很多开发者第一次接入 AI API 时,最关心的是 Base URL 怎么填、API Key 怎么申请、模型 ID 怎么写。
但真正进入日常使用后,更影响体验的往往不是第一条请求能不能跑通,而是高峰期偶发 timeout、批量任务触发 rate_limit、工具端提示网络异常、团队成员反复怀疑是不是 Key 或模型配置出了问题。
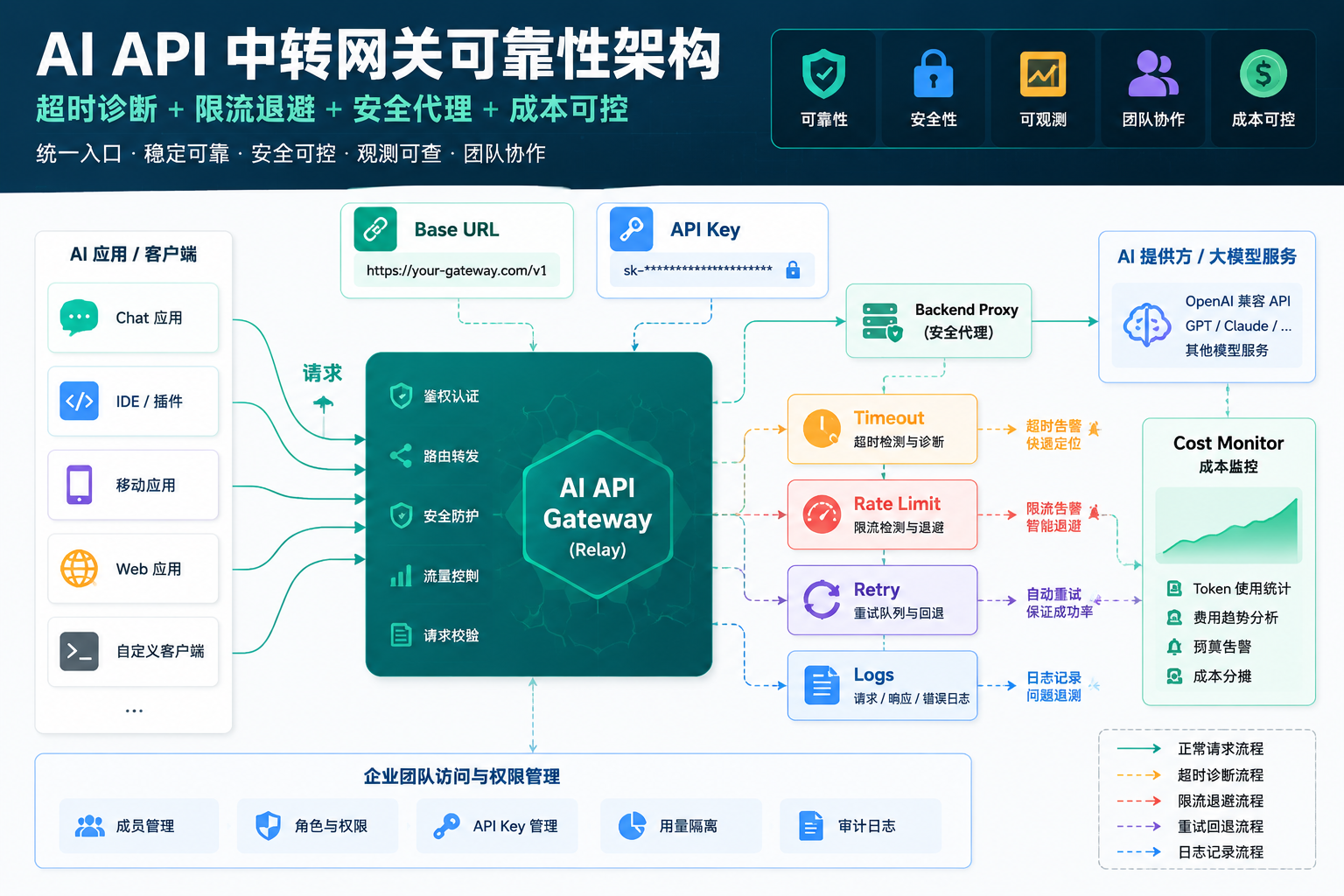
如果只是个人在 Chatbox 或 Cherry Studio 里问几个问题,偶发失败可以手动重试。
如果是 Dify 工作流、Cursor 代码辅助、内部客服机器人、批量内容处理脚本或企业后端服务,timeout 和 rate_limit 就不能只靠刷新页面解决。
它们需要一套可复用的排查方法:先确认 Base URL 和 API Key 没有问题,再看请求超时时间、模型响应耗时、并发量、重试策略、日志字段和成本控制。
向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。
注册试用入口:https://178.nz/csdn
本文不讨论抽象概念,而是按真实接入顺序写一套工程排查清单。
你可以把它当成一篇 OpenAI 兼容接口稳定性接入笔记:从注册后拿 Key、填写 Base URL、用 curl 验证,到 Python 重试、Node.js 后端代理、Dify/Cursor/Chatbox/Cherry Studio 配置,再到企业团队怎么做日志审计、限流、成本观察和 API Key 安全管理。
一、先判断问题属于哪一层
排查 timeout 和 rate_limit 之前,先不要急着改模型、换 Key 或重装工具。
这两个报错看起来都像"接口不可用",但原因完全不同。
timeout 通常表示请求在客户端、网关、上游模型或网络链路中的某一段等待时间超过阈值。
常见原因包括:客户端默认超时时间太短、模型输出过长、上下文过大、并发排队、网络波动、后端代理没有正确转发流式响应。
rate_limit 通常表示请求频率、并发数、额度、账户策略或模型侧限制被触发。
常见原因包括:同一 API Key 被多人共用、Dify 批量节点并发过高、Cursor 或脚本短时间内连续请求、后端没有队列、失败后立即重试导致请求更密集。
还有一类容易混淆的情况:真正的错误是 invalid_api_key 或 model_not_found,但工具端只显示网络异常或请求失败。
所以第一步应该把问题分层:
| 现象 | 更可能的位置 | 先检查什么 |
|---|---|---|
| 所有工具都失败 | Key、Base URL、账户状态 | API Key 是否正确,Base URL 是否写到 /v1 |
| 只有 Dify 工作流超时 | 工作流节点和输出长度 | 节点超时时间、上下文长度、是否需要流式输出 |
| 只有 Cursor 失败 | IDE 代理或第三方接口配置 | Base URL、模型名、系统代理、请求模式 |
批量脚本一跑就 rate_limit |
并发与重试策略 | 并发数、退避时间、单 Key 使用人数 |
| 偶发超时,重试后成功 | 网络或模型耗时波动 | 客户端 timeout、重试次数、日志耗时 |
| 失败后越来越频繁 | 立即重试造成放大 | 是否有指数退避、是否有队列 |
如果你正在评估国内 AI API 中转站是否适合团队使用,建议不要只看单次 curl 成功。
更合理的做法是把 timeout、rate_limit、日志、重试和成本统计一起纳入候选方案测试。
向量引擎这类 OpenAI 兼容接口服务,适合先用小额测试把接入路径、工具配置和错误处理跑顺,再决定是否扩大使用范围。
二、注册试用后先拿到 API Key,再写清三个地址
注册向量引擎后,第一步不是直接把 Key 发给所有同事,而是先用一个测试 Key 跑最小请求。
建议准备三类信息:
text
服务根地址:https://api.vectorengine.cn
OpenAI 兼容 Base URL:https://api.vectorengine.cn/v1
Chat Completions 完整请求地址:https://api.vectorengine.cn/v1/chat/completions这三行要分清用途。
在 Dify、Cursor、Chatbox、Cherry Studio 这类工具里,通常填写的是 OpenAI 兼容 Base URL,也就是:
text
https://api.vectorengine.cn/v1工具会自己拼接 /chat/completions 或 /models。
如果把完整请求地址填进工具的 Base URL 字段,可能会拼成重复路径。
如果只填服务根地址,又可能少了 /v1。
这两类问题在一些工具里不一定直接显示路径错误,可能表现成 timeout、连接失败、模型不可用或通用请求异常。
自写 curl、Python、Node.js 时,才会直接请求完整地址:
text
https://api.vectorengine.cn/v1/chat/completions企业团队可以把这三个地址写进接入文档,并规定客户端只拿到必要信息。
比如普通工具用户只看到 Base URL 和可用模型名,后端服务只通过环境变量读取 API Key,管理员再统一记录 Key 的用途、负责人、额度和轮换时间。
三、用 curl 做最小稳定性验证
在工具里反复点"测试连接"之前,先用 curl 验证最小链路。
这样可以把工具 UI、系统代理、工作流节点配置这些干扰因素先排除掉。
bash
curl --connect-timeout 10 --max-time 60 \
https://api.vectorengine.cn/v1/chat/completions \
-H "Authorization: Bearer $VECTOR_ENGINE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "用一句话说明 OpenAI Compatible API 的含义"
}
],
"temperature": 0.2,
"max_tokens": 120
}'这条命令里有两个超时参数。
--connect-timeout 10 是连接建立超时,适合判断网络是否能连上。
--max-time 60 是整个请求最多等待 60 秒,适合避免命令行一直挂住。
如果这里返回正常,再去配置 Dify、Cursor、Chatbox 或 Cherry Studio。
如果这里失败,先按下面顺序看:
invalid_api_key:Key 是否复制完整,是否多了空格,是否用错环境变量。model_not_found:模型 ID 是否在当前账户可用,工具里模型名是否与接口一致。timeout:连接超时还是总耗时超时,是否请求了过长输出。rate_limit:是否短时间多次请求,是否有脚本或团队成员共用同一个 Key。- 404 或路径异常:Base URL 和完整请求地址是否混用。
curl 通过后,建议再测一次较短输出和一次较长输出。
如果短输出稳定、长输出容易超时,问题可能在上下文长度、输出长度或客户端等待时间。
如果短输出也经常失败,才优先看网络、Key、账户状态或接口入口。
四、Python 调用:给 timeout、重试和退避留出明确策略
很多 Python 示例只写一条 requests.post(),这对 Demo 足够,但不适合生产脚本。
真实批量任务至少要处理超时、限流、非 JSON 响应和退避。
下面的示例故意不封装得太复杂,重点是展示一套可读的排查逻辑。
python
import os
import time
import requests
API_KEY = os.environ["VECTOR_ENGINE_API_KEY"]
URL = "https://api.vectorengine.cn/v1/chat/completions"
def call_chat(prompt: str, max_retries: int = 3) -> str:
payload = {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "你是一个简洁的技术助手。"},
{"role": "user", "content": prompt},
],
"temperature": 0.2,
"max_tokens": 300,
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
for attempt in range(max_retries + 1):
start = time.time()
try:
resp = requests.post(
URL,
headers=headers,
json=payload,
timeout=(10, 90), # 连接超时 10 秒,读取超时 90 秒
)
cost_ms = int((time.time() - start) * 1000)
if resp.status_code == 429:
wait_seconds = min(2 ** attempt, 16)
print(f"rate_limit: attempt={attempt}, wait={wait_seconds}s, cost={cost_ms}ms")
time.sleep(wait_seconds)
continue
if resp.status_code >= 500:
wait_seconds = min(2 ** attempt, 16)
print(f"server_error: status={resp.status_code}, wait={wait_seconds}s")
time.sleep(wait_seconds)
continue
resp.raise_for_status()
data = resp.json()
return data["choices"][0]["message"]["content"]
except requests.Timeout:
wait_seconds = min(2 ** attempt, 16)
print(f"timeout: attempt={attempt}, wait={wait_seconds}s")
time.sleep(wait_seconds)
except requests.HTTPError as exc:
print(f"http_error: status={resp.status_code}, body={resp.text[:300]}")
raise exc
raise RuntimeError("AI API request failed after retries")
if __name__ == "__main__":
print(call_chat("给我一个 Dify 接入 OpenAI 兼容接口的检查清单"))这段代码里最重要的不是 requests,而是四个工程约定。
第一,超时时间要拆成连接超时和读取超时。
连接超时短一些,读取超时可以根据模型和输出长度放宽。
第二,429 不要立即重试。
立即重试会把限流问题放大,应该做指数退避,并给上游留出恢复窗口。
第三,日志里要记录 attempt、status、cost_ms、模型名和任务 ID。
没有这些字段,后续很难判断是模型慢、网络慢、Key 受限,还是脚本并发过高。
第四,失败后要把错误抛出去,而不是静默返回空字符串。
Dify 节点、后端任务队列和批处理脚本都需要知道任务是否真的失败。
五、Node.js 后端代理:把 Key、限流和日志放在服务端
如果团队里多人使用 Dify、Cursor、Chatbox、Cherry Studio 或自建前端,不建议把同一个 API Key 分发到每台电脑。
更稳妥的方式是通过后端代理统一转发。
这样可以集中处理 Key 安全、日志审计、限流、重试、成本统计和模型白名单。
下面是一个 Express 代理示例,重点展示队列保护、超时和错误归一化。
js
import express from "express";
const app = express();
app.use(express.json({ limit: "1mb" }));
const API_KEY = process.env.VECTOR_ENGINE_API_KEY;
const UPSTREAM_URL = "https://api.vectorengine.cn/v1/chat/completions";
let running = 0;
const MAX_CONCURRENCY = 4;
function normalizeError(status, body) {
const text = typeof body === "string" ? body : JSON.stringify(body || {});
if (status === 401 || text.includes("invalid_api_key")) {
return { code: "invalid_api_key", message: "API Key 无效或权限不足" };
}
if (status === 404 || text.includes("model_not_found")) {
return { code: "model_not_found", message: "模型 ID 不存在或当前 Key 不可用" };
}
if (status === 429 || text.includes("rate_limit")) {
return { code: "rate_limit", message: "请求过于频繁,请降低并发并启用退避" };
}
if (status === 408 || text.includes("timeout")) {
return { code: "timeout", message: "请求超时,请检查输出长度、网络和上游耗时" };
}
return { code: "upstream_error", message: "上游接口返回异常" };
}
async function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function waitForSlot() {
while (running >= MAX_CONCURRENCY) {
await sleep(200);
}
running += 1;
}
async function callUpstream(payload, requestId) {
await waitForSlot();
const started = Date.now();
const controller = new AbortController();
const timeout = setTimeout(() => controller.abort(), 90_000);
try {
const resp = await fetch(UPSTREAM_URL, {
method: "POST",
signal: controller.signal,
headers: {
Authorization: `Bearer ${API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify(payload),
});
const text = await resp.text();
const costMs = Date.now() - started;
console.log(JSON.stringify({
requestId,
model: payload.model,
status: resp.status,
costMs,
promptMessages: payload.messages?.length || 0,
}));
if (!resp.ok) {
throw Object.assign(new Error("upstream failed"), {
status: resp.status,
detail: normalizeError(resp.status, text),
});
}
return JSON.parse(text);
} catch (err) {
if (err.name === "AbortError") {
throw Object.assign(new Error("timeout"), {
status: 408,
detail: normalizeError(408, "timeout"),
});
}
throw err;
} finally {
clearTimeout(timeout);
running -= 1;
}
}
app.post("/internal/ai/chat", async (req, res) => {
const requestId = req.header("x-request-id") || crypto.randomUUID();
const payload = {
model: req.body.model || "gpt-4o-mini",
messages: req.body.messages,
temperature: req.body.temperature ?? 0.2,
max_tokens: Math.min(req.body.max_tokens ?? 600, 1200),
};
try {
const data = await callUpstream(payload, requestId);
res.json(data);
} catch (err) {
const detail = err.detail || normalizeError(err.status || 500, err.message);
res.status(err.status || 500).json({ requestId, error: detail });
}
});
app.listen(3000, () => {
console.log("AI proxy listening on http://localhost:3000");
});这个代理不是为了让请求变复杂,而是为了把不应该散落在客户端里的逻辑收回来。
比如 API Key 不再写进前端页面,团队成员也不直接复制 Key。
Dify 或内部系统可以只访问 /internal/ai/chat,后端再统一转发到向量引擎的 OpenAI 兼容接口。
如果你后续要接入企业日志平台,可以在 console.log 的结构化日志里增加 userId、teamId、feature、token 估算、重试次数和错误分类。
这比事后翻聊天工具截图更容易定位问题。
六、Dify 配置:重点看 Base URL、模型名和节点超时
Dify 接入 OpenAI 兼容接口时,通常按"自定义模型供应商"或 OpenAI Compatible 类配置。
可以按下面顺序检查:
| 配置项 | 建议填写或检查 |
|---|---|
| Provider 类型 | OpenAI Compatible 或自定义兼容供应商 |
| Base URL | https://api.vectorengine.cn/v1 |
| API Key | 从向量引擎控制台获取,粘贴时不要带空格 |
| Model | 使用当前账户可用的模型 ID |
| Completion endpoint | 由工具自动拼接,通常不要手动填完整 /chat/completions |
| Timeout | 工作流节点里按任务复杂度设置,不要用过短默认值 |
Dify 工作流更容易触发 rate_limit 的场景,是批量处理、循环节点、知识库召回后长上下文总结,以及多个用户同时运行同一个应用。
如果你遇到工作流前几条成功、后面开始失败,可以先降低并发或加等待节点。
排查顺序建议是:
- 用同一个 Key 在 curl 里跑通最小请求。
- 在 Dify 里只配置一个简单聊天模型,不要立刻接完整工作流。
- 把输入文本缩短,确认短请求稳定。
- 再逐步增加上下文、工具调用和知识库召回。
- 如果批量触发
rate_limit,优先降低并发,而不是立刻增加重试次数。
对于企业使用,Dify 不一定要直接持有最终生产 Key。
可以把 Dify 指向内部代理,再由后端代理连接 https://api.vectorengine.cn/v1。
这样团队可以统一做限流、日志和 Key 轮换。
七、Cursor 配置:先验证第三方 Base URL,再看 IDE 代理
Cursor 配置第三方 OpenAI 兼容接口时,常见问题集中在 Base URL、模型名、系统代理和请求超时。
如果你准备用向量引擎做候选接入方案,可以先按这组信息准备:
text
API Key: 从向量引擎控制台复制
Base URL: https://api.vectorengine.cn/v1
Model: 选择当前账户可用模型Cursor 这类 IDE 工具的特点是请求频率不完全由你手动控制。
补全、聊天、代码解释、上下文读取都可能触发多次请求。
如果同一把 Key 同时给 Cursor、Chatbox、Dify 和后端脚本使用,rate_limit 的定位会变得很混乱。
建议至少做三点隔离:
- 给 Cursor 单独分配测试 Key,方便看请求来源。
- 先关闭不必要的自动请求功能,只保留聊天或代码解释。
- 如果公司网络有系统代理,先确认 curl 和 Cursor 走的是同一条出口链路。
如果 Cursor 显示网络错误,但 curl 正常,通常要检查 IDE 里的代理设置、证书拦截、Base URL 是否多写了路径,以及模型名是否被自动替换。
如果 curl 也超时,就先不要在 Cursor 里反复重试,先回到网络和接口层排查。
八、Chatbox 和 Cherry Studio:适合做普通用户侧验证
Chatbox 和 Cherry Studio 这类客户端适合用来验证"普通用户拿到配置后能不能顺利使用"。
它们比后端脚本更接近真实个人用户场景,也更容易暴露 Base URL、API Key、模型名和代理设置问题。
Chatbox 配置时,一般选择自定义 OpenAI 兼容服务:
text
服务类型:OpenAI Compatible / 自定义 OpenAI
API Key:向量引擎控制台生成的 Key
API Host 或 Base URL:https://api.vectorengine.cn/v1
模型:填写可用模型 IDCherry Studio 配置时,通常是添加自定义服务商:
text
Provider:自定义
API Key:向量引擎控制台生成的 Key
Base URL:https://api.vectorengine.cn/v1
模型列表:手动添加或从接口拉取如果这两个工具都能稳定对话,而 Dify 工作流失败,说明基础 OpenAI 兼容接口大概率没问题,问题更可能在工作流节点、上下文长度、并发或超时设置。
如果这两个工具也失败,再回到 curl 检查。
普通用户侧验证建议覆盖三类问题:
| 测试项 | 目的 |
|---|---|
| 一句话短问答 | 验证 Key、Base URL、模型 ID |
| 1000 字左右总结 | 验证读取超时和模型响应耗时 |
| 连续 10 次短请求 | 初步观察限流和客户端重试表现 |
这类测试不需要夸张流量。
目标是判断候选 API 接入方案是否适合继续评估,而不是一次性压满额度。
九、常见报错排查表
下面这张表可以直接放进团队接入文档。
它把常见错误和第一检查点放在一起,减少无效沟通。
| 报错或现象 | 常见原因 | 处理建议 |
|---|---|---|
invalid_api_key |
Key 复制不完整、Key 被禁用、环境变量读错 | 重新复制 Key,确认没有空格,检查服务端环境变量 |
model_not_found |
模型 ID 写错、当前账户不可用、工具自动改名 | 在模型列表确认 ID,先用 curl 跑通,再填工具 |
timeout |
输出过长、上下文过大、读取超时太短、上游响应慢 | 缩短输入,增加读取超时,开启流式输出或拆分任务 |
rate_limit |
并发过高、多人共用 Key、失败后立即重试 | 降低并发,做指数退避,给不同场景分配不同 Key |
| 404 | Base URL 与完整路径混用 | 工具填 https://api.vectorengine.cn/v1,代码请求完整接口 |
| 401 | Key 无效或请求头缺失 | 检查 Authorization: Bearer 格式 |
| 连接失败 | 本机代理、公司网络、防火墙、DNS 问题 | 对比 curl、浏览器和工具网络设置 |
| Dify 前几步成功后失败 | 工作流节点并发或上下文逐步变长 | 降低并发,拆分节点,限制每步输出 |
| Cursor 偶发失败 | IDE 自动请求密集或代理不一致 | 单独 Key,降低自动触发频率,检查代理 |
| 成本突然上升 | 重试放大、长上下文、多人共用 Key | 记录 requestId、userId、model、tokens 和重试次数 |
排查时要尽量避免只看一句错误提示。
同一个 timeout,可能是连接阶段失败,也可能是模型生成时间太长。
同一个 rate_limit,可能是账户额度策略,也可能是你自己的脚本把失败请求重复放大。
十、API Key 安全建议
API Key 安全不是出事后才处理的事情。
如果一开始就把 Key 发到群里、写进前端代码、提交到 Git 仓库,后续再做限流和审计会很被动。
建议按下面方式管理:
- 本地开发使用
.env,不要把 Key 写进源码。 - 后端服务通过环境变量读取 Key。
- Dify、Cursor、Chatbox、Cherry Studio 测试 Key 分开管理。
- 团队成员离职、项目下线或 Key 泄露时及时轮换。
- 日志里只记录 Key 后四位或 Key 标识,不记录完整 Key。
- 生产服务尽量通过后端代理统一转发,不在浏览器端暴露 Key。
- 给批量任务单独 Key,方便限流和成本归因。
如果怀疑 API Key 泄露,处理顺序应该是:先禁用或轮换旧 Key,再查看最近请求日志,最后排查泄露来源。
不要只在客户端改密码,因为已经泄露的 Key 仍可能被外部脚本调用。
十一、企业用户要额外评估哪些点
企业评估 API 中转或 OpenAI 兼容接口时,不应只看"单次调用能不能成功"。
更有价值的是一组可观察指标。
第一,稳定性。
记录不同时间段的成功率、P95 耗时、超时率和 rate_limit 比例。
如果只凭几次手动测试,很难判断高峰期表现。
第二,成本。
把模型、调用场景、输入长度、输出长度、重试次数和用户维度记录下来。
很多成本异常不是单价导致,而是长上下文和失败重试造成的。
第三,安全。
Key 是否能按项目、成员、环境分开。
是否能做到泄露后快速轮换。
是否能避免客户端直接暴露生产 Key。
第四,团队管理。
谁有权限创建 Key,谁能查看用量,谁负责处理报错,谁决定模型切换。
这些流程如果没有写清楚,后续所有问题都会变成"接口是不是坏了"。
第五,兼容性。
Dify、Cursor、Chatbox、Cherry Studio、自建 Python 脚本、Node.js 后端代理是否能走同一套 Base URL 和模型命名规则。
向量引擎这类候选方案的价值,主要体现在把这些工具和代码统一到 OpenAI 兼容接口形态下,便于后续排查和治理。
十二、FAQ
1. timeout 一定说明 API 中转站不可用吗?
不一定。
timeout 可能来自本机网络、客户端超时设置、输出过长、Dify 工作流节点耗时、后端代理没有流式转发,或者模型本身响应较慢。
先用 curl 的短请求验证,再逐步增加上下文和输出长度。
2. rate_limit 应该增加重试次数吗?
只增加重试次数通常不够,甚至可能放大问题。
更合理的是降低并发、加入指数退避、拆分批量任务,并给不同场景分配不同 Key。
3. Dify、Cursor、Chatbox、Cherry Studio 都应该填哪个 Base URL?
大多数 OpenAI 兼容工具应填写:
text
https://api.vectorengine.cn/v1不要把 https://api.vectorengine.cn/v1/chat/completions 当成工具 Base URL。
完整请求地址更适合 curl、Python 和 Node.js 代码直接调用。
4. 企业内部一定要做后端代理吗?
如果只是个人测试,可以先直接在工具里配置。
如果涉及多人、生产服务、客户数据、日志审计和成本管理,建议通过后端代理统一转发。
这样 Key 安全、限流、日志和模型白名单都更容易管理。
5. 向量引擎适合什么人先注册试用?
适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、后端代理转发、团队接口管理和成本观察的用户先做小范围评估。
如果你只需要偶尔网页聊天,不一定需要 API 接入方案。
6. 出现 invalid_api_key、model_not_found、timeout、rate_limit 时应该先查哪个?
建议按顺序查:Key 是否有效,Base URL 是否正确,模型 ID 是否可用,curl 是否跑通,工具配置是否多拼路径,最后再看超时、并发、退避和账户额度。
这样能避免把基础配置错误误判成稳定性问题。
总结
评估国内 AI API 中转站或 OpenAI 兼容接口时,不要只问"能不能用",更应该问"出错时能不能定位、团队使用时能不能管理、批量请求时能不能控制风险"。
向量引擎可以作为一个候选 API 接入方案来评估:先注册试用并获取 API Key,再确认 https://api.vectorengine.cn、https://api.vectorengine.cn/v1、https://api.vectorengine.cn/v1/chat/completions 三类地址的用途,随后用 curl、Python、Node.js 后端代理分别验证最小请求、重试退避和团队转发。
如果你正在把 Dify、Cursor、Chatbox、Cherry Studio 或内部后端服务接到统一模型入口,建议把 timeout、rate_limit、日志、成本和 API Key 安全一起纳入验收标准。
这样文章里的配置不只是能跑通一次,而是能支撑后续排查、协作和持续评估。