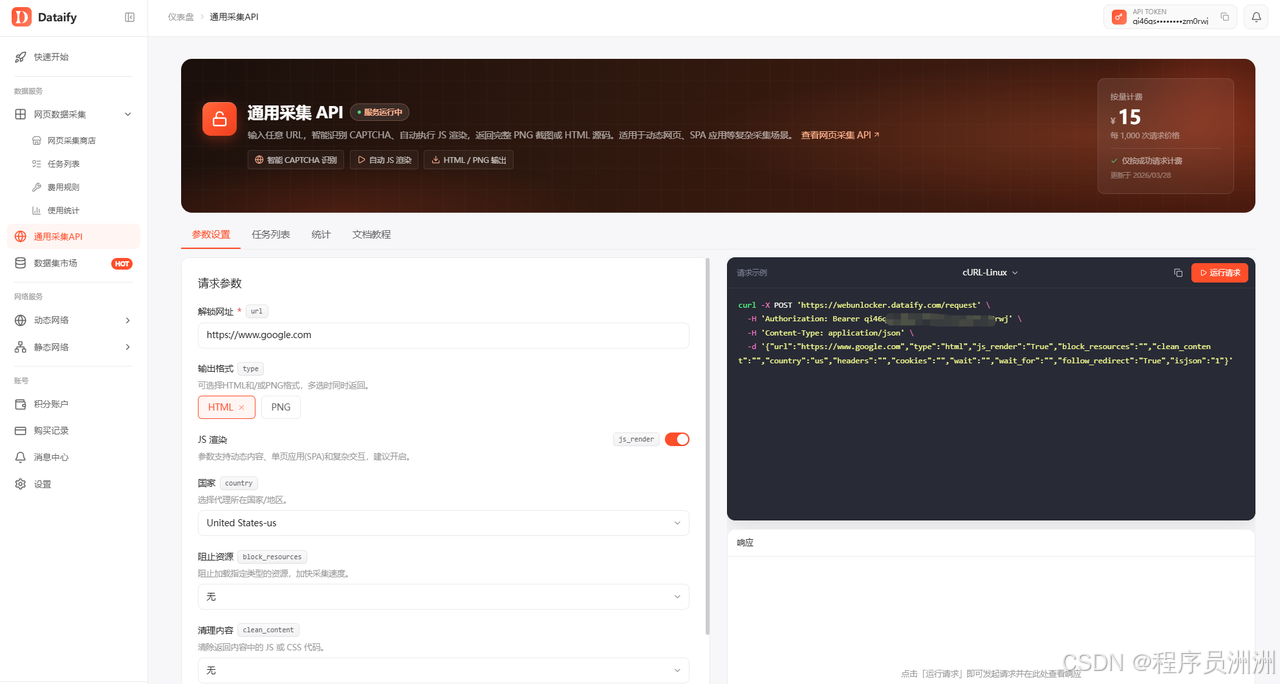
如果用传统方式做,研发通常要维护浏览器渲染、代理地区、等待策略、HTML 下载、截图归档和异常告警。Dataify 后台的通用采集 API 把这条链路压缩成一个参数面板:点击「通用采集API」后,可以配置目标 URL、输出格式、JS 渲染、国家/地区定位、阻止资源、清理内容、等待时间、等待选择器、重定向、Headers 和 Cookies。右侧代码面板支持 cURL、Python、C#、Go、Node.js 等语言示例,配置完成后点击「运行请求」,即可在响应区查看实时结果;任务完成后,还可以根据输出类型下载 PNG 截图或 HTML 源码。
从后台截图看,通用采集 API 的核心能力包括三类:
- 智能 CAPTCHA 识别:适合遇到访问验证的公开网页采集场景。
- 自动 JS 渲染:适合动态网页、单页应用 SPA 和复杂交互页面。
- HTML / PNG 输出:既能给后端解析,也能给业务侧做页面留档和人工复核。
下面代码基于后台通用采集 API 页面和文档参数整理而来。
bash
import hashlib
import http.client
import json
from pathlib import Path
from typing import Dict, Optional
from urllib.parse import urlencode
DATAIFY_API_KEY = "xxx示例秘钥xxx"
DATAIFY_HOST = "webunlocker.dataify.com"
DATAIFY_PATH = "/request"
ARCHIVE_DIR = Path("landing_page_archive")
def fetch_landing_page(
url: str,
*,
output_format: str = "html",
country: str = "us",
wait_for: str = "body",
js_render: bool = True,
) -> Dict[str, str]:
"""
使用 Dataify 通用采集 API 获取动态网页内容。
适用场景:
- 竞品落地页巡检
- SEO 页面归档
- 活动页源码分析
- 需要 JS 渲染的网页监控
"""
payload = {
"url": url,
"country": country,
"js_render": "True" if js_render else "False",
"format": output_format,
"follow_redirect": "True",
"wait_for": wait_for,
}
form_data = urlencode(payload)
headers = {
"Authorization": f"Bearer {DATAIFY_API_KEY}",
"Content-Type": "application/x-www-form-urlencoded",
}
conn = http.client.HTTPSConnection(DATAIFY_HOST, timeout=60)
try:
conn.request("POST", DATAIFY_PATH, form_data, headers)
response = conn.getresponse()
content = response.read()
finally:
conn.close()
if response.status >= 400:
raise RuntimeError(
f"Dataify request failed: {response.status} {response.reason} "
f"{content[:500].decode('utf-8', errors='ignore')}"
)
text = content.decode("utf-8", errors="ignore")
return {
"status": str(response.status),
"reason": response.reason,
"url": url,
"format": output_format,
"content": text,
}
def archive_html(result: Dict[str, str], tag: Optional[str] = None) -> Path:
ARCHIVE_DIR.mkdir(exist_ok=True)
digest = hashlib.sha256(result["content"].encode("utf-8")).hexdigest()[:12]
safe_tag = tag or result["url"].replace("https://", "").replace("http://", "")
safe_tag = "".join(ch if ch.isalnum() else "_" for ch in safe_tag)[:48]
output_path = ARCHIVE_DIR / f"{safe_tag}_{digest}.html"
output_path.write_text(result["content"], encoding="utf-8")
return output_path
def extract_business_signals(html: str) -> Dict[str, bool]:
lower_html = html.lower()
return {
"has_discount": any(word in lower_html for word in ["discount", "coupon", "sale"]),
"has_pricing": any(symbol in html for symbol in ["$", "¥", "€"]),
"has_signup": any(word in lower_html for word in ["sign up", "get started", "try free"]),
}
if __name__ == "__main__":
target_url = "https://www.google.com"
result = fetch_landing_page(
url=target_url,
output_format="html",
country="us",
wait_for="body",
js_render=True,
)
saved_path = archive_html(result, tag="competitor_landing_page")
signals = extract_business_signals(result["content"])
print(f"Status: {result['status']} {result['reason']}")
print(f"Saved HTML: {saved_path}")
print(json.dumps(signals, ensure_ascii=False, indent=2))这段代码做了三件事:
- 通过 webunlocker.dataify.com/request 发起通用采集请求。
- 开启 JS 渲染,并通过 wait_for="body" 等待页面主体出现。
- 将返回的 HTML 落盘归档,再提取折扣、价格、注册入口等业务信号。
如果业务需要的是截图留档,可以把 output_format 改成 png,在后台右侧响应面板中查看实时捕获结果,并通过下载按钮保存最终 PNG;如果业务需要做二次解析,则保留 html 输出,把页面源码接入后续的规则解析、LLM 摘要、变化检测或告警系统。
这就是通用采集 API 在真实业务中的价值:它不是简单"抓一个网页",而是把浏览器渲染、地区访问、等待策略、响应预览和结果下载串成一个可运营的流程。对于市场监控、竞品分析、SEO 巡检、RPA 页面核验这类场景,团队可以把精力放在"哪些变化值得关注",而不是反复处理页面为什么没有渲染出来。
四、Dataify 代码实战 2:用 Amazon 专用采集器批量采集商品数据
通用采集 API 解决的是"任意网页如何打开并取回内容";专用采集器解决的是"典型网站如何直接返回业务字段"。
在 Dataify 的网页采集商店中,Amazon 采集器不是一个空白表单,而是一套已经产品化的采集工具。进入采集器详情页后,后台会引导用户了解这个工具的关键信息,包括功能介绍、示例 JSON/CSV 输出、输出字段解释、输入参数说明等。如果当前采集器没有覆盖业务需要的字段,还可以通过页面反馈入口提交需求,官方会在 24 小时内联系处理。
以 Amazon 产品详情采集工具为例,后台左侧按工具类型分组,包含"通过 ASIN 采集、通过 URL 采集、通过关键词采集、通过类别 URL 采集、通过畅销商品 URL 采集"等方式。中间区域是参数配置区,右侧是代码示例区,支持 cURL-Linux、cURL-Windows、Python 等多种语言。配置完成后,可以通过两种方式发起任务:
- 在 API 构建器里直接填写 ASIN,点击「运行请求」。
- 复制右侧代码,在自己的后端服务、定时任务或数据管道中通过 POST 请求调用采集工具。
对于真实业务来说,这个场景非常典型:运营团队维护一批竞品 ASIN,系统每天定时提交采集任务,任务完成后从「任务列表」下载 JSON、CSV 或 xlsx 文件,再把价格、评分、库存、配送、评论数等字段写入内部数据库,用于价格监控和竞品分析。
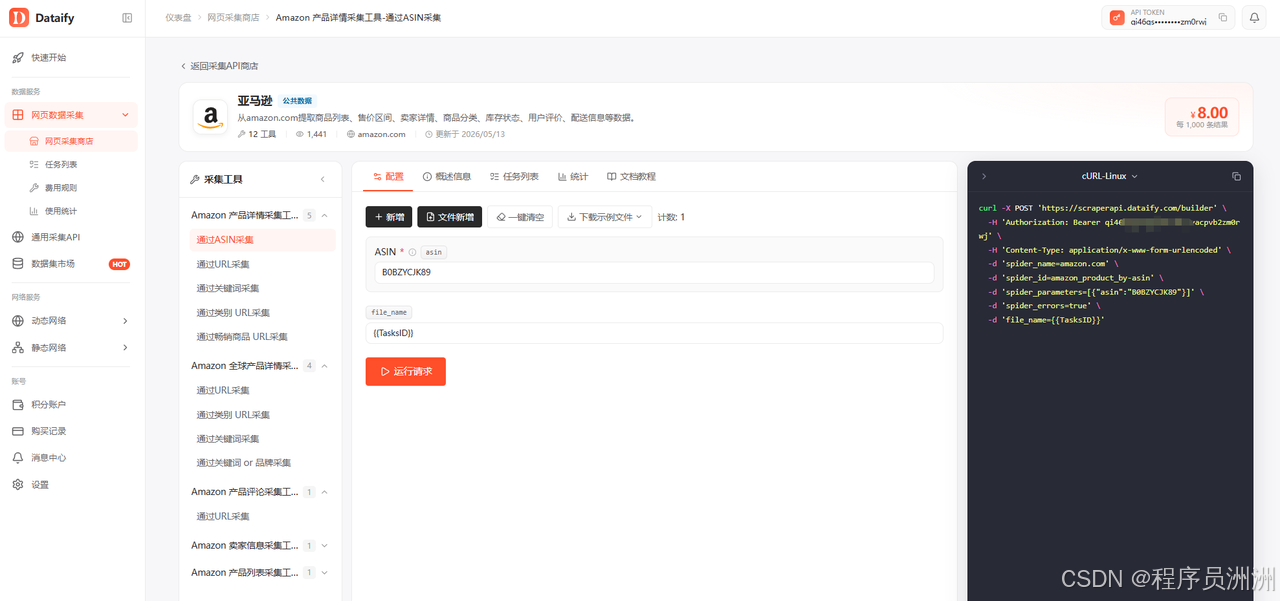
下面是一段完整模拟代码,用后台和文档中展示的 amazon_product_by-asin 采集器作为示例。
bash
import csv
import json
from dataclasses import dataclass
from datetime import datetime
from pathlib import Path
from typing import Any, Dict, Iterable, List
import requests
DATAIFY_API_KEY = "示例秘钥"
TASK_BUILDER_URL = "https://scraperapi.dataify.com/builder"
TASK_LOG_FILE = Path("dataify_amazon_task_log.jsonl")
RESULT_FILE = Path("amazon_product_monitor.csv")
@dataclass
class AmazonMonitorItem:
asin: str
tag: str
owner: str
def build_spider_parameters(items: Iterable[AmazonMonitorItem]) -> str:
"""
每个对象至少包含 asin,例如:[{"asin":"B0BZYCJK89"}]
"""
parameters = [{"asin": item.asin} for item in items]
return json.dumps(parameters, ensure_ascii=False)
def create_amazon_asin_task(items: List[AmazonMonitorItem]) -> Dict[str, Any]:
headers = {
"Authorization": f"Bearer {DATAIFY_API_KEY}",
"Content-Type": "application/x-www-form-urlencoded",
}
payload = {
"spider_name": "amazon.com",
"spider_id": "amazon_product_by-asin",
"spider_parameters": build_spider_parameters(items),
"spider_errors": "true",
"file_name": "{{TasksID}}",
}
response = requests.post(
TASK_BUILDER_URL,
headers=headers,
data=payload,
timeout=60,
)
response.raise_for_status()
return response.json()
def append_task_log(response: Dict[str, Any], items: List[AmazonMonitorItem]) -> None:
"""
记录任务创建结果,便于后续到 Dataify 后台"任务列表"中检索、下载和对账。
"""
record = {
"created_at": datetime.now().isoformat(timespec="seconds"),
"asins": [item.asin for item in items],
"tags": sorted({item.tag for item in items}),
"response": response,
}
with TASK_LOG_FILE.open("a", encoding="utf-8") as file:
file.write(json.dumps(record, ensure_ascii=False) + "\n")
def normalize_amazon_product(raw_item: Dict[str, Any]) -> Dict[str, Any]:
"""
将 Dataify 下载结果整理成内部监控表。
"""
return {
"asin": raw_item.get("asin"),
"title": raw_item.get("title"),
"price": raw_item.get("price"),
"rating": raw_item.get("rating"),
"review_count": raw_item.get("review_count"),
"stock_status": raw_item.get("stock_status"),
"seller": raw_item.get("seller"),
"delivery": raw_item.get("delivery"),
"collected_at": datetime.now().isoformat(timespec="seconds"),
}
def save_products_to_csv(products: List[Dict[str, Any]], output_file: Path) -> None:
if not products:
return
fieldnames = list(products[0].keys())
with output_file.open("w", newline="", encoding="utf-8-sig") as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(products)
def mock_downloaded_results() -> List[Dict[str, Any]]:
"""
后台任务列表支持按任务查看状态、成功率、结果数量、消耗积分、文件大小,并下载结果。
"""
return [
{
"asin": "B0BZYCJK89",
"title": "Wireless Noise Cancelling Headphones",
"price": "$89.99",
"rating": "4.7",
"review_count": 1284,
"stock_status": "In Stock",
"seller": "Example Store",
"delivery": "Free delivery",
},
{
"asin": "B08N5WRWNW",
"title": "Smart Speaker with Voice Assistant",
"price": "$49.99",
"rating": "4.6",
"review_count": 9821,
"stock_status": "In Stock",
"seller": "Example Direct",
"delivery": "Arrives tomorrow",
},
]
if __name__ == "__main__":
monitor_items = [
AmazonMonitorItem(asin="B0BZYCJK89", tag="headphones", owner="market-team"),
AmazonMonitorItem(asin="B08N5WRWNW", tag="smart-speaker", owner="market-team"),
]
task_response = create_amazon_asin_task(monitor_items)
append_task_log(task_response, monitor_items)
downloaded_rows = mock_downloaded_results()
normalized_rows = [normalize_amazon_product(row) for row in downloaded_rows]
save_products_to_csv(normalized_rows, RESULT_FILE)
print(f"Saved {len(normalized_rows)} rows to {RESULT_FILE}")这段代码对应的后台流程是:
- 在采集器详情页确认工具信息,理解输入参数、输出字段和示例结果。
- 选择"通过 ASIN 采集",在 API 构建器中填写一个或多个 ASIN。
- 如果是低频验证,可以直接点击「运行请求」;如果要接入业务系统,则复制右侧代码,用 POST 请求调用 https://scraperapi.dataify.com/builder。
- 任务创建后,到"任务列表"查看状态、成功率、结果数量、消耗积分、文件大小和执行记录。
- 任务完成后,通过下载按钮导出 JSON、CSV 或 xlsx,再进入内部数据清洗、监控和告警流程。
在图片里的任务列表中,Dataify 会展示任务 ID、状态、抓取工具、创建时间、采集时长、成功率、结果数量、消耗积分、文件大小和下载入口。对企业团队而言,这个页面很像采集任务的"控制台账本":哪天采了什么、是否成功、消耗多少、结果有多大,都能被追踪。
真实业务中,这条链路还可以继续往后接:
- 将任务 ID 写入数据库,便于追踪采集状态。
- 定时查询任务列表,下载 JSON、CSV 或 xlsx 结果。
- 对价格、库存、评分和评论量做字段归一化。
- 将异常价格、缺货、评分下降等事件推送给运营或供应链团队。
这就是专用采集器的价值:它不是把 HTML 扔给你,而是围绕一个明确网站和明确业务对象,把"工具说明、参数配置、代码调用、任务记录、结果下载"封装成一条完整的数据生产线。
五、典型场景
网页采集 API 的价值,往往不在单个页面,而在"持续获得可用数据"。
| 场景 | 可提取字段 | 业务价值 |
|---|---|---|
| 搜索引擎监控 | 关键词排名、自然结果、广告结果、图片/地图结果 | SEO 监控、品牌搜索声量、竞品投放跟踪 |
| 电商平台 | 商品名、价格、库存、评分、评论、配送、卖家信息 | 竞品分析、价格监控、选品决策、智能定价 |
| 社媒平台 | 帖子内容、发布时间、互动数、话题标签、账号信息 | 趋势分析、账号监控、品牌舆情、用户洞察 |
| 视频平台 | 视频标题、创作者、播放量、互动数据、发布时间 | 内容趋势分析、达人监控、视频数据归档 |
| 房产与旅游 | 房源/住宿列表、价格、位置、设施、评价、可用性 | 区域价格研究、供给监控、旅行产品分析 |
| 招聘与 B2B | 职位、公司、薪资、融资信息、企业动态 | 人才市场洞察、销售线索、行业研究 |
| 通用网页 | HTML、PNG 截图、动态渲染结果、页面状态 | RPA 巡检、网页归档、异常监控、长尾页面解析 |
| AI 训练数据 | 垂类文本、网页知识、问答内容、多模态素材 | LLM 训练、SFT、RAG、模型评估 |
如果把传统爬虫和 Dataify 这类网页采集 API 做一个对比,差异会更清楚:
| 对比项 | 传统爬虫 | Dataify 网页采集 API |
|---|---|---|
| 开发方式 | 手写请求、解析、清洗、导出逻辑 | 选择采集器或通用 API,配置参数 |
| 输出结果 | HTML、半结构化文本,需要自行清洗 | 专用采集器返回业务字段,通用 API 返回 HTML/PNG |
| 页面适配 | 改版后维护成本高 | 通过采集器模板或参数迭代降低维护成本 |
| 动态网页 | 需要自建浏览器渲染与等待策略 | 通用采集 API 支持 JS 渲染、等待选择器 |
| 网络稳定性 | 需要自建代理、重试、调度策略 | 可结合平台网络服务与任务机制 |
| 批量采集 | 自己处理分页、并发、失败重试 | 任务化提交,适配批量与持续采集 |
| 成本管理 | 脚本成本隐性,难以归因 | 后台展示任务、统计、价格口径和消耗 |
| 适用场景 | 高度定制、一次性工程 | 企业级、持续性、可复用的数据获取 |
这也是 Dataify 这类平台最适合切入的地方:不是取代所有定制开发,而是把 80% 重复、繁琐、容易失效的采集基础工作产品化,让技术团队把时间留给真正有业务壁垒的部分。
六、全文总结
今天,企业对网页数据的需求已经发生了变化。
过去大家关心的是"能不能爬到";现在真正重要的是"能不能稳定、合规、持续地拿到结构化数据,并让这些数据进入业务系统"。
Dataify 的网页采集 API,本质上是在把传统爬虫的工程复杂度向平台侧迁移。开发者不必把大量时间消耗在 HTML 适配、请求调度、规则维护和异常处理上,而是通过 API Token、任务参数、采集模板和结构化输出,把公开网页数据转化为可直接使用的数据资产。
这背后对应的是一个更大的趋势:AI 应用越往深处走,数据基础设施越重要。
无论是搜索引擎数据、电商价格监控、社媒舆情分析、视频数据归档、广告追踪,还是 RAG 知识库更新、模型训练数据构建、企业 RPA 自动化,Dataify 都提供了一条更短的路径:用专用采集器把典型网站变成结构化数据,用通用采集 API 把复杂网页变成 HTML/PNG,用任务化机制把一次性采集变成持续数据流。
对于正在搭建数据中台、AI 应用、市场情报系统、价格监控系统或舆情分析系统的团队来说,这类变化非常现实。因为业务真正需要的从来不是爬虫本身,而是更快、更稳、更干净的数据。
如果说传统爬虫解决的是"网页如何被抓取",那么 Dataify 试图回答的是另一个更接近企业决策的问题:
当公开网页数据已经成为 AI 和商业分析的重要燃料,企业要不要继续用零散脚本管理它,还是把它升级成一套可持续运行的数据基础设施?
答案,正在变得越来越清晰。
官方入口
- Dataify 官网:https://dataify.com?utm_source=cxyzz&utm_term=01
- Dataify 控制台:https://dashboard.dataify.com/dashboard/quick-start
- Dataify 文档:https://doc.dataify.com/