6月19号,Google 联合微软、Hugging Face,加上 GitHub、Amazon、NVIDIA、Cisco、Salesforce、Snowflake、Databricks,一起发了一份开放规范,叫 ARD。
没什么发布会,没什么 CEO 站台,连主流科技媒体都没怎么报。跟去年 Anthropic 发布 MCP 时各路大 V 争相解读的热闹场面比,ARD 几乎是悄悄上线的。
但我翻完这份规范文档之后(https://agenticresourcediscovery.org/spec/),觉得这事值得说道说道。
ARD 是什么,解决什么问题
ARD 全称 Agentic Resource Discovery------"智能体资源发现",这个规范 定义了 Agent 怎么找到别的 Agent 和工具。
想象一下,互联网上有 2000 个 Agent,其中 147 个跟 "差旅" 相关,83 个能处理 "报销",你需要的是那个同时满足两者的Agent。如何从2000个 Agent 当中找到你需要的?这就是 ARD 要解决的问题。
规范文档写得很直白:
当前的模型要求用户或开发者显式 "安装" 或硬编码每个 Agent 才能使用。当生态扩展到数千或数百万个 Agent 时,我们需要一个模型,让 LLM 能像搜索引擎发现网页一样,动态地发现和调用 Agent。
ARD 的运行机制
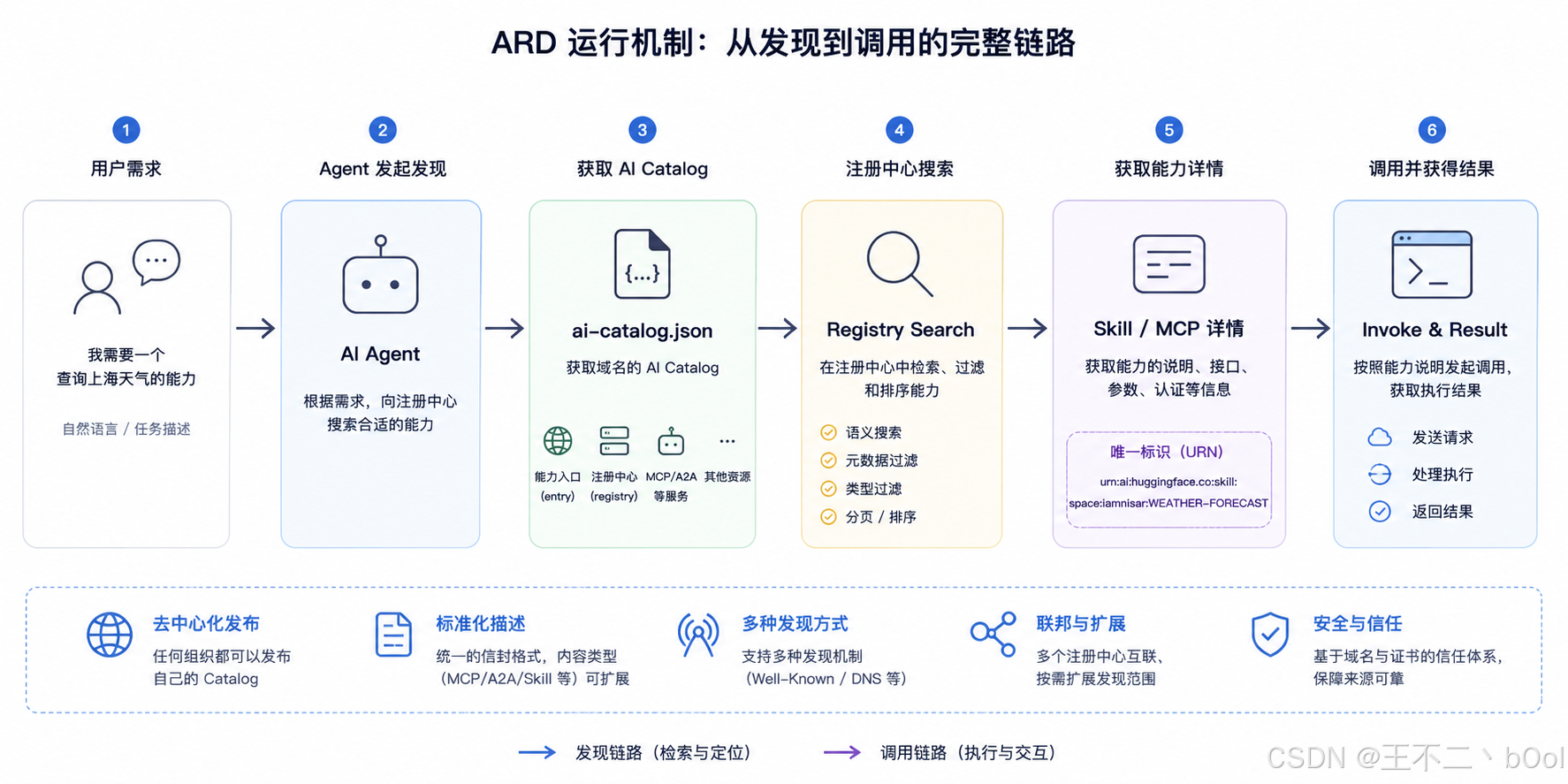
第一步:告诉别人你有什么
ARD 要求,每个域名的根目录放一个 /.well-known/ai-catalog.json,告诉全世界 "我有哪些 Agent 资源"。例如访问 Hugging Face 的 ai-catalog.json,会得到这样的返回数据(可以在浏览器里直接访问 https://huggingface-hf-discover.hf.space/.well-known/ai-catalog.json):
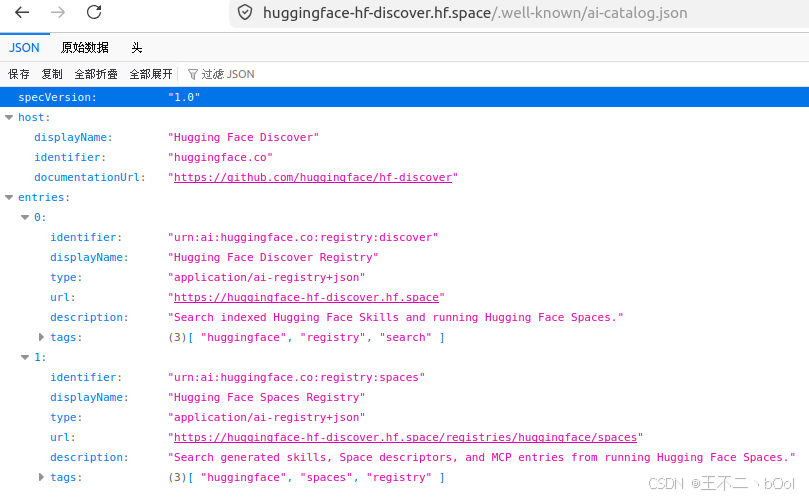
从返回结果中,我们可以看到 Hugging Face 提供了两个注册中心,一个搜全部的 Skills 和 Spaces,一个专门搜 Spaces。
其中的 type 字段,application/ai-registry+json 表示这个 entry 是一个注册中心。如果是一个 MCP Server,type 就是 application/mcp-server-card+json;如果是 A2A Agent,就是 application/a2a-agent-card+json。ARD 自己不定义每种资源的内部结构,它只当"信封"------不管你装的是 MCP 还是 A2A 还是别的什么,信封的格式是一样的。
这就是 ai-catalog.json 的角色------一张名片,贴在你家门口,告诉路过的人你家能干什么。
第二步:让别人找到你的名片
你的 ai-catalog.json 放好了,但别人怎么知道去哪找?ARD 提供了四条路。
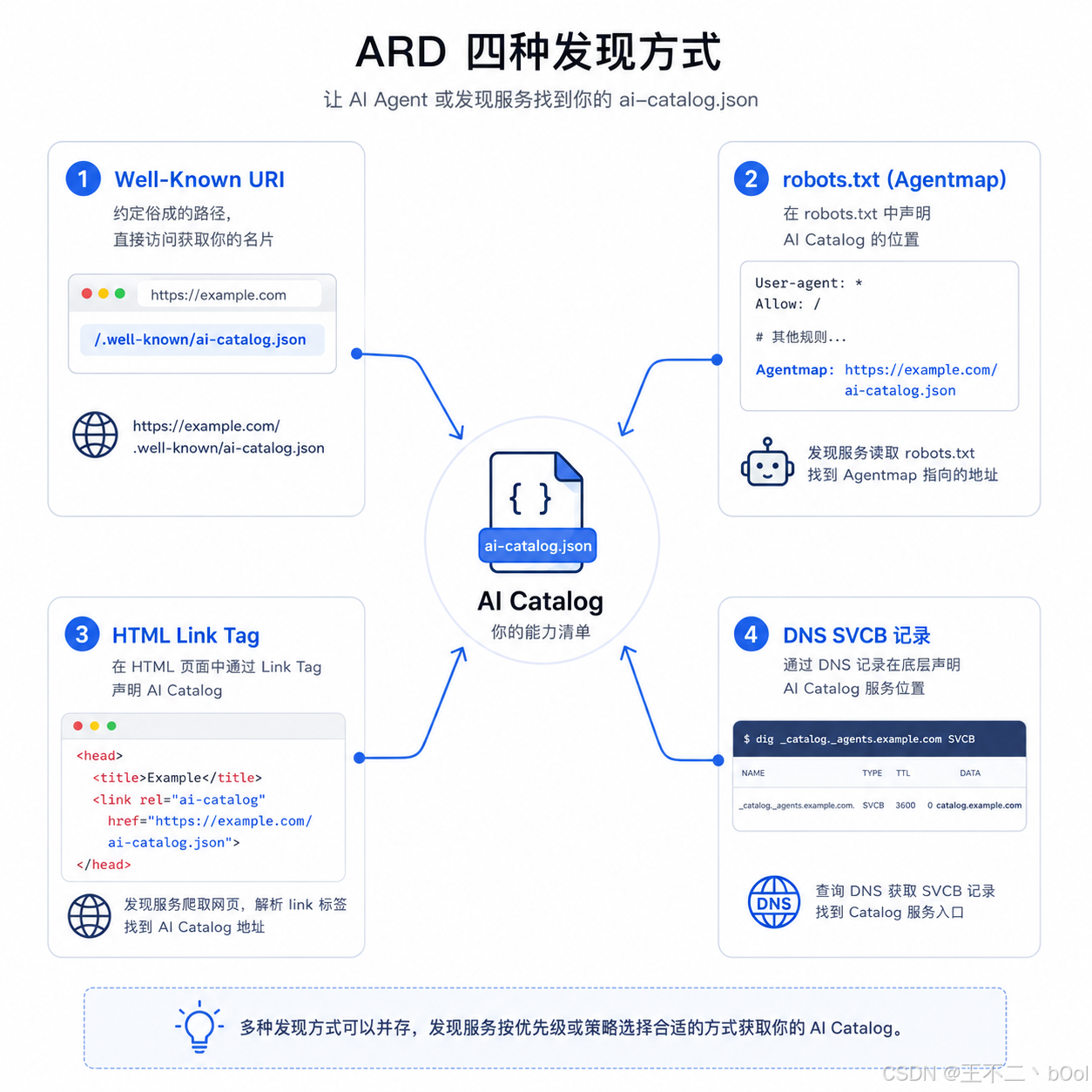
方式一:Well-Known URI------把名片放在约定俗成的位置
web 有一个约定,每一个域名下的 /.well-known/ 目录,是"大家约定好了去这找东西"的地方。比如你申请 HTTPS 证书的时候,证书颁发机构会往 /.well-known/acme-challenge/ 下放一个临时验证文件,证明你确实控制这个域名。
ARD 在这个约定目录下再加一个文件------/.well-known/ai-catalog.json。任何人、任何 Agent 想知道你有哪些 Agent 资源,直接拼这个地址去取就行。
方式二:Agentmap 指令------告诉别人你的名片在哪
一般网站都会有个 robots.txt 文件,它是网站根目录下的一个纯文本文件,专门给爬虫看的"访客须知"。每一家搜索引擎来你网站的第一件事,就是先读 https://你的域名/robots.txt,看看你有什么规则。比如:
Sitemap: https://example.com/sitemap.xml爬虫读到这行,就知道去 sitemap.xml 获取你整个网站的页面列表,不用一个一个爬你的页面了。
ARD 用了完全相同的套路,只是在 robots.txt 里多加了一种指令:
Agentmap: https://example.com/ai-catalog.jsonAgentmap 可以说完全参考 Sitemap,告诉 Agent 发现服务"我的 Agent 目录在这"。读到这行,发现服务就知道你的名片在哪个 URL,然后去拉取。现有的 Web 爬虫基础设施几乎不用改就能复用。
方式三:HTML Link Tag------在网页里藏一句暗号
就是在你网站的 HTML 页面 <head> 里加一行:
html
<link rel="ai-catalog" href="https://example.com/ai-catalog.json">这行代码是给程序看的声明------"这个网站关联了一个 AI Agent 目录,地址是 xxx"。当 ARD 发现服务爬到你的网页时,解析 HTML 就能看到这个标签,顺藤摸瓜找到你的 "名片"。
这个也是老套路了,很多网站 <head> 里有 <link rel="alternate" type="application/rss+xml" href="/feed.xml">,RSS 阅读器看到这行就知道去哪拿内容。浏览器看到 <link rel="icon" href="/favicon.ico"> 就知道网站图标在哪。ARD 只是加了一种 rel="ai-catalog",逻辑一模一样。
方式四:DNS 记录------记录在电话簿里
DNS 是互联网的"电话簿"------输入 google.com,DNS 告诉你对应的 IP 地址是 142.250.x.x。但 DNS 不只能存 IP,还能存各种服务的元数据。比如你手机上添加一个邮箱账户,只需要输入邮箱地址,App 根本不需要你告诉它邮件服务器在哪------它在 DNS 里查一条记录,SMTP 服务器地址就自动回来了。
ARD 在 DNS 里加一条 SVCB(Service Binding)记录:
_catalog._agents.example.com SVCB 0 catalog.example.com这条记录告诉全网的 DNS 系统:在 example.com 这个域名下,Agent 目录服务由 catalog.example.com 提供。任何人只要查 DNS,不访问你的网站、不读你的网页,就能发现你的 Agent 目录。这是最底层也最通用的发现方式。
第三步:找到之后怎么用?
拿到 catalog,知道了注册中心的地址,接下来就是搜索。
以上面 Hugging Face 的注册中心为例,我们搜索一个天气相关的能力:
bash
curl -s https://huggingface-hf-discover.hf.space/search \
-X POST -H "Content-Type: application/json" \
-d '{"query":{"text":"weather"},"pageSize":2}'返回结果长这样(简化版):
json
{
"results": [
{
"identifier": "urn:ai:huggingface.co:skill:space:georgescutelnicu:weather-image-classifier",
"displayName": "Weather Image Classifier",
"type": "application/ai-skill",
"description": "Classify weather conditions from an image",
"url": "https://evalstate-hf-discover.hf.space/skills/huggingface/georgescutelnicu/weather-image-classifier/SKILL.md",
"metadata": {
"spaceId": "georgescutelnicu/weather-image-classifier",
"sdk": "gradio",
"appUrl": "https://georgescutelnicu-weather-image-classifier.hf.space",
"runtimeStage": "RUNNING",
......
},
......
},
{
"identifier": "urn:ai:huggingface.co:skill:space:iamnisar:WEATHER-FORECAST",
"displayName": "WEATHER FORECAST",
"type": "application/ai-skill",
"description": "Get real-time weather and 7-day forecasts",
"url": "https://evalstate-hf-discover.hf.space/skills/huggingface/iamnisar/WEATHER-FORECAST/SKILL.md",
"metadata": {
"spaceId": "iamnisar/WEATHER-FORECAST",
"sdk": "gradio",
"appUrl": "https://iamnisar-weather-forecast.hf.space",
"runtimeStage": "RUNNING",
......
},
......
}
]
}返回结果中的 "identifier": "urn:ai:huggingface.co:skill:space:iamnisar:WEATHER-FORECAST" 是当前这个AI能力的全网唯一标识。
这里的唯一标识是 URN ,而不是 URL。考虑到服务一迁移 URL 就变,所有依赖全得改,而 URN 是纯粹的"名字",稳定性更强,所以设计中把地址放在 url 字段里,迁移只改 url,标识符不动。而且和域名锚定的 URN 天然有信任属性,urn:ai:google.com:tax-agent 里的 google.com 可以通过 mTLS 证书交叉验证,防止冒充,能提供一定程度的安全保障。
"url": "https://evalstate-hf-discover.hf.space/skills/huggingface/iamnisar/WEATHER-FORECAST/SKILL.md" 这个里面放的是当前技能的说明,告诉 Agent 如何使用。
To use this application (iamnisar/WEATHER-FORECAST: Get real-time weather and 7‑day forecast for any city):
API schema: GET https://iamnisar-weather-forecast.hf.space/gradio_api/info
Config (find fn_index): GET https://iamnisar-weather-forecast.hf.space/config → dependenciesi.id where api_name matches API schema endpoint
Join the queue: POST https://iamnisar-weather-forecast.hf.space/gradio_api/queue/join (pass {"data": ..., "fn_index": , "session_hash": ""})
Stream results: GET https://iamnisar-weather-forecast.hf.space/gradio_api/queue/data?session_hash=
File inputs: POST https://iamnisar-weather-forecast.hf.space/gradio_api/upload -F "files=@file.ext", use as: {"path": "", "meta": {"_type": "gradio.FileData"}, "orig_name": "file.ext"}
Auth: Bearer $HF_TOKEN (https://huggingface.co/settings/tokens)
SKILL 告诉 Agent ,可以通过 https://iamnisar-weather-forecast.hf.space/gradio_api/info 来获取接口概要。
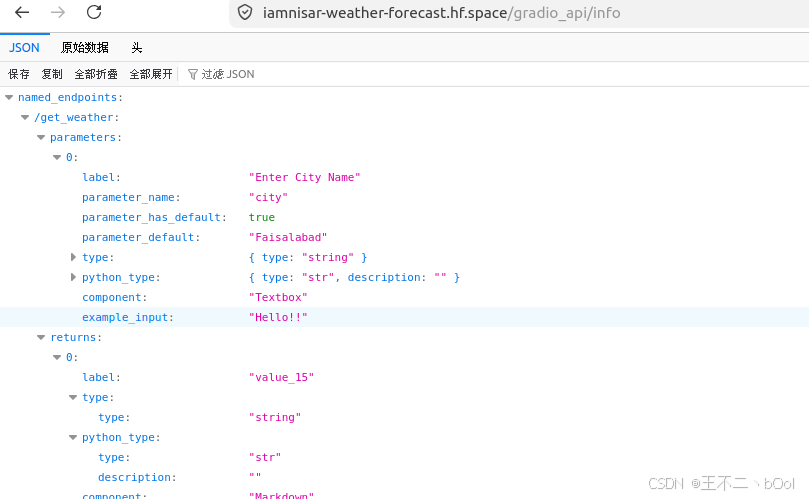
这个服务有一个接口叫 /get_weather,参数是 city,返回一组 Markdown 格式的天气数据。
然后按照 gradio 要求的两阶段方式(metadata 中的 "sdk": "gradio")发起调用:
bash
# 提交请求
curl -s -X POST "https://iamnisar-weather-forecast.hf.space/gradio_api/call/get_weather" \
-H "Content-Type: application/json" \
-d '{"data": ["上海"]}'
# 返回结果
{"event_id":"7ff9d5f9b7bb4e069bcc84834c4abb44"}
# 获取天气信息
curl -N "https://iamnisar-weather-forecast.hf.space/gradio_api/call/get_weather/{event_id}"第四步:一个注册中心不够怎么办?
Hugging Face 的注册中心只收录 HF 上的资源。如果 Agent 需要找 GitHub 上的 MCP Server 呢?或者公司内部的私有工具呢?
ARD 的联邦模式让多个注册中心互联,跟 DNS 的递归查询逻辑几乎一模一样:
- auto:你的注册中心自动去问上游,合并结果返回,用户无感
- referrals:先返回本地结果,再附上 "那边还有一个注册中心可能也有",客户端自己决定要不要跟进
- none:只搜本地
你问本地 DNS,本地 DNS 说"我没这条记录,你去问那个权威的DNS服务器"。ARD 的联邦也是这个路数。
ARD 和 MCP 的区别
最开始看到 ARD,感觉和 MCP 有点像,其实认证思考一下,和 MCP 完全是不同的协议。
MCP 解决的是"调用"问题。 一个 Agent 要用某个工具,MCP 定义了怎么连接、怎么传参、怎么拿到结果。用的是 JSON-RPC。
ARD 解决的是"发现"问题。 一个 Agent 要用某个工具,但不知道哪个工具存在、在哪、靠不靠谱,ARD 定义了怎么搜、怎么过滤、怎么跨注册中心找。用的是 REST HTTP。
ARD 的规范里明确支持 MCP 作为内部类型:type: application/mcp-server-card+json。ARD 的 catalog entry 可以直接包装 MCP Server 的描述,注册中心自身也能通过 MCP Tool 暴露搜索能力。它们是同一套链路上的两个环节。
Agent 需要工具
│
▼
[ARD] 发现工具在哪(有可能找到一个MCP服务器)
│
▼
[MCP] 连接并调用工具打个比方,MCP 是电话听筒,定义了怎么拨号、怎么通话。ARD 是电话号码簿,帮你找到该拨哪个号。你不会因为有了电话就不需要号码簿,也不会因为有了号码簿就不用电话。
从 Function Call 到 ARD:Agent 正在重走互联网的路
看完 ARD 让我觉得 Agent 生态正处在一个非常奇妙的阶段。回过头看,过去几年 Agent 的标准化进程,跟早期互联网的发展轨迹惊人地相似。
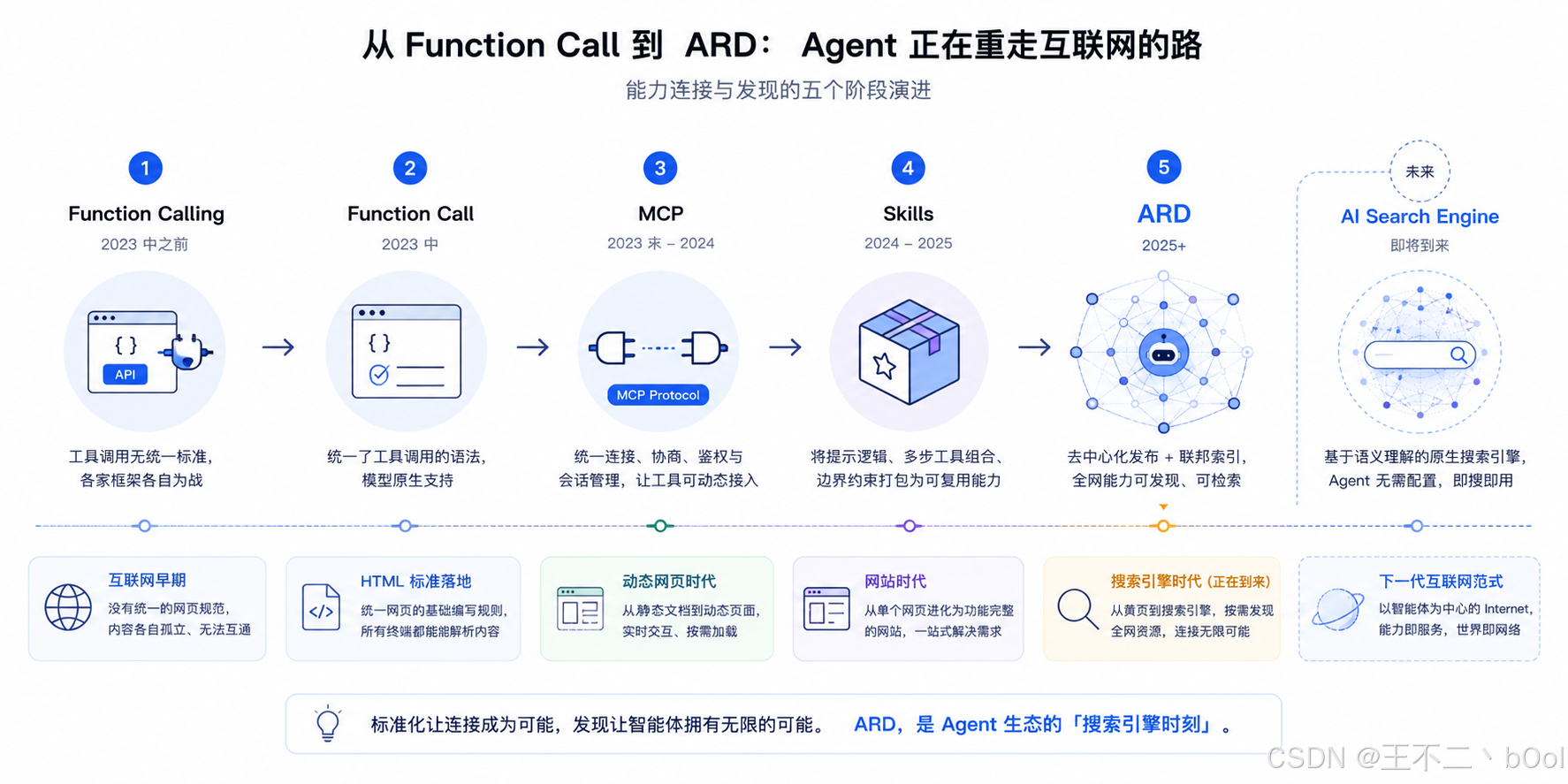
第一个阶段,工具调用无标准。 2023 年中之前,大模型调用工具全靠 Prompt 引导,每个框架各搞各的,LangChain 一套 tool 定义,AutoGPT 一套,互不相通。就像互联网早期,没有统一的网页规范,不同体系的内容各自孤立、无法互通。
第二个阶段,Function Call 出来,统一了调用的语法。 OpenAI 在 2023 年中推出 Function Calling,各家模型厂商迅速跟进,工具调用的格式首次统一并内置进模型原生模板。这就好比 HTML 标准落地,统一了网页的基础编写规则,所有终端都能按同一套标准解析内容。
第三个阶段,MCP 出来,把静态工具变为动态。 Function Calling 只定义了工具的描述与调用输出语法,MCP 则统一了 Agent 与工具间的建连、协商、鉴权与会话管理标准,让工具从硬编码的静态条目变为可动态接入的标准化服务。这就像网页从静态文档过渡到动态页面,不再是固定不变的内容,而是可以实时交互、按需加载最新能力。
第四个阶段,Skill 出来,能力的形态得以整合增强"。 Skill 不再局限于单次工具调用,而是把提示逻辑、多步工具组合、边界约束打包成可复用的完整能力单元,能独立完成一整类细分任务。这就像从零散的单个网页,进化为功能完整的网站,一站式解决一类需求。
第五个阶段,ARD 出来,把发现的范围从本地推到了全网。 此前的 MCP 和 Skill 都依赖提前配置的已知地址,ARD 则基于通用域名约定实现去中心化发布,搭配联邦索引网络,让 Agent 可动态检索全网能力。这就像互联网发展到早期黄页阶段,不用再靠提前记网址找服务,可以按需发现全网的可用资源。
顺着这条演进轨迹推演下去,我们可以做出一个清晰的预判。Agent 生态的下一个阶段,必然会诞生面向全网 AI 能力的原生搜索引擎 。Agent 无需预先配置任何服务地址,仅凭语义需求就能在全网范围内精准检索、即时对接对应的能力。这就像互联网从黄页时代迈入搜索引擎时代 ------ 它将彻底打破能力发现的边界,重构 Agent 获取外部能力的方式。让我们拭目以待。