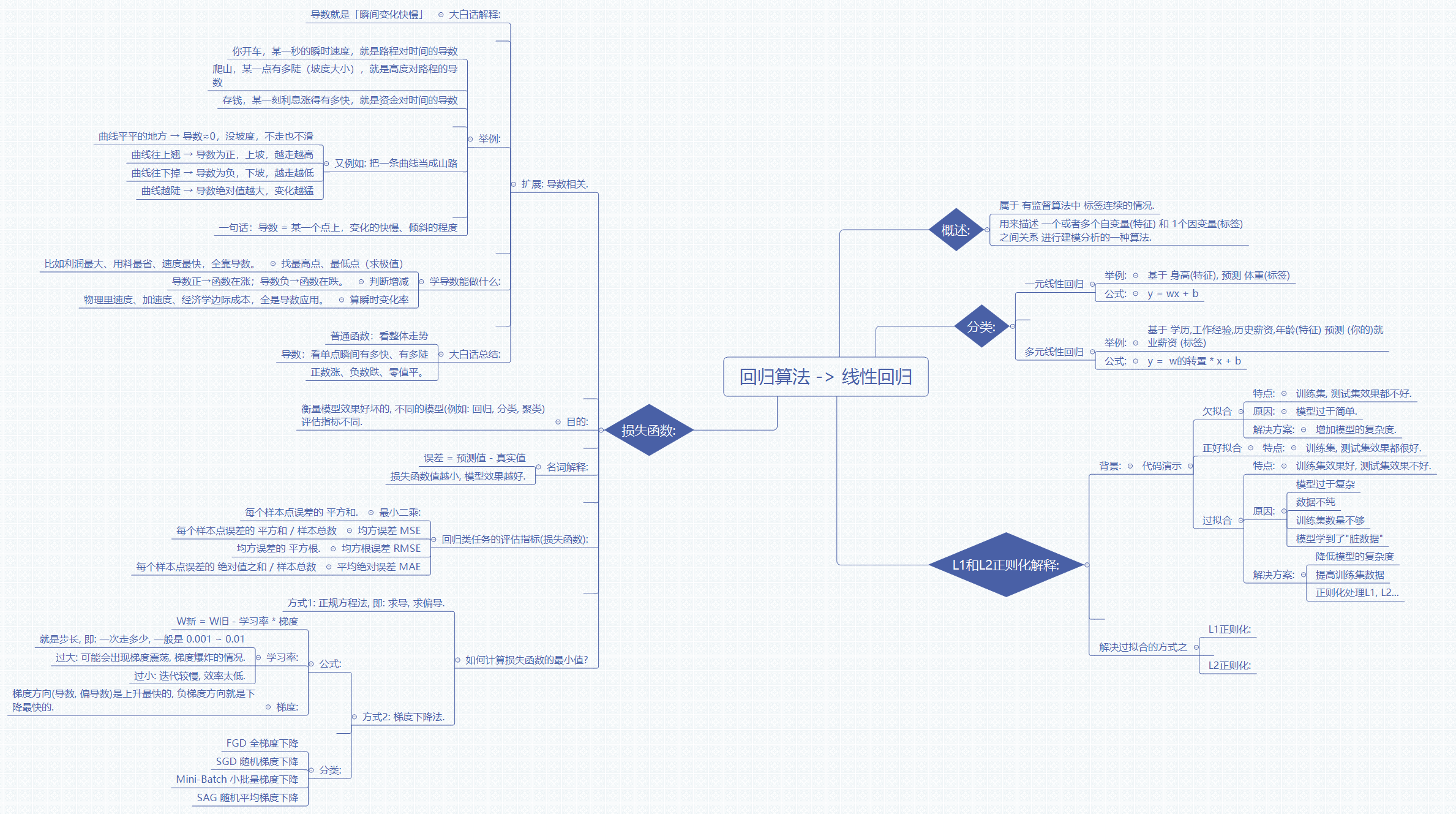
承接上一篇机器学习算法分类的内容,有监督学习包含回归与分类两大任务方向。线性回归是回归算法中最基础、应用最广泛的算法之一,也是理解后续复杂算法的重要基石。它通过拟合特征与标签之间的线性关系,实现对连续值的预测,在量化分析、趋势预测、因素分析等场景中具备不可替代的价值。本篇将从算法定义、损失函数、求解方法、正则化优化四个维度,系统讲解线性回归的核心原理。
一、线性回归算法概述
1.1 算法定义
线性回归属于有监督学习中标签为连续值的场景,核心是建立一个或多个自变量(特征)与因变量(标签)之间的线性映射关系,通过拟合数据的分布规律实现对未知样本的预测。
其核心假设是特征与标签之间存在线性相关关系,模型通过学习得到各特征对应的权重系数,最终以线性加权的方式输出预测结果。
1.2 算法分类
根据输入特征的数量,线性回归分为两类:
- 一元线性回归:仅包含一个特征变量,表达式为 y = wx + b。其中 w 为权重系数,b 为截距项。典型场景如通过身高特征预测体重标签。
- 多元线性回归:包含多个特征变量,表达式为 y = w^T · x + b,其中 w 为权重向量,每个维度对应一个特征的权重。典型场景如通过学历、工作经验、历史薪资等多个特征预测就业薪资。
二、损失函数与回归评估指标
2.1 损失函数的作用
模型训练的目标是让预测值尽可能接近真实值,损失函数就是衡量模型拟合效果的量化指标。不同算法任务对应不同的评估体系,回归、分类、聚类任务各有适配的损失计算方式。
对于线性回归,单样本误差定义为预测值与真实值的差值,整体损失函数值越小,代表模型拟合效果越好。
2.2 核心评估指标
回归任务的评估指标均基于样本误差计算,主流包含三类:
- 均方误差(MSE):计算所有样本误差的平方和后取均值,对应最小二乘法的核心思想。平方操作会放大较大的误差,对异常值更敏感,且函数处处可导,便于梯度求解,是线性回归最常用的损失函数。
- 均方根误差(RMSE):均方误差的平方根,量纲与原始标签一致,更便于直观理解误差的实际大小。
- 平均绝对误差(MAE):计算所有样本误差的绝对值之和后取均值。对异常值的敏感度低于均方误差,鲁棒性更强,但在零点处不可导,不便于直接作为梯度下降的损失函数。
三、导数与梯度的核心原理
求解损失函数的最小值,是线性回归训练的核心目标,而导数与梯度是优化求解的数学基础。
3.1 导数的物理意义
导数描述的是函数在某一点上的瞬时变化率,也可以理解为曲线在该点的倾斜程度。
- 曲线平缓处导数为 0,对应函数的极值点(极大值或极小值);
- 函数递增区间导数为正,递减区间导数为负;
- 导数的绝对值越大,代表函数在该点的变化越剧烈。
在工程场景中,利润最大化、成本最小化、速度极值等最优值求解问题,物理中的速度与加速度推导,经济学中的边际成本计算,本质都是导数的应用。
3.2 梯度与优化方向
单变量函数的变化率由标量导数描述,多变量函数则对应梯度向量。梯度的方向是函数在该点上升最快的方向;反之,负梯度方向就是函数下降最快的方向。
梯度下降法的核心逻辑,就是沿着负梯度方向不断迭代调整参数,逐步逼近损失函数的最小值点。
四、损失函数的最小化求解
线性回归的参数求解有两类主流方法:正规方程法与梯度下降法,分别适配不同的数据规模与应用场景。
4.1 正规方程法
正规方程法也叫最小二乘解析解法,通过对损失函数求偏导并令偏导数为零,直接推导得到最优参数的闭式解。其矩阵形式表达式为:θ = (X^T X)^{-1} X^T y。
- 优势:无需迭代,一次计算即可得到最优解,无需调试学习率等超参数,在小规模低维数据集上效率很高。
- 劣势:计算过程涉及矩阵求逆,当特征维度很高(通常超过一万维)时,计算复杂度会急剧上升;且当特征存在多重共线性时,矩阵不可逆,无法直接求解。
4.2 梯度下降法
梯度下降法是迭代式的优化方法,通过不断沿着负梯度方向更新参数,逐步降低损失函数值,最终收敛到最小值。
参数更新的核心公式为:新权重 = 旧权重 - 学习率 × 梯度。
其中学习率是关键超参数,代表每次迭代的步长:
- 学习率过大:容易出现梯度震荡,甚至越过最小值点导致发散,无法收敛;
- 学习率过小:迭代收敛速度慢,训练效率低,容易陷入局部最优。
工业界常用的学习率取值范围一般在 0.001 到 0.01 之间,需根据具体场景调试。
根据每次迭代使用的样本量,梯度下降分为多个变种:
- 全批量梯度下降(BGD):每次迭代使用全部样本计算梯度,下降方向稳定,收敛路径平滑,但大规模数据集下训练速度很慢。
- 随机梯度下降(SGD):每次迭代随机选取一个样本计算梯度,更新速度快,内存占用低,但方向波动大,收敛过程震荡明显。
- 小批量梯度下降(Mini-Batch):每次选取一小批样本计算梯度,兼顾了收敛速度与稳定性,是工业界最常用的实现方式。
- 随机平均梯度下降(SAG):通过维护历史梯度的平均值降低随机波动,在保留随机梯度下降效率的同时提升收敛稳定性。
五、L1 与 L2 正则化
5.1 正则化的背景
线性回归模型如果复杂度过高、训练数据不足或数据存在噪声,很容易出现过拟合现象:模型在训练集上表现优异,但在测试集上效果大幅下降,泛化能力差。
正则化是解决过拟合的核心手段之一,通过在损失函数中加入对参数的惩罚项,限制参数的规模,避免模型过度拟合训练数据中的噪声。
5.2 L1 正则化
L1 正则化对应 Lasso 回归,惩罚项为权重参数的绝对值之和。
- 核心特性:会使得部分权重参数收敛到 0,天然具备特征选择的能力,能够自动筛选出对结果影响显著的特征,适用于特征维度较高、需要做特征筛选的场景。
5.3 L2 正则化
L2 正则化对应岭回归(Ridge),惩罚项为权重参数的平方和。
- 核心特性:会均匀压缩所有参数的大小,避免单个特征权重过高,提升模型的稳定性与泛化能力。L2 正则化计算更简便,收敛更稳定,是工业界更常用的正则化方式。
六、逻辑图