👉 欢迎阅读这篇文章 👇
目录
- 1、链表
- 2、单链表
- 3、链表的分类
-
- [3.1 分类介绍](#3.1 分类介绍)
- 3.2双向链表的结构
- 3.3循环链表的结构
- 3.4单链表和循环单链表的比较
- 3.5双向链表和双向循环链表比较
- 4、带头双向循环链表的实现
1、链表
我们前面介绍了顺序表是元素存储在物理上连续空间中,优势是访问任意位序元素的时间复杂度事 O ( 1 ) O(1) O(1),但是要想插入元素,需要挪动大量的数据,时间复杂度是 O ( n ) O(n) O(n),并且空间如果满了就需要扩容。
所以发明了链式结构来存储线性表。
链式存储:把逻辑上相邻的数据元素存储在任意的一组物理存储单元中,数据元素之间的逻辑关系用指针来表示。
链表的优势在于可以按需申请空间,不再需要扩容,需要存储一个数据就申请一块空间,用指针将空间与空间链接起来,存储数据和指针的这一块空间叫做结点(节点)。还有优势是在某个节点位置插入和删除数据不再需要挪动数据,直接更改结点之间的链接关系。
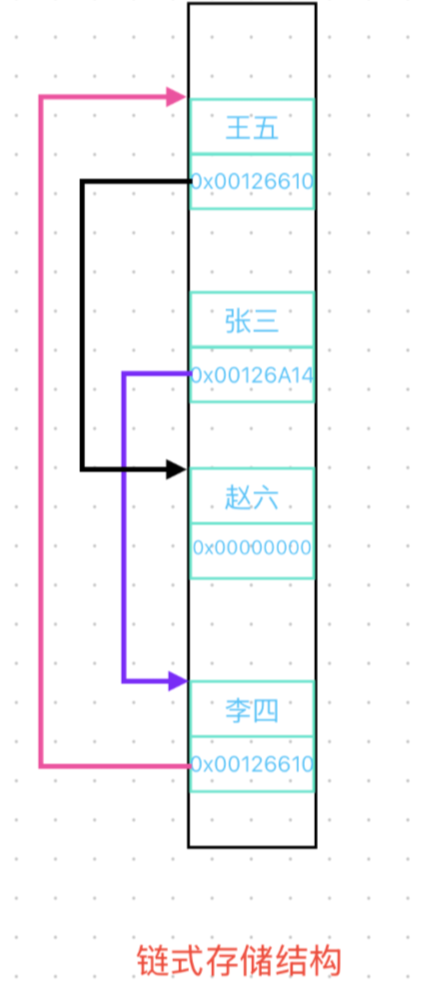
链表有很多种结构,先看一个单链表
2、单链表
2.1单链表的定义
单链表的结点中既要存储值,也要存储后继元素结点的指针。
结点的定义:
c
//定义结点
typedef int LDataType;
typedef struct ListNode
{
LDataType data;//存放数据
struct ListNode* next;//存放后继结点的指针
}LNode,*LinkList;单链表的特点:
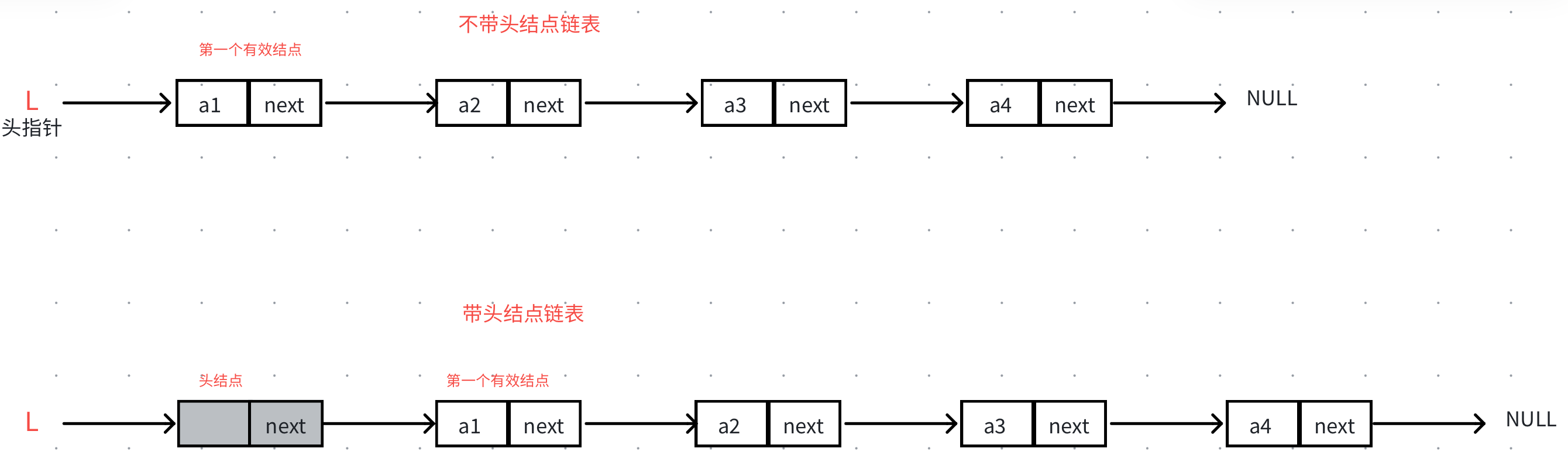
- 指向第一个结点的指针叫头指针。尾结点的指针指向空
- 单链表分为带头结点和不带头结点两种结构。头结点也叫哨兵位,不存储有效数据。
2.2接口函数定义
以下定义是针对带头结点的单链表进行研究的。
c
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int LDataType;
//定义结点
typedef struct ListNode
{
LDataType data;//存放数据
struct ListNode* next;//存放下一个结点的地址
} LNode,*LinkList;
//创建一个新结点
LNode* BuyListNode(int data);
//初始化
LNode* ListInit();
//打印链表
void Listprint(LNode* L);
//获取链表中有效元素的个数
int Listsize(LNode* L);
//按值查找
LNode* ListLocateElem(LNode*L,LDataType x);
//按下标查找
LNode* ListGetElem(LNode*L,int i);
//在下标为i的位置插入元素x
void ListInsert(LNode*L,int i,LDataType x);
//删除下标为i的结点,返回删除结点里存放的数据
LDataType ListDelete(LNode*L,int i);
//头插
void ListPushFront(LNode* L, LDataType x);
//尾插
void ListPushBack(LNode* L, LDataType x);
//头删
LDataType ListPopFront(LNode* L);
//尾删
LDataType ListPopBack(LNode* L);
//销毁
void ListDestroy(LNode* L);2.3初始化
LNode* ListInit() 初始化函数使⽤了返回哨兵位头结点,因为我们函数内部要创建⼀个头结点,返回头结点指针。
代码演示
c
//新建一个结点
LNode* BuyListNode(int data)
{
//申请空间
LNode* newNode=(LNode*)malloc(sizeof(LNode));
if(newNode==NULL)
{
perror("BuyListNode malloc:");
return NULL;
}
//开辟成功后,对结点中的数据域和指针域进行初始化
newNode->data = data;
newNode->next = NULL;
return newNode;
}
LNode* ListInit()
{
LNode* node=BuyListNode(-1);
return node;
}如果使⽤传参⽅式调⽤ListInit以获取指向哨兵位的头指针,就必须使⽤⼆级指针 LNode** 作为形参才能解决问题 void ListInit(LNode** pL)。或者使用C++引用的方式,即void ListInit(LNode& pL);
2.4遍历打印和求长度
打印的核心操作是遍历链表,遍历链表的本质:在当前结点中的next成员拿到下一个结点的地址进行迭代。
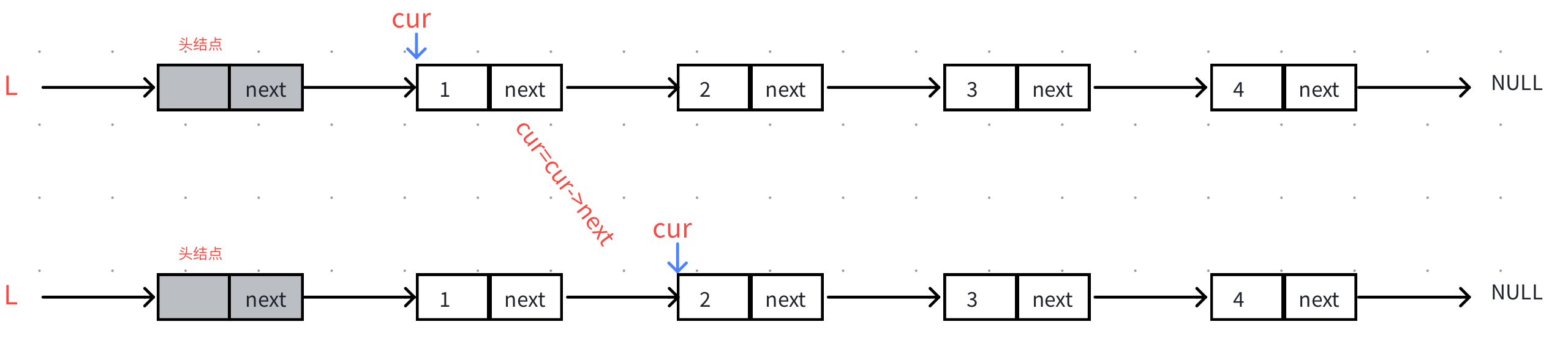
代码演示
c
void Listprint(LNode* L)
{
//哨兵位头指针不为空
assert(L);
//定义一个指针指向每一个结点
LNode* cur=L->next;
while(cur!=NULL)
{
printf("%d->",cur->data);
cur=cur->next;
}
printf("NULL\n");
}获取链表中有效元素的个数
代码演示
c
int ListLocateElem(LNode* L)
{
int n = 0;
LNode* cur=L->next;
while(cur!=NULL)
{
cur=cur->next;
n++;
}
return n;
}2.5查找
链表的查找分为按值查找和按下标查找
2.5.1按值查找
按值查找是遍历⼀遍链表,找到第⼀个值跟x相等的结点即返回,没有找到返回NULL。
代码演示
c
LNode* ListLocateElem(LNode*L,LDataType x)
{
assert(L);
LNode* cur=L->next;
while(cur!=NULL)
{
if(cur->data==x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}2.5.2按下标查找
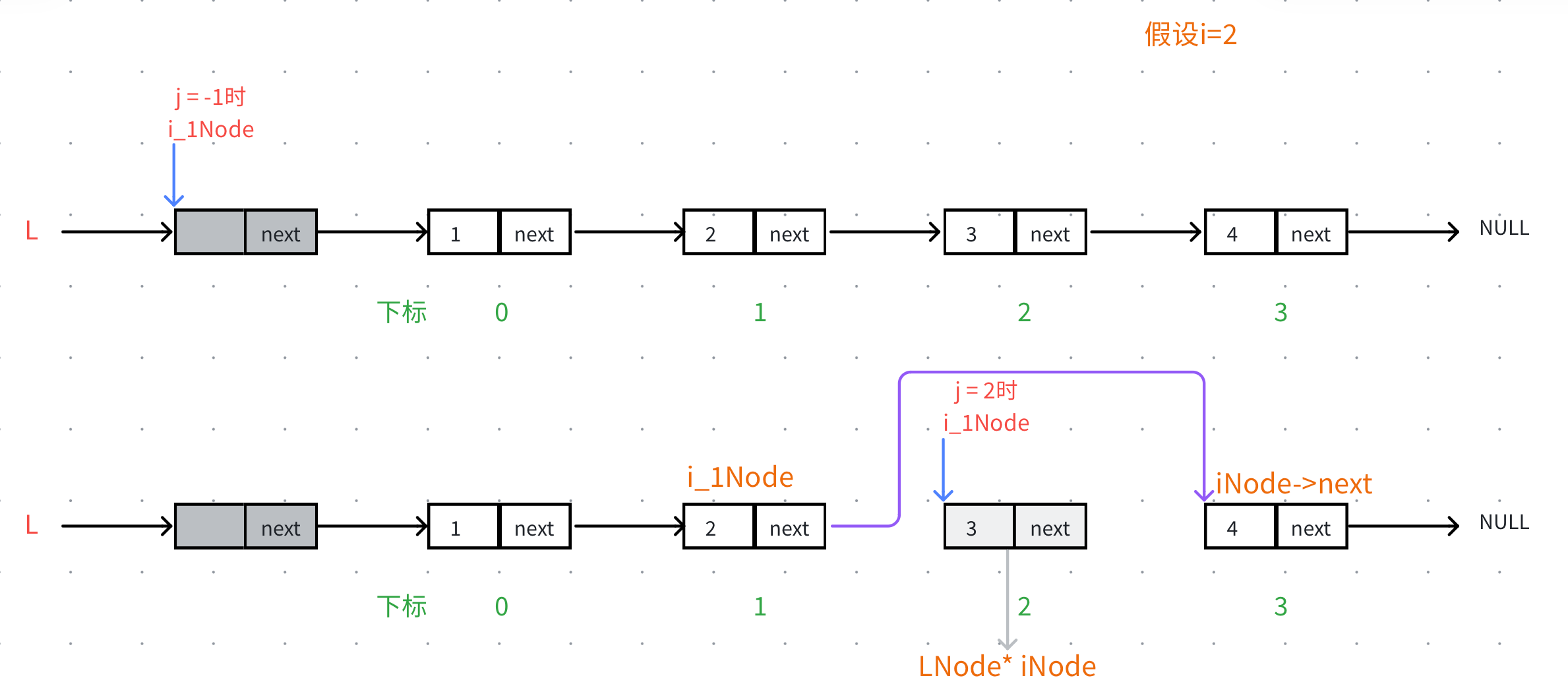
按下标查找相对更复杂一些,需要构造一个计数器j ,根据j的大小去遍历当j=i的时候就到了下标为i的这个结点。需要j<i&&iNode!=NULL 作为循环条件,因为链表的第i个结点不⼀定存在。(当i大于目前链表中结点个数的时候就不存在)。
代码演示
c
LNode* ListGetElem(LNode*L,int i)
{
assert(L);
int j = 0;
LNode* iNode = L->next;
while(j<i&&iNode!=NULL)
{
iNode = iNode->next;
j++;
}
return iNode;
}2.6插入
链表的插入不再需要像顺序表那样挪动数据,只需要改动结点间的链接关系,但是要在第i个结点之前插入,所以就要能够找到第i-1个结点i_1Node。
核心操作
- 找到
i_1Node,方法是利用计数器j和下标i的关系进行控制遍历次数,找到i_1Node - 计数器
j应该从-1开始,i_1Node最初应该是头指针,以保证头插的时候的正确性。 - 找到
i_1Node后,需要开辟一个新的结点newNode,需要让i_1Node->next指向newNode,而newNode->next需要指向i_Node->next(就是原iNode)。
注意 :为了保证正确,我们需要先操作newNode->next=i_Node->next再操作i_1Node->next=newNode。因为我们需要i_Node->next来代表第i个结点,如果先执行i_1Node->next=newNode,那么这时i_Node->next就是新插入的那个结点,无法找到第i个结点。
或者创建一个临时指针temp存储i_Node->next,后面再newNode->next=temp即可,这样顺序就不影响了。
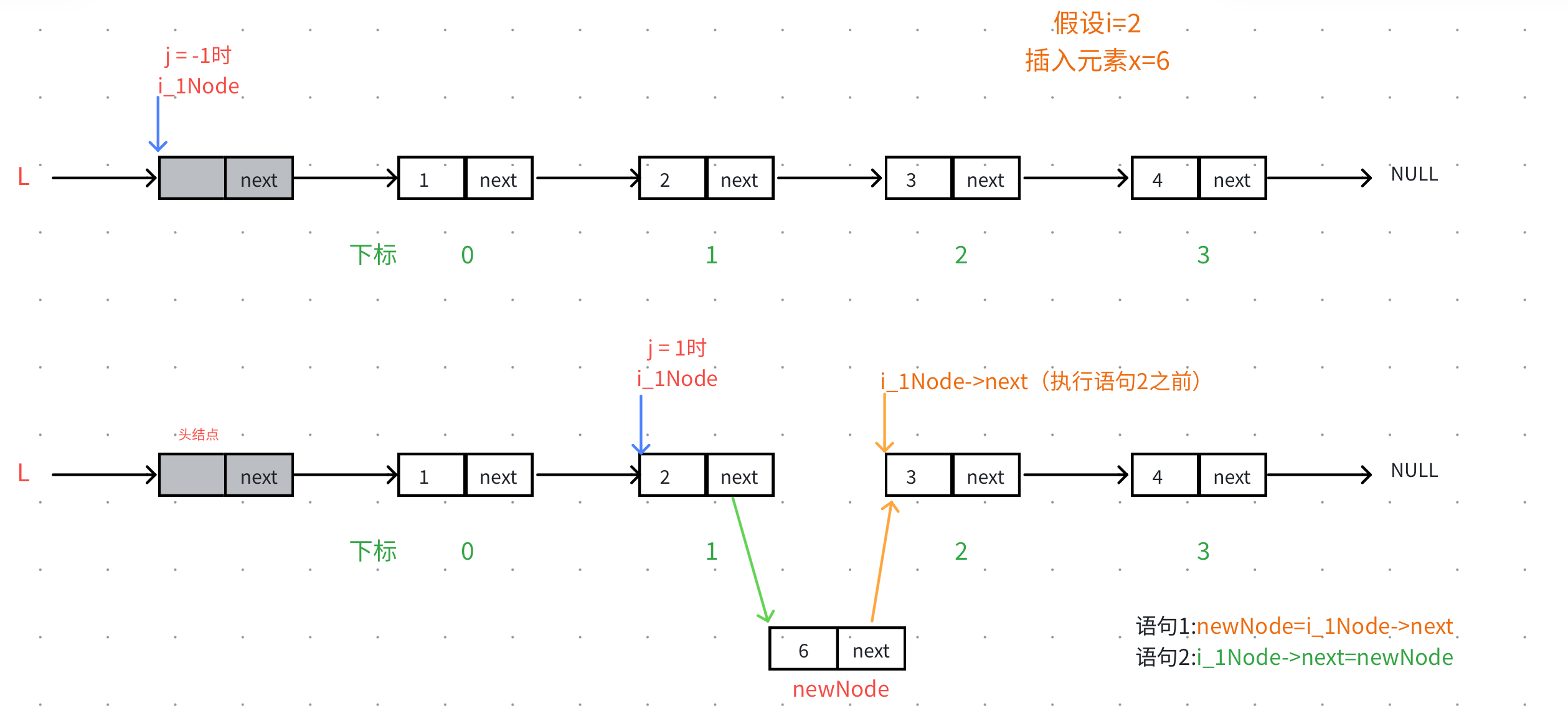
代码演示
c
void ListInsert(LNode*L,int i,LDataType x)
{
assert(L);
assert(i>=0);
//寻找i_1Node结点
int j = -1;
LNode* i_1Node = L;
while(j<i-1&&i_1Node!=NULL)
{
i_1Node = i_1Node->next;
j++;
}
//没有第i-1个结点,说明i非法
assert(i_1Node!=NULL);
//找到了第i-1个结点
LNode* newNode = BuyListNode(x);//创建新结点,放入要插入的元素x
//改变结点间的链接关系
newNode->next = i_1Node->next;//让新插入的结点的next指向原来下标为i的结点
i_1Node->next = newNode;//让原来的下标i-1的位置的结点指向新插入的结点
}2.7删除
链表的删除不再需要向顺序表那样挪动数据,只需要改动结点间的链接关系,要删除第i个结点,就需要找到第i-1个结点,叫i_1Node。
核心操作:
- 找到
i_1Node,方法是利用计数器j和下标i的关系进行控制遍历次数,找到i_1Node - 计数器
j应该从-1开始,i_1Node最初应该是头指针,以保证头删的时候的正确性。 - 具体操作的时候可以将删除的那个结点的数据返回
- 要先创建一个临时指针变量存储第i个结点的地址,防止后续找不到这个结点的位置。
- 执行完寻找
i_1Node的功能后,要检查前驱结点后的那个结点是否存在,检查要删除的结点是否存在。
注意:
如果没有头结点的链表删除,则形参 LNode** pL 必须⽤⼆级指针,因为如果i=0 头删时需要让实参头指针LT指向第i+1个结点(第2个结点),也就是 *pL = iNode->next;
所以不带头结点删除更复杂⼀些,因为要对头删单独判断处理,且要⽤⼆级指针处理。
代码演示:
c
//删除下标为i的结点,返回删除结点里存放的数据
LDataType ListDelete(LNode*L,int i)
{
assert(L);
assert(i>=0);
//查找下标为i-1的元素
int j = -1;
LNode* i_1Node = L;
while(j<i-1&&i_1Node!=NULL)
{
i_1Node = i_1Node->next;
j++;
}
//断言i不合法的情况和检查要删除的结点是否存在
assert(i_1Node!=NULL&&i_1Node->next!=NULL);
LNode* iNode = i_1Node->next;
//修改结点间链接地址
i_1Node->next = iNode->next;
LDataType x = iNode->data;
//释放删除的结点
free(iNode);
return x;
}2.8头尾删除插入
这些接口的实现可以直接复用上方的插入和删除函数
2.8.1头插
代码演示
c
void ListPushFront(LNode* L, LDataType x)
{
ListInsert(L, 0, x);
}2.8.2尾插
代码演示
c
void ListPushBack(LNode* L, LDataType x)
{
ListInsert(L, Listsize(L), x);
}2.8.3头删
代码演示
c
LDataType ListPopFront(LNode* L)
{
return ListDelete(L, 0);
}2.8.4尾删
代码演示
c
LDataType ListPopBack(LNode* L)
{
return ListDelete(L, Listsize(L) - 1);
}2.9销毁
链表的销毁就是不断遍历释放链表结点,不过需要先保存下⼀个结点,否则free了当前结点就找不到下⼀个结点了。
代码演示
c
void ListDestroy(LNode* L)
{
assert(L);
//构造遍历指针
LNode* cur=L->next;
//遍历释放
while(cur!=NULL)
{
//保存当前结点的下一个结点的指针
LNode* next = cur->next;
//释放当前结点
free(cur);
//把刚刚保存的下一个结点的指针赋给遍历指针
cur = next;
}3、链表的分类
3.1 分类介绍
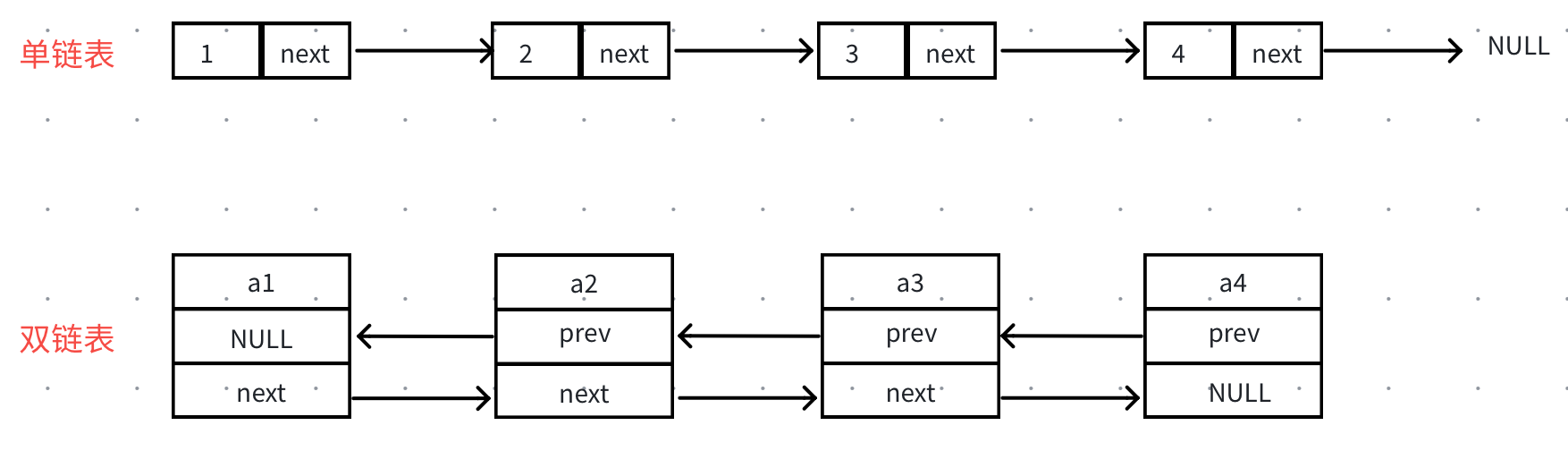
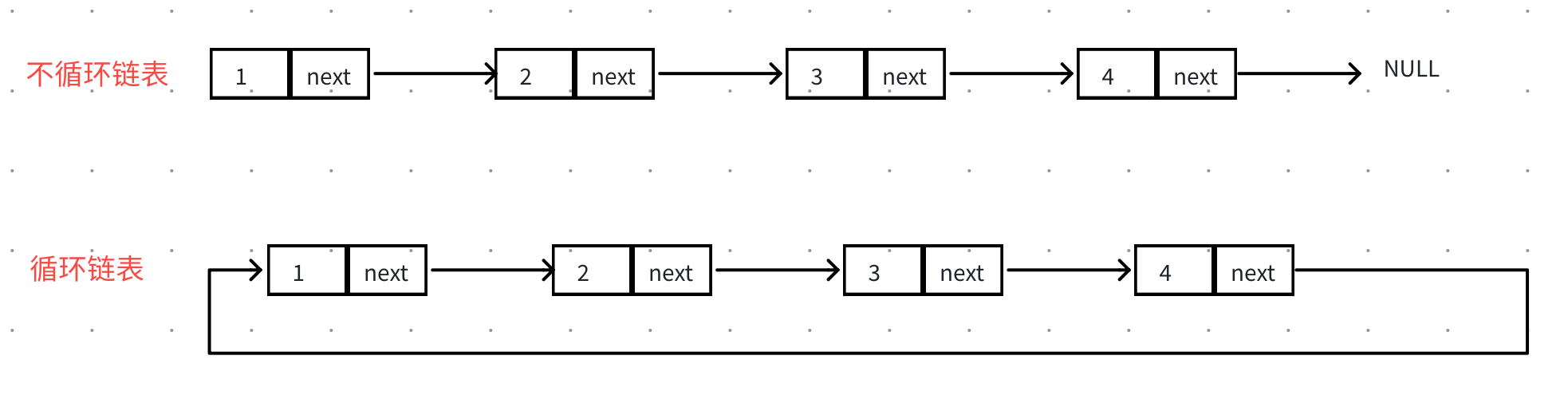
根据不同的需要,实践应用中出现了多种不同的链表结构,分为单向链表和双向链表、带头结点的链表和不带头结点的链表、循环链表和非循环链表。

将以上几种链表进行组合可以组合出8种链表结构
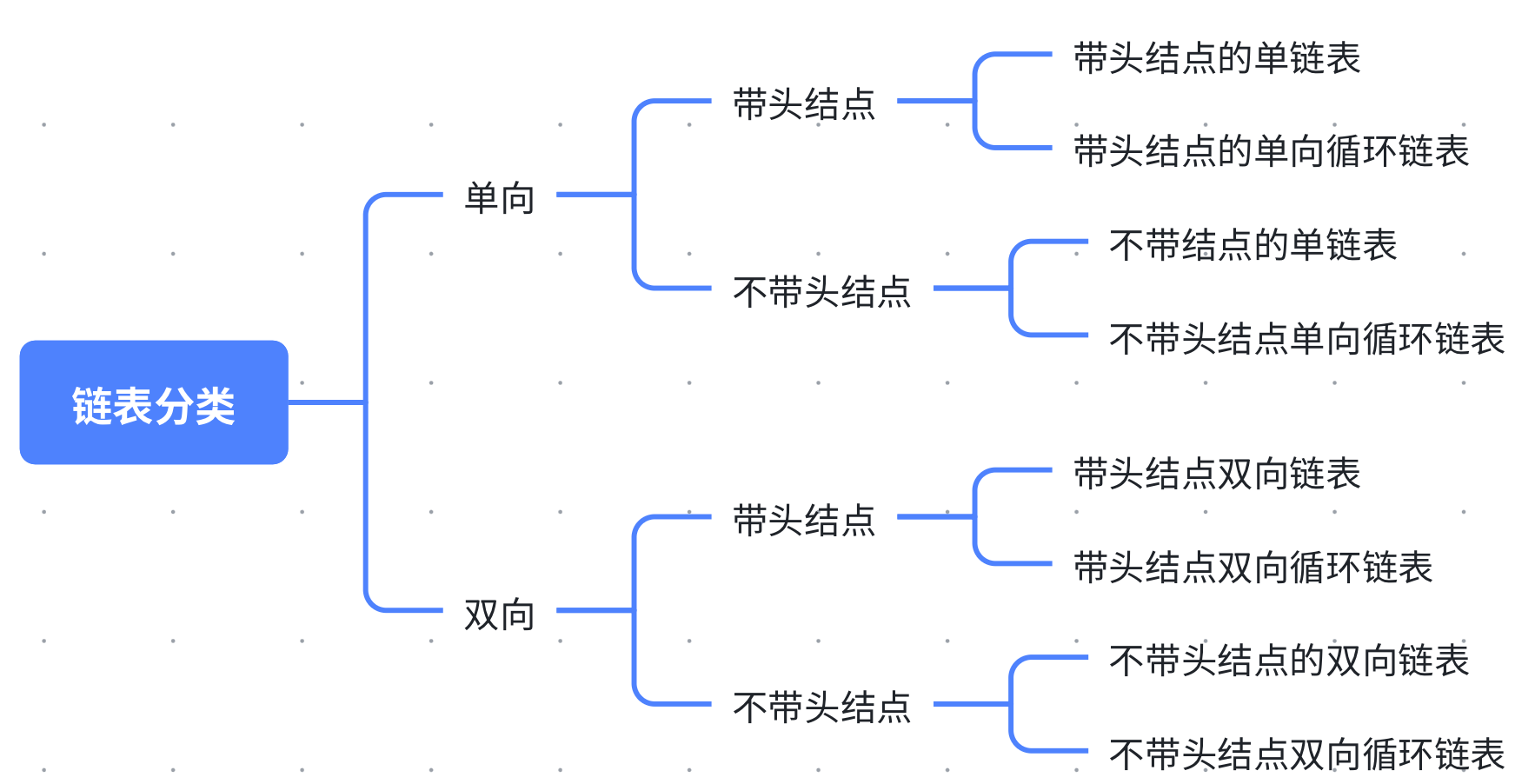
重点掌握带头结点单链表 /不带头结点单链表 /双向循环链表即可。
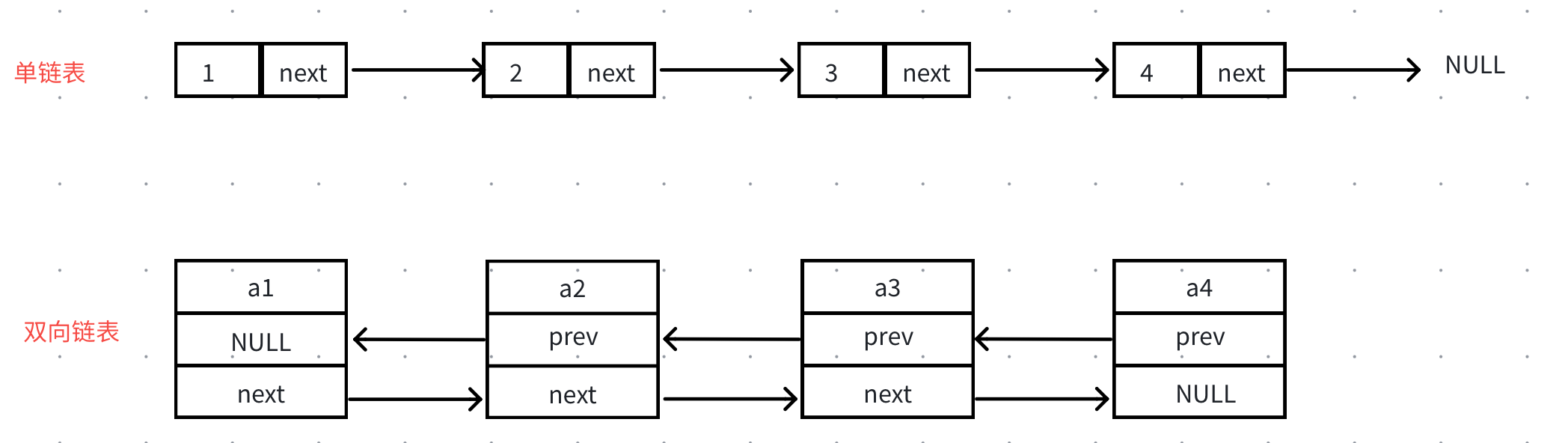
3.2双向链表的结构
通过前面的了解我们知道单链表中保存了指向后继结点的地址,所以在单链表中找当前结点的后继结点很容易,但要获取当前结点的前驱结点就很麻烦,只能从头开始遍历,时间复杂度为 O ( n ) O(n) O(n);
双向链表相比单链表的最大的一个特征是多了一个前驱指针,一些场景需要获取当前结点的前驱结点时就需要用到双向链表。
双向链表的⼀些不⾜是找尾结点依旧不是很⽅便,另外呢,头尾插⼊删除考虑的边界依旧⽐较多。后面的带头双向循环链表就可以很好地解决这些问题。
c
typedef int DLDataType;
struct DListNode
{
DLDataType data; //存放数据元素
struct DListNode* per; //指向前驱元素
struct DListNode* next;//指向后继元素
};
3.3循环链表的结构
实践应用中最常见的不是在第i个位序处插入删除元素,而是在头尾插入删除数据。
单链表头插头删效率很高,可以做到时间复杂度为 O ( 1 ) O(1) O(1),但是对于尾插尾删需要找到尾结点,时间复杂度为 O ( n ) O(n) O(n)。
双向链表头插头删效率⾼,确定某个结点位置以后插⼊删除效率也很⾼,均可以做到时间复杂度 O ( 1 ) O(1) O(1)
同样尾插尾删,需要增加⼀个尾指针,相对⿇烦;
所以这⾥我们引入循环链表可以解决这⾥的问题。
循环链表又可分为单向循环链表和双向循环链表
单向循环链表就是让尾结点的next指向头结点,双向循环链表就是尾结点的next指向头结点同时头结点的prev指向尾结点。
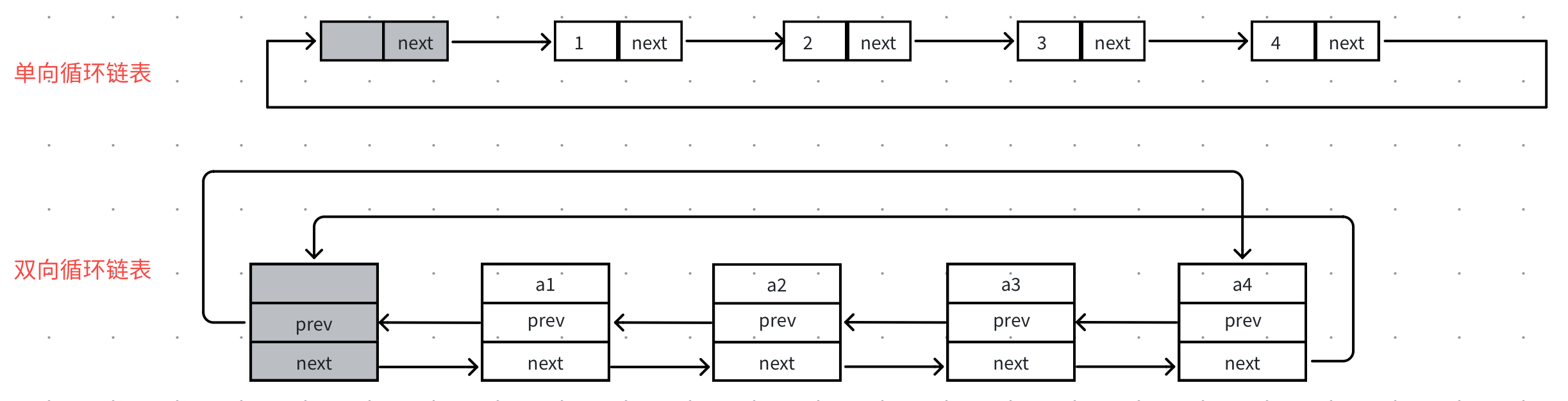
实践中双向循环链表⾮常实⽤,C++标准库(STL)中list就是使⽤的这个结构实现,因为他可以通过头结点的prev指针找到尾结点,轻松实现尾插尾删。也就是说这个结构头尾插⼊删除效率都是 O ( 1 ) O(1) O(1) ,确定某个结点位置以后得插⼊删除也是 O ( 1 ) O(1) O(1) 。
3.4单链表和循环单链表的比较
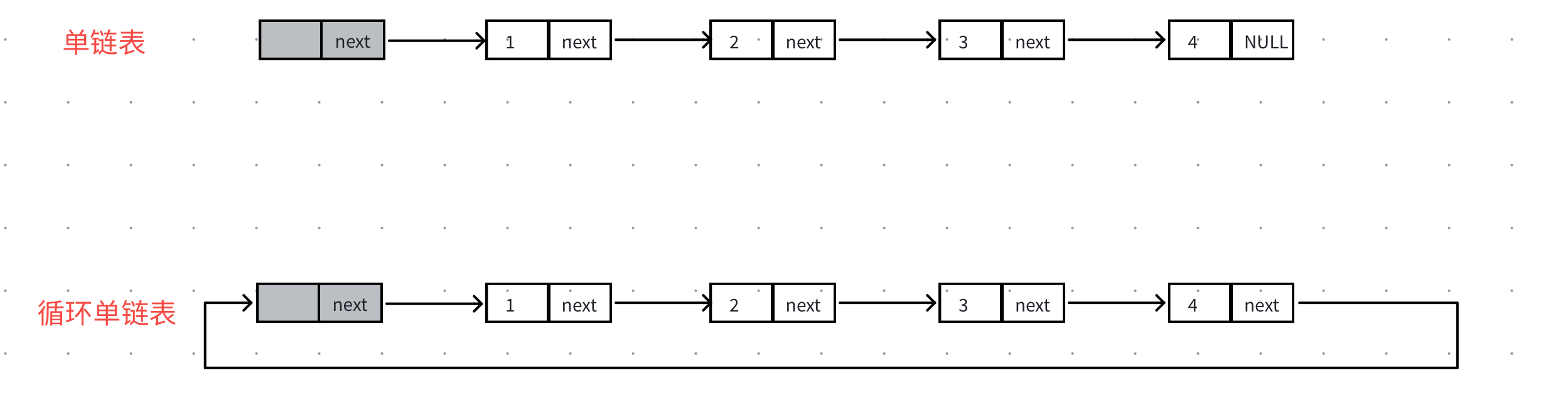
循环单链表和单链表在结构体定义和操作中有些不一样的地方
- 初始化不同,循环单链表初始化时要让头结点的next指向⾃⼰。
c
//单链表
void ListInit(struct ListNode* L)
{
L = BuyListNode(-1);
L->next = NULL;
}
//循环单链表
void ListCInit(struct CListNode* L)
{
L = BuyListNode(-1);
assert(L);
L->next = L;
}- 遍历时判断结束的逻辑不同,循环单链表遍历不能让迭代指针指向空作为结束条件,⽽是⾛⼀圈等于头结点时结束。
c
//单链表
int ListSize(struct ListNode* L)
{
int size = 0;
struct ListNode* cur = L->next;
while(cur!=NULL)
{
cur = cur->next;
size++;
}
return size;
}
//循环单链表
int CListSize(struct CListNode* L)
{
int size = 0;
struct CListNode* cur = L->next;
while(cur!=L)
{
cur = cur->next;
size++;
}
return size;
}3.5双向链表和双向循环链表比较
带头双向循环链表相比于双向链表的优势主要体现在两⽅⾯
第⼀:可以通过头结点的prev快速找到尾结点,⾼效实现尾插尾删;
第⼆:pos结点位置插⼊删除时可以更简单,因为不需要考虑尾结点的的后继结点为空的情况。
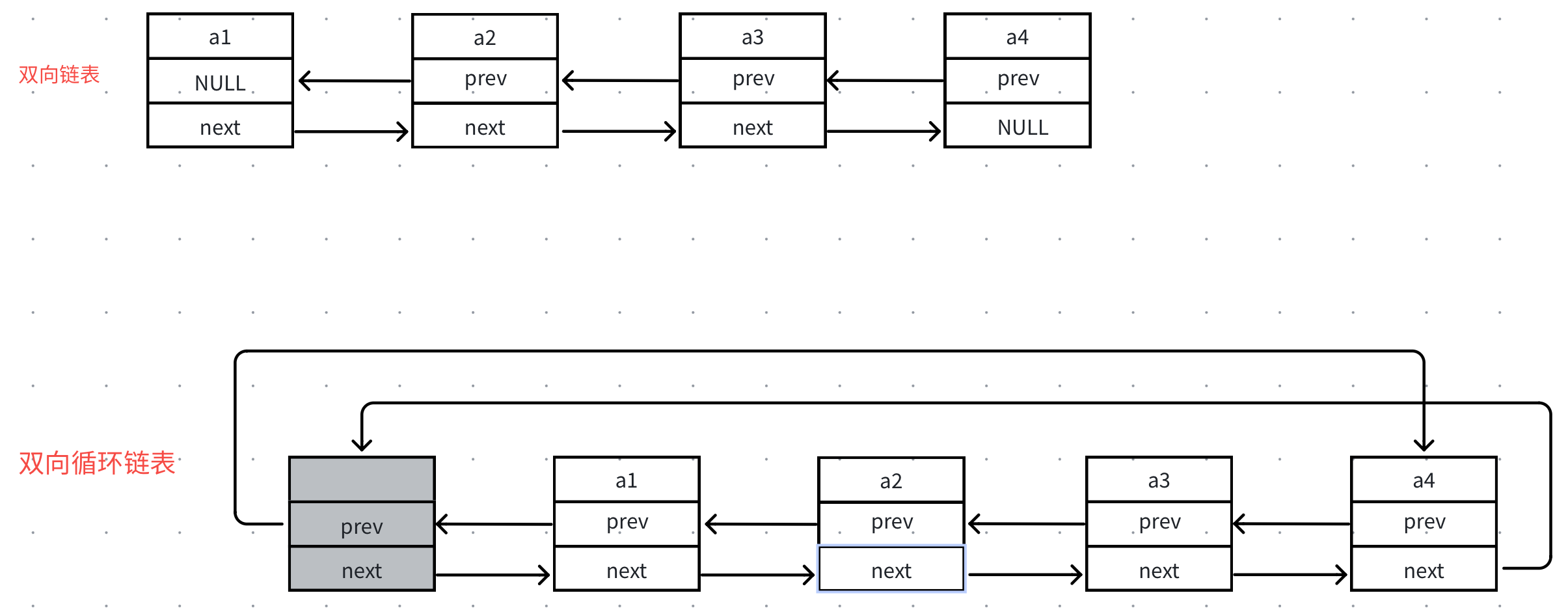
4、带头双向循环链表的实现
4.1接口函数定义
c
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int DCListDataType;
typedef struct DCListNode
{
DCListDataType data;
struct DCListNode* prev;
struct DCListNode* next;
}DCListNode;
//链表的头结点初始化
DCListNode* DCListInit();
//销毁链表
void DCListDestroy(DCListNode* L);
//打印链表
void DCListPrint(DCListNode* L);
//获取链表中下标为i的结点
DCListNode* DCListGetElem(DCListNode*L,int i);
//在结点pos后插入一个元素为x的结点
void DCListInsert(DCListNode*pos,DCListDataType x);
//删除pos结点
void DCListDelete(DCListNode*pos);4.2初始化/销毁/打印/查找
c
#include "DCList.h"
//创建新结点
DCListNode* BuyDCListNode(DCListDataType data)
{
DCListNode* L = (DCListNode*)malloc(sizeof(DCListNode));
if(L==NULL)
{
perror("BuyDCListNode");
return NULL;
}
// 初始化时要让⾃⼰指向⾃⼰,否则就会出问题
L->data = data;
L->next = L;
L->prev = L;
return L;
}
//链表头结点初始化
DCListNode* DCListInit()
{
DCListNode* L = BuyDCListNode(-1);
assert(L);
return L;
}
//销毁
void DestoryDCList(DCListNode* L)
{
assert(L);
//先销毁有效结点
DCListNode* cur = L->next;
while(cur!=L)
{
L->next = cur->next;
free(cur);
cur = L->next;
}
//再销毁头结点
free(L);
}
//打印链表
void DCListPrint(DCListNode* L)
{
assert(L);
DCListNode* cur = L->next;
while(cur!=L)
{
printf("%d->",cur->data);
cur = cur->next;
}
printf("\n");
// //从后往前打印
// cur = L->prev;
// while(cur!=L)
// {
// printf("%d->",cur->data);
// cur = cur->prev;
// }
// printf("\n");
}
//获取链表中下标为i的结点
DCListNode* DCListGetElem(DCListNode*L,int i)
{
assert(L);
int j = 0;
DCListNode* cur = L->next;
while(cur->next!=L&&j<i)
{
cur = cur->next;
j++;
}
//如果循环结束后j不等于i,说明i不合法
assert(j==i);
return cur;
}4.3插入
在pos结点之后插⼊⼀个新结点newNode。
pos可以指向的任意结点(包括头结点),不需要考虑pos前⼀个或者后⼀个为空的情况。
如果是双向链表(⾮循环),要注意的是pos为尾结点时,需要考虑pos->next为空的情况。
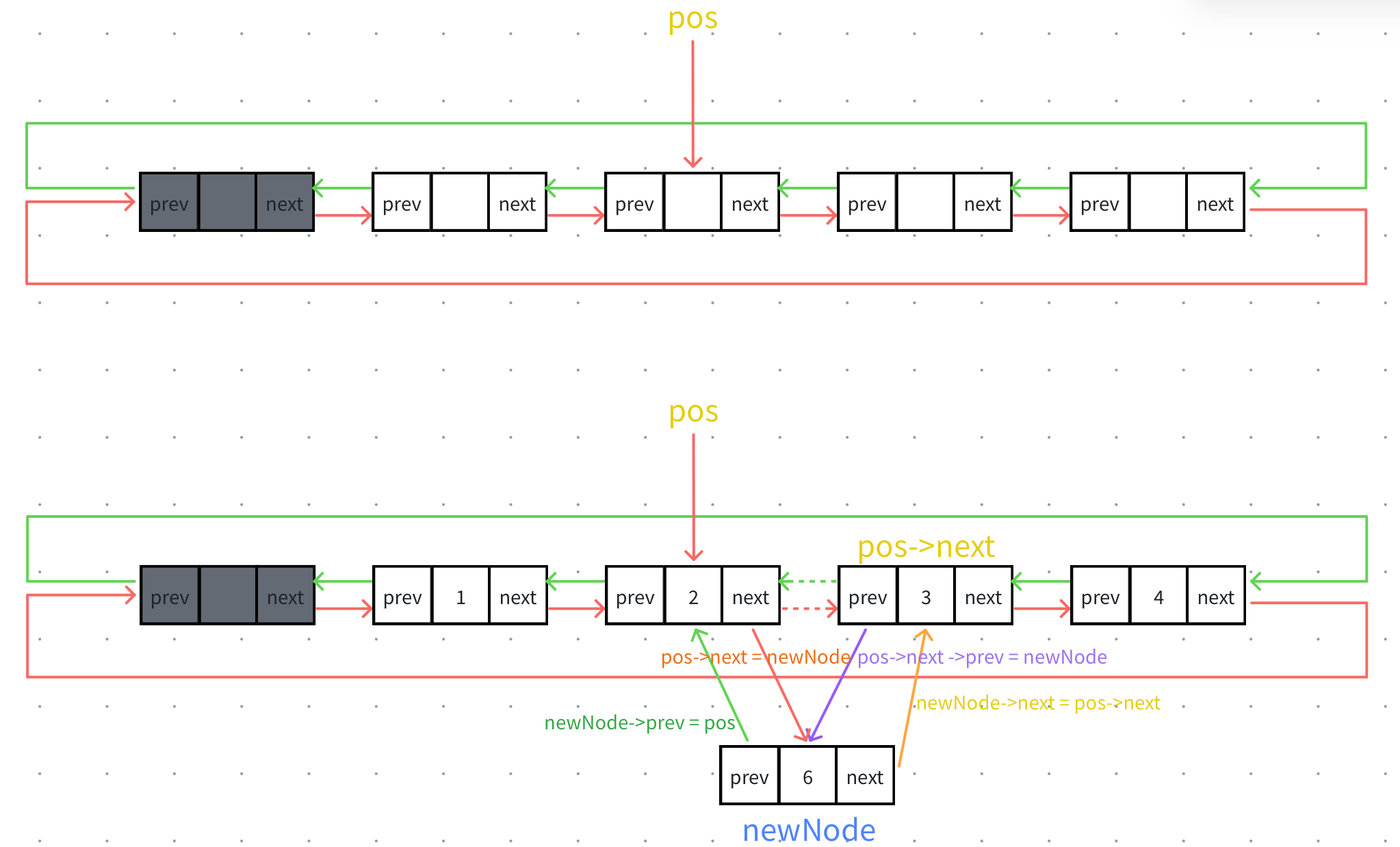
注意: 在修改结点间的链接关系的时候,要先修改newNode ->next = pos和pos->next->prev = newNode,再修改newNode->prev = pos和pos->next = newNode。因为需要通过pos->next记录原链表的pos后面的结点。
代码演示
c
void DCListInsert(DCListNode*pos,DCListDataType x)
{
assert(pos);
//创建一个新结点
DCListNode*newNode = BuyDCListNode(x);
//改变链接关系
newNode->next = pos->next;
pos->next->prev = newNode;
pos->next = newNode;
newNode->prev = pos;
}4.4删除
改动两个指针链接关系即可。
pos可以指向除了头结点以外的任意结点,不需要考虑pos前⼀个或者后⼀个为空的情况。如果是双向链表(⾮循环),要注意的是pos为尾结点时,需要考虑pos->next为空的情况。
代码演示
c
void DCListDelete(DCListNode*pos)
{
assert(pos);
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(pos);
}4.5头尾插入删除
对于头插尾插和头删尾删可以直接复用上面的插入和删除函数。