计算机旅游项目设计推荐:基于 Python 的旅游采集数据分析可视化推荐系统研究
随着旅游消费的网络化与个性化趋势不断增强,传统依赖人工检索与线下咨询的旅游信息获取方式已难以满足用户对时效性、准确性和决策效率的要求。针对旅游景区信息分散、评价数据利用不足以及推荐服务个性化程度不高等问题,本文结合 Python 爬虫技术、Django Web 开发框架、MySQL 数据库存储、ECharts 数据可视化技术以及基于用户的协同过滤推荐算法,设计并实现了一套旅游采集数据分析可视化推荐系统。
本系统以去哪儿旅游景区信息为主要数据来源,使用 requests 与 lxml 完成景区列表、景点详情、用户评论等数据的自动采集与结构化处理,并将采集结果保存至 MySQL 数据库。在系统实现层面,本文基于 Django 搭建了旅游信息管理、用户注册登录、评论交互、数据分析展示和推荐服务等功能模块。在数据分析层面,系统围绕景区等级、地区分布、价格区间、销量情况、评论数量及评分分布等维度进行可视化呈现。在推荐层面,系统根据用户评分行为构建用户-项目评分矩阵,采用余弦相似度计算用户之间的兴趣相似性,从而生成 Top-N 个性化旅游景点推荐结果。
研究结果表明,该系统能够较好地完成旅游数据的采集、存储、分析与推荐闭环,为用户提供较为直观的旅游信息查询与辅助决策支持。同时,本文结合作者博客项目整理经验,将系统实现过程、关键技术与可视化成果进行结构化梳理,使论文内容既保留学术写作的完整性,又兼顾项目展示型文章的可读性与传播性。
关键词: Python;旅游数据采集;Django;数据可视化;协同过滤;推荐系统
第一章 绪论
1.1 研究背景
在数字经济持续发展的背景下,旅游行业正加速向平台化、智能化与数据驱动方向演进。用户在选择旅游目的地时,通常会综合考虑景区等级、票价、评论、销量、地理位置与热门程度等多种因素。传统旅游信息获取方式往往依赖旅行社推荐、人工搜索或单页面浏览,存在检索效率低、信息整合难以及个性化不足等问题。
与此同时,大量旅游信息分散在各类在线平台中,包括景区基础信息、用户评论文本、评分结果和价格变化等。这些数据具有较高的商业价值和研究价值,如果能够通过网络爬虫进行采集,并结合数据分析与推荐技术加以挖掘,就可以显著提升用户旅游决策效率。
因此,围绕"旅游数据采集、数据分析、结果可视化与个性化推荐"构建一体化系统,不仅具有较高的工程应用价值,也具有较强的教学实践与学术训练意义。
1.2 研究目的与意义
本文的主要研究目标是设计并实现一套基于 Python 的旅游采集数据分析可视化推荐系统,使其能够完成旅游信息自动采集、结构化存储、统计分析、图形化展示以及个性化推荐等功能。具体意义体现在以下几个方面:
- 在应用层面,系统能够帮助用户快速掌握旅游景区信息,提高信息获取效率。
- 在技术层面,系统融合了爬虫、Web 开发、数据库管理、数据可视化与推荐算法,具有较强的综合实践价值。
- 在教学与论文写作层面,该项目适合作为数据分析类、Python 开发类及推荐系统类课题的综合案例。
- 在博客传播层面,项目具备较好的展示性,适合沉淀为面向读者的技术实战文章,从而扩大项目成果的复用价值。
1.3 国内外研究现状
从现有研究来看,旅游推荐系统相关工作主要集中在以下几个方向:一是基于内容的旅游资源检索与推荐,重点关注景点属性标签与用户兴趣标签的匹配;二是基于协同过滤的旅游推荐,利用用户行为数据挖掘群体偏好;三是结合知识图谱、深度学习与大模型技术构建智能旅游问答或智能路线规划系统。相比之下,中小型实战项目更强调系统闭环实现能力,即从数据采集到页面展示的全流程落地。
本文所研究的系统虽然在算法复杂度上相对适中,但突出"工程可实现、功能完整、图文并茂、适合项目论文与博客双场景使用"的特点,这也是本研究区别于纯理论型论文的重要特点。
第二章 相关技术与理论基础
2.1 Python 语言
Python 具有语法简洁、生态丰富、开发效率高等特点,尤其适合爬虫开发、数据处理、机器学习与 Web 应用开发。本文利用 Python 同时承担数据采集、后端业务、数据分析与推荐算法实现任务,使系统整体具有较好的统一性。
2.2 Django 框架
Django 是基于 Python 的高层 Web 开发框架,强调快速开发与模块化管理。本文系统采用 Django 4.2.3 作为核心开发框架,利用其路由、模型、模板、会话管理与管理后台等功能,快速完成系统业务逻辑的实现。
2.3 MySQL 数据库
MySQL 作为关系型数据库,具有结构清晰、查询效率较高和部署方便等优点。本文通过 Django ORM 将旅游数据与用户数据映射为数据库表,实现对系统核心信息的持久化管理。
2.4 网络爬虫技术
系统在数据采集阶段主要使用 requests 发起网络请求,利用 lxml 的 XPath 规则对目标页面进行解析,从而提取景区名称、等级、地址、价格、评论数量、详情介绍、图片链接和评论内容等字段。该方式在中小规模项目中具有实现简单、可维护性较强的优势。
2.5 数据可视化技术
系统前端主要使用 ECharts 完成图表展示,并借助词云图片展示评论文本特征与景点介绍关键词。与纯文本结果相比,可视化图表更有利于用户快速理解旅游数据特征,也更符合博客化展示的阅读习惯。
2.6 协同过滤推荐算法
协同过滤推荐算法是推荐系统中的经典方法。本文采用基于用户的协同过滤思想,依据用户对景区的评分记录构建兴趣向量,通过余弦相似度寻找与目标用户兴趣接近的其他用户,再选取相似用户偏好的景点作为推荐结果。该算法实现直观、逻辑清晰,适合本项目的课程设计与论文写作场景。
第三章 系统需求分析
3.1 功能需求分析
结合项目源码与现有整理文档,系统需要满足以下核心功能需求:
- 旅游数据采集功能:完成旅游景区基础数据与评论数据抓取。
- 用户管理功能:实现用户注册、登录、退出和个人信息修改。
- 数据管理功能:完成旅游数据列表展示、查询与评论录入。
- 可视化分析功能:支持景区城市分布、等级分布、评分分布、价格分布、销量分布和评论统计分析。
- 推荐功能:根据用户历史评分行为生成景点推荐结果。
- 后台管理功能:通过 Django Admin 对用户与旅游数据进行统一管理。
3.2 非功能需求分析
系统除满足功能需求外,还应满足以下非功能需求:
- 可用性:界面应简洁明了,方便普通用户浏览与使用。
- 可维护性:代码结构需要具备一定模块化特征,便于后续维护和扩展。
- 可扩展性:后续可继续接入更多旅游平台数据源或改进推荐算法。
- 可展示性:系统页面、图表和图文说明应适合答辩展示及博客发布。
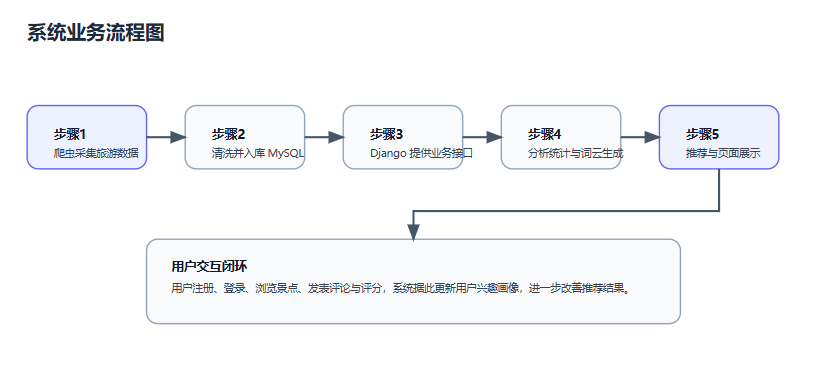
3.3 业务流程分析
系统整体业务流程为:首先通过爬虫程序抓取旅游数据并完成清洗入库;随后用户登录系统浏览旅游景点信息,系统通过可视化模块展示景区分析结果;当用户进行评论和评分后,系统再根据用户行为数据调用协同过滤算法进行个性化推荐,形成数据采集、分析与反馈闭环。
第四章 系统总体设计
4.1 总体架构设计
系统采用"数据源层 - 采集层 - 存储层 - 应用服务层 - 分析推荐层 - 展示层"的总体架构。数据源层负责提供原始旅游数据,采集层负责抓取与清洗,存储层负责结构化保存,应用服务层负责业务逻辑调度,分析推荐层负责模型与图表生成,展示层负责面向用户输出结果。
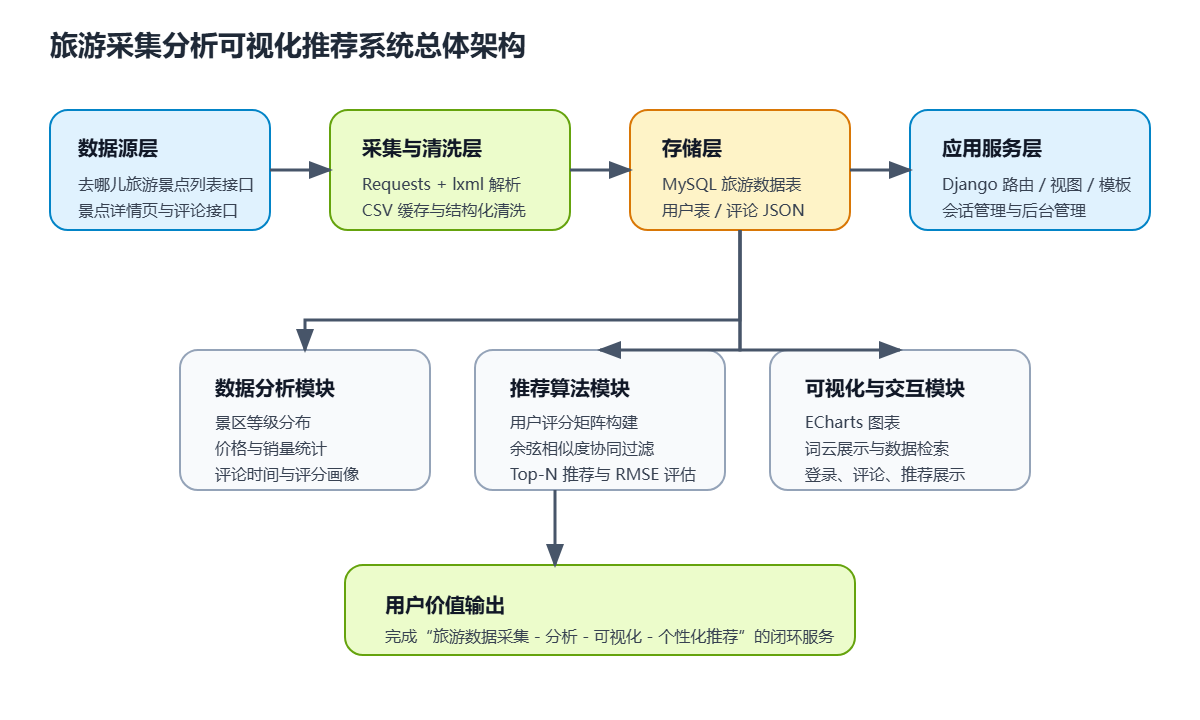
4.2 模块设计
根据源码结构,系统主要由以下几个模块构成:
- 爬虫模块 :位于
spider/spiderMain.py与spider/spiderCity.py,负责旅游城市列表读取、景点数据采集和评论抓取。 - 数据模型模块 :位于
app/models.py,定义TravelInfo与User两个核心数据模型。 - 业务视图模块 :位于
app/views.py,负责登录注册、首页展示、数据分析、评论提交和推荐结果渲染。 - 数据处理模块 :位于
app/utils/目录下,负责首页统计、公共数据提取、ECharts 数据组织、评论处理与推荐结果辅助查询。 - 推荐算法模块 :位于
app/recommdation.py,实现评分矩阵构建、协同过滤推荐及Top-N参数评估。 - 前端展示模块 :位于
templates/与app/templates/,完成页面布局与图表嵌入。
4.3 数据库设计
系统核心数据表包括用户表和旅游景区信息表。
4.3.1 用户表设计
用户表主要包含用户编号、用户名、密码、性别、地址、头像、个人简介与创建时间等字段,用于支撑系统登录、资料维护与推荐定位。
4.3.2 旅游景区信息表设计
旅游景区信息表主要包含景区名称、等级、折扣、销量、省份、热度、地址、评分、价格、评论数量、详情介绍、图片列表、评论内容与封面图等字段,为后续分析与推荐提供数据基础。
4.4 系统运行环境
结合现有项目配置,系统运行环境如下(仅供参考,环境兼容都可以):
| 项目 | 配置 |
|---|---|
| 开发语言 | Python 3.9 |
| Web 框架 | Django 4.2.3 |
| 数据库 | MySQL 8.0.26 |
| 前端图表 | ECharts |
| 推荐算法 | 基于用户的协同过滤 |
| 依赖库 | scikit-learn、numpy、lxml、jieba、matplotlib、wordcloud、pymysql |
| 操作系统 | Windows 10 |
| 开发工具 | PyCharm 2021.2.1 |
第五章 系统详细实现
5.1 旅游数据采集实现
系统爬虫模块主要通过景区列表接口获取基础数据,再进一步访问景区详情页和评论接口提取深层信息。采集字段包括景区名称、景区等级、地址、价格、销量、评分、评论数量、详情介绍、景区图片与用户评论等。程序先将数据写入 CSV 缓存文件,再导入 MySQL 数据库,以降低直接写库失败带来的风险。
在实现层面,爬虫类首先初始化目标 URL、详情 URL 和评论 URL,并设置请求头参数;之后通过 send_request() 完成网络请求,再在 spiderMain() 中提取并组织字段,最终由 save_to_sql() 执行批量入库。
5.2 用户与权限功能实现
系统利用 Django Session 机制实现用户登录状态维护。用户可通过注册页面完成账号创建,通过登录页面进入系统首页。进入系统后,用户还可修改个人信息与密码,并通过退出功能清理会话信息。虽然本项目未采用复杂的 RBAC 权限模型,但通过中间件与会话控制已经能够满足中小型系统的用户访问管理需求。
首页与统计功能实现
爬取数据源------去哪儿旅行 https://www.qunar.com/
系统爬虫部分核心代码
bash
def spiderMain(self,resp,province):
respJSON = resp.json()['data']['sightList']
for index,travel in enumerate(respJSON):
print('正在爬取该页第%s数据' % str(index + 1))
time.sleep(2)
detailAddress = travel['address']
discount = travel['discount']
shortIntro = travel['intro']
price = travel['qunarPrice']
saleCount = travel['saleCount']
try:
level = travel['star'] + '景区'
except:
level = '未评价'
title = travel['sightName']
cover = travel['sightImgURL']
sightId = travel['sightId']
# ================================= 详情爬取
detailUrl = self.detailUrl % sightId
respDetailXpath = etree.HTML(self.send_request(detailUrl).text)
score = respDetailXpath.xpath('//span[@id="mp-description-commentscore"]/span/text()')
if not score:
score = 0
star = 0
else:
score = score[0]
star = int(float(score)*10)
commentsTotal = respDetailXpath.xpath('//span[@class="mp-description-commentCount"]/a/text()')[0].replace('条评论','')
detailIntro = respDetailXpath.xpath('//div[@class="mp-charact-intro"]//p/text()')[0]
img_list = respDetailXpath.xpath('//div[@class="mp-description-image"]/img/@src')[:6]
# ================================= 评论爬取
commentSightId = respDetailXpath.xpath('//div[@class="mp-tickets-new"]/@data-sightid')[0]
commentsUrl = self.commentUrl % commentSightId
comments = []
try:
commentsList = self.send_request(commentsUrl).json()['data']['commentList']
for c in commentsList:
if c['content'] != '用户未点评,系统默认好评。':
author = c['author']
content = c['content']
date = c['date']
score = c['score']
comments.append({
'author': author,
'content': content,
'date': date,
'score': score
})
except:
comments = []
resultData = []
这里代码创建了一个 spider 类的实例对象 spiderObj,然后依次调用了该对象的 start() 方法和 save_to_sql() 方法。
spiderObj.start() 方法用于启动爬虫程序,即开始采集数据。
spiderObj.save_to_sql() 方法用于将爬取到的数据保存到 MySQL 数据库中。
bash
if __name__ == '__main__':
spiderObj = spider()
#spiderObj.init()
spiderObj.start() #采集数据
spiderObj.save_to_sql() #保存爬取的旅游数据到MySQL数据库爬取数据过程截图如下:

机器学习算法推荐部分是基于用户的协同过滤推荐算法,用于根据用户的评分数据推荐其可能喜欢的其他景点。
基于用户的协同过滤算法部分核心代码:

python
def user_bases_collaborative_filtering(user_id,user_ratings,top_n=20):
# def user_bases_collaborative_filtering(user_id, user_ratings, top_n=3):
# 获取目标用户的评分数据
target_user_ratings = user_ratings[user_id]
# 初始化一个字段,用于保存其他用户与目标用户的相似度得分
user_similarity_scores = {}
# 将目标用户的评分转化为numpy数组
target_user_ratings_list = np.array([
rating for _ , rating in target_user_ratings.items()
])
# 计算目标用户与其他用户之间的相似度得分
for user,ratings in user_ratings.items():
if user == user_id:
continue
# 将其他用户的评分转化为numpy数组
user_ratings_list = np.array([ratings.get(item,0) for item in target_user_ratings])
# 计算余弦相似度
similarity_score = cosine_similarity([user_ratings_list],[target_user_ratings_list])[0][0]
user_similarity_scores[user] = similarity_score
# 对用户相似度得分进行降序排序
sorted_similar_user = sorted(user_similarity_scores.items(),key=lambda x:x[1],reverse=True)
# 选择 TOP N 个相似用户喜欢的景点 作为推荐结果
recommended_items = set()
for similar_user,_ in sorted_similar_user[:top_n]:
recommended_items.update(user_ratings[similar_user].keys())
# 过滤掉目标用户已经评分过的景点
recommended_items = [item for item in recommended_items if item not in target_user_ratings]
return recommended_itemsuser_bases_collaborative_filtering函数接受三个参数:user_id: 目标用户的ID。user_ratings: 包含用户评分信息的字典,其中键是用户ID,值是包含景点及其评分的字典。top_n: 选择推荐结果的前N个景点,默认为20。
target_user_ratings = user_ratings[user_id]:获取目标用户的评分数据,即目标用户对各个景点的评分。user_similarity_scores = {}:初始化一个空字典,用于保存其他用户与目标用户的相似度得分。target_user_ratings_list = np.array([...]):将目标用户的评分转换为 NumPy 数组,以便后续计算余弦相似度。- 遍历
user_ratings中的每个用户,计算目标用户与其他用户之间的相似度得分:- 将其他用户的评分转化为 NumPy 数组。
- 使用余弦相似度计算两个用户之间的相似度得分。
- 将相似度得分存储在
user_similarity_scores字典中。
sorted_similar_user = sorted(user_similarity_scores.items(),key=lambda x:x[1],reverse=True):对用户相似度得分进行降序排序,得到一个包含用户ID和相似度得分的元组列表。recommended_items = set():初始化一个集合,用于保存推荐的景点。- 遍历排序后的相似用户列表,选择前
top_n个相似用户喜欢的景点,将这些景点添加到recommended_items集合中。 recommended_items = [item for item in recommended_items if item not in target_user_ratings]:过滤掉目标用户已经评分过的景点,得到最终的推荐结果。- 返回
recommended_items,即推荐给目标用户的景点列表。
这个函数接受目标用户ID、用户评分字典以及要返回的推荐结果数量作为参数。它计算目标用户与其他用户的相似度得分,然后选择相似度最高的用户喜欢的景点作为推荐结果。
-- 获取目标用户的评分数据
-- 初始化一个字典,用于保存其他用户与目标用户的相似度得分
-- 将目标用户的评分转化为numpy数组
-- 计算目标用户与其他用户之间的相似度得分(余弦相似度)
-- 对用户相似度得分进行降序排序
-- 选择TOP N个相似用户喜欢的景点作为推荐结果
-- 过滤掉目标用户已经评分过的景点

用户登录注册

系统首页

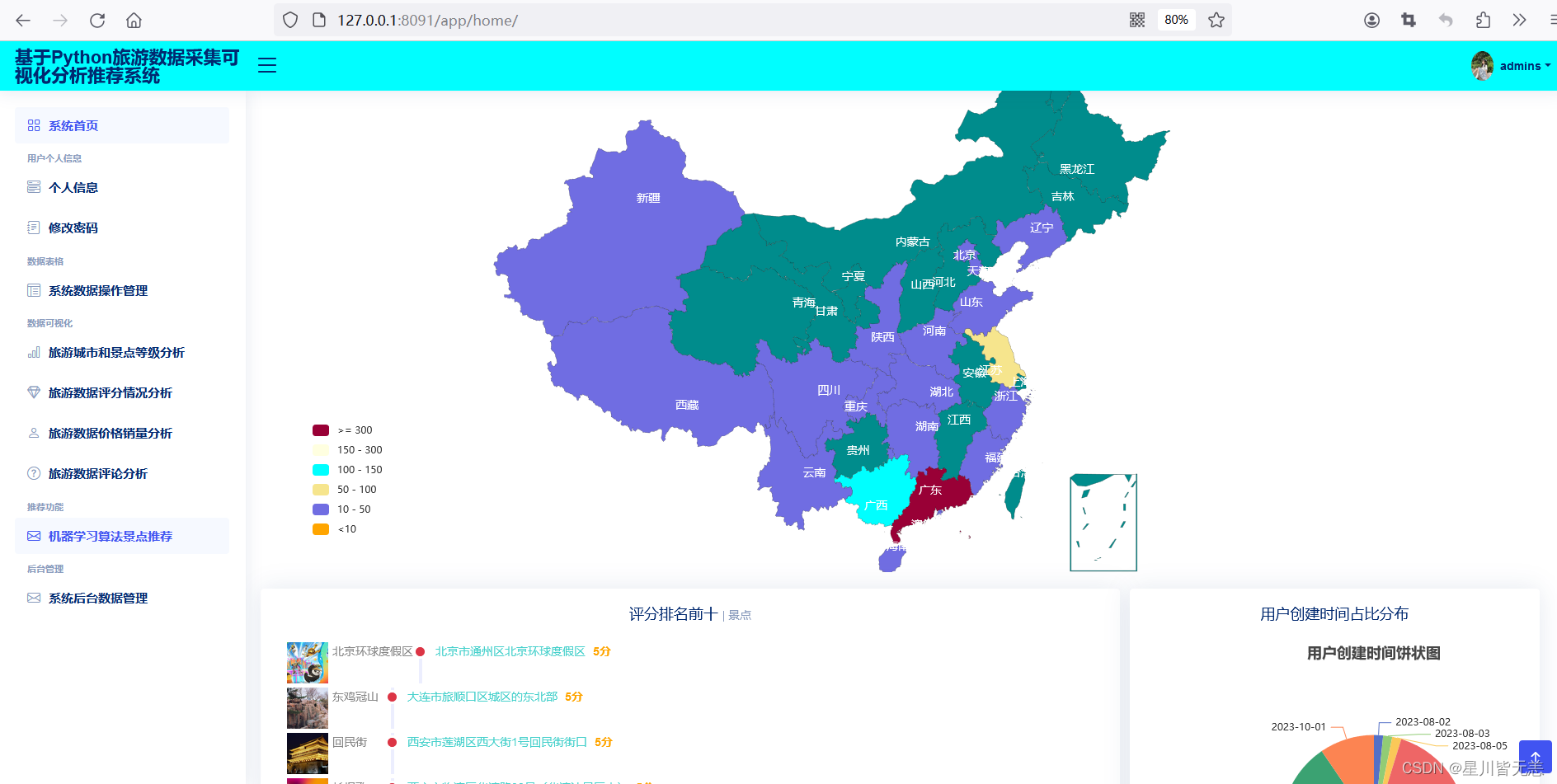

数据操作管理

价格与销量分析

旅游城市和景点等级分析

旅游数据评分情况分析

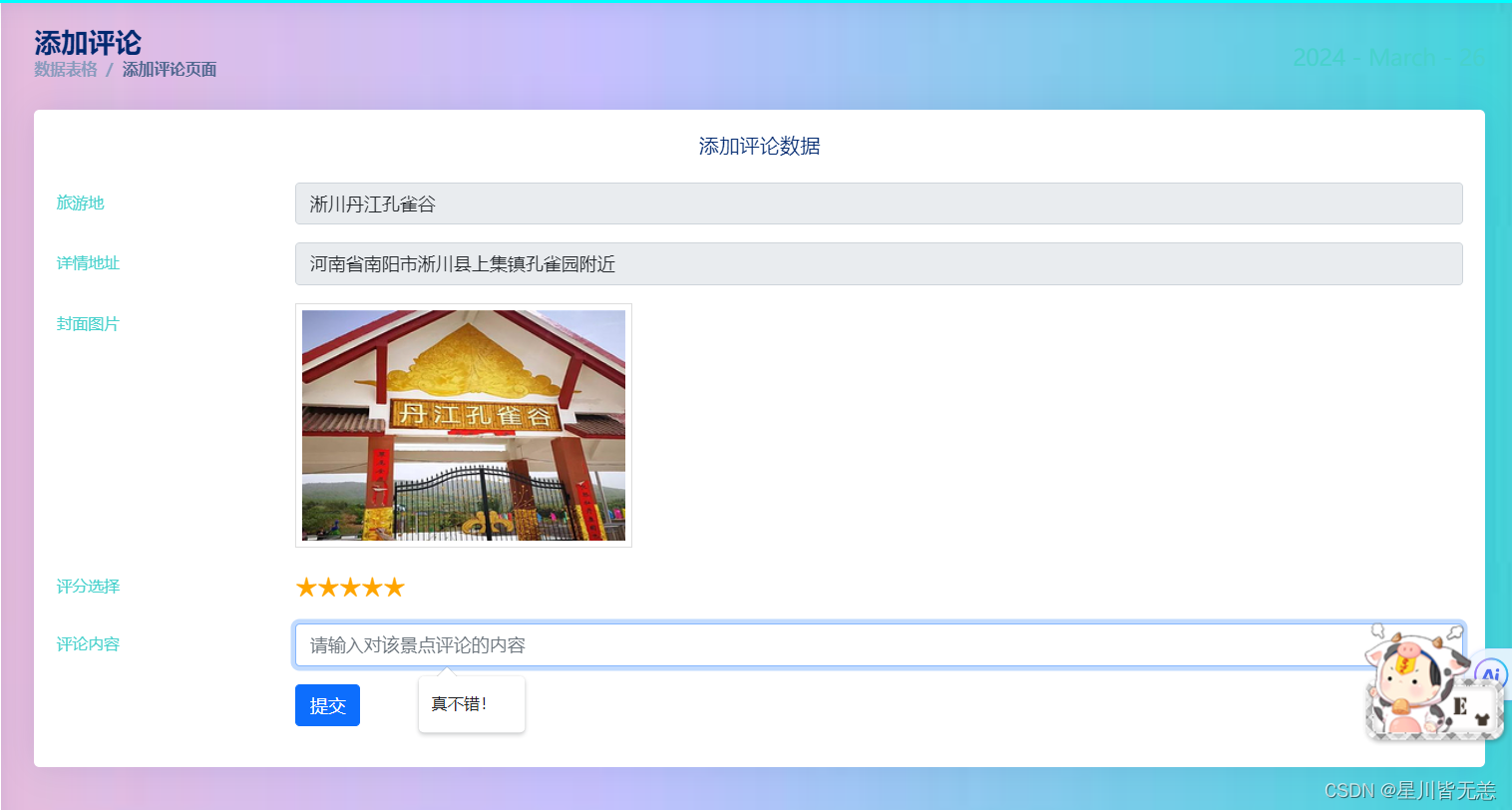
旅游数据评论情况分析

旅游景点用户评论评分
机器学习算法旅游景点及路线推荐

Django系统后台管理
python
http://127.0.0.1:8091/admin



5.4 数据分析功能实现
系统分析模块主要包括以下几类图表:
- 城市与等级分析:通过统计各省份景区数量和景区等级数量,反映旅游资源分布特征。
- 评分分析:围绕热度与评分两个维度展示景区质量画像。
- 价格与销量分析:对景区票价区间和销量区间进行统计,辅助用户判断消费结构与市场热度。
- 评论分析:分析评论时间分布、评论评分分布与评论数量区间分布。
- 词云分析:通过景点介绍词云和评论内容词云展示文本热点信息。

十七、结语
如需项目源码文档解析等资料/解析/商业合作/交流探讨~等可以评论留言/添加下面个人名片,感谢各位的喜欢与支持!
后面有时间和精力也会分享更多优质内容,喜欢的小伙伴可以点赞收藏加关注,感谢各位的喜欢与支持!
如需项目源码、部署文档、功能解析、二次开发、界面优化、项目定制、课程设计或毕业设计辅导,可通过评论区或个人主页方式交流。支持 Python 爬虫、数据分析可视化、大数据项目、算法模型、全栈系统开发与技术咨询。