资源和代码优化
本小节主要在Flink资源设置和代码层面来讲解Flink相关优化。在实际工作中可根据实际业务场景参考调整。
Slot资源配置
Flink中有TaskSlot概念,每个taskSlot都有固定的资源,假设一个TaskManager有三个TaskSlots,那么每个TaskSlot会将TaskMananger中的内存均分,即每个任务槽的内存是总内存的1/3,分配资源意味着subtask不会与其他作业的subtask竞争内存,taskslot的作用就是分离任务的托管内存,不会发生cpu隔离。
用户无论是基于Standalone或者Yarn提交Flink任务时,都可以通过配置$FLINK_HOME/conf/flink-conf.yaml文件中的"taskmanager.numberOfTaskSlots"参数来指定每个JobManager启动后拥有几个taskslot。一个TaskManger可以配置成单Slot模式,这样这个JobManager上运行的任务就独占了整个JVM进程;一个TaskManager配置更多的taskSlot意味着更多的subtask可以共享同一个JVM,同一个JVM中的task共享TCP连接和心跳信息,但也意味着越多的taskslot争夺CPU资源。
关于每个TaskManager配置Slot个数的建议如下:
-
基于Standalone集群运行Flink任务时,建议每个TaskManager配置的slot个数与该节点Cpu core保持一致,这样能保证每个subtask尽量使用一个core来处理数据。
-
基于Yarn集群提交Flink任务时,会动态的申请TaskManager,每个TaskManager中的slot个数也是由参数taskmanager.numberOfTaskSlots决定,该参数默认为1。如果调整该值可以小于等于Yarn中单个Container最大可以申请的cpu核数(由参数yarn.scheduler.maximum-allocation-vcores决定,默认值为4),具体情况还需要结合每个subtask使用的内存决定该值设置多少,如果设置过大,可能每个subtask对应的内存会过小。
指定合适并行度
Flink中可以为每个算子设置不同并行度以应对不同业务处理逻辑达到数据处理最优化。设置高并行度往往会Flink数据处理的效率,但并行度也不是越大越好,太多并行度也会加重数据在多个Solt/TaskManaer之间数据传输压力,包括序列化和反序列化带来的压力,所以Flink任务设置合适的并行度很有必要。
确定任务合适并行度可以从如下几点考虑:
-
数据源并行度:如果Flink读取Source数据支持多并行度读取,那么可以设置并行度与Source数据源一致。例如Flink读取Kafka中数据,最好设置开始并行度与读取的Kafka Topic的分区数一致,每个分区都可以被一个task独立读取。如果后续数据处理数据的速度跟不上,也可以设置一个task读取topic多个分区数据,但数据源的并行度应该等于或大于Flink读取souce的并行度,不能出现Flink读取Source并行度大于Source源并行度,否则会出现一些并行度使用不上,浪费资源。
-
算子逻辑的复杂度:算子逻辑越复杂,相应的并行度就需要更高才能提供足够的吞吐量。
-
数据Sink并行度:Flink写出数据时,如果写出端支持多并行写出的数量固定,可以设置写出并行度与接收数据端并行保持一致。例如,Flink写出数据到Kafka,可以设置并行度为Kafka topic的分区数。如果写出支持并行,但没有固定数量,需要结合写出端承受数据写出压力来确定合适并行度。
-
系统资源可用性:一个Flink Application的并行度通常认为是所有算子中最大的并行度,在确定算子并行度时,应该考虑系统可用的资源,如果系统的CPU和内存资源有限,那么高并行度可能会导致任务竞争和低性能。
-
数据倾斜:数据倾斜是指数据分布不均衡,这可能会导致某些算子的并行度成为瓶领,在这种情况下,可以通过调整算子的并行度来解决数据倾斜的问题。
-
多次调整:最终的并行度设置往往需要通过多次调节来确定,每次调节后可以通过观察作业执行性能来一步步迭代调节确定并行度。
Flink中并行度可以从以下四个层面指定:
1) Operator Level (算子层面)
算子层面设置并行度是给每个算子设置并行度,直接在算子后面调用.setparallelism()方法,写入并行度即可,只是针对当前算子有效,注意一些算子不能设置并行度,例如:keyBy 返回的对象是KeyedStream,这种分组操作无法设置并行度,socketTextStream是非并行source,只支持1个并行度,也不能设置并行度。
#算子层面设置并行度
ds.flatMap(line=>{line.split(" ")}).setParallelism(2)2) Execution Environment Level(执行环境层面)
执行环境层面设置并行度直接调用env.setParallelism()写入并行度即可,全局代码有效。
#执行环境层面设置并行度
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)3) Client Level(客户端层面)
以上无论是算子层面还是执行环境层面设置并行度都会导致硬编码问题,修改并行度时不灵活,我们也可以在客户端提交Flink任务时通过指定命令参数-p来动态设置并行度,并行度作用于全局代码。
#提交任务时通过 -p 参数指定并行度
./flink run -m node1:8081 -p 4 -c com.wubaibao.flinkjava.code.chapter4.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 如果是基于WebUI提交任务,我们也可以基于WebUI指定并行度:
4) System Level(系统层面)
我们也可以直接在提交Flink任务的节点配置$FLINK_HOME/conf/flink-conf.yaml文件配置并行度,这个设置对于在客户端提交的所有任务有效,默认值为1。
#配置flink-conf.yaml文件
parallelism.default: 5以上四种不同方式指定Flink并行度的优先级为:Operator Level>Execution Environment Level>Client Level>System Level,本地编写代码时如果没有指定并行度,默认的并行度是当前机器的cpu core数。
设置SlotSharingGroup共享组
默认情况下,Flink 允许 subtask 共享 taskSlot,即便它们是不同的 subtask,只要是来自于同一Flink作业即可(Flink不允许属于不同作业的task共享同一个slot),结果就是一个 slot 可以持有整个作业管道。
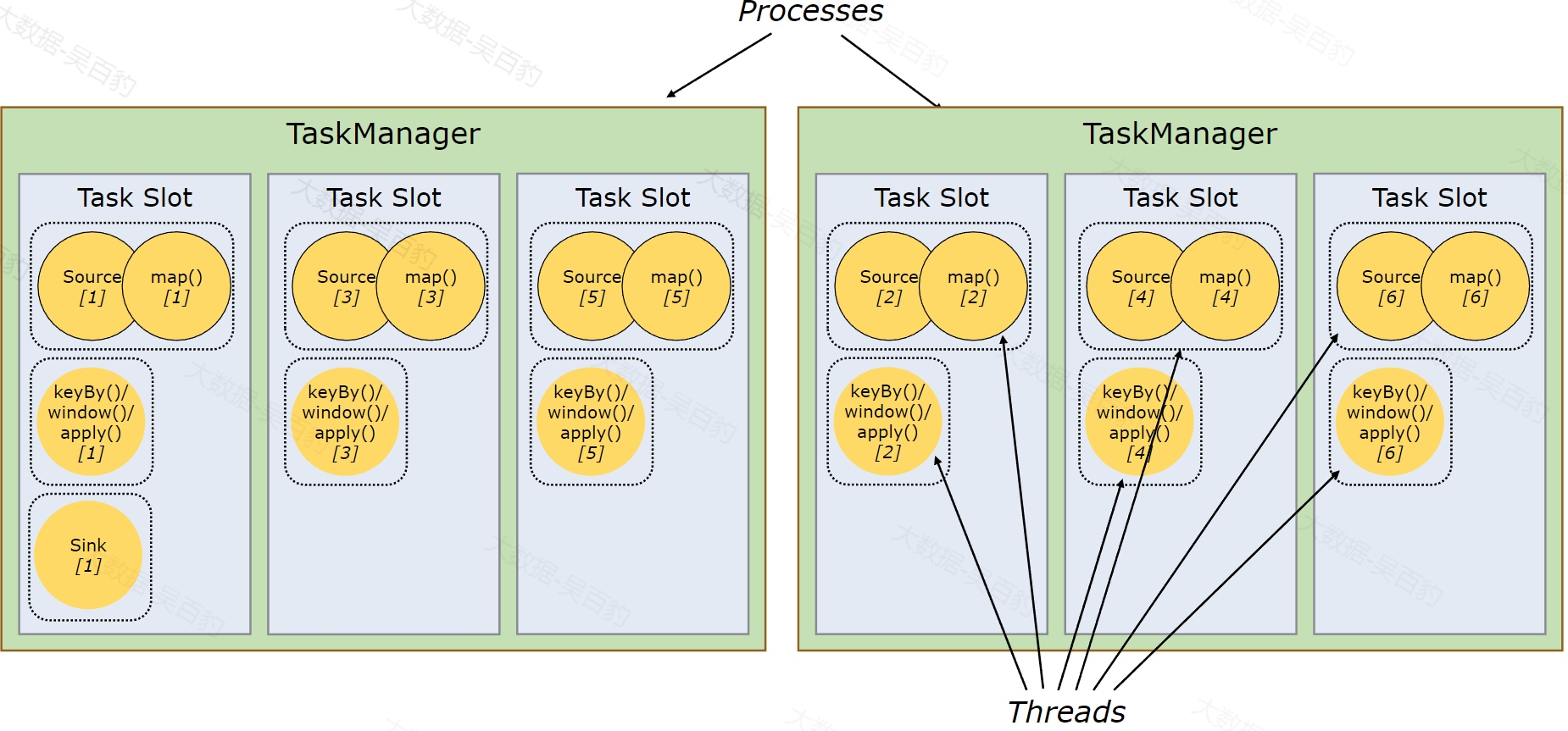
Flink中一个taskslot中可以运行多个subtask有什么好处呢?假设一个taskslot中只能运行一个subtask,上图中一共有13个subtask,对应的就需要13个slot资源,我们在提交Flink应用程序时需要关注我们程序中到底有多少subtask,然后再衡量Flink集群中slot个数是否足够,在一定程序上需要的slot资源较多。另外一个方面是在Flink中运行的task对CPU资源的占用不同,有CUP密集型task操作和CPU非密集型task操作情况,例如在Flink集群中source和map的操作只是读取数据进行转换,对应task运行占用的cpu资源极短,但是Window这种窗口聚合操作涉及大量数据计算,往往占用CPU资源时间长,这就会导致在运行任务时source/map、sink操作时间非常快,Window操作时间非常长,source/map对应的subtask会等待window对应的subtask执行,同样sink的对应的subtask也会等待window对应的subtask执行,站在集群slot角度上来看就出现了一些taskslot非常"繁忙",一些taskslot非常"轻松",集群的资源综合利用不高。
taskslot共享就可以很好地解决以上问题,Flink任务所有的subtask均衡的分散到不同的taskslot上执行,一个taskslot贯穿执行整个流程的subtask,这样每个taskslot、每个TaskManager上的资源使用情况非常均衡。所以允许 slot 共享有两个主要优点:
-
Flink 集群所需的 taskSlot 和作业中使用的最大并行度恰好一样,不需要关注Flink程序总共包含多少个 subtask。
-
容易获得更好的资源利用。如果没有 slot 共享,非密集 subtask(source/map())将阻塞和密集型 subtask(window())一样多的资源。通过 slot 共享,确保繁重的 subtask 在 TaskManager 之间公平分配。
在Flink中实现taskslot共享是通过SlotSharingGroup(Slot共享组,简称SSG)实现的,默认在Flink中有名称为"default"的默认SSG,所有算子操作都在当前这个SSG中,所以我们在执行Flink代码时会自动进行slot组共享。我们也可以在代码中手动指定某些算子操作的SSG组做到某些操作独占一个slot,指定方式如下:
#手动指定slotSharingGroup
someStream.filter(...).slotSharingGroup("name");不显式指定SSG时所有算子操作使用的是default slot group 。显式指定后对应的算子操作使用的指定的slot group,只有指定同一个共享组的算子操作才会开启slot共享,不同slot group 的算子操作是分配到不同的slot上执行的,如果一个Flink 任务有多个共享组,那么该Flink任务所需的总slot个数就是每个共享组最大并行度的总和。
使用细粒度资源管理
在Flink架构中,TaskManager中会划分多个Slot资源,Slot是Flink运行时进行资源调度和资源分配的基本单元。
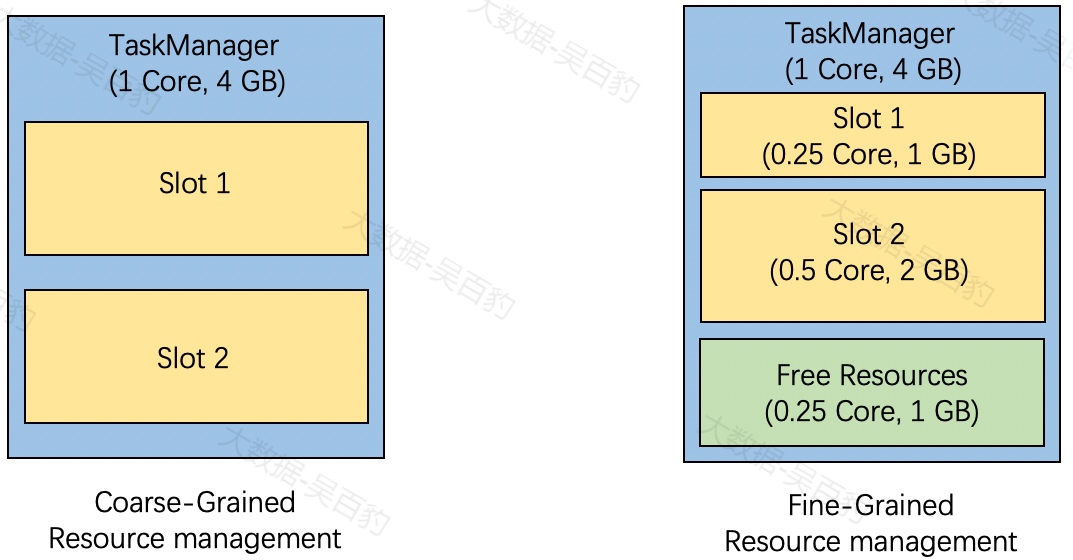
之前的Flink版本中,资源请求只包含所需的Slot,TaskManager有固定数量且资源相同Slot来满足用户资源请求,相当于是粗粒度的资源管理,现在Flink支持细粒度的资源管理,通过细粒度的资源管理,用户可以指定资源配置来对Slot进行请求,Flink根据用户的资源配置从TaskManager中动态剪切一个完全匹配的Slot,如上图所示,需要一个具有0.25 Core和1GB内存的Slot,Flink为其分配Slot 1。
注意:对于用户没有指定资源配置的资源请求,Flink会自动决定资源配置,目前默认的资源配置是根据TaskManager总资源和TaskManager.numberOfTaskSlots计算的,相当于是粗粒度资源管理。如上图所示,TaskManager的总资源为1Core和4G内存,当前TaskManager的Slot数量设置为2,那么每个Slot将会有0.5个core和2G内存。
在上图右侧图中是细粒度资源配置,TaskManager分配Slot 1和Slot 2后,TaskManager中剩余的可用内存为0.25 Core和1G内存,这些空闲资源可以进一步划分,以满足其他资源需求。
在Flink1.14版本中提出的细粒度资源调度是基于SlotSharingGroup的资源配置接口来实现,可以为任务中的每个SSG指定不同的资源可以最大化资源资源利用效率。
要使用细粒度资源管理,需要做以下操作:
1) 配置启用细粒度资源管理
在flink-conf.yaml配置文件中配置 cluster.fine-grained-resource-management.enabled为true,早期Flink版本中没有此配置,如果配置上会有异常报错。
2) 代码中指定资源需求
在代码中通过创建Slot Sharing Groups(Slot共享组)定义了细粒度的资源需求。在Flink内部SlotSharingGroup会告诉JobManager 哪些operator/tasks可以放在同一个Slot中。关于在代码中定义SlotSharingGroup和哪些算子使用对应的SSG,有以下两种方式:
- 构建SlotSharingGroup对象实例并指定资源,通过slotSharingGroup(String name)方式附加到算子上。
这种方式在创建SlotSharingGroup时指定共享组所需的资源,然后给算子通过slotSharingGroup(String name)方式来设置Slot共享组的名称,但是最后需要通过StreamExecutionEnvironment.registerSlotSharingGroup(SlotSharingGroup ssg) 注册这些SSG对象。
//创建SSG共享组对象指定资源配置
SlotSharingGroup ssgA = SlotSharingGroup.newBuilder("a")
.setCpuCores(1.0)
.setTaskHeapMemoryMB(10)
.build();
//指定构建SSG共享组对象的字符串名称“a” ,使用当前SSG共享组资源,后续需要注册
someStream.filter(...).slotSharingGroup("a")
//通过env注册名称为“a”的SSG共享组对象
env.registerSlotSharingGroup(ssgA); - 构建SlotSharingGroup对象实例并指定资源,通过slotshareinggroup (SlotSharingGroup ssg)附加到算子上。
同样,这种方式也是在创建SlotSharingGroup对象时指定SSG共享组的资源情况,给算子指定SSG共享组时直接通过slotshareinggroup (SlotSharingGroup ssg)即可。
//创建SSG共享组对象指定资源配置
SlotSharingGroup ssgB = SlotSharingGroup.newBuilder("b")
.setCpuCores(0.5)
.setTaskHeapMemoryMB(10)
.build();
//直接指定SSG共享组对象名称来使用SSG共享组资源
DataStream<...> ds1 = someStream.filter(...).slotSharingGroup(ssgB)注意:无论以上使用那种方式指定SSG共享组资源,每个SSG共享组只能附加到一个指定的资源,任何冲突都将导致作业编译失败。此外在构造SlotSharingGroup (Slot共享组)实例时,可以为Slot共享组设置以下资源信息:
| 资源 | 解释 |
|---|---|
| CPU cores | 必须项,定义需要多少个CPU 内核,需要显式配置正值。 |
| Task Heap Memory | 必须项,定义需要多少task堆内存,需要显式配置正值。 |
| Task Off-Heap Memory | 定义需要多少task堆外内存,可以是 0。 |
| Managed Memmory | 定义需要多少任务托管内存,可以是0。 |
| External Resources | 定义所需的外部资源,可以是空的。 |
Flink使用异步IO
Flink的异步I/O是一个非常受欢迎的特性,由阿里巴巴贡献给社区,并在1.2版本中引入,它的主要目的是解决与外部系统交互时网络延迟成为系统瓶颈的问题,外部系统往往是外部数据库。
在Flink流计算系统中,与外部数据库进行交互是常见的需求,通常情况下,我们会发送一个查询请求到数据库并等待结果返回,这期间无法发送其他请求,这种同步访问方式会导致阻塞,阻碍了吞吐量和延迟,为了解决这个问题,引入了异步模式,能够并发地处理多个到外部数据库的请求,下图为官方提供的异步IO原理图。
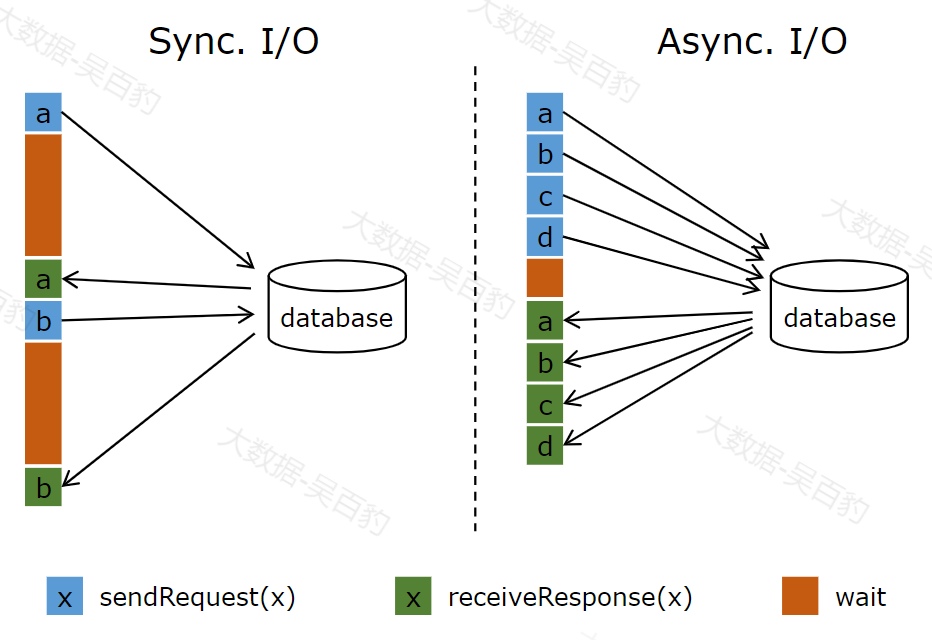
在Flink中使用异步I/O,我们可以连续发送多个查询请求到数据库,并在回复返回时处理每个回复,而不需要阻塞等待,这种并发处理的方式极大地减少了延迟。
异步I/O专门用于解决Flink计算过程中与外部系统的交互问题,特别需要注意的是为了提高Flink与外部系统交互能力,也可以提高Flink的并行度进而提高Flink处理数据的吞吐量,这种方式会付出更高的资源成本,如:更多的task、更多的内存缓存、更高的网络连接,而异步IO方式相对这种方式是基于某一个task之上的扩展,重复利用一个task资源做更多的事情,提高了Flink性能和资源利用率。
在Flink中查询外界数据库数据时要使用异步IO需要满足如下条件之一:
-
数据库(或K/V存储系统)提供支持异步请求的客户端,例如Java的Vertx。
-
对于不支持异步请求客户端的外部系统可以使用线程池模拟异步客户端。
大状态中设置TTL
Flink程序运行时随着时间推移,Flink状态大小也会持续增长,默认状态存储在内存中,时间久了就会给内存带来很大压力,我们可以调用.clear()方法直接清除状态,如果业务逻辑不允许使用clear()方法直接清除状态,我们可以通过配置状态的"生存时间"(Time-to-Live,TTL)来限制状态在内存中存在的时间,当状态存在的时间超过设置的TTL时,系统将自动尽快清除该状态,避免状态一直占用内存空间。
在代码中给键控状态设置TTL和应用TTL方式如下:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);以上设置TTL的方法解释如下:
- newBuilder(...)方法
该方法必须指定,需要传入一个时间,通过该方法来指定TTL状态生存时间。生存时间TTL计时是以Flink系统处理时间为基础,不支持事件事件。
- setUpdateType(...)方法
该方法可选,通过该方法来设置何时更新状态失效时间。默认值为StateTtlConfig.UpdateType.OnCreateAndWrite,表示仅在创建和写入状态时更新TTL。还可以设置为StateTtlConfig.UpdateType.OnReadAndWrite,表示所有读与写状态时更新TTL,这种方式只要对状态在TTL时间内进行读取,那么该状态生存时间就会一直更新延后。
- setStateVisibility(...)方法
该方法可选,该方法设置状态的可见性。默认值为StateTtlConfig.StateVisibility.NeverReturnExpired,表示状态数据过期就不会返回。还可以设置为StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp,表示状态数据即使过期,只要Flink还没有清除该状态就返回。
下面以ValueState为例来测试状态生存时间TTL。
需求:读取Socket中基站通话数据,统计每个主叫通话总时长。
Java代码实现
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/**
* Socket中数据如下:
* 001,186,187,busy,1000,10
* 002,187,186,fail,2000,20
*/
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//对ds进行转换处理,得到StationLog对象
SingleOutputStreamOperator<StationLog> stationLogDS = ds.map(new MapFunction<String, StationLog>() {
@Override
public StationLog map(String line) throws Exception {
String[] arr = line.split(",");
return new StationLog(
arr[0].trim(),
arr[1].trim(),
arr[2].trim(),
arr[3].trim(),
Long.valueOf(arr[4]),
Long.valueOf(arr[5])
);
}
});
stationLogDS.keyBy(stationLog -> stationLog.callOut)
.map(new RichMapFunction<StationLog, String>() {
//定义ValueState 用来存放同一个主叫号码的通话总时长
private ValueState<Long> valueState;
@Override
public void open(Configuration parameters) throws Exception {
//定义状态TTL
StateTtlConfig ttlConfig = StateTtlConfig
//设置状态有效期为10秒
.newBuilder(org.apache.flink.api.common.time.Time.seconds(10))
//设置状态更新类型为OnCreateAndWrite,即状态TTL创建和写入时更新
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//设置状态可见性为NeverReturnExpired,即状态过期后不返回
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
//定义状态描述器
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>("value-state", Long.class);
//设置状态TTL
descriptor.enableTimeToLive(ttlConfig);
//获取状态
valueState = getRuntimeContext().getState(descriptor);
}
@Override
public String map(StationLog stationLog) throws Exception {
Long stateValue = valueState.value();
if(stateValue==null){
//如果状态值为null,说明是第一次使用,直接更新状态值
valueState.update(stationLog.duration);
}else{
//如果状态值不为null,说明不是第一次使用,需要累加通话时长
valueState.update(stateValue+stationLog.duration);
}
return stationLog.callOut+"通话总时长:"+valueState.value()+"秒";
}
}).print();
env.execute();设置barrier对齐和非对齐
当Flink应用程序有多个并行度或者Flink上下游算子并行度不一致时,barrier上下游传递时涉及到barrier广播和barrier对齐机制。当上游数据向下游多个并行度中发送barrier时,需要对barrier进行广播,保证下游各个并行度barrier一致;当上游多个并行度向下游少量并行度传递barrier时,需要对brrier进行对齐,对齐是指下游每个并行度都要等到相同的barrier到达时才能进行 snapshot 快照状态的保存。
下图是Flink中barrier对齐机制的示意图:
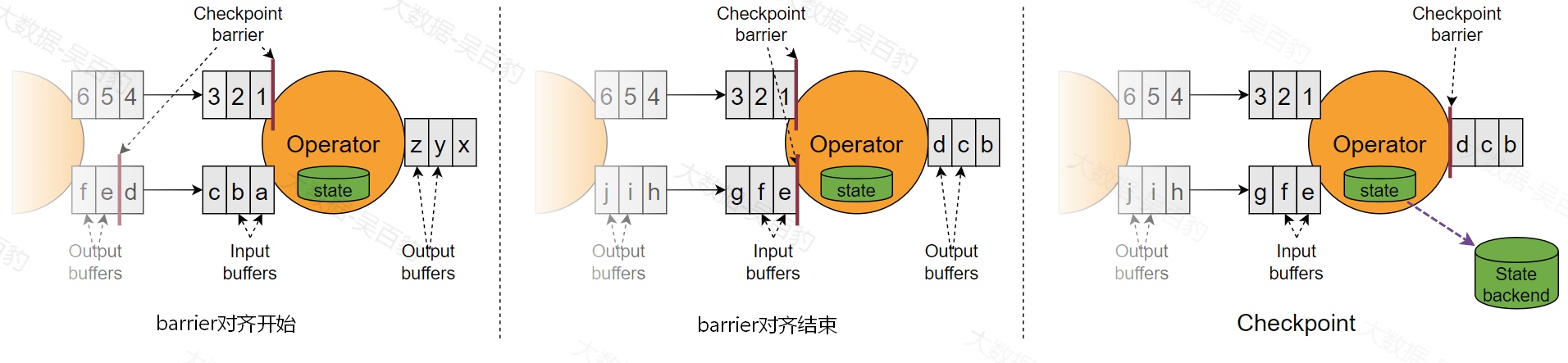
在barrier对齐机制中,下游barrier先到达分区会等待barrier未到达的分区以达到barrier对齐目的,这个对齐过程中就会涉及barrier先到达分区中数据的缓存,如果多个并行度中处理数据的速度不一致会导致下游任务堆积大量缓存数据,可能会造成Flink内存和磁盘负载压力,同时也使Flink 整体Checkpoint的时间延后变长,此外,在Flink中当数据流处理不过来时还会有反压机制(反压机制是指控制数据源的产生速度,避免数据积压),反压机制会限制数据流的流动,导致barrier在一些并行度中流速变慢,这样更近一步导致Checkpoint的时间延后的更长,导致恶性循环。
为了解决以上barrier对齐机制可能带来的问题,在Flink1.11后引入了barrier不对齐机制。下图是barrier不对齐机制的示意图:
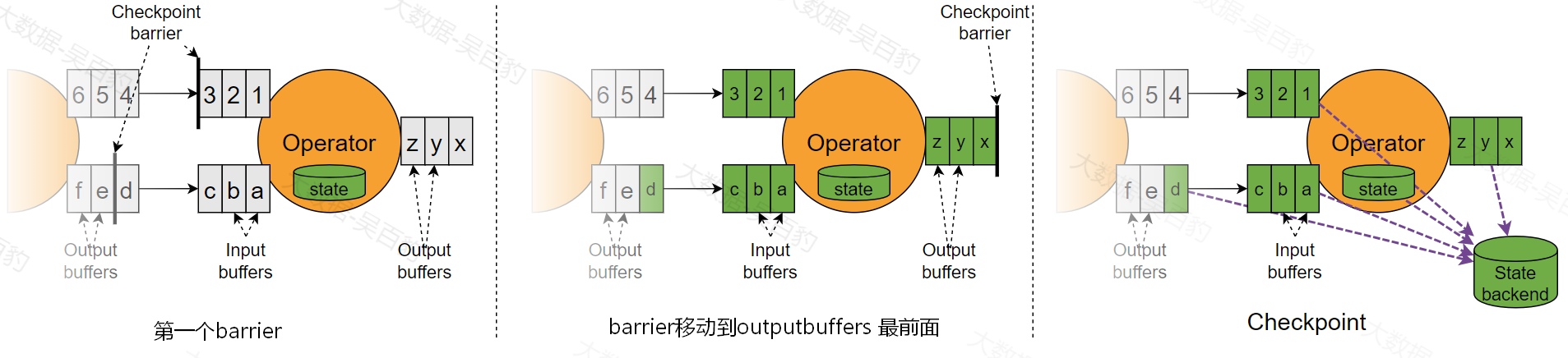
当流速快的barrier到达下游算子的input buffer后,Flink会将该barrier插入到该下游算子的output buffer的最前面,并将该barrier发送给后续的算子。同时当前算子会对自身进行checkpoint快照,包括当前的状态以及所有input buffers、output buffers以及流速慢的barrier之前的数据都会保存到状态后端中(注意:在进行checkpoint快照时,流速慢的barrier会被移除,并不会继续流动下去 ),这样当Flink应用程序异常中断恢复到此次checkpoint时,未计算之前的状态、barrier不对齐对应的input buffers、output buffers 数据会重新恢复到各个流中并保证数据的一致性和准确。值得注意的是barrier不对齐机制中需要向状态中保持更多的数据。
通过上文对Flink barrier对齐和不对齐机制的了解,我们发现两者各有优缺点:
- barrier对齐机制
优点:状态后端需要保存的数据少。
缺点:缓存堆积数据、Flink内存和磁盘负载有压力、checkpoint时间延长。
- barrier不对齐机制
优点:多并行度中只要有一个并行度中barrier到达,就会触发checkpoint,加快checkpoint进行,不容易出现数据反压问题。
缺点:状态后端保存数据多,状态恢复时比较慢。
在Flink中对于简单数据处理作业建议使用轻量级的barrier对齐机制,对于一些计算复杂导致任务出现数据高反压、checkpoint超时难以完成的的作业场景建议使用barrier不对齐机制,这样可以加快checkpoint进行、有效缓解数据高反压带来的一系列连锁问题。
代码中设置uid
为了能够在作业的不同版本之间以及Flink的不同版本之间顺利升级,强烈推荐程序员通过手动给算子赋予ID,这些ID将用于确定每一个算子的状态范围。如果不手动给各算子指定ID,则会由Flink自动给每个算子生成一个ID。而这些自动生成的ID依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动设置ID。
env.socketTextStream("node5",9999).uid("socket-source")
.flatMap((String line,Collector<Tuple2<String,Integer>> out) -> {
String[] words = line.split(",");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}).returns(Types.TUPLE(Types.STRING,Types.INT)).uid("flatmap")
.keyBy(tp -> tp.f0)
.sum(1).uid("sum")
.print().uid("print");一般Flink程序进行升级时都涉及使用savepoint保存状态,然后升级后再基于savepoint进行状态恢复。下面以读取Socket中的数据进行WordCount为例来演示savepoint和算子uid的配置及使用,可以按照如下步骤进行测试。
1) 编写代码并打包
- Java代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//读取socket数据做wordcount
SingleOutputStreamOperator<String> lines = env.socketTextStream("node5", 9999).uid("socket-source");
SingleOutputStreamOperator<Tuple2<String, Integer>> tuple2 = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(",");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).uid("flatmap");
SingleOutputStreamOperator<Tuple2<String, Integer>> result = tuple2.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
}).sum(1).uid("sum");
result.print().uid("print");
env.execute();- Scala代码
val env = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.streaming.api.scala._
// 读取socket数据做wordcount
env.socketTextStream("node5", 9999).uid("socket-source")
.flatMap(_.split(" ")).uid("flatMap")
.map((_, 1)).uid("map")
.keyBy(_._1)
.sum(1).uid("sum")
.print().uid("print")
env.execute()以上代码编写完成后,打包并上传到node5节点的/root/flink-jar-test目录中。
2) 在flink-conf.yaml中配置savepoint路径
在node5节点配置flink-conf.yaml文件"Fault tolerance and checkpointing"部分配置savepoint保存的路径,如下。
state.savepoints.dir: hdfs://mycluster/flink-savepoints3) 启动HDFS集群
#启动Zookeeper集群
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
#启动HDFS集群和Yarn集群
[root@node1 ~]# start-all.sh注意:启动HDFS集群后,如果有hdfs://mycluster/flink-savepoints目录,为了后续方便看出任务状态目录,最好删除该目录。
4) 提交任务并统计状态结果
node5节点启动socket服务并在node5节点上提交Flink任务,提交Flink任务后,向Socket中输入数据,观察Flink任务webui中统计的结果。
#node5节点启动socket服务
[root@node5 ~]# nc -lk 9999
#node5节点提交Flink任务
[root@node5 conf]# cd /software/flink-1.17.1/bin/
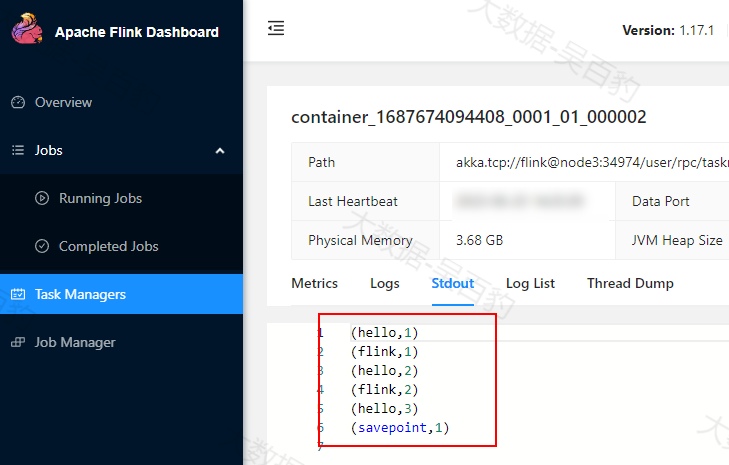
[root@node5 bin]# ./flink run-application -t yarn-application -c com.wubaibao.flinkjava.code.chapter7.savepoints.SavePointTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 提交任务后,向socket中输入以下数据:
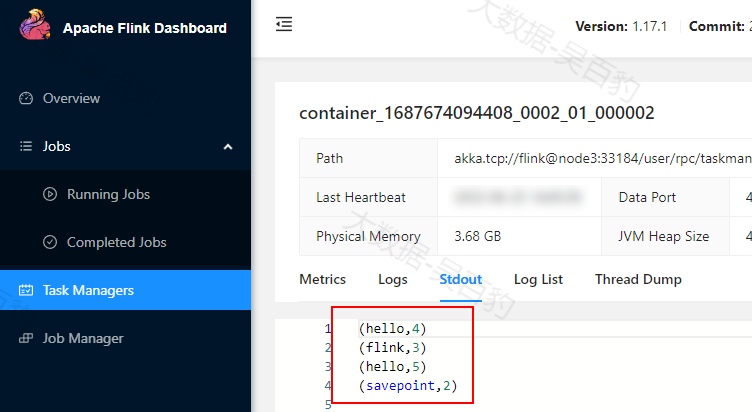
hello,flink
hello,flink
hello,savepoint输入数据后,观察Flink WebUI统计的结果如下:
5) 触发savepoint
执行如下命令执行savepoint 操作,将当前Flink程序的状态保存到对应路径中。
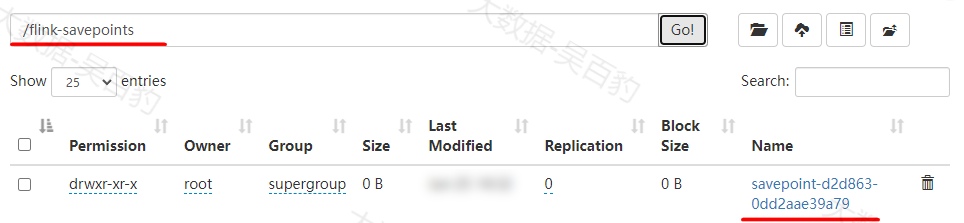
[root@node5 bin]# ./flink savepoint d2d863913b663ad70f60ee50d05aaa32 -yid application_1687674094408_0001以上命令注意以下几点:
-
savepoint操作命令格式为:./flink savepoint <Job ID> \
-
如果savepoint path(target directory)在当前提交任务节点的flink-conf.yaml中配置了,就不需要再写上。
-
如果是基于Yarn中运行的Flink任务,Flink JobID 通过Flink WebUI查看,并且执行savepoint命令最后需要通过-yid参数指定yarn application ID 链接到Yarn Application中。
以上savepoint 命令执行后,可以看到HDFS中生成对应的savepoint路径:
此时,我们可以手动取消Flink任务或者通过命令停止Flink任务,操作如下:
#命令方式取消Flink任务
[root@node5 bin]# ./flink cancel d2d863913b663ad70f60ee50d05aaa32 -yid application_1687674094408_00016) 从savepoint启动Job
可以通过如下命令来从savepoint路径中恢复Flink Job状态,命令如下:
[root@node5 bin]# ./flink run-application -t yarn-application -s hdfs://mycluster/flink-savepoints/savepoint-d2d863-0dd2aae39a79 -c com.wubaibao.flinkjava.code.chapter7.savepoints.SavePointTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jarFlink任务启动后,可以继续向Socket中输入如下数据:
hello,flink
hello,savepoint可以观察Flink WebUI对应统计的状态结果,可以看到Flink 任务已经成功从savepoint中恢复过来。
设置合适watermark
在Flink中,watermark是一种衡量事件时间进展的机制,watermark是一种特殊的数据记录,watermark本质就是一个时间戳,基于Flink接收到的事件时间(Event Time)计算得到,并且该时间标记会随着数据流往后流动,当Flink算子接收到Watermark(t)事件时,可以认为早于或等于t时刻的事件时间已经完全到达。
基于事件时间处理数据时定时器、流的关联、窗口触发都与watermark相关联,关于watermark的设置需要根据具体的业务数据延迟程度来决定,watermark延迟时间设置过大可能会导致内存使用过大或者窗口长时间不触发,这种情况下可以适当调小watermark大小,此外如果某个并行度中长时间没有数据到达,可以设置"WatermarkStrategy.xxx..withIdleness(Duration.ofSeconds(5))"来指定等待空闲时间自动推进watermark。
内存优化
Flink内存分布
Flink1.10版本后为了满足更细粒度以及灵活的内存管理,升级了内存模型,对内存组成进行了比较大的调整,由于在Flink中计算主要存在于TaskManager节点,这里说的Flink内存模型也就是TaskManager的内存模型,JobManager的内存模型与TaskManager的内存模型类似。
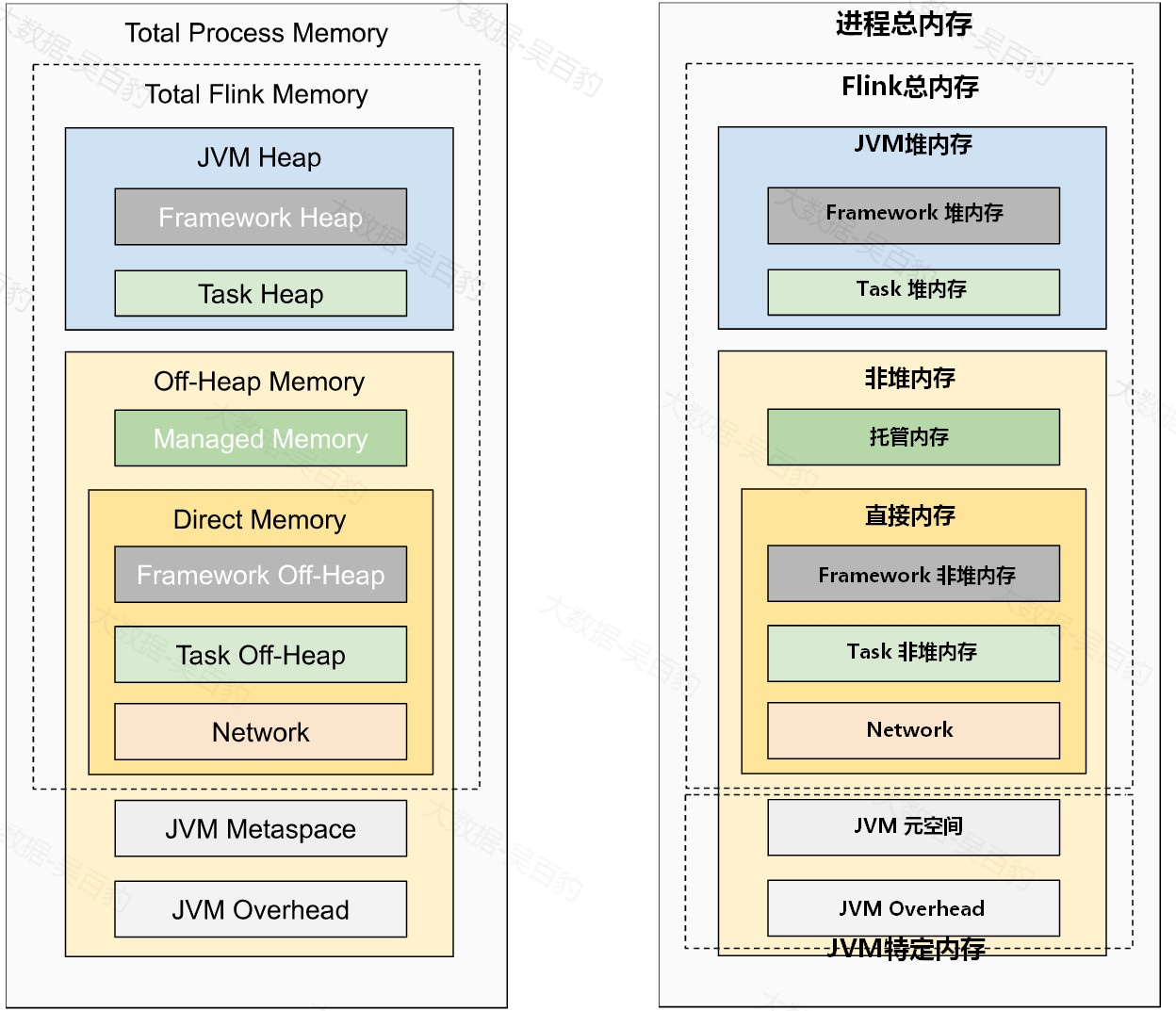
上图是Flink内存模型,从图中可以看出Flink 进程总内存(Total Process Memory)包含了Flink总内存(Total Flink Memory)和JVM特定内存。Flink总内存又包括JVM堆内存(JVM Heap)、托管内存(Managed Memory) 、直接内存(Direct Memory)。下面分别介绍各个部分内存功能以及参数配置。
Flink堆内存(JVM Heap)
Flink堆内存就是JVM堆内存(JVM Heap),分为Framework堆内存(Framework Heap)和Task堆内存(Task Heap),其中Framework 主要用于Flink框架本身需要的内存空间 ,Task堆内存则用于Flink算子、用户代码执行及状态数据存储,也被称为TaskExecutor使用的内存,两者的主要区别在于是否将内存计入Slot计算资源中,Framework堆内存不会将内存分配给Slot,Task堆内存会分配给Slot。
1) Framework堆内存(Framework Heap)
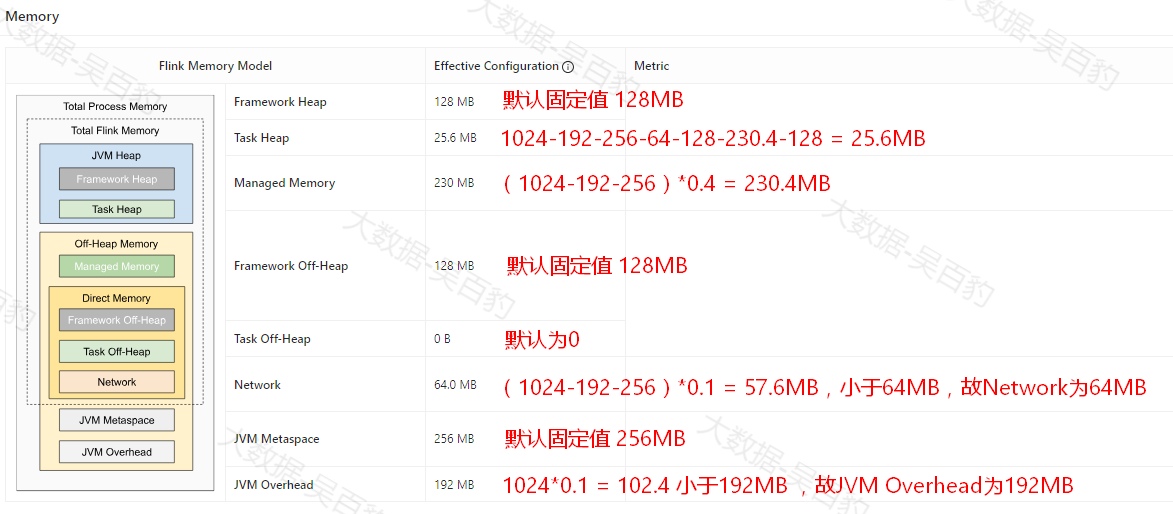
Framework堆内存配置参数为:taskmanager.memory.framework.heap.size,该值默认为128M。
2) Task 堆内存(Task Heap)
Task堆内存配置参数为:taskmanager.memory.task.heap.size,该值没有默认值,如果没有指定会自动用Flink总内存减去Framework堆内存(Framework Heap)、托管内存(Managed Memory)、Framework非堆内存(Framework Off-Heap)、Task非堆内存(Task Off-Heap)、NetWork的剩余内存。
Flink非堆内存(Off-Heap Memory)
非堆内存也可以叫做堆外内存,更准确来说是大部分的堆外内存,包含了托管内存(Managed Memory)、直接内存(Direct Memory)两部分。
1) 托管内存(Managed Memory)
托管内存(Managed Memory)是由Flink负责分配和管理的本地堆外内存,在流处理作业中用于RocksDBstateBackend状态存储后端,在批处理作业中用于排序、哈希表及缓存中间结果。
托管内存(Managed Memory)配置参数有两个,分别如下:
-
taskmanager.memory.managed.fraction,默认值0.4,如果未显式指定托管内存大小,则使用总Flink内存的百分比作为托管内存。
-
taskmanager.memory.managed.size,无默认值,一般也不指定,而是按照比例来推定,更加灵活。
2) 直接内存(Direct Memory)
直接内存(Direct Memory)分为Framework非堆内存(Framework Off-Heap)、Task 非堆内存(Task Off-Heap)和Network三个部分。直接内存主要作用是减少GC压力、提升性能效率。
Framework 非堆内存(Framework Off-Heap)
Framework 非堆内存即taskexecutor的Framework 堆外内存大小,不会分配给slot,配置参数为:taskmanager.memory.framework.off-heap.size,默认值128M。
Task非堆内存(Task Off-Heap)
Task非堆内存,配置参数taskmanager.memory.task.off-heap.size,默认值为0,即不使用。
Network
Network内存存储空间主要用于基于Netty进行网络数据交换,数据传输的本地缓存,例如:TaskManager之间Shuffle、广播、与外部组件的数据传输。Network的配置相关参数有3个,分别如下:
-
taskmanager.memory.network.min:网络缓存的最小值,默认64MB;
-
taskmanager.memory.network.max:网络缓存的最大值,默认1GB;
-
taskmanager.memory.network.fraction:网络缓存占Flink总内存taskmanager.memory.flink.size的比例,默认值0.1。若根据此比例算出的内存量比最小值小或比最大值大,就会限制到最小值或者最大值。
JVM 特定内存
JVM特定内存是JVM堆外内存的另一小部分内存,其不在Flink总内存范围之内,包括JVM元空间(JVM Metaspace)和JVM Overhead 两部分,其中JVM元空间存储JVM加载类的元数据,加载的类越多,需要的内存空间越大,该部分默认值为256M;JVM Overhead 则主要用于其他JVM开销,例如代码缓存、线程栈等,该部分默认值为TaskManager分配内存的0.1倍,最小值为192M,最大值为1GB。
Flink内存优化建议
关于Flink内存优化有如下几点建议:
-
在使用Flink过程中,我们可以设置参数来指定JobManager和TaskManager内存大小。Standalone部署模式下,可以通过 jobmanager.memory.flink.size和taskmanager.memory.flink.size 来指定JM和TM的内存大小。容器部署模式下(如:K8s,Yarn),可以通过jobmanager.memory.process.size和taskmanager.memory.process.size 来指定JM和TM的内存大小。JobManager主要负责管理TaskManager,这里给的内存可以相比TaskManager少一些,重点配置TaskManager内存。
-
提交Flink任务时指定的内存资源要保证程序不出现反压,并且在程序无反压使用内存基础上提供一些额外内存资源,这些内存资源可以在应用程序恢复期间更快的恢复状态及更快的处理停机期间累积的数据。
-
Flink内存管理中,如果需要根据Flink程序做一些调整建议有限调整fraction比例参数,例如:网络缓存占比taskmanager.memory.network.fraction(根据网络流量大小调节)与托管内存占比taskmanager.memory.managed.fraction(根据RocksDB状态大小调节),这样做可以间接影响任务内存的配额,需要特别注意的是如果手动指定较多的固定参数很有可能出现内存配额冲突导致Flink程序部署失败。
指定内存提交Flink任务案例
下面以Flink Yarn Application模式提交任务为例来演示提交Flink任务时指定JobManager和TaskManager内存。
以读取socket数据统计WordCount为例,代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/**
* Socket中数据如下:
* 001,186,187,busy,1000,10
* 002,187,186,fail,2000,20
*/
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//对ds进行转换处理,得到StationLog对象
SingleOutputStreamOperator<StationLog> stationLogDS = ds.map(new MapFunction<String, StationLog>() {
@Override
public StationLog map(String line) throws Exception {
String[] arr = line.split(",");
return new StationLog(
arr[0].trim(),
arr[1].trim(),
arr[2].trim(),
arr[3].trim(),
Long.valueOf(arr[4]),
Long.valueOf(arr[5])
);
}
});
stationLogDS.keyBy(stationLog -> stationLog.callOut)
.map(new RichMapFunction<StationLog, String>() {
//定义ValueState 用来存放同一个主叫号码的通话总时长
private ValueState<Long> valueState;
@Override
public void open(Configuration parameters) throws Exception {
//定义状态TTL
StateTtlConfig ttlConfig = StateTtlConfig
//设置状态有效期为10秒
.newBuilder(org.apache.flink.api.common.time.Time.seconds(10))
//设置状态更新类型为OnCreateAndWrite,即状态TTL创建和写入时更新
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//设置状态可见性为NeverReturnExpired,即状态过期后不返回
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
//定义状态描述器
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>("value-state", Long.class);
//设置状态TTL
descriptor.enableTimeToLive(ttlConfig);
//获取状态
valueState = getRuntimeContext().getState(descriptor);
}
@Override
public String map(StationLog stationLog) throws Exception {
Long stateValue = valueState.value();
if(stateValue==null){
//如果状态值为null,说明是第一次使用,直接更新状态值
valueState.update(stationLog.duration);
}else{
//如果状态值不为null,说明不是第一次使用,需要累加通话时长
valueState.update(stateValue+stationLog.duration);
}
return stationLog.callOut+"通话总时长:"+valueState.value()+"秒";
}
}).print();
env.execute();以上代码编写完成后打包,在node5节点启动socket服务,启动Hadoop集群,以Yarn Application 模式提交Flink任务,命令如下:
./flink run-application -t yarn-application \
-p 2 \
-Dtaskmanager.numberOfTaskSlots=2 \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=1024mb \
-c com.wubaibao.flinkjava.code.chapter12.MemoryTest \
/root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar任务提交后,可以通过查看Flink WebUI观察内存分布情况如下:
Checkpoint和大状态优化
Flink的checkpoint是一种实现容错和状态恢复的机制。Checkpoint会定期将Flink程序的状态保存到持久化存储系统中,通常是分布式文件系统,当Flink程序发生故障时,可以重新启动应用程序并从之前的状态中恢复,使得Flink程序能够回到故障发生前的一致状态。因此Flink中的checkpoint非常重要,本小节主要讲解Flink Checkpoint和大状态相关优化内容点。
Checkpoint的监控
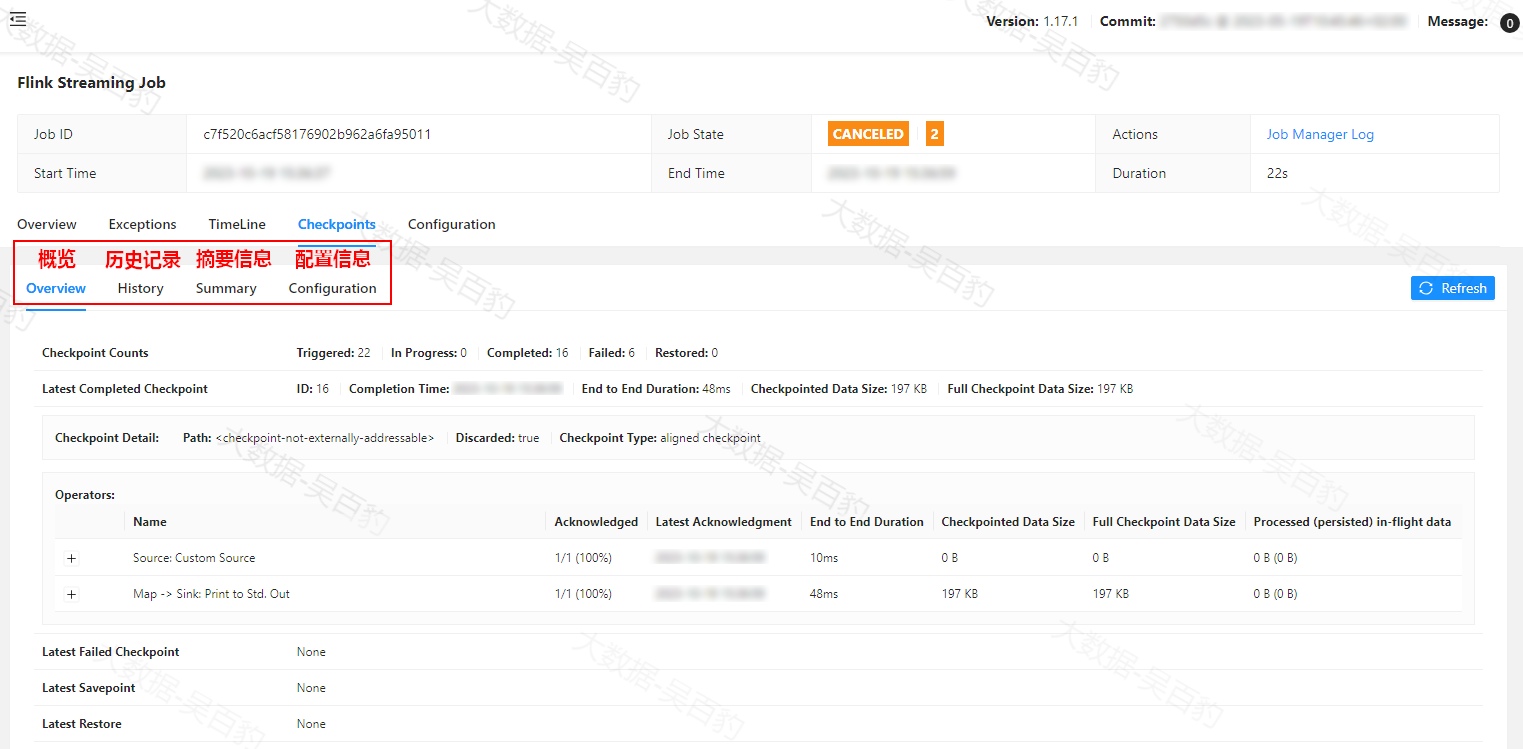
在Flink WebUI界面中提供了Flink Job的checkpoint监控信息。当Job结束后,这些信息仍然可用。如下图所示,有四个不同的选项卡(概览、历史记录、摘要信息、配置信息)可以显示checkpoint相关的信息,下面分别介绍这些内容。
概览(Overview)选项卡
概览选项卡列出了以下统计信息。
-
Checkpoint Counts
-
Triggered:自作业开始以来触发的checkpoint总数。
-
In Progress:当前正在进行的checkpoint数量。
-
Completed:自作业开始以来成功完成的checkpoint总数。
-
Failed:自作业开始以来失败的checkpoint总数。
-
Restored:自作业开始以来进行的恢复操作的次数。这还表示自提交任务以来已重新启动多少次。请注意,带有 savepoint 的初始任务提交也算作一次恢复,如果 JobManager 在此操作过程中丢失,则该统计将重新计数。
-
-
Latest Completed Checkpoint:最新(最近)成功完成的 checkpoint。
-
Latest Failed Checkpoint:最新失败的 checkpoint。
-
Latest Savepoint:最新触发的 savepoint 及其外部路径。
-
Latest Restore:有两种类型的恢复操作。
-
Restore from Checkpoint:从checkpoint恢复。
-
Restore from Savepoint:从savepoint恢复。
-
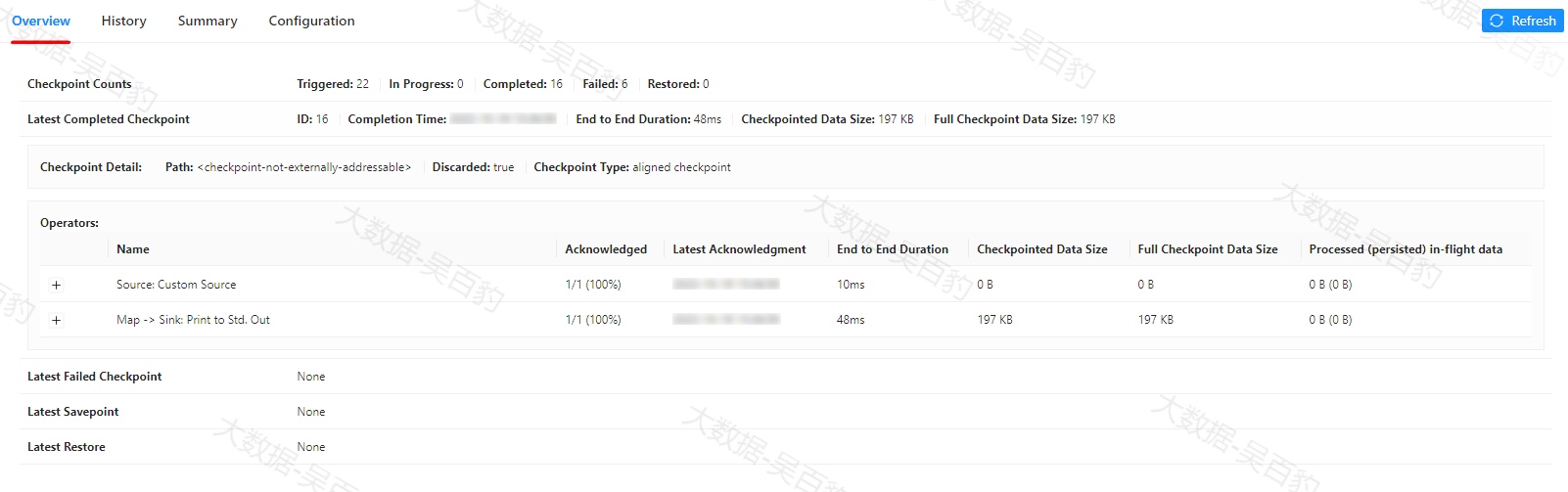
请注意,概览选项卡中的信息在JobManager丢失时无法保存,如果JobManager发生故障转移,这些信息将会被重置。
历史记录(History)选项卡
Checkpoint 历史记录保存有关最近触发的 checkpoint 的统计信息,包括当前正在进行的 checkpoint。对于失败的checkpoint,指标会尽最大努力进行更新,但是可能不准确。checkpoint统计详细信息内容如下:
-
ID:已触发 checkpoint 的 ID。每个 checkpoint 的 ID 都会递增,从 1 开始。
-
Status:Checkpoint 的当前状态,可以是正在进行(In Progress)、已完成(Completed) 或失败(Failed))。
-
Acknowledged:已确认完成的子任务数量与总任务数量。
-
Trigger Time:在 JobManager 上发起 checkpoint 的时间。
-
Latest Acknowledgement:JobManager 接收到任何 subtask 的最新确认的时间。
-
End to End Duration:从触发时间戳到最后一次确认的持续时间,也就是checkpoint开始到完成所需总时间。完整 checkpoint 的端到端持续时间由确认 checkpoint 的最后一个 subtask 确定。
-
Checkpointed Data Size: 在此次checkpoint的sync以及async阶段中持久化的数据量。如果启用了增量 checkpoint或者changelog,则此值可能会与全量checkpoint数据量产生区别。
-
Full Checkpoint Data Size: 所有已确认的 subtask 的 checkpoint 的全量数据大小。
-
Processed (persisted) in-flight data:在 checkpoint 对齐期间(从接收第一个和最后一个 checkpoint barrier 之间的时间)所有已确认的 subtask 处理/持久化 的大约字节数。如果启用了 unaligned checkpoint,持久化的字节数可能会大于0。
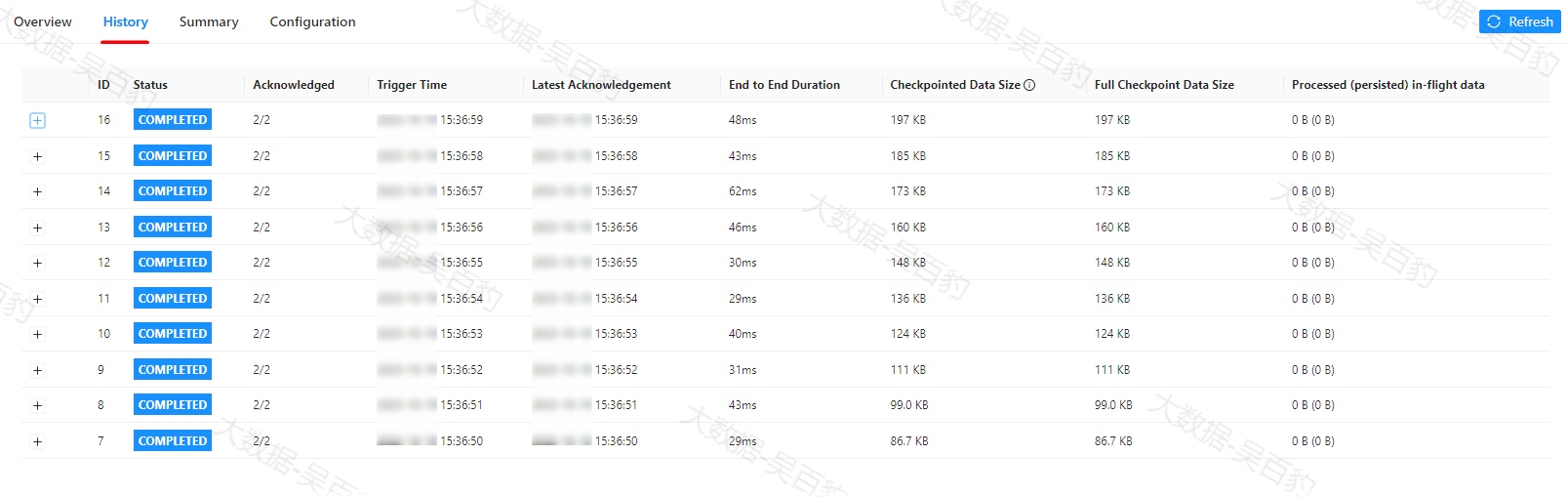
点击每个checkpoint记录前的"+"符号,可以看到每个checkpoint中subtask详情,对于subtask的一些详细信息如下图所示,解释如下:
-
Sync Duration:Checkpoint 同步部分的持续时间。这包括 operator 的快照状态,并阻塞 subtask 上的所有其他活动(处理记录、触发计时器等)。
-
Async Duration:Checkpoint 的异步部分的持续时间。这包括将 checkpoint 写入设置的文件系统所需的时间。对于 unaligned checkpoint,这还包括 subtask 必须等待最后一个 checkpoint barrier 到达的时间(checkpoint alignment 持续时间)以及持久化数据所需的时间。
-
Alignment Duration:处理第一个和最后一个 checkpoint barrier 之间的时间。对于 checkpoint alignment 机制的 checkpoint,在 checkpoint alignment 过程中,已经接收到 checkpoint barrier 的 channel 将阻塞并停止处理后续的数据。
-
Start Delay:从 checkpoint barrier 创建开始到 subtask 收到第一个 checkpoint barrier 所用的时间。
-
Unaligned Checkpoint:Checkpoint 完成的时候是否是一个 unaligned checkpoint。在 alignment 超时的时候 aligned checkpoint 可以自动切换成 unaligned checkpoint。
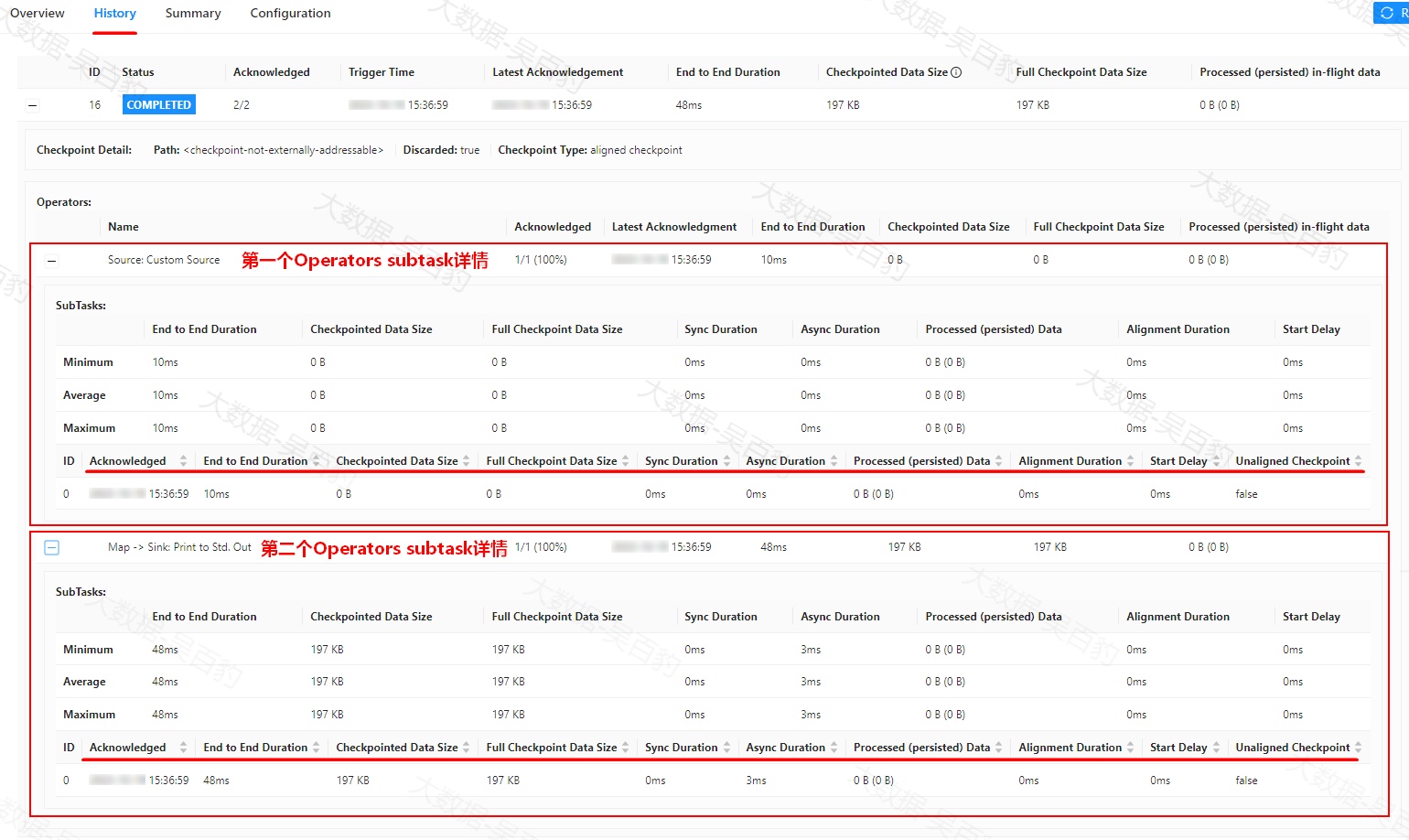
注意:默认在History中保存10个checkpoint记录,也可以在Flink配置文件flink-conf.yaml中配置web.checkpoints.history参数来增大WebUI中保存的Checkpoint记录数。
摘要信息(Summary)选项卡
摘要计算了所有已完成 checkpoint 的端到端持续时间、增量/全量Checkpoint 数据大小和 checkpoint alignment 期间缓冲的字节数的简单 min/average/maximum 统计信息。
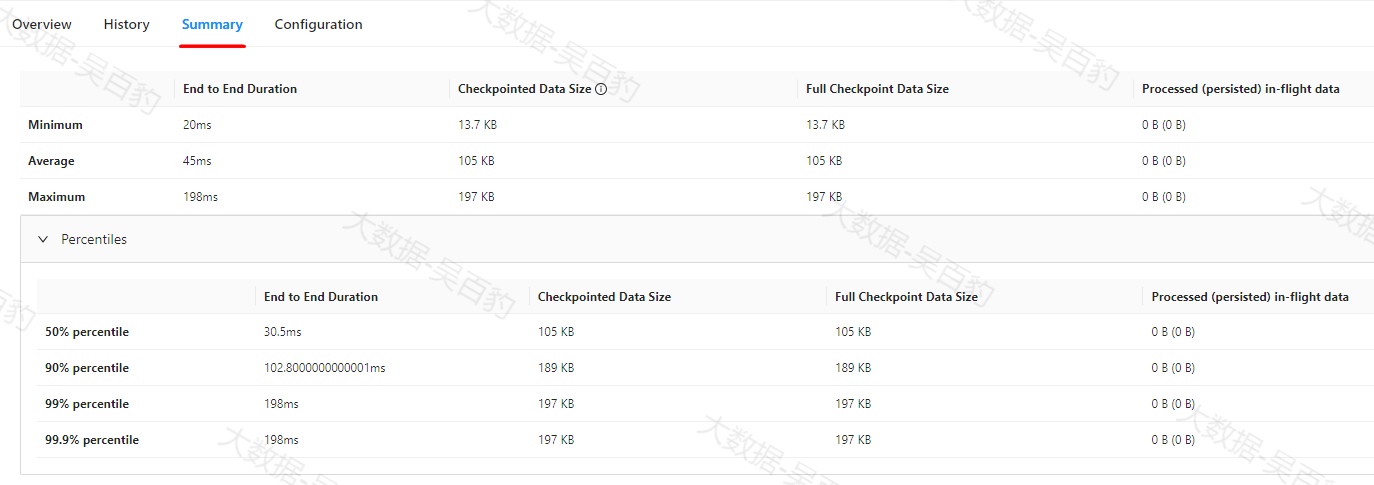
请注意:这些信息不会再JobManager中保存,如果JobManager故障转移,这些统计信息将重新计数。
配置信息(Configuration)选项卡
该选项卡展示了用户指定的配置。
-
Checkpointing Mode:恰好一次(Exactly Once)或者至少一次(At least Once)。
-
Interval:配置的 checkpoint 触发间隔。在此间隔内触发 checkpoint。
-
Timeout:超时之后,JobManager 取消 checkpoint 并触发新的 checkpoint。
-
Minimum Pause Between Checkpoints:Checkpoint 之间所需的最小暂停时间。Checkpoint 成功完成后,我们至少要等这段时间再触发下一个,这可能会延迟正常的间隔。
-
Maximum Concurrent Checkpoints:可以同时进行的最大 checkpoint 个数。
-
Persist Checkpoints Externally:启用或禁用持久化 checkpoint 到外部系统。如果启用,还会列出外部化 checkpoint 的清理配置(取消时删除或保留)。
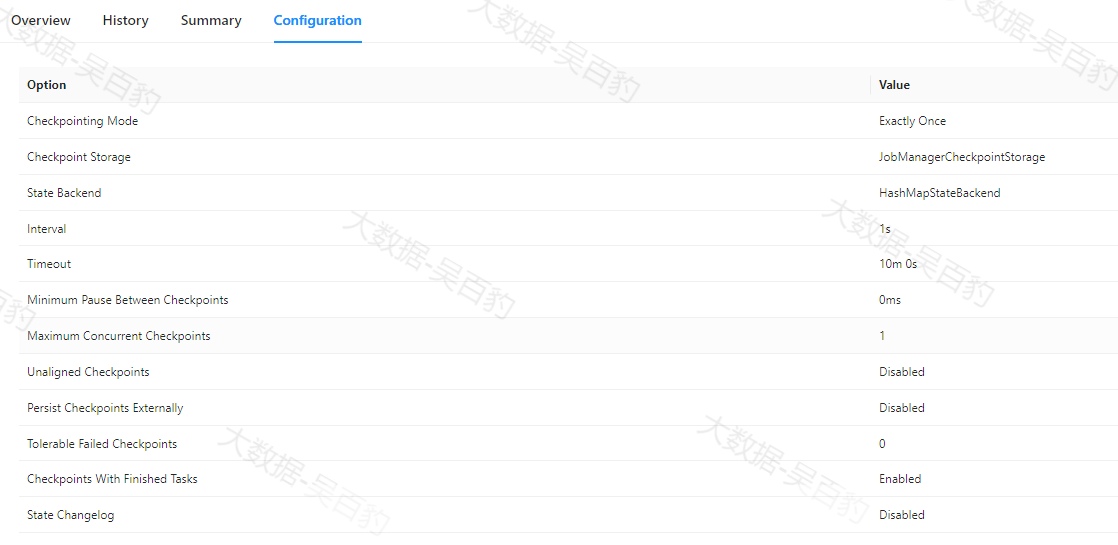
Checkpoint优化
设置CheckpointStorage
我们可以设置Checkpoint检查点快照(SnapShot)存储的位置,可以选择JobManagerCheckpointStorage或者FileSystemCheckpointStorage,两者分别代表JobManager堆内存和文件系统。默认情况下,snapshot 存储在JobManager的堆内存中,建议改为持久化文件系统。
Flink设置Checkpoint storage检查点存储位置代码如下:
//设置checkpoint storage存储为JobManagerStorage,默认堆内存存储状态大小为5M
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage(5*1024*1024));
//设置checkpoint storage存储为hdfs路径
env.getCheckpointConfig().setCheckpointStorage("hdfs://mycluster/flink/checkpoints");对于JobManagerCheckpointStorage来说,默认每个单独的状态大小限制为5M ,可以手动指定该值,如果Flink是本地开发调试或者Flink状态非常少的场景可以使用JobManagerCheckpointStorage,实际生产中推荐使用FileSystemCheckpointStorage。
设置Checkpoint模式
选择exactly-once语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink的性能也相对较弱,而at-least-once语义更适合于时延和吞吐量要求非常高但对数据的一致性要求不高的场景。
Flink中通过setCheckpointingMode()方法来设置检查点模式,默认情况下使用的是exactly-once模式。
//设置检查点模式为exactly-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置检查点模式为at-least-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);设置checkpoint超时时间
超时时间指定了每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过该阈值,Flink将会中断Checkpoint过程,并按照超时处理。该指标可以通过setCheckpointTimeout方法设定,默认为10分钟。
//设置Checkpoint 超时时间
env.getCheckpointConfig().setCheckpointTimeout(10*60*1000);设置checkpoint之间最小等待时间
通过Webui观察Flink任务运行情况,如果checkpoint的完成时间经常超过checkpoints基本间隔时(例如:因为状态比计划的更大或者访问checkpoints所在的存储系统暂时变慢),Flink系统会不断地进行checkpoints,因为一旦checkpoint完成,新的checkpoints就会立即启动。
这种情况下意味着多过的资源被不断地束缚在checkpointing中,并且checkpoint算子进行得缓慢,checkpoint占用了大量计算资源而影响到整个应用的性能。为了防止这种情况,应用程序可以定义checkpoint之间的最小等待时间。
//设置 checkpoint 最小间隔时间为500ms,默认值为0
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);除了以上设置方式外,还可以在提交Flink任务时进行"execution.checkpointing.min-pause"参数设置。
注意,当指定了该参数大于0时,Flink最大并行执行checkpoint的数量为1。
设置checkpoint并行度
如果Flink集群的资源充足,checkpoint周期时间较短,也可以配置Flink 应用程序同时进行多个checkpoints同时进行。这种情况下会分配更多的资源到checkpointing。Flink在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,进而提升Checkpoint整体的效率。
//设置checkpoint最大并行度,默认为1
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);以上设置方式还可以在提交Flink任务的时候通过"execution.checkpointing.max-concurrent-checkpoints"参数进行设置。
如下是测试checkpoint并行执行的代码案例。该案例中读取自定义source中的数据并通过map处理,每条数据暂停处理0.5秒。案例代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<StationLog> source = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
while (flag) {
String sid = "sid_" + random.nextInt(10);
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
Thread.sleep(1000);//1s 产生一个事件
}
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//处理数据
SingleOutputStreamOperator<String> result =
source.keyBy(stationLog -> stationLog.sid)
.map(new RichMapFunction<StationLog, String>() {
private ListState<String> listState;
@Override
public void open(Configuration parameters) throws Exception {
ListStateDescriptor<String> stateDescriptor = new ListStateDescriptor<>("liststate", String.class);
listState = getRuntimeContext().getListState(stateDescriptor);
}
@Override
public String map(StationLog value) throws Exception {
//100倍状态存储
for(int i = 0 ;i<100 ;i++){
listState.add(value.toString());
}
//每条数据都暂停处理 500ms
Thread.sleep(500);
return value.toString();
}
});
result.print();
env.execute();将以上代码打包并提交到Standalone集群执行,默认checkpoint并行度为1,此时FlinkCheckpoint会在上一次checkpoint执行完成后立即执行后续checkpoint;如果设置checkpoint多并行度,可以看到同时会有多个checkpoint同时进行。
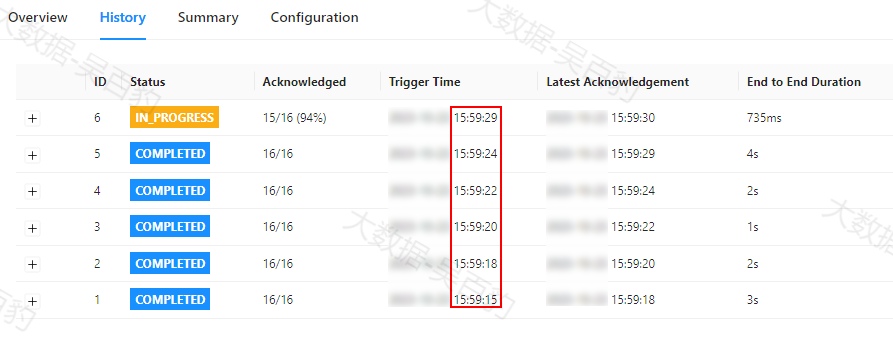
1) 使用默认checkpoint并行度为1
启动Standalone集群,并向集群中提交打包好的Flink任务,提交命令中设置并行度为8,checkpoint 周期为1s,checkpoint语义为exactly_once,checkpoint并行度使用默认的1。
[root@node4 ~]# cd /software/flink-1.17.1/bin/
[root@node4 bin]# ./flink run -m node1:8081 \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dexecution.checkpointing.mode=exactly_once \
-c com.mashibing.flinkjava.code.chapter12.CheckpointParalleCodeTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 可以看到Flink WebUI中checkpoint执行情况如下,可以看到虽然设置checkpoint的周期为1s,但是由于每个checkpoint中状态保存超过1s,所以每个checkpoint触发时间都是接着上个checkpoint执行完成后立即开始。
2) 设置checkpoint并行度为100
向Standalone集群中提交打包好的Flink任务,提交命令中设置并行度为8,checkpoint 周期为1s,checkpoint语义为exactly_once,checkpoint并行度为100。
[root@node4 ~]# cd /software/flink-1.17.1/bin/
[root@node4 bin]# ./flink run -m node1:8081 \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dexecution.checkpointing.mode=exactly_once \
-Dexecution.checkpointing.max-concurrent-checkpoints= 100 \
-c com.mashibing.flinkjava.code.chapter12.CheckpointParalleCodeTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 可以看到Flink WebUI中checkopint执行情况如下,checkpiont执行间隔为1s。
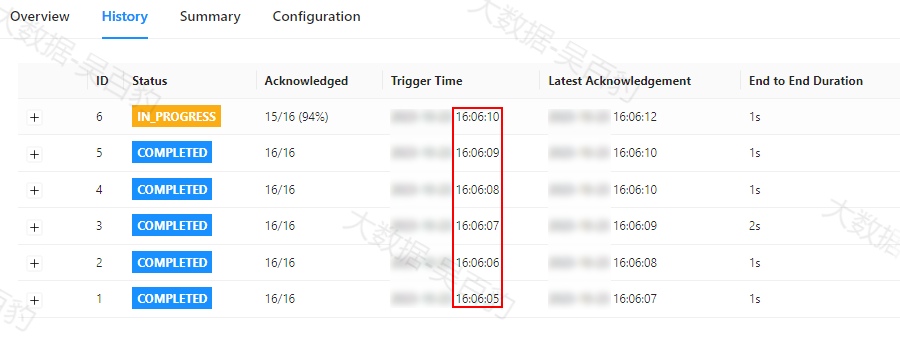
通过以上对比可以看到设置并行执行checkpoint可以加快checkpoint执行效率。
设置checkpiont失败次数
checkpoint在执行过程中如果出现失败设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务,没有默认值。
//设置可容忍checkpoint失败次数,没有默认值值,设置为0,表示不容忍任何checkpoint失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);设置checkpoint清理策略
当开启了checkpoint外部持久化存储时,可以通过如下两种方式决定在取消Flink作业时是否清空外部存储系统中的状态数据,如果不设置改参数,Flink取消任务时默认不清空checkpoint状态数据。
-
RETAIN_ON_CANCELLATION:在Flink作业取消时保留检查点。在这种情况下,必须手动清除检查点状态。
-
DELETE_ON_CANCELLATION:在Flink作业取消时删除检查点。只有作业失败时才会保存检查点状态。
/**
* 设置checkpoint的清理策略,当作业取消时,checkpoint数据的保留策略,默认值为RETAIN_ON_CANCELLATION
* RETAIN_ON_CANCELLATION:当作业取消时,保留checkpoint数据
* DELETE_ON_CANCELLATION:当作业取消时,删除checkpoint数据
*/
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);设置增量Checkpoint
在Flink状态后端章节中,我们提到Flink提供了两类状态后端,一类是HashMapStateBackend,另一类是EmbeddedRocksDBSatateBackend。
- HashMapStateBackend
HashMapStateBackend将状态数据以HashMap数据结构进行存储,默认将状态存储在JobManager内存中。通过用户指定checkpint持久化目录也可以将状态数据存储在外部持久化系统中。这种状态后端每次进行checkpoint检查点时都是全量方式进行,适用于较小的状态数据集。
- EmbeddedRocksDBStateBackend
EmbeddedRocksDBStateBackend 是 Flink 的一种基于 RocksDB 的状态后端。RocksDB 是一个高性能、持久化的键值存储引擎,它将状态数据存储在本地磁盘上,默认在TaskManager本地数据目录中。与 HashMapStateBackend全量存储状态不同,RockDBStateBackend是目前唯一支持增量检查点的状态后端,可以保存非常大的状态。
如果Flink任务checkpoint状态非常大,开启增量checkpoint应该是首要考虑因素,与完整的checkpoint相比,增量checkpoint可以显著减少checkpoint时间,因为增量checkpoint仅存储与先前完成的checkpoint不同的增量文件,而非全量数据备份。在生产环境中建议使用RockDBStateBackend方式存储状态。
代码中设置RockDBStateBackend的方式并开启增量checkpoint方式如下:
//设置状态后端为RocksDBStateBackend,并指定增量checkpoint
env.setStateBackend(new EmbeddedRocksDBStateBackend(true));
env.getCheckpointConfig().setCheckpointStorage("your-checkpoint-dir");在Flink代码中设置状态后端为new EmbeddedRocksDBStateBackend()默认是不开启增量checkpoint,加上true后支持增量checkpoint。也可以在Flink集群的flink-conf.yaml文件中配置state.backend.incremental为ture来开启增量checkpoint,或者在向集群中提交Flink任务时通过命令来设置。
下面通过一个案例来演示增量checkpoint保存。该案例中读取自定义source中的数据并通过map处理,每条数据暂停处理0.5秒。案例代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<StationLog> source = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
while (flag) {
String sid = "sid_" + random.nextInt(10);
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
Thread.sleep(1000);//1s 产生一个事件
}
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//处理数据
SingleOutputStreamOperator<String> result =
source.keyBy(stationLog -> stationLog.sid)
.map(new RichMapFunction<StationLog, String>() {
private ListState<String> listState;
@Override
public void open(Configuration parameters) throws Exception {
ListStateDescriptor<String> stateDescriptor = new ListStateDescriptor<>("liststate", String.class);
listState = getRuntimeContext().getListState(stateDescriptor);
}
@Override
public String map(StationLog value) throws Exception {
//100倍状态存储
for(int i = 0 ;i<100 ;i++){
listState.add(value.toString());
}
return value.toString();
}
});
result.print();
env.execute();如果不使用RocksDB 增量状态存储,可以看到checkpoint每次保存的都是全量状态。如果设置使用了RocksDB增量状态存储,可以看到checkpoint每次保存的都是增量状态。
1) 使用全量checkpoint
启动Standalone集群,并向集群中提交打包好的Flink任务,提交命令中设置并行度为8,checkpoint 周期为1s,状态后端使用rocksdb并设置状态保存在HDFS路径中,checkpoint语义为exactly_once。
[root@node4 ~]# cd /software/flink-1.17.1/bin/
[root@node4 bin]# ./flink run -m node1:8081 \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockDBState-dir \
-Dexecution.checkpointing.mode=exactly_once \
-c com.wubaibao.flinkjava.code.chapter12.CKWithRockDBStateBackend /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 可以看到Flink WebUI中checkpoint执行情况如下,checkpoint进行全量保存。
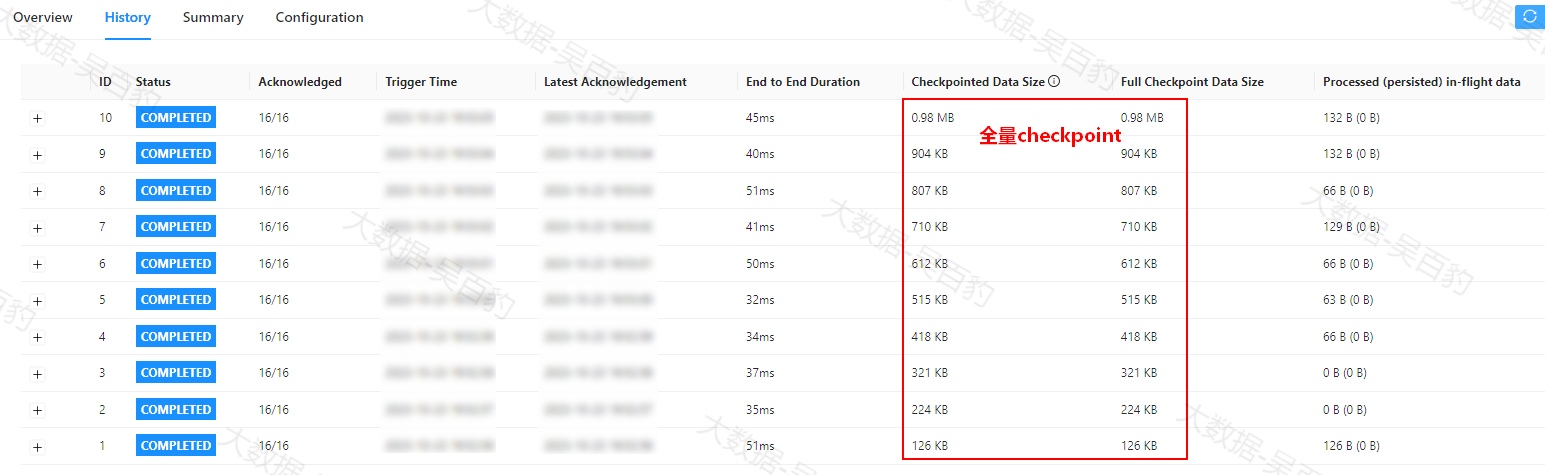
2) 设置RocksDB状态后端并开启增量checkpoint
启动Standalone集群,并向集群中提交打包好的Flink任务,提交命令中设置并行度为8,checkpoint 周期为1s,状态后端使用rocksdb并设置状态保存在HDFS路径中,checkpoint语义为exactly_once,checkpoint进行增量保存。
[root@node4 ~]# cd /software/flink-1.17.1/bin/
[root@node4 bin]# ./flink run -m node1:8081 \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockDBState-dir \
-Dexecution.checkpointing.mode=exactly_once \
-Dstate.backend.incremental=true \
-c com.mashibing.flinkjava.code.chapter12.RocksDBCKTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 可以看到Flink WebUI中checkpoint执行情况如下,checkpoint进行增量保存。
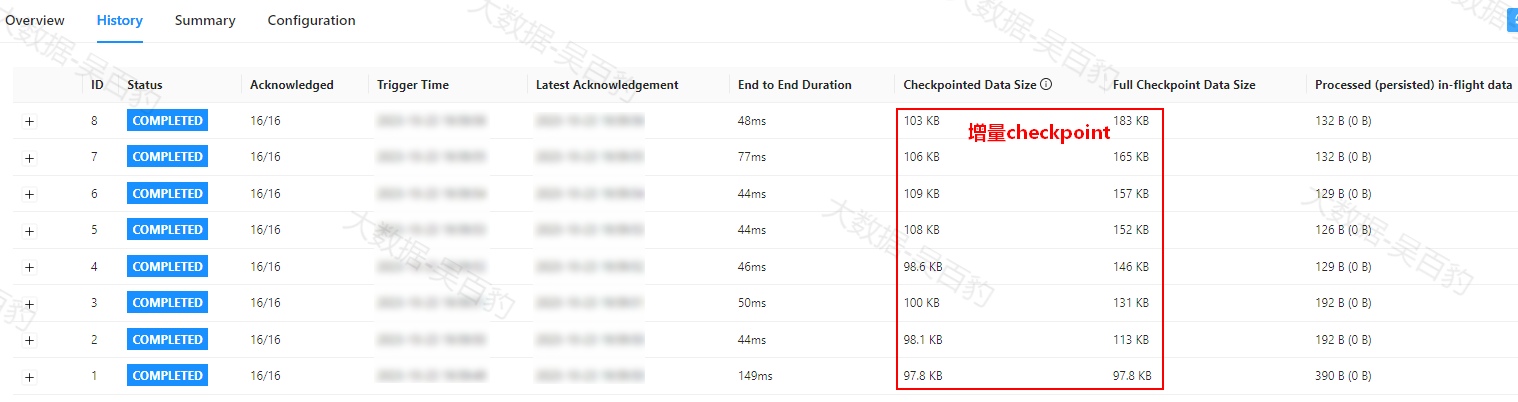
通过以上对比可以看出,使用RocksDB状态后端并设置checkpoint增量保存后,每次可以大大节省状态保存的大小。一旦启用了增量快照,网页上展示的 Full Checkpointed Data Size 只代表增量上传的数据量,而不是一次快照的完整数据量。
开启不对齐checkpoint
当Flink作业正运行在严重的背压下时,由于缓存中需要存储大量的数据可能会导致checkpoint周期非常长,这种情况下我们可以设置非对齐checkpoint(Unaligned checkpoint)。Flink从1.11版本开始支持 Unaligned checkpoints,非对齐checkpoint中 将In-flight 数据(例如,存储在缓冲区中的数据)作为 Checkpoint State的一部分,允许 Checkpoint Barrier 跨越这些缓冲区, Checkpoint 时长变得与当前吞吐量无关,从而减少checkpoint的时长。
可以通过两种方式来设置非对齐Checkpoint:代码中设置及flink-conf.yaml配置文件中设置。
1) 代码中设置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 启用非对齐 Checkpoint
env.getCheckpointConfig().enableUnalignedCheckpoints();2) flink-conf.yaml配置文件中设置
execution.checkpointing.unaligned: true注意:非对齐checkpoints 会增加状态存储的IO,因此当状态存储的IO是整个checkpoint过程中真正的瓶颈时,不能使用非对齐checkpoint。
开启Changelog
Flink 中使用RocksDB作为状态后端时,支持增量快照,可以减少checkpoint持续时间。在增量快照中,RocksDB出于空间放大和读性能的考虑会定期对状态做Compaction,Compaction会产生新的且相对较大的状态文件,这会导致除了新的变更之外还要重新上传旧状态。这个过程可能会带来如下2个问题:
-
由于要重新上传旧状态,会增加checkpoint快照上传所需时间。在 Flink 的大型作业中,每次checkpoint中至少有一个task上传大量数据的可能性非常高,所以在大型Flink任务重这种延迟问题较为突出。
-
目前这种增量checkpoint机制中,一个task只有在收到至少一个checkpoint barrier之后,才会做状态快照,无形中也增加了checkpoint时间。
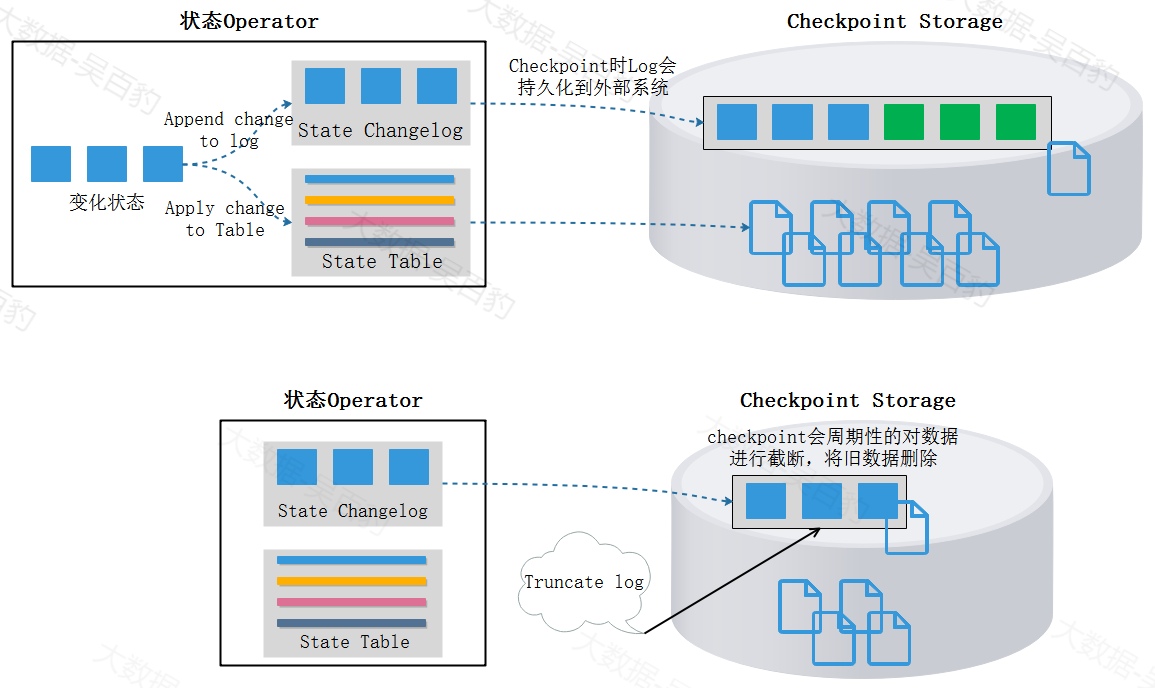
为了解决目前增量checkpoint出现的以上问题,Flink1.15版本引入了Changelog State Backend ,其核心思想是引入State Changelog (状态变化日志)更加细粒度的持久化状态。Changelog State Backend机制中TaskManager在做State操作时会进行两份状态写入:
-
State数据会写入到本地State Table中,State Table中记录了算子计算的状态结果,会周期性将数据存储到指定的外部存储系统中。这个过程是独立于Checkpoint过程。
-
State数据以Append Only的形式写到本地Changelog中,Changelog存储在TaskManager内存中,状态数据的增量更改(插入/更新/删除)会被写入到Changelog中,每次checkpoint时,只需要将这部分增量数据同步到持久化存储中就完成了checkpoint过程。
当State Table同步到Checkpoint Storage后,意味着State ChangeLog中相关部分也被持久化到Checkpoint Storage中,在Checkpoint Storage中的ChangeLog就可以被截断到相应的点。以上两份状态写入及ChangeLog截断示意图如下:
Changelog State Backend 由于Changelog信息相对固定,在做Checkpoint时只需要持久化Changelog部分,持久化的数据变少,所以可以减少checkpointing时间,可以减少exactly-once 模式下端到端的延迟。但是也会带来一些额外的开销:
-
在状态存储系统中创建更多额外的文件,更多的IO用来上传状态变更。
-
changelog带来TaskManager额外的内存使用。
-
容错恢复需要额外的重放 Changelog 带来的潜在的恢复时间的增加。
Changelog State Backend机制可以在代码中进行设置开启,方式如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableChangelogStateBackend(true);开启checkpoint压缩
Flink 为所有 checkpoints 和 savepoints 提供可选的压缩(默认:关闭)。 目前压缩仅支持使用 snappy 压缩算法,Flink未来版本会支持自定义压缩算法。 设置压缩后可以大大减少Flink存储状态的大小,压缩可以通过如下参数进行设置:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启checkpoint/savepoint 压缩
env.getConfig().setUseSnapshotCompression(true);注意:压缩选项对增量快照没有影响,因为增量快照使用的是 RocksDB 的内部格式,该格式始终使用开箱即用的 snappy 压缩。
RocksDB优化
RocksDB是由Facebook开发并开源的高性能键值存储库,使用C++编写,适合低延迟快速、大规模数据存储。在生产环境中,许多大型的Flink流应用程序的状态存储主要是RocksDB进行存储,这种状态后端可以可靠地存储大状态。
RocksDB类似HBase,采用LSM树(Log-Structured Merge Tree)的方式组织数据,在RocksDB3.0版本后引入列族概念(Column Families),RocksDB中的键值都与列族相关联,默认列族为"default"。
RocksDB架构中主要有三种结构:memtable、sstfile和logfile。memtable存在于内存中,当向RocksDB写入数据时,数据首先被写入内存中的memtable中,具有较高的写入性能,当memtable超过一定阈值时,会将数据写入磁盘中的sstfile中,整个数据写入操作还可被追加到logfile中形成WAL日志,以便保证数据的可靠性和一致性。RocksDB底层会定期将多个sstfile文件进行合并,以减少磁盘文件数量并优化读取性能。当从RocksDB中读取数据时,首先会在内存中的memtable中查找对应数据,找到直接返回,如果在memtable中没有找到则会在BlockCache块缓存中查找(BlockCache是用于读取数据的内存缓存,部分内存用于缓存SSTable文件的块,以提高读取性能),如果在BlockCache中未找到,则会在磁盘上sstfile文件中查找,最终返回数据。
RocksDB内存调优
在Flink中使用RocksDB状态后端进行状态存储时,RocksDB使用的内存由Flink管理(由state.backend.rocksdb.memory.managed参数决定,默认true,即Flink管理RocksDB使用内存),默认RocksDB可用的内存为TaskManager的托管内存(Managed Memory)大小,由参数taskmanager.memory.managed.fraction控制大小,默认为总Flink 内存的0.4倍。编写Flink程序时,大多数程序不需要调整RocksDB底层配置,只需要简单的增加Flink的托管内存大小即可改善内存相关性能问题。
Flink管理RocksDB内存使用中,对同一个task slot上所有的RocksDB实例共享内存,共享内存主要消耗有三个来源(blockcache、索引和bloom过滤器、memtable),一些情况下,如果RocksDB由于缺少写缓存内存而频繁刷新或者读缓存未命中而性能不佳时,我们还可以手动管理RocksDB内存分配,Flink提供了以下两个参数来控制memtable和索引过滤器、blockcache之间的内存分配。
-
state.backend.rocksdb.memory.write-buffer-ratio,默认值 0.5,即 50% 的给定内存会分配给写缓冲区使用。
-
state.backend.rocksdb.memory.high-prio-pool-ratio,默认值 0.1,即 10% 的 block cache 内存会优先分配给索引及布隆过滤器。 我们强烈建议不要将此值设置为零,以防止索引和过滤器被频繁踢出缓存而导致性能问题。
可以在提交Flink任务时通过命令进行以上参数设置。要想手动控制RocksDB内存需要首先将state.backend.rocksdb.memory.managed设置为false,此外,用户需要保证JVM有足够内存可供RocksDB使用。
下面通过命令方式演示如何设置以上参数,案例代码同上。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<StationLog> source = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
while (flag) {
String sid = "sid_" + random.nextInt(10);
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
Thread.sleep(1000);//1s 产生一个事件
}
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//处理数据
SingleOutputStreamOperator<String> result =
source.keyBy(stationLog -> stationLog.sid)
.map(new RichMapFunction<StationLog, String>() {
private ListState<String> listState;
@Override
public void open(Configuration parameters) throws Exception {
ListStateDescriptor<String> stateDescriptor = new ListStateDescriptor<>("liststate", String.class);
listState = getRuntimeContext().getListState(stateDescriptor);
}
@Override
public String map(StationLog value) throws Exception {
//100倍状态存储
for(int i = 0 ;i<100 ;i++){
listState.add(value.toString());
}
return value.toString();
}
});
result.print();
env.execute();将以上代码打包,并提交到Yarn集群运行任务,提交命令中设置并行度为8,checkpoint 周期为1s,状态后端使用rocksdb并设置状态保存在HDFS路径中,checkpoint语义为exactly_once,checkpoint进行增量保存,手动管理RocksDB内存,并设置写缓存区使用内存比例为0.6。
[root@node4 ~]# cd /software/flink-1.17.1/bin/
[root@node4 bin]# ./flink run -m node1:8081 \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockDBState-dir \
-Dexecution.checkpointing.mode=exactly_once \
-Dstate.backend.incremental=true \
-Dstate.backend.rocksdb.memory.managed=false \
-Dstate.backend.rocksdb.memory.write-buffer-ratio=0.6 \
-c com.mashibing.flinkjava.code.chapter12.RocksDBCKTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 以上命令提交后,在Flink WebUI中默认看不到RocksDB相关参数监控指标,关于Flink如何监控查看RocksDB相关指标在后续小节会进行介绍,这里只需要记住这种参数调节方式即可。
关于RocksDB内存调优相关问题,有如下2个建议:
-
尝试提高性能的第一步应该是增加托管内存的大小而不是通过调整 RocksDB 底层参数引入复杂性。在集群内存资源充足情况下,除非程序本身逻辑需要大量的JVM堆内存(对象多、计算逻辑复杂),否则大部分总内存通常都可以用于 RocksDB 。可以通过调节taskmanager.memory.managed.fraction(默认0.4)参数来增加托管内存大小。
-
如果Flink程序中状态非常多时,并且可以看到频繁的memtable刷新(参考后续小节监控RocksDB指标监控),意味着出现了写端瓶颈,此刻如果不能提供更多内存,可以手动管理RocksDB内存分配,设置 state.backend.rocksdb.memory.managed: false,并增加写缓冲区的内存比例(state.backend.rocksdb.memory.write-buffer-ratio,默认0.5)。
RocksDB优化参数
绝大多数情况下我们在进行RocksDB内存调节时,只需要增大TaskManager托管内存即可,如果不能满足生产,需要手动调节RocksDB相关参数可以参照如下参数进行调节。
- state.backend.rocksdb.memory.managed,默认true
在Flink中设置使用RocksDB状态后端进行状态存储时,RocksDB使用的内存是否由Flink进行管理,默认true,表示Flink管理RocksDB使用内存,分配大小为TaskManager的托管内存0.4倍。
- state.backend.rocksdb.memory.write-buffer-ratio,默认值 0.5
该参数表示将分配给RocksDB内存总量的 50% 分配给写缓冲区使用,限制了写缓存区可能占用的最大内存使用量。该参数需要设置state.backend.rocksdb.memory.managed为false。
- state.backend.rocksdb.memory.high-prio-pool-ratio,默认值 0.1
该参数表示将 10% 的 block cache 内存会优先分配给索引及布隆过滤器。 我们强烈建议不要将此值设置为零,以防止索引和过滤器被频繁踢出缓存而导致性能问题。该参数需要设置state.backend.rocksdb.memory.managed为false。
- state.backend.rocksdb.memory.partitioned-index-filters,默认false
RocksDB BlockCache中存的数据主要包含三部分:Data Block(真实数据)、Index Block(每条数据索引)、Filter Block(对文件的Bloom Filter)。这三部分占用内存最多的是Index Block 和 Filter Block,如果存入RocksDB中的文件数特别多,Index Block和Filter Block数据会不断的从内存和磁盘中进行替出换入,性能非常差。
这时我们可以设置state.backend.rocksdb.memory.partitioned-index-filters参数为true,表示针对Index Block 和 Filter Block设置多级索引,将这些顶级索引数据存入内存中,然后根据顶级索引按需查询Index Block 和 Filter Block数据加载到BlockCache中,加快速度。内存较小场景中,可以开启该参数,性能提升10倍左右。
以上参数是粗粒度设置RocksDB内存分配参数,这些参数使用时只需要在提交Flink任务时进行设置即可,命令如下所示:
./flink run-application -t yarn-application \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockdb-state-dir \
-Dexecution.checkpointing.mode=exactly_once \
-Dstate.backend.incremental=true \
-Dstate.backend.rocksdb.memory.managed=false \
-Dstate.backend.rocksdb.memory.write-buffer-ratio=0.6 \
-Dstate.backend.rocksdb.memory.high-prio-pool-ratio=0.2 \
-Dstate.backend.rocksdb.memory.partitioned-index-filters=true \
-c com.wubaibao.flinkjava.code.chapter12.RocksDBCKTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 如果以上参数不能满足需要,我们还可以对RocksDB进行底层优化参数设置来满足生产需要,以下RocksDB底层配置参数仅限于高级调优场景。高级优化中RocksDB底层调优常见的参数如下:
- state.backend.rocksdb.writebuffer.count,默认2
Flink向RocksDB中保存数据时,Flink中每个算子的每个state都对应一个列族(ColumnFamily),每个列族都有自己的MemTable。该参数表示允许在内存中保留的Memtable最大个数,超过这个个数后,数据会被Flush刷写到磁盘上形成SST文件。
如果Flink程序算子对应的状态多,并且内存足够大,可以将该参数适当调大,例如调大到5左右,降低Flush刷下磁盘次数。
- state.backend.rocksdb.writebuffer.size,默认64M
向RocksDB中写入数据,首先写入内存中,该参数表示数据写入RocksDB时在内存中空间占用大小。默认64M,如果Flink集群内存充足,可以适当调大该参数提高写入RocksDB性能。
- state.backend.rocksdb.writebuffer.number-to-merge,默认1
该参数表示writebuffer在写出到存储前进行合并的最小阈值。默认为1,即有数据写入形成writebuffer就会写出到存储中。根据经验,将该值可以设置为3,避免频繁的数据写出到存储。不要将该值设置太大以避免频繁的Merge操作造成写停顿。
可以在提交Flink任务时设置"state.backend.rocksdb.metrics.cur-size-all-mem-tables"参数为true来启动Flink监控RocksDB中memTable占用内存大小来评估该值设置大小。
- state.backend.rocksdb.block.cache-size,默认8M
该参数是设置RocksDB中BlockCache大小的参数,默认为8M。增加BlockCache大小可以明显增加读性能,在内存充足情况下,可以将该值设置到64~256MB,以增加数据读取性能。
可以在提交Flink任务时设置"state.backend.rocksdb.metrics.block-cache-usage"参数为true来启动Flink监控RocksDB Blockcache使用情况指标,可以实时观察Block Cache的用量并做出相应优化。
- state.backend.rocksdb.block.blocksize,默认4kb
RocksDB底层组成SST文件的基本单位是block块,block块中包含了一系列有序的key和value集合,该参数表示的就是block块大小,默认为4kb。
增大block大小,可以提高数据写入性能,因为不需要频繁切换block写入数据,在相同数据量下block总数量会减少,RocksDB中对应的索引所占用的内存会减少。但是如果增大block大小后,对应的BlockCache大小没有变,那么就意为着BlockCache中可存放的block数变少,如果BlockCache中还存索引和布隆过滤器,那么可存储的block块数目会更少,这时从RocksDB中读取数据时可能会需要更多的磁盘IO操作,以查找到想要的数据。
所以,减少该值可以提高读取数据性能,降低写入性能;增大该值,可以提高写入性能但是会降低读取性能。根据经验来看,如果Flink集群内存充足,可以提高block大小到128K,同时将BlockCache一并增大,这样就会有较好的读写性能,如果内存很吃紧,就不要调节该值和BlockCache大小。
- state.backend.rocksdb.thread.num,默认2
RocksDB后台会对写入的数据定期进行Compaction和Flush操作,该参数可以设置后台Compaction和Flush操作的线程数,默认值为2,如果使用的是机械硬盘可以相应提高该值,建议设置为4,不要设置太大,否则当有很多写入请求时,后台线程都在做Compaction操作会导致写停顿问题。
12.3.3.3 RocksDB参数使用
在Flink中设置以上RocksDB高级参数可以在代码中设置,也可以在提交任务时进行设置,在代码中设置时需要实现ConfigurableRocksDBOptionsFactory接口进行参数设置,相当于是硬编码且比较麻烦,建议在提交任务时通过指定对应参数进行设置,这种方式比较灵活方便。
- 代码中设置RocksDB高级参数
... ...
//设置状态后端为RocksDBStateBackend,并指定增量checkpoint
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
rocksDBStateBackend.setRocksDBOptions(new MyOptionsFactory());
env.setStateBackend(rocksDBStateBackend);
env.getCheckpointConfig().setCheckpointStorage("hdfs://mycluster/rockDBState-dir");
... ...
//MyOptionsFactory类实现
class MyOptionsFactory implements ConfigurableRocksDBOptionsFactory {
@Override
public DBOptions createDBOptions(DBOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
return currentOptions
//数据自动刷盘
.setAtomicFlush(true);
}
@Override
public ColumnFamilyOptions createColumnOptions(ColumnFamilyOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
return currentOptions
//设置在内存中允许保留的 memtable 最大个数,默认2
.setMaxWriteBufferNumber(2)
//设置数据写入RocksDB时在内存中空间占用大小,默认64M
.setWriteBufferSize(64*1024*1024L)
//设置内存中writebuffer 进行合并的最小阈值,默认1
.setMinWriteBufferNumberToMerge(1)
.setTableFormatConfig(
new BlockBasedTableConfig()
//设置RocksDB中BlockCache大小的参数,默认8M
.setBlockCache(new LRUCache(8*1024*1024L))
//设置SST文件底层block大小,默认4kb
.setBlockSize(4*1024L)
);
}
@Override
public RocksDBOptionsFactory configure(ReadableConfig configuration) {
//返回配置项
return this;
}
}以上高级参数设置有一定门槛,并且在代码设置比较麻烦,Flink还提供通过setPredefinedOptions方法选择Flink中预定义选项,这些选项中自动设置好了底层的一些参数,大大降低了使用门槛。设置RocksDB使用Flink预定义选项方式如下:
//设置状态后端为RocksDBStateBackend,并指定增量checkpoint
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
rocksDBStateBackend.setPredefinedOptions(PredefinedOptions.DEFAULT);
env.setStateBackend(rocksDBStateBackend);
env.getCheckpointConfig().setCheckpointStorage("hdfs://mycluster/rockDBState-dir");PredefinedOptions默认有四种选项:
-
DEFAULT:默认,没有额外参数优化,RocksDB只使用磁盘。
-
SPINNING_DISK_OPTIMIZED:RocksDB使用磁盘并设置一些优化参数。
-
SPINNING_DISK_OPTIMIZED_HIGH_MEM:RocksDB使用磁盘和内存并设置一些优化参数。
-
FLASH_SSD_OPTIMIZED:RocksDB使用固态磁盘并设置优化参数。
以上四种选项中,每一种Flink都设置了对应的优化参数,我们可以直接选择使用,当内存充足时,建议选择SPINNING_DISK_OPTIMIZED_HIGH_MEM方式。
- 提交任务时参数设置RocksDB高级参数
提交任务设置高级参数通过"-D"进行指定即可,代码中不设置任何RocksDB相关配置,提交命令中指定状态后端使用RocksDB及设置参数命令如下:
./flink run-application -t yarn-application \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockdb-state-dir \
-Dexecution.checkpointing.mode=exactly_once \
-Dstate.backend.incremental=true \
-Dstate.backend.rocksdb.memory.managed=false \
-Dstate.backend.rocksdb.writebuffer.count=2 \
-Dstate.backend.rocksdb.writebuffer.size=64M \
-Dstate.backend.rocksdb.writebuffer.number-to-merge=1 \
-Dstate.backend.rocksdb.block.cache-size=8M \
-Dstate.backend.rocksdb.block.blocksize=4kb \
-Dstate.backend.rocksdb.thread.num=2 \
-c com.mashibing.flinkjava.code.chapter12.RocksDBCKTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar RocksDB指标监控
Flink的监控指标系统支持监控RocksDB的原生指标。默认情况下,RocksDB的原生指标监控是未启用的,我们可以通过设置特定参数来启用。需要注意,一旦启用了RocksDB的原生指标监控,可能会对Flink应用程序的性能产生一定的影响。
Flink中开启RocksDB的原生指标监控需要设置"state.backend.latency-track.keyed-state-enabled"参数为true,该参数表示是否开启State状态性能监控,默认false,不跟踪监控State相关信息,开启该参数后,我们可以通过Flink WebUI查看Flink 任务中的一些状态写入延迟信息。
例如,我们在执行"RocksDBCKTest"Flink任务时,默认是看不到该任务中用户定义的ListState相关延迟状态,如果想要跟踪这些状态需要设置"state.backend.latency-track.keyed-state-enabled"参数为true。提交命令如下:
./flink run-application -t yarn-application \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockdb-state-dir \
-Dexecution.checkpointing.mode=exactly_once \
-Dstate.backend.incremental=true \
-Dstate.backend.latency-track.keyed-state-enabled=true \
-c com.mashibing.flinkjava.code.chapter12.RocksDBCKTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 任务提交后,我们可以通过WebUI查看Flink任务中设置状态的一些延迟指标,Flink针对每个并行度都有生成对应的监控指标。如下图所示。
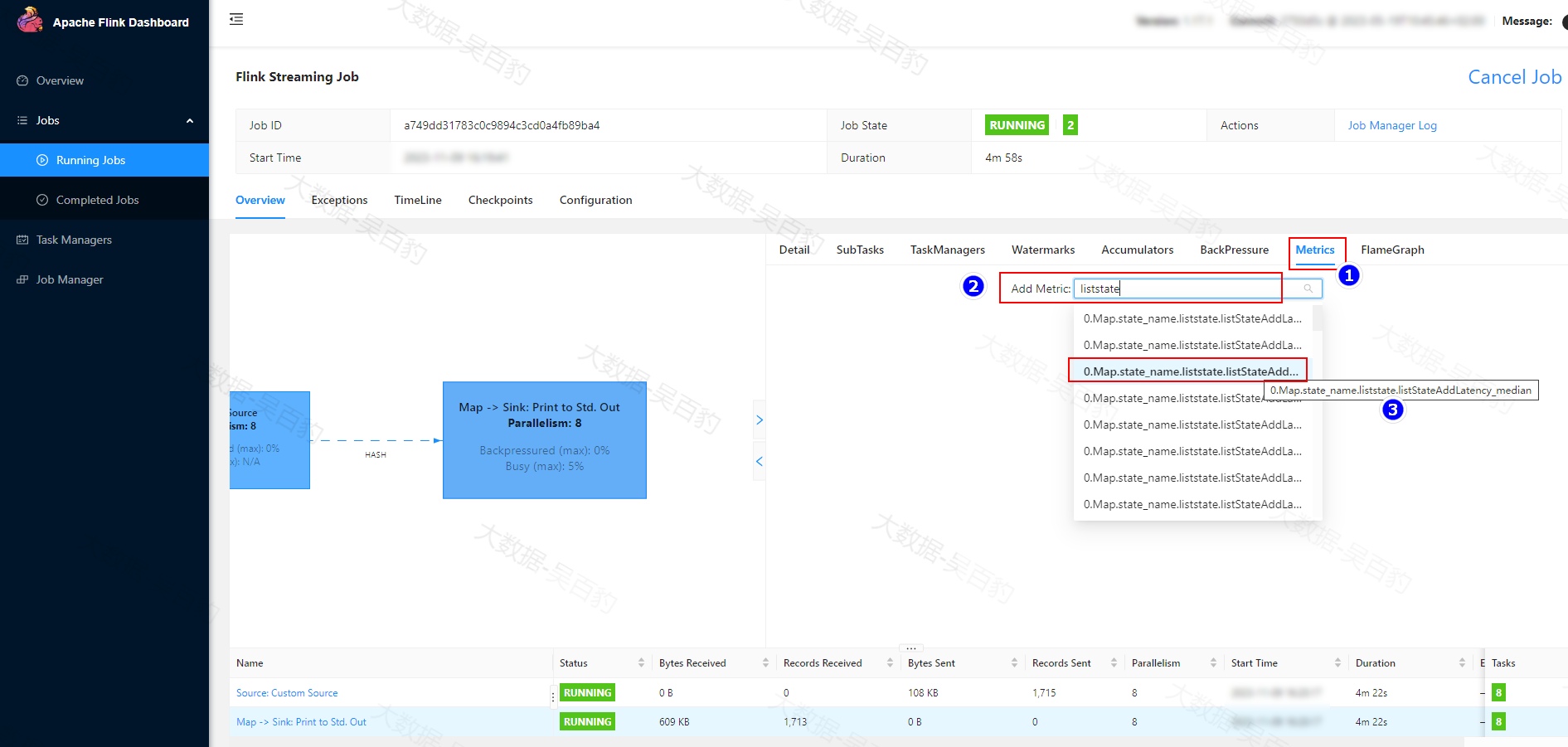
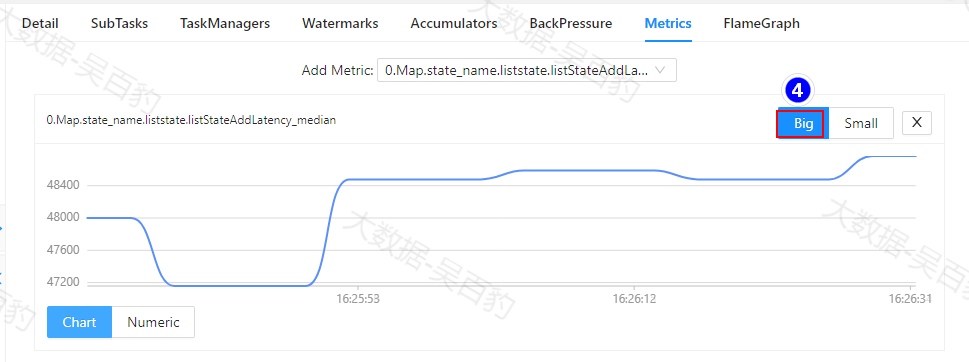
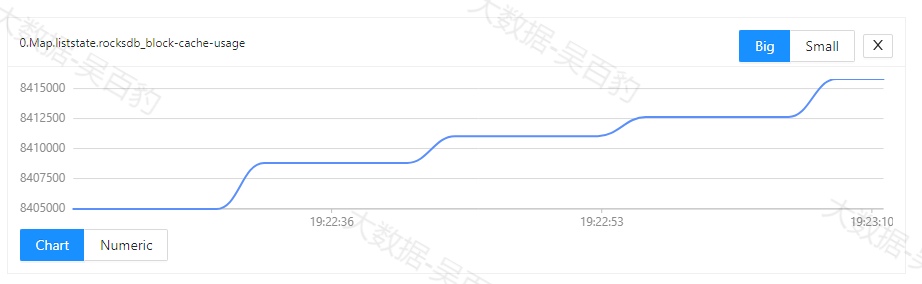
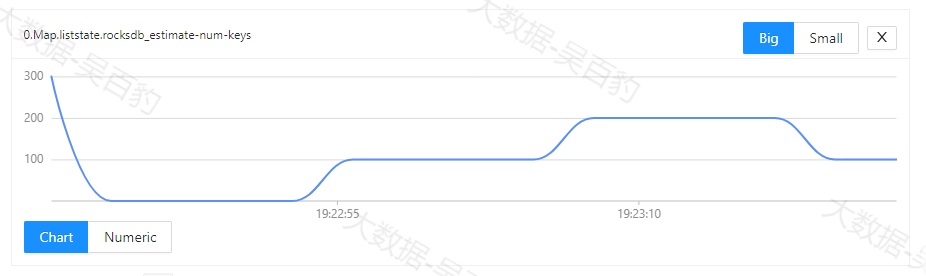
以上指标监控的是State写入的延迟中位数信息,单位是ns,例如上图中48000ns表示的写入延迟为0.48ms(1ms毫秒=1000us微秒=1000000ns纳秒)。我们也可以在提交Flink任务时,指定监控RocksDB的原生指标,常见的RocksDB监控指标如下:
- state.backend.rocksdb.metrics.actual-delayed-write-rate,默认false
监控RocksDB写延迟率,0表示没有延迟。
- state.backend.rocksdb.metrics.block-cache-capacity,默认false
监控RocksDB BlockCache 容量。
- state.backend.rocksdb.metrics.block-cache-pinned-usage,默认false
监控RocksDB BlockCache 中固定内存占用大小。
- state.backend.rocksdb.metrics.block-cache-usage,默认false
监控RocksDB BlockCache 内存占用情况。
- state.backend.rocksdb.metrics.bytes-written,默认false
监控RocksDB中Put()、Delete()、 Merge()、Write()操作写入的未压缩字节数,不包括压缩写入字节数。
- state.backend.rocksdb.metrics.cur-size-active-mem-table,默认false
监视活动memtable的大致大小(以字节为单位)。
- state.backend.rocksdb.metrics.cur-size-all-mem-tables,默认false
监视活动和未刷新的不可变memtable的大致大小(以字节为单位)。
- state.backend.rocksdb.metrics.estimate-num-keys,默认false
估计RocksDB中的键数。
- state.backend.rocksdb.metrics.is-write-stopped,默认false
跟踪RocksDB中写操作是否停止。如果写已停止返回1,否则返回0。
- state.backend.rocksdb.metrics.num-entries-active-mem-table,默认false
监视活动memtable中的条目总数。
- state.backend.rocksdb.metrics.num-running-flushes,默认false
监视当前正在运行的flush次数。
例如,我们在提交Flink任务时除了指定"state.backend.latency-track.keyed-state-enabled"参数外,还可以开启监控RocksDB指标,以提交Flink "RocksDBCKTest"任务为例,提交命令如下:
./flink run-application -t yarn-application \
-Dparallelism.default=8 \
-Dexecution.checkpointing.interval=1000 \
-Dstate.backend.type=rocksdb \
-Dstate.checkpoints.dir=hdfs://mycluster/rockdb-state-dir \
-Dexecution.checkpointing.mode=exactly_once \
-Dstate.backend.incremental=true \
-Dstate.backend.latency-track.keyed-state-enabled=true \
-Dstate.backend.rocksdb.metrics.block-cache-usage=true \
-Dstate.backend.rocksdb.metrics.estimate-num-keys \
-c com.wubaibao.flinkjava.code.chapter12.RocksDBCKTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 任务提交后,我们可以通过WebUI查看RocksDB监控指标。如下图所示。
imer状态保存
Flink中,当选择RocksDB作为State Backend时,Timer定时器会默认存储在RocksDB中,在 RocksDB 中维护计时器会有一定的成本,因此 Flink 也提供了将定时器存储在 JVM 堆上而使用 RocksDB 存储其他状态的选项。当Timer定时器数量较少时,基于堆的定时器可以有更好的性能。可以通过设置state.backend.rocksdb.timer-service.factory 参数为 heap来将Timer定时器存储在Jvm堆上提高性能。
设置状态生存时间TTL
此部分参考资源及代码优化小节内容。
Task本地恢复
在Flink Checkpoint机制中,每个task都生成其状态快照,然后将其写入分布式存储。每个task通过发送一个描述状态在分布式存储中位置的句柄来确认将状态成功写入JobManager。JobManager随后收集所有任务的句柄,并将它们捆绑到一个Checkpoint对象中。
在状态恢复的情况下,JobManager打开最新的Checkpoint对象,并将句柄发送回相应的tasks,tasks可以从分布式存储中恢复其状态。使用分布式存储来存储状态的优势是:状态具备容错及所有节点都可以从分布式存储中访问获取状态信息。
然而,使用远程分布式存储也有一个很大的缺点:所有tasks都必须通过网络从远程位置读取其状态。在许多情况下,恢复可以将失败的task重新调度到与先前运行相同的TaskManager中,但我们仍然必须从远程读取其状态,这可能导致大状态的长时间恢复。
Task本地恢复原理
为了解决Task恢复时从远程获取状态导致大状态恢复时间长的问题,Flink支持Task本地恢复。其思想如下:对于每个 checkpoint ,每个 task 不仅将 task 状态写入分布式存储中, 而且还在 task 本地存储(例如本地磁盘或内存)中保存状态快照的次要副本(secondary copy)。请注意,快照的主存储仍然必须是分布式存储,因为本地存储不能确保节点故障下的持久性,也不能为其他节点提供重新分发状态的访问,所以这个功能仍然需要保存状态快照的主副本(primary copy)。
这样,对于可以重新调度到以前的TaskManager节点进行恢复的 task ,我们可以从本地状态进行状态恢复,并避免远程读取状态的成本。考虑到许多故障不是节点故障,即使节点故障通常一次只影响一个或非常少的节点, 在恢复过程中,大多数 task 很可能会重新部署到它们以前的TaskManager节点,并从本地状态进行状态恢复,这就是 task 本地恢复有效地减少大状态恢复时间的原因。
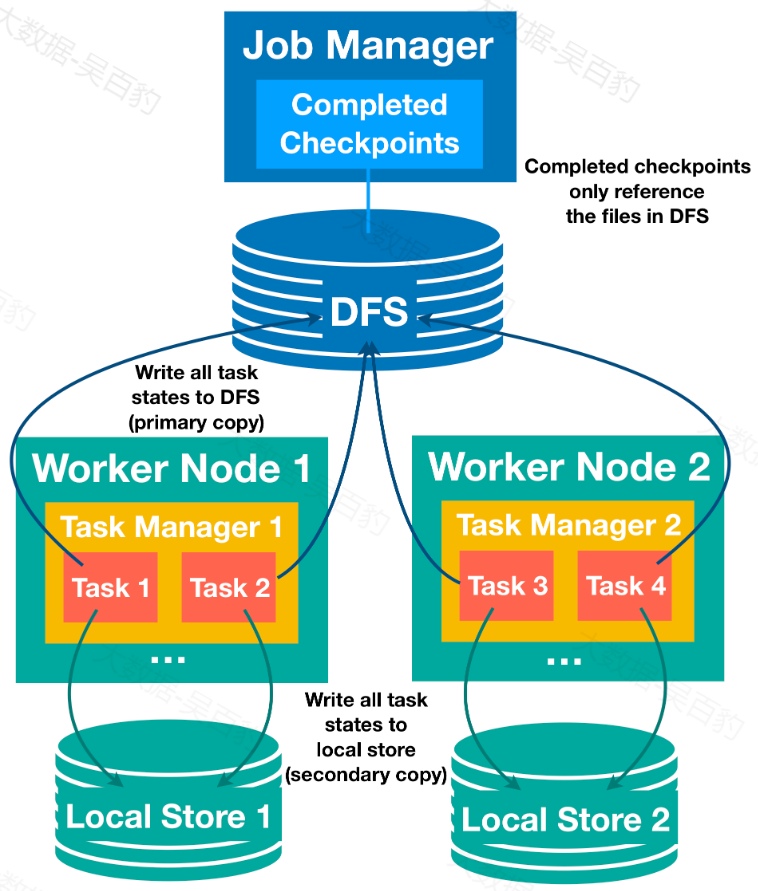
注意:在大多数情况下,本地次要副本实现只是简单地将对分布式存储的写操作复制到本地文件,性能上可能会有一些额外的成本。
分布式快照主副本(primary copy)和本地次要副本(secondary copy)有如下几点需要注意:
-
对于Checkpointing,主副本必须成功,并且生成的本地次要副本的失败不会使checkpoint失败。如果主副本创建失败,即使存在本地次要副本,checkpoint也是失败的。
-
Checkpoint 主副本和次要副本生命周期互不影响。主副本由JobManager进行管理,次要副本由TaskManager进行管理。
-
关于task恢复状态时,如果匹配的次要副本可用,Flink将始终首选从本地恢复task状态,如果在次要副本恢复过程中出现问题,Flink可以从主副本恢复task状态。仅当从主副本和次要副本恢复task都失败时,恢复才会失败。
-
Task本地副本可能仅包含完整task状态的一部分(例如:写入一个本地文件时出现异常)。这种情况下,Flink会首先尝试在本地恢复本地部分,非本地状态从主副本恢复。主状态必须始终是完整的,并且是task本地状态的超集。
-
Task本地状态可以存储在堆内存或者磁盘中。不必与Task 主状态保持一致。
-
如果TaskManager丢失,则所有task的本地状态都会丢失。
-
task本地恢复仅涵盖Keyed State ,不久的将来会支持算子状态和定时器状态。
-
unaligned checkpoint 目前不支持task本地恢复。
12.3.6.2 配置Task本地恢复
Task 本地恢复默认是禁用的,可以在提交Flink任务时通过设置state.backend.local-recovery参数为true 来启用。
网络内存优化
Flink数据传输机制
Flink架构中涉及JobManger、TaskManger角色,TaskManager中可以运行Task处理数据,为了更好的理解Flink Task之间的数据交换,我们需要先了解如下概念。
- JobManager
Flink Master节点,负责任务分配、协调、故障恢复。在JobManager中保存着Flink Job执行的逻辑拓扑图(ExecutionGraph)。
- TaskManager
Flink Worker节点,通过多线程执行task任务。每个TaskManager中包含一个CommunicationManager(负责通信,多个task之间共享)和一个MemoryManager(负责内存管理,多个task之间共享)。TaskManager之间通过TCP连接进行通信,一个TaskManager内的多个task和另一个TaskManager内的多个task之间数据通信复用同一个网络连接。在同一个TaskManager内部的多个task之间可能也需要通信,但内部通信不走网络连接,而是本地线程间的通信机制。
- ExecutionGraph
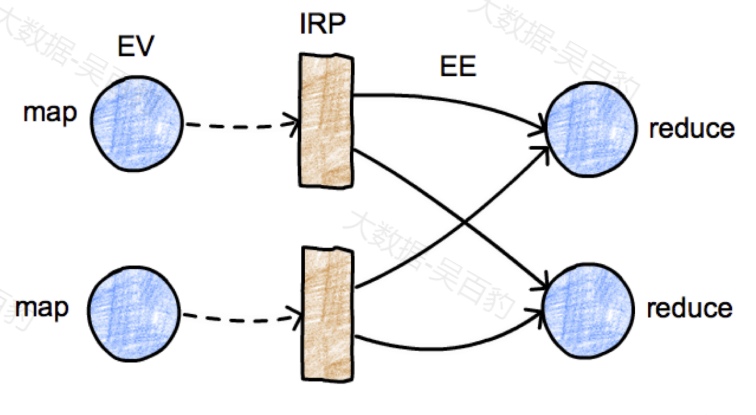
上图中的执行逻辑拓扑图由EV、IRP和EE组成。其中EV(ExecutionVertex,执行顶点)代表计算任务本身;IRP(Intermediate Result Partitioin,简称IRP/RP)代表计算任务产生的中间结果分区;EE(Execution Edge,执行边界)代表该计算任务负责消费上游任务产生的计算结果。
- ResultPartition(简称IRP/RP)
中间结果分区表示单个task任务计算后输出的一块数据写缓存区(BufferWriter),一个RP实际上包含多个Result Subpartition。
- ResultSubpartition(简称RS)
中间结果分区由上游的计算任务(EV)计算得到,其中的一个子分区对应下游的一个计算任务(EE)。
Flink任务在运行时,数据会在各个TaskManager之间进行流动交换,上游TaskManager和下游TaskManager之间的数据传输可以简单看做是生产者-消费者模式。下图展示了在Flink中数据传递交换机制,图中有两个TaskManager,每个TaskManager中各有一个maptask和reduce task,可以理解为2个算子。粗箭头代表数据流,细箭头代表系统通知。
Flink整个数据流传递交换是由数据的接收方触发的。首先,M1计算得到中间结果RP1(箭头1),当RP变的可用之后,会通知JobManager(箭头2),JobManager会将RP可用的消息通知到R1和R2(箭头3a和3b),R1和R2收到通知后会发起数据交换的请求(箭头4a和4b),该请求会触发数据的交换(箭头5a和5b),由此可见,Flink中数据交换本质上采用的是数据消费端"拉"模式。
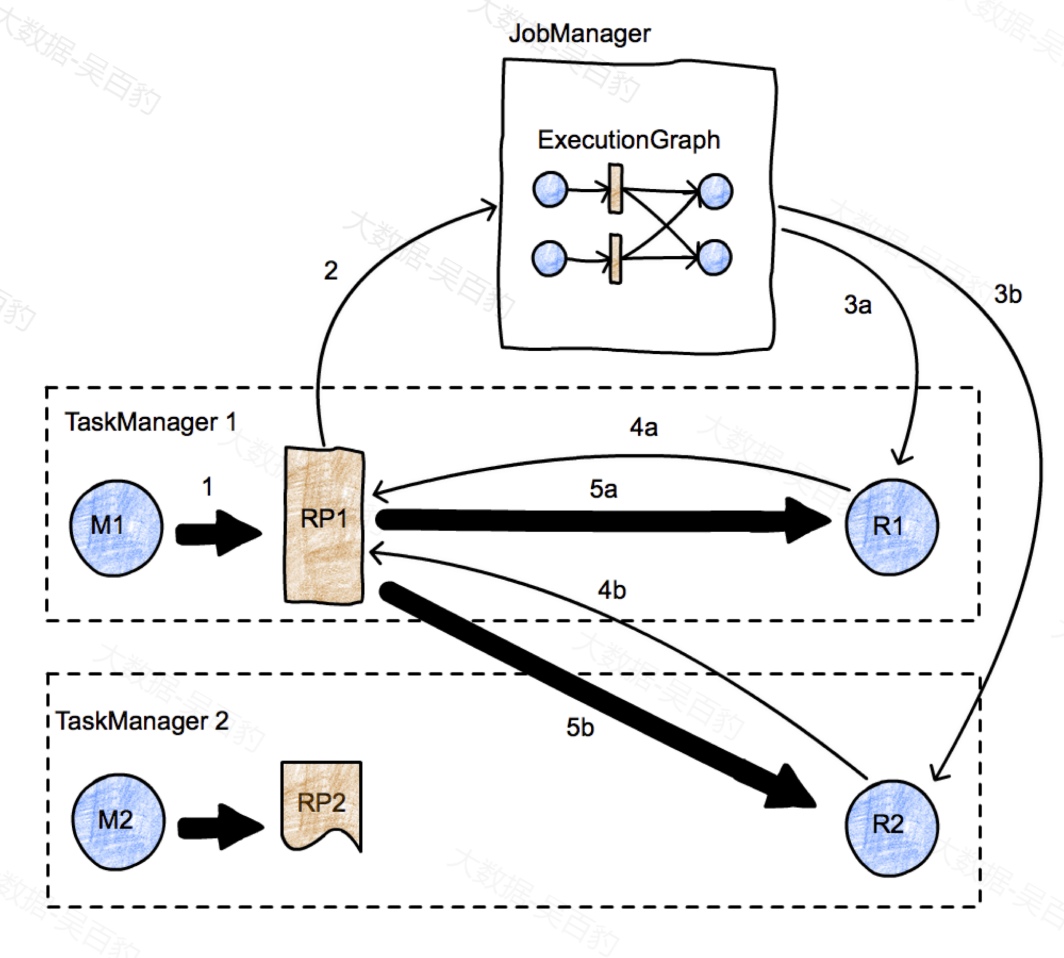
下图更详细的描述了数据从一个TaskManager传递到另一个TaskManager的生命周期。其中有一些概念如下:
- InputGate(简称IG)
在Task中,InputGate是对输入的封装,与数据写出端的ResultPartition逻辑等价。每个InputGate消费一个或者多个ResultPartition。
- InputChannel(简称IC)
InputChannel负责收集ResultSubpartitoin中的数据。InputGate由多个InputChannel构成,InputChannel和ResultSubpartition一一相连,一个 InputChannel接收一个ResultSubpartition 的输出。
- buffer
Flink网络层数据交换的最小单元,承载序列化后的数据,以直接内存方式分配,由参数 taskmanager.memory.segment-size 配置,默认为32Kb。
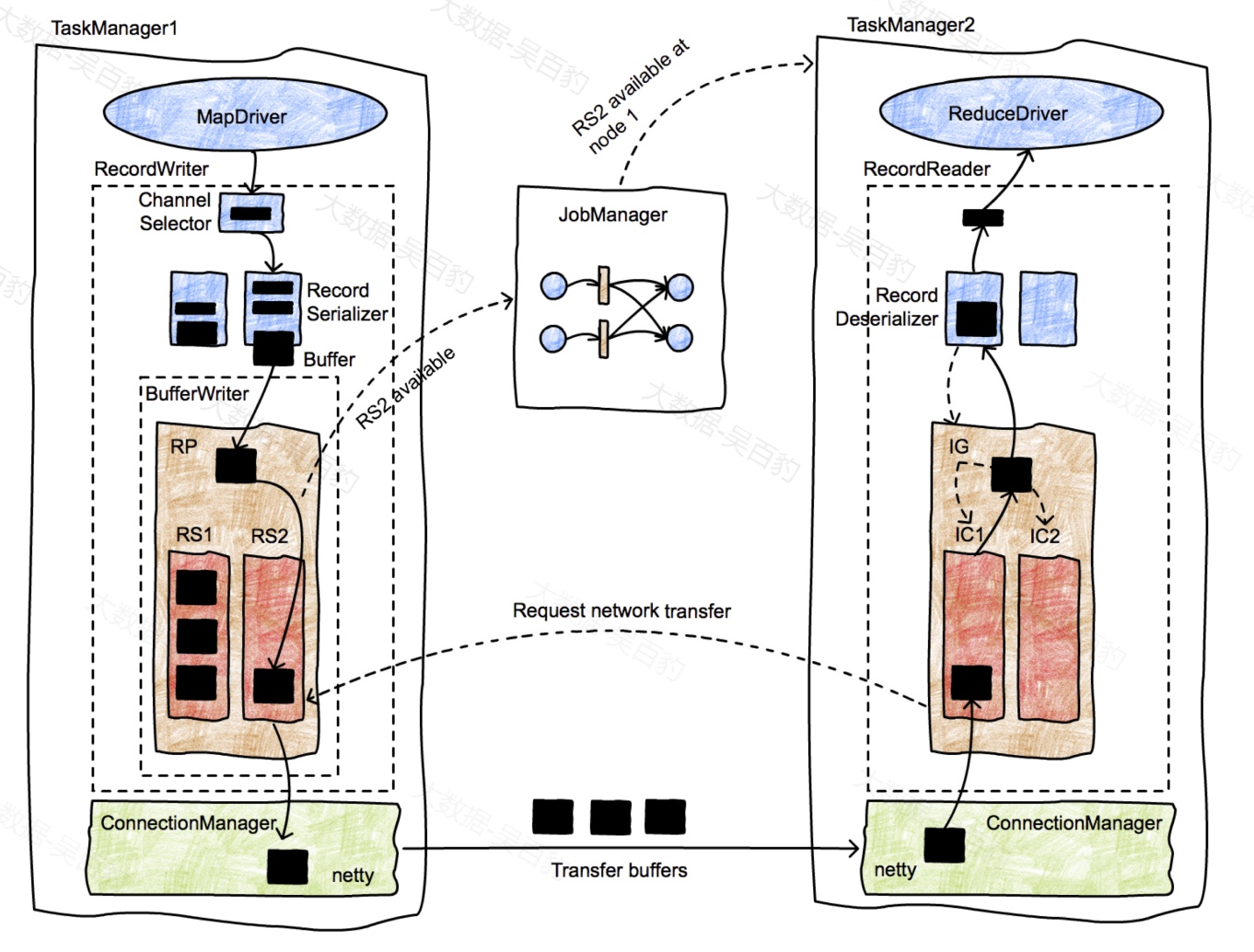
最初,MapDriver生成记录(由Collector收集),然后传递给RecordWriter对象。RecordWriters包含多个序列化器(RecordSerializer对象),每个序列化器对应可能消费这些记录的一个消费者任务。例如,在洗牌或广播中,将有与消费者任务数量相同的序列化器。ChannelSelector选择一个或多个序列化器来放置记录。例如,如果记录是广播的,它们将放置在每个序列化器中。如果记录经过哈希分区,ChannelSelector将计算记录的哈希值并选择适当的序列化器。
序列化器将记录序列化为它们的二进制表示,并将它们放置在固定大小的缓冲区中(记录可以跨越多个缓冲区)。这些缓冲区交给BufferWriter并写入ResultPartition(RP)。RP由多个子分区(ResultSubpartitions - RSs)组成,用于收集消费者消费数据的缓冲区。上图中当RS2准备好数据后,会通知JobManager数据可用。
JobManager会通知到TaskManager 2有数据块可用并查找RS2的消费者,找到应接收此缓冲区的InputChannel,然后InputChannel通知RS2可以启动网络传输。然后,RS2将缓冲区交给TM1的网络堆栈,然后由netty进行传输。TaskManager节点之间的网络连接是长期存在的,而不是每个任务都创建网络连接。
一旦缓冲区被TM2接收,数据将通过一个类似数据写出端的对象层次结构,从InputChannel开始,到InputGate,最后在RecordDeserializer中结束,该RecordDeserializer从缓冲区生成类型记录,并将它们交给接收ReduceDriver进行处理。
Flink数据反压机制
前面内容中我们了解了Flink数据传输机制本质上是生产者-消费者模式,这种模式中,当上游和下游数据处理的速度不一致时就会出现数据堵塞问题,为了应对这种情况,Flink引入了动态反馈机制------反压机制,这种机制可以根据实时数据传输情况调整数据的发送和接收速率,以更好的进行网络数据传输。
Flink反压机制有两种:"基于TCP的反压机制"和"基于Credit的反压机制",Flink1.5版本之前使用"基于TCP的反压机制",1.5版本之后默认采用"基于Credit的反压机制",下面分别对这两种机制进行介绍。
基于TCP的反压机制
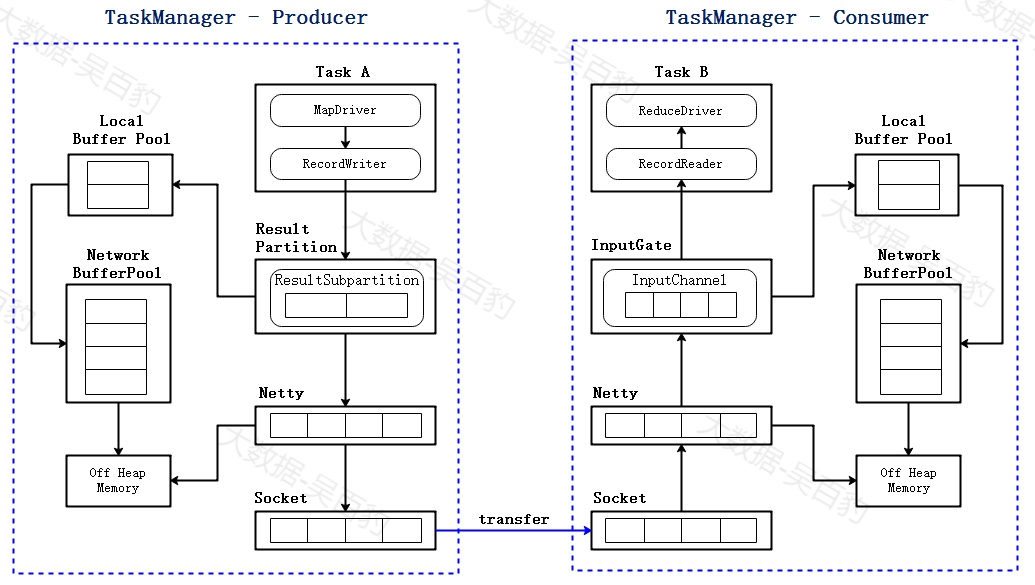
上图表示两个TaskManager之间传递数据流程,每个TaskManager中都会有个被内部所有task共享的NetworkBuffer Pool,它从堆外内存申请内存资源,可以为每个ResultSubpartition/InputChannel创建Local Buffer Pool。
假设Producer产生数据的速度比Consumer消费数据的速度快,那么经过一段时间,各层buffer被打满,从而引起反压的过程。
基于TCP的反压机制流程如下:
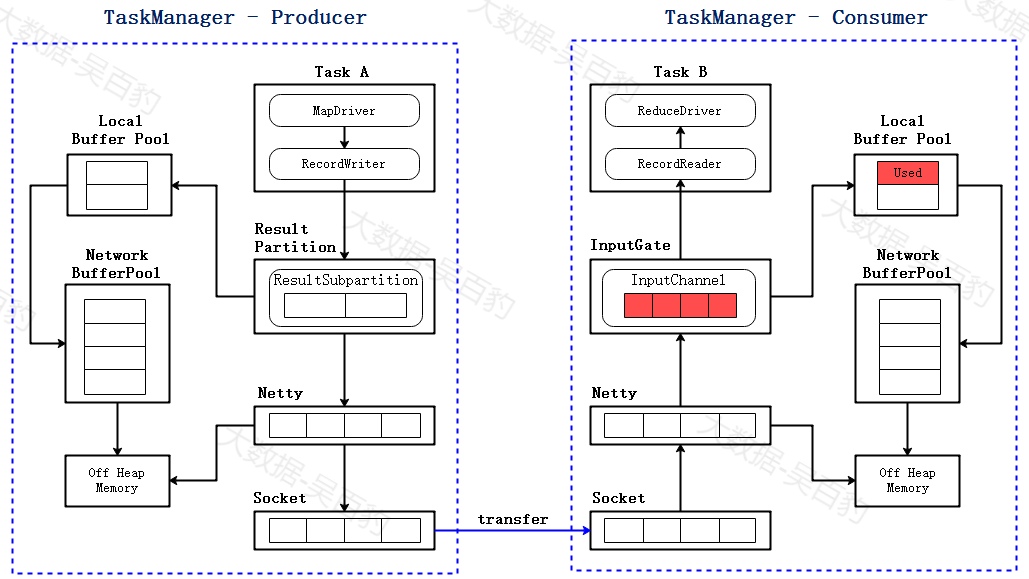
1) InputChannel Buffer打满
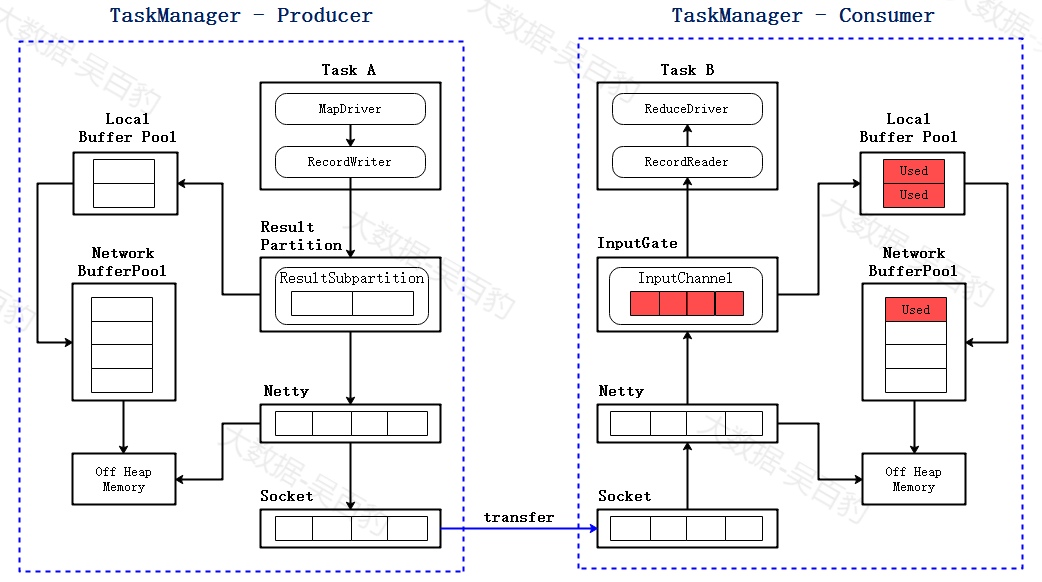
由于消费者处理速度慢,一段时间后会达到下图状态:InputChannel暂时被打满,需要向Local Buffer Pool申请新的Buffer,此时Local Buffer Pool里的一个buffer被标记为Used。
2) Consumer Local Buffer Pool打满
由于下游处理数据慢,一段时间后,InputChannel将Local Buffer Pool的内存申请完,此时Local Buffer Pool所有的buffer都被标记为Used,但还可以向Network Buffer Pool继续申请buffer。
3) Consumer Network Buffer Pool 打满
慢慢的Network Buffer Pool 也没有可用的buffer,全都变成了Used,此时消费者无法再读取数据,Netty也不会接收Socket的数据。
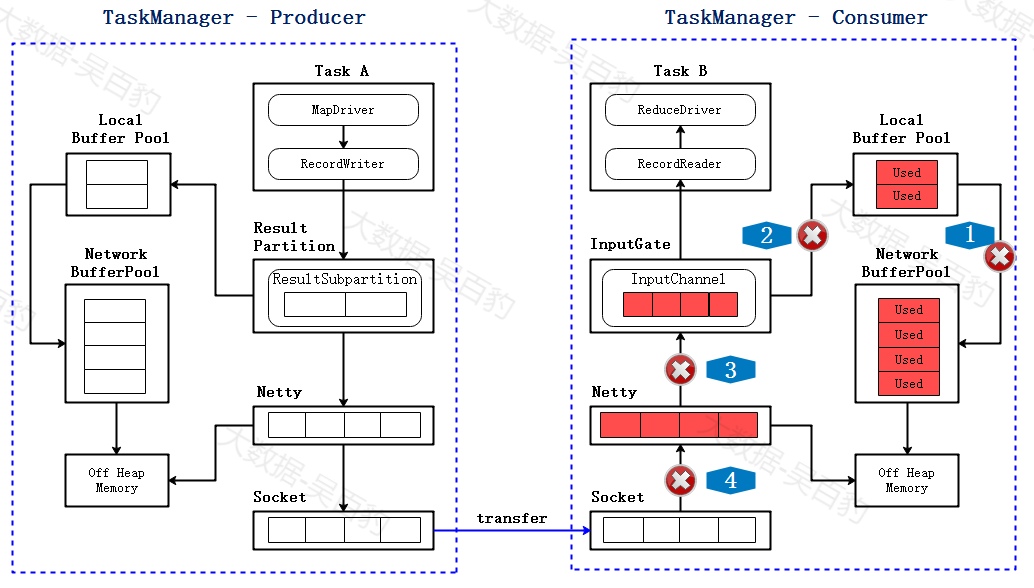
4) Socket停止数据传输
当消费者的socket被用尽,此时会反馈给生产者端,socket会停止发送数据。
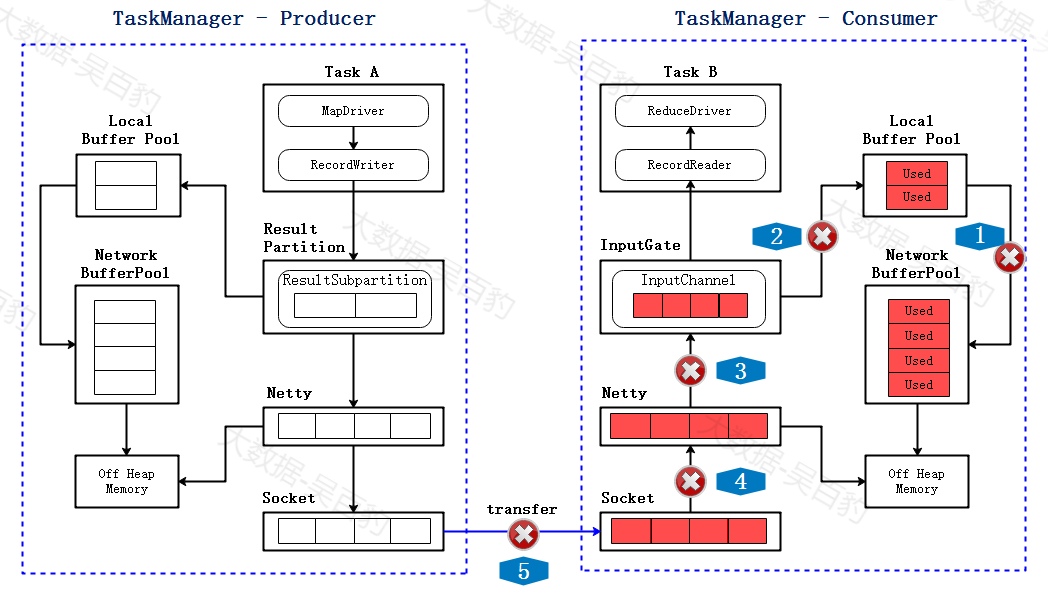
5) Netty 不可写
不久socket buffer用尽,Netty检测到后会停止向socket发送数据,之后由于RecordWriter还在发送数据,这些数据会堆积在Netty Buffer中,到一定程度后,Netty会变成不可写的状态。
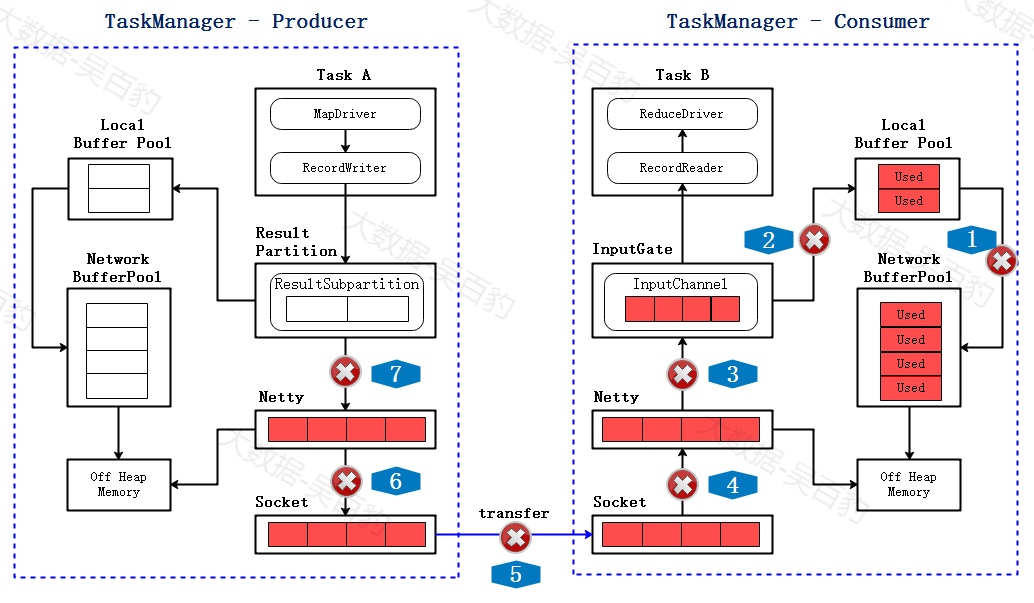
6) RecordWriter 停止写数据
ResultSubpartition 空间很快被用尽,直到Local Buffer Pool 和Net Buffer Pool的Buffer都被打满后,RecordWriter就会停止写数据,至此,完成了跨TaskManager的反压。
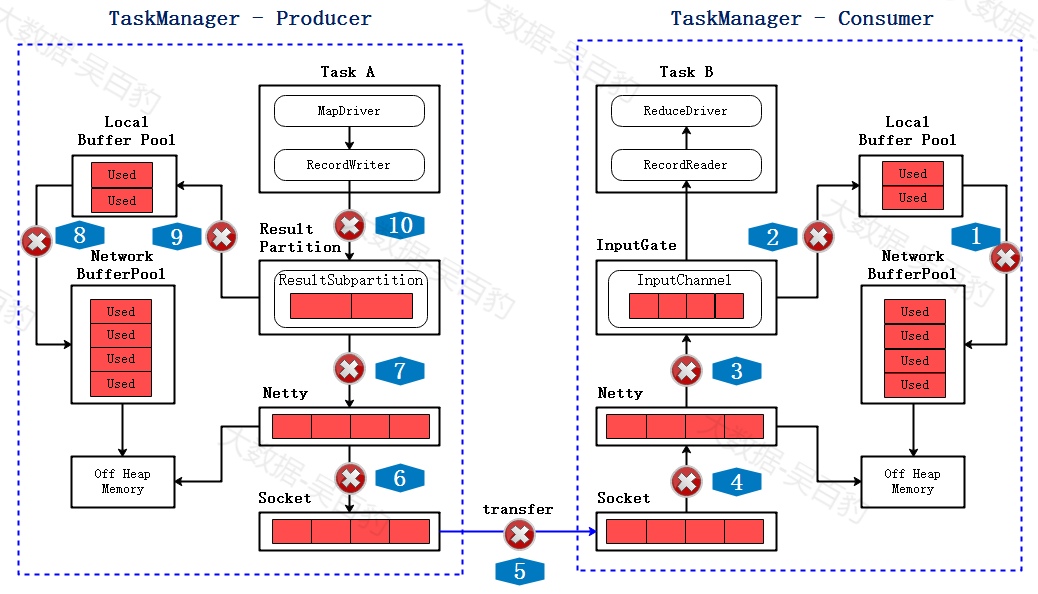
基于TCP的反压机制有如下问题:
-
一个TaskManager内通常会有多个Task,它们底层会复用同一个Socket,一旦某个Task反压导致Socket阻塞不可用,即使其他Task关联的缓冲池仍然有空余,也都无法向TCP连接中写入数据或者从中读取数据。
-
基于底层TCP的反压机制从InputChannel到Netty再到ResultSubpartition整条链路较长,会导致反压行为不够灵敏,动态反馈过程比较迟钝。
基于Credit的反压机制
为了解决以上问题,Flink1.5后重构了网络栈,引入"基于Credit的反压机制",主要解决了数据反压链路长、TaskManager之间网络连接在反压下处于阻塞的问题。
基于Credit的反压机制思路非常简单,它在数据接收端和发送端建立了一种类似"信用评级"的机制,发送端向接收端发送的数据永远不会超过接收端的信用值大小。对于Flink来说,信用值就是接收端TaskManager可用的buffer数量,这样就可以保证发送端TaskManager不会向TCP连接中发送超过接收端缓冲区可用容量的数据。
基于Credit实现数据反压具体流程如下:
-
当发送端发送buffer的时候,会将当前堆积数据的buffer数量(backlog size)告知接收端。
-
接收端将根据发送端堆积的数量来申请buffer。
-
接收端向发送端声明可用的Credit(一个可用的buffer对应一个credit)。
-
当接收端分配了N点Credit给发送端,表明它有N个空闲的buffer可以接收数据。
-
当发送端获得了N点Credit,表明它可以向网络中发送N个buffer。
-
只有在credit>0的情况下发送端才发送buffer,当发送端每发送一个buffer,credit也相应的减少。
如下图所示,当前ResultPartition已经堆积了两个buffer数据,在底层网络传输时会将要传输的数据以及backlog size =2 发送至接收端,下游接收到后会根据接收到的backlog sieze及剩余的buffer计算credit信用值,假设这里返回credit为5,表示接收端还可以接收5个buffer数据。
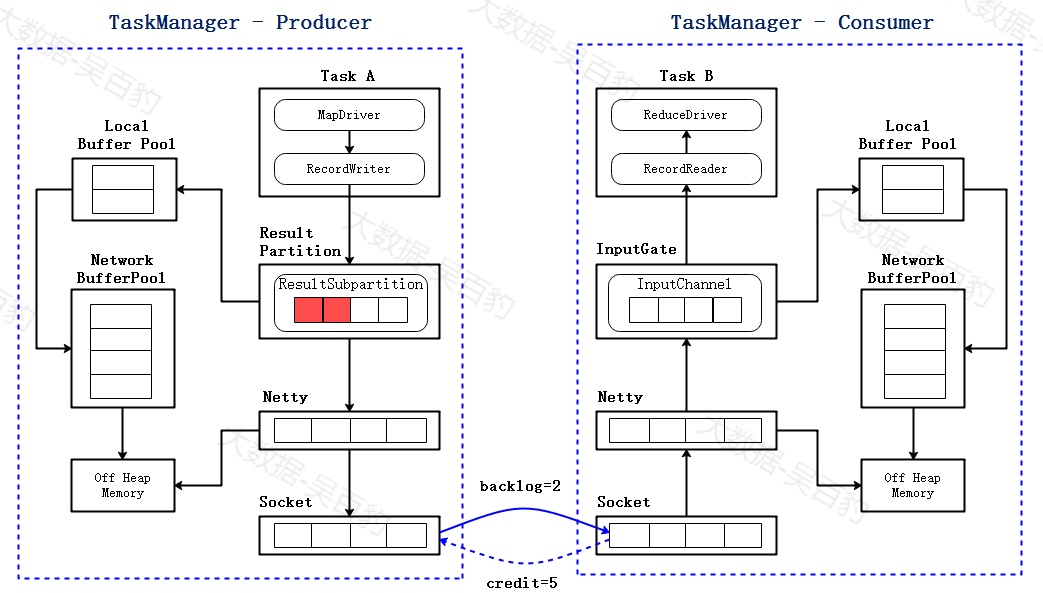
当接收端各级buffer打满后,下游会向上游返回credit为0,说明由于上下级处理速率不一致,导致了下游暂时无法处理数据,此时ResultPartition就不会向Netty传输数据,数据很快打满,从而达到反压效果。
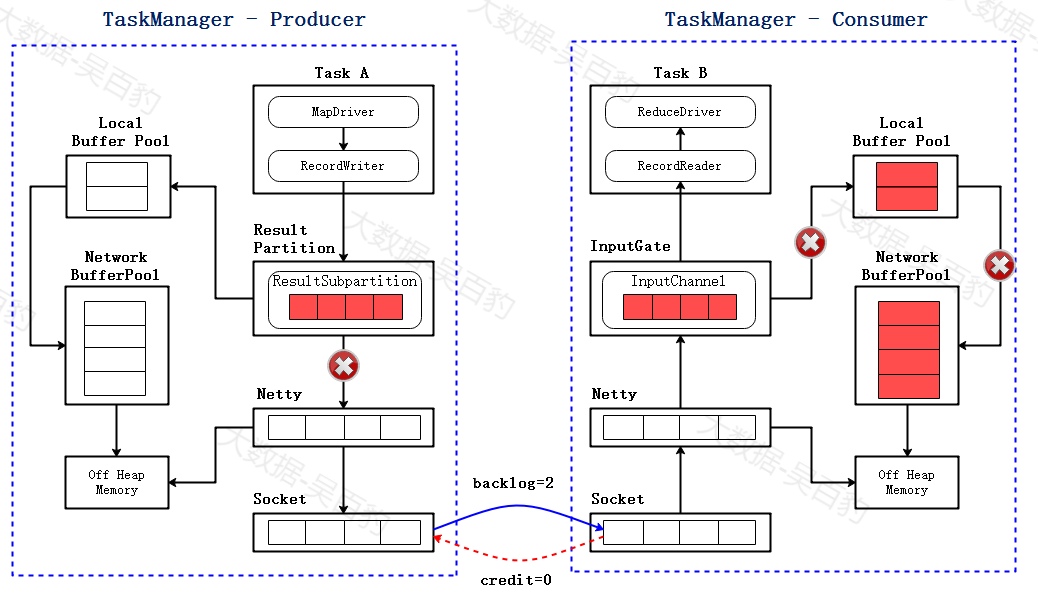
基于Credit的反压机制主要解决了如下问题:
-
可以在ResultPartition层面实现反压,而不用将压力流经多层传递,层层反馈,降低了延迟。
-
不会把底层socket打满,从而阻碍网络传输数据,不会让单个Task的瓶颈成为整个TaskManager的瓶颈。
网络内存优化
Flink中每条消息都会被放到网络缓冲(network buffer)中,并以此为最小单位发送到下一个subtask,为了维持连续的高吞吐,Flink在传输数据过程中输入端和输出端都有多个本地缓冲区池。每个输出和输入流对应的缓冲区池的目标缓冲区数由下面公式计算得到。
channels*taskmanager.network.memory.buffers-per-channel+ taskmanager.network.memory.floating-buffers-per-gate
以上公式中channels表示通道,即输入/输出的并行度,通过该公式可以计算输出和输入缓冲区使用的buffer总数量,然后根据每个缓冲区(Buffer)的大小(可通过参数taskmanager.memory.segment-size 来设置)可以估算Flink每个操作输入/输出缓冲区大小。
关于输出/输入缓冲区的一些参数配置项解释如下:
- taskmanager.memory.segment-size
该值表示一个网络缓冲(network buffer)大小,默认值32kb。
- taskmanager.network.memory.buffers-per-channel
该参数表示在基于 credit 的流控制模型中,每个 Subpartition/Input Channel 独占网络缓冲区数,默认值为2。对于Subpartition,该值是每个channel的有效独占buffer数;对于InputChannel,该值是每个channel独占buffer的最大值,每个channel的有效独占buffer数量根据taskmanager.network.memory.read-buffer.required-per-gate.max 动态计算,有效范围从0到配置值。
- taskmanager.network.memory.read-buffer.required-per-gate.max
该值表示InputGate所需的网络读缓冲区(buffer)的最大数目阈值,在Flink流式计算中该值默认为Integer.MAX_VALUE,在Flink批处理中,该值为1000。InputGate所需的缓冲区数量取决于各种因素(例如上游任务的并行度),会在运行时动态计算。当动态计算得到的网络缓冲区数目小于该阈值的部分被称为必须(Required)缓冲区,剩余的部分(如果有的话)是可选(Optional)缓冲区,如果无法获得必须缓冲区,会导致Flink任务失败,如果无法获得可选缓冲区,Flink任务不会失败,但可能会降低性能。
通常,该阈值越小,出现"网络缓冲区数量不足"异常的可能性越小,但Flink工作性能可能会降低,反之依然。不建议用户更改该值,除非用户有充足的理由修改它,并明确该阈值带来的影响。
- taskmanager.network.memory.floating-buffers-per-gate
该参数表示在基于 credit 的流控制模型中,每个ResultPartition/Inputgates在所有channels之间能共享的浮动网络缓冲区(buffer)数目,默认为8。浮动buffers可以缓解由于Subpartitions之间数据分布不平衡而造成的背压问题。对于ResultPartition,该值是每个ResultPartition有效浮动buffer数;对于InputGate,每个InputGate的有效浮动网络缓冲区的数量是根据taskmanager.network.memory.read-buffer.required-per-gate.max动态计算,有效浮动缓冲区的范围是从0到(parallelism-1)。
- taskmanager.network.memory.max-overdraft-buffers-per-gate
该参数表示每个ResultPartition使用的最大透支网络缓冲区数,默认值为5。当 subtask 被下游 subtasks 反压且当前 subtask 需要请求超过 1 个网络缓冲区(network buffer)才能完成当前的操作时,将使用透支缓冲区,例如序列化大记录,不能放入单个网络缓冲区中;为单个输入记录生成多个记录的flatMap操作;或周期性地或某些事件触发产生大量 records 的算子(例如:WindowOperator 的触发)。在这种情况下,系统将允许subtask请求透支缓冲区,这样子任务就可以完成这种不可中断的操作,而不会长时间阻塞unaligned checkpoints。只有当系统有一些未使用的缓冲区可用时,才会提供透支缓冲区,使用透支缓冲区的subtask将不允许再处理任何记录,直到透支缓冲区返回到池中。
网络缓存消胀(Buffer Debloating)机制
在Flink中进行checkpoint时,需要所有的subtask都收到对应的barrier才能完成checkpoint快照。在barrier对齐或者非对齐的checkpoint场景中,只要多个subtask处理数据速度不一致都需要缓存数据更多数据,这些数据就存放在网络缓冲(network buffer)中。关于网络缓存,一般只需要调整内存参数taskmanager.memory.network.fraction(网络缓存占Flink总内存taskmanager.memory.flink.size的比例,默认值0.1)即可。内部一些网络输出/输入缓冲区的一些参数默认也都是静态的(通过指定缓冲区的数量和大小),针对同一个Flink应用运行时,需要调节这些网络缓存底层参数时很难有统一的完美参数,如果缓存大量数据会导致内存空间浪费以及checkpoint时间过长。为了解决以上这个问题,Flink1.14引入了网络缓存消胀(Network Buffer Debloating)机制尝试通过自动调整缓冲数据量到一个合理值。
网络缓冲消胀机制原理是根据一个预设的消费时间阈值和一定时间段内的数据吞吐量来动态调节接收端的Buffer大小。可以通过设置 taskmanager.network.memory.buffer-debloat.enabled 为 true 来开启缓冲消胀机制。关于网络缓存消胀机制更多可调参数如下:
-
taskmanager.network.memory.buffer-debloat.target:缓存数据被接收方消费的期望时间阈值,默认1s。默认值能满足大多数场景。
-
taskmanager.network.memory.buffer-debloat.period:这是缓冲区大小重算的最小时间周期。默认值200ms。周期越小,缓冲消胀机制的反应时间就越快,但是必要的计算会消耗更多的CPU。
-
taskmanager.network.memory.buffer-debloat.samples:调整用于计算平均吞吐量的采样数。默认20。采集样本的频率可以通过 taskmanager.network.memory.buffer-debloat.period 来设置。样本数越少,缓冲消胀机制的反应时间就越快,但是当吞吐量突然飙升或者下降时,缓冲消胀机制计算的最佳缓冲数据量会更容易出错。
-
taskmanager.network.memory.buffer-debloat.threshold-percentages:缓存消胀过程中的新旧Buffer相对变化率的阈值,默认为25(即25%)。若变化率小于此值,则不执行Debloat操作,可以避免频繁调整产生性能抖动。
以上参数一般选择默认值即可,只需要设置开启缓存消胀机制即可,如果Flink作业复杂经常变化,例如:突如其来的数据尖峰、定期窗口聚合、大量数据join ,可以适当减少taskmanager.network.memory.buffer-debloat.period、taskmanager.network.memory.buffer-debloat.samples参数,以到达更快自动调节缓冲区大小目的。
网络缓存消胀机制使用目前也有一些限制,如下:
-
如果Flink作业中的subtask有很多不同的输入或者有一个合并的输入,开启缓存消胀机制后可能会导致低吞吐的subtask输入有太多缓存数据,从而导致高吞吐输入的缓冲区数量太少而不够维持当前吞吐。
-
开启缓存消胀机制与Flink应用程序使用的缓冲区大小不冲突,也就是说缓存消胀机制仅在使用的缓冲区上设置上限,Flink作业实际的缓冲区大小和个数保持不变。
缓冲区大小和数量建议
- 关于缓冲区大小建议
网络缓冲区用于收集记录,以优化将数据部分发送到下一个子任务时的网络开销,保证数据传输的高吞吐,如果缓冲区太小,或缓冲区刷新太频繁,由于每个缓冲区的开销明显高于Flink运行时的每条记录开销,这可能导致吞吐量下降。如果缓冲区太大,会导致内存使用增多、checkpoint变大、checkpoint周期变长、内存使用率低(当缓冲区刷新周期较短时,默认100ms,可能缓冲区还没有被塞满,数据就被发送到下游,导致分配内存使用效率低下)这些问题,所以根据经验,我们不建议考虑增加缓冲区大小,保持默认值即可,除非在实际Flink任务中观察到网络瓶颈。
- 关于缓冲区数量建议
通过前面小节的学习,我们了解到缓冲区的数量是通过taskmanager.network.memory.buffers-per-channel和taskmanager.network.memory.floating-buffers-per-gate 来配置的。为了最好的吞吐率,关于缓冲区数量调优总体思路是建议使用独占缓冲区和流动缓冲区的默认值,如果缓冲数据量存在问题,更建议打开缓冲消胀。
如果吞吐效果不佳,你可以关闭缓冲消胀机制并人工调整网络缓冲区个数。需要注意以下三点。
- 可以通过如下公式计算维持吞吐所需要的缓冲区数量
number_of_buffers = expected_throughput * buffer_roundtrip / buffer_size
expected_throughput 表示期待的数据吞吐量(单位bytes/second);buffer_roundtrip表示数据在节点之间往返时间延迟,一般为1ms;buffer_size表示缓冲区大小,默认为32kb。例如,期待吞吐量为 320MB/s,往返延迟为 1ms,缓冲区为默认大小,为了维持吞吐需要使用10个活跃的缓冲区(number_of_buffers = 320MB/s * 1ms / 32KB = 10)。
-
流动缓冲区的目的是为了处理数据倾斜。理想情况下,流动缓冲区的数量(默认8个)和每个通道独占缓冲区的数量(默认2个)能够使网络吞吐量饱和。
-
独占缓冲区的目的是提供一个流畅的吞吐量,也就是当一个缓冲区在传输数据时,另一个缓冲区被填充。当吞吐量比较高时,独占缓冲区的数量是决定 Flink 中缓冲数据的主要因素,可以适当增加独占缓冲区;当低吞吐量下出现反压时,应该考虑减少独占缓冲区,这种情况下数据处理慢,给太多独占缓冲区也是浪费内存。
Flink反压优化
在Flink中,反压是指当一个任务(task)生成数据的速率超过下游任务消费数据的速率时触发的警告。以一个简单的Source -> Sink任务链为例,如果Source生成数据的速率高于Sink消费数据的速率,就会发生反压警告。这表示数据流向下游,但由于下游处理速度较慢,系统发出警告以通知上游任务,反压信息沿着相反的方向传播,向上游传递,帮助系统调整任务链以维持平衡,防止性能问题。
Flink任务中出现反压会有如下影响:
-
Flink任务处理性能下降:反压会导致任务链中某些任务被迫减缓数据生成速率,以适应下游任务的处理速度,从而影响整体性能。如:Flink消费Kafka数据时,反压会导致Kafka数据消费有很大滞后。
-
checkpoint时间长或失败:Flink任务出现反压会使数据处理速度变慢,甚至是数据阻塞,这将导致Checkpoint barrier流经整个数据管道的时间变长,进而Checkpoint的总体时间变长,甚至导致Checkpoint失败。
-
内存OOM:在checkpoint barrier对齐下的Exactly-once场景中,由于部分并行度的反压,将导致barrier缓慢到达,数据处理快的并行度会将数据缓存起来以等待数据处理缓慢并行度的barrier对齐,这样可能会导致并行度快的数据一直积压到内存中,导致State占用大量内存资源,最终可能出现OOM问题。
-
任务卡住:在下游有窗口的计算逻辑中,如果上游出现数据持续反压,将导致watermark一直不往下游流动,这时导致窗口一直不触发,出现任务卡住情况。
Flink反压问题定位
Flink WebUI提供了Flink 任务运行时的JobGraph图,通过查看该图我们很方便的确定Flink任务是否有反压。在WebUI界面中的JobGraph图中每个算子链默认展示了所有SubTasks的反压和繁忙指标的最大值,如下图所示:
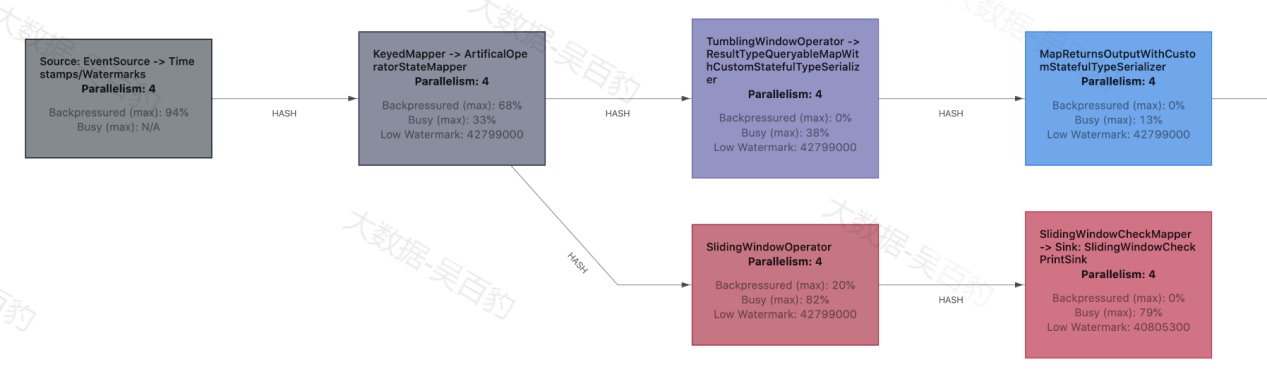
在JobGraph图中除了显示原始的数值外,task也用不同颜色进行了标记,闲置的 tasks 为蓝色,完全被反压的 tasks 为黑色,完全繁忙的 tasks 被标记为红色。 中间的所有值都表示为这三种颜色之间的过渡色。
通过Flink WebUI我们大体能判断Flink Job是否存在反压,但由于Flink默认会将多个算子合并成算子链,通过JobGraph我们只能看到存在反压的算子链,无法具体定位到某个存在反压的算子,这时我们就需要拆成多个步骤来定位具体出现反压的算子,进而定位Flink出现反压的具体原因。
可以按照如下步骤进行Flink任务反压问题定位。
-
Flink任务禁用算子链后运行Flink任务。
-
根据JobGrap定位出现反压的位置。
-
结合WebUI Task执行情况定位问题点。
-
解决问题点。
下面我们通过一个Flink案例来说明如何一步步定位Flink反压问题,找出出现反压具体原因。有如下存在反压问题的Flink代码:
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(8);
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
while (flag) {
String sid = "sid_" + random.nextInt(10);
if (sid.equals("sid_0")) {
for (int i = 0; i < 1000; i++) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
Thread.sleep(200);
} else {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
Thread.sleep(200);
}
}
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//过滤通话状态为fail的数据
SingleOutputStreamOperator<StationLog> ds2 = ds1.filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return !"fail".equals(value.callType);
}
});
//对数据进行keyby
KeyedStream<StationLog, String> ds3 = ds2.keyBy(new KeySelector<StationLog, String>() {
@Override
public String getKey(StationLog value) throws Exception {
return value.sid;
}
});
//对数据进行聚合操作
SingleOutputStreamOperator<StationLog> ds4 = ds3.sum("duration");
SingleOutputStreamOperator<String> result = ds4.map(new MapFunction<StationLog, String>() {
@Override
public String map(StationLog value) throws Exception {
Thread.sleep(1);
return "基站ID:" + value.sid + ",通话时长:" + value.duration;
}
});
result .print();
env.execute();以上Flink代码中我们通过自定义数据源来产生基站日志数据,产生每条数据的间隔为200ms,当基站为"sid_0"时,立即生产1000条基站为"sid_0"的数据,后续针对这些数据按照基站进行分组,统计每个基站的通话总时长,模拟出数据按照基站分组时存在数据倾斜。在统计得到每个基站总通话时长后,对数据进行转换,处理每条数据时暂停1毫秒。由于数据存在倾斜并且每条数据暂停处理1毫秒会导致下游处理数据的速度小于上游产生数据的速度,进而出现反压现象。
运行以上案例时,我们基于本地运行环境运行,代码中开启了本地WebUI,代码运行后,可以在登录https://localhost:8081进入 Flink WebUI查看Flink任务出现反压。当代码运行一段时间后,Flink Job出现反压如下:
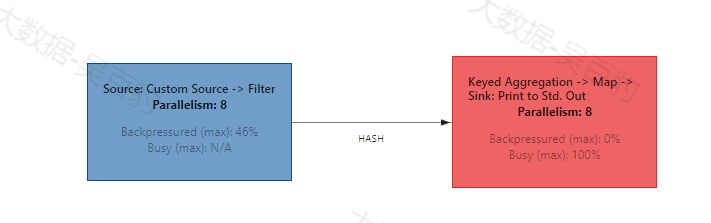
通过上图,我们只能定位到某个算子链中存在反压情况,定位不到反压出现的具体原因,需要按照步骤一步步定位出现反压原因。
1) 代码设置禁用算子链并重新运行,查看任务反压情况
在Flink代码中禁用算子链,Flink DataStream和FlinkSQL中禁用算子链方式如下:
#DataStream 设置方式
env.disableOperatorChaining();
#FlinkSQL中设置方式
tableEnv.getConfig().set("pipeline.operator-chaining",false)设置禁用算子链后,重新运行代码,每隔几秒刷新Flink WebUI可以看到如下反压情况:

我们可以看到由于在代码map算子中处理每条数据暂停1毫秒导致Map算子处理数据非常繁忙,进而导致数据按照数据流反方向一层层进行反压。
2) 根据JobGrap定位出现反压的位置
在Flink中当上游算子在WebUI显示有反压时,一般是下游算子存在性能问题,可以继续向下游算子进行排查,直到没有出现反压的算法为止,往往该算子处于繁忙状态,该算子极有可能出现性能问题。
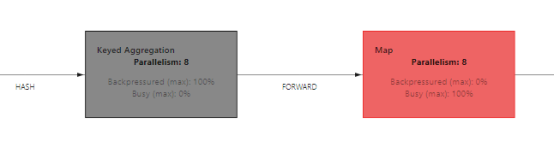
例如:在以上运行任务中,最开始出现反压的操作为"Keyed Aggregation",定位反压就找该操作下游算子Map,通过WebUI我们可以看到Map没有出现反压且处于繁忙状态,那么该算子可能存在性能问题。如果Map算子也出现了反压,那就继续向下游进行排查,直到找到没有出现反压的算子为止,说明当前算子出现了性能问题。
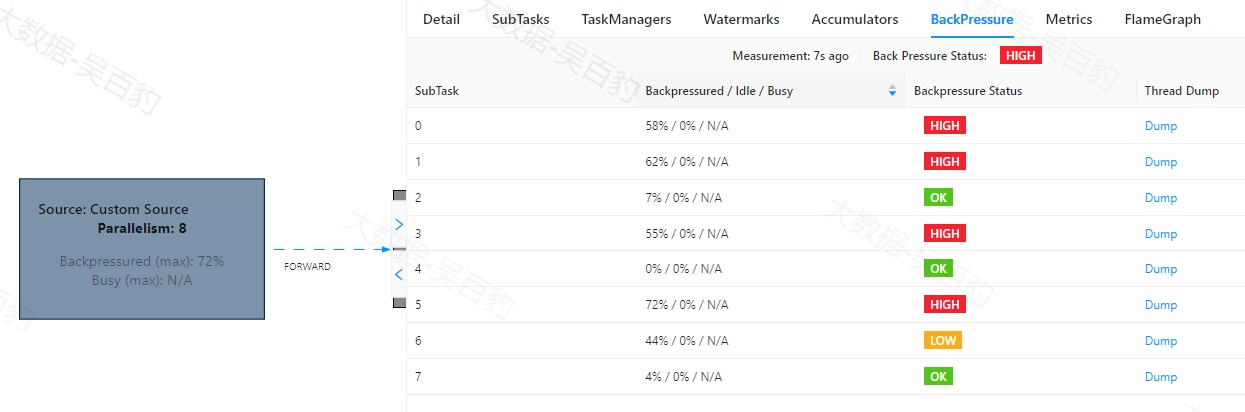
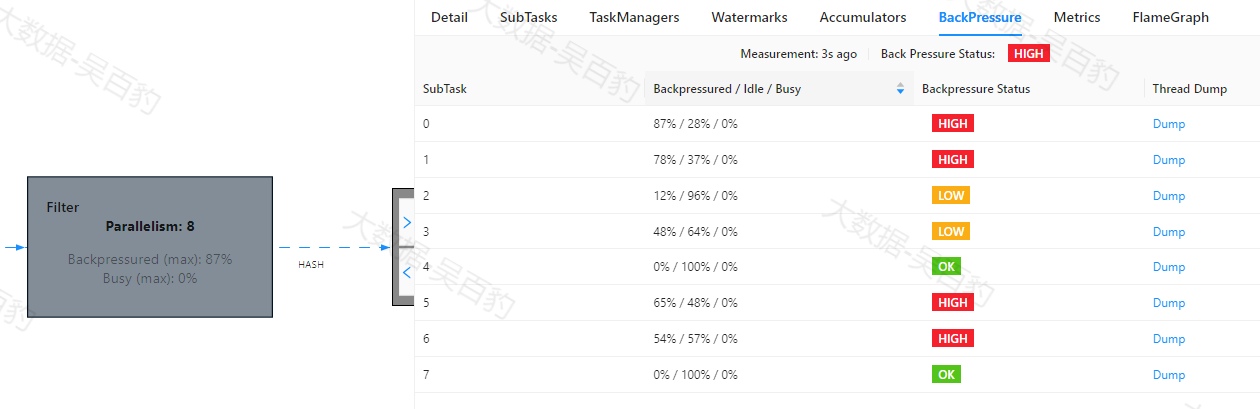
除此外,我们还可以点击每个操作对应的Graph图,查看每个操作对应Task的反压情况,来确定没有反压的第一个操作,如下图所示。
Source操作对应Task反压图:
Filter操作对应Task反压图:
KeyBy聚合操作对应Task反压图:
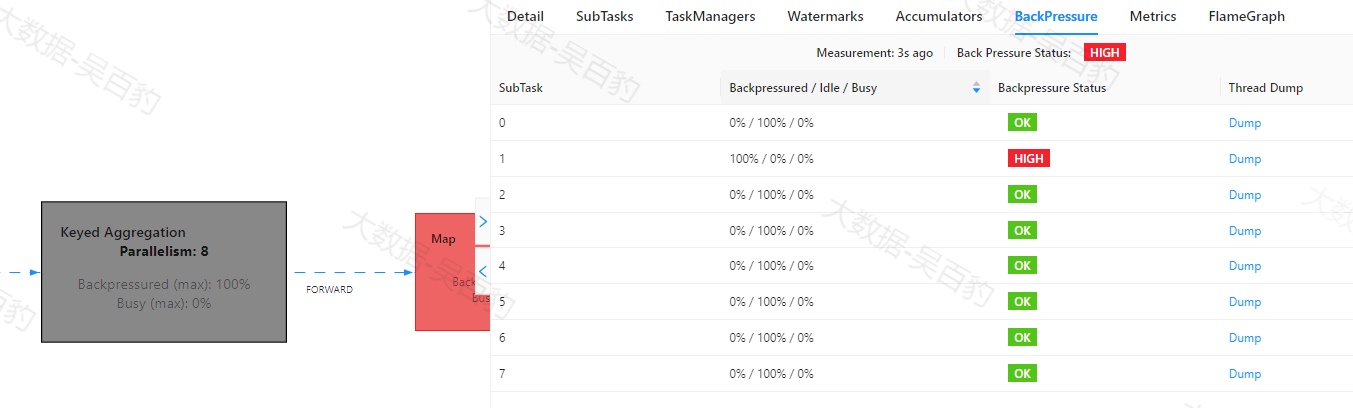
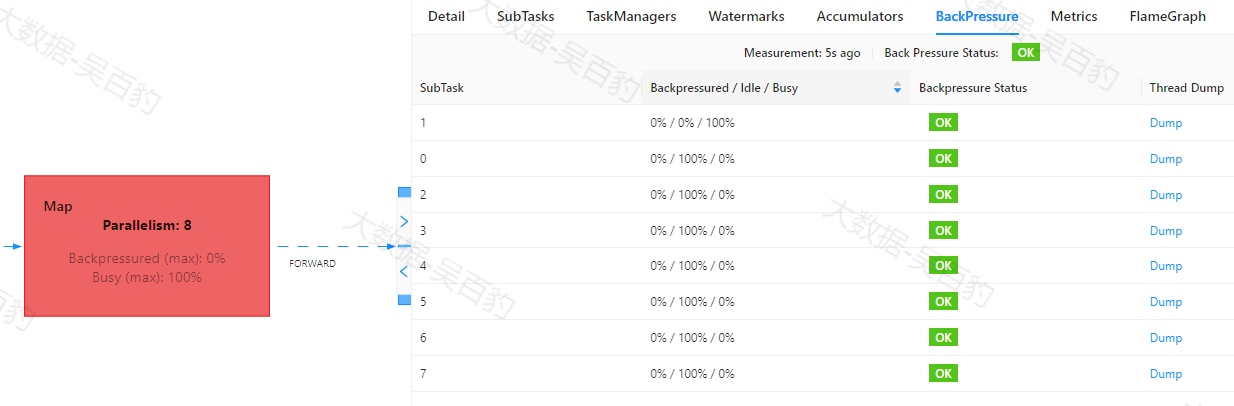
Map聚合操作对应Task反压图:
以上图中会看到每个操作的反压颜色不同,这些颜色表示意义如下:
-
OK: 0% <= 反压比例 <= 10%
-
LOW: 10% < 反压比例 <= 50%
-
HIGH: 50% < 反压比例 <= 100%
并且WebUI中展示的"Backpressured/Idle/Busy"表示每个task被反压、闲置和繁忙的时间百分比。当刷新该Flink任务时,会看到算子数据反压一层层反向阻塞数据,数据流动越来越慢,影响Flink执行效率。
通过以上方式我们也可以确定Map操作没有数据反压,但对应的1号subtask 非常Busy,可能性能出现问题。
3) 结合WebUI Task执行情况定位问题点。
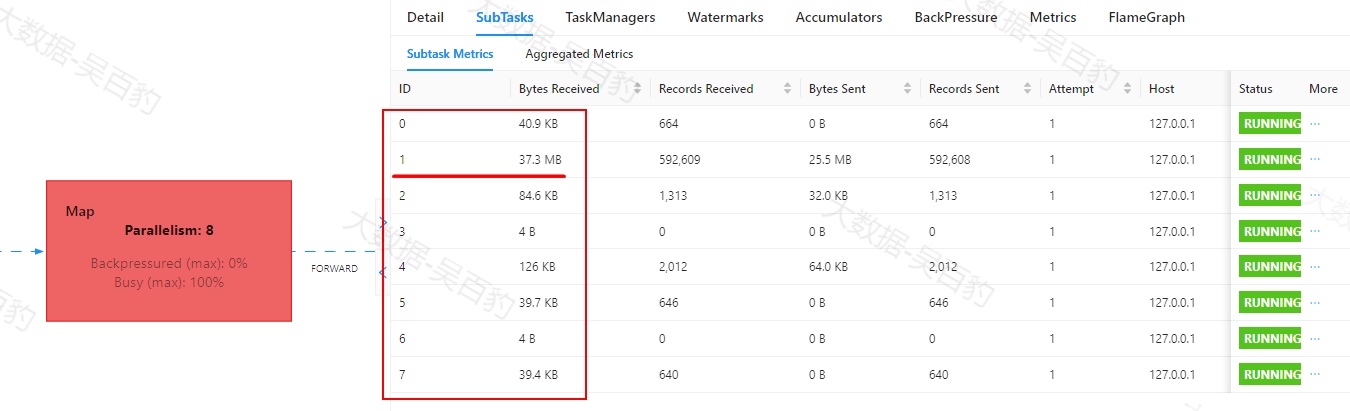
可以进一步查看每个操作对应的SubTask确定具体性能问题点。从Map操作反向查看每个操作SubTask执行情况:
Map操作Subtask执行情况如下,其中1号task处理数据相比起其他task多很多,出现数据倾斜。
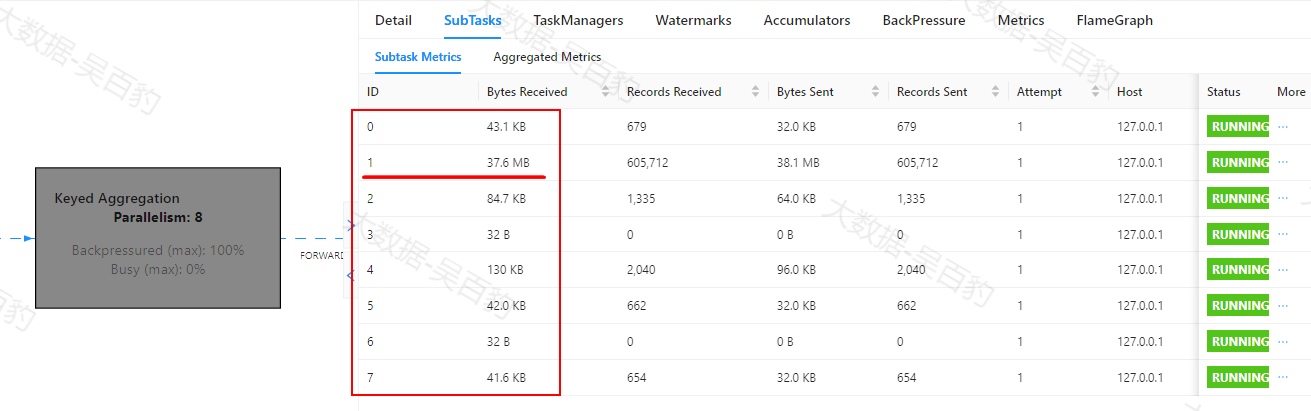
KeyBy聚合操作Subtask执行情况如下,其中1号task处理数据相比起其他task多很多,出现数据倾斜。
Filter操作Subtask执行情况如下,其中1号task处理数据相比起其他task多很多,出现倾斜问题。
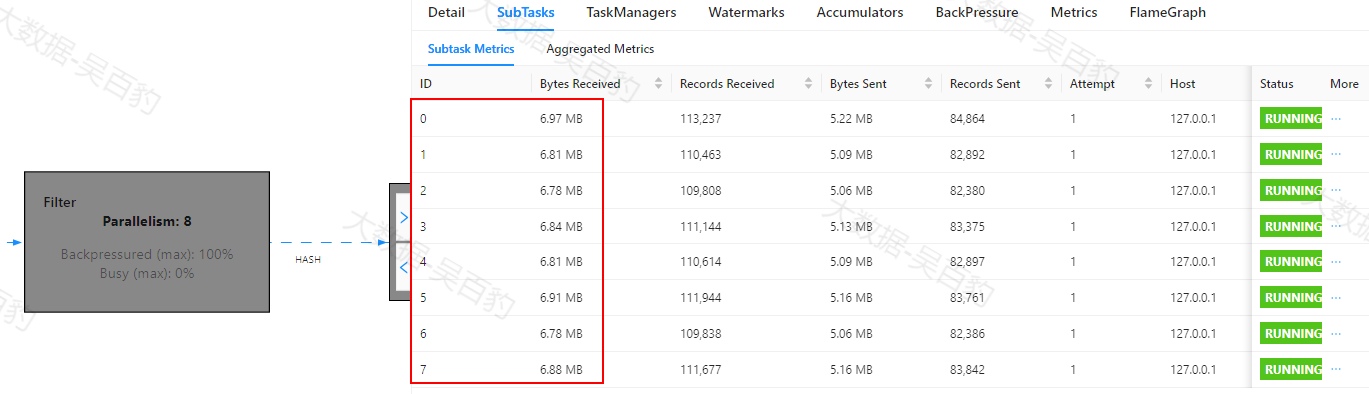
根据以上每个操作subtask执行情况,可以大致判断出由于keyby对key进行分组,可能导致数据出现了倾斜,并且由于聚合之后数据默认采用FORWARD(并行分区)方式,数据向下游传递过程中都是1号task出现数据倾斜。参考Map算子BackPressure的情况大致可以判断出由于数据倾斜导致1号task一直处于处理数据状态,进而出现数据反压。
此外,我们还可以通过火焰图来查看Flink业务逻辑是否出现性能问题。火焰图是一种可视化工具,可以有效地显示Flink中subtask操作占用资源时间长短信息。火焰图是通过多次采样堆栈信息来构建的,每个方法调用由一个柱状图表示,其中柱状图的长度表示某个调用方法在样本中出现的次数多或者少,表示该方法执行时间的长短,长度越长表示执行时间越长。高度由下到上表示Flink执行该方法调用逻辑的顺序。火焰图如下所示:
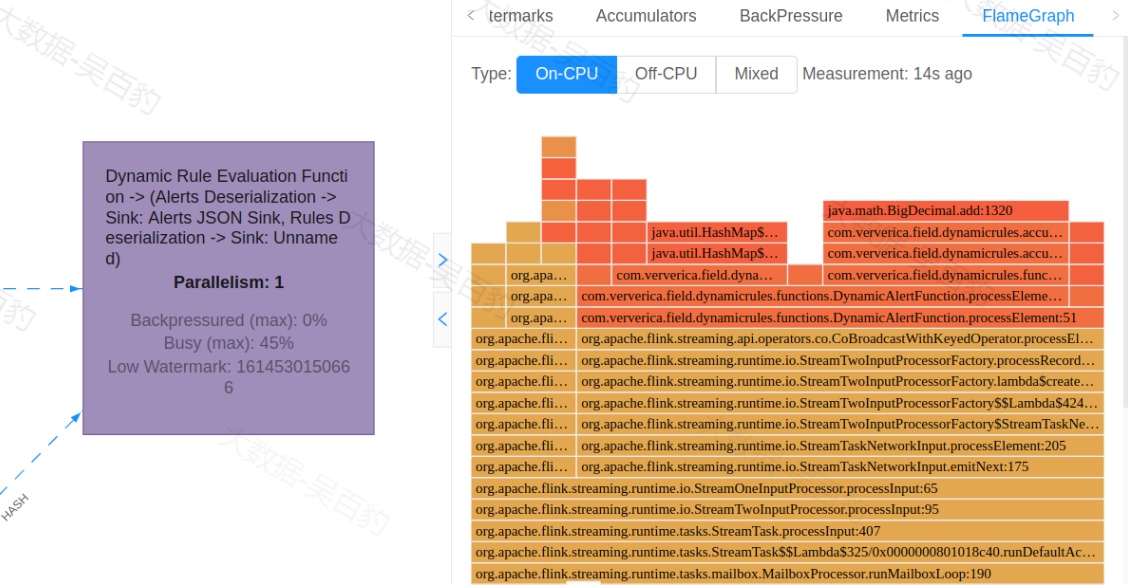
图中On-CPU表示线程状态为RUNNABLE,NEW;Off-CPU表示线程状态为TIMED_WAITING, WAITING, BLOCKED,Mixed表示两者结合。
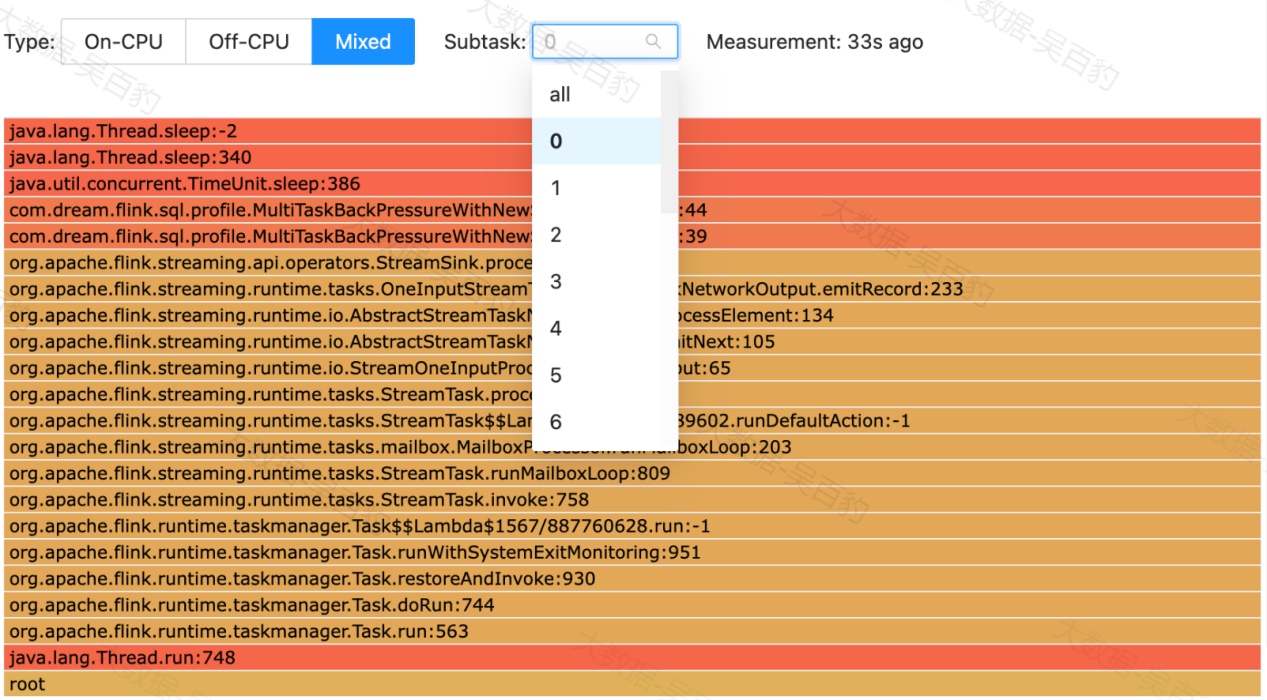
通过火焰图,我们还可以查看具体某个操作中各个subtask执行的CPU占用信息,如下图所示:
为了避免性能浪费,执行Flink任务时默认没有开启火焰图,我们可以在Flink的conf/ flink-conf.yaml中设置rest.flame .enabled: true或者在提交Flink任务时代码中设置参数开启火焰图即可。
//开启火焰图
conf.setString("rest.flamegraph.enabled","true");
//火焰图刷新周期,默认1分钟
conf.setString("rest.flamegraph.refresh-interval","10 s");在以上案例代码中设置以上参数开启火焰图,可以查看Map操作中每个task执行具体占用CPU情况,这里启动程序后需要等待采样一段时间,可以看到对应的Map操作CPU占用时间主要是我们代码中的113行。
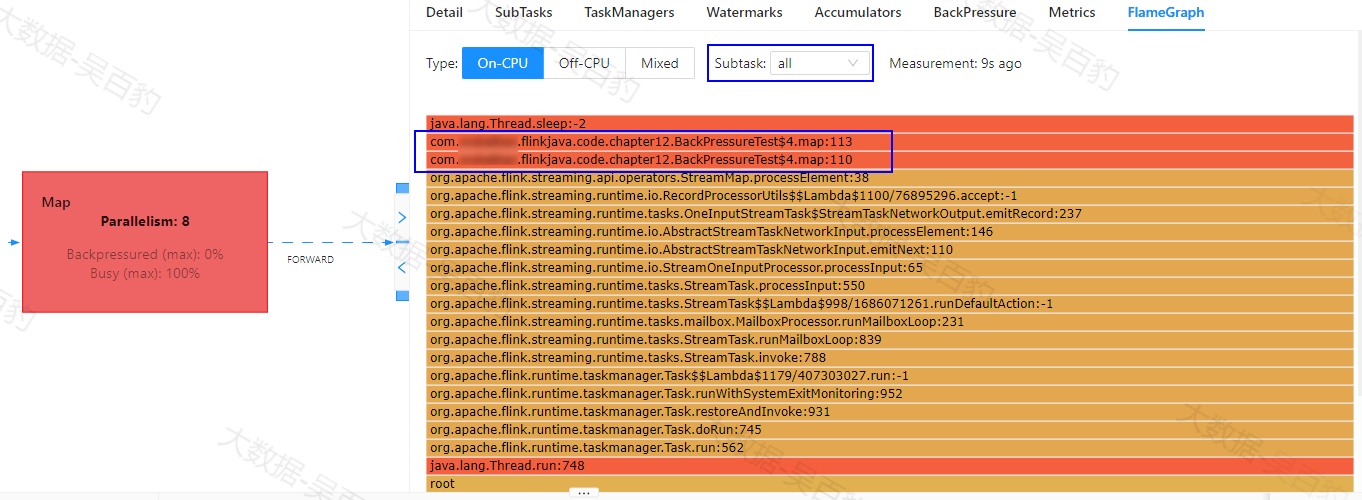
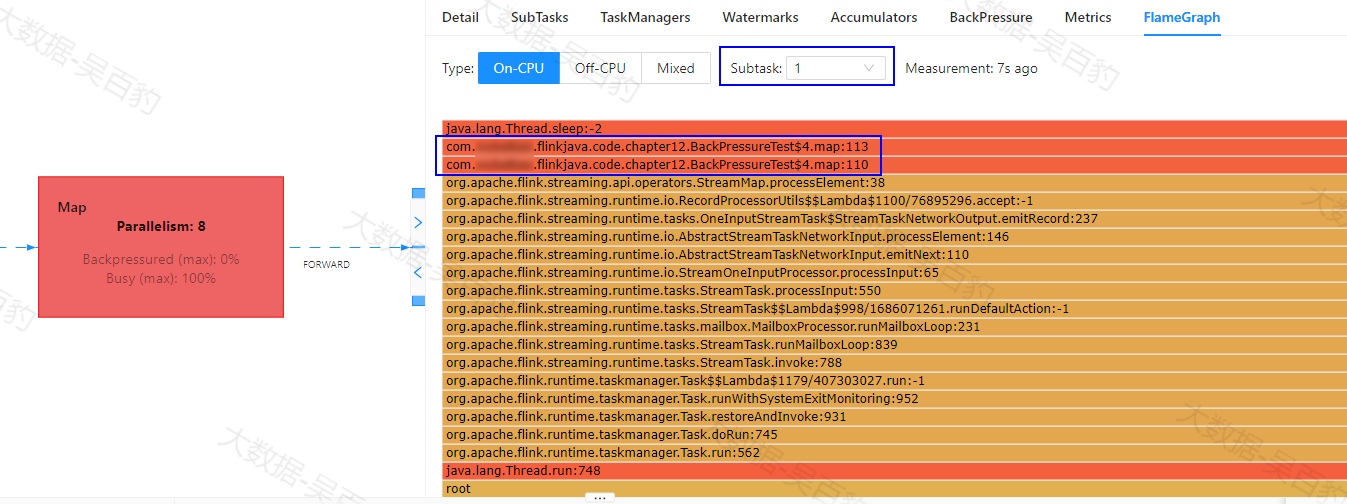
查看代码会发现这里的逻辑处理每条数据时暂停了1ms导致性能问题。
4) 解决任务反压
解决以上代码性能问题,我们只需要设置map操作并行度大于前面keyby聚合操作并行度,使两者之间数据分区方式由FORWARD并行分区改变为REBLANCE轮序分区即可,这样每个task处理的数据变得均匀并且将原来大数据量分担到多个task中执行。当然数据倾斜问题如果是代码执行瓶颈问题还需要从源头解决数据倾斜问题。
... ...
SingleOutputStreamOperator<String> result = ds4.map(new MapFunction<StationLog, String>() {
@Override
public String map(StationLog value) throws Exception {
Thread.sleep(1);
return "基站ID:" + value.sid + ",通话时长:" + value.duration;
}
}).setParallelism(16);
... ...Flink反压原因及优化
Flink任务中出现反压的原因及优化解决方案如下:
1) 资源设置不合理:当数据源产生数据速度很快,Flink处理数据跟不上时任务很容易产生反压。这种原因主要是Flink处理任务本身性能不足。这种情况可以结合Flink WebUI查看每个task执行和内存使用情况,适当增大Flink任务资源及并行度来解决反压问题。
2) 突发性数据量激增:突发性数据量增加也会导致Flink任务出现反压,例如某个事件窗口内的事件数量突然激增,导致任务无法在规定时间内完成处理。这种反压问题往往需要观察数据量激增频率,偶发生数据激增问题不需额外处理,频繁性数据激增问题最好适当增加Flink任务并行度分摊负载、适当增大窗口大小来解决。
3) 数据倾斜问题:当Flink出现数据倾斜时,会导致处理数据量大的任务会比其他任务处理慢,导致数据在整个流水线中堆积,最终出现数据反压并且还会进一步加剧反压情况。这种情况下需要根据业务数据情况查找数据倾斜问题点并优化解决数据倾斜问题。如:找到数据倾斜key并打散倾斜key。
4) 代码执行效率问题:当Flink代码执行效率慢也会导致Flink反压,代码效率问题可以通过火焰图来了查看确定。代码效率问题原因可能是多方面的,可以根据具体情况进行优化,例如:源头数据读取采用多并行方式、读取外部数据库数据使用异步IO方式、提高算子并行度、避免算子内出现大状态、checkpoint使用不对齐机制、多步骤分散业务避免在一个算子内实现复杂逻辑。
5) DownStream操作延迟:如果Flink作业的下游处理数据能力不足(如:Sink端写入性能差),也会导致Flink任务反压问题,这种情况大多数是由于下游系统的性能瓶颈或者下游交互延迟操作引起。例如:根据下游不同组件来解决优化(如:clickhouse创建分布式表、增大kafka分区、MySQL创建分区表、批量写出);提高Sink端处理数据能力;采用并行写出数据方式(如RichSinkFunction)。
数据倾斜处理
在 Apache Flink 中,数据倾斜是指在分布式数据处理过程中发生的数据分布不均衡现象。数据倾斜表现为某些节点或分区处理的数据量远多于其他节点,导致数据反压、频繁GC甚至OOM一系列问题,从而影响整个系统的性能和效率。本小节主要讲解如何对Flink中的数据倾斜进行优化。
数据倾斜的影响
在Flink中出现数据倾斜时会带来如下影响:
-
数据反压严重:往往产生数据倾斜时,导致某个subtask处理数据量非常大,从而会产生反压问题。
-
GC频繁问题:某个subtask处理数据量特别大,可能会使JVM的内存资源短缺,导致频繁的GC,甚至出现TaskManager OOM问题,最终导致任务失败。
-
watermark延迟严重:数据倾斜导致某个subtask处理数据量大,数据流动缓慢,watermark延迟大,不更新推进问题。
定位数据倾斜
Flink中出现数据倾斜时往往会产生反压,我们可以通过Flink WebUI观察反压信息来进一步确定是否有数据倾斜问题。同时可以进入出现反压算子的下个算子subtask执行详情页面,观察每个subtask处理数据量和接收数据条数来判断是否出现倾斜,一般某个subtask处理数据量多且相比其他subtask处理数据量相差10倍以上,极有可能出现数据倾斜问题。
如下案例中,首先通过自定义source在源头对数据模拟倾斜,并当遇到基站id为sid_0多生产100倍数据模拟sid_0基站数据相比其他基站数据多,后续又经过filter、flatMap、map、keyBy、sum等操作对数据进行处理。为了能通过WebUI清晰的看到数据倾斜效果,代码关闭了算子链、设置并行度为4并以本地模式运行。
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.关闭算子链
env.disableOperatorChaining();
//3.设置并行度为4
env.setParallelism(4);
//4.自定义源,模拟数据源头存在数据倾斜
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
// 获取当前子任务的索引
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
while (flag) {
String sid = "sid_" + random.nextInt(10);
// 如果是0号子任务,生成更多数据
if (subtaskIndex == 0) {
for (int i = 0; i < 100; i++) {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
} else {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
if (sid.equals("sid_0")) {
for (int i = 0; i < 100; i++) {
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
}
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//5.过滤通话状态不为fail的数据
SingleOutputStreamOperator<StationLog> ds2 = ds1.filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return !"fail".equals(value.callType);
}
});
//6.使用flatMap对数据处理,这里仅仅是返回当前数据
SingleOutputStreamOperator<StationLog> ds3 = ds2.flatMap(new FlatMapFunction<StationLog, StationLog>() {
@Override
public void flatMap(StationLog value, Collector<StationLog> out) throws Exception {
out.collect(value);
}
});
//7.对数据使用map 处理,转换成key,value格式数据,key:基站,value:计数
SingleOutputStreamOperator<Tuple2<String, Long>> ds4 = ds3.map(new RichMapFunction<StationLog, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(StationLog value) throws Exception {
return new Tuple2<String, Long>(value.sid , 1L);
}
});
//8.使用keyby按sid进行分组
KeyedStream<Tuple2<String, Long>, String> ds5 = ds4.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
//9.统计每个基站对应的数据量
SingleOutputStreamOperator<Tuple2<String, Long>> result = ds5.sum(1);
result.print();
env.execute();以上代码运行后,可以通过Flink WebUI观察到数据处理存在数据倾斜问题。
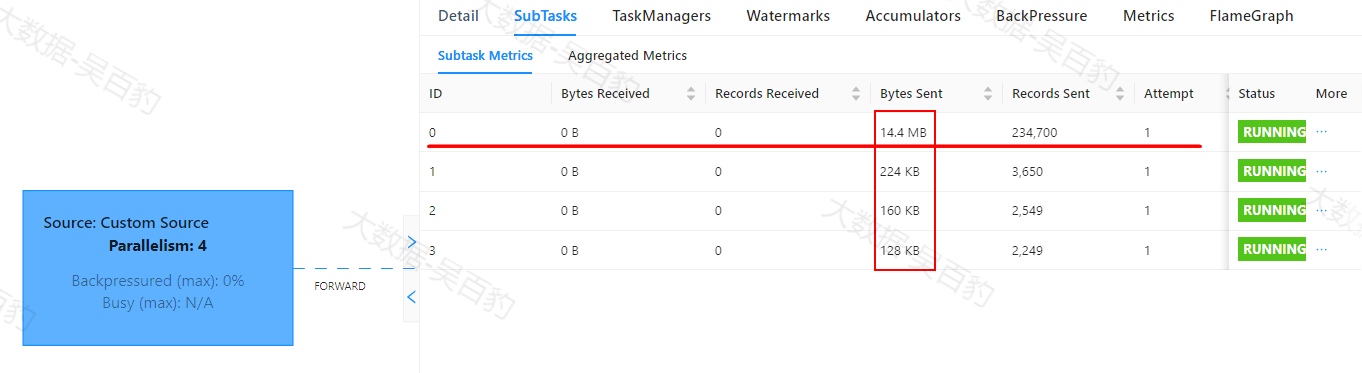
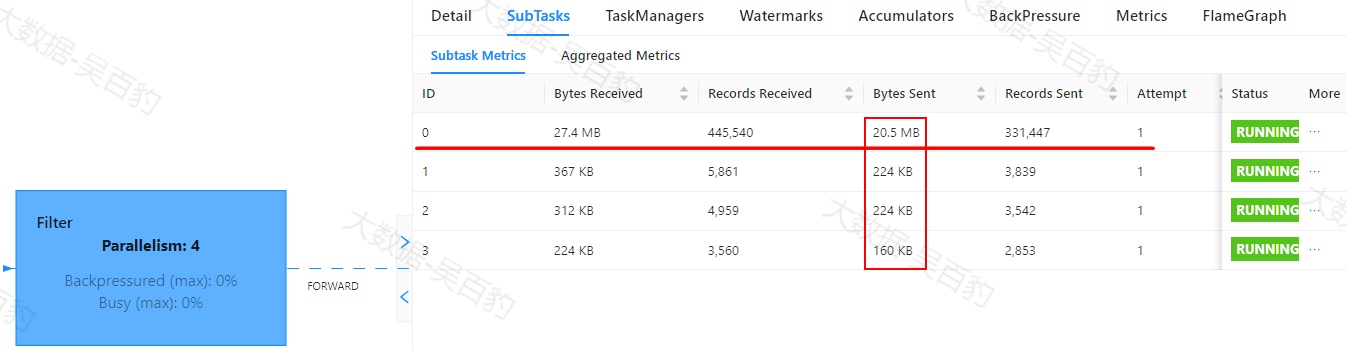
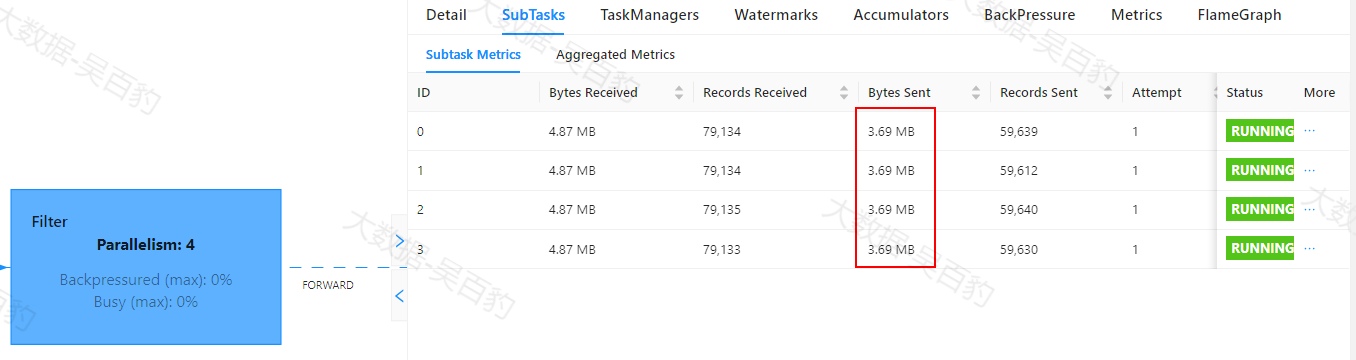
数据倾斜原因及解决方式
Flink中产生数据倾斜的原因主要就是两个方面,一个是业务数据本身存在数据倾斜,例如:一线城市外卖单量明显比三、四线小城市外卖订单量要大 ;另一个是Flink业务处理中按照某个key进行聚合操作,例如:使用keyby算子对数据分组造成了数据倾斜。下面分别对这两种情况进行分析并提出解决数据倾斜思路。
数据源本身数据倾斜
当Flink读取的数据源本身出现数据倾斜时,Flink读取过来数据极大概率也是倾斜的,这种情况下我们可以对读取过来的数据使用shuffle或者rebalance进行分区操作,这样就可以将读取过来不均匀的数据均匀的发送给Flink各个subtask进行处理。也可以改变上下游算子的并行度来解决这种倾斜问题,当上下游算子并行度不一致时,Flink默认就会使用rebalance partitioner分区策略,解决数据倾斜问题。
例如Flink读取Kafka数据时,Source并行度一般建议与读取Kafka的topic分区数保持一致,但如果某个分区出现数据倾斜,可以设置source后续操作的并行度为topic的整数倍或者更多,这样Flink后续处理并行度与Source并行度数不一致,自动采用rebalance分区策略解决数据倾斜问题。
如上案例中,ds1出现数据倾斜,可以在对ds1进行转换前调用shuffle或者rebalance方法设置分区策略,这样后续SubTask处理数据时就会均匀。如下代码:
... ...
//过滤通话状态不为fail的数据
// SingleOutputStreamOperator<StationLog> ds2 = ds1.shuffle().filter(new FilterFunction<StationLog>() {
SingleOutputStreamOperator<StationLog> ds2 = ds1.rebalance().filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return !"fail".equals(value.callType);
}
});
SingleOutputStreamOperator<StationLog> ds3 = ds2.flatMap(new FlatMapFunction<StationLog, StationLog>() {
@Override
public void flatMap(StationLog value, Collector<StationLog> out) throws Exception {
out.collect(value);
}
});
... ...以上代码修改后,执行,可以看到源头数据虽有倾斜,但在后续阶段算子处理时,各个subtask处理的数据已经很均匀。
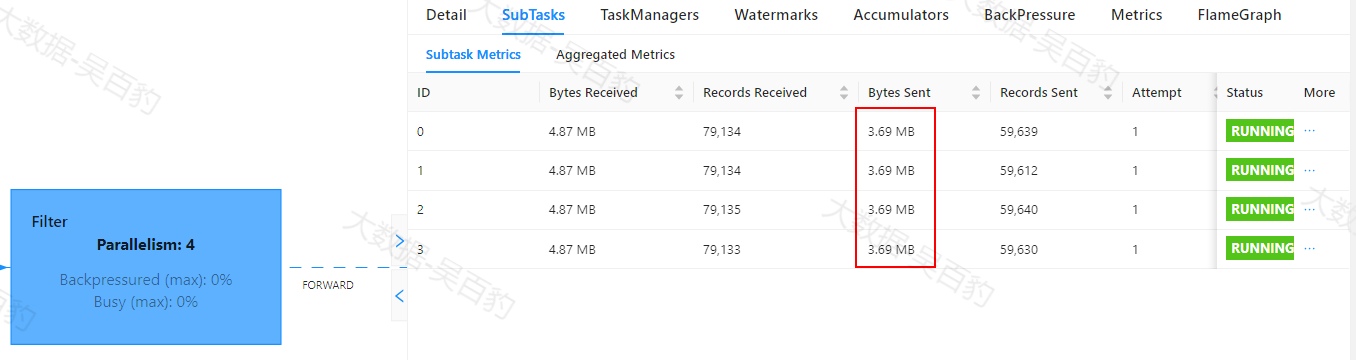
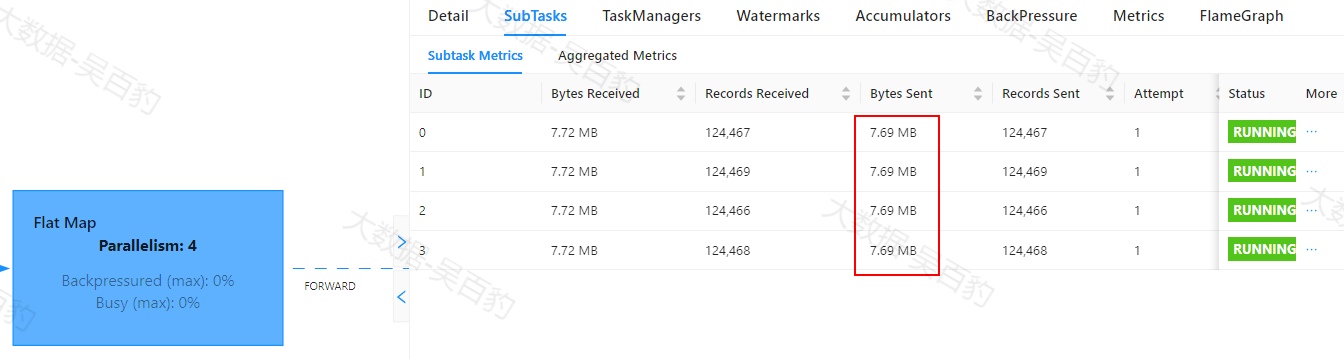
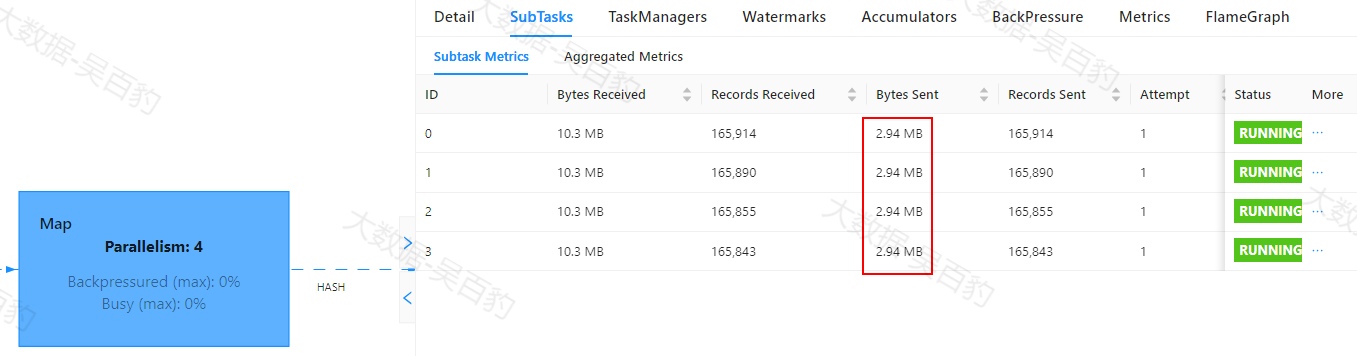
KeyBy导致数据倾斜
针对以上案例虽然使用shuffle或者rebalance方法设置分区策略解决了源头数据倾斜问题,但在代码业务逻辑中通过了keyby按照基站id进行分组,数据中本身基站sid_0的数据较其他基站id数据量大,所以keyby后的数据还是存在数据倾斜。下面介绍Flink中KeyBy分组导致数据倾斜的情况处理。
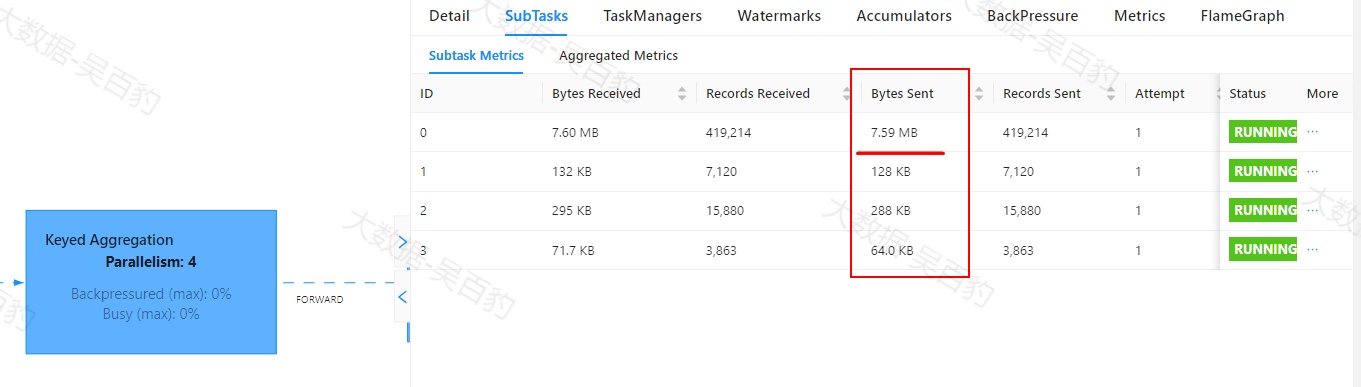
计算框架中处理由于分组导致的数据的场景往往采用双重聚合方式,即:首先对分组的key进行随机加前缀聚合,然后再对聚合结果去掉前缀再次聚合。在Flink实时数据处理场景中,针对KeyBy导致的数据倾斜不能统一简单的使用双重聚合方式操作,因为在Flink中对DataStream使用KeyBy后可以进行简单的聚合操作(例如:sum/count),也可以进行窗口设置(例如:timewindow)。如果keyby导致数据倾斜的场景是简单的聚合操作,由于数据流是实时向下游传递,再使用双重聚合方式反而无效甚至导致数据统计结果不准确,这时需要保证第一阶段聚合后的结果不能实时完后传递,可以通过手动方式进行攒批处理后统一向下游传递来保证最终结果的正确性。如果keyby导致数据倾斜的场景是窗口操作那么可以使用双重聚合方式。
- KeyBy简单聚合操作解决数据倾斜方式
以上案例业务是对基站id进行keyby分组后进行简单聚合,基站id sid_0出现严重数据倾斜。解决这种数据倾斜方式首先对分组key进行随机加前缀,然后分组进行第一次聚合,对聚合的结果攒批向下游传递。然后对第一次聚合后的结果进行去前缀,再次聚合即可。
以下代码对ds3进行随机加1000前缀,分组后在flatMap中进行第一次聚合结果累加,当累计10000条数据后,统一将聚合结果向下游传递,然后再进行keyby分组和第二次聚合操作。
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//关闭算子链
env.disableOperatorChaining();
//设置并行度为4
env.setParallelism(4);
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
// 获取当前子任务的索引
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
while (flag) {
String sid = "sid_" + random.nextInt(10);
// 如果是0号子任务,生成更多数据
if (subtaskIndex == 0) {
for (int i = 0; i < 100; i++) {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
} else {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
if (sid.equals("sid_0")) {
for (int i = 0; i < 100; i++) {
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
}
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//过滤通话状态不为fail的数据
SingleOutputStreamOperator<StationLog> ds2 = ds1.shuffle().filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return !"fail".equals(value.callType);
}
});
SingleOutputStreamOperator<StationLog> ds3 = ds2.flatMap(new FlatMapFunction<StationLog, StationLog>() {
@Override
public void flatMap(StationLog value, Collector<StationLog> out) throws Exception {
out.collect(value);
}
});
//对数据随机加前缀
SingleOutputStreamOperator<Tuple2<String, Long>> ds4 = ds3.map(new RichMapFunction<StationLog, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(StationLog value) throws Exception {
Random random = new Random();
return new Tuple2<String, Long>(random.nextInt(1000)+"-"+value.sid , 1L);
}
});
//分组
KeyedStream<Tuple2<String, Long>, String> ds5 = ds4.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
//聚集100条数据进行统计一次,并将结果输出
SingleOutputStreamOperator<Tuple2<String, Long>> ds6 = ds5.flatMap(new FlatMapFunction<Tuple2<String, Long>, Tuple2<String, Long>>() {
//用于计数,满100条就输出数据
private int count=0;
//创建map存储数据统计结果
private Map<String, Long> dataMap = new HashMap<String, Long>();
@Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, Long>> out) throws Exception {
//每条数据对count计数
count++;
//当前数据key
String key = value.f0;
if (dataMap.containsKey(key)) {
dataMap.put(key, dataMap.get(key) + 1L);
} else {
dataMap.put(key, 1L);
}
if (count == 10000) {
//count达到10000就输出结果
for (Map.Entry<String, Long> one : dataMap.entrySet()) {
out.collect(new Tuple2<>(one.getKey(), one.getValue()));
}
//清空count,清空map
count = 0;
dataMap.clear();
}
}
});
//去掉前缀
SingleOutputStreamOperator<Tuple2<String, Long>> ds7 = ds6.map(new MapFunction<Tuple2<String, Long>, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Tuple2<String, Long> value) throws Exception {
String realKey = value.f0.split("-")[1];
return new Tuple2<>(realKey, value.f1);
}
});
//第二次keyby 并 sum聚合
KeyedStream<Tuple2<String, Long>, String> ds8 = ds7.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple2<String, Long>> result = ds8.sum(1);
result.print();
env.execute();以上代码运行后,可以看到keyby数据倾斜问题缓解很多。
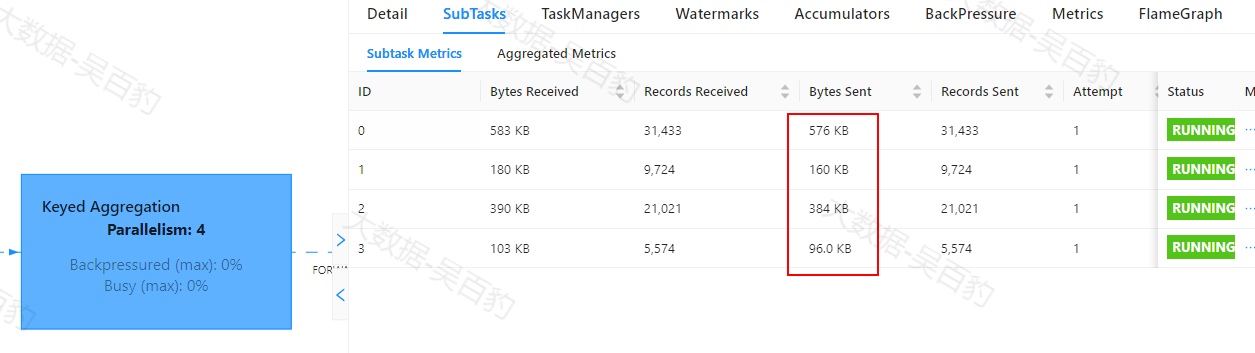
- KeyBy窗口操作解决数据倾斜方式
如下代码案例与之前数据倾斜案例类似,代码中KeyBy后设置窗口并进行基站通话时长统计。
/1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//关闭算子链
env.disableOperatorChaining();
//设置并行度为4
env.setParallelism(4);
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
// 获取当前子任务的索引
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
while (flag) {
String sid = "sid_" + random.nextInt(10);
// 如果是0号子任务,生成更多数据
if (subtaskIndex == 0) {
for (int i = 0; i < 100; i++) {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
} else {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
if (sid.equals("sid_0")) {
for (int i = 0; i < 100; i++) {
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
}
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//设置watermark
SingleOutputStreamOperator<StationLog> ds2 = ds1.assignTimestampsAndWatermarks(
WatermarkStrategy.<StationLog>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<StationLog>() {
@Override
public long extractTimestamp(StationLog element, long recordTimestamp) {
return element.callTime;
}
}).withIdleness(Duration.ofSeconds(5))
);
//过滤通话状态不为fail的数据
SingleOutputStreamOperator<StationLog> ds3 = ds2.shuffle().filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return !"fail".equals(value.callType);
}
});
//转换数据
SingleOutputStreamOperator<Tuple2<String, Long>> ds4 = ds3.map(new MapFunction<StationLog, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(StationLog value) throws Exception {
return new Tuple2<>(value.sid, value.duration);
}
});
//分组
KeyedStream<Tuple2<String, Long>, String> ds5 = ds4.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
//设置窗口
WindowedStream<Tuple2<String, Long>, String, TimeWindow> ds6 = ds5.window(TumblingEventTimeWindows.of(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Long>> ds7 = ds6.process(new ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>() {
@Override
public void process(String key,
ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>.Context context,
Iterable<Tuple2<String, Long>> iterable,
Collector<Tuple2<String, Long>> collector) throws Exception {
Long totalDuration = 0L;
for (Tuple2<String, Long> info : iterable) {
totalDuration += info.f1;
}
collector.collect(new Tuple2<>(key, totalDuration));
}
});
ds7.print();
env.execute();以上代码中基站sid_0存在数据倾斜,在keyby后设置window窗口处理中同样也有数据倾斜问题。运行以上代码,可以通过webui观察到数据倾斜。
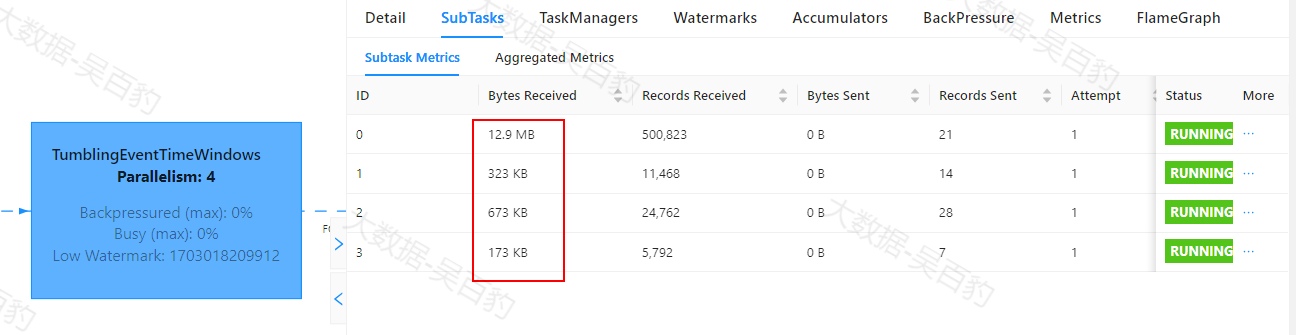
由于Flink中设置窗口本身就类似一种批处理,所以解决这种keyby后进行window处理的数据倾斜问题,可以直接像Spark中使用双重聚合解决即可。解决思路:首先对分组key进行随机加前缀打散,然后分组并设置窗口,窗口内进行第一次数据的聚合,然后将结果进行去前缀,然后再按照去掉前缀的key进行聚合,最终得到每个窗口的结果数据。由于最终统计的是Flink每个窗口对应的结果数据,在去前缀操作中需要保留窗口的起始信息,这样才能在第二次聚合时保证相同窗口数据进行聚合操作。
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//关闭算子链
env.disableOperatorChaining();
//设置并行度为4
env.setParallelism(4);
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
// 获取当前子任务的索引
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
while (flag) {
String sid = "sid_" + random.nextInt(10);
// 如果是0号子任务,生成更多数据
if (subtaskIndex == 0) {
for (int i = 0; i < 100; i++) {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
} else {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
if (sid.equals("sid_0")) {
for (int i = 0; i < 100; i++) {
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
}
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//设置watermark
SingleOutputStreamOperator<StationLog> ds2 = ds1.assignTimestampsAndWatermarks(
WatermarkStrategy.<StationLog>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<StationLog>() {
@Override
public long extractTimestamp(StationLog element, long recordTimestamp) {
return element.callTime;
}
}).withIdleness(Duration.ofSeconds(5))
);
//过滤通话状态不为fail的数据
SingleOutputStreamOperator<StationLog> ds3 = ds2.shuffle().filter(new FilterFunction<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return !"fail".equals(value.callType);
}
});
//转换数据
SingleOutputStreamOperator<Tuple2<String, Long>> ds4 = ds3.map(new MapFunction<StationLog, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(StationLog value) throws Exception {
Random random = new Random();
return new Tuple2<>(random.nextInt(1000)+"-"+value.sid, value.duration);
}
});
//根据随机加前缀的key进行分组
KeyedStream<Tuple2<String, Long>, String> ds5 = ds4.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
//设置窗口
WindowedStream<Tuple2<String, Long>, String, TimeWindow> ds6 = ds5.window(TumblingEventTimeWindows.of(Time.seconds(5)));
//第一次聚合操作
SingleOutputStreamOperator<Tuple2<String, Long>> ds7 = ds6.process(new ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>() {
@Override
public void process(String key,
ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>.Context context,
Iterable<Tuple2<String, Long>> iterable,
Collector<Tuple2<String, Long>> collector) throws Exception {
Long totalDuration = 0L;
for (Tuple2<String, Long> info : iterable) {
totalDuration += info.f1;
}
//获取窗口起始时间}
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
String windowStartTime = sdf.format(context.window().getStart());
String windowEndTime = sdf.format(context.window().getEnd());
collector.collect(new Tuple2<>(key + "|" + windowStartTime + "|" + windowEndTime, totalDuration));
}
});
//对聚合结果去掉前缀,然后再次聚合
SingleOutputStreamOperator<Tuple2<String, Long>> result = ds7.map(new MapFunction<Tuple2<String, Long>, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Tuple2<String, Long> value) throws Exception {
String newKey = value.f0.split("-")[1];
return new Tuple2<>(newKey, value.f1);
}
}).keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
}).reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> tp1, Tuple2<String, Long> tp2) throws Exception {
System.out.println(tp1.f0);
return new Tuple2<>(tp1.f0.split("\\|")[0], tp1.f1 + tp2.f1);
}
});
result.print();
env.execute();代码运行后可以通过webui看到,经过双重聚合处理后,没有再出现数据倾斜问题。
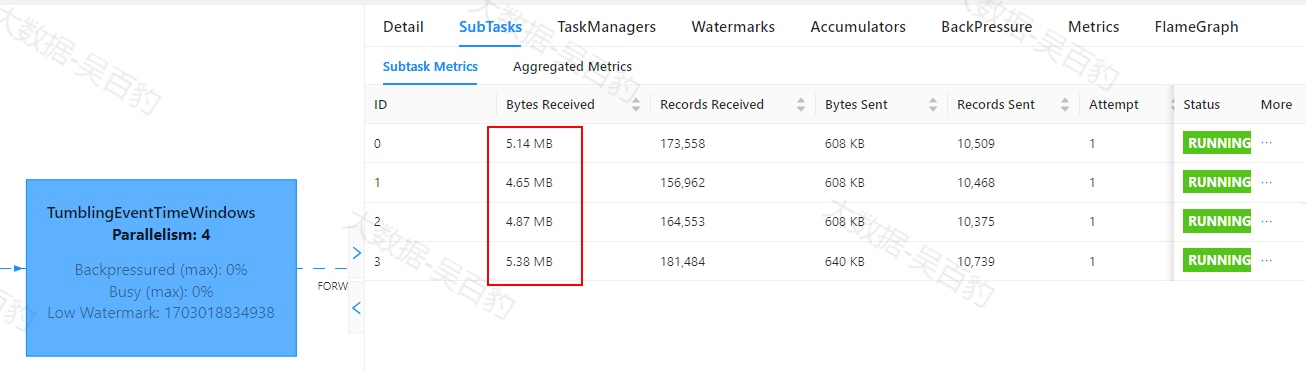
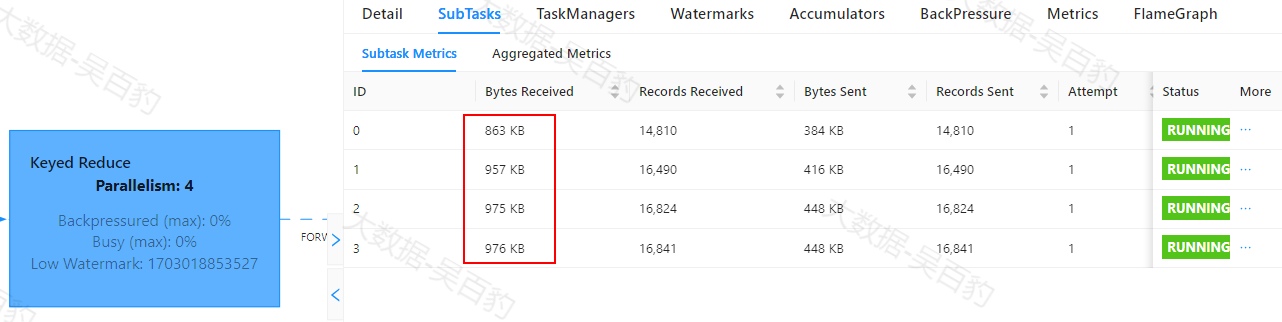
Table & SQL 优化
在Flink中除了DataStream API之外,还有Table和SQL API ,Table API 和 SQL 是高效优化过的,它集成了许多查询优化和算子优化,但并不是所有的优化都是默认开启的,因此对于某些工作负载,可以通过打开某些选项来提高性能。在实际工作场景中我们使用FlinkSQL居多,本小节根据Flink SQL使用来介绍Table和SQL中的一些优化内容。
对状态设置TTL
在Flink编程中如果涉及到的状态较大并且业务允许清空状态,可以设置ttl参数,指定状态超过一定时间后自动清空,来达到减少状态效果。
Flink Table和SQL中可以通过TableEnvironment来指定table.exec.state.ttl参数,决定状态保存的时长。
下面通过代码方式来演示Flink Table API和SQL编程中状态的使用,该案例读Socket中基站日志数据,按照基站进行分组统计基站的通话时长。
//获取DataStream的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取Table API的运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//设置状态保存时间,默认为0,表示不清理状态,这里设置5s
tableEnv.getConfig().set("table.exec.state.ttl","5000");
SingleOutputStreamOperator<StationLog> ds = env.socketTextStream("node5", 9999)
.map(new MapFunction<String, StationLog>() {
@Override
public StationLog map(String s) throws Exception {
String[] split = s.split(",");
return new StationLog(split[0], split[1], split[2], split[3], Long.valueOf(split[4]), Long.valueOf(split[5]));
}
});
//将DataStream转换成Table
tableEnv.createTemporaryView("station_tbl",ds);
//通过SQL统计通话时长信息
Table result = tableEnv.sqlQuery("select sid,sum(duration) as total_duration from station_tbl group by sid");
//打印输出
result.execute().print();以上代码运行后,向socket-9999端口中输入基站日志数据,对于连续5秒内输入的相同基站日志数据,Flink 会对基站统计的通话时长数据进行状态保存,当相同基站日志数据隔5秒后再次输入,可以看到该基站统计数据会重新统计。
#socket-9999中输入数据
001,181,182,success,1000,40
002,182,183,result,3000,20
001,183,184,success,2000,30
#隔5s后输入,可以看到基站001的统计重新开始
001,184,185,success,6000,50使用累积窗口
累积窗口是Flink SQL中特有的窗口函数。滚动窗口和滑动窗口适合固定周期统计指标,除了这种固定周期统计指标场景外,还有一种特殊场景:当统计周期较长时,需要在统计周期内间隔输出某指标的统计值,并且这些输出的值是逐步累积的,这种情况下滚动窗口和滑动窗口就不能满足需求,这种场景中就可以使用累积窗口来解决。
例如:我们按天来实时统计网站的PV,每小时输出今天到此刻PV总量。如果我们设置1天一个滑动窗口,那么需要等到24点才会计算一次,这样输出频率太低,满足不了我们的需求;如果每隔一段时间统计过去1天的PV值,这样虽然计算频率增高,但是计算的结果并不是我们想要的今天到此刻的PV值。这种特殊的窗口统计就是"累积窗口",我们可以通过Flink SQL提供的累计窗口表值函数来解决。
Flink SQL中通过CUMULATE 表值函数来设置累积窗口,如下:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)CUMULATE 参数解释如下:
-
data:指定Table 表。
-
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
-
step:指定窗口累积步长,即多久输出一次累积结果。
-
size:指定窗口长度,即多久生成一个窗口。
CUMULATE 表值函数在流处理模式下,时间属性字段必须是事件时间或处理时间属性,在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。与TUMBLE表值函数一样,CUMULATE 的返回值包括原始关系的所有列,以及额外的三列,分别命名为"window_start"(窗口起始时间)、"window_end"(窗口结束时间)和"window_time"(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。原始时间属性"timecol"将在窗口表值函数之后成为常规的时间戳列。下面通过一个案例来演示Flink SQL 中累积窗口使用。
案例:读取Kafka中基站日志数据,按日统计,每5s输出每个基站所有主叫通话时长。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL TumblingWindow
Table result = tableEnv.sqlQuery("select " +
"sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" CUMULATE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND , INTERVAL '1' DAY)" +
") " +
"group by sid,window_start,window_end");
//打印结果
result.execute().print();代码编写完成后,可以向Kafka stationlog-topic中输入如下数据,可以看到随着数据的输入,每隔5秒会展示一次当日统计结果。
#向kafka stationlog-topic中输入如下数据
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50
#[0~5000)窗口触发
001,181,182,busy,7000,10
002,182,183,fail,9000,20
001,183,184,busy,11000,30
002,184,185,busy,6000,40
#[0~10000)窗口触发
003,181,183,busy,12000,50
#[5000~15000)窗口触发
003,181,183,busy,17000,50控制台输出结果如下:
+----+-----+-------------------------+-------------------------+--------+
| op | sid | window_start | window_end |sum_dur |
+----+-----+-------------------------+-------------------------+--------+
| +I | 001 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:05.000 | 40 |
| +I | 002 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:05.000 | 20 |
| +I | 001 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:10.000 | 50 |
| +I | 003 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:10.000 | 50 |
| +I | 002 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:10.000 | 120 |
| +I | 001 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:15.000 | 80 |
| +I | 003 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:15.000 | 100 |
| +I | 002 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:15.000 | 120 |MiniBatch聚合
Flink Table和SQL聚合场景中默认来一条数据聚合一条,聚合过程往往涉及状态操作所以每来一条数据聚合处理过程为:从状态中获取数据------>状态累加------>状态更新写出,这种来一条聚合一条数据处理模式可能会增加StateBackend开销(尤其是对于RocksDB StateBackend),如果遇到数据倾斜,会加剧这个开销并容易导致job反压。
这种聚合场景下,为了进一步减少StateBackend开销,在Flink Table和SQL 中我们可以设置开启MiniBatch聚合(默认关闭),其核心思想是将一组输入的数据缓存在聚合算子内部的缓冲区中,经过一定时间后再做触发处理,触发前会进行本地局部聚合,这样在触发处理时,每个key只需要一次访问状态,可以大大减少状态开销并获得更好的吞吐量。主要注意,开启MiniBatch聚合后,由于不是立即处理实时数据可能会增加Flink一些延迟,所以开启或者不开启MiniBatch聚合是吞吐量和延迟之间的权衡。
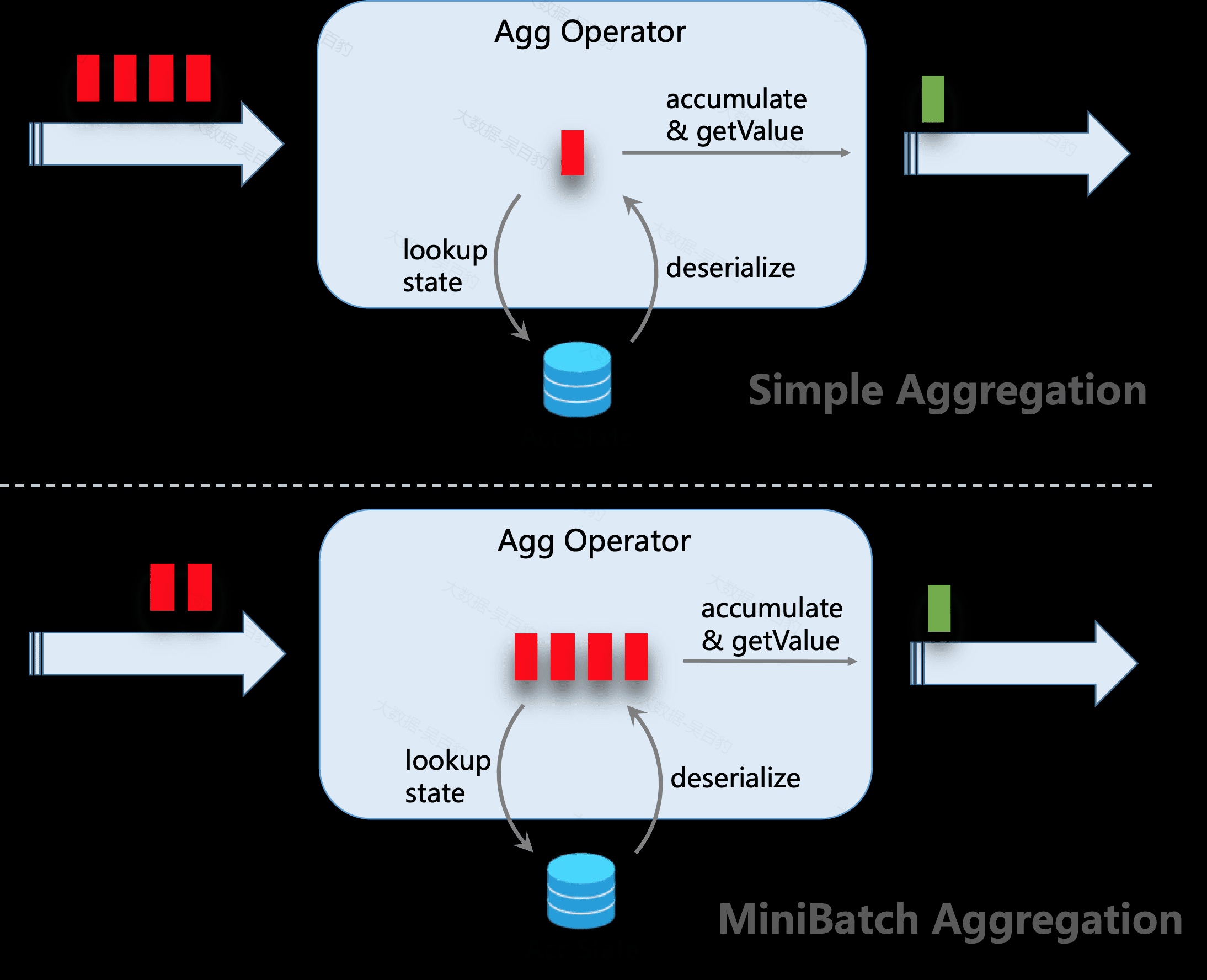
Flink Table和SQL中T默认MiniBatch优化是关闭的,Table和SQL 操作中可以通过设置如下选项进行开启。
// 初始化 table environment
TableEnvironment tEnv = ...;
//通过flink configuration进行参数设置
TableConfig configuration = tEnv.getConfig();
//开启MiniBatch 优化,默认false
configuration.set("table.exec.mini-batch.enabled", "true");
//设置5秒时间处理缓冲数据,默认0s
configuration.set("table.exec.mini-batch.allow-latency", "5 s");
//设置每个聚合操作可以缓冲的最大记录数,默认-1,开启MiniBatch后必须设置为正值
configuration.set("table.exec.mini-batch.size", "5000"); 代码案例:
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//创建流处理执行环境
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.创建TableEnv
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//3.开启minibatch
//通过flink configuration进行参数设置
TableConfig configuration = tableEnv.getConfig();
//开启MiniBatch 优化,默认false
configuration.set("table.exec.mini-batch.enabled", "true");
//设置5秒时间处理缓冲数据,默认0s
configuration.set("table.exec.mini-batch.allow-latency", "5 s");
//设置每个聚合操作可以缓冲的最大记录数,默认-1,开启MiniBatch后必须设置为正值
configuration.set("table.exec.mini-batch.size", "5000");
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
while (flag) {
String sid = "sid_" + random.nextInt(10);
generateData(ctx, random, sid, callTypes);
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//将DataStream 转换成 Table
tableEnv.createTemporaryView("stationlog_tbl", ds1);
//打印表结构
Table table = tableEnv.from("stationlog_tbl");
table.printSchema();
TableResult result = tableEnv.executeSql("select sid,sum(duration) as totalDuration from stationlog_tbl group by sid");
result.print();以上代码中不开启minibatch和设置minibatch可以通过WebUI页面看到变化:
Local-Global聚合
Local-Global聚合主要解决Table 和 SQL操作中的数据倾斜问题,其思想是通过将一组聚合分为两个阶段,先在上游进行本地聚合,然后再下游进行全局聚合,类似MapReduce中的Combine+Reduce模式。如下SQL:
SELECT color, sum(id)
FROM T
GROUP BY color以上SQL当按照Color进行分组聚合处理时,可能由于各Color存在数据不均衡出现一些并行实例处理相比其他实例处理更多的记录。开启Local-Global聚合后,可以将具有相同key的输入数据在本地预先聚合,然后全局聚合将预聚合结果进行最后累加,这样大大减少了网络shuffle和状态访问的成本,每次本地聚合累积的输入数据量基于 mini-batch 间隔,这意味着 local-global 聚合依赖于启用了 mini-batch 优化。
下图展示了local-global聚合实现原理:
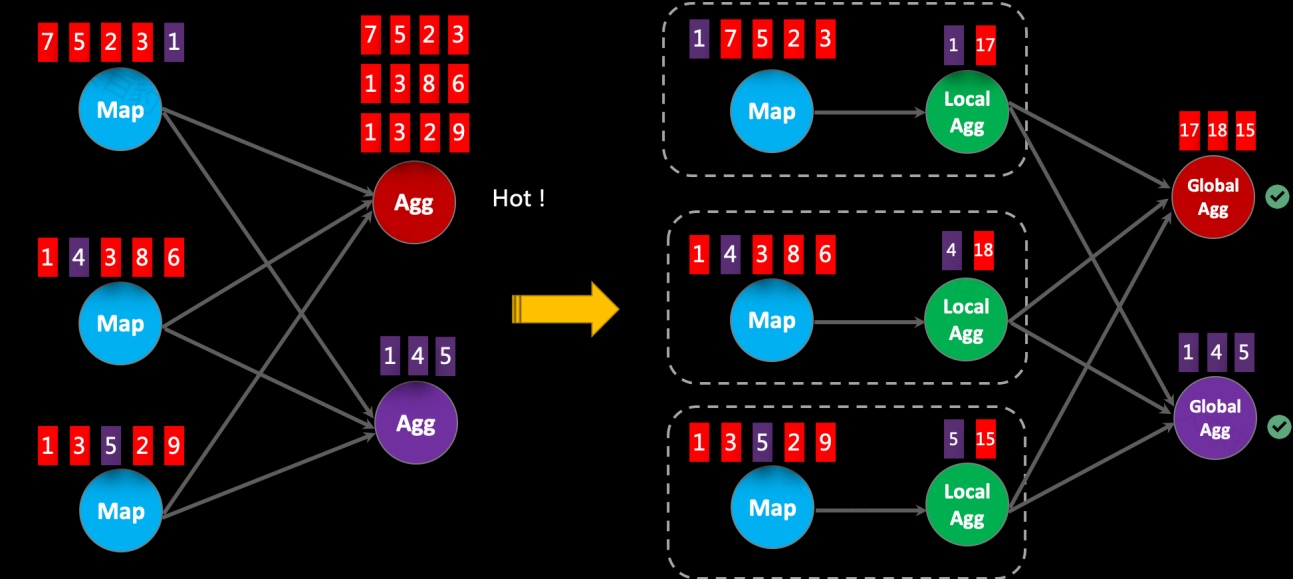
可以在Flink Table和SQL编程中通过如下参数开启local-global:
// 初始化 table environment
TableEnvironment tEnv = ...;
//通过flink configuration进行参数设置
TableConfig configuration = tEnv.getConfig();
//开启MiniBatch 优化,默认false
configuration.set("table.exec.mini-batch.enabled", "true");
//设置5秒时间处理缓冲数据,默认0s
configuration.set("table.exec.mini-batch.allow-latency", "5 s");
//设置每个聚合操作可以缓冲的最大记录数,默认-1,开启MiniBatch后必须设置为正值
configuration.set("table.exec.mini-batch.size", "5000");
//设置Local-Global 聚合
configuration.set("table.optimizer.agg-phase-strategy", "TWO_PHASE");如下代码中在产生基站数据时将sid_0多生产很多,这样导致后续按照基站进行分组统计时出现数据倾斜问题:
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//创建流处理执行环境
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.创建TableEnv
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
// 获取当前子任务的索引
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
while (flag) {
String sid = "sid_" + random.nextInt(10);
// 如果是0号子任务,生成更多数据
if (subtaskIndex == 0) {
for (int i = 0; i < 100; i++) {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
} else {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
if (sid.equals("sid_0")) {
for (int i = 0; i < 100; i++) {
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
}
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//将DataStream 转换成 Table
tableEnv.createTemporaryView("stationlog_tbl", ds1);
//打印表结构
Table table = tableEnv.from("stationlog_tbl");
table.printSchema();
TableResult result = tableEnv.executeSql("select sid,sum(duration) as totalDuration from stationlog_tbl group by sid");
result.print();查看Flink WebUI可以观察到存在数据倾斜问题:

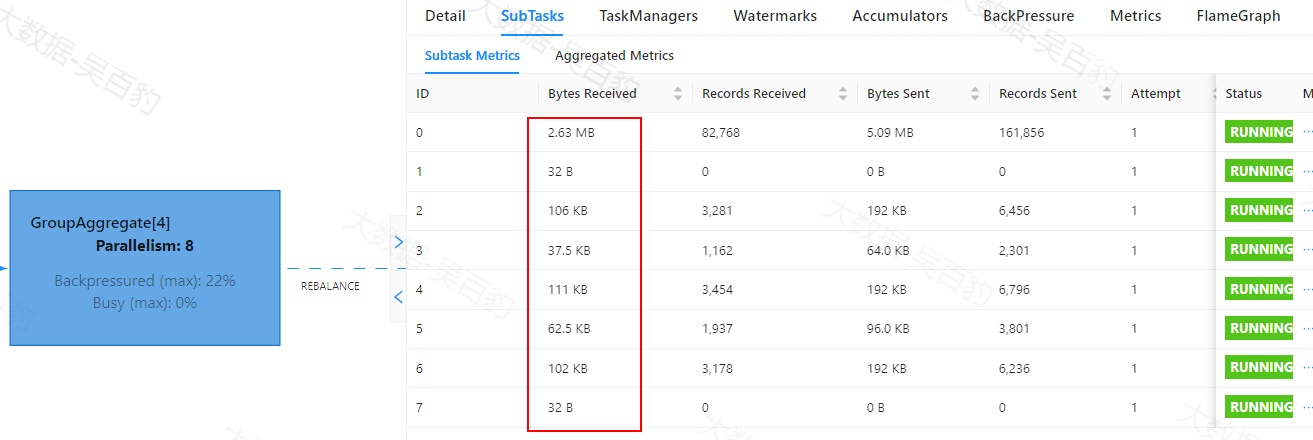
代码中设置Local-Global聚合后,数据倾斜问题被很大程度解决。在以上代码中增加Local-Global聚合设置。
... ...
//2.创建TableEnv
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//3.开启Local-Global 聚合
//通过flink configuration进行参数设置
TableConfig configuration = tableEnv.getConfig();
//开启MiniBatch 优化,默认false
configuration.set("table.exec.mini-batch.enabled", "true");
//设置5秒时间处理缓冲数据,默认0s
configuration.set("table.exec.mini-batch.allow-latency", "5 s");
//设置每个聚合操作可以缓冲的最大记录数,默认-1,开启MiniBatch后必须设置为正值
configuration.set("table.exec.mini-batch.size", "5000");
//设置Local-Global 聚合
configuration.set("table.optimizer.agg-phase-strategy", "TWO_PHASE");
DataStreamSource<StationLog> ds1 = env.addSource...
... ...通过WebUI可以看到开启Local-Global聚合后,数据处理中没有出现数据倾斜。
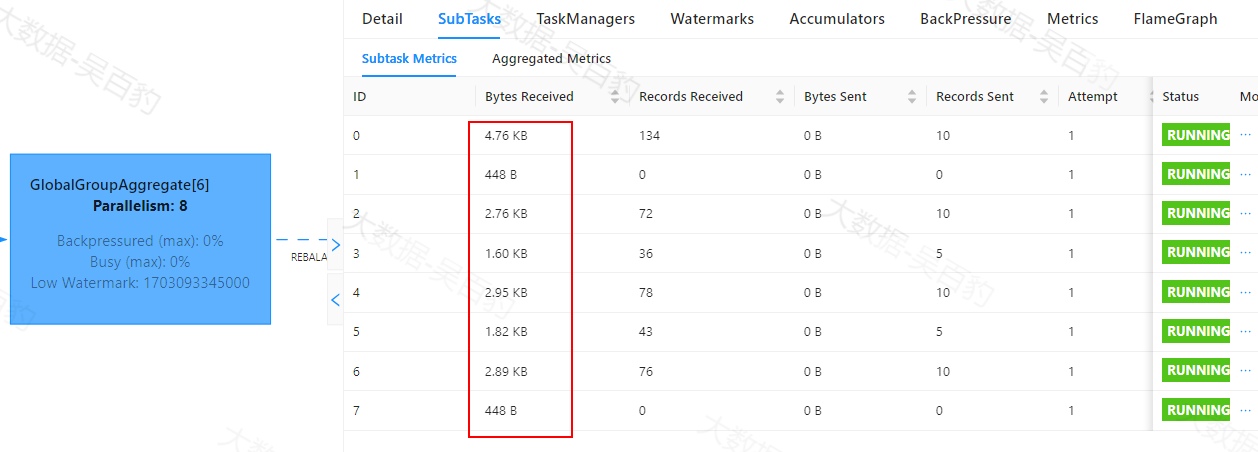
拆分distinct聚合
Local-Global 优化可有效消除常规聚合的数据倾斜,例如 SUM、COUNT、MAX、MIN、AVG。但是在处理 distinct 聚合时,其性能并不令人满意。例如,如果我们要分析今天有多少唯一用户登录。我们可能有以下查询:
SELECT day, COUNT(DISTINCT user_id)
FROM T
GROUP BY day如果 distinct key (即 user_id)的值分布稀疏且出现数据倾斜,则 COUNT DISTINCT 不适合减少数据,即使启用了 local-global 优化也没有太大帮助,因为每个并行可能仍然包含几乎所有原始记录,并且全局聚合将成为瓶颈(大多数繁重的累计操作由一个并行实例处理)。
以上这种优化就可以使用拆分distinct聚合方式来解决。其优化原理是将不同的聚合(例如 COUNT(DISTINCT col))分为两个级别。第一次聚合由 group key 和额外的 bucket key 进行 shuffle。bucket key 是使用 HASH_CODE(distinct_key) % BUCKET_NUM 计算的。BUCKET_NUM 默认为1024,可以通过 table.optimizer.distinct-agg.split.bucket-num 选项进行配置。第二次聚合是由原始 group key 进行 shuffle,并使用 SUM 聚合来自不同 buckets 的 COUNT DISTINCT 值。由于相同的 distinct key 将仅在同一 bucket 中计算,因此转换是等效的。bucket key 充当附加 group key 的角色,以分担 group key 中热点的负担。bucket key 使 job 具有可伸缩性来解决不同聚合中的数据倾斜/热点。
拆分distinct聚合后,以上查询将自动改写为如下查询:
SELECT day, SUM(cnt)
FROM (
SELECT day, COUNT(DISTINCT user_id) as cnt
FROM T
GROUP BY day, MOD(HASH_CODE(user_id), 1024)
)GROUP BY day下图显示了拆分 distinct 聚合如何提高性能(假设颜色表示 days,字母表示 user_id)。
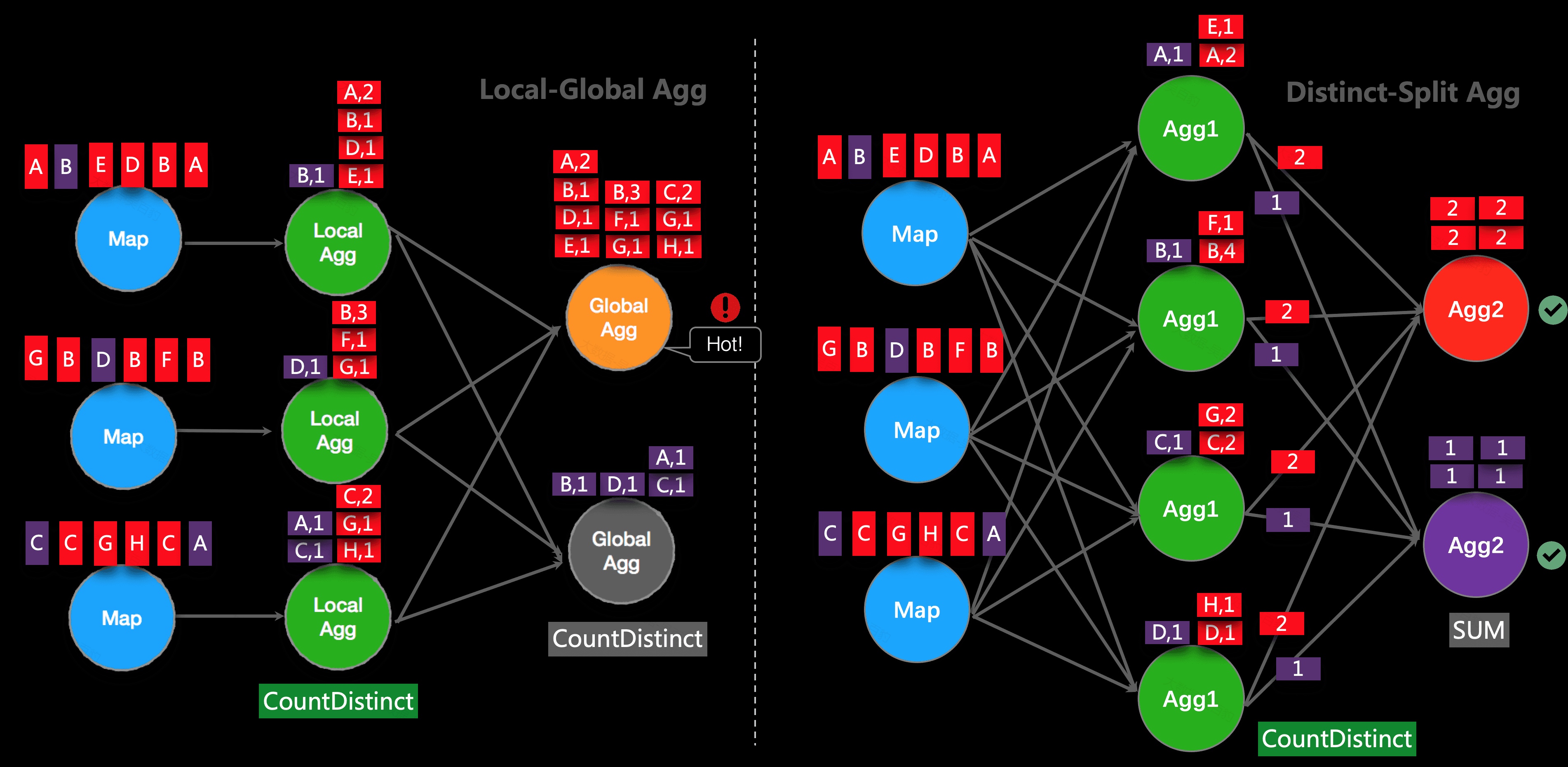
拆分distinct聚合时有如下两个注意点:
-
上面是可以从这个优化中受益的最简单的示例。除此之外,Flink 还支持拆分更复杂的聚合查询,例如,多个具有不同 distinct key (例如 COUNT(DISTINCT a), SUM(DISTINCT b) )的 distinct 聚合,可以与其他非 distinct 聚合(例如 SUM、MAX、MIN、COUNT )一起使用。
-
当前拆分优化不支持包含用户定义的 AggregateFunction 聚合。
在Flink Table和SQL编程中设置拆分distinct聚合优化方式如下:
//初始化 table environment
TableEnvironment tEnv = ...;
//通过flink configuration进行参数设置
TableConfig configuration = tEnv.getConfig();
//开启拆分distinct 聚合
configuration.set("table.optimizer.distinct-agg.split.enabled", "true"); 如下案例中,按照基站分组对通话类型去重统计,即使设置了Local-Global聚合操作,在不开启拆分distinct 聚合时,最终处理数据还是存在各个Task处理数据不均衡问题。
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//创建流处理执行环境
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.创建TableEnv
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//通过flink configuration进行参数设置
TableConfig configuration = tableEnv.getConfig();
//开启MiniBatch 优化,默认false
configuration.set("table.exec.mini-batch.enabled", "true");
//设置5秒时间处理缓冲数据,默认0s
configuration.set("table.exec.mini-batch.allow-latency", "5 s");
//设置每个聚合操作可以缓冲的最大记录数,默认-1,开启MiniBatch后必须设置为正值
configuration.set("table.exec.mini-batch.size", "5000");
//设置Local-Global 聚合
configuration.set("table.optimizer.agg-phase-strategy", "TWO_PHASE");
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
/**
* 主要方法:启动一个Source,大部分情况下都需要在run方法中实现一个循环产生数据
* 这里计划1s 产生1条基站数据,由于是并行,当前节点有几个core就会有几条数据
*/
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
// 获取当前子任务的索引
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
while (flag) {
String sid = "sid_" + random.nextInt(10);
// 如果是0号子任务,生成更多数据
if (subtaskIndex == 0) {
for (int i = 0; i < 100; i++) {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
} else {
// 数据生成逻辑
generateData(ctx, random, sid, callTypes);
}
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
if (sid.equals("sid_0")) {
for (int i = 0; i < 100; i++) {
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
}
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//将DataStream 转换成 Table
tableEnv.createTemporaryView("stationlog_tbl", ds1);
//打印表结构
Table table = tableEnv.from("stationlog_tbl");
table.printSchema();
TableResult result = tableEnv.executeSql("" +
"select " +
" sid,count(distinct callType) as total_callType " +
"from stationlog_tbl " +
"group by sid");
result.print();以上代码运行后,可以通过WebUI观察执行情况如下:

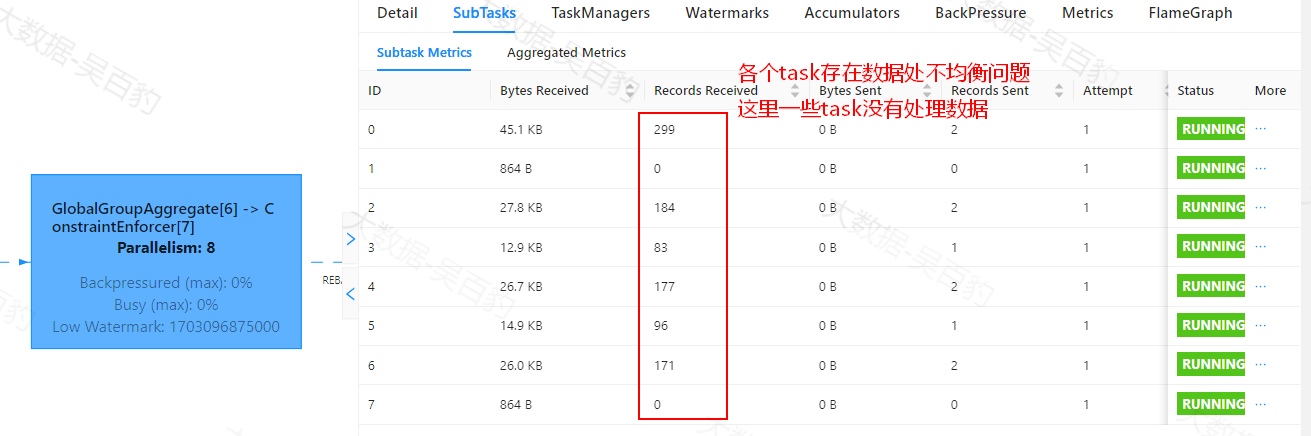
当设置拆分distinct聚合参数后,可以看到执行图中多了xxx阶段,并且后续聚合阶段各个task处理数据量相对均衡。只需要在代码中加入如下配置:
... ...
//3.设置拆分distinct聚合
configuration.set("table.optimizer.distinct-agg.split.enabled", "true");
... ...代码执行后WbeUI信息:

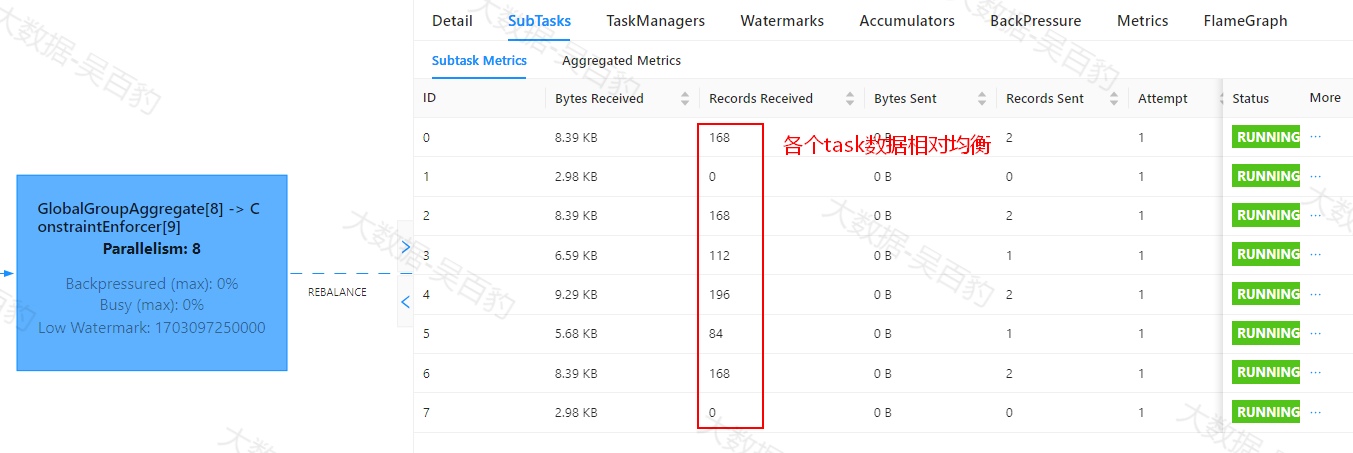
使用Filter修饰符
在某些情况下,用户可能需要从不同维度计算 UV(独立访客)的数量,例如来自 Android 的 UV、iPhone 的 UV、Web 的 UV 和总 UV。很多人会选择 CASE WHEN,例如:
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone') THEN user_id ELSE NULL END) AS app_uv,
COUNT(DISTINCT CASE WHEN flag IN ('wap', 'other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day以上SQL中三个查询指标都是针对user_id进行去重统计,每个查询的指标都会维护一个状态实例,导致Flink维护状态过大。在这种情况下,建议使用 FILTER 语法替换 CASE WHEN语法,因为 FILTER 更符合 SQL 标准且能获得更多的性能提升。将上面的示例替换为 FILTER 修饰符,如下所示:
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY dayFlink SQL 优化器可以识别相同的 distinct key 上的不同过滤器参数。例如,在上面的示例中,三个 COUNT DISTINCT 都在 user_id 一列上,Flink 可以只使用一个共享状态实例,而不是三个状态实例,以减少状态访问和状态大小,在某些工作负载下,可以获得显著的性能提升。
如下代码示例中,使用case when 来统计每个基站中通话时间处于某个时间长度的个数。
//1.使用本地模式
Configuration conf = new Configuration();
//设置WebUI绑定的本地端口
conf.setString(RestOptions.BIND_PORT,"8081");
//使用配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//开启checkpoint
env.enableCheckpointing(5000);
//创建流处理执行环境
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.创建TableEnv
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//3.开启minibatch
//通过flink configuration进行参数设置
TableConfig configuration = tableEnv.getConfig();
//开启MiniBatch 优化,默认false
configuration.set("table.exec.mini-batch.enabled", "true");
//设置5秒时间处理缓冲数据,默认0s
configuration.set("table.exec.mini-batch.allow-latency", "5 s");
//设置每个聚合操作可以缓冲的最大记录数,默认-1,开启MiniBatch后必须设置为正值
configuration.set("table.exec.mini-batch.size", "5000");
DataStreamSource<StationLog> ds1 = env.addSource(new RichParallelSourceFunction<StationLog>() {
Boolean flag = true;
@Override
public void run(SourceContext<StationLog> ctx) throws Exception {
Random random = new Random();
String[] callTypes = {"fail", "success", "busy", "barring"};
while (flag) {
String sid = "sid_" + random.nextInt(10);
generateData(ctx, random, sid, callTypes);
Thread.sleep(50);
}
}
private void generateData(SourceContext<StationLog> ctx, Random random, String sid, String[] callTypes) {
String callOut = "1811234" + (random.nextInt(9000) + 1000);
String callIn = "1915678" + (random.nextInt(9000) + 1000);
String callType = callTypes[random.nextInt(4)];
Long callTime = System.currentTimeMillis();
Long durations = Long.valueOf(random.nextInt(50) + "");
ctx.collect(new StationLog(sid, callOut, callIn, callType, callTime, durations));
}
//当取消对应的Flink任务时被调用
@Override
public void cancel() {
flag = false;
}
});
//将DataStream 转换成 Table
tableEnv.createTemporaryView("stationlog_tbl", ds1);
//打印表结构
Table table = tableEnv.from("stationlog_tbl");
table.printSchema();
//使用CaseWhen实现
TableResult result = tableEnv.executeSql("" +
"SELECT" +
" sid, " +
" COUNT(DISTINCT callOut) AS total_sid_cnt, " +
" COUNT(DISTINCT CASE WHEN duration >= 20 AND duration <40 THEN callOut ELSE NULL END) AS middle_sid_cnt, " +
" COUNT(DISTINCT CASE WHEN duration >= 40 AND duration <50 THEN callOut ELSE NULL END) AS long_sid_cnt " +
"FROM stationlog_tbl " +
"GROUP BY sid ");
result.print();以上代码执行后可以观察FlinkWebUI 每次checkpoint大小如下:
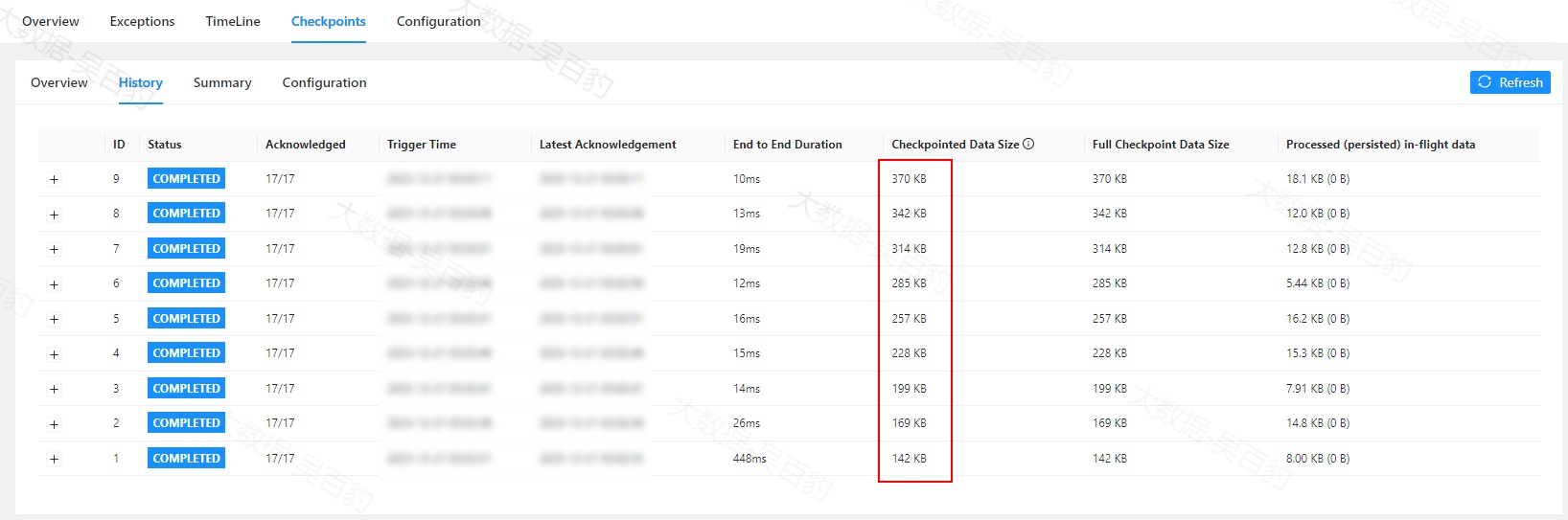
将代码中的SQL替换成Filter实现方式,如下:
TableResult result2 = tableEnv.executeSql("" +
"SELECT" +
" sid, " +
" COUNT(DISTINCT callOut) AS total_sid_cnt, " +
" COUNT(DISTINCT callOut) FILTER (WHERE duration>=20 and duration <40) AS middle_sid_cnt, " +
" COUNT(DISTINCT callOut) FILTER (WHERE duration>=40 and duration <50) AS long_sid_cnt " +
"FROM stationlog_tbl " +
"GROUP BY sid ");可以观察WebUI对应的Checkpoint状态大小,明显较Case When 实现方式管理状态少。