笔记定位:遵循「总览→硬件基础→文件格式→静态链接→动态链接→内核加载→进阶原理→排错实战」的学习路径,逐层深入,所有核心结论均附可复现命令验证,适合系统复习、博客沉淀、面试复盘。
前言
Linux 下的 C/C++ 开发,本质上就是不断和「编译、链接、加载、执行」打交道。写下 gcc main.c -lm 时,链接器在做什么?程序运行时动态库如何被加载进内存?多个进程为什么能共享同一份库代码?
很多人学习时把「静态库/动态库用法」「ELF格式」「内存映射」当成孤立知识点,本文会从最底层的 MMU 硬件分页出发,打通编译四阶段、ELF 双视图、静态链接规则、动态库加载、GOT/PLT 重定位、多进程写时复制的完整链路,补齐所有底层细节与实操排错方法,做到知其然更知其所以然。
一、总览:从源文件到运行程序的完整生命周期
一个 C 程序从 .c 源码到内存中运行的进程,一共要经历 4 个编译阶段 + 1 个加载阶段,动静态库的核心差异集中在「链接阶段」和「加载阶段」。
1.1 编译四阶段拆解
GCC 内部会依次调用预处理器、编译器、汇编器、链接器四个工具,每个阶段输入输出明确。
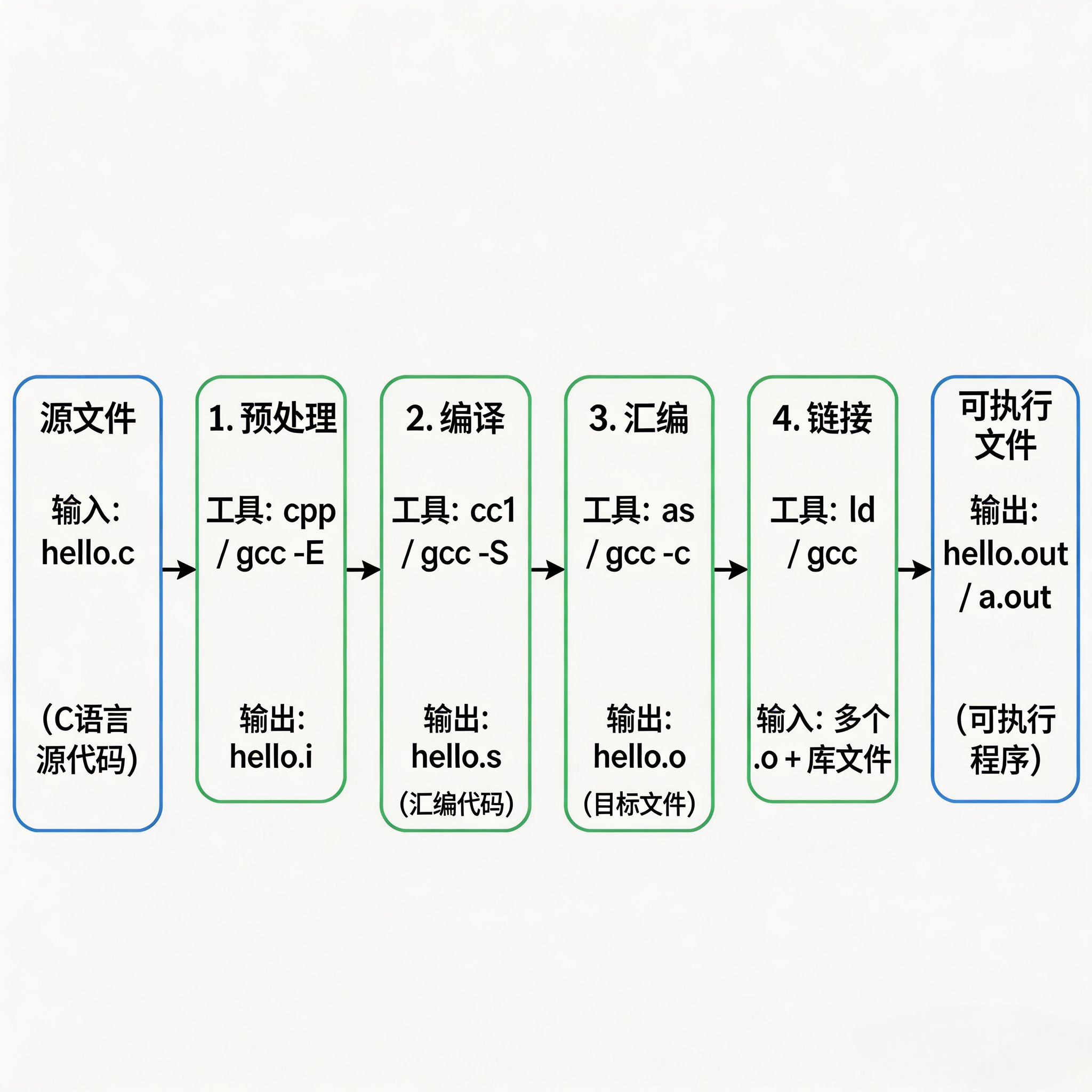
阶段1:预处理(Preprocessing)
-
核心工作 :处理所有
#开头的预处理指令- 展开
#include头文件 - 替换
#define宏定义 - 处理条件编译
#ifdef/#endif - 删除注释,添加行号标记
- 展开
-
对应命令 :
bashgcc -E main.c -o main.i # 生成预处理后的 .i 文件 -
产物特征:纯 C 代码文本,无任何宏定义和头文件引用。
阶段2:编译(Compilation)
-
核心工作:将 C 代码翻译成汇编语言,进行语法检查、优化、寄存器分配
-
对应命令 :
bashgcc -S main.i -o main.s # 生成汇编文件 .s -
产物特征:x86_64 汇编代码,人类可读的助记符格式。
阶段3:汇编(Assembly)
-
核心工作 :将汇编指令翻译成机器码,生成可重定位目标文件
.o -
对应命令 :
bashgcc -c main.s -o main.o # 生成目标文件 .o -
产物特征:二进制 ELF 文件,包含机器指令、数据、符号表、重定位表,但地址都是从 0 开始的相对偏移,无法直接运行。
阶段4:链接(Linking)
-
核心工作 :把多个
.o目标文件、库文件合并,解析符号、修正地址,生成最终可执行文件- 静态链接:把库中用到的代码直接复制进可执行文件
- 动态链接:只记录依赖关系,运行时再加载库
-
对应命令 :
bashgcc main.o add.o -o app # 链接多个目标文件 -
产物特征:完整的 ELF 可执行文件,有确定的虚拟地址布局,可以被内核加载运行。
1.2 加载执行阶段
可执行文件存储在磁盘上,双击/命令执行时,内核通过 execve 系统调用:
- 读取 ELF 头,解析段布局
- 创建进程地址空间,把代码段、数据段映射到虚拟内存
- 如果是动态链接程序,加载动态链接器
ld-linux.so - 跳转到程序入口,开始执行
全文核心脉络:先讲支撑内存映射的硬件基础,再讲 ELF 文件格式,再从简单到复杂讲静态链接、动态链接,最后深入内核加载与重定位原理。
二、硬件基石:MMU、虚拟地址空间与分页机制
所有内存映射、代码共享、写时复制的底层支撑,都是 CPU 内置的 MMU 与分页机制。不理解硬件层面的地址翻译,就无法真正理解动态库为什么能共享、为什么要分代码段数据段。
2.1 为什么需要虚拟地址?
如果程序直接使用物理地址,会有三个致命问题:
- 内存隔离差:程序可以访问任意物理地址,恶意程序能直接篡改其他进程数据
- 内存利用率低:程序必须连续存放,产生大量外部碎片
- 重定位困难:程序加载地址不固定,每次都要修改所有地址引用
虚拟地址完美解决了这些问题:
- 每个进程拥有独立的、完整的虚拟地址空间(32位下4GB,64位下256TB)
- 进程只能看到自己的虚拟地址,完全感知不到物理内存的真实分布
- 地址翻译由 MMU 硬件自动完成,对程序完全透明
2.2 MMU 与页表的工作原理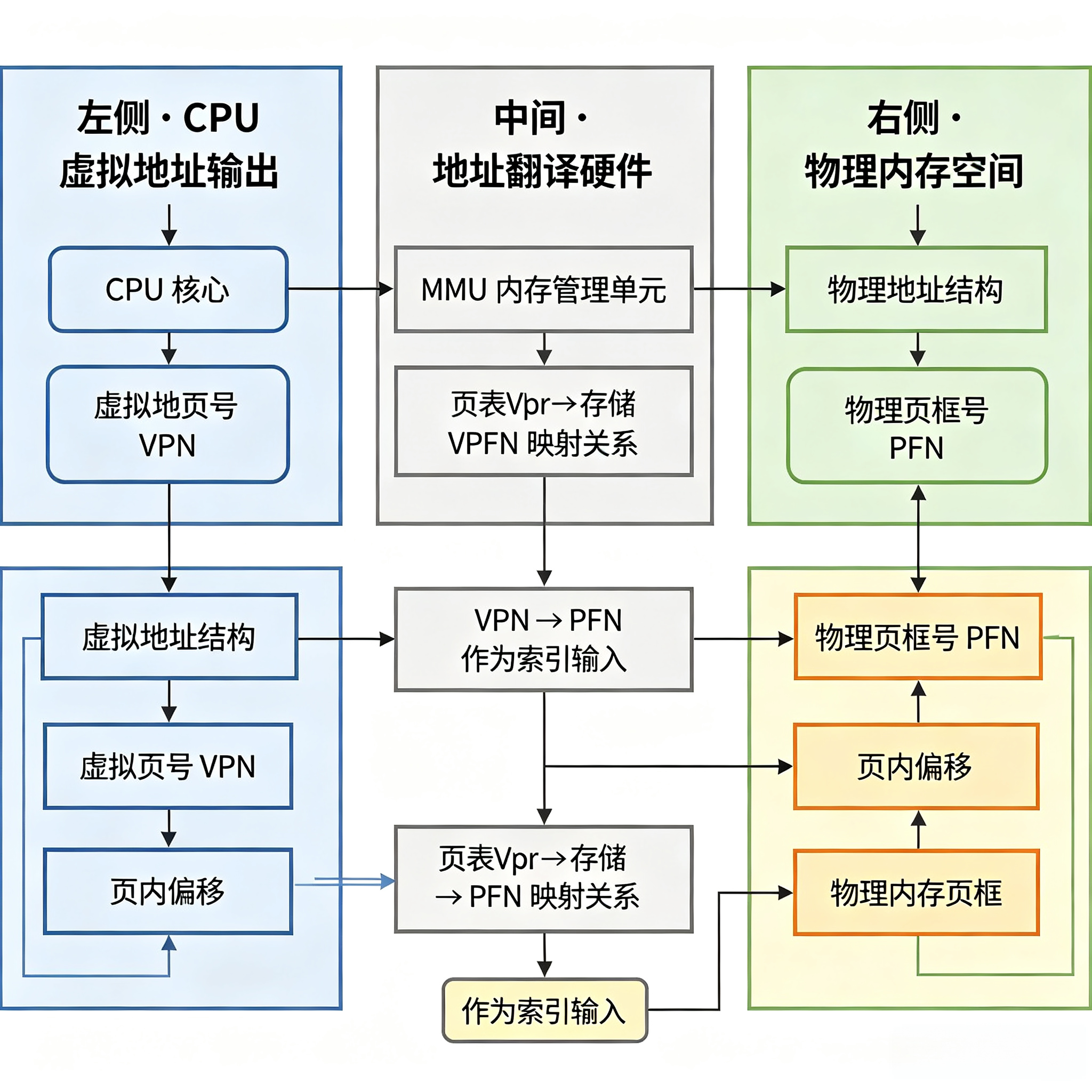
核心概念
-
页(Page) :内存管理的最小单位,x86_64 Linux 默认 4KB
bashgetconf PAGE_SIZE # 输出 4096,即 4KB -
页框(Page Frame):物理内存被划分为一个个 4KB 的物理页框
-
页表(Page Table):内核维护的一张映射表,记录「虚拟页号 → 物理页框号 + 权限位」
地址翻译过程
CPU 发出的虚拟地址分为两部分:虚拟页号 + 页内偏移
- MMU 根据虚拟页号查页表,找到对应的物理页框号
- 页内偏移直接拼接在物理页框号后,得到最终物理地址
- 页内偏移占 12 位(4KB = 2^12),因此页内偏移完全不需要翻译,虚拟地址和物理地址的偏移量完全相同
多级页表
64 位系统下如果用一级页表,单个进程的页表会占用几十 GB 内存。Linux 采用四级页表(页全局目录 PGD → 页上级目录 PUD → 页中间目录 PMD → 页表 PTE),只给实际使用的虚拟地址分配页表项,大幅节省内存。
2.3 缺页异常(Page Fault)
当 MMU 查页表时,遇到三种情况会触发缺页异常,由内核中断处理:
- 缺页(未分配) :虚拟地址合法,但还没分配物理页。内核分配物理页、填充数据、更新页表,返回继续执行。
- 比如访问
.bss段、申请堆内存、mmap 映射文件,都是「惰性分配」,真正访问时才分配物理页。
- 比如访问
- 写时复制缺页(COW) :页面标记为「只读 + 共享」,进程尝试写入时触发异常。内核复制一份新的物理页给当前进程,更新页表为可写,返回继续执行。
- 这是
fork()子进程、动态库数据段共享的核心硬件基础。
- 这是
- 权限错误 :比如往只读代码段写入数据,内核直接发送
SIGSEGV段错误信号终止进程。
2.4 页权限与段划分
每个页表项都有独立的权限位:读(R)、写(W)、执行(X)。操作系统根据用途把内存分为不同区域,设置对应权限:
- 代码段:
R + X,只读可执行,防止代码被篡改 - 数据段:
R + W,可读写,不可执行,防止数据被当成代码执行 - 只读数据段(
.rodata):R,只读不可写不可执行
这就是为什么 ELF 要把权限相同的节合并成段------内核按页设置权限,必须整页统一权限,这是段存在的硬件根源。
三、ELF 文件格式:链接视图与执行视图
ELF(Executable and Linkable Format)是 Linux 下目标文件、可执行文件、共享库、核心转储文件的统一格式。它最精妙的设计就是「一套文件,两种视图」,分别服务于链接器和加载器。
3.1 三类 ELF 文件
| 文件类型 | 后缀 | 特点 | 对应视图 |
|---|---|---|---|
| 可重定位目标文件 | .o |
地址从 0 开始,包含重定位信息,供链接器使用 | 链接视图为主 |
| 可执行文件 | 无后缀 | 有确定的虚拟地址(或 PIE 偏移),可直接加载运行 | 执行视图为主 |
| 共享目标文件 | .so |
位置无关代码,同时支持链接时使用和运行时加载 | 两种视图都支持 |
验证文件类型:
bash
readelf -h main.o # Type: REL (可重定位)
readelf -h /bin/ls # Type: DYN (PIE 可执行)
readelf -h /lib64/libc.so.6 # Type: DYN (共享库)3.2 ELF 整体结构
一个完整的 ELF 文件从前往后依次是:
- ELF 头(ELF Header):文件最开头,描述文件整体信息
- 节区(Sections):链接视图的基本单位,存放代码、数据、符号、重定位等
- 节区头表(Section Header Table):记录所有节的名称、偏移、大小、属性
- 程序头表(Program Header Table):执行视图的基本单位,描述段的加载信息
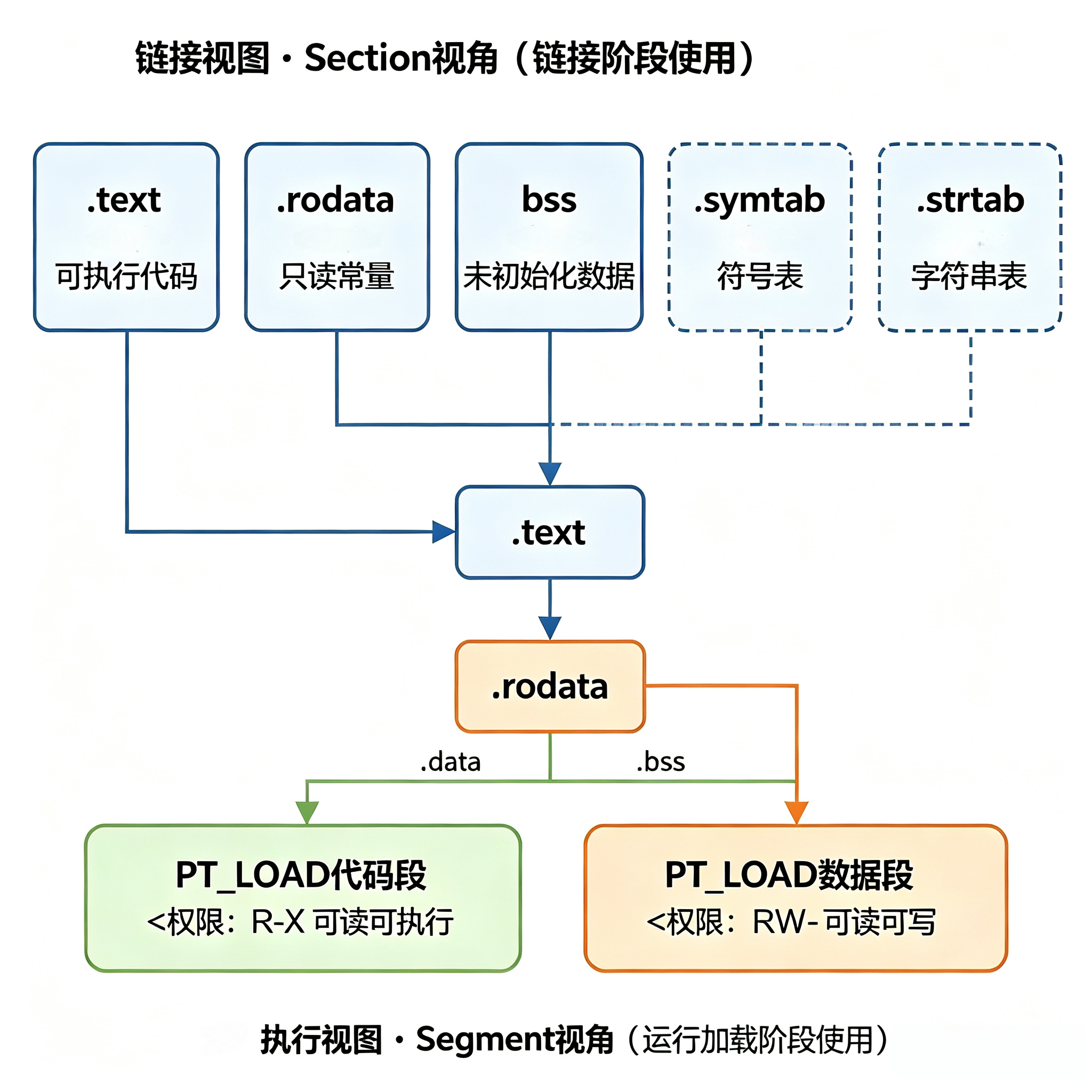
3.3 链接视图:节(Section)详解
节是链接器处理的基本单位,每个节有明确的功能。最核心的节如下:
| 节名 | 权限 | 作用 |
|---|---|---|
.text |
只读可执行 | 存放函数的机器指令,代码段核心 |
.rodata |
只读 | 只读数据,比如字符串常量、const 全局变量 |
.data |
可读写 | 已初始化的全局变量、静态变量 |
.bss |
可读写 | 未初始化的全局变量、静态变量,文件中不占空间,加载时清零 |
.symtab |
只读 | 符号表,存储所有函数、变量的符号名与地址 |
.strtab |
只读 | 字符串表,存储符号名的字符串,符号表只存偏移 |
.dynsym |
只读 | 动态符号表,只存和外部交互的符号,运行时加载用 |
.dynstr |
只读 | 动态字符串表,对应动态符号表 |
.rela.text / .rel.text |
只读 | 代码段重定位表,记录需要修正地址的位置 |
.rela.dyn |
只读 | 动态数据重定位表,全局变量的重定位 |
.rela.plt |
只读 | 动态函数重定位表,对应 GOT/PLT 的函数重定位 |
.got |
可读写 | 全局偏移表,存全局变量的真实地址 |
.got.plt |
可读写 | 函数地址表,存外部函数的真实地址 |
.plt |
只读可执行 | 过程链接表,函数跳转桩代码 |
.dynamic |
可读写 | 动态段,存储动态链接所需的所有信息(依赖库、符号表位置等) |
查看所有节:
bash
readelf -S main.o
readelf -S /bin/ls3.4 执行视图:段(Segment)详解
加载器不关心节,只关心段。段的核心作用是:把多个权限相同、地址连续的节合并在一起,一次性映射到内存。
最核心的两个 PT_LOAD 段:
- 代码段(LOAD + R E) :包含
.text、.rodata、.plt、.dynsym等只读/可执行的节 - 数据段(LOAD + R W) :包含
.data、.bss、.got、.got.plt、.dynamic等可读写的节
查看程序头与段-节映射:
bash
readelf -l /bin/ls输出末尾的 Section to Segment mapping 会清晰展示每个段包含哪些节。
核心结论:节是链接时的「零件分类」,段是加载时的「搬运单位」。链接器负责把零散的节按权限合并成段,加载器负责把段按页映射到内存。
四、静态库与静态链接全解析
静态链接是最朴素的链接方式:链接时直接把用到的库代码复制进可执行文件,运行时不再依赖库。
4.1 静态库的本质:归档文件
静态库 .a 本质是一个 归档文件(archive) ,相当于把多个 .o 目标文件打包成一个文件,并附带一个符号索引表,方便链接器快速查找符号。
制作静态库完整流程
bash
# 1. 编译生成多个目标文件
gcc -c add.c sub.c mul.c -Wall
# 2. 打包成静态库
ar rcs libmath.a add.o sub.o mul.or:替换库中已存在的目标文件,不存在则添加c:静默创建库,不输出提示s:生成符号索引,等价于单独执行ranlib
查看静态库内容
bash
# 查看包含的目标文件
ar t libmath.a
# 查看符号索引,以及符号属于哪个 .o
nm -s libmath.a
# 提取出其中的 add.o
ar x libmath.a add.o4.2 静态链接的两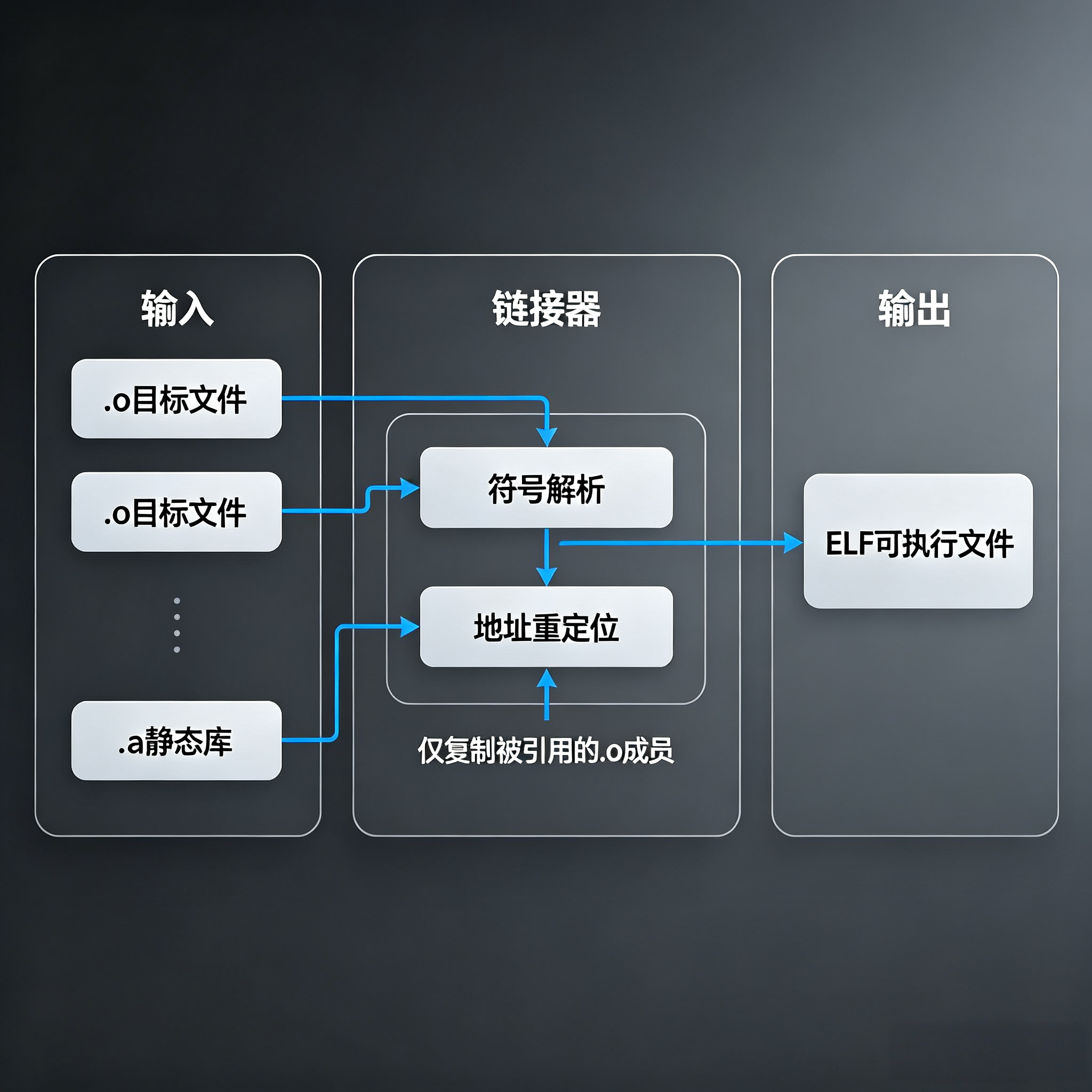
个核心步骤
链接器 ld 处理静态链接时,分为符号解析 和重定位两步,缺一不可。
第一步:符号解析(Symbol Resolution)
- 链接器维护两个集合:「已定义符号集合」「未定义符号集合」
- 从左到右依次处理输入的
.o和.a文件:- 遇到
.o文件:把它所有的符号全部加入已定义集合,同时把它引用的外部符号加入未定义集合 - 遇到
.a静态库:遍历库中的所有.o,如果某个.o定义了当前未定义的符号,就把这个.o整体链接进来,更新两个集合;否则直接跳过这个.o
- 遇到
关键规则:静态库只会提取「能解决当前未定义符号」的目标文件,不会把整个库都链进去。这也是为什么库要放在目标文件后面------如果先处理库,此时还没有未定义符号,所有
.o都会被跳过。
第二步:重定位(Relocation)
所有符号都解析完成后,链接器:
- 给所有
.o分配最终的虚拟地址空间,确定每个函数、变量的绝对地址 - 遍历重定位表,把所有引用符号的地方,修正为最终的虚拟地址
常见重定位类型(x86_64):
R_X86_64_PC32:相对寻址,计算目标地址与当前指令地址的差值,用于函数调用、跳转R_X86_64_64:绝对寻址,直接写入 64 位绝对地址,用于全局变量指针
查看目标文件的重定位表:
bash
readelf -r main.o4.3 静态链接实操与验证
bash
# 链接静态库生成可执行文件
gcc main.c -L. -lmath -o app_static-L.:告诉链接器在当前目录查找库-lmath:链接名为libmath.a的静态库(自动补 lib 前缀和 .a 后缀)
验证代码已嵌入:
bash
# 查看 add 函数的机器码,确认在可执行文件内
objdump -d app_static | grep -A 10 '<add>:'
# 验证无动态依赖
ldd app_static
# 输出:not a dynamic executable 或 只有 linux-vdso.so4.4 多文件使用同一个静态库
当工程有多个源文件时,通常先分别编译成 .o,再统一链接:
bash
# 分别编译
gcc -c main.c helper.c
# 统一链接,库必须放在最后
gcc main.o helper.o -L. -lmath -o app链接顺序易错点 :
如果库 A 依赖库 B,必须把 A 放在 B 前面,比如 main.o -lA -lB。如果循环依赖,可以用分组参数让链接器反复扫描:
bash
gcc main.o -Wl,--start-group -lA -lB -Wl,--end-group -o app4.5 静态库的优缺点
| 优点 | 缺点 |
|---|---|
| 最终可执行文件独立,运行时不需要依赖库 | 可执行文件体积大,多个程序都用同一个库时,磁盘和内存都会重复占用 |
| 运行时没有加载开销,启动速度快 | 库升级必须重新编译所有程序 |
| 不存在版本兼容问题,代码完全确定 | 无法动态替换函数,灵活性差 |
五、动态库基础:制作、链接与使用
动态库不会把代码复制进可执行文件,只在文件里记录依赖关系,程序启动时由动态链接器加载到内存。多个进程可以共享同一份库代码,大幅节省内存和磁盘空间。
5.1 位置无关代码(PIC):动态库的核心
动态库要实现代码共享,前提是代码必须是位置无关代码(Position Independent Code, PIC)------代码加载到任意虚拟地址都能正确运行,不需要修改代码段本身。
为什么非 PIC 代码不能共享?
非 PIC 的代码里包含绝对地址引用,加载时需要重定位修改代码段。一旦修改了代码段,这个页就变成进程私有,无法被其他进程共享,失去了动态库的意义。
PIC 的实现原理
- 全局数据访问 :所有对全局变量的访问,都通过 GOT(全局偏移表) 间接寻址。GOT 放在数据段,每个进程有自己的副本,代码段完全不用修改。
- 外部函数调用 :所有对外部函数的调用,都通过 PLT(过程链接表)+ GOT 间接跳转,代码段保持只读。
- 内部函数调用:使用相对跳转指令,和位置无关,不需要重定位。
编译生成 PIC 代码:
bash
gcc -c -fPIC add.c sub.c mul.c5.2 动态库的三套命名规则与版本管理
Linux 动态库有严格的三级命名,用于版本管理和链接查找,分别是:
- Real Name(真实文件名) :
libmath.so.1.0.0- 完整的版本号,是库的真实文件,主版本号+次版本号+发布号
- SONAME(逻辑库名) :
libmath.so.1- 嵌入在库文件的
.dynamic段中,是程序依赖记录的名字 - 主版本号相同代表接口兼容,主版本号升级代表不兼容
- 嵌入在库文件的
- Linker Name(链接名) :
libmath.so- 编译链接时使用的名字,通常是指向最新版本的软链接
制作带版本号的动态库完整流程
bash
# 1. 编译生成带 soname 的动态库
gcc -shared -fPIC -Wl,-soname,libmath.so.1 -o libmath.so.1.0.0 add.c sub.c mul.c
# 2. 创建 soname 软链接
ln -sf libmath.so.1.0.0 libmath.so.1
# 3. 创建链接名软链接
ln -sf libmath.so.1 libmath.so验证库中的 soname:
bash
readelf -d libmath.so.1.0.0 | grep SONAME5.3 编译时链接动态库
bash
gcc main.c -L. -lmath -o app_dynamic链接器只会做符号检查,确认库中有所需的符号,不会复制任何代码。可执行文件中只会记录依赖的 soname。
查看动态依赖:
bash
# 查看所有依赖的动态库
readelf -d app_dynamic | grep NEEDED
# 查看依赖库是否能找到
ldd app_dynamic5.4 动态库搜索路径全解
动态链接器 ld-linux.so 加载库时,按固定优先级搜索路径,从高到低依次是:
- 可执行文件中的 DT_RPATH:编译时硬编码的路径,优先级最高,已不推荐使用
- LD_LIBRARY_PATH 环境变量:临时指定搜索路径,调试最常用
- 可执行文件中的 DT_RUNPATH:现代版 rpath,只影响直接依赖,不影响递归依赖
- /etc/ld.so.cache 缓存:由 ldconfig 生成的系统级缓存
- 系统默认路径 :
/lib、/usr/lib(64位系统为/lib64、/usr/lib64)
五种配置方式实操
方式A:临时环境变量(调试首选)
bash
# 临时生效,只影响当前终端
export LD_LIBRARY_PATH=/path/to/lib:$LD_LIBRARY_PATH
./app_dynamic方式B:编译时嵌入 rpath/runpath
bash
# 把路径硬编码进可执行文件,运行时不用设环境变量
gcc main.c -L. -lmath -Wl,-rpath,/opt/math/lib -o app_dynamic
# 查看嵌入的 rpath
readelf -d app_dynamic | grep RPATH方式C:系统级永久配置
bash
# 1. 把库路径写入配置文件
sudo echo "/opt/math/lib" > /etc/ld.so.conf.d/math.conf
# 2. 更新缓存
sudo ldconfig
# 3. 直接运行即可找到
./app_dynamic方式D:LD_PRELOAD 强制预加载
优先级最高,会在所有库之前加载,可以覆盖同名函数:
bash
LD_PRELOAD=/path/to/liboverride.so ./app_dynamic方式E:运行时动态加载(dlopen 系列)
不需要编译时链接,程序运行时主动加载库、查找函数:
c
#include <dlfcn.h>
#include <stdio.h>
int main() {
// 打开动态库
void *handle = dlopen("libmath.so.1", RTLD_LAZY);
if (!handle) {
printf("加载失败:%s\n", dlerror());
return 1;
}
// 获取函数地址
int (*add)(int, int) = dlsym(handle, "add");
printf("1+2 = %d\n", add(1, 2));
// 关闭库
dlclose(handle);
return 0;
}编译时需要链接 libdl:
bash
gcc main.c -o app_dl -ldl5.5 动态库的优缺点
| 优点 | 缺点 |
|---|---|
| 多个进程共享代码,节省物理内存 | 启动时有加载和符号解析开销 |
| 可执行文件体积小,节省磁盘空间 | 运行时必须依赖库,部署相对麻烦 |
| 库升级不需要重新编译程序,替换库文件即可 | 存在版本兼容问题,接口变更可能导致程序崩溃 |
| 支持 dlopen 动态加载,插件化开发灵活 | 存在 GOT/PLT 间接跳转的运行时性能损耗 |
六、内核加载器:ELF 加载与进程地址空间构建
当你执行 ./app_dynamic 时,内核通过 execve 系统调用,把磁盘上的 ELF 文件一步步变成内存中运行的进程。
6.1 execve 系统调用完整流程
- 文件校验:读取 ELF 头,检查魔数(7f 45 4c 46)、架构、文件类型,确认是可执行的 ELF 文件
- 清理旧地址空间:释放原进程的所有内存映射,销毁旧的页表,为新程序腾出地址空间
- 映射可执行文件段 :遍历程序头表,对每个
PT_LOAD段调用mmap,映射到指定虚拟地址 - 映射动态链接器 :如果有
PT_INTERP段,读取动态链接器路径(通常是/lib64/ld-linux-x86-64.so.2),把它也映射进地址空间 - 初始化栈:在栈区压入命令行参数、环境变量、辅助向量(auxv,比如程序入口、页大小等)
- 设置入口地址:把 CPU 的程序计数器(PC)设置为动态链接器的入口(动态链接程序)或程序入口(静态链接程序)
- 返回用户态:开始执行代码
6.2 进程地址空间完整布局
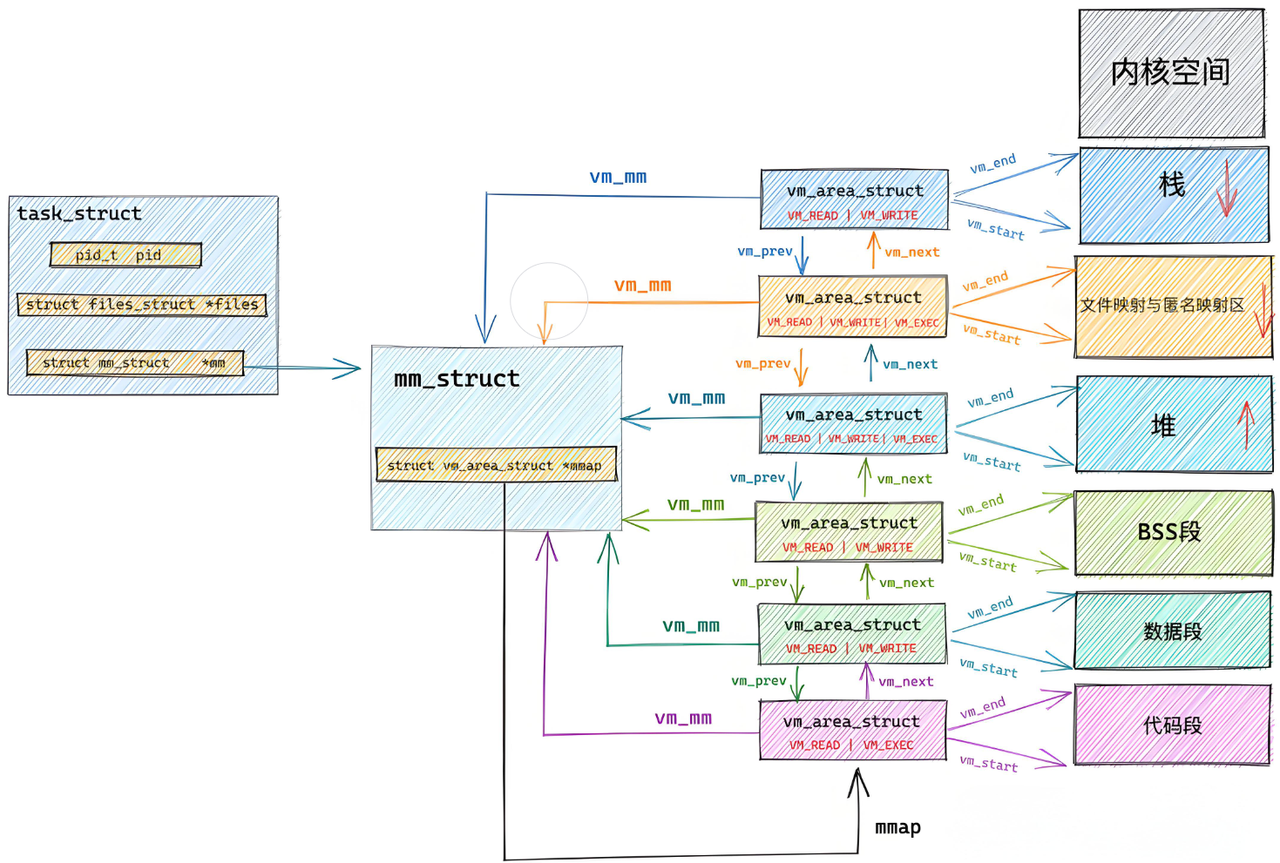
通过 mm_struct 结构体,内核管理着进程的整个虚拟地址空间。64 位系统下从低地址到高地址的典型布局:
| 地址从低到高 | 区域 | 权限 | 说明 |
|---|---|---|---|
| 最低地址 | 代码段(.text) | r-xp | 只读可执行,对应 ELF 第一个 LOAD 段 |
| → | 只读数据段(.rodata) | r--p | 常量字符串、const 变量 |
| → | 数据段(.data) | rw-p | 已初始化全局变量 |
| → | BSS 段(.bss) | rw-p | 未初始化全局变量,加载时清零 |
| → | 堆(Heap) | rw-p | malloc 分配,从低往高增长 |
| 中间区域 | 内存映射区(Mmap) | 不定 | 动态库、mmap 文件映射、共享内存,从高往低增长 |
| → | 栈(Stack) | rw-p | 局部变量、函数调用栈帧,从高往低增长 |
| 最高地址 | 内核空间 | - | 用户态不可访问 |
实时查看进程内存布局:
bash
./app_dynamic &
PID=$!
cat /proc/$PID/maps
kill $PID6.3 mm_struct 核心字段
内核用 struct mm_struct 描述整个地址空间,核心字段:
mmap:所有内存区域的链表/红黑树start_code / end_code:代码段起止start_data / end_data:数据段起止start_brk / brk:堆的起止start_stack:栈的起始地址arg_start / arg_end:命令行参数位置env_start / env_end:环境变量位置
验证部分字段:
bash
cat /proc/self/stat | awk '{print "startcode="$26, "endcode="$27, "startstack="$28}'6.4 页对齐与段间隙
为什么必须页对齐?
内存映射的最小单位是页,权限也是按页设置的。因此 ELF 的每个 PT_LOAD 段,都必须满足:
文件偏移 % 页大小 == 虚拟地址 % 页大小这样才能保证文件内容和内存页精确对齐,mmap 可以直接映射,不需要额外拷贝。
为什么代码段和数据段之间有空隙?
代码段是只读可执行,数据段是可读写,权限不同,必须分到不同的页。因此即使代码段只用了半页,数据段也必须从下一个整页开始,中间会产生内部碎片。
同时,两个段之间通常会有一个无权限的保护页(---p),防止越界访问。
6.5 PIE 与 ASLR
传统可执行文件(EXEC 类型)的加载地址是固定的,容易被漏洞利用。现代 Linux 默认开启:
- PIE(位置无关可执行文件):可执行文件也编译成位置无关代码,和共享库一样从 0 偏移开始
- ASLR(地址空间随机化):内核加载时,给代码段、栈、堆、mmap 区都随机选一个基址,大幅提升攻击难度
关闭 ASLR 观察固定地址:
bash
# 临时关闭 ASLR 运行程序
setarch x86_64 -R ./app_static &
PID=$!
cat /proc/$PID/maps | grep app_static
kill $PID关闭后会看到经典的 0x400000 起始地址。
七、动态链接核心:GOT/PLT 与延迟绑定机制
动态库的函数和全局变量地址,在加载前是未知的。为了不修改代码段、实现代码共享,Linux 设计了 GOT + PLT 的间接寻址机制,并且默认开启延迟绑定优化启动速度。
7.1 两个核心表的分工
| 表名 | 所在段 | 权限 | 作用 |
|---|---|---|---|
| GOT(Global Offset Table) | 数据段 | 可读写 | 存储外部符号的真实地址,分为 .got(全局变量)和 .got.plt(函数) |
| PLT(Procedure Linkage Table) | 代码段 | 只读可执行 | 每个外部函数对应一段桩代码,负责跳转到 GOT 中记录的地址 |
核心设计思想:把所有需要修改的地址都放在数据段的 GOT 里,代码段完全只读,这样代码段就能被多个进程安全共享。
7.2 延迟绑定(Lazy Binding)原理
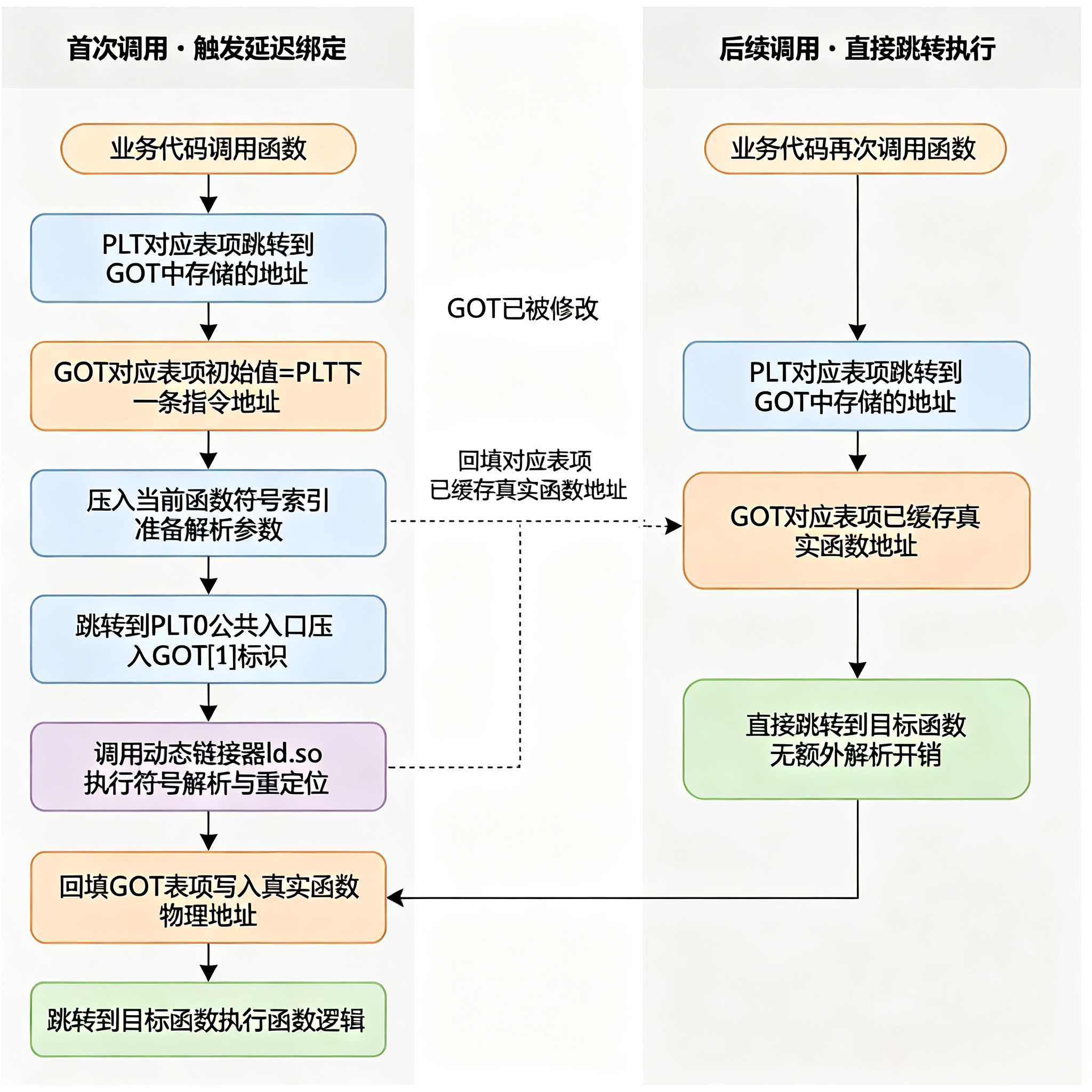
如果程序启动时就把所有外部函数的地址都解析出来,会浪费大量启动时间(一个普通程序依赖几百个函数)。因此默认采用延迟绑定:函数第一次被调用时,才去解析真实地址。
首次调用函数的完整流程
以调用 add 函数为例,编译后会变成 call add@plt,进入 PLT 条目:
- 第一步跳转 :
add@plt第一条指令是jmp *GOT[n]。此时 GOTn 里存的不是函数地址,而是 PLT 中下一条指令的地址,所以会继续往下执行。 - 压入索引 :
push n,把当前函数的符号索引压栈。 - 公共跳转 :跳转到
PLT[0],把模块句柄压栈,然后调用动态链接器的_dl_runtime_resolve函数。 - 解析地址 :
_dl_runtime_resolve根据符号索引,在动态符号表中查找add的真实地址,把地址写入GOT[n]中。 - 执行函数 :解析完成后,直接跳转到
add函数执行。
后续调用函数
再次调用 add@plt 时,jmp *GOT[n] 会直接跳转到 add 的真实地址,不再经过动态链接器,只有一次间接跳转的开销。
7.3 实操验证延迟绑定
bash
# 1. 查看 PLT 条目
objdump -d -j .plt app_dynamic
# 2. 查看待重定位的 GOT 条目
readelf -r app_dynamic | grep JUMP_SLOT用 gdb 观察 GOT 值变化:
bash
gdb ./app_dynamic
(gdb) start # 启动程序,停在 main
(gdb) x/gx 0x404018 # 假设 add 对应的 GOT 地址,调用前指向 PLT 内部
(gdb) next # 执行一次 add 调用
(gdb) x/gx 0x404018 # 调用后,值变成 add 函数的真实地址7.4 关闭延迟绑定
延迟绑定虽然启动快,但运行时第一次调用有额外开销,而且 GOT 可写存在安全风险。可以强制立即绑定:
bash
# 环境变量方式
LD_BIND_NOW=1 ./app_dynamic
# 编译时强制开启
gcc main.c -L. -lmath -Wl,-z,now -o app_now开启后,程序启动时就会解析所有符号,GOT 表项会被标记为只读,防止被篡改(常见的安全加固选项)。
八、多进程内存共享与写时复制
动态库最大的优势就是多进程共享同一份代码,节省物理内存,这个特性完全基于 MMU 的写时复制(COW)机制。
8.1 代码段的共享机制
当多个进程加载同一个动态库时:
- 每个进程的虚拟地址可能不同(ASLR)
- 但内核只会把库的代码段在物理内存中加载唯一一份
- 所有进程的页表都指向同一个物理页框,权限都是只读可执行
这样 100 个进程都用 libc,物理内存里也只存一份 libc 代码,节省大量内存。
8.2 数据段的写时复制
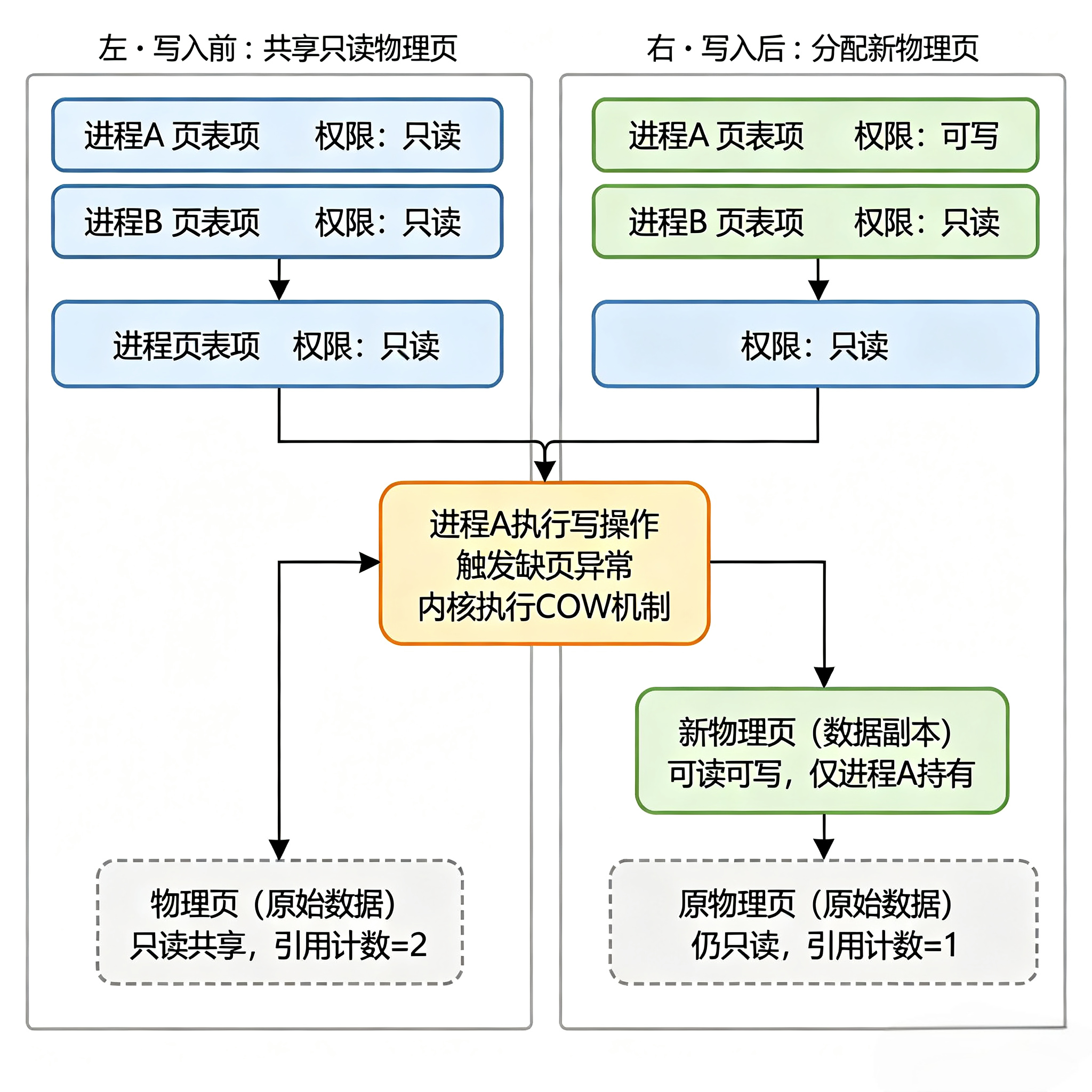
数据段是可读写的,不能直接共享,否则一个进程修改全局变量会影响所有进程。Linux 用写时复制解决:
- 初始状态:所有进程的数据段都映射到同一份物理页,权限标记为「只读 + 私有」
- 进程尝试写入:触发缺页异常,内核介入
- 内核处理:分配一个新的物理页,把原页的数据复制过去,更新当前进程的页表,标记为可写
- 后续:该进程拥有自己的私有数据页,其他进程仍然共享原来的物理页
效果:只要不修改全局变量,数据页也能共享;一旦修改,才会复制一份,最大化节省内存。
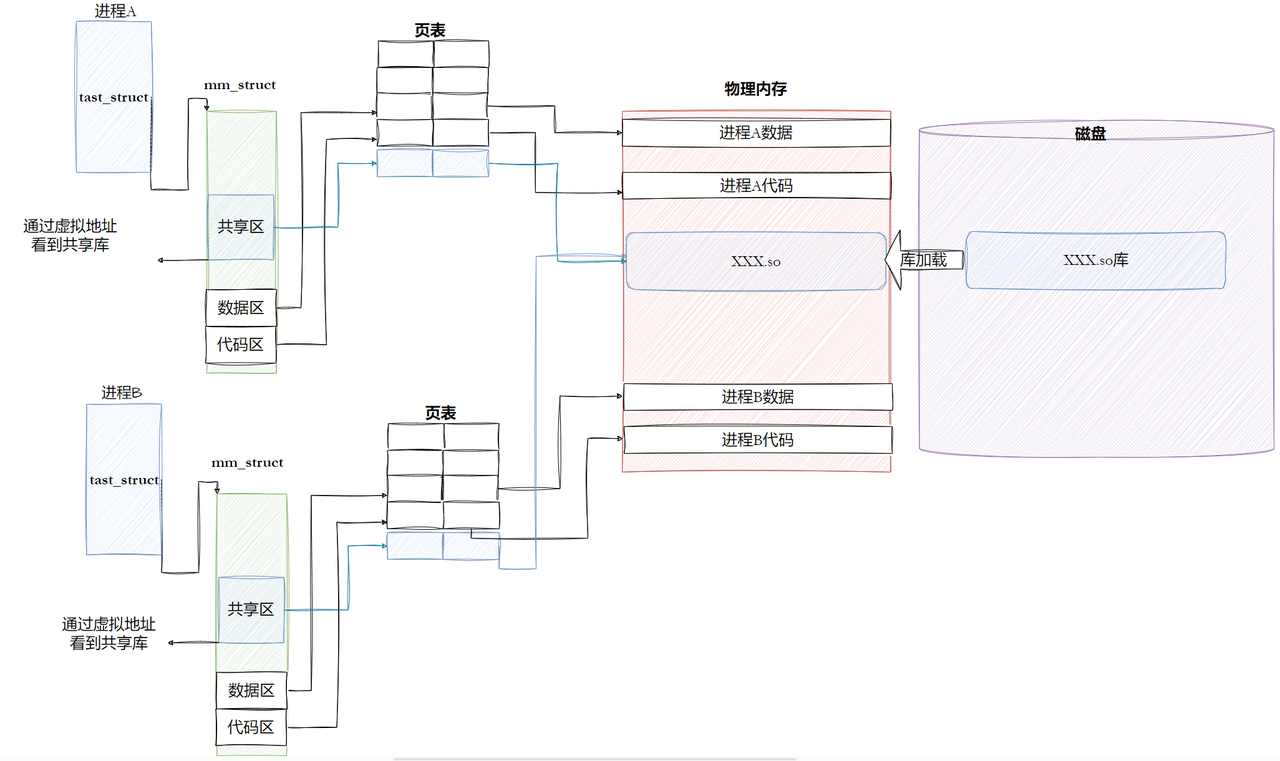
8.3 双进程加载同一份动态库的地址与PIC特性辨析
针对「两份独立程序链接同一个动态库,虚拟地址、物理地址、PIC代码是否相同」的问题,可从三个维度逐一拆解:
8.3.1 虚拟地址:默认不同,关闭ASLR可相同
虚拟地址是否一致,完全取决于地址空间随机化(ASLR)是否开启:
- 开启 ASLR(系统默认) :
内核加载每个进程时,都会给 mmap 区域(动态库加载区)生成一个随机的加载基址load_bias。同一份动态库在两个独立进程中的起始虚拟地址完全不同,对应到每个函数、每个变量的虚拟地址也都不一样。 - 关闭 ASLR 时 (通过
setarch x86_64 -R关闭):
动态库会加载到固定的虚拟基址,两个进程中同一份库的虚拟地址可以完全一致。
补充:即使关闭 ASLR,两个独立可执行文件本身的代码段地址相同,但动态库的加载地址只和库自身的加载顺序、系统布局有关,和可执行文件无关。
8.3.2 物理地址:代码段完全相同,数据段写前相同、写后不同
物理地址是否共享,要区分代码段和数据段分别讨论:
-
代码段(r-xp 只读可执行):物理地址完全相同
内核采用「页缓存共享」机制:同一份动态库文件的只读代码段,在整个系统物理内存中只会加载唯一一份。所有加载该库的进程,页表都会映射到同一个物理页框,这是动态库节省内存的核心机制。
无论虚拟地址怎么随机化,底层的物理页都是同一份,由操作系统的页缓存统一管理。
-
数据段(rw-p 可读写):初始物理地址相同,写入后不同
初始加载完成、尚未修改任何全局变量时,两个进程的数据段也共享同一份物理页,权限被标记为「只读 + 私有映射」,和代码段一样共享物理内存。
当任意一个进程修改了库中的全局变量/静态变量,会触发写时复制缺页异常:内核为该进程分配新的物理页、拷贝原数据、更新页表。此时两个进程的数据段物理地址不再相同,各自拥有私有副本。
8.3.3 PIC:代码本身完全相同,是编译期固定属性
PIC(位置无关代码)是动态库编译阶段就确定的代码属性,和加载的进程、加载的地址完全无关:
- 动态库的
.text代码段,在编译时就生成了符合 PIC 规范的机器码:内部跳转全部使用相对寻址,外部全局数据/函数全部通过 GOT 间接访问,代码本身不包含任何绝对地址。 - 两个进程加载的是同一份物理代码页,因此 PIC 代码的指令内容、执行逻辑完全一致。
- 差异只存在于数据段的 GOT 表中:因为加载基址不同,GOT 里填充的最终绝对地址不同,但代码段的跳转逻辑完全不变。
总结:PIC 是代码的编译属性,库本身只有一份 PIC 代码,所有进程共享使用;虚拟地址是进程维度的映射,默认随机不相同;物理地址是系统维度的资源,只读段全局共享,可写段写时复制。
简易验证命令
bash
# 启动两个相同程序
./app_dynamic & PID1=$!
./app_dynamic & PID2=$!
# 对比同一份动态库的虚拟地址
echo "进程1 动态库虚拟起始地址:"
cat /proc/$PID1/maps | grep libmath | head -1
echo "进程2 动态库虚拟起始地址:"
cat /proc/$PID2/maps | grep libmath | head -1
kill $PID1 $PID2输出会看到两个进程的虚拟起始地址不同,但底层代码段物理页是同一份(需通过 pagemap 工具解析物理页框号 PFN 验证)。
8.4 和 fork() 的 COW 对比
fork() 创建子进程时,并不会复制所有内存,而是让父子进程共享所有物理页,全部标记为只读 COW。只有当任意一方写入时,才会复制对应页。
- 动态库的 COW:针对动态库的数据段,多个独立进程之间共享
- fork 的 COW:针对整个进程地址空间,父子进程之间共享
- 底层原理完全一致,都是 MMU + 缺页异常 + 页复制
九、链接进阶:符号规则、依赖顺序与冲突处理
9.1 强符号与弱符号
链接器处理多重符号定义时,遵循强符号弱符号规则:
- 强符号:函数、已初始化的全局变量
- 弱符号 :未初始化的全局变量;用
__attribute__((weak))标记的函数/变量
链接规则:
- 强符号在整个程序中只能有一个定义,否则报「多重定义」错误
- 如果有一个强符号和多个弱符号,选择强符号的定义
- 如果全是弱符号,选择占用空间最大的那个定义
弱符号示例:
c
// 弱函数,库中提供默认实现,用户可以覆盖
__attribute__((weak)) void callback() {
printf("默认回调\n");
}如果用户定义了同名的强函数,就会自动覆盖弱符号。
9.2 链接顺序的底层原理
为什么库必须放在目标文件后面?
链接器是单遍扫描的,从左到右处理文件,维护「已定义符号」和「未定义符号」两个集合:
- 先处理
.o:把所有符号加入集合,产生一堆未定义符号 - 后处理
.a:只提取能解决未定义符号的.o
如果反过来,先处理库,此时还没有未定义符号,库中所有.o都会被跳过,后面.o产生的未定义符号就无法被解决,最终报undefined reference。
9.3 符号冲突与覆盖
- 链接时冲突:多个库有同名强符号,先出现的会被选中,后面的会被忽略
- 运行时冲突:动态链接遵循「全局符号介入」规则,先加载的库中的符号会覆盖后加载的同名符号
- LD_PRELOAD 原理:在所有库之前加载,因此里面的同名符号优先级最高,可以替换系统库函数,常用于内存检测、功能劫持
9.4 动态库符号可见性
默认情况下动态库的所有全局符号都是导出的,可以通过隐藏符号减少动态符号表大小、提升加载速度:
c
// 显式导出
__attribute__((visibility("default"))) int add(int a, int b);
// 隐藏,外部不可见
__attribute__((visibility("hidden"))) void internal_func();编译时也可以全局设置隐藏:
bash
gcc -shared -fPIC -fvisibility=hidden add.c -o libmath.so十、全套诊断工具与常见错误排错指南
10.1 诊断工具速查表
| 目的 | 命令 |
|---|---|
| 查看 ELF 文件头、类型 | readelf -h <file> |
| 查看所有节区信息 | readelf -S <file> |
| 查看程序头与段映射 | readelf -l <file> |
| 查看动态段、依赖库、soname | readelf -d <file> |
| 查看重定位表 | readelf -r <file> |
| 查看符号表 | nm <file>;动态符号用 nm -D <file> |
| 反汇编代码段 | objdump -d <file> |
| 查看动态依赖与查找状态 | ldd <file> |
| 跟踪系统调用与文件打开 | strace -e openat,mmap ./app |
| 查看进程内存映射 | cat /proc/<pid>/maps |
| 查看库符号导出 | objdump -T <so文件> |
| 强制预加载库 | LD_PRELOAD=<库路径> |
| 临时添加库搜索路径 | LD_LIBRARY_PATH=<路径> |
10.2 常见错误排查
错误1:undefined reference to xxx
原因 :链接时找不到符号的定义
排查步骤:
- 检查库/目标文件是否放在了源文件后面,链接顺序是否正确
- 检查函数是否真的在库中:
nm -D libxxx.so | grep 函数名 - C++ 检查是否有名字修饰(name mangling),是否漏加
extern "C" - 检查符号是否被隐藏,是否有可见性限制
错误2:cannot find -lxxx
原因 :链接时找不到库文件
排查步骤:
- 检查库名是否正确:
-lmath对应libmath.so或libmath.a - 检查库路径是否通过
-L指定 - 检查软链接是否存在,是否指向正确版本
错误3:error while loading shared libraries: libxxx.so
原因 :运行时动态链接器找不到库
排查步骤:
- 用
ldd 程序名查看哪个库没找到,显示not found - 临时用
LD_LIBRARY_PATH测试是否能运行 - 永久解决:配置 ldconfig、或者编译时加 rpath
十一、全文总结
Linux 下的编译链接与动态库,是一套从硬件到操作系统层层配合的精密设计:
- 硬件层:MMU 与分页机制提供了虚拟地址、权限控制、写时复制的能力,是所有内存管理的基础
- 文件格式层:ELF 用双视图设计,同时满足链接和加载两种需求
- 静态链接:复制代码,独立运行,适合小工具、无依赖场景
- 动态链接:PIC 代码 + GOT/PLT 间接寻址,实现代码共享、按需加载
- 内核加载层:通过 mmap 把 ELF 段映射到虚拟地址,构建完整进程地址空间
- 运行时层:延迟绑定平衡启动速度与运行性能,写时复制最大化内存利用率
理解了这条完整链路,所有编译、链接、运行时的错误都能快速定位到具体层级,从「靠经验试错」变成「按原理排查」,真正做到游刃有余。