一、Transformer 架构 以deepseek为例61 层是同时运行的吗?
串行

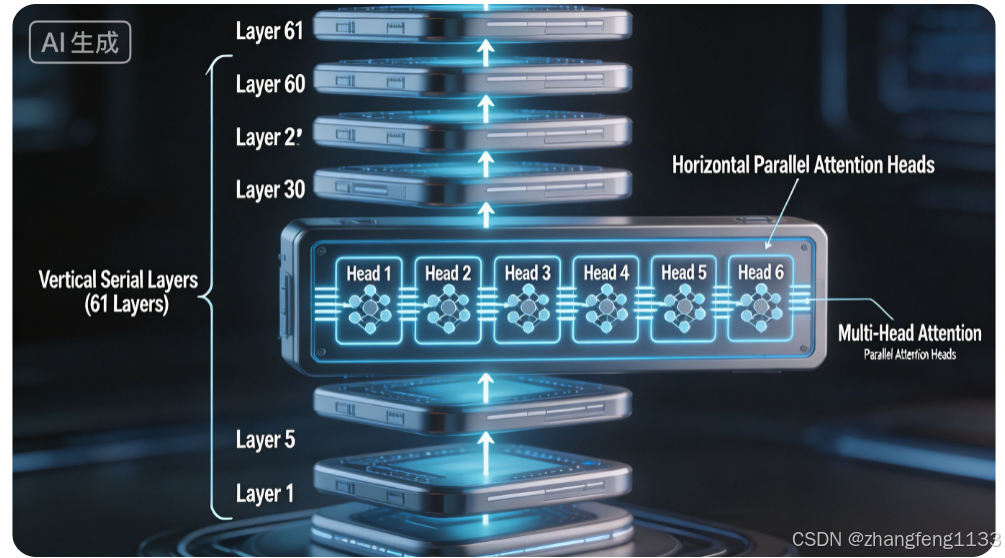
不是同时运行,而是逐层顺序执行(Sequential Execution)。
这是所有 Transformer 架构的基本特性:
- 第 NNN 层的输出是第 N+1N+1N+1 层的输入,层与层之间存在数据依赖关系
- 因此 61 层必须一层一层往上叠,无法并行执行所有层
- 正如技术报告中描述的:"Pro 有 61 层,Flash 有 43 层,CSA 和 HCA 一层一层往上叠"
不过,单层内部的操作可以高度并行化。vLLM 的实现中,在单层内部使用了多 CUDA 流重叠技术:
- 索引器计算、主注意力 KV 压缩、滑动窗口 token 插入这三个分支可以并行
- 在低 batch size 下,这种重叠能带来 5-6% 的端到端延迟降低
二、如何提高 DeepSeek-V4 部署效率?
1. MoE Decode 优化(你的直觉是对的)
DeepSeek-V4-Pro 的 MoE 配置:
- 384 个 routed experts + 1 个 shared expert
- 每 token 只激活 6 个专家(约 49B 激活参数,总参数 1.6T)
优化方向:
| 优化手段 | 说明 |
|---|---|
| Expert Parallelism (EP) | --enable-expert-parallel 将不同专家分布到不同 GPU,减少单卡显存压力 |
| FP4 量化 | V4 支持 MXFP4 量化,MoE 权重(显存大头)可砍半,且 FP4→FP8 dequant 无损 |
| Mega-MoE | vLLM 中 use_mega_moe 优化 all-to-all 通信 |
| CUDA Graphs | 削减 decode 路径的 kernel 启动开销 |
2. 长上下文 KV 缓存优化(V4 的核心优势)
V4 的混合注意力机制(CSA + HCA 交替)使 KV 缓存大幅降低:
- 1M 上下文下,每个序列仅需 9.62 GiB KV 缓存
- 比传统 61 层 Dense Attention 堆栈的 83.9 GiB 小了 88.5%
部署建议:
- 使用
--kv-cache-dtype fp8进一步压缩 - 开启
--attention_config.use_fp4_indexer_cache=True加速索引器
3. 并行策略配置
根据 Together.ai 的分析,不同负载需要不同的并行配置 :
| 场景 | 推荐配置 |
|---|---|
| 长上下文 Agent | 大 TP(如 TP=8/16)、大 batch、prefix reuse |
| 代码补全 | 中等 TP、注重 cache tiering 和 SWA 重计算策略 |
| 短对话 | 小 TP、小 batching delay、短上下文优化 kernel |
| RL Rollouts | 高吞吐优先,长轨迹生成 |
4. vLLM 部署命令参考
V4-Pro(8×B200/B300):
bash
docker run --gpus all --ipc=host -p 8000:8000 \
vllm/vllm-openai:deepseekv4-cu130 deepseek-ai/DeepSeek-V4-Pro \
--trust-remote-code \
--kv-cache-dtype fp8 \
--block-size 256 \
--enable-expert-parallel \
--data-parallel-size 8 \
--compilation-config '{"cudagraph_mode":"FULL_AND_PIECEWISE", "custom_ops":["all"]}' \
--attention_config.use_fp4_indexer_cache=True注意: 目前 V4-Pro 在 TP=16 时存在 shared_experts 的 FP8 block-shape 兼容性问题,建议先用 TP=8
三、总结
| 问题 | 答案 |
|---|---|
| 61 层是否同时运行? | 否,逐层顺序执行,但单层内部可多流并行 |
| 提高效率的关键? | MoE EP + FP4 量化 + KV 缓存压缩 + CUDA Graphs |
| Decode 阶段重点? | 保持 GPU 满载(低 batch 时多流重叠、减少启动开销) |
| 长上下文优势? | CSA/HCA 混合注意力使 KV 缓存亚线性增长 |
如果你正在部署 V4-Pro,建议优先开启 --enable-expert-parallel 和 --attention_config.use_fp4_indexer_cache=True,并根据实际负载调整 TP 大小。
我来为你详细解释多头注意力机制(Multi-Head Attention, MHA)的原理,以及 DeepSeek-V4 中的特殊变体。
一、标准多头注意力机制(MHA)
1. 核心思想
"多头" = 多组独立的注意力计算,让模型同时从不同的"视角"关注输入序列的不同方面。
输入: Q, K, V (来自同一序列的不同线性投影)
┌─→ Head 1: 关注语法结构 ──┐
├─→ Head 2: 关注语义关系 ──┤
Q,K,V ──┼─→ Head 3: 关注指代消解 ──┼─→ Concat ─→ Linear ─→ 输出
├─→ Head 4: 关注位置信息 ──┤
└─→ Head 5: 关注长程依赖 ──┘2. 数学公式
对于单个 head iii:
Attentioni(Qi,Ki,Vi)=softmax(QiKiTdk)Vi\text{Attention}_i(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right) V_iAttentioni(Qi,Ki,Vi)=softmax(dk QiKiT)Vi
其中:
- Qi=XWiQQ_i = X W_i^QQi=XWiQ, Ki=XWiKK_i = X W_i^KKi=XWiK, Vi=XWiVV_i = X W_i^VVi=XWiV(通过可学习的投影矩阵得到)
- dk=dmodel/hd_k = d_{model} / hdk=dmodel/h(每个 head 的维度,hhh 为 head 数量)
最终输出:
MultiHead(Q,K,V)=Concat(head1,...,headh)WO\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, ..., \text{head}_h) W^OMultiHead(Q,K,V)=Concat(head1,...,headh)WO
3. 为什么需要多头?
| 单头注意力的局限 | 多头注意力的优势 |
|---|---|
| 只能捕捉一种关系模式 | 不同 head 学习不同模式(语法、语义、指代等) |
| 表达能力有限 | 并行计算多个子空间,增强模型容量 |
| 容易过拟合到特定模式 | 注意力分布更平滑、更鲁棒 |
二、DeepSeek-V4 的混合注意力机制
DeepSeek-V4 没有使用标准 MHA,而是采用了 CSA(Compressed Sparse Attention)和 HCA(High Compression Attention)交替的混合设计 :
1. CSA(压缩稀疏注意力)
输入序列: [t1, t2, t3, t4, t5, t6, t7, t8, ...]
压缩方式: 每 m=4 个 token 压缩成 1 个 KV entry
[t1-t4] → kv1, [t5-t8] → kv2, ...
注意力: 每个 query 只关注 top-k 个压缩后的 KV(稀疏)特点:
- 压缩率温和(m=4)
- 保留 token-level 精细信息
- 适合局部细节检索
2. HCA(高压缩注意力)
输入序列: [t1, t2, t3, ..., t128, ...]
压缩方式: 每 m'=128 个 token 压缩成 1 个 KV entry
[t1-t128] → kv1, [t129-t256] → kv2, ...
注意力: 对所有压缩后的 KV 做 dense attention特点:
- 压缩率激进(m'=128)
- 适合长距离全局信号汇总
- 计算量小,覆盖范围广
3. 为什么交替使用?
Layer 1: HCA → 建立全局上下文概览
Layer 2: CSA → 在全局框架下检索局部细节
Layer 3: HCA → 整合局部信息,更新全局理解
Layer 4: CSA → 基于更新后的全局理解再检索细节
...效果: 更多的 CSA↔HCA 交替轮次 → 更多次"精化-验证"循环 → 信息整合更充分
三、V4 中的额外注意力机制
1. Sliding Window Attention(滑动窗口注意力)
每个 query 除了看压缩 KV 外,还能看最近 128 个 token 的原始 KV作用: 补偿压缩注意力的严格因果性(query 看不到同一块内其他 token 的信息)
2. Attention Sink

在 attention 分母上加一个可学习的 sink logit
允许 attention score 总和不等于 1作用: 避免长序列中注意力被迫均摊,让模型更聚焦
四、对比总结
| 机制 | 标准 Transformer | DeepSeek-V4 |
|---|---|---|
| 注意力类型 | 统一 Dense Attention | CSA + HCA 交替 |
| KV 缓存增长 | O(L)O(L)O(L) 线性 | O(L/m)O(L/m)O(L/m) 亚线性 |
| 1M 上下文 KV 缓存 | ~83.9 GiB | ~9.62 GiB |
| 长程依赖 | 靠位置编码 | HCA 显式压缩聚合 |
| 局部细节 | 全部保留 | CSA 稀疏检索 |
| 计算效率 | 低(O(L2)O(L^2)O(L2)) | 高(混合稀疏) |
五、直观类比
想象你在读一本 1000 页的书:
| 机制 | 阅读策略 |
|---|---|
| 标准 MHA | 每读到一个新词,都要回头和所有 1000 页的内容做对比(累死) |
| CSA | 每 4 页做个摘要,读到新内容时只快速翻看相关摘要 |
| HCA | 每 128 页做个超级摘要,先把握全书脉络 |
| V4 混合 | 先翻超级摘要把握全局 → 再查详细摘要深入细节 → 再更新全局理解 → 再查细节... |
这种设计让 V4 在保持长上下文能力的同时,大幅降低了计算和显存开销。
明白了!你是问多头注意力机制(Multi-Head Attention)和多层 Transformer 串行执行之间的关系和区别。这是两个不同维度的概念:
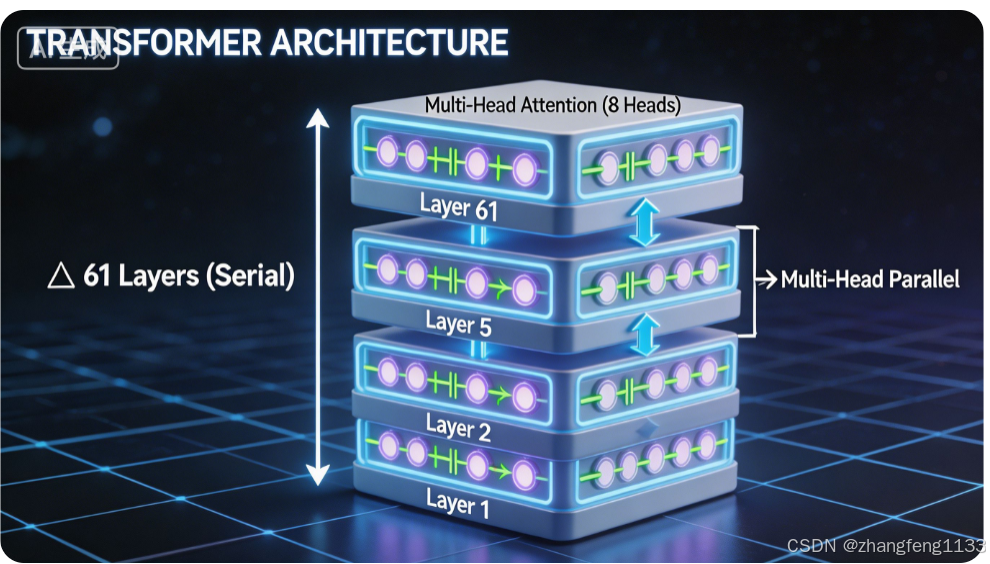
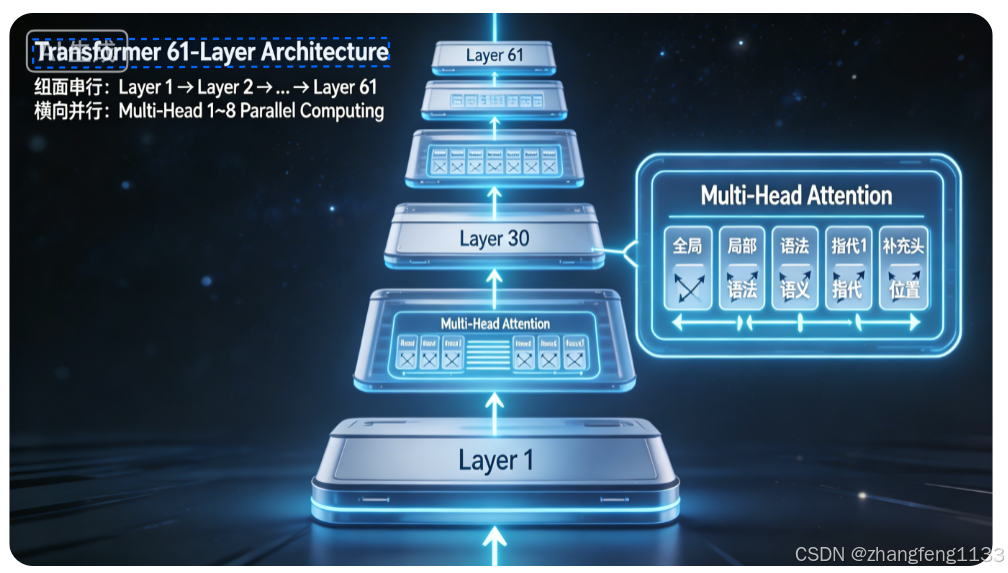
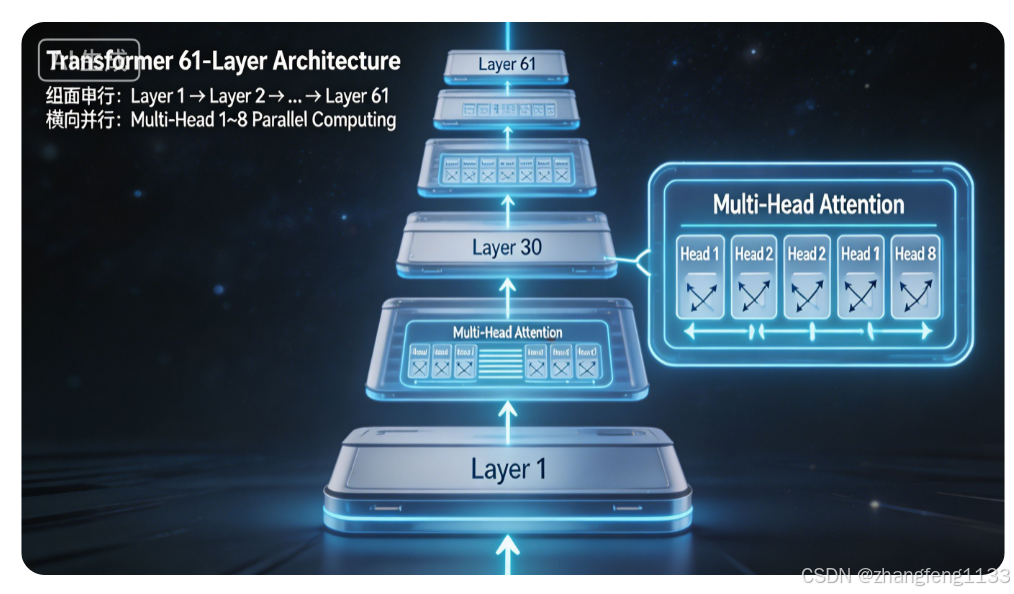
一、核心区别:正交的两个维度
┌─────────────────────────────────────────────────────────┐
│ Transformer 架构 │
├─────────────────────────────────────────────────────────┤
│ 纵向:层与层之间(Layer-wise) → 串行执行,61层 │
│ 横向:层内注意力头(Head-wise) → 并行计算,多 head │
└─────────────────────────────────────────────────────────┘| 维度 | 多头注意力(MHA) | 多层 Transformer |
|---|---|---|
| 所在位置 | 单层内部 | 层与层之间 |
| 执行方式 | 并行(多个 head 同时计算) | 串行(第 N 层输出 = 第 N+1 层输入) |
| 目的 | 从多个"视角"同时关注输入 | 逐步提取/转换特征,深度建模 |
| 数据依赖 | 各 head 独立,无依赖 | 层间强依赖,必须顺序执行 |
| 类比 | 一个团队多人同时从不同角度分析 | 工厂流水线,上一道工序做完才能做下一道 |
二、详细拆解
1. 多头注意力(层内并行)
输入 X ──┬─→ Head 1 (WQ1, WK1, WV1) ──→ Attention1 ──┐
├─→ Head 2 (WQ2, WK2, WV2) ──→ Attention2 ──┤
├─→ Head 3 (WQ3, WK3, WV3) ──→ Attention3 ──┼─→ Concat ─→ WO ─→ 输出
├─→ Head 4 (WQ4, WK4, WV4) ──→ Attention4 ──┤
└─→ Head 5 (WQ5, WK5, WV5) ──→ Attention5 ──┘
↑ 这 5 个 head 的计算是并行的,互不依赖关键点:
- 每个 head 有独立的 WQ,WK,WVW^Q, W^K, W^VWQ,WK,WV 投影矩阵
- 所有 head 对同一个输入 X 做不同的线性变换
- GPU 上可以同时计算所有 head,然后拼接结果
2. 多层 Transformer(层间串行)
输入 Embedding ──→ Layer 1 ──→ Layer 2 ──→ Layer 3 ──→ ... ──→ Layer 61 ──→ 输出
↑ ↑ ↑ ↑
必须等 Layer 1 的输出作为 Layer 2 的输入
↑ 这 61 层必须串行,因为每层都在前一层的基础上进一步变换关键点:
- 第 N 层的输出 = 第 N+1 层的输入(残差连接后)
- 层与层之间存在数据依赖,无法跳过或并行
- 深度(61层)提供逐级抽象能力
三、两者如何配合工作
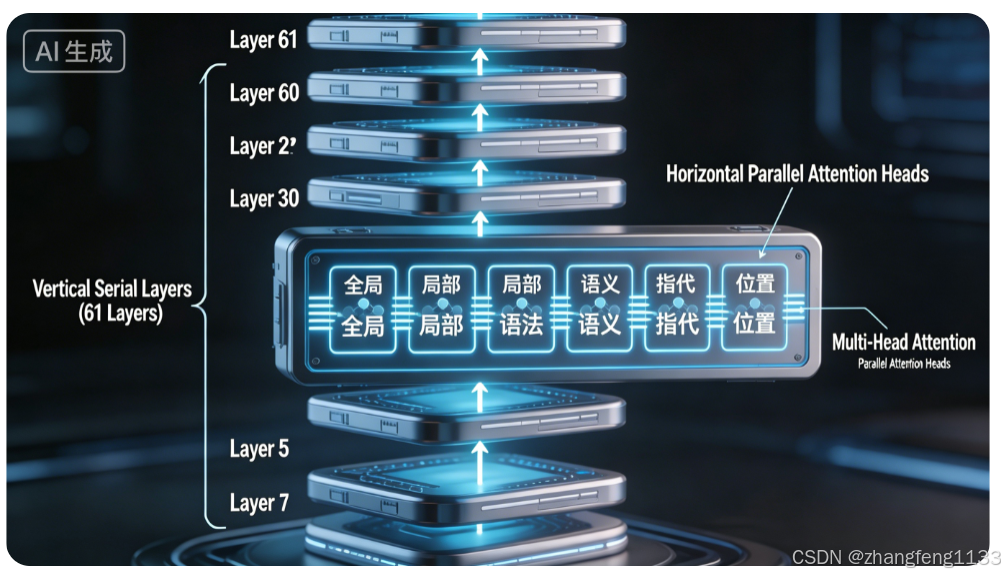
┌────────────────────────────────────────────────────────────┐
│ Layer 1 (HCA) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Multi-Head Attention (8 heads 并行) │ │
│ │ Head1 Head2 Head3 Head4 Head5 Head6 Head7 Head8 │ │
│ │ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │ │
│ │ 全局 全局 局部 局部 语法 语义 指代 位置 │ │
│ │ └────────── Concat + Linear ──────────────────────┘ │
│ └─────────────────────────────────────────────────────┘ │
│ ↓ (输出作为 Layer 2 的输入) │
│ Layer 2 (CSA) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Multi-Head Attention (8 heads 并行) │ │
│ │ Head1 Head2 Head3 Head4 Head5 Head6 Head7 Head8 │ │
│ │ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │ │
│ │ 稀疏 稀疏 精细 精细 局部 局部 细节 细节 │ │
│ │ └────────── Concat + Linear ──────────────────────┘ │
│ └─────────────────────────────────────────────────────┘ │
│ ↓ (输出作为 Layer 3 的输入) │
│ ... │
└────────────────────────────────────────────────────────────┘
横向:每层内部,多个 head 并行计算(多头注意力)
纵向:层与层之间,必须串行执行(深度堆叠)四、形象类比
类比 1:工厂流水线
| 概念 | 类比 |
|---|---|
| 多层 Transformer | 流水线的 61 个工位,必须按顺序加工 |
| 多头注意力 | 每个工位上有 8 个工人同时从不同角度检查产品 |
类比 2:写作过程
| 概念 | 类比 |
|---|---|
| 多层 Transformer | 写作的 61 轮修改:草稿 → 润色 → 校对 → ... |
| 多头注意力 | 每轮修改时,同时从语法、逻辑、风格、事实等多个角度审视 |
类比 3:图像识别
| 概念 | 类比 |
|---|---|
| 多层 Transformer | CNN 的深层网络:边缘 → 纹理 → 部件 → 物体 |
| 多头注意力 | 每层内部,多个滤波器同时检测不同特征(横线、竖线、斜线、曲线) |
五、为什么这样设计?
| 设计选择 | 原因 |
|---|---|
| Head 内并行 | 同一层内不同视角的计算无依赖,GPU 友好 |
| 层间串行 | 深度网络需要逐级抽象,浅层提取局部特征,深层整合全局语义 |
| 两者结合 | 既利用并行计算的硬件优势(head 并行),又获得深度建模能力(层间串行) |
六、总结
┌────────────────────────────────────────┐
│ 多头注意力 vs 多层 Transformer │
├────────────────────────────────────────┤
│ 空间维度 vs 时间/深度维度 │
│ 并行计算 vs 串行执行 │
│ 多视角观察 vs 逐级抽象 │
│ 横向扩展 vs 纵向堆叠 │
│ "一起看" vs "逐步想" │
└────────────────────────────────────────┘两者是正交互补的:
- 多头 解决的是"怎么看"的问题(多视角并行)
- 多层 解决的是"想多深"的问题(逐级串行抽象)
DeepSeek-V4 的 61 层 × 每层多 head 的设计,就是在两个维度上都做到极致。