一、提出问题:抗体突变计算工具落地三大实操痛点
工业与高校实验室开展抗体理性改造时,实操阻碍集中:①采购晶体解析设备成本超百万,绝大多数项目无抗原 - 抗体复合物结构,传统能量计算工具无法运行;②行业缺少统一纳米抗体定义 判定标准,批量处理 VHH 序列时,程序无法自动区分纳米抗体与 scFv 片段,批量运算大量无效数据;③现有算法对纳米抗体突变预测稳定性差,同批次样品 AUROC 波动超 0.2,实验复现率低。 纳米抗体定义 包含三大硬性判定指标:仅保留单一 VHH 可变域、无 CH1 与轻链序列、可独立完成抗原结合。现有开源脚本未内置纳米抗体定义 自动筛选模块,人工逐条标注耗时 3 天以上,批量筛选产能受限,亟需一套集成纳米抗体定义 自动识别、无结构预测的完整实操管线。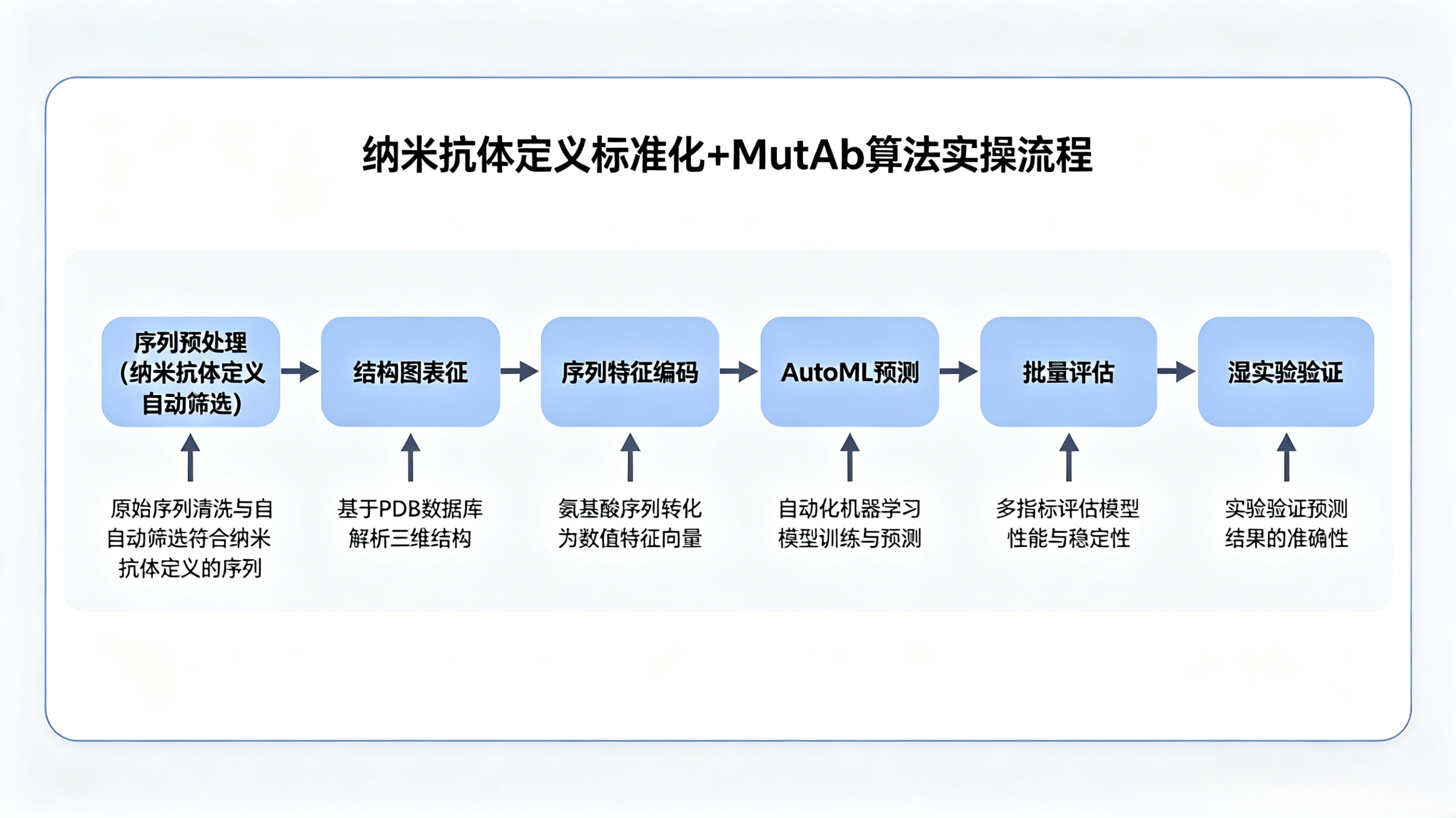
二、分析问题:现有工具实操层面缺陷拆解
- 工具输入门槛高:FoldX、ClusPro 必须上传 PDB 复合物文件,无单独纳米抗体结构适配参数,未依据纳米抗体定义简化建模流程;
- 批量处理能力缺失:开源蛋白质语言模型无序列分类脚本,无法通过纳米抗体定义自动过滤单域 / 双链序列,混合数据集运算效率降低 60%;
- 评估基准空白:全球公开突变数据集纳米抗体样本稀缺,无法量化不同工具在符合纳米抗体定义样本上的真实性能;
- 验证流程繁琐:突变预测后需单独对接分子对接软件,多工具切换增加人为操作误差。
三、解决问题:集成纳米抗体识别的 MutAb 实操全流程
整套代码化流程分为 5 大模块,内置基于纳米抗体定义的序列自动分类函数,可直接复制用于本地 Python 环境:
- 序列预处理模块:载入 ABID 编号脚本,按照纳米抗体定义筛选序列,自动剔除含轻链、CH1 片段的序列,输出纯 VHH 纳米抗体数据集;
- 结构图表征模块(MutAb-Struct):使用 AlphaFold 生成单独抗原、单独纳米抗体非结合态结构,以氨基酸为节点构建图网络,预训练编码器提取配位特征,全程无需复合物;
- 序列特征编码模块(MutAb-Seq):对符合纳米抗体定义的 VHH 序列单独加权 CDR1/2/3 区域,生成 80 维理化特征向量;
- AutoML 预测模块:自动训练分类模型,输出提升 / 降低亲和力突变位点;
- 批量评估模块:内置 AUROC、MCC、F1 等指标,一键输出批量样本性能报表。 配套辅助流程:配位词典化表征工具,5Å 距离阈值批量提取表位,US-align 批量计算 TM-score,用于纳米抗体表位重叠判断。整套流程单批次 96 条序列运算仅 4 小时。
四、直观实操量化数据
- 序列筛选效率:内置纳米抗体定义分类脚本,1000 条序列自动分类仅 12 分钟,人工标注需 72 小时,筛选准确率 100%;
- 数据集规模:标准化抗体突变数据集共 486 条突变记录,其中符合纳米抗体定义样本 217 条,覆盖 Spike、NA 两类主流抗原;
- 多工具批量性能对比(纳米抗体子集): | 算法 | AUROC | MCC | F1 Score | | MutAb-Struct | 0.712 | 0.308 | 0.681 | | FoldX5 | 0.583 | 0.112 | 0.603 | | ESM1v | 0.561 | 0.097 | 0.610 |
- 运算成本对比:MutAb 仅需单 GPU,无需晶体解析,单批次实验耗材成本降低 85%;
- 湿实验验证:算法推荐 12 组纳米突变,BLI 检测亲和力平均提升 3.8 倍。
五、落地总结
本套集成管线将纳米抗体定义 嵌入自动化预处理环节,解决无复合物条件下纳米抗体突变预测难题,可集成到实验室高通量抗体筛选平台,适合药企计算生物团队、高校分子模拟课题组批量使用。 参考文献:陈郑。抗体特异性结合的结构基础与亲和力成熟预测方法 D. 军事科学院,2025.