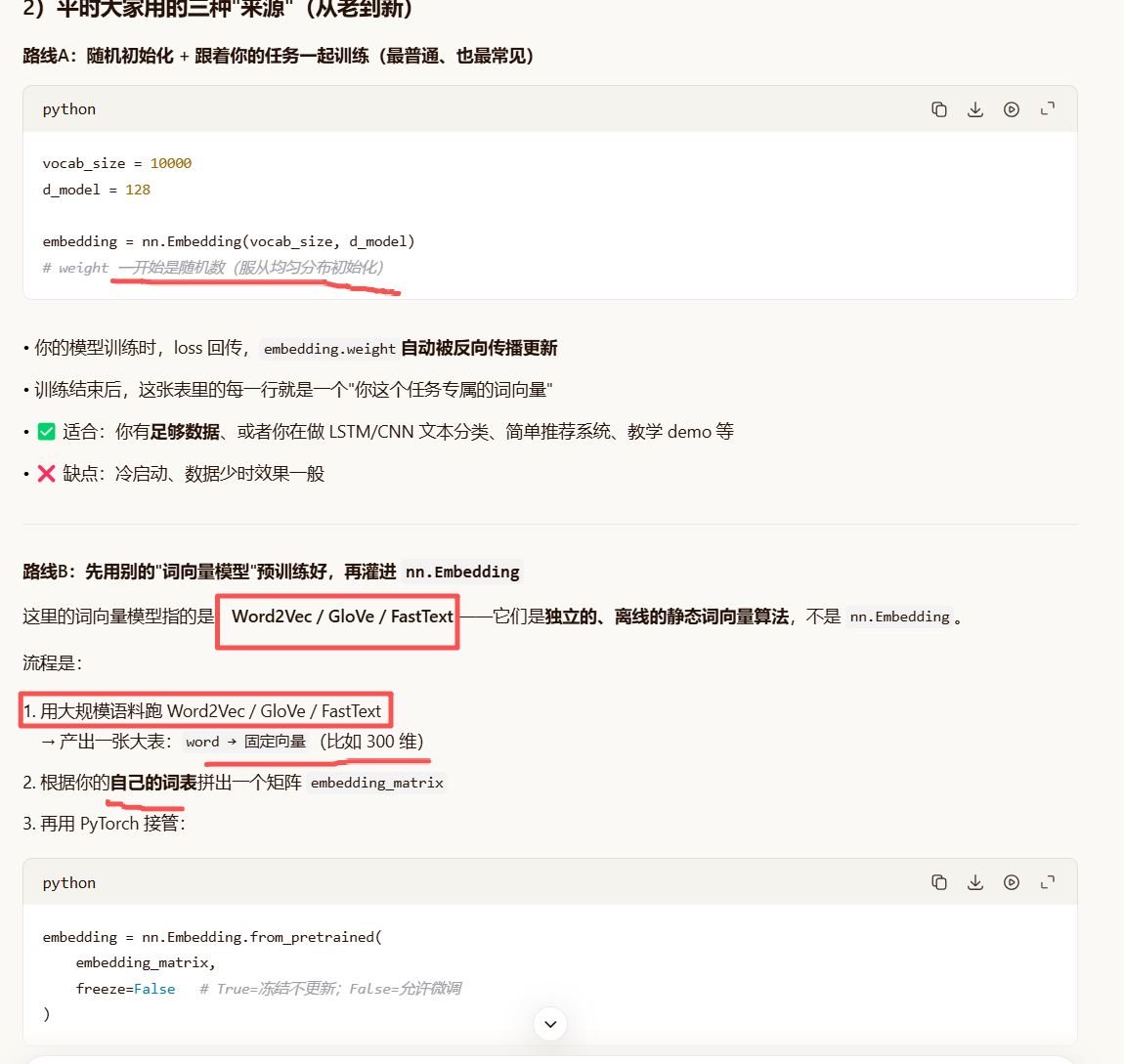
embedding(one-hot+linear重要 )
embedding详细的去看吴恩达词嵌入章节,和onehot不一样
本质上就是一张表:行号=词的编号,每行=这个词对应的向量
embedding = nn.Embedding(num_embeddings=词表大小, embedding_dim=向量维度)
内部等价于一个矩阵 weight.shape == 词表大小, 向量维度
embedding可以理解为one-hot+linear embedding这一块得先去看词向量是怎么抽象出来的
embeding一是能够压缩空间,二是它的参数是能够学习的,可以捕捉前后词元的关系,本质是矩阵相乘
embed 是word2vec的思想,把词典里one-hot编码的字或者词,变成预训练(可能需要微调)的词向量 onehot是最简单的一种embedding,复杂的word2vec之类的可以有更好的语义表达 embed就是对onehot的降维
以单词为例,用one hot,那么good和bad的"距离"与good和best的"距离"是一样的。但word2vec之后,good和best的"距离"就比和bad的"距离"近多了。 简单来说就是由于vocal_size太大了,已经不能用独热编码了,这个embedding就是使用某种方式来能够唯一表示每一个词元。
embed的第一维是vocal_size大小,第二维是embed_size。embed_size类似于之前RNN的vocab_size,实际上都是input_size
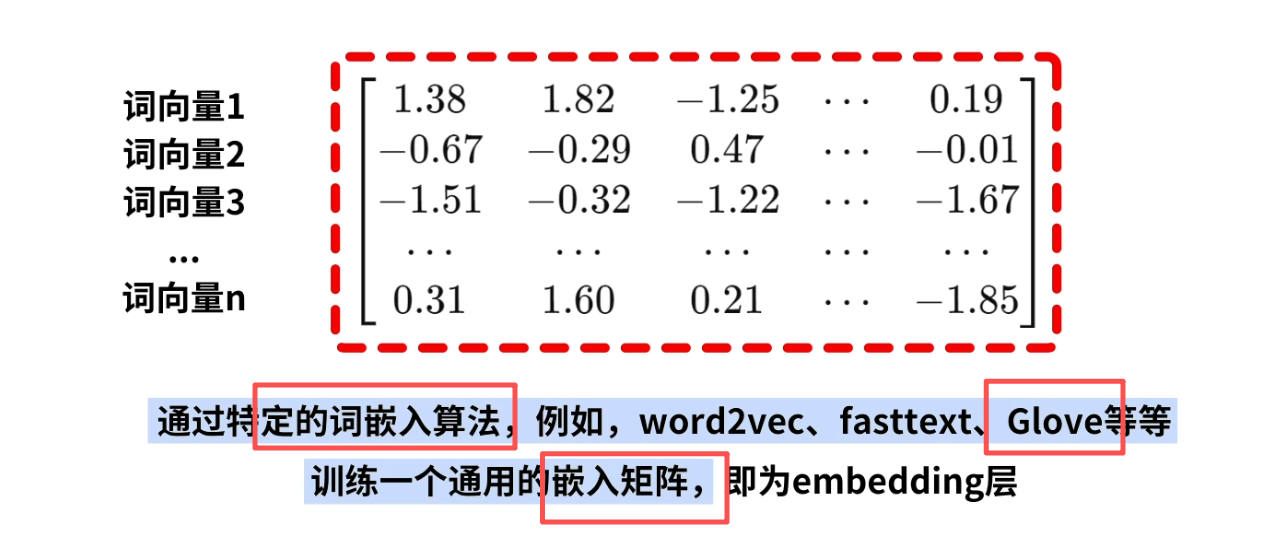
这些值一般是随机生成,后续根据损失函数利用反向传播进行调整
例子:
理解1:矩阵相乘 左乘行变换
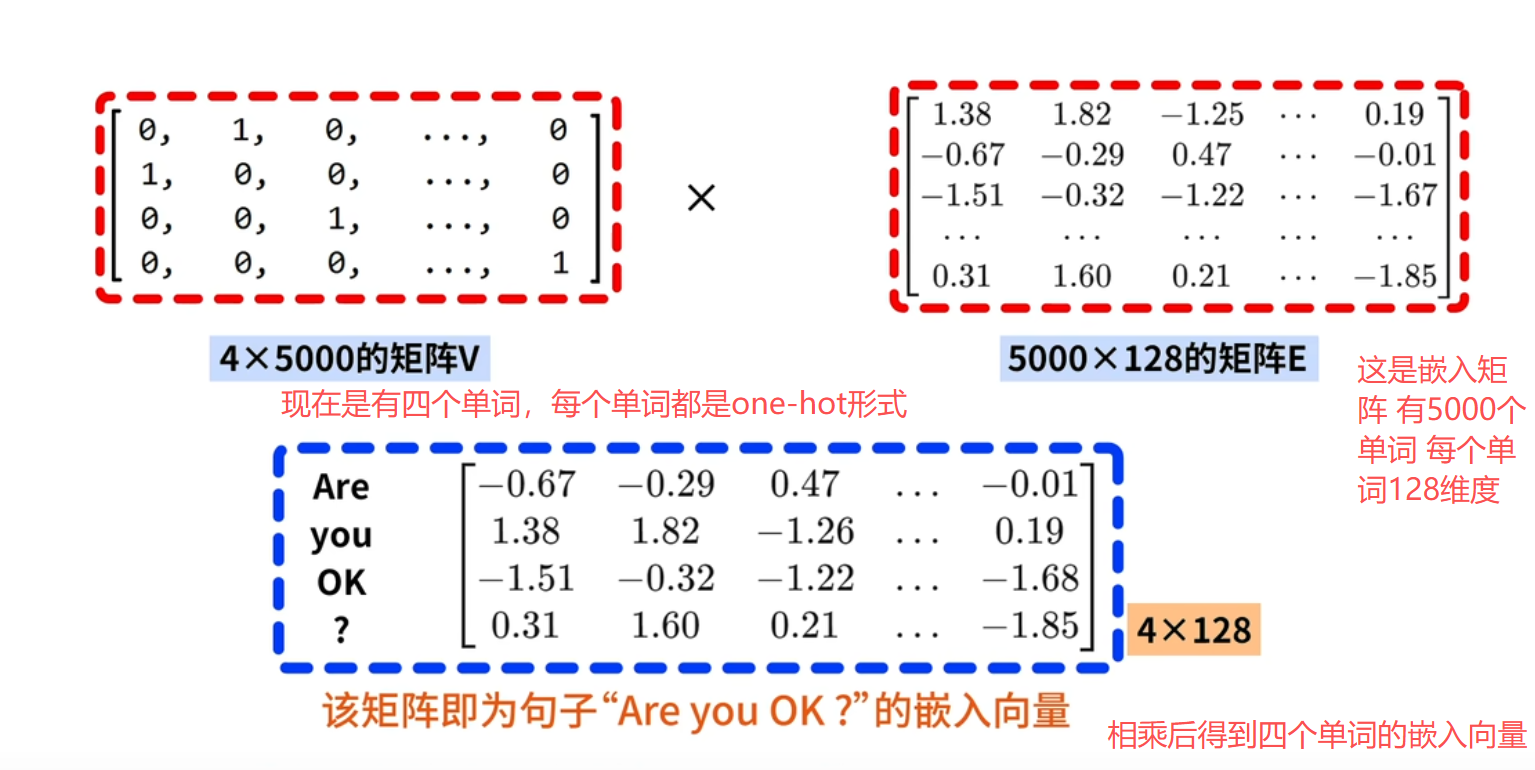
理解2:
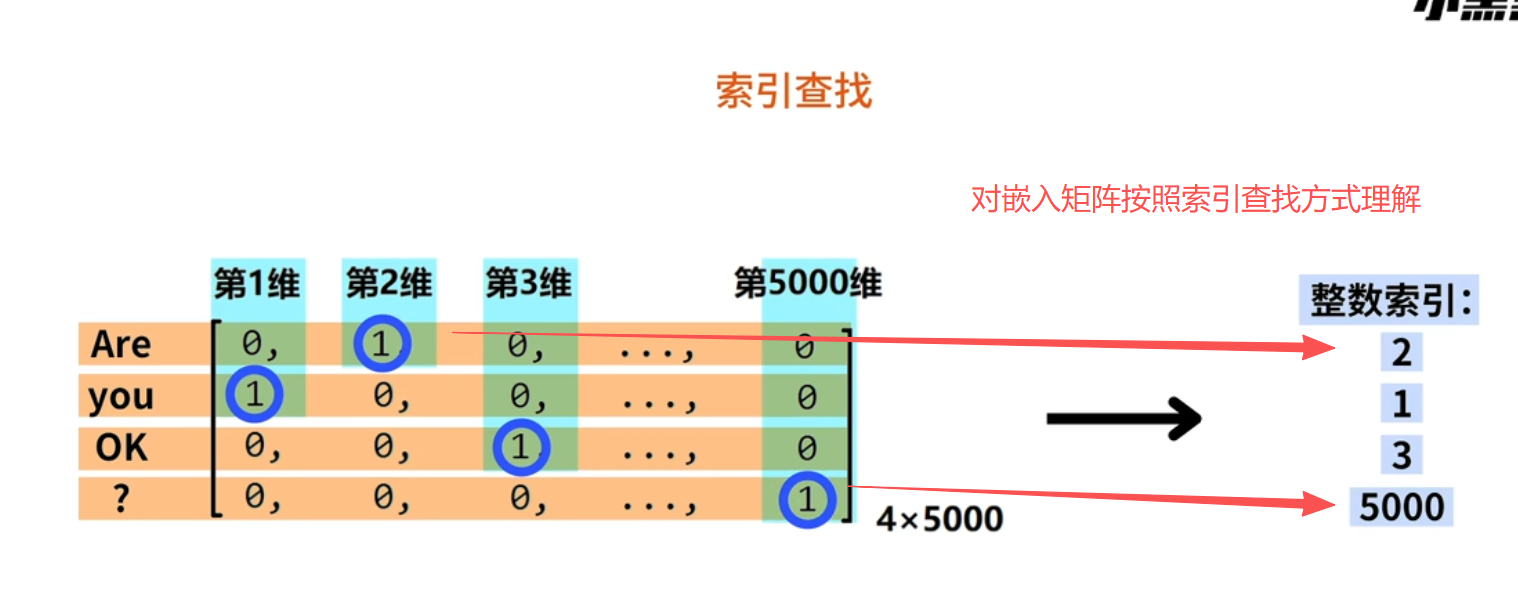
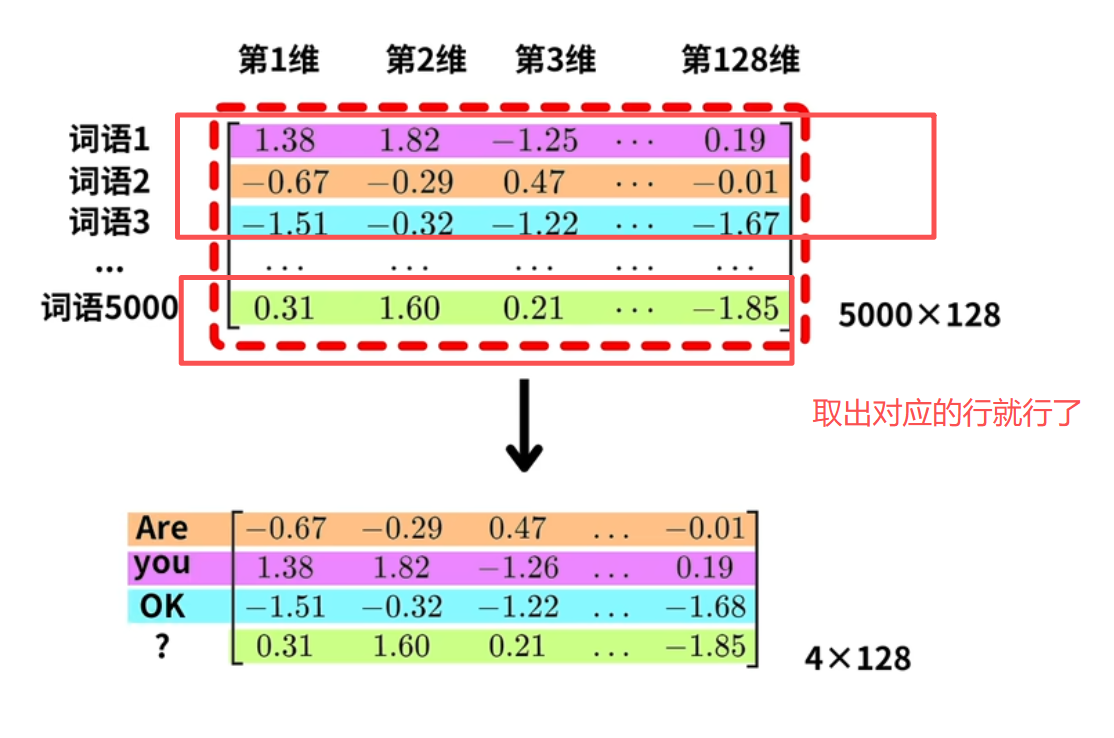
其实就是查表 这个就是嵌入层最精妙的地方,保留了稀疏矩阵的优点,又增加词的可用性
其实这还有一个点,就是embedding的维度。这个其实是fasttext,Word2vec,这些模型在训练数据时,使用的神经元的隐藏层的结果。先初始化,再在预料上训练,最后得到每个词嵌入结果。
使用预训练模型的词向量代码
python
# 运行前请安装依赖:
# pip install torch torchtext scikit-learn matplotlib
import torch
import torch.nn as nn
from torchtext.vocab import GloVe # torchtext 内置的 GloVe 加载器
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# ==========================================
# 1. 加载预训练的 GloVe 词向量
# ==========================================
# 首次运行会自动下载 GloVe 文件(约 800 MB)到 ~/.vector_cache/
# 这里使用 6B 语料库、100 维(速度快);若想匹配原图的 300 维,可将 dim 改为 300
print("正在加载 GloVe 词向量...")
glove = GloVe(name='6B', dim=100) # 也可以改成 dim=300
# ==========================================
# 2. 创建 nn.Embedding 层,并用预训练权重初始化
# ==========================================
embedding = nn.Embedding.from_pretrained(glove.vectors)
print(f"Embedding 权重形状: {embedding.weight.shape}") # 例如 [400000, 100]
# ==========================================
# 3. 选取特定单词,获取它们的向量
# ==========================================
words = ['man', 'woman', 'king', 'queen', 'cat', 'dog', 'mother', 'father']
indices = []
print("\n--- 单词 → 索引 ---")
for word in words:
idx = glove.stoi[word] # stoi: string to index
indices.append(idx)
print(f"{word} → {idx}")
indices = torch.tensor(indices)
# ------------------------------------------
# 【关键】detach() 的作用:
# 1. embedding(indices) 返回的张量默认会记录梯度,以便后续反向传播。
# 2. 但我们这里只需要拿到数值来做可视化,完全不需要梯度。
# 3. detach() 将这个张量从计算图中"剥离",变成一个普通的、不需要梯度的张量。
# 4. 这样做可以节省显存/内存,并且之后调用 .numpy() 时不会报错(带梯度的张量不能直接转numpy)。
# ------------------------------------------
vectors = embedding(indices).detach().numpy()
print(f"\n提取到的向量形状: {vectors.shape}") # [8, 100] 或 [8, 300]
# ==========================================
# 4. PCA 降维:从高维(100/300)降到 2 维
# ==========================================
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
# ==========================================
# 5. 用 Matplotlib 画散点图 + 标注
# ==========================================
plt.figure(figsize=(10, 8))
plt.scatter(vectors_2d[:, 0], vectors_2d[:, 1])
for i, word in enumerate(words):
plt.annotate(word,
xy=(vectors_2d[i, 0], vectors_2d[i, 1]),
xytext=(-10, 10),
textcoords='offset points')
plt.title("词向量 PCA 可视化")
plt.grid(True)
plt.show()embedding发展:
transformer的embedding层又是由transformer架构的模型训练出来的,所以这里存在一个先有鸡还是先有蛋的问题 如果我的理解没有问题的话,应该是先有word2vec
谷歌搞搜索先有word2vec,然后搞出transformer,embedding其实再叠加了位置信息
embedding计算过程:
pytorch.org/docs/stable/generated/torch.nn.Embedding.html (官网有提到作用原理)

前向计算:
python
# an Embedding module containing 10 tensors of size 3
embedding = nn.Embedding(10, 3) #v==10 h==3
embedding.weight
#输出
Parameter containing:
tensor([[ 0.8376, 0.6068, 1.7555],
[ 0.4941, 0.1717, -0.2396],
[-1.8685, 1.2610, -0.5606],
[ 0.8324, 1.0663, 1.2586],
[-0.7126, -0.8973, -2.2054],
[ 0.7383, 0.2399, 0.1330],
[-1.3319, -0.5330, 0.9591],
[ 0.7808, -0.2259, 0.1930],
[ 1.1298, 0.1678, 1.1490],
[-0.6612, -0.9927, -0.4817]], requires_grad=True)
# a batch of 2 samples of 4 indices each
# b==2, s==4,
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
print(input.dtype)
#输出
torch.int64
# (b, s, ) => (b, s, h) h==3
embedding(input)
#输出
tensor([[[ 0.4941, 0.1717, -0.2396],
[-1.8685, 1.2610, -0.5606],
[-0.7126, -0.8973, -2.2054],
[ 0.7383, 0.2399, 0.1330]],
[[-0.7126, -0.8973, -2.2054],
[ 0.8324, 1.0663, 1.2586],
[-1.8685, 1.2610, -0.5606],
[-0.6612, -0.9927, -0.4817]]], grad_fn=<EmbeddingBackward0>)onehot矩阵乘法:
python
# num_classes == vocab size
# (b, s) => (b, s, v)
input_onehot = F.one_hot(input, num_classes=10)
print(input_onehot.shape)
input_onehot
torch.Size([2, 4, 10])
tensor([[[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]],
[[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]]])
print(embedding.weight.dtype)
print(embedding.weight.shape)
torch.float32
torch.Size([10, 3])
# input_onehot.shape: (b, s, v)
# embedding.weight.shape: (v, h)
# (b, s, h)
torch.matmul(input_onehot.type(torch.float32), embedding.weight)
tensor([[[ 0.4941, 0.1717, -0.2396],
[-1.8685, 1.2610, -0.5606],
[-0.7126, -0.8973, -2.2054],
[ 0.7383, 0.2399, 0.1330]],
[[-0.7126, -0.8973, -2.2054],
[ 0.8324, 1.0663, 1.2586],
[-1.8685, 1.2610, -0.5606],
[-0.6612, -0.9927, -0.4817]]], grad_fn=<UnsafeViewBackward0>)max-norm参数补充:
不带max-norm:
python
# 定义一个 Embedding 层:词汇表大小=3,每个词向量维度=5
embedding = nn.Embedding(3, 5)
# 查看初始化后权重的均值和标准差(随机初始化)
print(embedding.weight.mean()) # 输出均值,例如 tensor(0.0240)
print(embedding.weight.std()) # 输出标准差,例如 tensor(0.6895)
# 打印整个权重矩阵(形状 [3,5])
print(embedding.weight)
# 计算每个词向量的 L2 范数(沿 dim=1 计算)
torch.norm(embedding.weight, dim=1)
# 输出类似:tensor([1.5840, 0.7675, 1.8884])
# 表示三个词向量的长度分别为 1.58, 0.77, 1.89
# 构造输入索引:0,1,2(三个词的编号)
inputs = torch.tensor([0, 1, 2])
print(inputs.shape) # torch.Size([3])
# 查表:将索引映射为对应的向量
outputs = embedding(inputs)
# outputs 形状 [3,5],内容与 embedding.weight 完全相同
print(outputs)
# 再次计算 outputs 的 L2 范数(与前面结果一致)
torch.norm(outputs, dim=1)
# tensor([1.5840, 0.7675, 1.8884])带max-norm:
python
# 定义 Embedding 层,并设置 max_norm=True(等价于 max_norm=1)
embedding = nn.Embedding(3, 5, max_norm=True)
# 查看初始化后权重的均值和标准差(仍然是随机初始化,但后续 forward 时会截断)
print(embedding.weight.mean()) # 例如 tensor(0.1015)
print(embedding.weight.std()) # 例如 tensor(1.2156)
# 打印权重矩阵(注意:此时的权重是原始随机值,还未被截断)
print(embedding.weight)
# 可以看到各向量的范数可能大于 1,例如 tensor([2.9869, 2.9021, 1.8704])
# 计算原始权重的 L2 范数(大于 1)
torch.norm(embedding.weight, dim=1)
# tensor([2.9869, 2.9021, 1.8704])
# 构造输入索引
inputs = torch.tensor([0, 1, 2])
print(inputs.shape) # torch.Size([3])
# 查表:此时由于 max_norm=1,在 forward 过程中会对权重进行"就地"截断
outputs = embedding(inputs)
# outputs 形状 [3,5],但内容不再是原始权重,而是经过归一化后的向量
print(outputs)
# 例如输出:
# [[ 0.2454, -0.0920, 0.1727, -0.8421, 0.4385],
# [ 0.1423, -0.1673, 0.7201, -0.0453, 0.6566],
# [-0.3672, -0.1644, -0.4596, -0.6068, 0.5086]]
# 计算 outputs 的 L2 范数:全部变为 1.0000
torch.norm(outputs, dim=1)
# tensor([1.0000, 1.0000, 1.0000])
# 再次查看 embedding.weight,发现它已经被原地修改为截断后的值
print(embedding.weight)
# 与 outputs 的内容一致
torch.norm(embedding.weight, dim=1)
# tensor([1.0000, 1.0000, 1.0000])3️⃣ max_norm的作用详解

基本功能
max_norm是 nn.Embedding的一个参数,用于限制每个词向量的最大 L2 范数。
-
当
max_norm=None(默认)时,词向量可以任意大。 -
当
max_norm=p(正数)时,每次 forward 过程中,如果某个词向量的 L2 范数超过p,则会将该向量缩放到范数为p(即除以原范数再乘以p)。 -
特殊用法:
max_norm=True等价于max_norm=1(即限制范数不超过 1)。
工作原理
-
在
forward阶段(即embedding(inputs)调用时),PyTorch 会检查权重矩阵中每个向量的 L2 范数。 -
如果某个向量的范数 >
max_norm,则对该向量进行缩放:v_new = v * (max_norm / ||v||) -
这个缩放是就地(in-place) 进行的,即会直接修改
embedding.weight中的数据,因此后续的查询都会使用截断后的向量。
为什么需要 max_norm?
-
防止过拟合:限制词向量的大小可以作为一种正则化手段,避免某些词向量变得过大而导致模型不稳定。
-
提高数值稳定性:在后续的运算(如点积、余弦相似度)中,向量范数过大可能导致梯度爆炸。
-
保证语义可比性:当所有词向量的范数都相同时,余弦相似度就完全由夹角决定,便于比较语义方向。
注意事项
-
max_norm是在 forward 时生效,训练过程中会持续截断,因此权重矩阵会被不断修改。 -
如果希望权重不被截断(例如使用预训练向量),则不应设置
max_norm。 -
截断操作会引入一定的信息损失,但在很多任务中利大于弊。
nn.Embedding训练原理代码:
python
# ============================================================
# 04_embedding_details.py
# nn.Embedding 逐行拆解:从 One-Hot 到 Lookup Table 到训练更新
# ============================================================
import torch
import torch.nn as nn
import torch.optim as optim
# ============================================================
# 0. 准备一个极小的"词汇表",手动做映射
# ============================================================
vocab = ['<pad>', 'the', 'cat', 'sat', 'on', 'mat']
word2idx = {w: i for i, w in enumerate(vocab)}
V = len(vocab) # 词汇表大小 = 6
D = 4 # 我们故意用很小的 dim,方便你看数字
print("=== 词汇表 ===")
print(word2idx)
# ============================================================
# 1. One-Hot 回忆杀:为什么 One-Hot 不行?
# ============================================================
print("\n=== 1. One-Hot(作为对照)===")
import torch.nn.functional as F
#onehot原理
def one_hot(idx, size):
v = torch.zeros(size)
v[idx] = 1.0
return v
for w in ['the', 'cat']:
oh = one_hot(word2idx[w], V)
print(f"One-Hot({w!r}) = {oh}")
# 问题:One-Hot 维度 = V(一万词就一万维),而且任意两不同词的内积 = 0(正交)
# → 完全表达不了"cat 和 sat 比 cat 和 mat 在语义上谁更近"
# ============================================================
# 2. nn.Embedding 的本质:可学习的 Lookup Table(查找表)
# ============================================================
print("\n=== 2. nn.Embedding:查表,不是矩阵乘 ===")
emb = nn.Embedding(num_embeddings=V, embedding_dim=D, padding_idx=0)
# ↑ padding_idx=0:index 0(<pad>)对应的那行向量永远初始为 0,且不参与梯度
print(f"emb.weight.shape = {emb.weight.shape}")
# 输出:torch.Size([6, 4])
# ---- 查看初始随机值 ----
print("\n初始 weight(查找表):")
with torch.no_grad():
for i, w in enumerate(vocab):
print(f" [{i}] {w!r:6s} -> {emb.weight[i].tolist()}")
# ---- 用整数索引查表 ----
ids = torch.LongTensor([word2idx['cat'], word2idx['sat'], word2idx['the']])
vecs = emb(ids)
print(f"\n查表 emb([cat,sat,the]) 输出 shape: {vecs.shape}")
print(vecs)
# 等价于:分别取出 weight[2], weight[3], weight[1]
# ============================================================
# 3. 等价视角:Embedding(x) == OneHot(x) @ weight (但 Embedding 更快更省)
# ============================================================
print("\n=== 3. 证明:Embedding 等价于 One-Hot × 矩阵(理论视角)===")
def emb_via_onehot(ids, weight):
"""用 One-Hot 乘 weight 来模拟 Embedding(慢,但数学等价)"""
batch = []
for idx in ids:
oh = F.one_hot(idx, num_classes=V).float()
batch.append(oh @ weight)
return torch.stack(batch)
with torch.no_grad():
slow = emb_via_onehot(ids, emb.weight)
fast = emb(ids)
print("fast (Embedding 查表) =\n", fast)
print("slow (OneHot @ weight) =\n", slow)
print("是否完全一致(忽略梯度追踪):", torch.allclose(fast, slow))
# ============================================================
# 4. padding_idx 的效果
# ============================================================
print("\n=== 4. padding_idx=0 的效果 ===")
pad_vec = emb(torch.LongTensor([0]))
print("emb(<pad>) =", pad_vec) # 应该是全 0
# ============================================================
# 5. 梯度会流回 weight:跑一个小训练看看 Embedding 是怎么"被训练"的
# ============================================================
print("\n=== 5. 极小训练示例:让模型学会把 'cat' 和 'sat' 的向量拉近 ===")
emb_train = nn.Embedding(V, D, padding_idx=0)
# 假任务:
# 输入 = cat 的 id,预测 = sat 的 id
# 我们用一个最简单的线性 probe:先从 emb 取出向量 → Linear → logits over vocab
probe = nn.Linear(D, V, bias=False)
optimizer = optim.SGD(list(emb_train.parameters()) + list(probe.parameters()), lr=0.3)
criterion = nn.CrossEntropyLoss()
cat_id = torch.LongTensor([word2idx['cat']]) # 输入
sat_id = torch.LongTensor([word2idx['sat']]) # 目标
print("\n训练前:")
with torch.no_grad():
print(" cat 向量 =", emb_train(cat_id))
print(" sat 向量 =", emb_train(sat_id))
print(" 余弦相似度 =",
F.cosine_similarity(emb_train(cat_id), emb_train(sat_id)).item())
# ---- 训练循环 ----
for step in range(120):
optimizer.zero_grad()
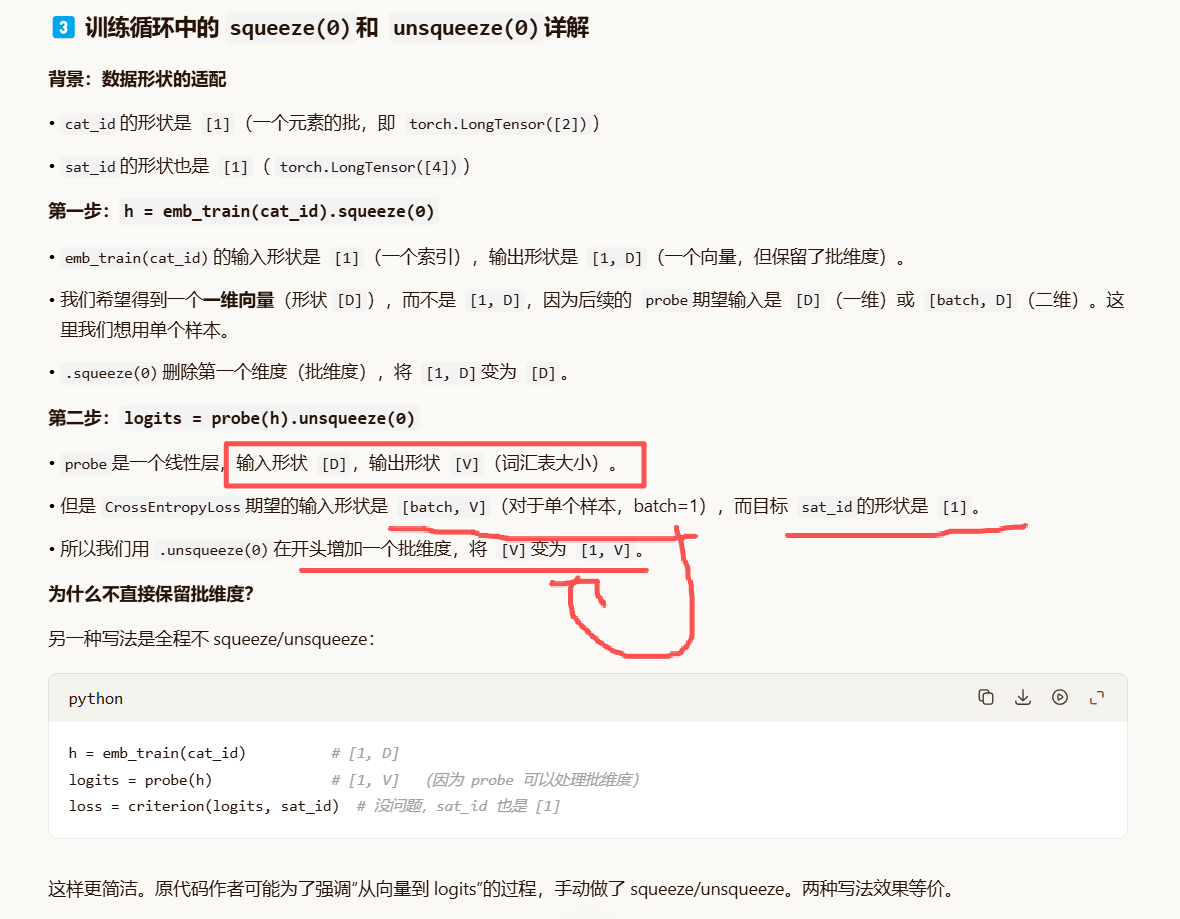
h = emb_train(cat_id).squeeze(0) # [D]
logits = probe(h).unsqueeze(0) # [1, V]
loss = criterion(logits, sat_id)
loss.backward()
optimizer.step()
print("\n训练后:")
with torch.no_grad():
print(" cat 向量 =", emb_train(cat_id))
print(" sat 向量 =", emb_train(sat_id))
cos = F.cosine_similarity(emb_train(cat_id), emb_train(sat_id)).item()
print(" 余弦相似度(越大越同向)=", cos)
# 注意:loss 算出来后 backward(),梯度一路回传到 emb_train.weight
# → 这就是你上一问里说的"没显式训练 embedding,但它其实在训练"的原因
# ============================================================
# 6. 如果你想"冻结" embedding(不让它更新)
# ============================================================
print("\n=== 6. 冻结(freeze)示例 ===")
emb_freeze = nn.Embedding.from_pretrained(emb_train.weight.data.clone(), freeze=True)
print("requires_grad?", emb_freeze.weight.requires_grad) # False
# 此时 emb_freeze(ids) 参与 forward 也不会更新权重
print("\n✅ 全部演示跑完。要点:")
print(" 1) nn.Embedding = 查找表(weight[index])")
print(" 2) 输入必须是整数 LongTensor,范围是 [0, num_embeddings-1]")
print(" 3) padding_idx 那行初始为 0 且通常不更新")
print(" 4) 只要你把 emb(...) 的输出接进有 loss 的网络里并 backward,它就会被训练")
print(" 5) freeze=True / requires_grad_(False) 才能把它当『固定预训练向量』用")结果:
python
=== 词汇表 ===
{'<pad>': 0, 'the': 1, 'cat': 2, 'sat': 3, 'on': 4, 'mat': 5}
=== 1. One-Hot(作为对照)===
One-Hot('the') = tensor([0., 1., 0., 0., 0., 0.])
One-Hot('cat') = tensor([0., 0., 1., 0., 0., 0.])
=== 2. nn.Embedding:查表,不是矩阵乘 ===
emb.weight.shape = torch.Size([6, 4])
初始 weight(查找表):
[0] '<pad>' -> [0.0, 0.0, 0.0, 0.0]
[1] 'the' -> [0.08579888939857483, 0.6406185626983643, 0.4436138868331909, 0.720757782459259]
[2] 'cat' -> [0.4685240685939789, -0.5182120203971863, -0.02361511066555977, -2.2310237884521484]
[3] 'sat' -> [-0.3302285671234131, 0.9967318177223206, -1.5859938859939575, 1.114179015159607]
[4] 'on' -> [-1.4573171138763428, -0.5354864597320557, -1.337132453918457, -1.508694052696228]
[5] 'mat' -> [0.013314490206539631, 0.27371495962142944, -0.46544134616851807, -0.5200143456459045]
查表 emb([cat,sat,the]) 输出 shape: torch.Size([3, 4])
tensor([[ 0.4685, -0.5182, -0.0236, -2.2310],
[-0.3302, 0.9967, -1.5860, 1.1142],
[ 0.0858, 0.6406, 0.4436, 0.7208]], grad_fn=<EmbeddingBackward0>)
=== 3. 证明:Embedding 等价于 One-Hot × 矩阵(理论视角)===
fast (Embedding 查表) =
tensor([[ 0.4685, -0.5182, -0.0236, -2.2310],
[-0.3302, 0.9967, -1.5860, 1.1142],
[ 0.0858, 0.6406, 0.4436, 0.7208]])
slow (OneHot @ weight) =
tensor([[ 0.4685, -0.5182, -0.0236, -2.2310],
[-0.3302, 0.9967, -1.5860, 1.1142],
[ 0.0858, 0.6406, 0.4436, 0.7208]])
是否完全一致(忽略梯度追踪): True
=== 4. padding_idx=0 的效果 ===
emb(<pad>) = tensor([[0., 0., 0., 0.]], grad_fn=<EmbeddingBackward0>)
=== 5. 极小训练示例:让模型学会把 'cat' 和 'sat' 的向量拉近 ===
训练前:
cat 向量 = tensor([[-2.1931, 0.8205, 1.6551, -0.0674]])
sat 向量 = tensor([[-0.6559, -0.0597, -2.0950, 0.0432]])
余弦相似度 = -0.3302852511405945
训练后:
cat 向量 = tensor([[-2.5309, 0.8159, 2.1445, -0.4023]])
sat 向量 = tensor([[-0.6559, -0.0597, -2.0950, 0.0432]])
余弦相似度(越大越同向)= -0.3836608827114105
=== 6. 冻结(freeze)示例 ===
requires_grad? False
✅ 全部演示跑完。要点:
1) nn.Embedding = 查找表(weight[index])
2) 输入必须是整数 LongTensor,范围是 [0, num_embeddings-1]
3) padding_idx 那行初始为 0 且通常不更新
4) 只要你把 emb(...) 的输出接进有 loss 的网络里并 backward,它就会被训练
5) freeze=True / requires_grad_(False) 才能把它当『固定预训练向量』用补充:
padding_idx=0的意思是:指定索引 0 对应的那一行向量固定为全零,并且在训练过程中不会更新。
具体作用:
1.向量固定为零,无论你怎么训练,emb.weight0始终是零向量(全 0)。
print(emb(torch.LongTensor(0))) # 输出永远是 0., 0., ..., 0.
2.不参与梯度更新:
反向传播时,padding_idx所在的行不会被计算梯度,也不会被优化器更新。这样可以保证填充位(padding token)不会学到任何无意义的语义。
3.为什么要用?
在处理变长序列时,通常会把较短的句子用 <pad>(索引 0)补齐到相同长度。
如果不设 padding_idx,模型可能会学到"0 这个 token 代表某种特殊含义",导致干扰真实语义。
而将其固定为零,相当于告诉模型:"这些位置没有任何信息,忽略它们"。
4.底层实现
PyTorch 在初始化时,直接将 weightpadding_idx置零,并将该行的 requires_grad设置为 False。在 backward()时,梯度不会流向该行。
5.限制
只能指定一个 padding_idx(例如 0),不能同时指定多个。指定的索引必须在 0, num_embeddings-1范围内。

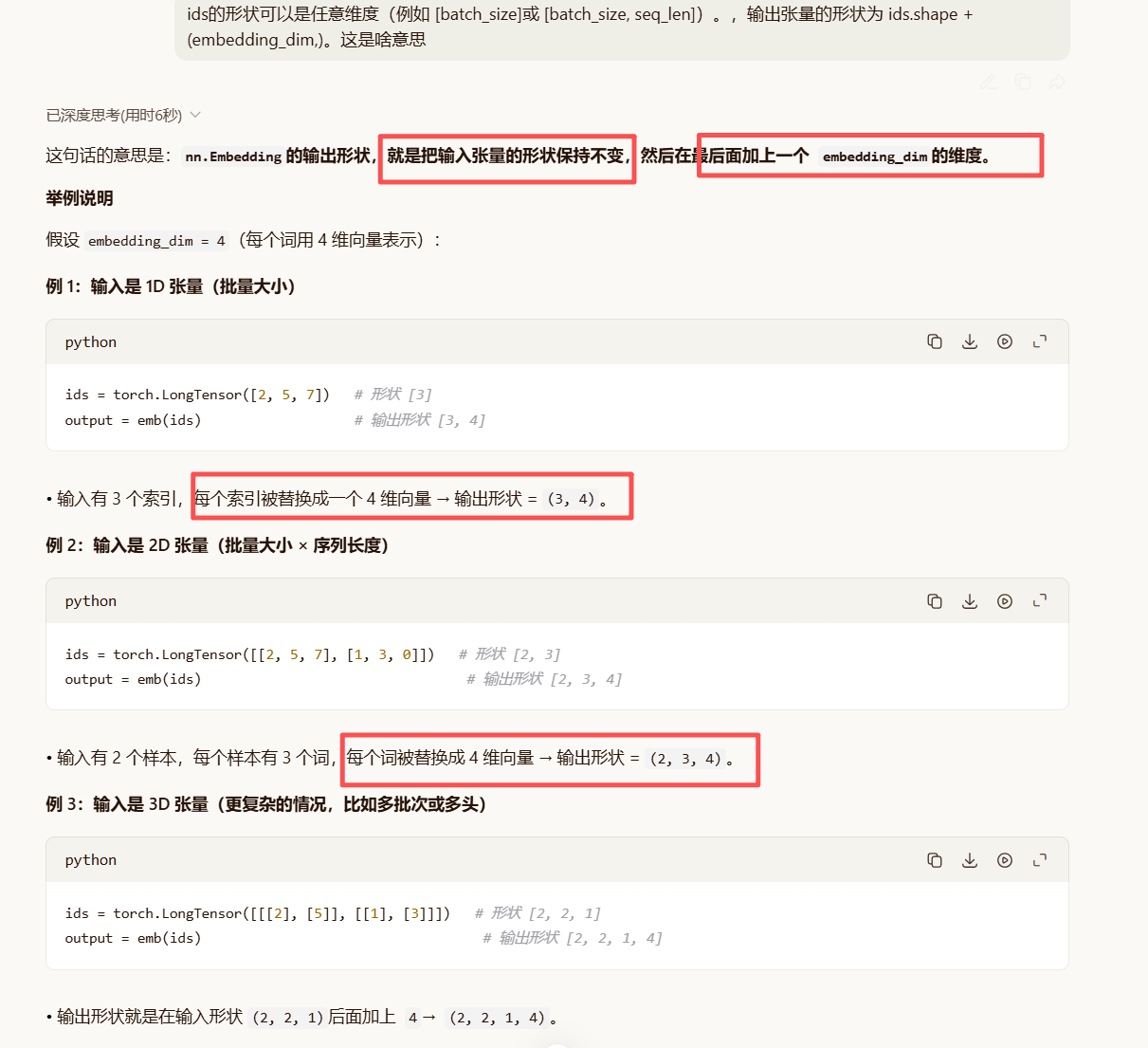
规律总结
-
输入形状 :
(d1, d2, ..., dn) -
输出形状 :
(d1, d2, ..., dn, embedding_dim)
也就是说,nn.Embedding会把输入张量中的每一个整数元素 替换成一个 embedding_dim长的浮点数向量,所以输出的维度比输入多了一维(最后一维是向量维度)。


问题:
首先词如何划分?应该不是必须每个字就是划分为一个词,不同的划分方式对结果有何影响?
第二是,每个词的维度多少比较好?
划分词的方法很多,比较经典的是编辑bpe算法(bert,字词分割),然后大模型还有别的方法,相似词分割。
维度大小无所谓,看你预料训练时神经元设置的大小(这个就是最后词的结果),使用embedding训练数据的时候,改一下紧跟embedding层的网络层中输入参数的大小就可以了。
平时的embedding: