业务背景
设计一个事件流处理平台。需要支持数百万客户端实时写入事件,并允许多个下游服务实时消费这些事件。典型应用场景包括:
-
用户点击流
-
视频观看事件
-
广告曝光事件
-
。。。
系统需求
功能需求
-
支持写入事件。延迟低,写入顺序可维护,支持持续流式写入。
-
支持读取事件。多个consumer之间互不影响。
-
支持consumer group。多个consumer组成consumer group。系统自动分配partition。要求同一个partition同一时刻只能被group中的一个consumer消费。自动负载均衡。
-
支持消费位置管理(offset)。consumer可以记录自己的消费位置。
-
支持信息保留(retention)
-
支持消息重放
-
支持消息顺序
-
支持消息过滤
-
支持批量读取
-
支持死信队列(DLQ)
非功能需求
-
高吞吐量
-
低写入延迟
-
高可用
-
持久化
-
支持水平扩展
api设计
- 发送事件:
POST: /event
request body:
{
"id": "event12345",
"type": "video-click",
"attributes": [
{
"name": "user_id",
"value": "user123"
},
{
"name": "video_id",
"value": "video456
}
],
"timestamp": 12345664,
"event-source": "client789"
}- 读取事件:
GET /event?topic=abc&cursor=abcd
系统架构设计
系统分为两个部分:写入事件和消费事件。
我们首先设计写入事件。首先,我们处理的是一个需要保持事件顺序的事件流系统。因此我们的核心数据存储使用基于logs的顺序存储数据。也就是所有的事件只能append到当前log的尾部,不允许对已经写入的log做修改。其次,我们要支持高并发的写,所以我们需要引入partition的概念。我们通过event ID计算它的partition key,然后将写入的请求交由相关的broker进行处理。每个broker维护一个partition的写入。这样同一个partition内部的event可以保持写入严格有序。不同partition之间的顺序默认是不能保证的,因此需要用户设计event ID来满足他的业务需求。这部分的系统架构如下: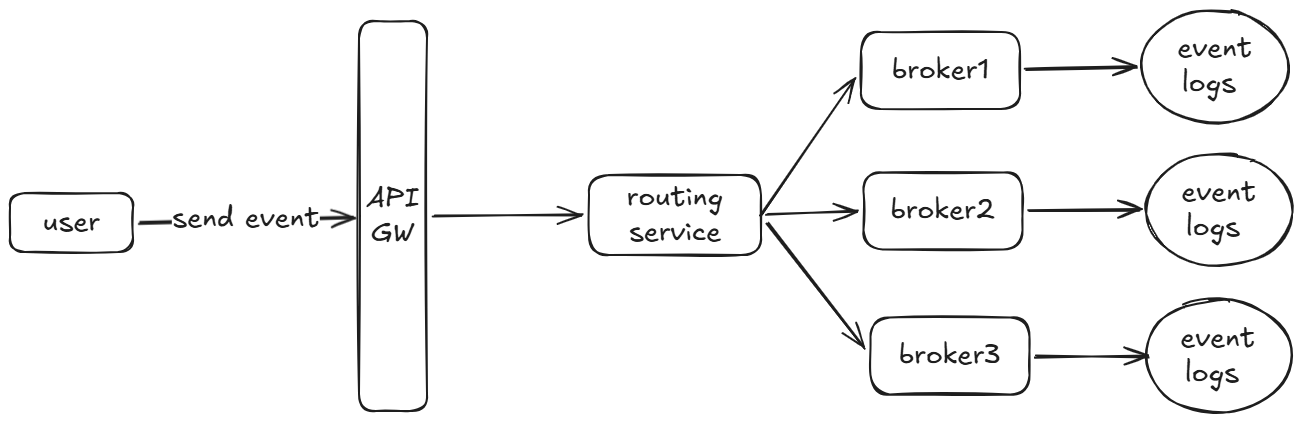
其次,我们设计消费事件的逻辑。这里我们引入consumer group的概念。即消费同一个topic的多个consumer被编为一个组,这样它们可以并行消费不同partition的数据,从而增加consumer group的整体throughput。另外,为了维护对于每一个partition消费的offset,我们需要引入一个meta DB,保存每个consumer group在每一个partition上已经消费的offset。整体框架图如下: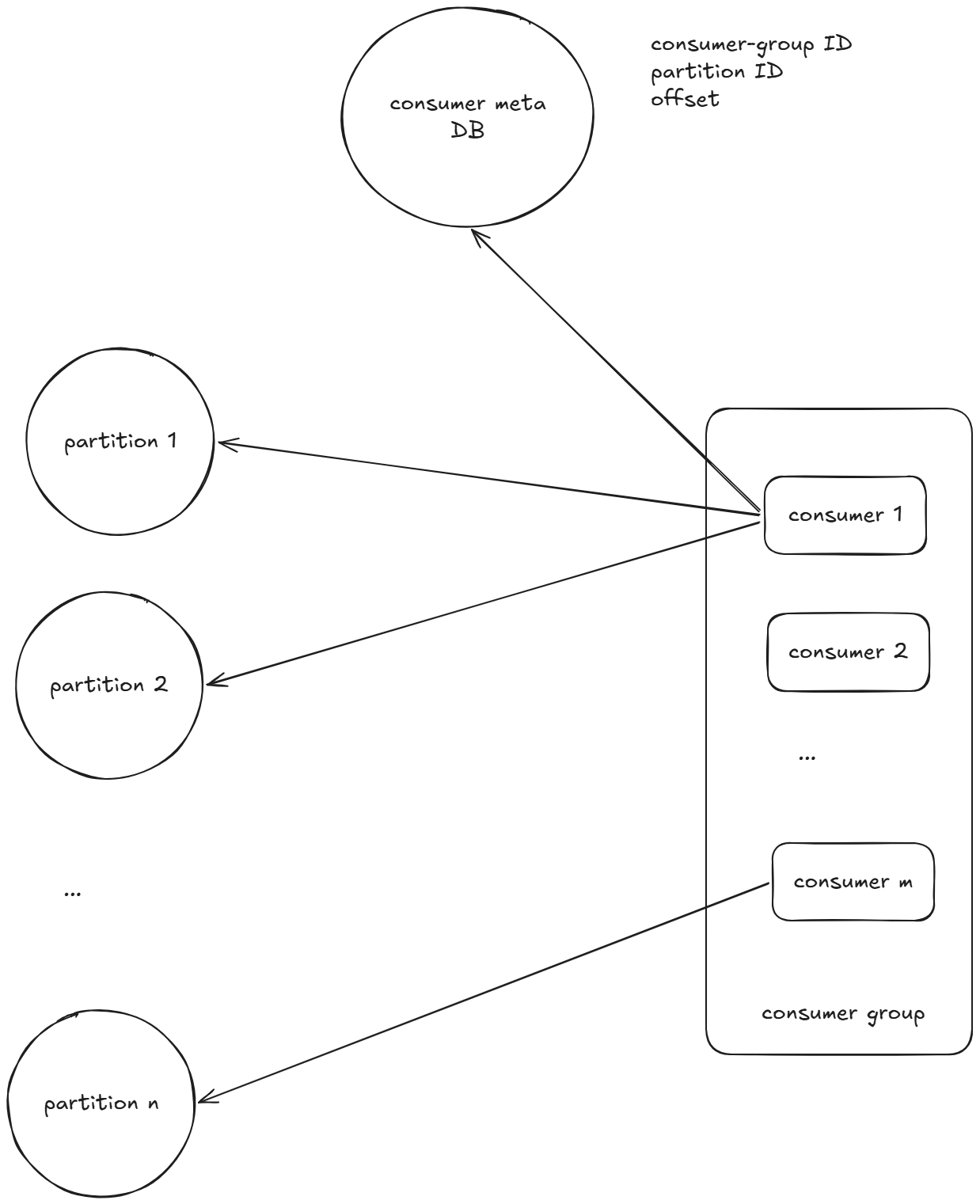
利用offset我们可以支持消息的replay。
讨论
-
为什么使用logs而不使用数据库作为broker内部的数据存储服务:数据库的优势在于随机写数据,修改数据,和读数据。但是我们系统的要求是按照事件顺序进行读写。logs作为只可以增加而不能修改以前的数据的存储结构,完全满足我们的要求,同时读取效率会大大优于数据库。
-
partition数据冗余设计:为了保持系统的fault tolerance,同时也为了增强系统的读的scalability,我们考虑给partition数据进行冗余,也就是设计replica。我们需要为每个parition设计一个leader的角色,一个leader可以有一个到多个follower。示意图如下所示:
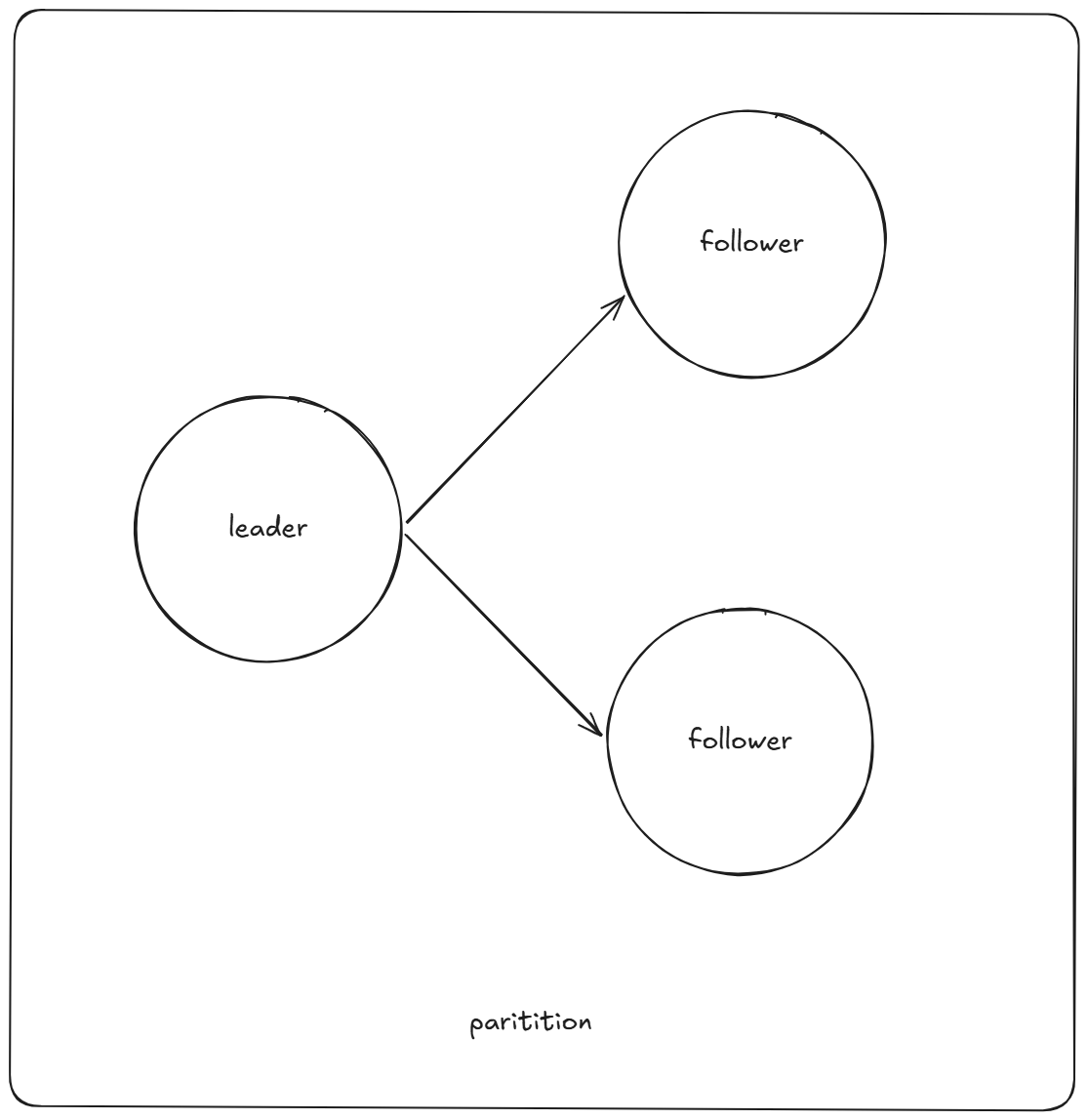
leader作为一个partition的interface。这里有两种可供选择的同步机制:一种是全部follower的数据都同步完成了才确认一次partition的更新完成;一种是基于quorum,也就是当一次读操作需要访问的node数和一次写操作需要访问的node数的和大于partition的node数量,既可以认为一个partition的更新完成。前一种同步机制会造成写的时延更长,但是读的时延短;后一种会减少写的时延,但是读的时延长。我们可以根据具体的业务要求进行选择。
-
Delivery Semantics:delivery semantics可以分为三种:at most once, at least once, 和exactly once。下面分别讨论。at most once:即更新最多只更新一次,也可能是零次。对应的更新逻辑为先commit update,然后进行update。at least once:即更新至少一次,也可能多次。对应的更新逻辑为先进行update,然后commit update。exactly once:即保证更新至少一次,且只为一次。最普遍的操作方式是at least once加上下游consume的操作需要幂等(idempotent)。在实际业务中使用最多的是at least once。
-
partition 扩容(reparition):考虑到partition内部数据巨大,通常的做法是保持旧有数据不动,仅仅将新的数据映射到增加的partition上。这样带来的一个副作用是之前同一个partition内部的消息顺序会受到影响。这也是目前kafka的做法。如果我们为了减少增加partition带来的消息顺序的影响,可以考虑使用consistent harsh,这样会最小化该影响。另外一种比较高级的做法是采用virtual partition,然后维护virtual partition和physical partition之间的映射关系,这样增加physical partition不会影响在virtual partition里的消息顺序。