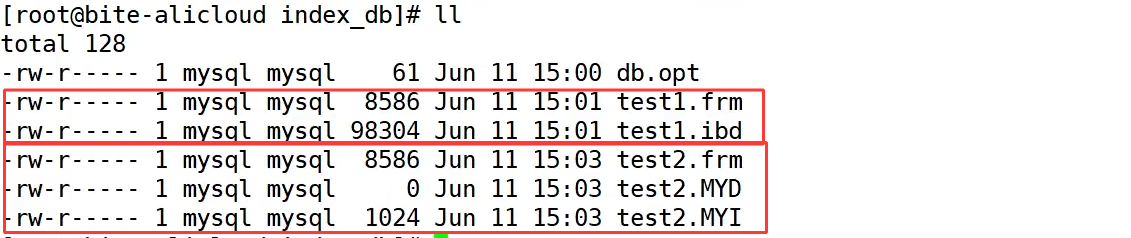
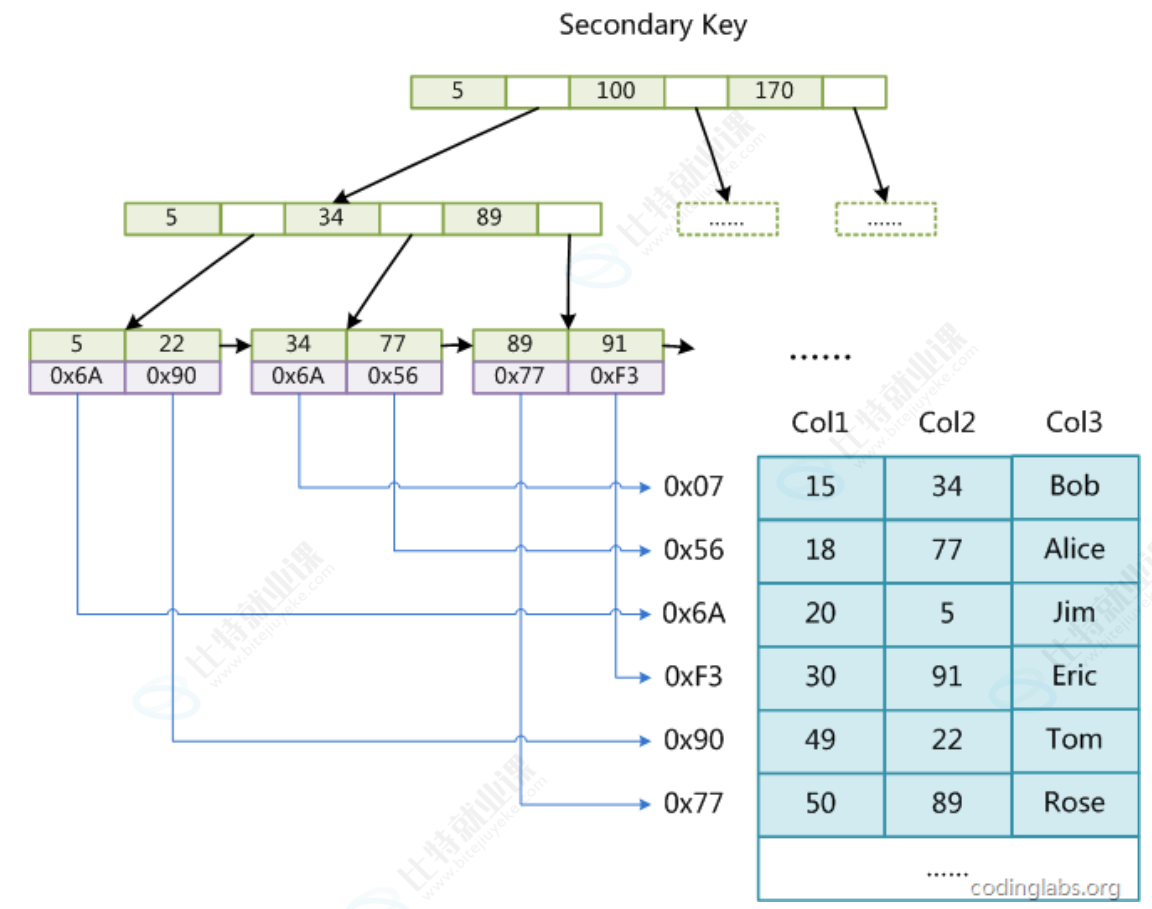
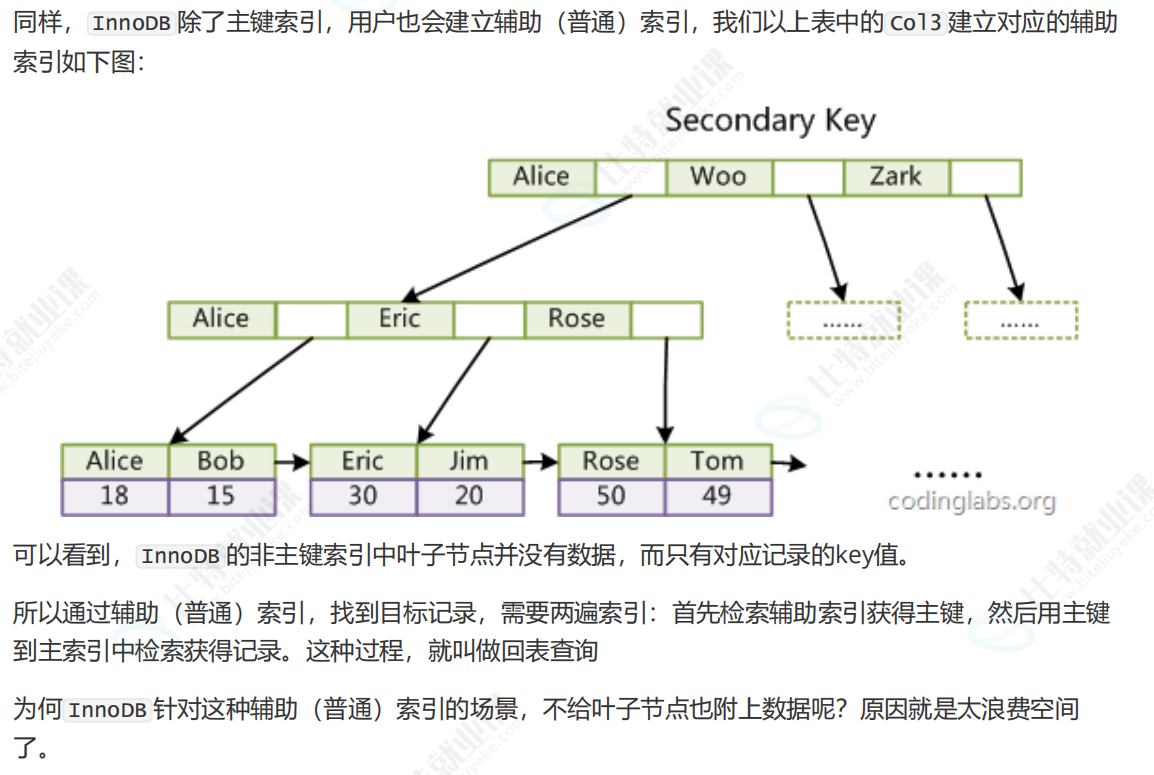
MySQL 服务器的所有数据操作,本质上都是在内存中完成的,索引也不例外。而决定算法效率的关键因素有两个:**一是数据的组织方式,二是算法本身。**索引正是通过改变数据的组织方式,也就是重构数据结构来优化查询效率的,这就是我们常说的 "结构决定算法"。它的好处非常明显,不需要修改程序,也不用调整 SQL 语句,只要通过 create index 创建合适的索引,查询速度就可能提升成百上千倍,是数据库优化中性价比极高的手段。但也要注意,索引并非没有代价,天下没有免费的午餐,查询性能的提升,是以插入、更新、删除等写操作的速度为代价的,因为维护索引需要额外的 IO 开销。所以,索引的核心价值就是在需要频繁查询的场景下,用写操作的少量性能损耗,换取海量数据检索时的巨大效率提升。
--构建一个8000000条记录的数据
--构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解
-- 产生随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
--产生随机数字
delimiter $$
create function rand_num()
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
--创建存储过程,向雇员表添加海量数据
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
-- 执行存储过程,添加8000000条记录
call insert_emp(100001, 8000000);
我们接着前面的磁盘硬件话题,来看 MySQL 与磁盘交互的软件层面逻辑,重点理解 MySQL 和操作系统、磁盘之间的数据流转过程。
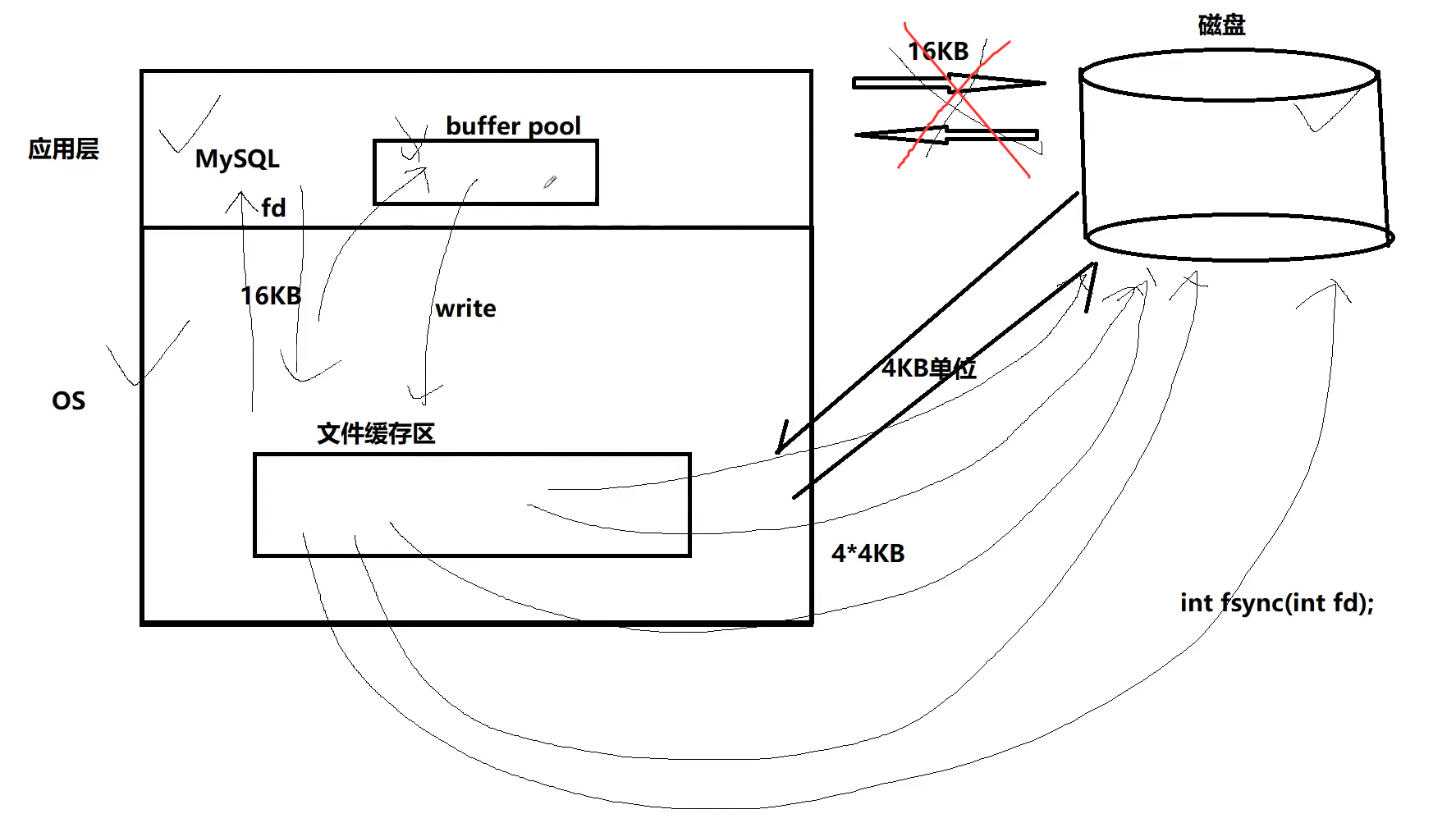
首先,我们可以把 MySQL 理解成运行在操作系统之上的一款特殊文件系统,MySQL 的核心任务就是管理磁盘上的数据。从架构上看,它分为三个层级:最上层是应用层的 MySQL 进程,中间是操作系统 OS,最底层是磁盘硬件。MySQL 进程无法直接和磁盘通信,所有数据读写都必须通过操作系统来完成,这是现代操作系统的基本机制,所有应用程序都不能直接操作硬件,必须通过系统调用完成。
我们先看数据写入的路径。当 MySQL 需要把数据写入磁盘时,它不会直接和磁盘交互,而是先把数据写入自己的缓冲区 ------Buffer Pool。 Buffer Pool 是 MySQL 专门为了提高 IO 效率设计的内存缓冲区,数据在这里被组织成 MySQL 的基本交互单位,也就是 16KB 大小的 "页" (Page)。 随后,MySQL 通过文件描述符 fd,向操作系统发起 write 系统调用,把 16KB 的数据写入操作系统的文件缓存区。文件描述符 fd 在这里的作用,就像一个 "文件的钥匙",MySQL 通过它来指定要操作的磁盘文件,操作系统通过它来识别对应的文件对象,完成后续的数据转发。
接下来,操作系统和磁盘之间的数据交互,是以系统默认的 4KB 为单位进行的。MySQL 传入的 16KB 数据,会被操作系统拆分成 4 个 4KB 的数据块,分批写入磁盘。为了确保数据真正落盘,而不是停留在操作系统缓存中,MySQL 会调用 fsync 系统调用,强制操作系统把缓存中的数据同步刷新到磁盘硬件上,确保数据持久化。这个过程中,操作系统起到了承上启下的作用,它接收上层应用的 16KB 数据,再按照磁盘和系统的 4KB 单位进行拆分和写入,最终把数据存到磁盘的扇区里。
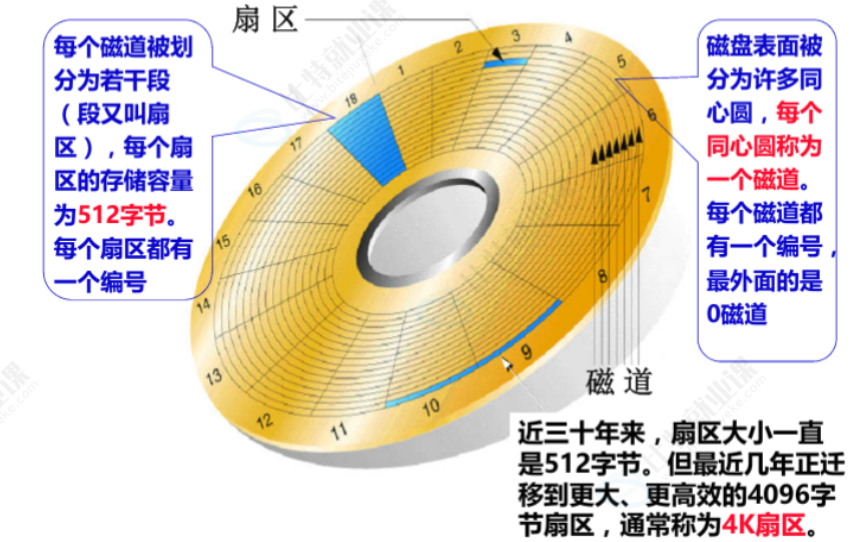
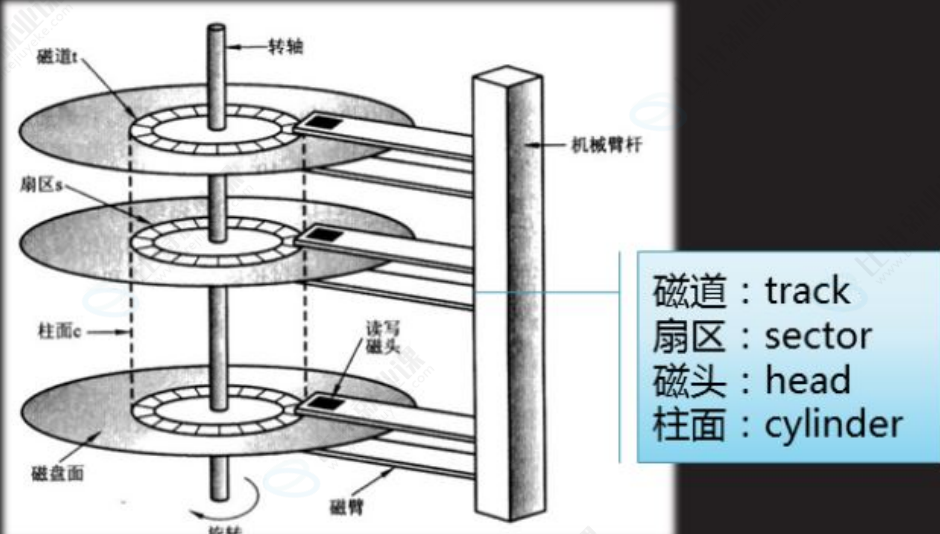
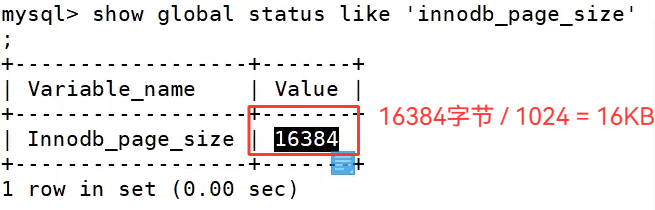
最后,我们可以通过 show global status like 'innodb_page_size'; 查看 MySQL 的交互单位,结果显示为 16384 字节,换算后正好是 16KB。这说明,虽然磁盘的基本单位是 512 字节,操作系统的 IO 单位是 4KB,但 MySQL 为了平衡 IO 效率和数据管理的灵活性,把自己和磁盘交互的基本单位设置为了 16KB,这个单位在 MySQL 中就叫做 "页"。每一次 MySQL 和磁盘的 IO 操作,都是以 16KB 的页为单位进行的,这也是后续 B + 树索引结构设计的基础。
我们接着前面的内容,深入理解 MySQL 中 "页(Page)" 和缓冲池(Buffer Pool)的核心逻辑:
MySQL 的数据文件本质上都是以 16KB 的页为单位存储在磁盘上的。所有的 CURD 操作,无论是插入、查询还是修改数据,都需要先找到对应的页,再在页内完成后续操作。而 CPU 处理数据必须在内存中进行,所以 MySQL 会先把磁盘上的页加载到内存,操作完成后再按策略刷新回磁盘,这个过程就是磁盘与内存的数据交互,而交互的基本单位,正是这 16KB 的页。
所以为了高效管理这些内存中的数据,MySQL 在启动时就会申请一块专门的内存空间,也就是我们上面说的 Buffer Pool。Buffer Pool 本质上是一个大内存缓冲区,专门用来缓存从磁盘加载的页数据,所有的 IO 交互都通过它来完成。这样一来,频繁访问的页会被保留在内存中,不用每次都重新从磁盘读取,能大幅减少磁盘 IO 次数,这也是 MySQL 提升性能的关键手段之一。
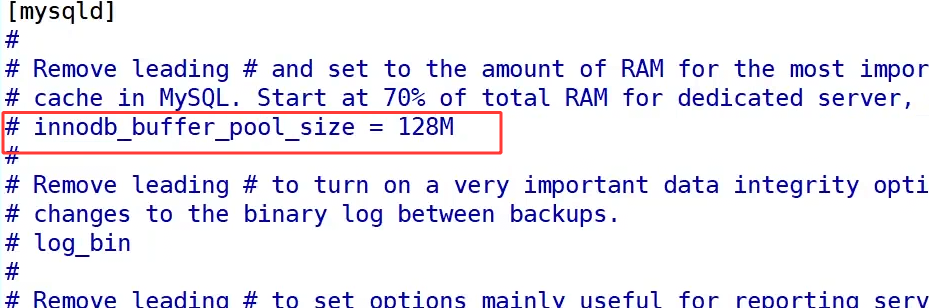
Buffer Pool 的大小可以通过配置文件中的 innodb_buffer_pool_size参数来设置,默认值通常为 128M,我们可以根据服务器的内存情况进行调整,比如在专用的数据库服务器上,一般会设置为总内存的 70% 左右,让 MySQL 尽可能缓存更多的数据页,减少磁盘 IO 压力。
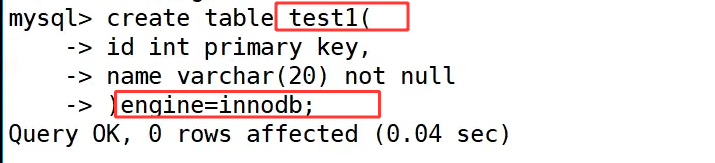
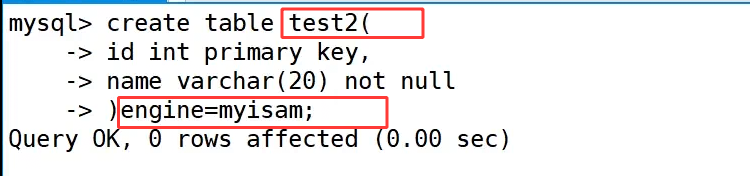
首先,我们创建了一张 user 表,其中 id 字段被设置为 primary key 主键。从建表语句和表结构可以看到,id 字段带有 PRI 标识,这意味着 MySQL 会自动为 id 创建主键索引,这是我们接下来要观察的关键点。
再插入数据:
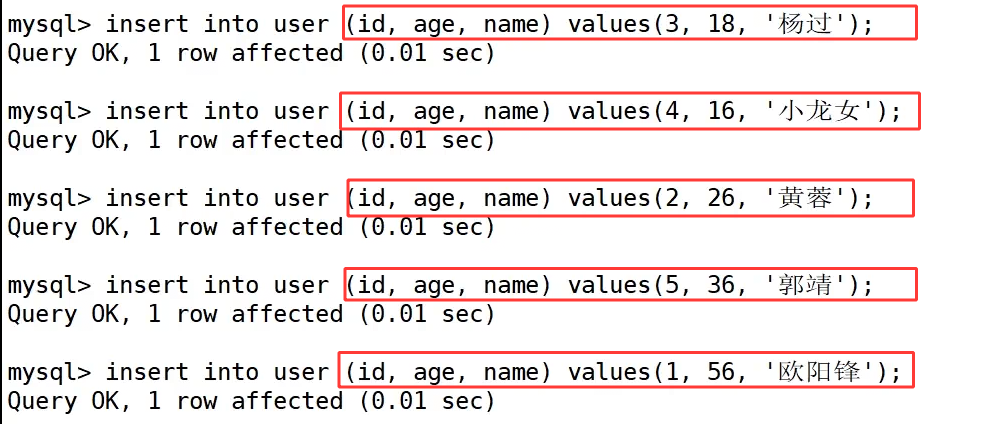
接着,我们向表中插入数据,但插入的顺序是完全乱序的:先插入 id 为 3 的数据,再插入 4、2、5,最后才插入 id 为 1 的数据。
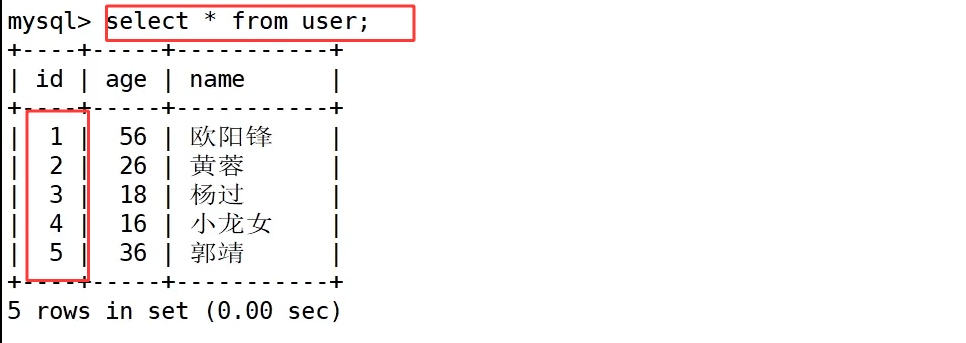
现在,当我们执行 select * from user; 查询数据时,会发现返回的结果是按 id 从小到大有序排列的。这就引出了问题:明明我们是乱序插入的,为什么查询结果却是有序的?是谁帮我们排好序的?
答案就是 MySQL 为 id 创建的主键索引。因为主键索引的底层是 B + 树结构,为了保证查询效率,数据在物理存储上就是按索引键值有序组织的。即使我们乱序插入数据,MySQL 也会按照主键索引的规则,将数据有序地存放在对应的位置,所以我们查询时看到的自然就是有序的结果了。这也是索引改变数据组织方式的直接体现。
重谈page
我们继续深入理解 MySQL 中的 page 概念,这是理解索引和 IO 优化的关键。
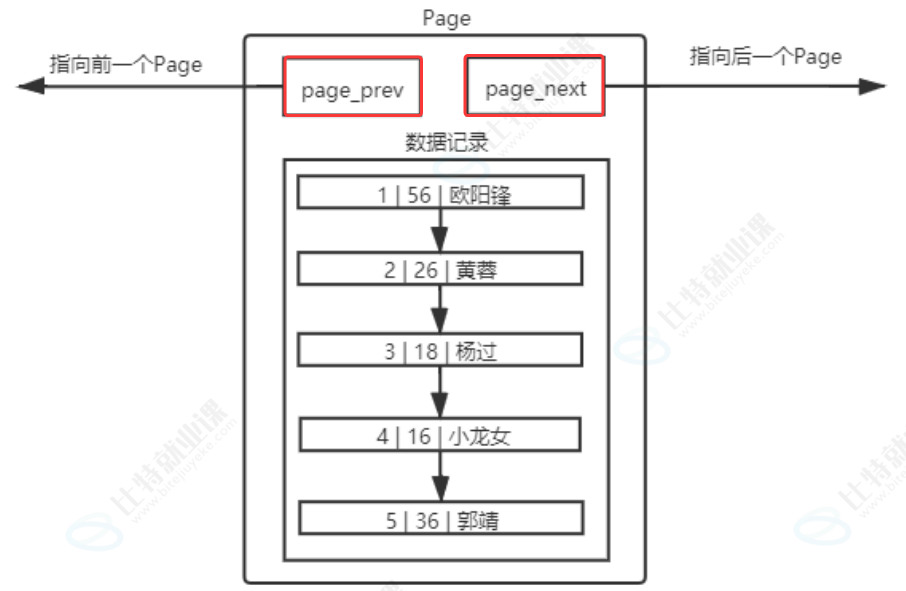
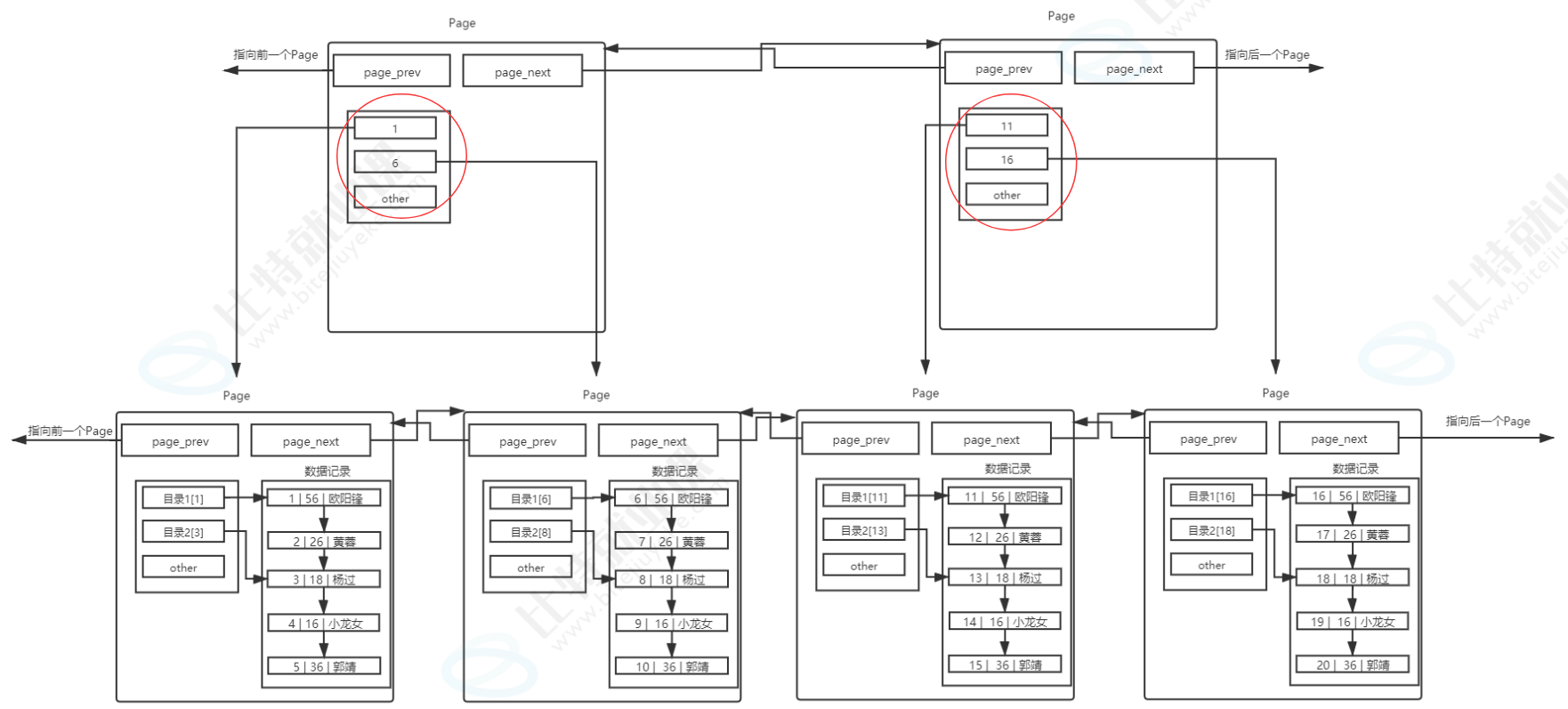
首先,MySQL 内部会同时存在大量的page,所以它必须对这些 page 进行统一管理。这就要求我们不能简单地把 page 看作一个普通的内存块,它内部必须包含管理信息,用来记录和维护自身的状态。上图中的 struct page 结构体就是这种管理方式的模型,它包含了 next 和 prev 指针,用来把所有的 page 串联成一个双向链表,方便在 Buffer Pool 中进行管理;同时还有 buffer 数组,用来存储真正的数据。这个结构体就是 MySQL 在内存中对 page 的建模,既包含了管理元数据,也包含了数据存储区域。
接下来我们要理解,为什么 MySQL 和磁盘交互时,要采用以 page 为单位的批量读取,而不是 "用多少加载多少"?
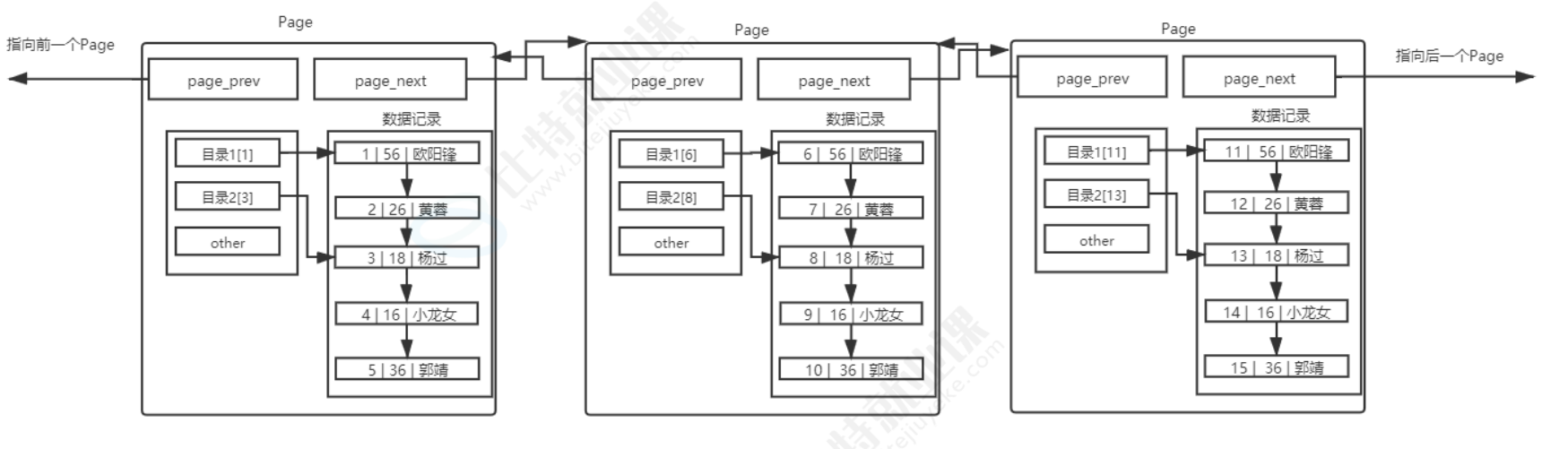
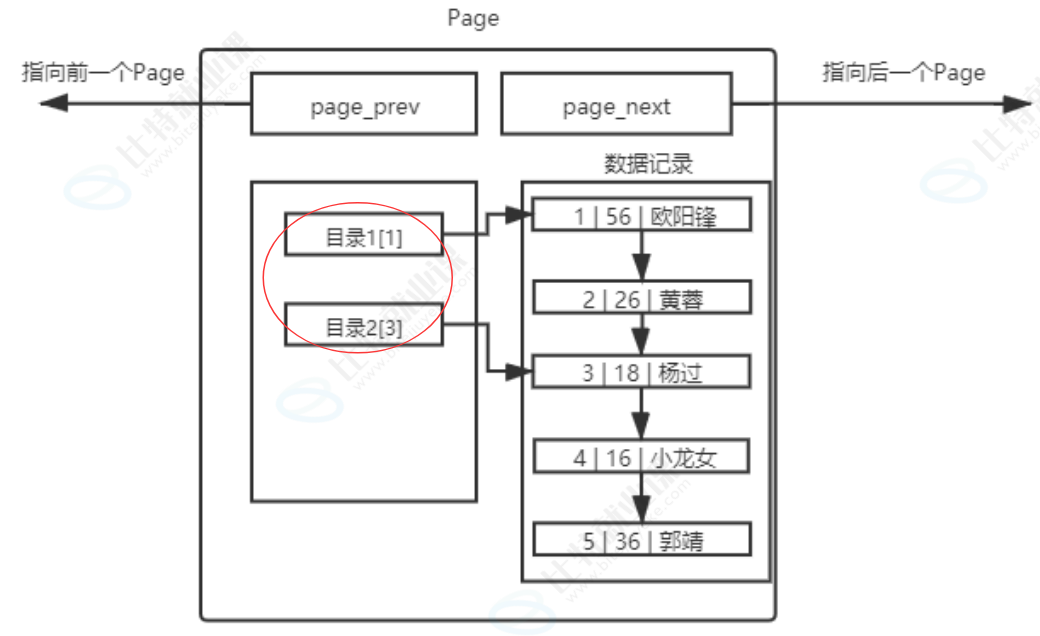
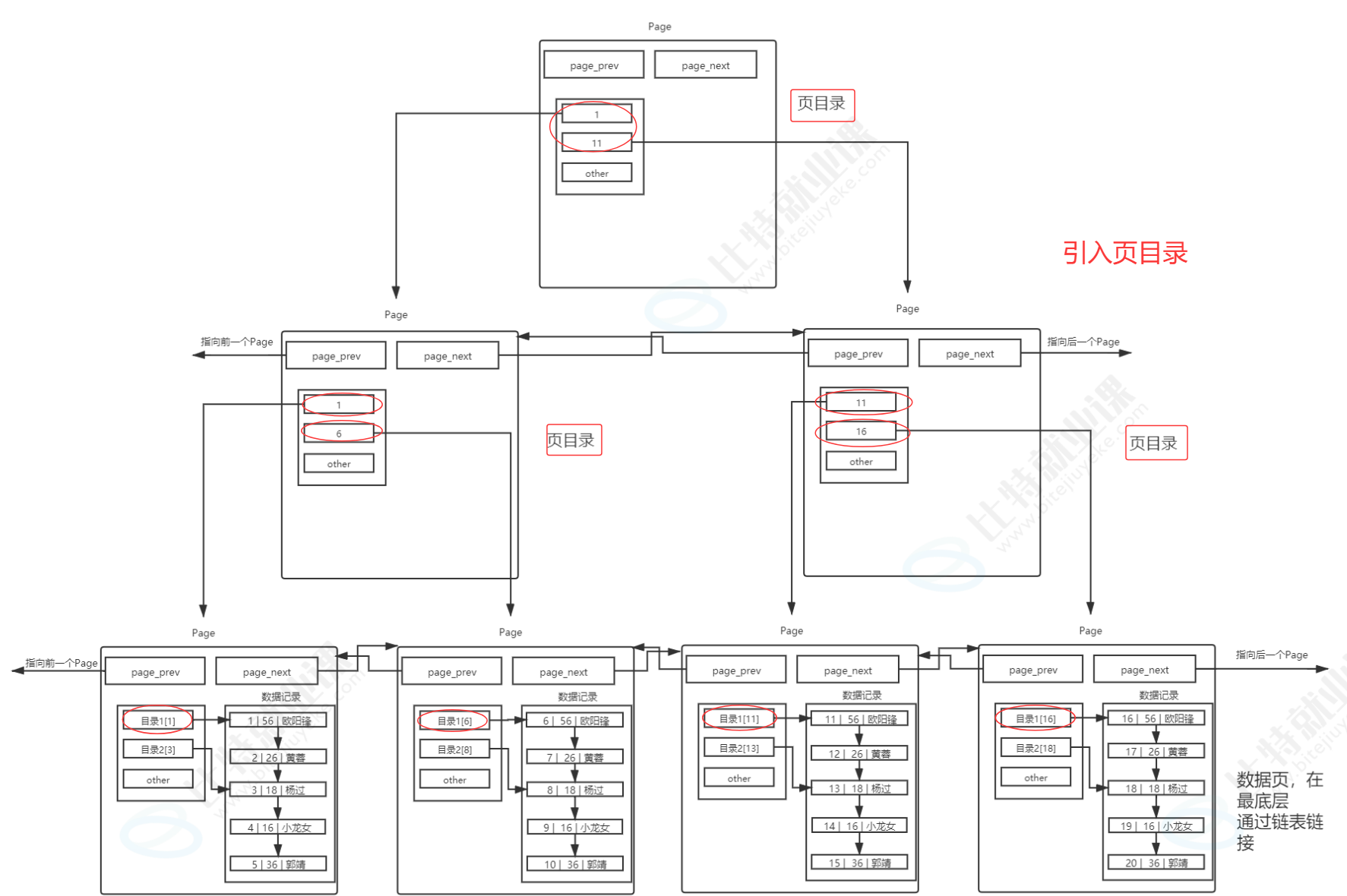
其实目录页的本质也是普通的页,只是普通页里存的是用户数据,而目录页里存的是普通页的地址和键值信息。 这种 "目录页管理数据页" 的层级结构,正是 B + 树索引的核心雏形,它把原本线性的链表遍历,变成了树形结构的快速查找,这也是为什么索引能在海量数据场景下实现高效查询的根本原因。
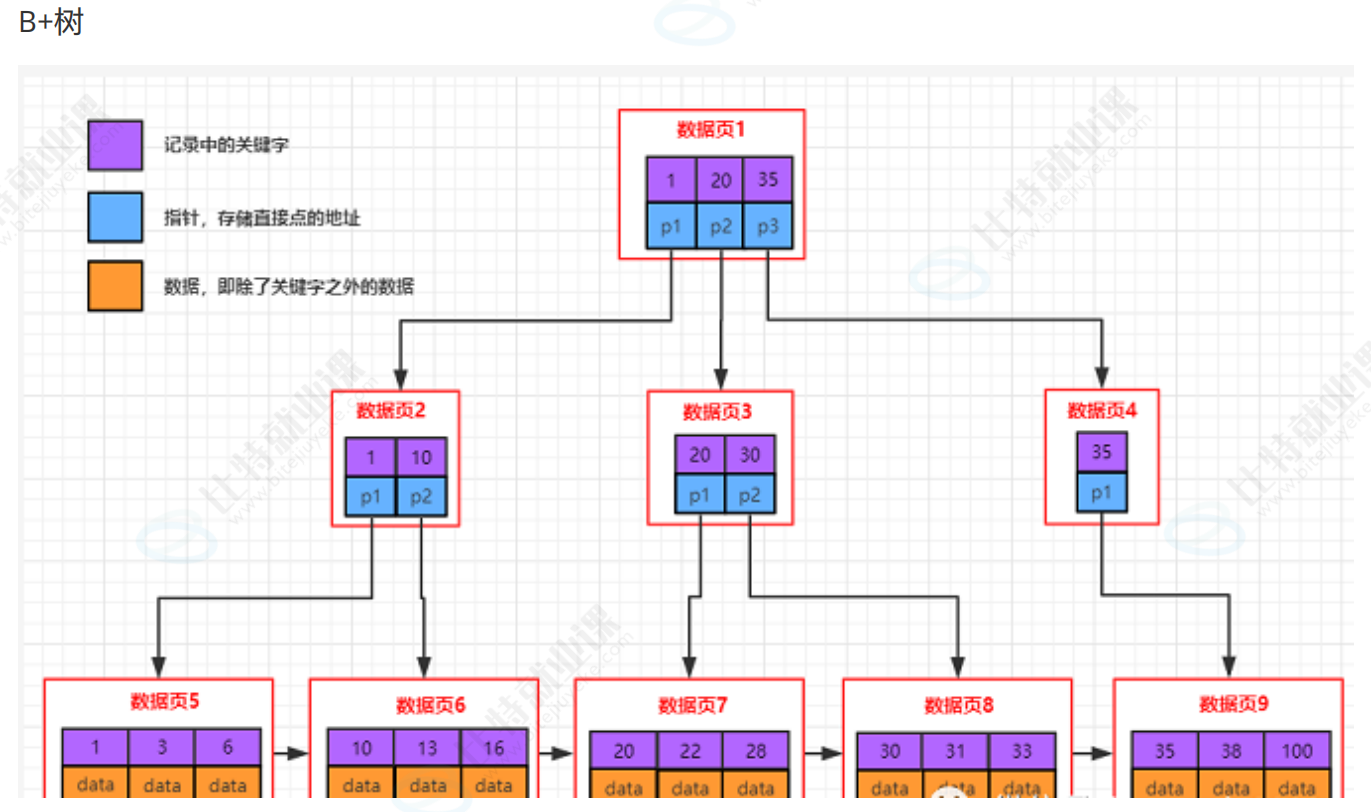
B+树索引结构
我们接着前面的内容,来看多层目录页如何演变成 B + 树索引结构,以及它为什么能让查询效率实现质的飞跃。
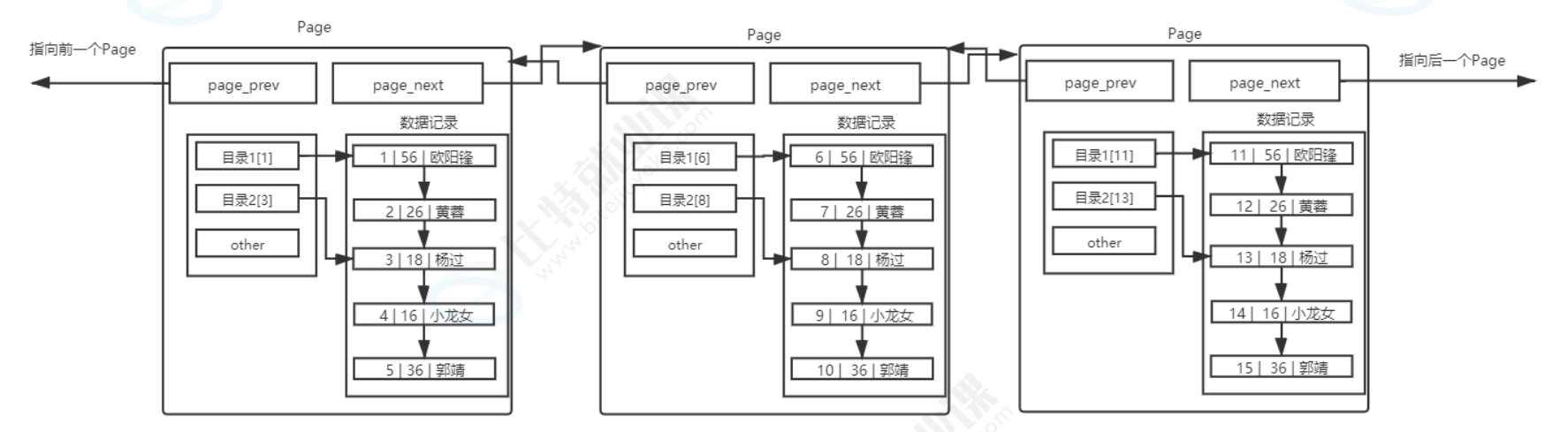
随着数据量越来越大,管理数据页的目录页也会越来越多,如果我们还是线性遍历这些目录页,效率又会回到原点。这时候我们可以用同样的思路,给目录页再加上一层更高层级的目录页,最终形成一个从上到下的层级结构,也就是我们常说的 B + 树。从下图可以看到,最顶层是根目录页,中间是各级非叶子节点,最底层是存储用户数据的叶子节点页。查找数据时,我们直接从根节点往下索引,完全不需要再进行线性遍历,每次查找的页数量大幅减少,IO 次数也随之降低,查询效率自然就提上来了。
B + 树有几个关键的设计特点,正是这些特点让它成为了 MySQL 的首选索引结构。首先,非叶子节点不存储数据,只存储目录项,也就是键值和指针。这样一来,单个目录页就能存储更多的目录项,管理更多的子节点页,让整棵树保持**"矮胖型"** 的结构,树的高度会被控制得很低,查找时需要访问的页数量就会非常少,IO 次数也随之大幅减少。其次,叶子节点全部用双向链表串联起来,这是 B + 树的重要特性,能让我们高效地进行范围查询,比如查询 id 在 1 到 100 之间的数据,只需要找到起始节点,然后顺着链表往后遍历即可,不用再回到上层节点反复跳转。
我们可以总结一下 B + 树索引提升效率的核心逻辑:
每个节点都包含目录项,能让我们快速缩小查找范围,减少不必要的页访问;
矮胖型的树结构,让查找路径上的节点数量极少,需要读取的页数量也就很少;
叶子节点的链表结构,又让范围查询变得非常高效。
这种结构正是 MySQL InnoDB 引擎的索引底层实现,即使我们建表时没有设置主键,MySQL 底层也会自动生成隐藏列来构建 B + 树索引,所有的增删改查操作,都是在这个结构上完成的。
复盘一下:
首先复盘一下 B + 树索引的核心逻辑。在 B + 树结构中,Page被分为两种:目录页和数据页。目录页只存储各个下级 Page 的最小键值和指针,不存储实际数据;查找数据时,我们从顶层目录页自顶向下检索,只需要加载少量目录页到内存中,就能快速定位到目标数据所在的数据页,大幅减少了磁盘 IO 次数。
接下来我们对比一下,为什么其他数据结构不适合作为 MySQL 的索引底层:
链表:只能线性遍历,每次查找都要逐个比对,效率极低,完全无法应对海量数据场景。
二叉搜索树:在极端情况下会退化成线性结构,查询效率直接从 O (logn) 降到 O (n),无法保证稳定的性能。
AVL 树和红黑树:虽然是平衡二叉树,但本质还是二叉结构,树的整体高度会比多阶的 B + 树高很多。树越高,查询时需要访问的节点就越多,磁盘 IO 次数也会随之增加,效率不如 B + 树。
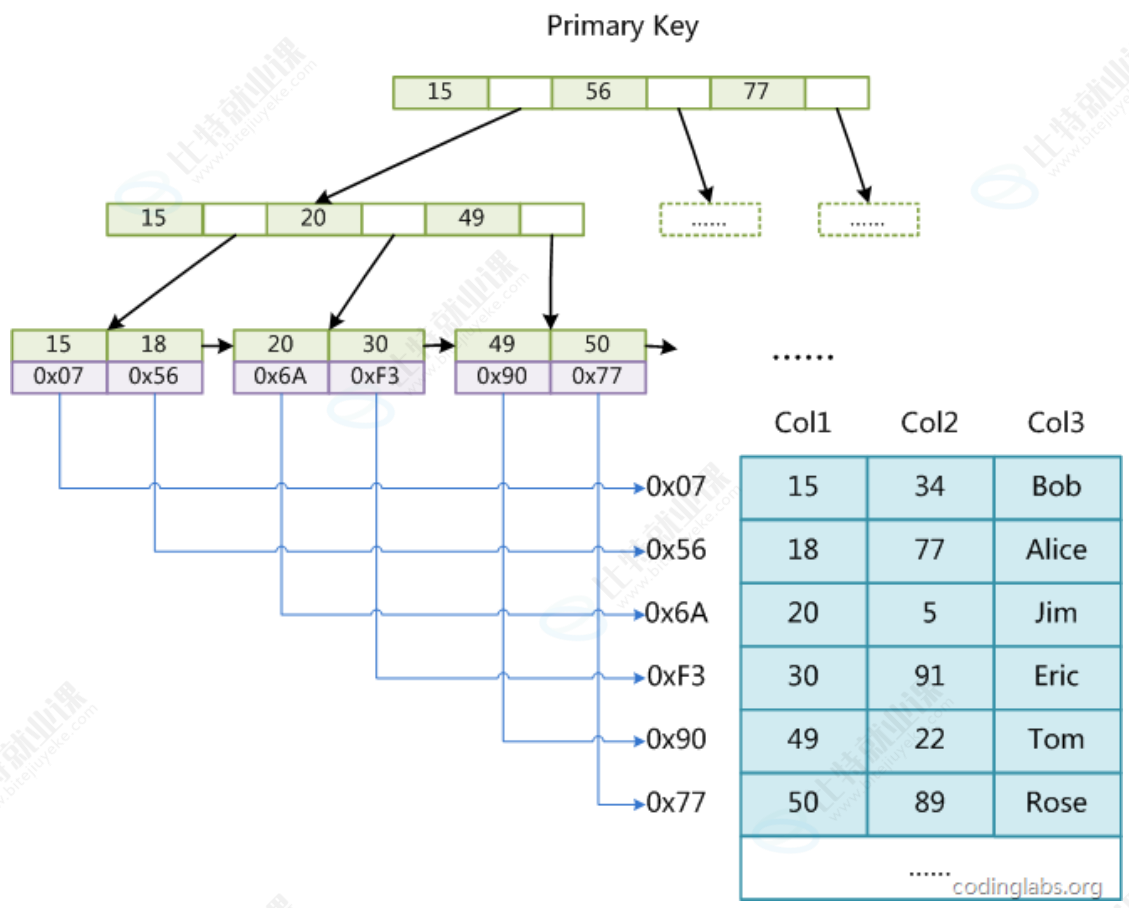
再看 InnoDB 的辅助索引,它的实现和主键索引(聚簇索引)完全不同。从图中可以看到,基于Col3建立的辅助索引,叶子节点里并没有存储完整的数据,只存储了对应记录的主键值。这意味着,当我们通过辅助索引查找数据时,需要执行两次索引查找:首先在辅助索引的 B + 树中找到目标记录的主键值,再拿着这个主键值去聚簇索引的 B + 树中,找到完整的数据记录,这个过程就叫做 "回表查询"。
接下来我们看索引的常见分类,这些也是实际开发中最常用的几种索引类型。
最终表结构中就有8000000条员工记录,也就是创建出了海量的数据。
索引创建完成后,我们再次执行相同的查询语句,查询员工编号为 998877 的员工,这次的查询耗时直接降到了 0.00 秒,几乎是瞬间完成。这是因为索引改变了数据的组织方式,数据库不再需要逐条遍历,而是可以通过索引结构直接定位到目标记录,查询效率得到了质的提升。



首先,我们创建了一张 user 表,其中 id 字段被设置为 primary key 主键。从建表语句和表结构可以看到,id 字段带有 PRI 标识,这意味着 MySQL 会自动为 id 创建主键索引,这是我们接下来要观察的关键点。


从图中可以看到,B 树的每个节点都会同时存储键值、指针和数据