一、硬件理解
1. 磁盘的物理结构:从盘片到扇区
现代机械硬盘(HDD)由多个盘片(platter) 堆叠组成,每个盘片的正反两面都可存储数据,对应一个磁头(head)。所有盘片共用一个主轴旋转,磁头通过传动臂在盘片表面径向移动,实现数据的读写。
- 磁道(Track):盘片上以同心圆形式划分的环形区域,是数据存储的物理路径。
- 柱面(Cylinder):所有盘片上相同半径的磁道组合成一个"圆柱体",称为柱面。柱面数量 = 磁道数。
- 扇区(Sector) :磁道被进一步划分为更小的弧段,即扇区。扇区是磁盘存储数据的最小物理单位,传统大小为512字节(现代硬盘可能使用4KB高级格式,但逻辑上仍兼容512B)。
- 磁头(Head):每个盘面配有一个磁头,负责读写对应盘面的数据。磁头随传动臂同步移动,因此同一时刻所有磁头位于同一柱面。
💡 关键细节:磁头是"共进退"的 ------ 当磁头移动到某个柱面时,所有盘面的对应磁道同时可被访问,这为后续的CHS寻址提供了基础。
2. 如何定位一个扇区?------ CHS 寻址法
在早期的硬盘系统中,操作系统通过**柱面-磁头-扇区(Cylinder-Head-Sector, CHS)**三元组来精确定位任意一个扇区:
- C(柱面):决定磁头在径向上的位置(即哪个磁道环)。
- H(磁头):决定访问哪个盘面(即哪个盘片的哪一面)。
- S(扇区):决定在该磁道上从哪个起始点开始读写。
例如,要访问第3个柱面、第2个磁头、第5个扇区的数据,系统会驱动磁头移动到第3柱面,选择第2磁头对应的盘面,然后等待盘片旋转到第5扇区的位置进行读写。
⚠️ 注意:CHS寻址有容量限制!由于早期BIOS和IDE接口使用10bit表示柱面、8bit表示磁头、6bit表示扇区,最大支持约8.4GB硬盘(2^10 × 2^8 × 2^6 × 512B = 8.4GB)。现代硬盘已普遍采用LBA(逻辑块地址)寻址,但底层仍可能映射回CHS。
3. 磁盘容量计算公式
磁盘总容量可通过以下公式估算:
总容量 = 柱面数 × 磁头数 × 每磁道扇区数 × 每扇区字节数例如,若某硬盘参数为:
- 柱面数 = 1024
- 磁头数 = 63
- 每磁道扇区数 = 63
- 每扇区 = 512 字节
则总容量 ≈ 1024 × 63 × 63 × 512 ≈ 2.1 GB(实际因格式化开销略小)
✅ 实际使用中,可通过
fdisk -l或lsblk命令查看磁盘分区表和容量信息,如图中所示的/dev/vda设备及其分区详情。
4. 磁盘的逻辑结构:从三维数组到一维线性空间
虽然磁盘在物理上是立体的------由多个盘片堆叠而成,每个盘片有多个磁道,每个磁道又划分为多个扇区------但在逻辑上,我们可以将其抽象为一个三维数组:
- 第一维:柱面(Cylinder) ------ 所有盘片上相同半径的磁道组成一个柱面,相当于"环"。
- 第二维:磁头(Head) ------ 对应盘面编号,决定访问哪个盘面。
- 第三维:扇区(Sector) ------ 每个磁道上的最小存储单元。
💡 举例:若硬盘有100个柱面、2个磁头(即2个盘面)、每磁道63个扇区,则总扇区数 = 100 × 2 × 63 = 12,600 个扇区。
这种结构就像把一整卷磁带"展开"成一张二维表格,再把多张表格叠起来形成三维空间。但操作系统并不直接操作这个三维结构,而是将其"拉直"成一个一维线性数组,这就是LBA的由来。
5. LBA:逻辑块地址 ------ 操作系统的统一语言
LBA是一个从0开始的连续整数,代表磁盘上每一个扇区的唯一编号。它屏蔽了底层复杂的CHS几何结构,让文件系统可以像访问内存一样按"块号"读写数据。
LBA的优势:
- 简化寻址:无需关心磁头、柱面、扇区的物理位置。
- 支持大容量硬盘:突破CHS的8.4GB限制(因LBA使用32位或48位地址)。
- 便于文件系统管理:ext4、XFS等文件系统都以"块"为单位分配空间,而块本质就是若干个连续扇区的LBA集合。
CHS ↔ LBA 转换公式:
假设:
- C = 柱面号(从0开始)
- H = 磁头号(从0开始)
- S = 扇区号(从1开始)
- HPC = 每柱面磁头数(即盘面数)
- SPT = 每磁道扇区数
则:
LBA = (C × HPC + H) × SPT + (S - 1)反向转换:
C = LBA // (HPC × SPT)
H = (LBA % (HPC × SPT)) // SPT
S = (LBA % SPT) + 1💡 注意:现代硬盘和操作系统已不再直接使用CHS,而是通过固件将LBA映射到物理位置。用户和文件系统只需关心LBA即可。
二、引入文件系统
1. 引入"块"(Block)概念
硬盘的物理存储单元是"扇区"(Sector),通常大小为 512 字节或 4KB。但操作系统不会直接按扇区读写,因为效率太低。因此,文件系统引入了"块"(Block)的概念------它是文件系统管理数据的最小单位。
- 块的大小:由文件系统格式化时决定,常见为 4KB(即 8 个 512 字节扇区)。
- 块的作用:操作系统以"块"为单位进行数据的读取和写入,提高 I/O 效率。
- 块的寻址 :每个块有唯一的逻辑块地址(LBA),通过公式
块号 = LBA / 每块扇区数可计算。
💡 注意:一个文件可能占用多个不连续的块,文件系统负责记录这些块的分布。
2. 引入"分区"(Partition)概念
一块物理硬盘可以被划分为多个逻辑区域,称为"分区"。在 Windows 中我们熟悉的 C:、D: 盘就是分区的体现。在 Linux 中,分区同样存在,但更强调其作为"设备文件"的属性(如 /dev/sda1)。
- 分区的本质:是对硬盘空间的逻辑划分,便于管理和隔离不同用途的数据(如系统、用户数据、交换空间等)。
- 分区表:记录每个分区的起始柱面、结束柱面、大小等信息。柱面是硬盘物理结构中的最小可寻址单位,由磁头、柱面、扇区共同定位。
- LBA 与分区的关联:知道分区的起始 LBA 和大小,就能确定该分区内所有块的地址范围。
📌 关键点:分区是文件系统存在的"容器",而"块"是文件系统内部管理数据的基本单元。
3. 引入"inode"(索引节点)概念
这是理解 Linux 文件系统的核心!在 Linux 中,文件名 ≠ 文件本身。文件名只是指向文件元数据的一个"标签",而真正的文件信息(属性、数据位置等)存储在 inode 中。
1. 什么是 inode?
- 定义:inode 是文件系统中用于存储文件元数据(metadata)的数据结构。
- 内容:包括文件大小、所有者、权限、创建/修改时间、链接数、数据块指针等。
- 唯一性:每个文件(或目录)都有且仅有一个 inode,由一个唯一的 inode 号标识。
2. 如何查看 inode?
使用 ls -li 命令可以同时显示文件的 inode 号和详细信息:
[root@localhost linux]# ls -li
total 16
1052669 -rw-rw-r-- 1 whb whb 225 Oct 17 19:09 file1.txt
1052007 -rw-rw-r-- 1 whb whb 488 Oct 17 19:06 file2.c
...第一列数字即为 inode 号。
3. inode 的结构(以 ext2 为例)
struct ext2_inode {
__le16 i_mode; /* 文件类型和权限 */
__le16 i_uid; /* 所有者 UID */
__le32 i_size; /* 文件大小(字节) */
__le32 i_atime; /* 最后访问时间 */
__le32 i_ctime; /* 创建时间 */
__le32 i_mtime; /* 最后修改时间 */
__le32 i_dtime; /* 删除时间 */
__le16 i_gid; /* 所属组 GID */
__le16 i_links_count; /* 硬链接数 */
__le32 i_blocks; /* 占用的块数 */
__le32 i_flags; /* 文件标志 */
union {
struct { ... } linux1;
struct { ... } hurd1;
struct { ... } masix1;
} osd1; /* OS 相关字段 */
__le32 i_block[EXT2_N_BLOCKS]; /* 数据块指针数组 */
__le32 i_generation; /* 文件版本(用于 NFS) */
__le32 i_file_acl; /* 文件 ACL */
__le32 i_dir_acl; /* 目录 ACL */
__le32 i_faddr; /* 碎片地址 */
union {
struct { ... } linux2;
struct { ... } hurd2;
struct { ... } masix2;
} osd2; /* OS 相关字段 */
};⚠️ 重要提醒:
- 文件名不存储在 inode 中,而是存储在目录项(directory entry)里。
- inode 大小通常是 128 字节或 256 字节(现代文件系统如 ext4 默认为 256 字节)。
- 一个 inode 对应一个文件,但一个文件可以有多个文件名(硬链接),它们共享同一个 inode。
三、ext2文件系统
ext2(Second Extended File System)是 Linux 早期广泛使用的文件系统,其设计简洁、高效,至今仍被用于教学和研究。它采用"块组"(Block Group)的组织方式,将磁盘空间划分为多个逻辑单元,每个单元独立管理自己的元数据和数据块,从而提升性能和容错能力。
ext2首先将整个分区划分为若干个大小相等的 Block Group(块组)。每个块组在物理上连续,且内部结构完全相同。这种设计让文件系统可以"分而治之"------管理好一个块组,就能管理所有块组。
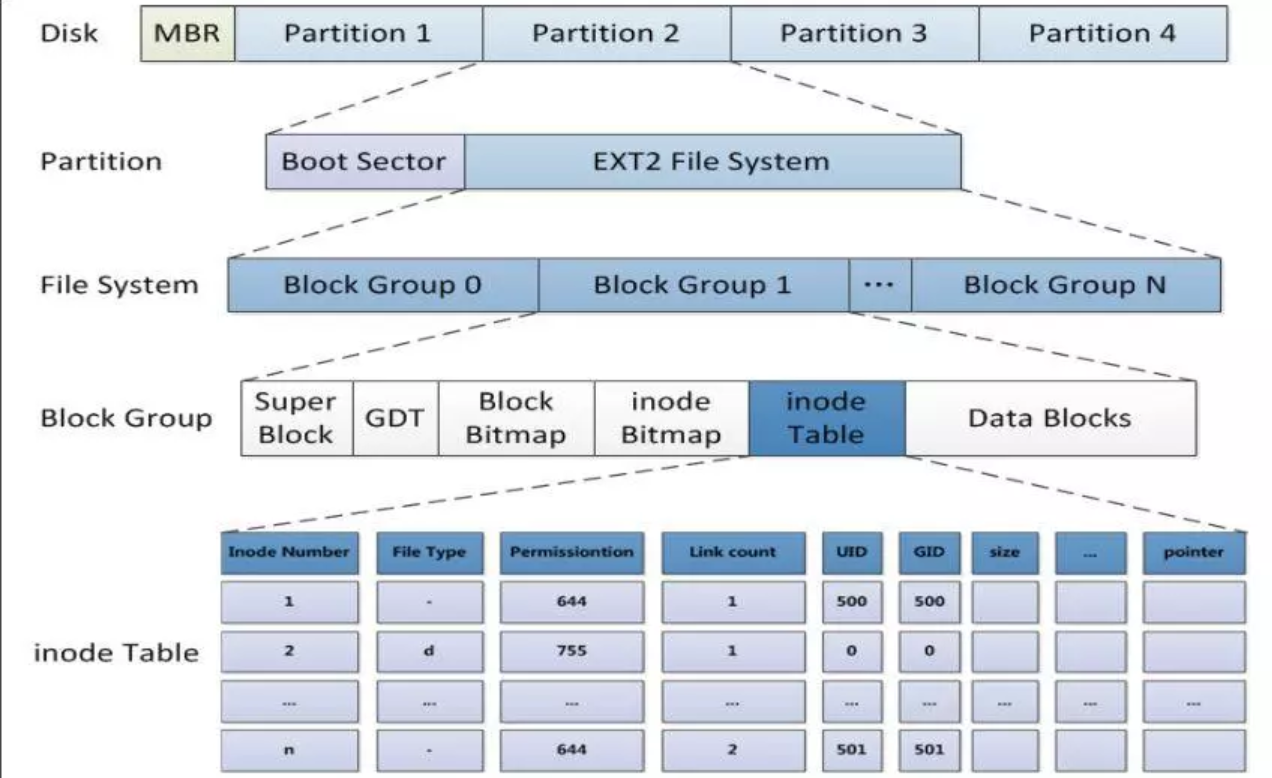
启动块(Boot Sector):大小为固定的1KB,用于存储引导信息。这是PC标准预留的,任何文件系统都不能占用或修改它,所以ext2的实际数据从启动块之后才开始。
1. 超级块(Super Block)
超级块存储的是整个分区级别的信息,例如:
-
block总数、inode总数
-
空闲block/inode数量
-
block大小(通过
s_log_block_size计算) -
每组的block数、inode数
-
挂载次数、最近检查时间、魔数(
0xEF53)等
⚠️ 重要 :超级块一旦损坏,整个文件系统几乎无法挂载。因此,ext2在每个块组的开头都保留一份超级块副本(第一个块组必须要有,后面的可选),以提高容错性。
内核中用 struct ext2_super_block 描述它,字段多达70+,涵盖了从兼容性标志到日志、UUID、卷名等丰富信息。
2. GDT ------ 块组的"户口本"
GDT中每一个 ext2_group_desc 对应一个块组,记录该组的:
-
bg_block_bitmap------ 块位图所在的块号 -
bg_inode_bitmap------ inode位图所在的块号 -
bg_inode_table------ inode表的起始块号 -
空闲block/inode数量、目录数量等
与超级块类似,GDT也在每个块组中保留副本,确保元数据的可靠性。
3. 位图(Bitmap)
位图是高效管理空闲资源的关键。
-
Block Bitmap:每个bit对应一个数据块,1表示已用,0表示空闲。
-
Inode Bitmap:每个bit对应一个inode,标记是否被分配。
分配新文件时,文件系统会先扫描位图找到空闲位置,然后置1,速度极快。
4. inode表 (inode Table)
inode(索引节点)存储文件的元数据,包括:
-
文件大小
-
所有者(UID/GID)
-
权限(rwx)
-
时间戳(创建/修改/访问)
-
数据块指针(指向Data Blocks)
注意:文件名并不在inode中 ,而是存放在目录的数据块里。
inode Table是一个4KB大小的数据块,一个inode大小固定为128字节,所以inode Table会保存32个inode,当文件系统和IO交互的时候直接访问inode Table即32个inode
5. 数据块 (Data Blocks)
数据块根据文件类型存放不同内容:
-
普通文件:直接存放文件二进制内容。
-
目录文件 :存放该目录下的文件名及其对应的inode编号(可用
ls -li查看)。ls -l看到的其他信息(大小、权限等)则来自inode。
这种"目录存名字 + inode存属性 + 数据块存内容"的三层分离,是ext2高效灵活的基础。
6. 其他问题
1. 理解文件系统的载体是分区
文件系统的载体是分区,因为分区是硬盘上被独立划分出来的连续逻辑存储空间,文件系统必须在这个空间上"画"出自己的数据结构(超级块、GDT、位图、inode表、数据块),才能组织和管理文件。
所以数据块和inode是可以跨组编号但是不能跨分区,在同一分区内部inode编号和块号是唯一的
2. 怎么通过inode找到分组和数据块
分组的大小是固定的,inode 编号通过数学运算得到块组号,再通过 GDT 定位到 inode 本体;inode 内部的 15 个指针(直接/间接/双重/三重)层层索引,最终找到存放文件内容的数据块。
四、inode和datablock映射
1. 解剖 inode:不只是属性容器
ext2 的磁盘 inode 结构远比你想象的丰富(见代码片段)。除了我们熟悉的 i_mode(权限)、i_size(大小)、i_atime/i_ctime/i_mtime(时间戳)外,最关键的是那块用于块寻址的数组:
cpp
__le32 i_block[EXT2_N_BLOCKS]; /* Pointers to blocks */EXT2_N_BLOCKS = 15,这 15 个指针构成了 inode 到 data block 的完整映射体系。
2. 15 个指针如何撑起大文件?
这 15 个指针并非全直接指向数据块,而是分层设计的:
| 指针类型 | 数量 | 作用 |
|---|---|---|
| 直接块指针 | 12 | 直接指向存储文件数据的磁盘块 |
| 一级间接块指针 | 1 | 指向一个块,该块内存放更多数据块指针 |
| 二级间接块指针 | 1 | 指向一个块,该块指向多个一级间接块 |
| 三级间接块指针 | 1 | 指向一个块,该块指向多个二级间接块 |
这种多级索引结构,使得 ext2 能够用极小的 inode 开销(默认 128 或 256 字节)管理从几 KB 到几十 GB 的文件。
3. 知道 inode 号,如何在分区中找到它?
这依赖于文件系统格式化时建立的分组管理结构。每个分组包含:
-
Super Block(超级块)
-
Group Descriptor Table(组描述符表)
-
Block Bitmap(块位图)
-
Inode Bitmap(inode 位图)
-
inode 表 和 数据块区
给定 inode 号后,系统按以下步骤定位:
cpp
分组号 = (inode号 - 1) / 每组的inode数
组内偏移 = (inode号 - 1) % 每组的inode数4. 创建一个新文件(touch)背后发生了什么?
以 touch abc 为例,得到的 inode 号为 263466。内核实际执行了 4 个关键动作:
-
存储属性
在 inode 位图中找到一个空闲 inode(263466),将文件的权限、大小、时间等写入该 inode。
-
存储数据
从 block bitmap 中分配 3 个空闲数据块(如 300、500、800),将用户数据依次写入这些块。
-
记录分配情况
将这 3 个块号按顺序填入 inode 的
i_block[]数组中(前 3 个直接块指针)。 -
添加文件名到目录
在当前目录的数据块中新增一条目录项:
(inode=263466, 文件名="abc")。从此,文件名 ↔ inode ↔ 属性 ↔ 数据块 的完整链条就建立了。
5. 增、删、查、改,本质都是 inode 操作
| 操作 | 核心动作 |
|---|---|
| 查(读) | 根据文件名 → 目录项找到 inode → 读取 i_block → 加载数据块 |
| 改(写) | 同上定位 inode,然后修改数据块(可能新分配/释放块) |
| 增(创建) | 分配空闲 inode + 分配空闲块 + 写入目录项 |
| 删(删除) | 从目录项移除文件名,释放 inode 和数据块(标记位图空闲) |
⚠️ 注意:删除文件时,inode 和数据块并不会立即擦除,只是标记为"空闲",这也是数据恢复工具的原理基础。
五、目录和路径
1. 目录的本质:特殊文件与 inode 的关联
在 ext2 文件系统中,目录本身是一种特殊的文件------它不存储"内容",而是存储「文件名 → inode 编号」的映射关系。
- inode(索引节点):是文件系统为每个文件/目录分配的"身份证",记录了文件的元数据(权限、大小、时间戳、数据块指针等)。
- 目录项(dentry) :目录文件中每一行记录,格式为
文件名 + inode 编号。例如执行ls -i时,输出的inode 号 文件名就是目录项的直接体现。
代码视角:遍历目录的逻辑
通过系统调用(如 opendir()、readdir())可以读取目录内容,本质是解析目录文件中的 dentry 结构。示例伪代码如下:
cpp
DIR *dir = opendir("/path/to/dir"); // 打开目录文件
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) { // 逐条读取目录项
printf("文件名: %s, inode: %u\n", entry->d_name, entry->d_ino);
}
closedir(dir); // 关闭目录2. 路径解析:从字符串到 inode 的"寻址"过程
当用户输入 /home/user/test.txt 这样的路径时,内核需要逐层解析路径组件 ,最终定位到目标文件的 inode。这一过程称为路径查找(Path Lookup)。
路径解析的核心步骤
- 起始点确定 :以根目录
/或当前工作目录(CWD)为起点,获取其 inode。 - 逐组件查找 :对路径中每个子目录名(如
home、user),在当前目录的 dentry 列表中匹配文件名,找到对应 inode。 - 类型校验:若当前组件是目录,继续向下解析;若为普通文件,终止查找并返回 inode。
关键数据结构:dentry(目录项缓存)
为了加速路径解析,内核维护了 dentry cache (目录项缓存),用 struct dentry 表示:
struct dentry {
atomic_t d_count; // 引用计数
unsigned int d_flags; // 标志位
struct inode *d_inode; // 指向对应的 inode
struct list_head d_child;// 父目录的子目录链表
struct list_head d_subdirs; // 子目录链表
char d_name[NAME_MAX]; // 文件名
};- 缓存命中:若路径组件的 dentry 已在缓存中,直接复用,避免重复磁盘 I/O。
- 缓存淘汰:采用 LRU(最近最少使用)策略,内存紧张时释放冷数据。
六、挂载
当我们能根据inode号在分区内自由定位文件,能通过目录项找到目标inode时,似乎已在单个分区内"为所欲为"。但一个根本问题始终悬而未决:inode不能跨分区,Linux却支持多个分区,系统怎么知道我该去哪个分区找文件?
1. 从"分区独立"到"全局树"的鸿沟
在Ext2/Ext4等文件系统中,每个分区都拥有自己独立的inode表、数据块和目录树。inode号只在所属分区内唯一,不同分区的inode 1001毫无关联。这意味着:
-
访问
/home/user/a.txt时,系统不能只靠inode号 -
必须首先确定
/home/user这个路径对应哪个分区
2. 实验验证:分区不能"裸用"
cpp
# 创建一个5MB的文件作为模拟分区
$ dd if=/dev/zero of=/tmp/myfs bs=1M count=5
# 格式化为ext4文件系统
$ mkfs.ext4 /tmp/myfs
# 尝试直接读写该"分区文件" ------ 失败!
$ echo "hello" > /tmp/myfs/hello.txt
# 输出:No such file or directory结论 :
分区写入文件系统后,无法直接使用,必须通过挂载(mount)与目录树中的某个目录关联,才能被用户访问。这就好比一块硬盘分区是"孤岛",挂载点是搭建到主大陆的"桥梁"。
3. 挂载的本质:建立"路径前缀 → 分区"的映射
Linux内核维护一张挂载表(mount table),记录了每个挂载点与对应分区的关联:
| 挂载点(目录) | 设备/分区 | 文件系统类型 |
|---|---|---|
/ |
/dev/sda2 |
ext4 |
/home |
/dev/sda3 |
ext4 |
/mnt/usb |
/dev/sdb1 |
vfat |
当访问 /home/user/file.txt 时,内核进行最长前缀匹配:
-
检查路径的每一级前缀:
/→/home→/home/user -
匹配到
/home是挂载点,对应/dev/sda3 -
将路径剩余部分
/user/file.txt交给/dev/sda3分区的文件系统解析 -
在该分区的根目录下找
user目录,再找file.txt
关键认知 :每个分区都有自己独立的根目录(inode号为2),挂载操作本质上是把某个分区的根目录"嫁接"到主目录树的某个节点上。
4. 跨分区访问的完整链路(以 /home/test.log 为例)
cpp
用户态访问 /home/test.log
↓
VFS(虚拟文件系统)层:解析路径
↓
挂载表匹配 → 最长前缀匹配到 /home(挂载点)
↓
找到对应分区 /dev/sda3,读取其超级块
↓
在该分区的根目录(inode 2)下查找 "test.log"
↓
返回该分区的inode号 → 读取数据块重点 :切换分区发生在挂载点边界,一旦进入某个分区,其内部所有路径查找(包括目录项、inode)均局限于该分区,绝不跨区。
七、软硬链接
在 Linux 文件系统中,硬链接 和软链接是两种用于实现"一个文件多个访问路径"的机制,它们在底层原理、使用场景和行为表现上存在本质区别。
1. 硬链接:inode 的多重映射
硬链接的本质是多个文件名指向同一个 inode。这意味着,无论你通过哪个文件名访问文件,操作的都是同一份数据块。例如:
touch abc
ln abc def
ls -li abc def
# 输出:263466 abc 和 263466 def ------ inode 号完全一致- 删除行为:删除一个硬链接文件,只是将该目录项移除,并将 inode 的硬链接计数减 1。只有当计数归零时,系统才会真正释放磁盘空间。
- 限制:硬链接不能跨文件系统创建,也不能对目录创建(防止循环引用)。
- 典型用途 :
.和..就是目录的硬链接;- 用于文件备份或共享,避免重复存储。
2. 软链接:独立文件的"快捷方式"
软链接是一个独立的文件,它拥有自己的 inode,内容仅保存目标文件的路径字符串。例如:
ln -s abc abc.s
ls -li abc.s
# 输出:261678 lrwxrwxrwx ... abc.s -> abc ------ 有独立 inode,类型为符号链接- 行为特征 :
- 删除原文件后,软链接会变成"悬空链接",访问时会报错;
- 可以跨文件系统、可以对目录创建;
- 权限为
lrwxrwxrwx,实际访问权限取决于目标文件。
- 典型用途 :
- 类似 Windows 的快捷方式,用于简化路径或版本管理;
- 程序部署中指向不同版本的库或配置文件。