目录
[1.1 性能思维的建立](#1.1 性能思维的建立)
[1.2 性能估算](#1.2 性能估算)
[2.1 性能分析工具](#2.1 性能分析工具)
[2.2 处理扁平性能剖析](#2.2 处理扁平性能剖析)
[三、 性能的硬件限制](#三、 性能的硬件限制)
[3.1 CPU限制](#3.1 CPU限制)
[3.1.1 CPU流水线宽度](#3.1.1 CPU流水线宽度)
[3.1.2 端口/执行单元限制](#3.1.2 端口/执行单元限制)
[3.2 内存访问限制](#3.2 内存访问限制)
[3.2.1 延迟限制](#3.2.1 延迟限制)
[3.2.2 内存带宽限制](#3.2.2 内存带宽限制)
[3.2.3 并发限制:行填充缓冲区 (LFB)](#3.2.3 并发限制:行填充缓冲区 (LFB))
[4.2 内存管理](#4.2 内存管理)
[4.2.1 减少内存分配](#4.2.1 减少内存分配)
[4.2.1.1 结构体对齐优化 (Struct Padding)](#4.2.1.1 结构体对齐优化 (Struct Padding))
[4.2.1.2 使用更小的整型(以空间换时间)](#4.2.1.2 使用更小的整型(以空间换时间))
[4.2.1.3 容器的容量回收 (Shrink to Fit)](#4.2.1.3 容器的容量回收 (Shrink to Fit))
[4.2.1.4 字符串优化:避开堆分配](#4.2.1.4 字符串优化:避开堆分配)
[4.2.1.5 惰性初始化 (Lazy Initialization)](#4.2.1.5 惰性初始化 (Lazy Initialization))
[4.2.1.6 享元模式 (Flyweight Pattern)](#4.2.1.6 享元模式 (Flyweight Pattern))
[4.2.2 提高数据局部性](#4.2.2 提高数据局部性)
[4.2.2.1 优先访问连续内存](#4.2.2.1 优先访问连续内存)
[4.2.2.2 分块存储](#4.2.2.2 分块存储)
[4.2.2.3 布局优化:SoA 代替 AoS](#4.2.2.3 布局优化:SoA 代替 AoS)
[4.2.2.4 数据重组:冷热数据分离 (Hot/Cold Splitting)](#4.2.2.4 数据重组:冷热数据分离 (Hot/Cold Splitting))
[4.2.3 避免不必要的拷贝](#4.2.3 避免不必要的拷贝)
[4.2.4 内存分配优化](#4.2.4 内存分配优化)
[4.2.4.1 栈分配替代堆分配](#4.2.4.1 栈分配替代堆分配)
[4.2.4.2 对象重用与 clear()](#4.2.4.2 对象重用与 clear())
[4.4.4.3 预分配空间](#4.4.4.3 预分配空间)
[4.2.4.4 在Protobuf中使用Arena分配内存](#4.2.4.4 在Protobuf中使用Arena分配内存)
[4.2.4.5 链接jemalloc优化内存分配](#4.2.4.5 链接jemalloc优化内存分配)
[4.3 微架构与硬件优化](#4.3 微架构与硬件优化)
[4.3.1 分支预测优化](#4.3.1 分支预测优化)
[4.3.1.1 排序后再处理](#4.3.1.1 排序后再处理)
[4.3.1.2 静态分支预测](#4.3.1.2 静态分支预测)
[4.3.1.2 使用查表法替换分支](#4.3.1.2 使用查表法替换分支)
[4.3.2 向量化](#4.3.2 向量化)
[4.4 构建与编译器优化](#4.4 构建与编译器优化)
[4.4.1 链接时优化 (LTO - Link Time Optimization)](#4.4.1 链接时优化 (LTO - Link Time Optimization))
[4.4.2 反馈引导优化 (PGO - Profile-Guided Optimization)](#4.4.2 反馈引导优化 (PGO - Profile-Guided Optimization))
[4.4.3 编译期运行](#4.4.3 编译期运行)
[4.4.4 指令集针对性构建](#4.4.4 指令集针对性构建)
[4.5 并发与同步优化](#4.5 并发与同步优化)
[4.5.1 减少锁的粒度](#4.5.1 减少锁的粒度)
[4.5.2 读写分离](#4.5.2 读写分离)
[4.5.3 无锁编程 与原子操作](#4.5.3 无锁编程 与原子操作)
[4.5.4 避免伪共享](#4.5.4 避免伪共享)
[4.5.5 线程本地存储 (Thread Local Storage, TLS)](#4.5.5 线程本地存储 (Thread Local Storage, TLS))
一、性能优化的核心原则
1.1 性能思维的建立
提升软件性能至关重要,它能为用户提供更多服务,节省更多资源。
关键原则:
-
在编写代码时,如果不显著影响可读性/复杂性,应优先选择更快的实现方式
-
培养对性能影响的直觉,做出更明智的决策
-
快速估算性能
-
任何性能优化都需要做基准测试(代码优化受编译器优化、内存分配等变量影响,实际效果可能与估算不符),以验证优化有效
1.2 性能估算
在选择性能特征可能不同的方案时,您可以借助 **粗略的估算**进行更深入的分析。这类估算可以快速粗略地估计不同方案的性能,并可用于排除某些方案而无需实际实施。
以下是这种估算方法的运作方式:
-
估算需要进行的各种底层操作的数量,例如磁盘寻道次数、网络往返次数、传输字节数等。
-
将每种昂贵操作与其粗略成本相乘,然后将结果加在一起。
-
以上内容列出了系统在资源使用方面的成本。如果您关注的是延迟,并且系统存在并发性,则部分成本可能会重叠,您可能需要进行更复杂的分析来估算延迟。
下表为Google在2007年做的各种底层操作的性能估算:
L1 缓存访问:0.5 ns
L2 缓存访问:3 ns
分支预测错误:5 ns
互斥锁/解锁(无竞争):15 ns
主内存访问:50 ns
用Snappy压缩1KB数据:1,000 ns
从SSD读取4KB:20,000 ns
同数据中心往返:50,000 ns
从内存顺序读取1MB:64,000 ns
通过100Gbps网络读取1MB:100,000 ns
从SSD读取1MB:1,000,000 ns
磁盘寻道:5,000,000 ns
从磁盘顺序读取1MB:10,000,000 ns
二、性能分析与测量
2.1 性能分析工具
主要工具:
-
perf:Linux系统中的性能分析工具,它支持硬件性能计数、软件性能计数和动态追踪。
-
Intel vtune: Intel开发的功能强大的图形化性能分析工具
-
gogole benchmark: google提供的用于对代码进行微基准测试的库
分析技巧:
-
在优化前后进行性能分析
-
使用多个不同输入进行分析
-
分析生产环境代码(如果可能)
2.2 处理扁平性能剖析
当CPU剖析显示扁平分布(无明显热点)时:
-
检查缓存未命中 :使用
perf stat -e cache-misses -
检查分支预测错误 :使用
perf stat -e branch-misses -
检查TLB未命中
-
分析内存带宽使用
三、 性能的硬件限制
3.1 CPU限制
3.1.1 CPU流水线宽度
流水线宽度(Pipeline Width)指CPU在单个时钟周期内能够并行处理、发射或完成的指令数量,是衡量处理器指令级并行(ILP)能力的关键指标。现代高效能处理器普遍采用宽泛的流水线设计,如Intel CPU通常支持每个时钟周期处理4个或更多指令。
Intel Skylake:每周期最多4个融合uops
Intel Ice Lake:每周期最多5个融合uops
AMD Zen 3:每周期最多6个MOPs
Apple M1:每周期最多8个ops
下图展示了5级流水线CPU的理想流水线视图:
-
指令获取(IF)
-
指令解码(ID)
-
执行(EXE)
-
存储访问(MEM)
-
写回(WB)
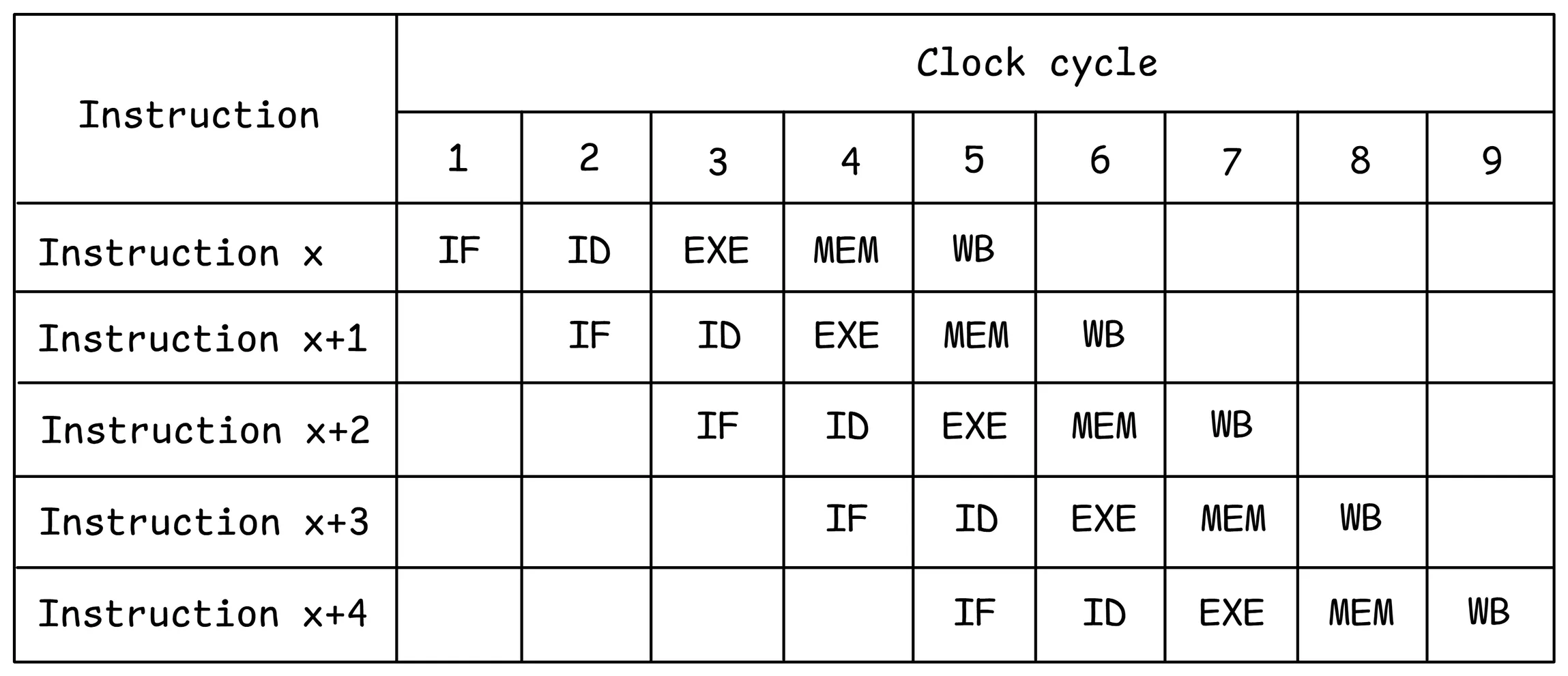
为了提高性能,CPU流水线执行时会有大量的指令预取、分支预测、乱序执行、指令级并行等处理。
针对CPU处理的优化策略:
-
优化分支预测 :分支预测错误会导致流水线清空,极大地浪费带宽。应使用简单的代码结构、减少分支数量、利用分支预测提示(如
__builtin_expect),使代码顺序执行。 -
指令级并行与循环展开:通过循环展开(Loop Unrolling)将多次迭代合并,显式地增加并行指令数。这使CPU的指令发射单元能更充分地填充流水线。
-
消除数据依赖:数据相关性(后一条指令需要前一条的结果)是流水线并行的主要瓶颈。应尽量减少不必要的读写依赖,使用寄存器重命名或重新排序指令以提高并行度。
-
优化缓存访问:确保数据命中缓存(L1/L2),减少因缓存缺失(Cache Miss)引起的内存访问延迟,因为流水线在等待数据时会停顿。
-
编译器优化 :通过开启编译器优化选项(如
-O3)让编译器自动进行指令调度、向量化(Vectorization)和流水线优化。
3.1.2 端口/执行单元限制
现代 CPU 是"超标量"的。指令经过译码后进入重排序缓冲区(ROB),然后被分配到不同的分发端口(Dispatch Ports)。
以常见的 Intel Skylake/Tiger Lake 架构为例:
-
它通常有 8 个或更多端口(Port 0 到 Port 7)。
-
每个端口后面连接着特定的执行单元。
Port 0: 整数运算 (ALU)、浮点乘法、向量运算。
Port 1: 整数运算 (ALU)、浮点加法、向量运算。
Port 5: 整数运算 (ALU)、向量洗牌 (Shuffle)。
Port 2/3: 加载数据 (Load)。
Port 4: 存储数据 (Store)。
核心限制:执行单元的类型与数量
虽然有 8 个端口,但并不是所有端口都能处理所有任务。
A. 算术单元限制
如果你有一堆浮点加法指令,而 CPU 只有 2 个端口连接了浮点加法器(FADD),那么即使 CPU 频率再高,一个周期也只能处理 2 条浮点加法。
- 例子 :如果代码中全是
a = b + c(浮点),你的 IPC(Instructions Per Cycle,每个周期执行的指令数) 理论上限就被卡在了 2.0。
B. 内存端口限制
现代 CPU 通常有 2 个加载端口(Load)和 1 个存储端口(Store)。
- 后果:一个周期内,CPU 最多只能从 L1 缓存读取 2 个 64 字节的数据。如果你的算法涉及大量零散的内存读写,端口就会爆满。
3.2 内存访问限制
这就是现代计算机架构中最著名的**内存墙(Memory Wall)**问题。CPU 的计算速度(以 GHz 计)远超内存的供数速度(以 ns 计)。
内存访问的三个维度:延迟(Latency) 、带宽(Bandwidth)和并发能力(Concurrency)。
3.2.1延迟限制
这是最直观的限制。当 CPU 需要的数据不在 Cache 中时,它必须停下所有的计算指令,空转等待数据从内存传回。
-
物理开销对比:
-
L1 Cache: ~4 周期
-
L2 Cache: ~12 周期
-
L3 Cache: ~40-60 周期
-
内存 (DRAM) : 200-300+ 周期
-
-
瓶颈表现:即便 CPU 频率是 5GHz,一旦发生一次内存访问(Cache Miss),它就要等待几百个周期。
-
优化方向 :提高空间局部性。让数据在内存中紧凑排列,使 CPU 预取器(Prefetcher)能提前预判并加载数据。
3.2.2 内存带宽限制
带宽决定了单位时间内内存能"灌"给 CPU 多少数据。
-
现状:双通道 DDR5 内存的带宽通常在 50-80 GB/s。虽然看起来很大,但在多核并行计算中,所有核心共享这一个带宽。
-
饱和迹象 :如果你的算法是纯粹的数据搬运(如
std::copy或向量加法),核心数增加到一定程度后,吞吐量不再提升,这时就触碰了带宽上限。 -
优化方向 :减少数据体积 (例如用
float代替double,用int8_t代替int32_t),从而在同样的带宽下传输更多的元素
3.2.3并发限制:行填充缓冲区 (LFB)
这是一个非常底层且容易被忽视的限制。CPU 并不是只能"一次请求一个数据",它拥有有限的并行请求能力。
-
核心组件:Line Fill Buffers (LFB):
- 在 Intel 架构中,每个核心通常只有 10-12 个 LFB。
-
限制逻辑:当你的代码同时请求了 20 个分布在不同内存区域的数据(例如遍历一个极其杂乱的链表),只有前 12 个请求能并发发出。剩下的 8 个请求必须等待前面的请求完成才能启动。
-
结论:过度的随机访问会打断内存级的并行性。
四、性能优化方法
4.1算法/数据结构层面优化
这是优化的基石。如果你选择了错误的算法,再底层的优化也救不了你。
案例:斐波那契数列的实现
优化前:递归实现,代码看似简单,但实际存在大量的重复计算,算法复杂度高达
long long fib_recursive(int n) {
if (n <= 1) return n;
return fib_recursive(n - 1) + fib_recursive(n - 2);
}优化后:通过引入一个简单的动态规划,算法复杂度提升为
long long fib_iterative(int n) {
if (n <= 1) return n;
long long a = 0, b = 1, sum = 0;
for (int i = 2; i <= n; ++i) {
sum = a + b;
a = b;
b = sum;
}
return b;
}4.2 内存管理
从上节中的硬件限制可知,仔细考虑重要数据结构的内存占用和缓存占用通常可以显著节省性能。
另外日常开发中的性能问题经常不是算法问题,而是内存问题,优化内存使用将会对性能有很大提升。
4.2.1 减少内存分配
4.2.1.1 结构体对齐优化 (Struct Padding)
在 C++ 中,结构体的大小并不总是其成员大小之和。编译器为了迎合 CPU 的对齐要求,会在成员之间插入"填充字节"(Padding)。
// 🔴 糟糕:随意排列,大小为 24 字节
struct Bad {
char a; // 1 字节 + 7 填充
double b; // 8 字节
int c; // 4 字节 + 4 填充
};
// 🟢 优化:按大小降序排列,大小为 16 字节
struct Good {
double b; // 8 字节
int c; // 4 字节
char a; // 1 字节 + 3 填充
};技巧:将占用空间大的成员放在前面,小的放在后面,可以减少因对齐产生的内存空洞。
4.2.1.2 使用更小的整型(以空间换时间)
不要习惯性地在所有地方都用 int 或 long long。
-
位域 (Bit-fields):如果你有很多布尔值或范围很小的整数。
-
特定宽度类型 :
<cstdint>。struct Status {
uint8_t health : 7; // 0-127 范围,只占 7 位
uint8_t is_dead : 1; // 布尔标志,只占 1 位
}; // 整个结构体只占 1 字节
4.2.1.3 容器的容量回收 (Shrink to Fit)
std::vector 的 clear() 只是清空元素,不会释放缓冲区。如果你的程序处理了一个巨大的数据集后,接下来的时间只需要一小部分数据,你应该释放多余的容量。
std::vector<int> big_data(1000000);
// ... 处理数据 ...
big_data.erase(big_data.begin() + 10, big_data.end()); // 现在只剩下 10 个元素
// 🟢 此时 vector 依然占用 1000000 个元素的内存!
big_data.shrink_to_fit(); // 强制释放多余内存4.2.1.4 字符串优化:避开堆分配
-
std::string****的限制:虽然有 SSO(小字符串优化),但如果字符串超过 15~22 字节(取决于编译器),它就会在堆上分配。
-
std::string_view**(C++20)** :如果你的字符串是从配置文件加载后就不再修改的只读文本,使用
string_view指向原始缓冲区,而不是为每个类实例拷贝一份字符串。
4.2.1.5 惰性初始化 (Lazy Initialization)
如果你的类包含了一些很大但不常用的成员(比如复杂的缓存或大型对象),不要在构造时就创建它们。
class HeavyService {
std::unique_ptr<LargeObject> data; // 初始为 nullptr
public:
void use() {
if (!data) data = std::make_unique<LargeObject>(); // 仅在需要时分配
data->do_work();
}
};4.2.1.6 享元模式 (Flyweight Pattern)
如果你的程序中有成千上万个对象,且它们有很多共同属性(比如森林里每棵树的贴图路径),不要把这些属性存放在每个对象里。
- 做法:将共同属性提取出来存放在一个全局池中,每个对象只持有一个指向该属性的指针或 ID。比如将节点的serviceName都提取到一个公共字符串池中,将大大减少服务发现数据量。
4.2.2 提高数据局部性
提高数据局部性(Data Locality)是让程序跑得快的"第一准则"。其核心目标是:预测 CPU 接下来要用的数据,并确保它们已经在缓存(Cache)里等着了。
数据局部性分为两种:
-
空间局部性:当你访问一个地址,其相邻的地址也很快被访问(例如遍历数组)。
-
时间局部性:一个地址被访问后,短时间内再次被访问(例如局部缓存中的数据)。
以下是提高数据局部性的具体方法:
4.2.2.1 优先访问连续内存
CPU 每次不是只从内存取 1 字节,而是取回一整块(通常是 64 字节 ),这被称为 Cache Line(缓存行)。
示例:按行遍历 vs 按列遍历
在 C++ 中,二维数组是按"行"连续存储的。
// 🟢 推荐:按行遍历(空间局部性极佳)
// CPU 载入 A[0][0] 时,顺便把 A[0][1...7] 都存入了缓存
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
sum += matrix[i][j];
}
}
// 🔴 糟糕:按列遍历(步长过大,缓存失效)
// 每次访问 matrix[i][j] 都要跨越整行内存,导致每次都是 Cache Miss
for (int j = 0; j < cols; ++j) {
for (int i = 0; i < rows; ++i) {
sum += matrix[i][j];
}
}4.2.2.2 分块存储
应考虑使用分块扁平表示法将多个元素紧密地存储在内存中的类型,例如使用absl库中的flat_hash_map,flat_hash_set替换std::map,std::set。
absl::flat_hash_map改进了内存布局,将所有pair放在一段连续内存中,将hash值相同的多个pair放在相邻位置。查找key时,以二次探测方式遍历hash值相等的pair,寻找值相等的key。hash值相同的pair存储在相邻内存位置处,内存局部性好,对CPU cache友好,可以提高查询效率。

absl::flat_hash_map内存布局
4.2.2.3 布局优化:SoA 代替 AoS
如果你的结构体很大,但你只在某个循环中处理其中一个字段,使用 SoA (Structure of Arrays) 能大幅提升局部性。
// 🔴 AoS (Array of Structures): 逻辑简单但局部性差
struct Particle {
float x, y, z;
int id;
char name[16];
};
std::vector<Particle> particles(10000);
// 此时计算所有 X 的位置,CPU 会强行载入 y, z, id 等不用的数据,浪费带宽
for (auto& p : particles) p.x += velocity;
// 🟢 SoA (Structure of Arrays): 局部性极好
struct ParticleSystem {
std::vector<float> x; // 内存完全连续,100% 缓存利用率
std::vector<float> y;
std::vector<float> z;
};
// CPU 预取器可以完美工作,IPC 显著提升
for (float& posX : system.x) posX += velocity;4.2.2.4 数据重组:冷热数据分离 (Hot/Cold Splitting)
如果你有一个庞大的类,但某些成员很少被访问,把它们拆出去。
// 🔴 优化前:Hot 和 Cold 数据混在一起,占用 Cache Line 空间
class Player {
// Hot data: 每帧都要算
float x, y;
int health;
// Cold data: 只有打开菜单才看
char bio[1024];
int skin_id;
};
// 🟢 优化后:将冷数据移到外部指针
class PlayerOptimized {
float x, y;
int health;
std::unique_ptr<PlayerExtraInfo> extra; // 只有在需要时才加载冷数据
};这样在遍历玩家列表时,缓存行里能塞下更多的热数据(时间局部性好),减少了内存访问次数。
4.2.3避免不必要的拷贝
-
使用
const T&传递大对象。 -
利用 移动语义(Move Semantics / std::move**)**:将资源的所有权"偷"过来,而不是深拷贝。
C++17中的std::string_view和brpc中的IOBuf都是使用类似零拷贝的技术减少数据不必要的拷贝。
减少不必要的数据拷贝往往能大幅提升性能。
4.2.4 内存分配优化
4.2.4.1 栈分配替代堆分配
最简单的优化就是尽量避免使用 new。栈内存的分配只需移动栈指针(1 个周期),而堆分配可能需要数百个周期。
大内存(超过1MB)不要在栈上分配,否则可能会导致栈溢出
// 🔴 糟糕:为小对象使用堆分配
void process() {
auto p = new Point(1, 2);
// ... 使用 p
delete p;
}
// 🟢 优化:直接在栈上分配
void process() {
Point p(1, 2);
// 自动管理生命周期,速度极快
}4.2.4.2 对象重用与 clear()
在循环中,不要反复创建和销毁容器。利用 std::vector 或 std::string 的 clear() 方法,它们会清空内容但保留已申请的内存缓冲区。
// 🔴 糟糕:每次循环都重新分配内存
for (int i = 0; i < 1000; ++i) {
std::vector<int> data;
data.reserve(100); // 每次都在分配和释放
fill_data(data);
}
// 🟢 优化:在循环外重用容器
std::vector<int> data;
data.reserve(100);
for (int i = 0; i < 1000; ++i) {
data.clear(); // 清空元素,但容量(Capacity)不变,不触发内存分配
fill_data(data);
}4.4.4.3 预分配空间
如果你提前知道容器大概需要装多少数据,务必使用 reserve()。这能避免 vector 在扩容时反复进行的"申请新空间 -> 拷贝旧数据 -> 释放旧空间"的过程。
std::vector<int> vec;
vec.reserve(10000); // 一次性搞定,后续 10000 次 push_back 都是 O(1) 且无内存分配除了std::vector,std::unordered_map也可以通过 reserve() 预分配内存。
4.2.4.4 在Protobuf中使用Arena分配内存
Protobuf的 Arena (仅C++ protobuf中有)是一种基于**区域内存管理(Region-based Memory Management)**的技术。
它旨在解决 C++ 中频繁使用 new/delete 带来的性能开销和内存碎片问题。简单来说,它将"多次零散的内存分配"变成了"一次大块内存分配,然后切着用"。
Arena 能够摊销内存分配的成本,并使内存释放操作几乎变为零开销。此外,通过从连续的内存块中分配数据,它还能显著提升内存局部性。
在处理高并发、低延迟的 RPC 服务(如 gRPC)时,开启 Arena 往往能带来 20% - 50% 的 CPU 耗时降低,同时显著减少内存碎片。
#include <google/protobuf/arena.h>
#include "my_proto.pb.h"
void HandleIncomingData(const char* data, size_t size) {
// 1. 创建 Arena
// 通常在栈上或作为类成员重用
google::protobuf::Arena arena;
// 2. 在 Arena 上创建消息对象
// 这一步很关键!必须通过 CreateMessage 创建,
// 这样后续 Parse 过程中产生的所有子对象才会自动进入 Arena。
MyMessage* msg = google::protobuf::Arena::CreateMessage<MyMessage>(&arena);
// 3. 解析数据
// Protobuf 知道 msg 是在 Arena 上的,
// 所以解析出来的子字段(string, sub-message)都会分配在 arena 中
if (msg->ParseFromArray(data, size)) {
// 处理消息...
Process(msg);
}
// 4. 函数结束,arena 析构
// 整个消息树(包括 msg 本身和它所有的子字段)被瞬间释放。
// 无需手动 delete msg。
}4.2.4.5 链接jemalloc优化内存分配
在 Linux 环境下,使用 jemalloc 优化 C++ 程序通常被视为"性价比最高"的性能方案。相比系统默认的 ptmalloc,jemalloc 通过更精细的分级管理(Size Classes)和多线程缓存(Thread Cache),极大地降低了内存碎片和多线程竞争。
4.3 微架构与硬件优化
这一层通过迎合 CPU 的物理特性来提高性能。
4.3.1 分支预测优化
CPU会对代码中的逻辑分支做预测,并提前加载指令,当 CPU 猜错分支时,已经进入流水线的几十条指令必须全部作废并重新加载,这会造成巨大的性能损失。
4.3.1.1 排序后再处理
这是最著名的分支预测示例。当数据是随机的,CPU 无法预测 if 的走向;当数据有序时,预测器的成功率接近 100%。
-
场景:统计数组中大于 128 的元素个数。
-
优化前:直接遍历随机数组。
-
优化后 :先对数组进行
std::sort。// 排序后,分支走向从"随机"变成了"连续的 false 接着连续的 true"
// 硬件分支预测器可以完美识别这种模式
std::sort(data.begin(), data.end());
for (int i = 0; i < n; i++) {
if (data[i] >= 128) sum++;
}
性能差异 :在处理大型数组时,排序后的遍历速度通常比随机遍历快 3 到 5 倍,即便它们执行的指令逻辑完全一样。
4.3.1.2 静态分支预测
在某些无法消除的分支中(如错误处理),我们可以明确告诉编译器哪个路径是"冷路径",从而优化指令排布。
可以使用C++17中的 [[likely]] / [[unlikely]] ,boost中的BOOST_LIKELY / BOOST_UNLIKELY ,或者编译器中的**__builtin_expect**明确指定冷热分支。
示例:防御性编程
void process(Data* p) {
if (p == nullptr) [[unlikely]] { //这里的代码块会被移到函数末尾
log_error("Null pointer!");
return;
}
// 正常业务逻辑
p->do_work();
}编译器会将 [[unlikely]] 后的代码块移到函数末尾(冷区域),保证热路径的指令在内存中是连续的。
4.3.1.2 使用查表法替换分支
对于复杂的多分支逻辑(如 switch-case 或多个 if-else if),查表法可以将分支转换为一次内存访问。
- 场景:根据状态码执行不同的加成计算。
-
优化方法:将加成系数预先存入数组。
// 优化前:多次判断
if (status == 1) score *= 1.1;
else if (status == 2) score *= 1.5;// 优化后:直接取值
static const float multipliers[] = {1.0, 1.1, 1.5, 1.0};
score *= multipliers[status & 0x3];
4.3.2 向量化
在现代处理器上,使用SIMD指令可以在常规未向量化(标量)代码上实现巨大的加速。
标量版本加法:
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}使用 AVX2 Intrinsic 手动向量化
通过手动调用内置函数(Intrinsics),我们可以强制 CPU 每次循环处理 8 个浮点数
#include <immintrin.h>
void vec_add(float* a, float* b, float* c, int n) {
for (int i = 0; i < n; i += 8) {
// 1. 从内存加载 8 个 float 到 256 位寄存器
__m256 va = _mm256_load_ps(&a[i]);
__m256 vb = _mm256_load_ps(&b[i]);
// 2. 仅用一个时钟周期完成 8 次加法
__m256 vc = _mm256_add_ps(va, vb);
// 3. 将结果存回内存
_mm256_store_ps(&c[i], vc);
}
}4.4构建与编译器优化
构建和编译优化无需修改代码,就能提升软件性能,是代码优化外的性能利器。
例如字节Service Mesh仅使用LTO、PGO等编译优化技术就将Envoy的性能提升了25% !字节跳动 Service Mesh 数据面编译优化实践
4.4.1 链接时优化 (LTO - Link Time Optimization)
原理 :通常编译器以"源文件"为单位进行优化。如果 A.cpp 调用了 B.cpp 里的函数,编译器在编译 A 时看不见 B 的内联细节。LTO 允许编译器在最后的链接阶段跨越整个程序进行全局优化。
-
CMake 开启方式:
set(CMAKE_INTERPROCEDURAL_OPTIMIZATION TRUE) -
优化效果 :编译器可以跨文件进行函数内联 、死代码消除 以及去虚拟化(将虚函数调用转为直接调用)。
4.4.2 反馈引导优化 (PGO - Profile-Guided Optimization)
原理:编译器不知道你的代码在现实中哪条路径更热。PGO 分为三个步骤:
-
插桩编译:生成一个会记录运行轨迹的程序。
-
训练运行 :用真实数据跑一遍程序,生成
.profraw文件。 -
优化编译:编译器读入运行轨迹,将真正的热点代码放在 Cache 效率最高的地方。
gcc PGO示例:
# 步骤1:生成插桩程序
g++ -O3 -fprofile-generate main.cpp -o app
# 步骤2:训练(运行)
./app < data.txt
# 步骤3:根据数据重新编译
g++ -O3 -fprofile-use main.cpp -o app_opt优化效果:分支预测准确率大幅提升,代码布局(Code Layout)更符合缓存特性。
4.4.3 编译期运行
原理:通过在编译期计算结果,减少运行时的开销。
// 🔴 运行时计算
double calculate(double r) {
return 2 * 3.14159 * r;
}
// 🟢 编译期计算 (C++11/14/17)
constexpr double pi = 3.14159;
constexpr double get_circumference(double r) {
return 2 * pi * r;
}4.4.4 指令集针对性构建
原理 :默认情况下,编译器生成的代码为了保证兼容性(能在旧电脑上跑),只使用最通用的指令。这会导致现代 CPU 的 AVX2 或 AVX-512 指令集闲置。
-
GCC/Clang 优化参数:
-
-march=native:探测当前电脑的 CPU 架构并开启所有支持的特性(最快,但无法在旧机运行)。 -
-msse4.2/-mavx2:手动开启特定指令集。
-
4.5 并发与同步优化
当 CPU 占用率接近 100% 时,并不一定意味着计算性能到头了,也可能是因为锁竞争等原因CPU在空转等待,对并发操作的优化往往能带来很大的性能提升。
4.5.1 减少锁的粒度
原理:锁的竞争范围越小,线程并行的机会就越大。
-
粗粒度锁(Bad):整个哈希表共用一把锁。当一个线程在读取时,另一个线程连插入都不行。
-
细粒度锁(Good):使用**分段锁(Segmented Lock)**或对单个桶(Bucket)加锁。
分段锁示例:
// 🟢 细粒度优化示例:分段锁
class ThreadSafeMap {
std::vectorstd::mutex locks; // 每个桶一把锁
std::vector<std::list> buckets;
public:
void insert(K key, V val) {
int idx = hash(key) % 16;
std::lock_guardstd::mutex lock(locks[idx]); // 仅锁定相关的分段
buckets[idx].push_back({key, val});
}
};
Intel的TBB 库就是使用了分段加锁的方式,减少了锁竞争冲突,从而提升了容器并发更新的性能。
4.5.2 读写分离
原理:在大多数场景中,读操作远多于写操作。互斥锁(Mutex)不区分读写,会阻止多个线程同时读取。
-
优化方案 :使用
std::shared_mutex(C++17)、 boost::shared_mutex 或 pthread_rwlock 等读写锁。 -
效果:允许多个线程同时拥有"读锁",只有在写入时才会阻塞所有线程。这在配置信息读取、路由表查询等场景下性能提升极大。
4.5.3 无锁编程 与原子操作
原理 :利用 CPU 的 CAS (Compare-And-Swap) 指令来实现同步,避免线程进入内核态挂起。
示例:计数器优化
// 🔴 糟糕:使用互斥锁,开销巨大
std::mutex mtx;
int count;
void increment() {
std::lock_guard<std::mutex> lock(mtx);
count++;
}
// 🟢 优化:使用原子操作
std::atomic<int> count;
void increment() {
count.fetch_add(1, std::memory_order_relaxed); // 硬件级同步,无锁开销
}4.5.4 避免伪共享
原理 :这是最隐蔽的并发性能杀手。当两个不相关的变量位于同一个 Cache Line(通常是 64 字节)中,且被运行在不同核心上的线程修改时,CPU 会为了保持缓存一致性而反复在核心间同步该内存块,导致严重的性能退化。
优化方案 :使用 alignas(64) 或 std::hardware_destructive_interference_size 来强制变量分布在不同的缓存行。
struct KeepApart {
alignas(64) std::atomic<int> thread1_count; // 线程A修改
alignas(64) std::atomic<int> thread2_count; // 线程B修改
};
// 这样修改 thread1_count 时,不会干扰 thread2_count 的缓存4.5.5 线程本地存储 (Thread Local Storage, TLS)
原理 :减少同步最好的办法就是不需要同步。如果每个线程都维护自己的数据副本,最后再进行一次汇总,就能彻底消除中间过程的锁竞争。
thread_local int local_count = 0; // 每个线程独享
void handle_request() {
local_count++; // 无需锁,极快
}
// 只有在需要最终结果时,才对所有线程的 local_count 求和总结:并发优化清单
|----------|---------------------|-------------------|
| 优化技术 | 解决的问题 | 核心工具 |
| 细粒度锁 | 锁竞争过重 | 分段加锁 |
| 读写锁 | 读多写少场景 | std::shared_mutex |
| 原子操作 | 简单状态同步 | std::atomic |
| 对齐填充 | 伪共享 (False Sharing) | alignas(64) |
| TLS | 频繁的全局变量访问 | thread_local |