背景:为什么这个接口适合做战力数据工具
王者荣耀战力数据常见的使用场景并不复杂:输入英雄,选择系统和平台,拿到不同省、市、区县的战力分布,再根据最低战力、最高战力或完整榜单做展示。难点在于,英雄 ID、区服枚举、数据层级和接口响应结构如果不统一,后续做前端看板、机器人查询或定时分析时会反复写胶水代码。
极数本源的「王者战力查询」接口把这件事压缩成一个 HTTP GET 接口:
action=heroes:获取英雄目录,包含中文名、ename、称号和头像地址。action=query:查询指定英雄在指定区服的全国战力分布。type=all|min|max:分别对应完整列表、最低战力、最高战力三种返回策略。
截至 2026-06-18 实测,action=heroes 返回 130 个英雄;query&hero_id=107&zone=aqq&type=min 可以拿到赵云在 Android QQ 区的最低战力结构化数据。
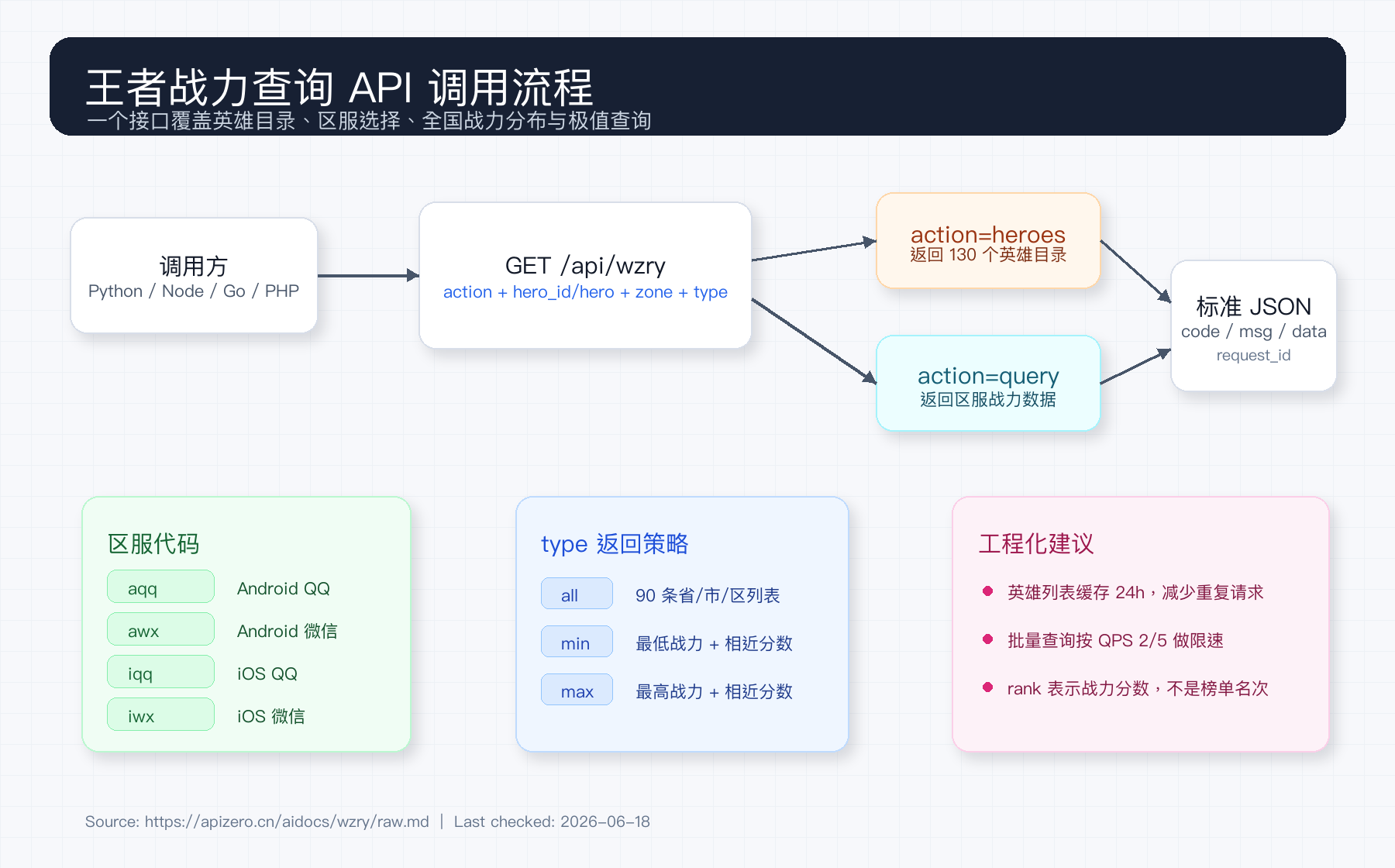
接口能力速览
接口地址:
text
GET https://v1.apizero.cn/api/wzry核心参数如下:
| 参数 | 必填 | 说明 | 示例 |
|---|---|---|---|
action |
是 | heroes 获取英雄列表;query 查询战力 |
query |
hero |
条件必填 | 英雄中文名,action=query 时与 hero_id 二选一 |
赵云 |
hero_id |
条件必填 | 英雄 ename,优先级高于 hero |
107 |
zone |
查询必填 | 区服代码 | aqq |
type |
否 | all、min、max,默认 all |
min |
区服代码建议在业务侧做成枚举,避免用户输入不可控:
| zone | 系统 | 平台 |
|---|---|---|
aqq |
Android | |
awx |
Android | 微信 |
iqq |
iOS | |
iwx |
iOS | 微信 |
type 的差异尤其重要:
| type | 返回重点 | 适合场景 |
|---|---|---|
all |
约 90 条省、市、区县混合战力列表 | 地图、表格、筛选分析 |
min |
省级、市级、区县级最低战力及相近分数 | 找低门槛地区、做推荐 |
max |
省级、市级、区县级最高战力及相近分数 | 展示顶尖战力、做对比 |
这里有一个容易踩坑的字段名:响应里的 rank 表示战力分数,不是榜单名次。比如 rank: 10577 的含义是战力分为 10577,而不是第 10577 名。
认证、限流与缓存策略
接口支持匿名调用,也支持 API Key 鉴权。匿名调用适合开发调试;如果要做定时任务、Web 服务或多人查询工具,建议申请 API Key,并在后端通过 Authorization 请求头携带。
text
Authorization: Bearer sk_live_xxxxxxxxxxxxxx配额和缓存信息可以直接影响工程设计:
| 项目 | 匿名调用 | 已认证用户 |
|---|---|---|
| 每日免费额度 | 50 次 | 200 次 |
| QPS 限制 | 2 req/s | 5 req/s |
| 英雄列表缓存 | 24 小时 | 24 小时 |
| 战力数据缓存 | 1 小时 | 1 小时 |
实践中建议这样处理:
- 英雄列表本地缓存 24 小时,启动时或缓存过期后再刷新。
- 批量查询时按更保守的速度限流,匿名调用至少间隔 0.5 秒。
- API Key 不要写进前端代码,前端请求自己的后端,由后端转发。
- 战力数据有 1 小时缓存,分钟级高频轮询没有必要。
先看真实响应结构
英雄列表响应的 data.list 是后续查询的基础。每个英雄都有 name 和 ename,其中 ename 就是查询时可用的 hero_id。
json
{
"code": 0,
"msg": "成功",
"data": {
"action": "heroes",
"count": 130,
"list": [
{
"name": "赵云",
"title": "苍天翔龙",
"ename": "107",
"avatar": "https://game.gtimg.cn/images/yxzj/img201606/heroimg/107/107.jpg"
}
]
}
}查询 type=min 或 type=max 时,rank_data 不是数组,而是 extreme + similar 结构:
json
{
"action": "query",
"hero": {
"name": "赵云",
"title": "苍天翔龙",
"ename": "107"
},
"zone": {
"code": "aqq",
"system": "Android",
"platform": "QQ"
},
"type_code": "min",
"syn_date": "2026-06-18",
"rank_data": {
"extreme": {
"province": {
"address": "天津",
"level": "province",
"rank": 10577
}
},
"similar": {
"province": []
}
}
}如果是 type=all,rank_data 会变成列表,每一项包含 address、level、rank、adcode。因此代码里不能把三种 type 的返回结构混为一谈。
Python 封装:查询赵云最低战力并导出 CSV
下面这份脚本只使用 Python 标准库,可以直接运行。没有 API Key 时会走匿名调用;如果配置了环境变量 APIZERO_KEY,脚本会自动加上鉴权头。
保存为 wzry_power.py:
python
import csv
import json
import os
import time
from pathlib import Path
from typing import Any
from urllib.parse import urlencode
from urllib.request import Request, urlopen
BASE_URL = "https://v1.apizero.cn/api/wzry"
API_KEY = os.getenv("APIZERO_KEY")
ZONE_NAMES = {
"aqq": "Android QQ",
"awx": "Android 微信",
"iqq": "iOS QQ",
"iwx": "iOS 微信",
}
LEVEL_NAMES = {
"province": "省级",
"city": "市级",
"district": "区县级",
}
ERROR_HINTS = {
4000: "参数错误:检查 action、zone、type,或确认 hero/hero_id 是否存在",
4015: "匿名调用每日额度已用完:请配置 API Key",
4029: "QPS 超限:降低请求频率后重试",
4030: "今日额度已用完:等待额度刷新或调整调用策略",
5020: "上游 HTTP 失败:稍后重试",
5021: "上游响应异常或该英雄在该区服暂无战力数据",
}
def call_wzry(params: dict[str, Any], retries: int = 2) -> dict[str, Any]:
headers = {}
if API_KEY:
headers["Authorization"] = f"Bearer {API_KEY}"
for attempt in range(retries + 1):
query = urlencode(params)
request = Request(f"{BASE_URL}?{query}", headers=headers, method="GET")
with urlopen(request, timeout=15) as response:
payload = json.loads(response.read().decode("utf-8"))
if payload.get("code") == 0:
return payload["data"]
code = int(payload.get("code", -1))
message = payload.get("msg", "未知错误")
hint = ERROR_HINTS.get(code, "未收录错误码,请查看接口返回")
if code == 4029 and attempt < retries:
time.sleep(1.5 * (attempt + 1))
continue
raise RuntimeError(f"API 调用失败 code={code}, msg={message}, hint={hint}")
raise RuntimeError("重试后仍未成功")
def fetch_heroes() -> list[dict[str, Any]]:
data = call_wzry({"action": "heroes"})
return data["list"]
def find_hero(heroes: list[dict[str, Any]], name: str) -> dict[str, Any]:
for hero in heroes:
if hero["name"] == name:
return hero
raise ValueError(f"英雄不存在:{name}")
def query_power(hero_id: str, zone: str = "aqq", type_code: str = "min") -> dict[str, Any]:
if zone not in ZONE_NAMES:
raise ValueError(f"非法区服:{zone}")
if type_code not in {"all", "min", "max"}:
raise ValueError(f"非法查询类型:{type_code}")
return call_wzry(
{
"action": "query",
"hero_id": hero_id,
"zone": zone,
"type": type_code,
}
)
def flatten_minmax(data: dict[str, Any]) -> list[dict[str, Any]]:
hero_name = data["hero"]["name"]
zone_code = data["zone"]["code"]
type_code = data["type_code"]
syn_date = data["syn_date"]
rank_data = data["rank_data"]
rows: list[dict[str, Any]] = []
for level, level_name in LEVEL_NAMES.items():
extreme_item = rank_data.get("extreme", {}).get(level)
if extreme_item:
rows.append(
{
"hero": hero_name,
"zone": zone_code,
"type_code": type_code,
"syn_date": syn_date,
"level": level_name,
"group": "extreme",
"address": extreme_item["address"],
"rank": extreme_item["rank"],
"adcode": extreme_item.get("adcode", ""),
}
)
for item in rank_data.get("similar", {}).get(level, []):
rows.append(
{
"hero": hero_name,
"zone": zone_code,
"type_code": type_code,
"syn_date": syn_date,
"level": level_name,
"group": "similar",
"address": item["address"],
"rank": item["rank"],
"adcode": item.get("adcode", ""),
}
)
return rows
def write_csv(rows: list[dict[str, Any]], output: Path) -> None:
fieldnames = [
"hero",
"zone",
"type_code",
"syn_date",
"level",
"group",
"address",
"rank",
"adcode",
]
with output.open("w", newline="", encoding="utf-8-sig") as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(rows)
def main() -> None:
heroes = fetch_heroes()
hero = find_hero(heroes, "赵云")
data = query_power(hero_id=hero["ename"], zone="aqq", type_code="min")
rows = flatten_minmax(data)
for row in rows[:8]:
print(
f"{row['hero']} | {row['zone']} | {row['level']} | "
f"{row['group']} | {row['address']} | 战力 {row['rank']}"
)
write_csv(rows, Path("zhaoyun_aqq_min.csv"))
print("已导出:zhaoyun_aqq_min.csv")
if __name__ == "__main__":
main()运行:
bash
python wzry_power.py如果你有 API Key,可以这样配置:
bash
export APIZERO_KEY="sk_live_xxxxxxxxxxxxxx"
python wzry_power.py这段封装做了几件生产环境里很有价值的事:
- 请求参数只使用文档中存在的字段:
action、hero_id、zone、type。 - 对
zone和type做本地校验,提前拦截无效输入。 - 对
4029QPS 超限做了简单退避重试。 - 把
min/max的嵌套结构摊平成 CSV,方便 Excel、BI 或 Pandas 继续处理。 - 使用
utf-8-sig写 CSV,Windows Excel 打开中文更省心。
如果要处理 type=all,应该怎么展开
type=all 的结构更适合做地图和表格,因为它直接返回一组地区战力记录。可以单独写一个展开函数:
python
def flatten_all(data: dict[str, Any]) -> list[dict[str, Any]]:
hero_name = data["hero"]["name"]
zone_code = data["zone"]["code"]
syn_date = data["syn_date"]
rows = []
for item in data["rank_data"]:
rows.append(
{
"hero": hero_name,
"zone": zone_code,
"syn_date": syn_date,
"level": item["level"],
"address": item["address"],
"rank": item["rank"],
"adcode": item.get("adcode", ""),
}
)
return rows调用时只需要把查询类型改成 all:
python
data = query_power(hero_id="107", zone="aqq", type_code="all")
rows = flatten_all(data)注意:all 返回的 level 仍然是英文代码,例如 province、city、district。如果是面向用户展示,建议在前端或后端统一映射为「省级」「市级」「区县级」。
错误码应该如何落到业务逻辑
接口返回的 HTTP 状态码不一定能表达全部业务错误,真正要看的还是 JSON 里的 code。
| code | 含义 | 建议处理 |
|---|---|---|
4000 |
参数错误、英雄未找到 | 给用户明确提示,并打印参数用于排查 |
4015 |
匿名每日额度用完 | 引导配置 API Key |
4029 |
QPS 超限 | 退避重试,批量任务降低并发 |
4030 |
今日额度用完 | 停止任务,等待额度刷新 |
5020 |
上游 HTTP 失败 | 稍后重试,记录 request_id |
5021 |
上游格式异常或暂无数据 | 展示空态,不要当成程序崩溃 |
对用户侧工具来说,最重要的是区分「用户可修正」和「系统暂不可用」:
4000通常是参数问题,应该让用户换英雄、换区服或检查输入。4015、4030是额度问题,应该减少调用或启用 Key。5020、5021更像数据源问题,应该保留日志并给出友好的空态。
工程化落地建议
1. 英雄目录做本地索引
用户通常输入的是中文英雄名,但查询时用 hero_id 更稳定,因为 hero_id 的优先级高于 hero。建议服务启动后先拉取 action=heroes,生成两个索引:
python
heroes = fetch_heroes()
by_name = {hero["name"]: hero for hero in heroes}
by_id = {hero["ename"]: hero for hero in heroes}这样既能支持中文搜索,也能在内部统一用 ename 查询。
2. 批量查询要主动限速
假设要查询 20 个英雄、4 个区服、3 种类型,总请求数是:
text
20 * 4 * 3 = 240这个量级已经超过单日免费额度,且很容易触发 QPS 限制。因此批量任务要先判断是否真的需要全部组合。常见优化方式包括:
- 默认只查用户关心的
zone。 - 首页只展示
min,详情页再查all。 - 同一英雄同一区服的数据缓存 1 小时。
- 离线任务分批运行,不要瞬间打满。
3. 前端展示要解释 rank 字段
如果直接把字段名 rank 展示给用户,很容易被理解成「排名」。更好的做法是在 UI 上显示为「战力」或「战力分」。字段名不改,展示语义要改。
示例:
text
天津 | 省级最低战力:10577
新疆/克州 | 市级最低战力:6315
内蒙古/乌兰察布市/化德县 | 区县级最低战力:19744. 记录 request_id 方便排查
当接口返回错误时,响应里可能带有 request_id。生产环境建议把它和请求参数一起写入日志。这样排查上游异常、额度问题或格式变化时,会比只看错误文本有效得多。
可以扩展成哪些项目
这个接口非常适合做小而完整的数据项目:
- 王者英雄战力查询网页:英雄搜索、区服切换、最低战力推荐。
- QQ/微信群机器人:输入「赵云 安卓QQ 最低」返回省市区最低战力。
- 数据看板:按
province/city/district聚合,展示不同英雄的门槛变化。 - 定时报告:每天拉取重点英雄数据,保存 CSV 后生成趋势图。
- 游戏资料聚合页:英雄头像、称号、战力区服数据一起展示。
如果只是做个人工具,Python 脚本加 CSV 已经够用;如果要做多人访问服务,建议加一层后端缓存,把 API Key、限流和错误处理都放在服务端。
小结
王者战力查询 API 的优势是边界清晰:一个接口、两个 action、四个区服、三种查询类型。真正写代码时,重点不在「怎么发 GET 请求」,而在于把返回结构理解透:heroes 是英雄目录,query 是战力数据;all 返回列表,min/max 返回 extreme + similar;rank 是战力分数,不是名次。
只要在工程侧补上本地缓存、参数枚举、错误码处理和限流策略,就可以很快把它包装成一个可用的战力查询工具。
参考资料:极数本源王者战力查询 API 文档