一、回顾
一致性模型:
| 一致性级别 | 强度 | 说明 |
|---|---|---|
| 最终一致性 | 最弱 | 最终会一致,中间可以乱 |
| 顺序一致性 | 中等 | 每个进程内部顺序保留 |
| 线性一致性 | 最强 | 按真实时间顺序执行 |
一致性模型定义了系统对外承诺的行为边界
1、顺序一致性(Sequential Consistency)
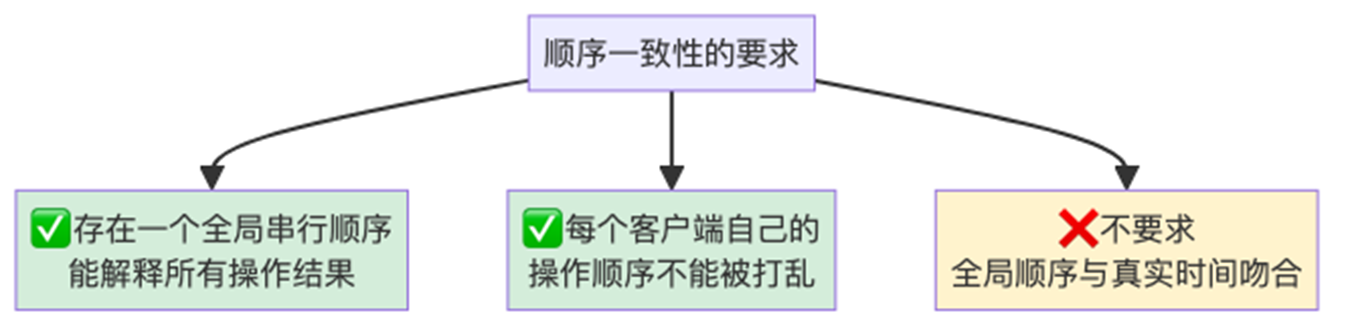
定义:所有操作的结果,等价于将所有客户端的操作按某种顺序交错执行 ,且每个客户端自己内部的操作顺序必须被保留。
2、线性一致性(Linearizability)
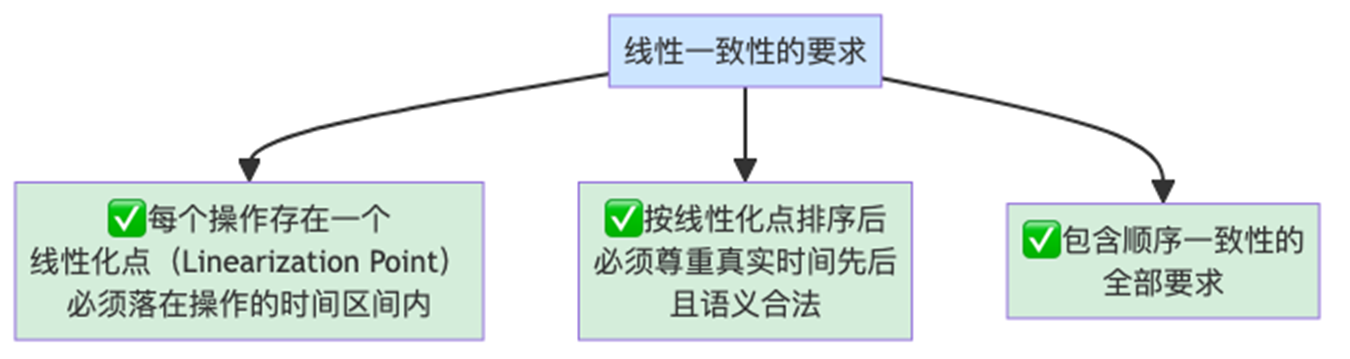
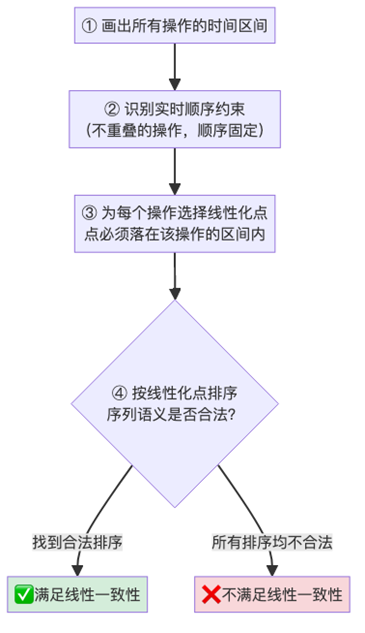
定义:每个操作在其 调用, 返回 区间内某个瞬间原子地生效,整体等价于一个遵照真实时间顺序的串行执行。
如何判断线性一致性:
3、二者对比
| 顺序一致性 | 线性一致性 | |
|---|---|---|
| 要求 | 找到一个自洽的串行顺序 | 自洽的串行顺序 + 符合真实时间 |
| real-time 约束 | ❌ 没有 | ✅ 有 |
| 实现代价 | 稍低 | 更高 |
| 直观程度 | 较抽象 | 更直观 |
顺序一致性 = 找到一个自洽的串行顺序
线性一致性 = 自洽的串行顺序 + 符合真实时间
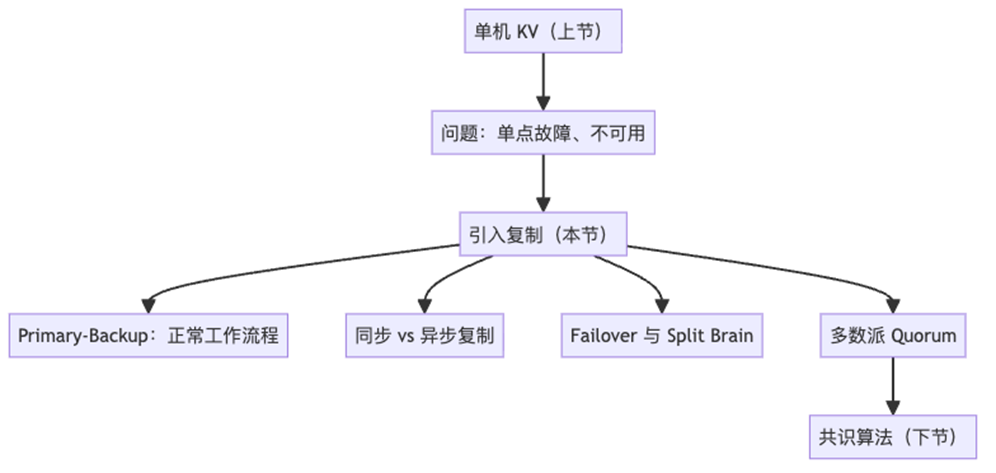
4、单机故障
单机存在的问题:
| 问题 | 说明 |
|---|---|
| 可用性 | 机器宕机 → 服务完全不可用,恢复时间不确定 |
| 持久性 | 内存数据随进程消失;即使写磁盘,硬盘也可能物理损坏 |
如何解决这个问题?
答:复制
二、复制
将数据复制到多台机器上
复制的好处:
-
一台挂了,另一台还有数据
-
一台忙不过来,另一台可以分担读请求
复制的代价:
-
多份数据需要保持一致
-
写操作变复杂(写一份还是写多份?)
-
故障检测和切换需要额外机制
-
网络分区时面临 consistency vs availability 的选择
1、最简单的复制方案:Primary-Backup
核心思想:
-
指定一个节点为 primary(主) ,其余为 backup(备)
-
所有写请求发给 primary
-
Primary 负责把数据同步给 backup
-
读请求可以只从 primary 读
| 角色 | 职责 |
|---|---|
| Primary | 接收所有写请求;决定操作的执行顺序;将操作同步给 backup |
| Backup | 接收 primary 发来的操作;按相同顺序执行;在 primary 故障时准备接管 |
为什么需要一个 Primary?如果两个节点都能接收写,状态会不一致。Primary 负责排序所有写操作,避免冲突。
2、State Machine Replication(状态机复制)
核心思路:如果两台机器从相同初始状态 出发,按相同顺序执行相同的操作,它们的最终状态一定相同。
前提条件:
-
操作必须是**确定性(deterministic)**的
-
执行顺序必须完全一致
什么叫确定性?
| 确定性操作 ✅ | 非确定性操作 ❌ |
|---|---|
| 读写 map 中的 key-value | 读取当前时间 |
| 字符串拼接 | 生成随机数 |
| 数值计算 | 依赖本地文件系统状态 |
如何处理非确定性数据?
-
随机数:primary 生成后把结果发给 backup
-
时间戳:primary 决定时间值,backup 使用相同值
-
外部输入:primary 记录输入内容,backup 重放
Primary-Backup 流程:
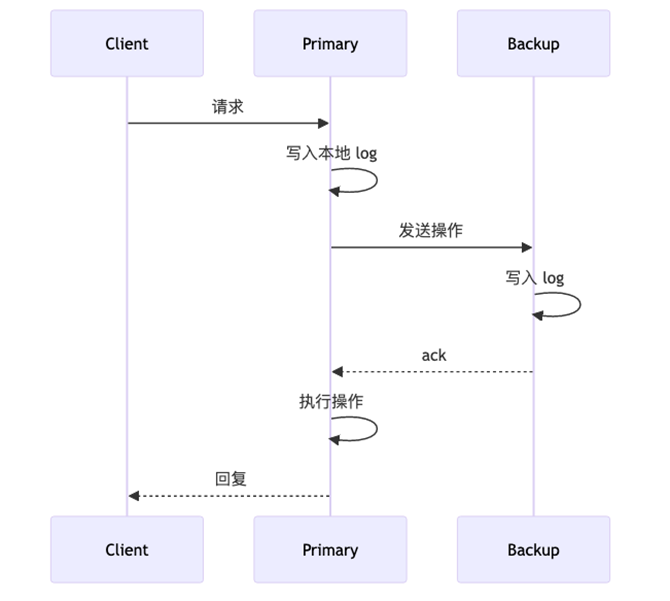
3、同步复制&异步复制
| 同步复制 | 异步复制 | |
|---|---|---|
| 流程 | primary 等 backup 确认后再回复客户端 | primary 立即回复客户端,后台同步给 backup |
| 优点 | backup 一定有最新数据,不丢数据 | 写延迟低,不受 backup 影响 |
| 缺点 | 每次写都要等一个 RTT;backup 慢时拖慢 primary | primary 挂了,最近的写可能丢失 |
|--------|---------------------|--------------|
| 维度 | 同步复制 | 异步复制 |
| 写延迟 | 高(等 backup ack) | 低(立即返回) |
| 数据安全 | 不丢已确认的写 | 可能丢最近的写 |
| 可用性 | backup 故障影响 primary | backup 故障不影响 |
| 一致性 | 容易保证强一致 | 需要额外机制 |
| 系统 | 复制模式 |
|---|---|
| MySQL 主从 | 默认异步,可配置半同步 |
| PostgreSQL | 支持同步复制 |
| Raft/Paxos(分布式系统) | 同步复制到多数派 |
1)同步复制
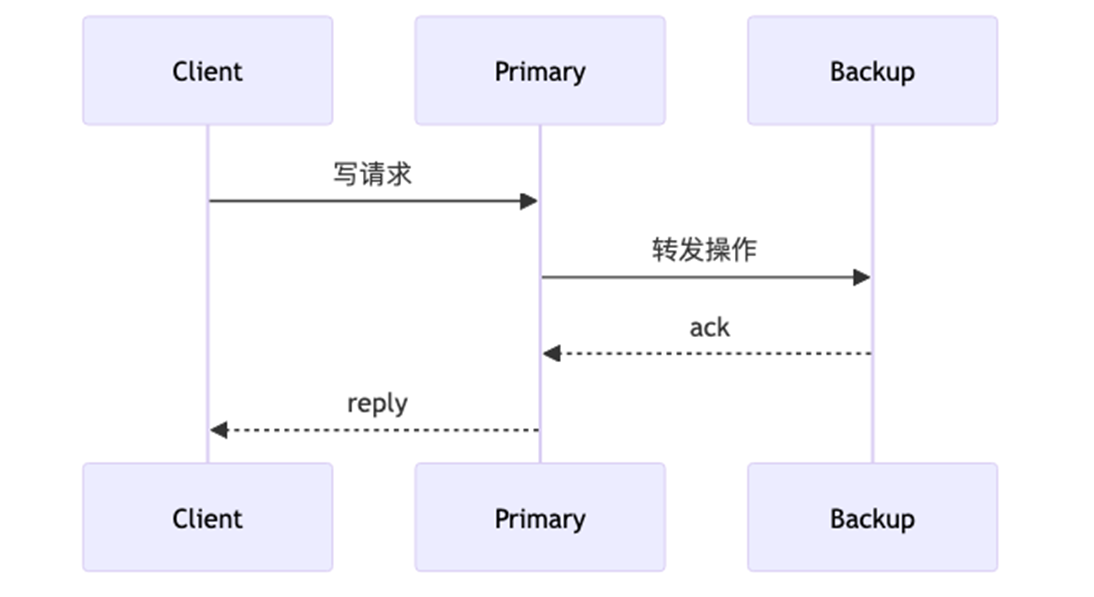
2)异步复制
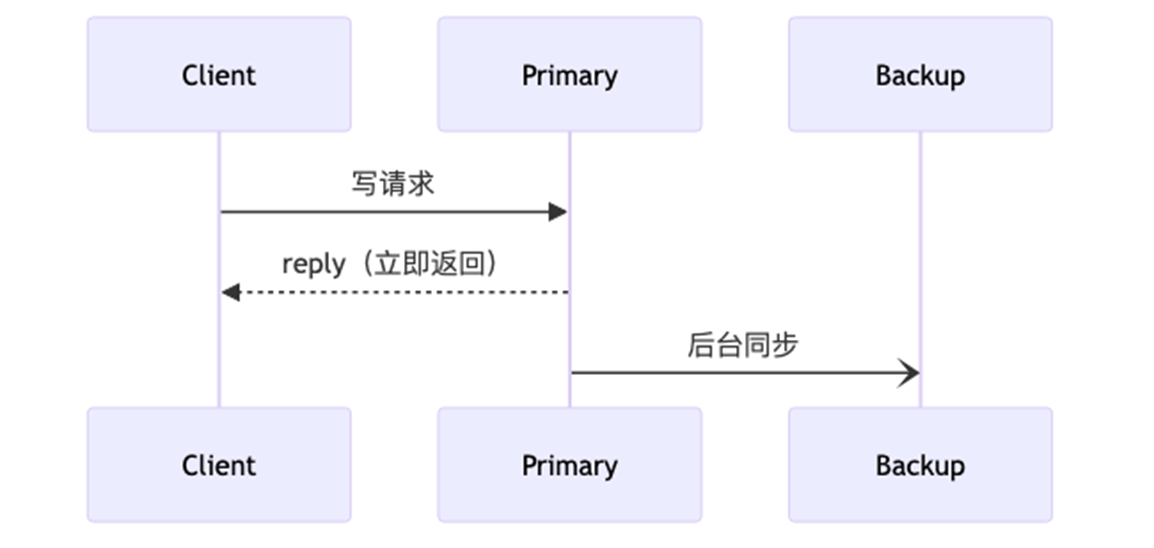
4、Primary backup
同步复制:
-
Primary 决定操作顺序
-
Backup 按相同顺序执行
Q:如果 primary 同时收到两个并发请求,primary 如何决定执行顺序?
答:谁先拿到 primary 内部的锁,谁就排在前面。和单机 KV 一样。
Q:Primary 挂了怎么办?
5、Failover(故障转移)
基本流程:
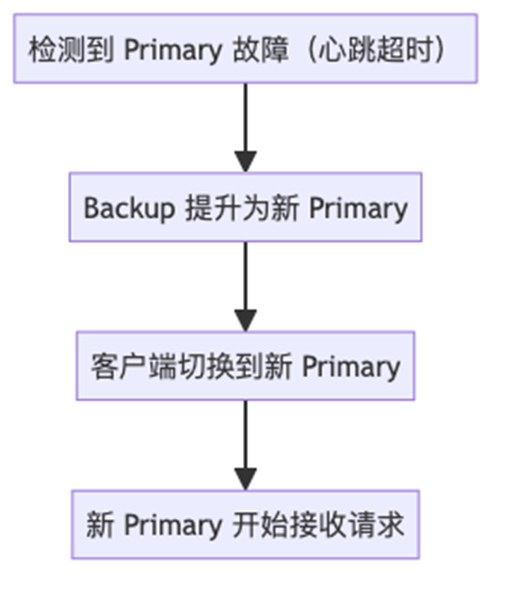
Q1:如何检测到故障?
Primary 和 backup 之间定期发心跳。如果 backup 连续 N 次没收到心跳 → 判定 primary 故障。
但心跳超时不一定意味着 primary 真的挂了:
-
网络拥塞导致心跳延迟
-
Primary 正在做 GC,暂时无响应
-
网络分区:primary 还活着,但 backup 联系不上它
Q2:同步复制下的数据完整性
| 情况 | 结果 |
|---|---|
| Primary 挂之前,所有已确认写已同步到 backup | 数据完整 ✅ |
| Primary 在发送给 backup 之后、收到 ack 之前挂了 | backup 可能收到也可能没收到 ⚠️ |
Q3:异步复制下的数据完整性
-
Primary 可能已经回复客户端成功
-
但还没来得及同步给 backup
-
Primary 挂了 → 这些写操作永久丢失
6、VM-FT 的解决方案:Output Rule
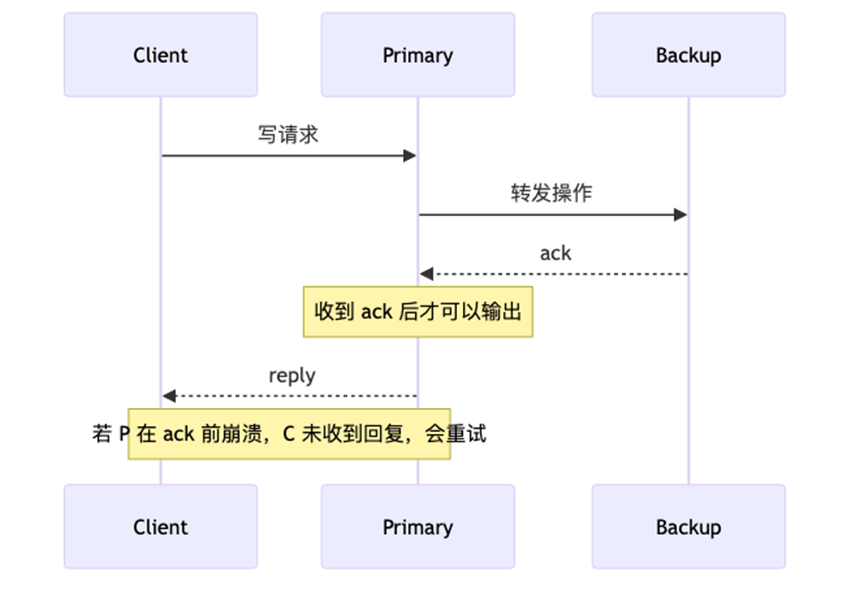
如果一个事件发生了但没有人观察到,它是否真的发生了?
-
客户端还没收到回复 → 从客户端视角,操作还没完成
-
此时 primary 崩溃,backup 接管
-
客户端会重试,backup 重新执行
-
关键:只要客户端没收到确认,丢失就是可接受的。
7、重复执行问题
客户端发了一个请求,primary 执行了但在回复前崩溃。Backup 接管后,客户端超时重试,backup 又执行了一次。
-
Put 操作(幂等):执行两次没问题
-
Append 操作(非幂等):执行两次会重复追加 ❌
如何解决:
给每个请求分配唯一 ID,server 端去重。
8、Split Brain
1)什么是 split brain?
系统中同时存在两个(或多个)节点认为自己是 primary
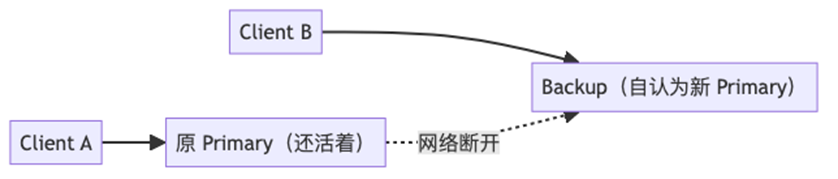
Primary A ──心跳──→ Backup B
✗(网络断了)
Primary A 还活着 Backup B 收不到心跳
(认为自己是 primary) (认为 A 挂了,把自己提升为 primary)
现在系统中有两个 primary!
Split Brain 导致:两个 primary 各自接收不同的写
| 原 Primary | 新 Primary |
|---|---|
| Put("x", 1) | Put("x", 3) |
| Put("y", 2) | Put("z", 4) |
-
两者的状态不一致
-
客户端看到的结果取决于连到了哪个节点
-
Linearizability 被彻底破坏
2)导致 Split Brain 的根本原因:
网络分区(Network Partition) :节点之间的通信中断,但节点本身还在正常运行。
心跳超时无法区分两种情况:
-
Primary 真的挂了
-
Primary 还活着,只是网络不通
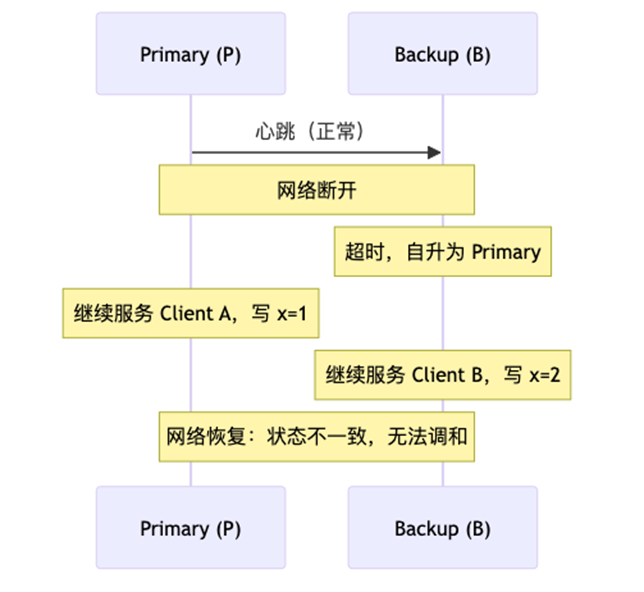
3)如何解决 Split Brain
方案一:人工介入
-
检测到 split brain 时报警
-
运维人员手动判断哪个是真 primary
-
手动关闭另一个
缺点:恢复时间长,不适合高可用场景。
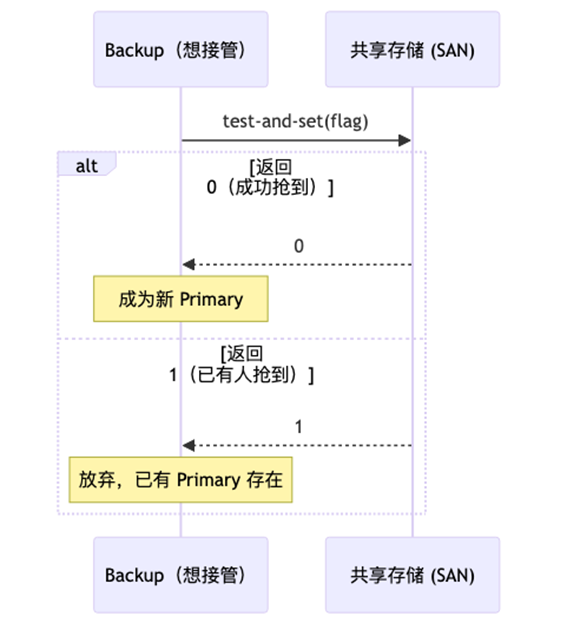
方案 2:共享存储
-
Primary 和 backup 共享一块存储(如 SAN)
-
存储上有一个 atomic test-and-set 变量
方案3:多数派(Quorum)------最根本的方案
如果有 3 个节点而不是 2 个:
-
任何决策需要至少 2 个节点同意
-
网络分区时,只有包含多数节点的那一侧能继续工作
-
少数派一侧自动停止服务
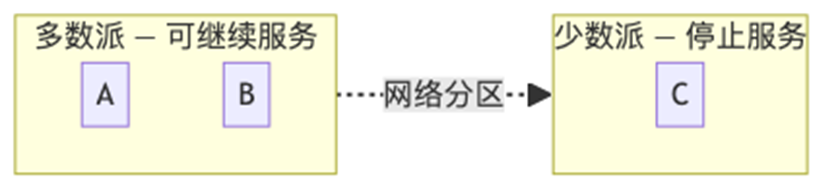
不选用偶数个节点:因为区分不开。分布式共识系统通常用奇数个节点

9、View(每一任 primary 对应一个 view)
系统运行过程中,primary 由于故障等原因可能会变。每一任 primary 对应一个 **view,**相当于编号了
View 1:Primary = A,Backup = B, C
View 2:Primary = B,Backup = A, C (A 故障后切换)
View 3:Primary = C,Backup = A, B (B 故障后切换)
View number 单调递增,保证所有节点对"当前是第几任"有共识
为什么需要 View number 作用是什么?
没有 view number 的话:
-
旧 primary 网络恢复后,可能还认为自己是 primary
-
新 primary 已经在服务了
-
两者冲突
有了 view number:
-
节点收到来自旧 view 的消息,直接拒绝
-
类似 Raft 中的 term------编号小的让位给编号大的
Primary backup 缺了:
primary 故障后,如何选举新的 primary?
选出新 primary 之后,还要保证:
-
旧 primary 已经 commit 的数据不能丢
-
新 primary 的 log 必须包含所有已 commit 的操作
-
旧 primary 如果还活着,必须让位
10、从 Primary-Backup 到 Consensus(共识)
Consensus 协议(如 Raft)把选举、复制、安全性统一在一个协议里
|----------------|----------------------------|------------------|
| 问题 | Primary-Backup****能解决吗 | 需要 Consensus |
| 数据复制 | 能 | --- |
| 操作排序 | 能(primary 决定) | --- |
| 检测故障 | 心跳(不完美) | --- |
| 选新 primary | 不能 | 需要 |
| 保证数据不丢 | 部分(同步复制) | 需要 |
| 防止 split brain | 不能(2 节点) | 需要 |
尽管有 split brain 问题,primary-backup 在实践中仍然广泛使用:
- MySQL 主从复制
- Redis Sentinel
- PostgreSQL streaming replication
通常配合外部协调服务(如 ZooKeeper、etcd)来做 leader election
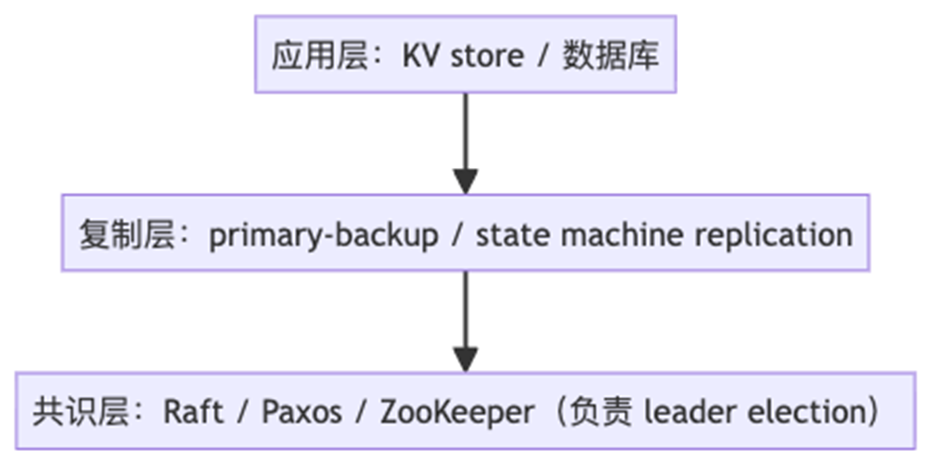
11、从 Primary-Backup 到 Raft 的演进
| 方案 | 问题 |
|---|---|
| Primary-Backup | Leader election 依赖外部机制 |
| 外部协调服务 | 外部服务本身也可能故障 |
| Raft | 把 leader election 和 log replication 统一在一个协议里,不依赖外部服务,用多数派保证安全性 |
12、总结
| 问题 | 答案 |
|---|---|
| 加一台备份机能解决单点故障吗? | 能提高可用性,但 failover 不是简单的切换 |
| 备份机直接接管能保证正确性吗? | 不能。同步复制/异步复制有取舍;网络分区会导致 split brain |
| 概念 | 一句话 |
|---|---|
| Primary-Backup | 一个 primary 排序所有写,backup 跟随 |
| 同步复制 | 等 backup 确认再回复,数据安全但慢 |
| 异步复制 | 立即回复,快但可能丢数据 |
| State Machine Replication | 相同顺序 + 确定性 = 相同状态 |
| Split Brain | 网络分区导致多个 primary 共存 |
| 多数派(Quorum) | 2f+1 节点中 f+1 同意才能决策 |