基于 ms-swift 与 Qwen2.5 实现语音控制机器人意图识别模型的 LoRA 微调
本文基于 ms-swift 微调框架与 Qwen2.5-1.5B-Instruct 模型,使用 amazon_massive_intent_zh-CN 语音控制数据集,通过 LoRA(Low-Rank Adaptation)完成指令微调。覆盖环境搭建、数据准备、模型下载、LoRA 训练全流程,最终在 8GB 显存的 RTX 4060 Ti 上完成训练。
一、核心概念:什么是 LoRA 微调?
大语言模型(LLM)拥有强大的通用能力,但在特定领域任务上,往往需要"微调"来适配。LoRA(Low-Rank Adaptation) 是一种参数高效微调方法:
| 概念 | 说明 | 对比 |
|---|---|---|
| 全量微调 | 更新模型所有参数 | 显存需求大,1.5B 模型约需 12GB+ |
| LoRA 微调 | 冻结原始权重,仅训练低秩分解矩阵 | 仅训练 0.6% 参数,显存需求降低 70%+ |
| Prompt Tuning | 在输入端添加可学习 token | 不修改模型权重,能力有限 |
LoRA 的核心思想: 不直接修改原始权重矩阵 WWW,而是学习一个低秩增量 ΔW=BA\Delta W = BAΔW=BA,其中 B∈Rd×rB \in \mathbb{R}^{d \times r}B∈Rd×r,A∈Rr×kA \in \mathbb{R}^{r \times k}A∈Rr×k,r≪min(d,k)r \ll \min(d, k)r≪min(d,k)。推理时 W′=W+ΔWW' = W + \Delta WW′=W+ΔW,不增加推理延迟。
本次微调目标: 让 Qwen2.5-1.5B-Instruct 学会理解语音控制机器人的自然语言指令(如设置闹钟、调节音量、播放音乐等),并给出恰当的回复。
二、系统架构
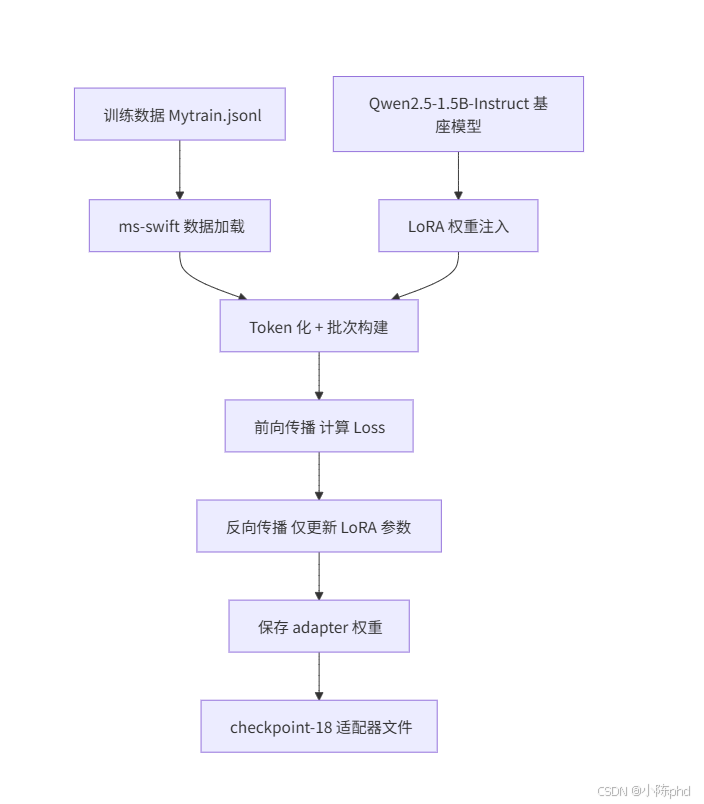
核心组件:
| 组件 | 版本 | 职责 |
|---|---|---|
ms-swift |
3.12.6 | ModelScope 微调框架,封装训练流程 |
transformers |
4.48.0 | HuggingFace 模型加载与推理 |
peft |
0.18.1 | LoRA 适配器实现 |
trl |
0.17.0 | 基于 transformers 的训练工具 |
torch |
2.6.0+cu124 | GPU 加速计算 |
三、环境准备
3.1 硬件环境
| 配置 | 规格 |
|---|---|
| GPU | NVIDIA RTX 4060 Ti 8GB |
| CUDA | 12.4 |
| 显存占用 | 训练峰值 ~3.91 GiB |
3.2 软件环境
使用 plate_ocr conda 环境,关键依赖如下:
bash
# 核心依赖
pip install ms-swift==3.* transformers==4.48.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# PyTorch(已有)
torch==2.6.0+cu124
# 模型下载
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple踩坑记录: ms-swift 4.x 要求 transformers>=5.0,与 torch 2.6.0 存在兼容性问题。解决方案是降级到 ms-swift 3.12.6 + transformers 4.48.0,同时卸载不需要的 torchvision(文本微调不涉及视觉功能)。
3.3 下载基座模型
从 ModelScope 下载 Qwen2.5-1.5B-Instruct(约 2.88GB):
python
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen2.5-1.5B-Instruct',
cache_dir='./models'
)
print(f"模型下载完成,路径: {model_dir}")
四、步骤详解
步骤 1:训练数据准备
使用 amazon_massive_intent_zh-CN 数据集,这是语音控制机器人的意图识别数据集,采用 messages 格式:
json
{
"messages": [
{"role": "system", "content": "你是一个语音控制机器人"},
{"role": "user", "content": "星期五早上九点叫醒我"},
{"role": "assistant", "content": "已为你设置星期五上午九点的闹钟,到时候会准时提醒你。"}
]
}数据集特点:
| 属性 | 说明 |
|---|---|
| 样本数 | 100 条 |
| 格式 | messages(system / user / assistant 三轮对话) |
| 角色设定 | "你是一个语音控制机器人" |
| 意图类型 | 闹钟设置、音量控制、音乐播放、天气查询、定时器、灯光控制等 |
| 平均 token 长度 | 35.5 ± 3.8 |
数据示例(部分意图类型):

步骤 2:LoRA 训练参数配置
通过 swift sft 命令行配置训练参数:
bash
swift sft ^
--model models\Qwen\Qwen2___5-1___5B-Instruct ^
--train_type lora ^
--dataset amazon_massive_intent_zh-CN\Mytrain.jsonl ^
--num_train_epochs 3 ^
--per_device_train_batch_size 2 ^
--learning_rate 1e-4 ^
--lora_rank 8 ^
--lora_alpha 32 ^
--output_dir output关键参数说明:
| 参数 | 值 | 说明 |
|---|---|---|
train_type |
lora | 使用 LoRA 微调,而非全量训练 |
lora_rank |
8 | 低秩矩阵的秩,越大表达能力越强但参数越多 |
lora_alpha |
32 | 缩放系数,通常设为 rank 的 2~4 倍 |
learning_rate |
1e-4 | LoRA 学习率,比全量微调大 10 倍 |
per_device_train_batch_size |
2 | 单卡 batch size,受 8GB 显存限制 |
num_train_epochs |
3 | 训练轮数 |
LoRA 的数学原理:
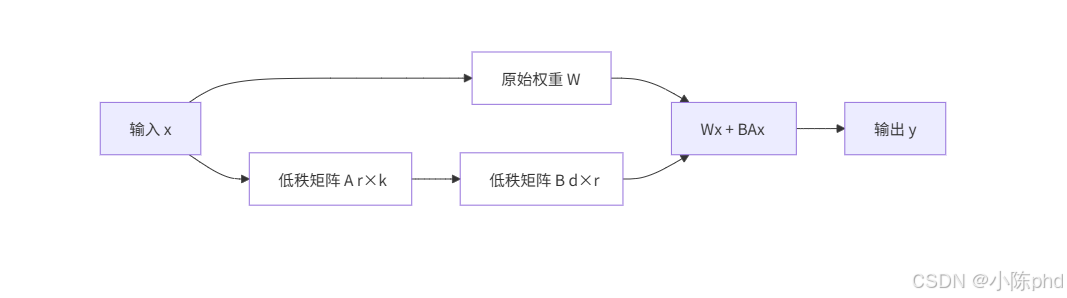
- 原始权重 W∈Rd×kW \in \mathbb{R}^{d \times k}W∈Rd×k 被冻结,不参与梯度更新
- 仅训练 A∈Rr×kA \in \mathbb{R}^{r \times k}A∈Rr×k 和 B∈Rd×rB \in \mathbb{R}^{d \times r}B∈Rd×r,其中 r=8≪min(d,k)r=8 \ll \min(d,k)r=8≪min(d,k)
- 缩放因子 αr=328=4\frac{\alpha}{r} = \frac{32}{8} = 4rα=832=4,控制 LoRA 增量的影响幅度
步骤 3:LoRA 目标模块选择
ms-swift 自动为 Qwen2.5 的以下模块注入 LoRA 适配器:
python
target_modules = {
'q_proj', # 注意力 - 查询矩阵
'k_proj', # 注意力 - 键矩阵
'v_proj', # 注意力 - 值矩阵
'o_proj', # 注意力 - 输出投影
'gate_proj', # MLP - 门控投影
'up_proj', # MLP - 上投影
'down_proj' # MLP - 下投影
}为什么选择这些模块?
- 注意力层(q/k/v/o_proj):控制模型"关注什么",对指令遵循能力影响最大
- MLP 层(gate/up/down_proj):控制模型的"知识存储",对回复内容生成至关重要
参数量统计:
| 指标 | 数值 |
|---|---|
| 模型总参数 | 1552.95M |
| 可训练参数 | 9.23M(0.59%) |
| 缓冲区参数 | 0.0001M |
步骤 4:训练过程监控
训练共 18 步(100 样本 × 3 epoch ÷ batch_size 2 ÷ gradient_accumulation 8 ≈ 18 步),总耗时约 42 秒。
训练日志关键指标:
| Step | Loss | Token Acc | 学习率 | 显存 |
|---|---|---|---|---|
| 1 | 19.07 | 48.96% | 9.92e-05 | 3.59 GiB |
| 5 | 14.71 | 57.77% | 8.21e-05 | 3.91 GiB |
| 10 | 9.08 | 63.43% | 4.13e-05 | 3.91 GiB |
| 15 | 7.89 | 69.17% | 6.70e-06 | 3.91 GiB |
| 18 | --- | 69.85% | --- | 3.91 GiB |
训练趋势分析:
- Loss 持续下降:19.07 → 7.89,模型在学习指令-回复的映射关系
- Token Acc 稳步提升:48.96% → 69.85%,模型生成的 token 越来越准确
- 学习率衰减:采用余弦退火策略,从 1e-4 衰减到接近 0
- 显存稳定:峰值 3.91 GiB,远低于 8GB 上限
步骤 5:训练产物
训练完成后,输出目录结构如下:
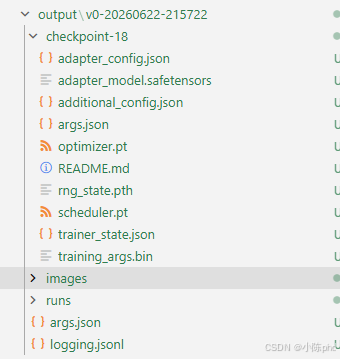
核心产物是 adapter_model.safetensors------仅 37MB 的 LoRA 权重文件,配合原始基座模型即可还原微调后的完整模型。
五、训练结果展示
5.1 训练曲线
训练结束后,ms-swift 自动生成以下可视化图表:
| 曲线 | 趋势 | 说明 |
|---|---|---|
| train_loss | 19.07 → 7.89 | 损失持续下降,模型在学习 |
| train_token_acc | 48.9% → 69.9% | 生成准确率稳步提升 |
| train_learning_rate | 1e-4 → ~0 | 余弦退火衰减 |
| train_grad_norm | 41.4 → 18.8 | 梯度范数下降,训练趋于稳定 |
5.2 最终训练指标
train_runtime: 41.87s
train_samples_per_second: 7.164
train_steps_per_second: 0.43
train_loss: 10.54
token_acc: 69.85%
memory(GiB): 3.91
train_speed(s/it): 2.325.3 模型推理验证
微调后的模型可通过以下方式加载并推理:
python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained(
"models\\Qwen\\Qwen2___5-1___5B-Instruct"
)
# 叠加 LoRA 适配器
model = PeftModel.from_pretrained(
base_model,
"output\\v0-20260622-215722\\checkpoint-18"
)
tokenizer = AutoTokenizer.from_pretrained(
"models\\Qwen\\Qwen2___5-1___5B-Instruct"
)
# 推理测试
inputs = tokenizer(
"你是一个语音控制机器人\n用户: 帮我设个半小时后的闹钟\n助手:",
return_tensors="pt"
)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# 预期输出: "已为你设置30分钟后的闹钟,时间到会提醒你。"六、核心技术点总结
| 技术点 | 实现方式 | 作用 |
|---|---|---|
| LoRA 低秩分解 | rank=8, alpha=32 | 仅训练 0.59% 参数,大幅降低显存需求 |
| 目标模块选择 | 注意力层 + MLP 层共 7 个模块 | 兼顾指令遵循与知识记忆 |
| 梯度累积 | accumulation_steps=8 | 等效 batch_size=16,稳定训练 |
| 余弦退火 | 学习率从 1e-4 衰减到 ~0 | 前期快速学习,后期精细收敛 |
| bf16 混合精度 | torch.bfloat16 | 减少显存占用,加速训练 |
| messages 格式 | system/user/assistant 三轮 | 统一对话微调的数据格式 |
| 适配器保存 | safetensors 格式 | 仅保存 37MB LoRA 权重,便于部署 |
七、延伸思考
- 更多训练数据:当前仅 100 条样本,增加到 1000+ 条可显著提升模型泛化能力
- 更多训练轮数:3 个 epoch 对 100 条数据仍显不足,可增加到 10~20 个 epoch
- 权重合并(merge) :使用
swift export --merge_lora将 LoRA 权重合并回基座模型,便于部署 - 模型量化:合并后可进一步做 GPTQ/AWQ 量化,在 CPU 或低显存 GPU 上推理
- 评估指标:添加验证集,监控 eval_loss 防止过拟合
- QLoRA:结合 4-bit 量化 + LoRA,进一步降低显存到 2GB 以下,实现在更小的 GPU 上微调大模型