1、Deepspeed概述
(1)解决什么问题
-显存不足(模型/优化器/激活值太大)
-算力不够(单卡训练太慢)
-通信瓶颈(GPU间同步开销大)
-工程复杂(分布式代码难写)
(2)Deepspeed是什么?
它是微软开源的大模型训练优化库,核心目标是:让大模型训练更快、更省显存、更易用。
(3)最核心技术:ZeRO(零冗余优化器)
-
通过分片去除显存冗余,三级递进:
-
ZeRO-1:分片优化器状态 → 显存降 4倍
-
ZeRO-2:分片优化器+梯度 → 显存降 8倍
-
ZeRO-3 :分片优化器+梯度+参数 → 显存降 N倍(随GPU数量线性增长)
-
-
ZeRO-Infinity (2022):打通CPU和NVMe内存,支持万亿参数训练。
(4)并行策略:3D并行
无缝集成 数据并行+模型并行+流水线并行,极致扩展集群算力。
(5)其他关键特性
-混合精度训练(FP16/BF16)
-梯度检查点(用计算换显存)
-极简接入:Pytorch代码仅需修改几行即可启用
(6)总结
DeepSpeed=ZeRO内存优化 + 3D并行 + 开箱即用,是大模型训练的加速器和显存放大镜。
2、ZeRO原理
ZeRO = Zero Redundancy Optimizer。
它通过智能分区模型状态 而非 模型计算图,在保持计算效率和通信量的同时,线性减少每个设备的内存占用,使训练超大模型成为可能。
并行策略演进路线:
数据并行(内存冗余高) -> 模型并行(通信开销大) -> ZeRO(零冗余、高效)
(1)数据并行的局限
数据并行:每个GPU持有完整的模型副本,处理不同的数据批次。
优点:实现简单,扩展性好,通信模式规整(All-Reduce)
缺点:
-内存冗余:每个设备有完整的模型参数、梯度和优化器状态
-单卡内存瓶颈:当模型规模超过单卡内存时无法训练
-优化器状态(如Adam的动量、方差)占用大量内存(约为参数的2~3倍)
(2)模型并行的局限
模型并行:将模型层或算子拆分到不同设备上
优点:允许训练超过单卡内存的模型
缺点:
-计算粒度细:引入大量设备间通信(P2P)
-设备利用率低:通信等待导致计算流水线气泡
-编程复杂:需要手动划分模型,通用性差
(3)ZeRO的三个阶段详解
1)基线数据并行的标准做法
假设有4个同学(4张GPU ),每人手里有一整完整的教材(模型参数 )和一本厚厚的错题本(优化器状态,记录着动量和方差)。
-做题(前向/反向 ):每个人独立用教材算题,算出每道题的修改意见(梯度)
-对答案(All-Reduce ):4个人碰头,把各自的修改意见加起来求平均,得出一个公认的最佳修改意见。此时每个人都得到了完整的平均修改意见。
-改错题本(优化器步骤):每个人根据完整的平均意见,把自己手里那本完整的错题本全部翻一遍,更新所有记录。
2)ZeRO Stage1的做法-每人只保管一页笔记
设定:4个同学,每人有完整的教材(模型参数),但错题本(优化器状态)被撕成4份,各管一页。
第一步:独立做题(前向/反向传播)
每个人用自己手里的完整教材(参数),独立算出每道题的修改意见(梯度)。此时每个人手里都有一份完整的、针对所有参数的修改意见。
第二步:部分对答案(Reduce-Scatter,而不是 All-Reduce)
4个人碰头,但不是 为了交换所有修改意见,而是只汇总自己负责的那部分:
-
A 只收集大家对第1页的修改意见,把它们加起来求平均,得到"第1页的平均意见"。
-
B 只收集大家对第2页的意见,得到"第2页的平均意见"。
-
C、D 同理。
此时,每个人手里只有自己那一页的平均意见 ,而不是完整的平均意见。这一步的通信量是 G(即总梯度大小)。
第三步:各自改错题和教材(优化器步骤)
因为 A 手里只有"第1页的平均意见",所以它只能更新自己保管的第1页错题本,并顺手修改教材里的第1页参数。B 只改第2页,C 改第3页,D 改第4页。
第四步:交换新教材(All-Gather 参数)
改完后,A 把新的第1页教材内容复印给 B、C、D,B 把新的第2页复印给 A、C、D......大家互相交换。这一步完成后,每个人手里又凑齐了一本完整的、更新后的新教材 。这一步的通信量也是 G(参数总大小)。
通信量对比:
-
标准数据并行 :通过一次
All-Reduce,通信量为 2G(G 用于汇总,G 用于分发)。 -
ZeRO Stage 1 :通过
Reduce-Scatter(G)+All-Gather参数(G),通信量总和为 2G。
3)ZeRO Stage2的做法-连"算题时的草稿"都只算自己那一页
在 Stage 1 中,虽然每个人只负责更新自己那一页错题本,但为了计算出那一页的修改意见,反向传播时每个人依然必须把整本书 4 页的修改意见(即完整梯度)全部算出来 。算完之后,每个人只挑走自己需要的那 1 页用于更新错题本,而其余 3 页的梯度数据在显存中继续占着空间,直到所有页的错题本更新完毕才会被释放。
前向传播(不变):每人用完整教材 + 各自 1/4 数据,算出损失。
第二步:反向传播(算修改意见):
-
反向传播时,每个人必须把 4 页梯度全部算出来(链式法则决定了无法只算 1 页),这与 Stage 1 的计算量完全相同。
-
但与 Stage 1 不同的是:每算出一层的梯度 ,就立即通过 Reduce-Scatter 进行汇总平均,然后只保留自己负责的那 1 页平均梯度 ,其余 3 页立刻从显存中清空。整个过程是边算边丢,而不是等全部算完再统一处理。
优化器步骤(不变):每人用保留的那 1 页梯度,更新自己那 1 页错题本和教材参数。
同步新教材(不变):All-Gather 交换新教材,凑齐完整版。
4)ZeRO Stage3的做法-参数分区(连教材都撕开)
核心变化 :Stage 1 撕了错题本,Stage 2 撕了草稿纸,Stage 3 连教材(模型参数)都撕成 4 份。每个人手里只有自己负责的那 1/4 页教材,不再拥有完整教材。
第1步,前向传播(边借边算边还)
-
算哪层,就通过 All-Gather 临时借齐该层所需的 4 页参数
-
该层计算完成后,立即释放借来的 3 页,只保留自己的 1 页
-
逐层进行:算一层,借一层,还一层
第2步,反向传播(同理)
-
同样通过 All-Gather 临时借齐完整参数计算梯度
-
算完该层梯度后立即释放借来的参数
-
梯度汇总:每层算完立即 Reduce-Scatter,只保留自己那 1 页平均梯度,其余清空(同 Stage 2)
第3步,优化器步骤(不变)
- 用保留的 1 页梯度,更新自己的 1 页错题本和 1 页教材参数
同步新教材(不需要了)
-
Stage 1/2 最后需要 All-Gather 凑齐完整教材
-
Stage 3 每人本来就只有 1/4 页,无需凑齐,下次用的时候临时借最新版本即可
5)三个阶段对比
| Stage 1 | Stage 2 | Stage 3 | |
|---|---|---|---|
| 显存里有 | 完整教材 + 完整梯度 + 1/4错题本 | 完整教材 + 1/4梯度 + 1/4错题本 | 1/4教材 + 1/4梯度 + 1/4错题本 |
| 省了什么 | 错题本 | 错题本 + 梯度 | 错题本 + 梯度 + 教材 |
| 通信量 | 2G | 2G | 约 3G(前向All-Gather参数 + 反向All-Gather参数 + Reduce-Scatter梯度) |
| 代价 | 无额外通信 | 无额外通信 | 用通信换内存 |
3、ZeRO-Offload原理
(1)概述
ZeRO-Offload把重型计算(前向/反向)留在GPU,把轻量但占内存的优化器更新和状态 卸载到CPU。利用step耗时短(5%)且计算轻量,通过异步拷贝和流水线重叠隐藏通信开销,用PCIe带宽换GPU显存,单卡可训练数倍的模型。
(2)训练循环的三部分组成
1)前向传播:模型输入数据,逐层计算得到损失。这是重型矩阵计算,耗时最长,占总时间约70%。
2)反向传播:loss.backward(),从损失反向求导,算出每个参数的梯度。同样是重型计算,耗时约25%。
3)优化器步骤:optimizer.step(),读取梯度,结合优化器状态(如Adam的动量/方差),更新参数值。这是轻量级计算,耗时仅5%,但内存占用极大(FP32状态是FP16参数的两倍)。
(3)ZeRO-Offload的穿插优化
1)前向和反向(GPU全权负责):FP16模型参数留在GPU显存,矩阵计算照常进行,速度不受影响。CPU处于待命状态。
2)反向结束瞬间异步拷出:反向刚算完梯度的那一刻,立即启动异步拷贝,将FP16梯度从GPU复制到CPU内存。这个拷贝与反向收尾计算重叠,几乎不增加耗时。
3)优化器步骤(挪到CPU执行):GPU不等CPU,直接开始下一轮前向传播(流水线)。CPU在后台做3件事:
1.读取刚收到的FP16梯度,转化为FP32
2.读取本地内存中的FP32优化器状体(动量/方差)
3.计算新参数(FP32),转成FP16后异步拷回GPU
关键流水线:GPU算下一轮前向(几百毫秒)时,CPU同步处理下一轮的优化器更新(几毫秒+拷贝几毫秒)。CPU的活干完了,GPU前向还没算完,通信开销被完全隐藏。
(4)数据最终分布
-模型参数(FP16):全程参与前向/反向(95%时间),高频访问 -> 留在GPU
-梯度(FP16):反向末尾生成,算完立即搬走 -> 搬去CPU内存
-优化器状态(FP32):只在step(5%时间)使用,且占用最大 -> 始终驻留CPU内存
(5)优化器状态使用FP32的原因
optimizer.step()本质是在执行公式:新参数 = 旧参数 - 学习率 * 梯度。
这个过程涉及微小的加减累加 和梯度的平方计算(Adam方差),对精度极其敏感。因此,执行这一步时:
-
旧参数、梯度、新参数 都必须转为 FP32 运算,否则极小的增量(如
1e-6)会在 FP16 下被舍入为 0,模型无法收敛。 -
优化器自带的 动量与方差 (Adam状态)同样涉及累加和平方,为防止下溢,也必须保持 FP32。
(6)deepspeed配置示例

4、ZeRO-Infinity原理
(1)核心思想
在ZeRO-3(参数分片)的基础上,将不活跃的参数、梯度和优化器状态进一步卸载到NVMe固态硬盘,构建 GPU显存 -> CPU内存 -> NVMe硬盘 三级存储体系,用低速存储换超大容量,实现万亿参数模型训练。
(2)分层存储与数据流架构
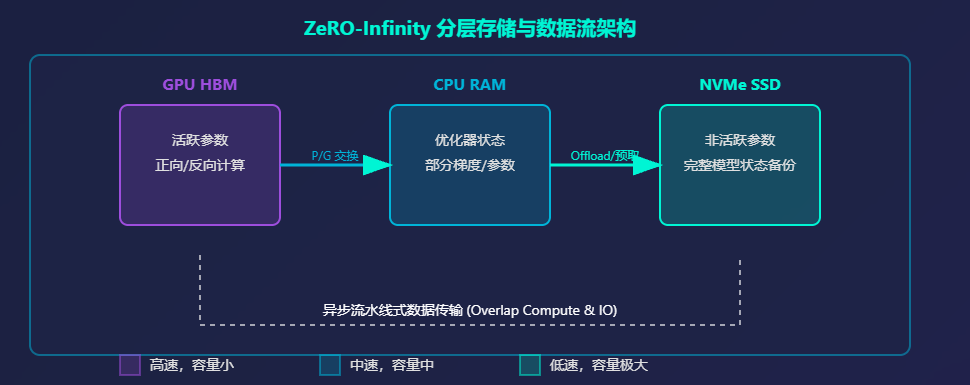
(3)三级存储分工
| 存储层级 | 速度 | 容量 | 存放内容 |
|---|---|---|---|
| GPU HBM | 最快(TB/s级) | 最小(几十GB) | 当前正在计算的活跃参数 |
| CPU 内存 | 中等(GB/s级) | 中等(几百GB) | 优化器状态、部分梯度/参数(高速缓存) |
| NVMe SSD | 最慢(GB/s级) | 极大(TB级) | 非活跃参数、完整模型状态备份 |
(4)关键技术
1)智能预取:根据计算图依赖,提前将下一层需要的参数从NVMe -> CPU -> GPU异步加载,与GPU计算重叠,隐藏IO延迟
2)异步IO(AIO):使用原生异步读写操作,大幅提升NVMe吞吐效率
(5)核心权衡
-收益:理论上可训练无限大的模型(受限于NVMe总容量),突破单卡/多卡显存墙。
-代价:引入PCIe和NVMe的IO开销,训练速度比纯显存方案慢,是典型的用时间/IO换空间。
(6)核心配置参数
1)优化器Offload(offload_optimizer)
| 参数 | 值 | 作用 |
|---|---|---|
device |
"nvme" |
将优化器状态(Adam动量/方差)卸载到NVMe硬盘(也可设cpu或none) |
nvme_path |
"/local_nvme" |
NVMe挂载路径,存放卸载数据 |
buffer_count |
4 |
并行I/O缓冲块数量,越大吞吐越高,但占CPU内存 |
fast_init |
false |
是否快速初始化(大数据集建议false保稳定) |
2)参数Offload(offload_param)
| 参数 | 值 | 作用 |
|---|---|---|
device |
"nvme" |
将非活跃模型参数卸载到NVMe |
buffer_count |
5 |
I/O缓冲块数量 |
buffer_size |
1e8 |
每个缓冲块大小(字节),约100MB,影响单次I/O吞吐 |
max_in_cpu |
1e9 |
CPU内存中最多缓存1GB参数(热点缓存) |
3)ZeRO-3运行调优(stage3_*)
| 参数 | 值 | 作用 |
|---|---|---|
stage3_max_live_parameters |
1e9 |
GPU上同时驻留的最大参数数量(≈1GB),限制显存峰值 |
stage3_max_reuse_distance |
1e9 |
参数重用距离阈值,超过则释放并存入NVMe,避免重复预取 |
stage3_prefetch_bucket_size |
5e8 |
单次预取参数总量(≈500MB),越大吞吐越高,但占显存 |
stage3_param_persistence_threshold |
1e6 |
小于该值的参数不卸载,常驻GPU(小参数卸载开销大于收益) |
4)通用调优
| 参数 | 值 | 作用 |
|---|---|---|
contiguous_gradients |
true |
梯度在内存中连续存储,减少碎片,提升带宽 |
overlap_comm |
true |
通信(传输)与GPU计算重叠,隐藏延迟 |
5)异步IO调优(aio)
| 参数 | 值 | 作用 |
|---|---|---|
block_size |
1048576(1MB) |
单次I/O读写块大小,影响NVMe吞吐(通常1-4MB最佳) |
queue_depth |
8 |
I/O请求队列深度,越大并发越高 |
thread_count |
1 |
执行异步I/O的线程数 |
single_submit |
false |
false=批量提交I/O请求,减少系统调用开销 |
overlap_events |
true |
I/O事件与计算重叠 |
5、混合精度训练
(1)概述
混合精度=FP16/BF16算(前向/反向,省显存、加速) + FP32存(主权重、优化器状态,保精度)。用低精度跑矩阵乘法,用高精度做参数更新。
(2)三种精度格式对比
| FP32 | FP16 | BF16 | |
|---|---|---|---|
| 指数位 | 8 | 5(窄) | 8(同FP32) |
| 尾数位 | 23 | 10 | 7(精度稍低) |
| 数值范围 | 宽 | 窄(±65504) | 宽(同FP32) |
-FP16:范围窄,易上溢/下溢,需要Loss Scaling
-BP16:范围同FP32,无溢出风险,不需要Loss Scaling
(3)训练流程
1.存:优化器维护一份FP32主权重
2.算:主权重 -> 转成FP16/BF16 -> 做前向,得损失
3.放大(仅FP16):损失 * 缩放因子S -> 反向时梯度被同步放大,避免下溢
4.反传:用半精度算梯度
5.还原并更新:梯度 / S -> 转回FP32 -> 更新主权重
(4)Loss Scaling
为什么?
FP16最小有效值约6e⁻⁸,小梯度在反向传播中直接变0,模型"学不动"
怎么做?
-
损失乘S(如65536)→ 梯度整体放大 → 进入FP16安全区间
-
更新前除以S还原真实梯度
动态策略:
-
溢出(出现Inf/NaN)→ 跳过本次更新,S减半
-
连续N轮无溢出 → S增大
日志里能看到 loss_scale 值在不断变化------它在动态寻找"不溢出"和"充分利用范围"之间的平衡点。
(5)什么时候用FP16,什么时候用BF16
-
Ampere架构及以上(A100/H100) → BF16(稳,不用调Loss Scale)
-
老卡(V100/Turing) → FP16 + 动态Loss Scaling
FP16和BP16不能同时使用,只能二选一。
6、梯度累积
(1)概述
多个小批次梯度累加后统一更新参数,用时间换显存,模拟更大的批量大小。
(2)工作流程
1.前向+反向算出每个微批次的梯度
2.梯度累加器汇总,不立即更新参数
3.累积满N步后,执行一次optimizer.step(),清零梯度
(3)关键收益
1)降低激活值峰值显存
有效批量=微批次大小*累积步数。峰值显存由微批次大小决定,而非有效批量。
累积步数允许你把大批量拆成小份依次运算,反向传播后每份激活值立即释放,显存峰值被压到最低。
2)有效批量更大 -> 梯度估计更稳定,收敛更平滑
累积N步等效于N个独立梯度的平均,方差缩小为原来的1/N,更新方向更准。
3)通信开销显著降低
通信(All-Reduce)发生在反向传播之后、参数更新之前。累积N步后梯度同步次数从N次降为1次,总通信量从N*G降为G,同时启动延迟也减少N倍。
7、激活检查点
(1)概述
一种用计算换显存 的技术:丢弃大部分层的激活值,反向传播时临时重算,大幅降低显存峰值。核心逻辑是**"用完即焚"**:前向省下的显存,留到反向时花少量计算去"补救"
(2)核心机制
-
存(前向) :仅保存部分层的输出激活(称为"检查点"),其余层的激活值不保存,直接丢弃。
-
算(反向) :反向传播到被丢弃的层时,从最近的检查点出发重新做一次前向传播,算出该层所需的输入激活值。
-
弃(用完) :激活值算出后立刻用来求梯度,梯度算完,激活值当场释放,绝不滞留。
8、Fused Adam优化器
(1)概述
将Adam优化器的多个计算内核融合为单个CUDA内核,通过减少内核启动和全局内存访问来加速参数更新。
(2)为什么需要 Fused Adam
标准 Adam 在 step() 中依次执行:梯度加载 → 一阶矩更新 → 二阶矩更新 → 偏差校正 → 参数更新。每个操作独立启动一个 CUDA 内核,导致:
-
多次内核启动开销:每次启动有固定微秒级延迟
-
冗余全局内存读写:每个内核都要从显存读/写数据,带宽被浪费
-
内核间同步等待:前一个内核完成,下一个才能开始
(3)关键收益
-
减少内核启动延迟:多次变一次
-
提升内存局部性:数据在寄存器中复用,全局内存访问大幅减少
-
消除中间同步:一气呵成,无等待
-
无缝支持混合精度:内部自动处理 FP16/FP32 转换
9、LAMB优化器
(1)概述
LAMB是一种支持超大批量训练的自适应优化器,核心贡献是引入 逐层信任比率,使大批量训练不损失精度。
(2)核心问题
标准Adam在大批量下精度下降,原因是梯度方差虽小,但更新步长失控,导致收敛变慢。
(3)核心机制
在Adam基础上增加逐层归一化,每层有自己的自适应学习率缩放系数,而非全局统一。
10、Pipeline并行
(1)概述
对模型按层(深度方向)切分到多个GPU,每个GPU负责若干连续层,用通信换显存。
(2)与张量并行的区别
1)Pipeline并行(层间切分):按深度切层,相邻GPU点对点传输,通信频率低(等于切分段数),总通信量远小于张量并行。
2)张量并行(层内切分):按宽度切权重矩阵,所有GPU全局All-Reduce频繁同步,通信频率高(等于总层数*每层多次)。
(3)两种调度策略
1)GPipe:所有微批次先全部前向、再全部反向。实现简单但激活峰值高。
2)1F1B:每个设备前向依次后立即反向,交替执行。激活峰值降低约50%,GPU利用率更高。
11、张量切片并行
(1)概述
其核心思想是将矩阵乘法运算 中的权重矩阵W按行或列进行分割,每个设备仅持有并计算一部分权重,通过同步通信(All-Reduce或All-Gather)来组合出完整的输出结果。
DeepSpeed通过 DeepSpeed-Megatron 集成,无缝引入了Megatron-LM的Tensor并行实现。Megatron-LM是NVIDIA提出的高效模型并行方案,其核心是对Transformer层中的关键线性层(MLP、Attention)进行切分。
(2)前向传播通信示例说明
假设,
如果W是按列切分成2列,则:
,
GPU0计算得到90, 100即左半部分,GPU1计算
得到110, 120即右半部分。
结果拼装All-Gather后得到完整的90, 100, 110, 120
如果W是按行切分成2行,即:
,
输入的X按列切分成两部分:X1=1,2, X2=3,4
GPU0计算得到11,14,17,20,GPU1计算
得到79,86,93,100
上面得到的都是结果矩阵的一部分值,最后结果需要两者通过All-Reduce进行结果相加,11+79, 14+86, 17+93, 20+100 = 90, 100, 110, 120。
12、3D并行策略
(1)概述
3D并行,通过数据并行(Data Parallelism,DP)、张量并行(Tensor Parallelism,TP)和流水线并行(Pipeline Parallelism,PP)的有机结合,实现对超大规模模型的高效训练。
(2)数据并行
1)原理
复制完整的模型到多个设备,每个设备处理不同的数据批次
2)通信
前向传播后同步梯度(All-Reduce)
3)优点
实现简单,扩展性好
4)缺点
每个设备需要存储完整模型,内存受限
5)适用场景
模型参数可放入单卡内存时
(3)张量并行
1)原理
将模型的单个层(如MLP、Attention)的矩阵运算在多个设备间横向拆分
2)通信
层内前向/反向传播需要All-Reduce或All-Gather
3)优点
减少单卡内存负载,支持更大单层
4)缺点
通信频繁,设备间依赖强
5)适用场景
模型有非常大的层(如Transformer的FFN层)
(4)流水线并行
1)原理
将模型按层纵向切分到多个设备,形成流水线
2)通信
设备间传递激活值和梯度(点对点通信)
3)优点
显著减少单卡内存,支持极深模型
4)缺点
存在流水线气泡,设备利用率可能下降
5)适用场景
模型层数非常多
(5)3D并行的组合方式
1.外层为数据并行(DP):将整个训练集群划分为多个DP组,每个组包含完整的模型副本。
2.中层为流水线并行(PP):在每个DP组内,将模型按层切分为多个阶段(Stage),分配到不同设备上
3.内层为张量并行(TP):在每个流水线阶段(PP Stage)内部,将单个层的计算进一步拆分到多个设备上。
13、通信优化
(1)梯度同步优化(AllReduce)
1.梯度压缩:用1-bit Adam这类技术,原本32位的梯度只传正负符号,剩下超多传输流量;本地存误差补上丢失的数值,保证训练不崩。Adam要先完整传几轮预热,之后固定方差,只压缩动量。
2.梯度打包:零散小梯度合并成大包再传输,传输更快
(2)参数同步优化(AllGather)
1.参数拆分分批调取,减少瞬间占用内存
2.优先同步马上要用的参数,把等待通信的时间隐藏起来
3.重复使用传输缓存,减少内存浪费
(3)计算通信同步进行
模型前向计算、反向求梯度、更新参数这三个阶段,一边算一边传数据,掩盖通信等待时间,显卡利用率更高。
(4)多种通信工具按需选用
单机多卡默认NCCL速度最快;
大规模集群用MPI
简易异构环境用Gloo
14、DeepSpeed使用流程
1)关键接口
deepspeed.initialize:将模型、优化器、训练参数等封装为DeepSpeed引擎
DeepSpeedEngine:封装了前向传播、反向传播、梯度更新以及分布式通信。
2)示例
python
import deepspeed
# 模型与优化器定义
model = MyLargeModel()
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
# DeepSpeed初始化
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
optimizer=optimizer,
model_parameters=model.parameters(),
config="ds_config.json" # DeepSpeed配置文件
)
# 之后使用model_engine进行训练
for epoch in range(num_epochs):
for batch_idx, batch in enumerate(train_loader):
# 将数据移至设备
inputs, labels = batch
inputs = inputs.to(model_engine.local_rank)
labels = labels.to(model_engine.local_rank)
# 前向传播
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
# 反向传播与梯度累积
model_engine.backward(loss)
# 梯度裁剪(可选)
model_engine.clip_grad_norm(max_norm=1.0)
# 达到累积步数时更新参数
if (batch_idx + 1) % gradient_accumulation_steps == 0:
model_engine.step()
model_engine.zero_grad()
# 日志记录
if batch_idx % log_interval == 0:
print(f"Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}")
# 每个epoch保存检查点
model_engine.save_checkpoint(save_dir=f"./checkpoints/epoch{epoch}")
def evaluate(model_engine, eval_loader):
model_engine.eval() # 设置为评估模式
total_correct = 0
total_samples = 0
with torch.no_grad(): # 禁用梯度计算
for batch in eval_loader:
inputs, labels = batch
inputs = inputs.to(model_engine.local_rank)
labels = labels.to(model_engine.local_rank)
# 前向推理
outputs = model_engine(inputs)
predictions = outputs.argmax(dim=-1)
# 统计准确率
total_correct += (predictions == labels).sum().item()
total_samples += labels.size(0)
accuracy = total_correct / total_samples
model_engine.train() # 恢复训练模式
return accuracy15、DeepSpeed配置文件核心参数
(1)训练基础配置
| 参数 | 含义 | 说明 |
|---|---|---|
train_batch_size |
全局有效批量大小 | 所有GPU上累计的等效批量,是最终参与更新的样本数 |
train_micro_batch_size_per_gpu |
每张卡每次前向的样本数 | 单次送入GPU的样本数,受显存限制 |
gradient_accumulation_steps |
梯度累积步数 | 微批次累积多少次才更新参数,三者关系:train_batch_size = micro_batch × GPU数 × 累积步数 |
(2)优化器配置
python
"optimizer": {
"type": "AdamW", // 优化器类型:Adam、AdamW、OneBitAdam、LAMB 等
"params": {
"lr": 3e-5, // 学习率
"betas": [0.9, 0.999], // Adam 的动量衰减系数
"eps": 1e-8, // 数值稳定项,防除零
"weight_decay": 0.01 // 权重衰减(L2正则化强度)
}
}(3)学习率调度器配置
python
"scheduler": {
"type": "WarmupLR", // 调度器类型:WarmupLR、CosineAnnealingLR 等
"params": {
"warmup_min_lr": 0, // 预热起始学习率(通常为0)
"warmup_max_lr": 3e-5, // 预热目标学习率(峰值)
"warmup_num_steps": 1000, // 预热步数
"total_num_steps": 10000 // 总训练步数(Cosine等调度需要)
}
}(4)ZeRO阶段选择
| 阶段 | 分片内容 | 内存节省 | 通信量 | 适用场景 |
|---|---|---|---|---|
| ZeRO-1 | 优化器状态(动量+方差) | ~4倍 | 低 | 10~30B 参数 |
| ZeRO-2 | 优化器状态 + 梯度 | ~8倍 | 中等 | 30~100B 参数 |
| ZeRO-3 | 优化器状态 + 梯度 + 模型参数 | ~N倍(N=GPU数) | 高 | 100B+ 参数 |
(5)ZeRO配置参数
python
"zero_optimization": {
"stage": 3, // 0/1/2/3
"offload_optimizer": { // 优化器状态卸载
"device": "cpu", // "cpu" 或 "nvme"
"pin_memory": true // 锁页内存加速传输
},
"offload_param": { // 参数卸载(仅stage 3)
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true, // 通信与计算重叠
"contiguous_gradients": true, // 梯度连续存储,减少碎片
"reduce_bucket_size": 5e8, // AllReduce分桶大小(字节)
"stage3_prefetch_bucket_size": 5e8, // 预取桶大小(stage 3)
"stage3_param_persistence_threshold": 1e6, // 小于此值的参数常驻GPU,不卸载
"sub_group_size": 1e9 // ZeRO-3子分组大小
}(6)并行策略配置
| 参数 | 含义 | 说明 |
|---|---|---|
data_parallel_size |
数据并行度 | 通常等于总GPU数 |
tensor_parallel.tp_size |
张量并行度 | 层内切分,通常2/4/8,限单节点内 |
pipeline_parallel.pp_size |
流水线并行度 | 层间切分,阶段数 |
pipeline_parallel.schedule |
调度策略 | "1f1b" 或 "gpipe",默认1F1B |
(7)精度配置(FP16/BF16)
python
"fp16": {
"enabled": true,
"loss_scale": 0, // 0=动态缩放,>0=静态固定值
"initial_scale_power": 16, // 初始缩放因子 = 2^16 = 65536
"loss_scale_window": 1000, // 动态缩放调整窗口
"hysteresis": 2, // 容错步数
"min_loss_scale": 1 // 最小缩放因子
}
"bf16": {
"enabled": true // BF16配置极简,与fp16二选一
}(8)通信优化配置
| 参数 | 含义 | 说明 |
|---|---|---|
communication_data_type |
梯度通信精度 | "fp16" 半精度通信减流量 |
allreduce_bucket_size |
AllReduce分桶大小 | 越大单次通信效率越高 |
compression_training.enabled |
梯度压缩开关 | 配合 1bit_adam 等使用 |
(9)其他通用配置
| 参数 | 含义 | 说明 |
|---|---|---|
gradient_clipping |
梯度裁剪阈值 | 防止梯度爆炸,如 1.0 |
steps_per_print |
打印间隔 | 每N步输出一次日志 |
wall_clock_breakdown |
耗时分析 | 开启后输出各阶段耗时明细 |
16、模型保存与加载
(1)Checkpoint格式
1)结构
为结构化目录,含模型/优化器状态文件、配置文件、训练超参数等;ZeRO-3下各GPU仅存负责的参数分片,降低存储压力
2)核心组件
model_states(模型参数,必需)
optim_states(优化器状态,恢复训练必需)
random_states(保障可复现)
ds_config(保证加载环境一致)
client_state(自定义状态,仅推荐)
(2)分布式保存与加载
1.保存流程
各Rank分片写入 -> 全局同步 -> Rank 0聚合元数据 -> 原子提交目录
2.加载流程
读取元数据 -> 定位分片 -> 并行加载 -> 重建模型/优化器状态
(3)异构存储支持
1.分层策略
本地NVMe/SSD存高频元数据、并行文件系统存完整分片、对象存储(S3等)长期归档/跨中心迁移
2.优化
支持异步上传/预取Checkpoint,避免I/O阻塞计算。
(4)训练恢复与迁移
- 弹性恢复:可从最新 Checkpoint 恢复,适配动态调整的硬件 / 并行拓扑。
- 跨配置迁移:支持 GPU 数量、ZeRO 阶段、跨架构(GPU→NPU)等变更(部分需工具转换)。
- 生产部署:剥离训练状态、合并 ZeRO 分片、转换为 ONNX 等推理格式。
17、性能分析与调试
(1)核心分析维度
计算效率(FLOPs)、通信开销、内存占用与带宽
(2)Flops Profiler:计算性能分析
DeepSpeed Flops Profiler能够测量模型的前向/后向传递的浮点运算量(FLOPs)、计算时间、各层耗时占比,并估算理论吞吐量上限。
from deepspeed.profiling.flops_profiler import get_model_profile
# 初始化模型
model = MyLargeModel()
# 启动分析
flops, macs, params = get_model_profile(
model=model,
input_shape=(batch_size, seq_len), # 输入张量形状
print_profile=True, # 打印详细报告
detailed=True, # 显示每层详情
module_depth=5, # 显示模块深度
top_modules=3 # 显示最耗时的前3个模块
)-FLOPs:浮点运算次数 :衡量计算密度,与硬件峰值算力对比
-MACs:乘加运算次数:评估AI加速器利用率
-Params:参数量:结合内存分析,优化模型切分
-Time(%):各层耗时百分比:定位计算热点,考虑算子融合
当计算效率(实际 FLOPs / 理论 FLOPs)低于 40% 时,一般代表存在计算瓶颈,常见诱因有:小矩阵运算(运算量不足,访存调度开销挤占算力)、频繁内核启动(每次启动存在固定调度耗时,大量占用运算时间)、数据格式转换(额外增加读写与类型换算开销,中断连续计算)等。
(3)通信分析
在ZeRO等分布式策略中,通信是主要瓶颈之一。DeepSpeed可以分析通信操作:
- All-Reduce:梯度同步(ZeRO-1/2)
- Reduce-Scatter:梯度分区(ZeRO-2/3)
- All-Gather:参数收集(ZeRO-3)
- 点对点通信:流水线并行间通信
启用通信日志:
# 在DeepSpeed配置文件中启用通信分析
{
"train_batch_size": 32,
"zero_optimization": {
"stage": 3,
"contiguous_gradients": true,
"overlap_comm": true
},
"comms_logger": {
"enabled": true,
"verbose": true,
"prof_all": true,
"debug": false
}
}高延迟症状:
-GPU利用率周期性下降
-小规模All-Reduce耗时异常
-不同节点间耗时差异大
带宽不足症状:
-大规模张量通信时间长
-通信时间随模型大小线性增长
-无法通过重叠通信完全隐藏
通信优化策略
| 策略 | 机制 | 适用场景 |
|---|---|---|
| 通信重叠 | 在计算同时进行通信(overlap_comm) | 计算密集型层后的大梯度同步 |
| 梯度累积 | 累积多个小批次后再通信 | 微批次极小,通信频繁 |
| 分层通信 | 对不同层使用不同通信组 | 异构网络或层次化拓扑 |
| 压缩通信 | 梯度/参数压缩(1-bit Adam等) | 带宽严重受限 |
(4)内存组成
大模型训练内存主要消耗在:
-模型参数:FP16/FP32权重
-梯度:反向传播产生的梯度
-优化器状态:如Adam的动量、方差
-激活值:前向传播中间结果(可用于重计算)
-临时缓冲区:通信、计算中间缓存

内存分析工具:
# 通过DeepSpeed内置功能获取内存快照
from deepspeed.runtime.utils import see_memory_usage
# 在训练循环中插入
see_memory_usage("Before forward", force=True)
output = model(input)
see_memory_usage("After forward", force=True)
# 或使用PyTorch原生工具
import torch
print(torch.cuda.memory_summary())(5)系统化调优流程
| 瓶颈类型 | 症状 | 诊断工具 | 调优方案 |
|---|---|---|---|
| 计算瓶颈 | GPU利用率持续>90%,吞吐量低 | Flops Profiler, NSight Compute | 算子融合、混合精度、内核优化 |
| 通信瓶颈 | GPU利用率周期性下降,同步等待 | DeepSpeed通信日志, NCCL调试 | 重叠通信、梯度累积、拓扑优化 |
| 内存瓶颈 | OOM错误,频繁内存交换 | see_memory_usage, PyTorch profiler | 激活检查点、ZeRO阶段提升、卸载 |
| I/O瓶颈 | 数据加载线程等待,GPU空闲 | 系统监控(iostat), 数据加载器统计 | 数据预取、高速存储、格式优化 |
每次只调整一个参数,量化性能变化。
通常通信和内存瓶颈的收益高于纯计算优化。
18、DeepSpeed 自定义模型支持
DeepSpeed 不仅适配 Transformer 架构,还支持 CNN、RNN、GNN、MoE 等非 Transformer 模型,通过参数注册、自定义前后向传播、梯度钩子等机制,让自定义模型也能使用 ZeRO 内存优化、混合精度训练、梯度检查点等高级功能。
示例代码:
python
# 1. 定义自定义模型(以CNN为例)
class CustomCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.scale = nn.Parameter(torch.ones(1)) # 自定义可训练参数
def forward(self, x):
return torch.relu(self.conv1(x)) * self.scale
# 2. DeepSpeed初始化
model = CustomCNN()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
ds_config = {"fp16": {"enabled": True}, "zero_optimization": {"stage": 2}}
model_engine, optimizer, _, _ = deepspeed.initialize(model=model, optimizer=optimizer, config=ds_config)
# 3. 训练循环
for inputs, targets in data_loader:
outputs = model_engine(inputs.to(model_engine.device))
loss = F.cross_entropy(outputs, targets.to(model_engine.device))
model_engine.backward(loss) # 自定义后向
model_engine.step() # 参数更新19、Inference推理方案
(1)模型压缩方案
1.量化
INT8:精度损失低
INT4:带宽敏感场景
支持PTQ训练后量化,QAT量化感知训练
2.辅助压缩
知识蒸馏、结构化剪枝、搭配ZeRO-Infinity支撑超大模型
(2)单卡计算优化
1.算子融合:合并LayerNorm、QKV、激活等小算子,减少频繁内核开销
2.内存优化:激活重计算、参数持久化、内存卸载
3.CUDA Graph、动态最优内核调度,降低推理延迟
(3)多卡并行推理
- 张量并行 TP:切分层内权重,适合单层超大模型,通信开销高;
- 流水线并行 PP:切分层网络,适合层数多的模型;
- 数据并行 DP:多请求批处理,通信开销小;
- MoE 专家并行:适配混合专家模型;
- 工程常用:TP+PP+DP 混合并行部署。
(4)在线服务低延迟优化
-连续批请求
-异步计算通信重叠
-预分配内存池
20、稀疏注意力
(1)作用
标准注意力复杂度,长序列开销巨大;
稀疏注意力靠掩码限制交互范围,降复杂度至,支持超长文本
(2)四类稀疏模式
-局部:只看相邻token
-全局:少量特殊token互通全局信息
-随机:随机采样部分token
-带状:间隔固定步长关注
(3)两种内置实现
1.BigBird:局部+全局+随机,极致长文本通用
2.Longformer:滑动窗口,文档类任务效率高
(4)使用方式
ds_config开启sparse_attention,配置窗口、全局块、随机块参数,无需改模型代码。