目录
[循环神经网络与 Transformer](#循环神经网络与 Transformer)
神经网络是什么
神经网络(简称:ANN)是一种受人脑神经元连接方式启发而设计的机器学习模型,它通过大量相互连接的"神经元"来处理数据、提取特征并完成预测或判断。
简单来说,神经网络会接收输入数据,例如图片、文字、声音或数字信息,然后经过一层或多层隐藏层的计算,把原始数据逐步转换成更有意义的特征,最后在输出层给出结果。它并不是依靠人手动编写固定规则来解决问题,而是通过大量样本数据进行训练,在不断比较预测结果和真实答案的差距后,自动调整内部的权重和偏置,使模型的预测越来越准确。因此,神经网络特别适合处理复杂、难以用传统规则描述的问题,比如图像识别、语音识别、自然语言处理、推荐系统和自动驾驶等。可以把神经网络理解为一种能够从数据中学习规律的数学模型,它的核心能力就是通过训练发现输入和输出之间隐藏的关系。
神经网络主要由输入层,隐藏层以及输出层构成,当隐藏层只有一层的时候,该网络为两层神经网络,由于输出层未做任何变换,可以不用单独看成一层。隐藏层层数以及隐藏层神经元是由人工设定。一个基本的两层神经网络可见下图。
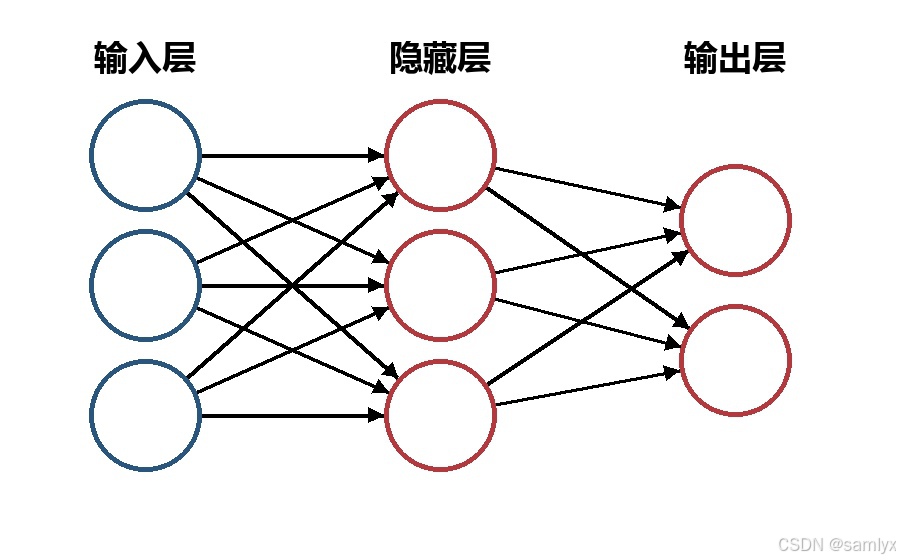 神经网络结构图
神经网络结构图
神经元模型
神经元是神经网络中最基本的计算单元,可以理解为模型中的一个小型处理器,它负责接收来自上一层的数据输入,并对这些输入进行加权计算,再加上一个偏置项,最后通过激活函数得到输出结果。每个输入都会对应一个权重,权重表示这个输入对最终结果的重要程度,偏置则用于调整整体计算结果,使模型更加灵活。
神经元的计算过程通常可以表示为先进行线性运算,也就是把各个输入与对应权重相乘后相加,再加上偏置,当某个神经元接收了足够多的神经递质,那么其点位变会积累地足够高,从而超过某个阈值, 超过这个阈值之后,这个神经元变会被激活 ,达到兴奋的状态,而后发送神经递质给其他的**神经元,**就会经过激活函数转换成输出值。可以说,神经元虽然本身结构简单,但它是构成整个神经网络的基础,神经网络强大的学习能力正是由大量神经元协同工作产生的。下图是MP神经元模型。
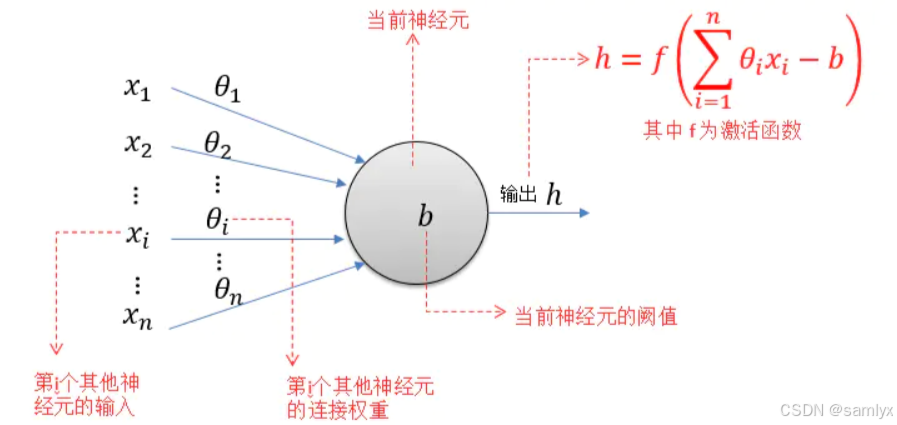 MP神经元模型
MP神经元模型
MP神经元模型 接收来自n个其他神经元传递过来的输入信号(x1~xn),这些输入信号通过带权重(θ来表示权重)的连接进行传递,然后神经元(图示阈值为b)收到的总输入(所有输入和权重的乘积的和)与神经元的阈值b比较,并经由激活函数处理之后产生神经元的输出。理想情况下输出有0或1 两种,0 表示神经元不兴奋,1 则表示神经元兴奋。因此对于激活函数的选择通常会选择Sigmoid 函数。通过把很多个神经单元 按照一定的层次连接起来,便得到了一个神经网络。
感知机
感知机是最早的一种人工神经网络模型,也可以看作是单个神经元的经典形式,它主要用于解决简单的二分类问题。感知机会接收多个输入特征,并为每个特征分配一个权重,然后将输入与权重相乘后求和,再加上偏置项,最后判断输出结果属于哪一类。如果计算结果超过设定阈值,感知机就输出一类;如果没有超过阈值,就输出另一类。
它的学习过程就是根据预测结果和真实标签之间的差异,不断调整权重和偏置,使分类结果逐渐变得准确。感知机结构简单、思想直观,是理解神经元和神经网络的重要基础,但它只能处理线性可分的问题,对于复杂的非线性问题能力有限,因此后来发展出了多层神经网络和更复杂的深度学习模型。
神经网络目标函数
神经网络的目标函数,也叫损失函数或代价函数,是用来衡量模型预测结果与真实标签之间差距的数学表达式,它是神经网络训练过程中最核心的部分之一。在训练时,神经网络的目标就是不断调整权重和偏置,使目标函数的值尽可能小,因为目标函数值越小,说明模型的预测越接近真实答案。不同的任务会使用不同的目标函数,例如在分类任务中,常用的目标函数是交叉熵损失 ,它衡量的是模型预测的概率分布与真实标签分布之间的差异;在回归任务中,常用的目标函数是均方误差,它计算的是预测值与真实值之间差值的平方的平均值。目标函数的值会随着训练的进行而逐渐下降,如果目标函数不再下降或者开始上升,可能意味着模型已经收敛或者出现了过拟合。可以说,目标函数就是神经网络学习过程中的"指南针",它告诉模型当前预测有多糟糕,以及应该朝哪个方向改进。
交叉熵损失函数
交叉熵损失函数是神经网络中处理分类任务时最常用的目标函数之一,它用来衡量模型预测的概率分布与真实标签分布之间的差异。其核心思想是:当模型预测的概率越接近真实类别,损失值就越小;反之,当预测结果与真实答案相差越大,损失值就会迅速变大,从而错误预测。
在二分类任务中,交叉熵损失通常写作 ,其中
是真实标签,取值为 0 或 1,a 是模型预测样本属于类别 1 的概率;如果真实标签是 1,损失主要由
决定,预测概率越接近 1,损失越小;如果真实标签是 0,损失则主要由
决定,预测概率越接近 0,损失越小。具体细节可以跳转机器学习-逻辑回归-CSDN博客
在多分类任务中,交叉熵损失会扩展为对所有类别求和的形式,通常与 Softmax 函数搭配使用SoftMax函数-CSDN博客,让输出层输出每个类别的概率分布。交叉熵损失之所以被广泛使用,是因为它不仅能反映预测与真实之间的差距,还具有良好的梯度性质,能够让模型在训练时更新得更稳定、更高效,从而帮助神经网络快速收敛到较优的参数。
神经网络优化算法
神经网络与普通的分类器不同,其是一个巨大的网络,最后一层的输出与每一层的神经元都有关系。而神经网络的每一层,与下一层之间,都存在一个参数矩阵。我们需要通过优化算法求出每一层的参数矩阵,对于一个有 K 层的神经网络,我们共需要求解出 K−1 个参数矩阵。因此我们无法直接对目标函数进行梯度的计算来求解参数矩阵。
对于神经网络的优化算法,主要需要两步:前向传播 与反向传播。
前向传播
前向传播是神经网络进行预测的核心过程,它指的是数据从输入层进入网络,依次经过每一层隐藏层的计算,最终在输出层得到预测结果的信息流动方向。具体来说,前向传播时,每个神经元会先接收来自上一层所有神经元的输出,然后将这些输入与对应的权重相乘后求和,再加上偏置项,得到一个线性组合结果,接着这个结果会经过激活函数进行非线性变换,产生该神经元的输出值,并传递给下一层的神经元。这个过程从输入层开始,逐层向后推进,直到输出层给出最终的预测值。
前向传播的本质是神经网络根据当前已经学习到的参数,对输入数据进行计算和变换,从而得到一个输出。在训练阶段,前向传播完成后,模型会将预测结果与真实标签进行比较,计算出损失函数的值。以下述例子来看:
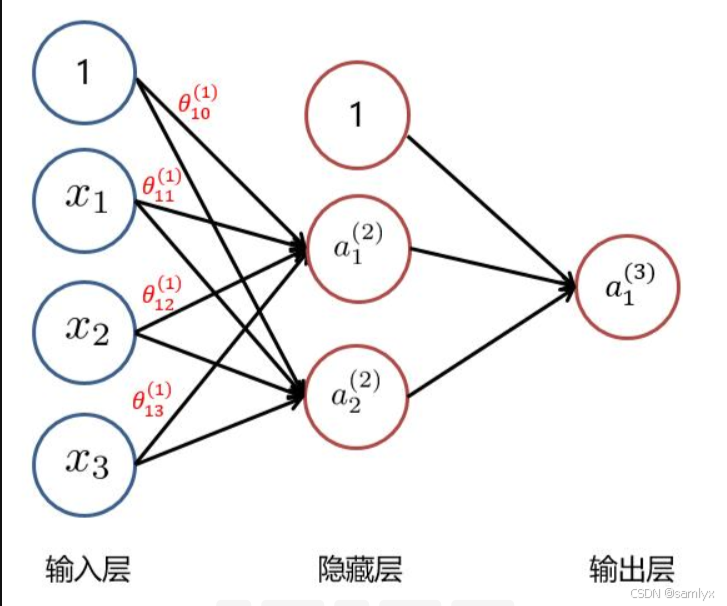 神经网络传播模型
神经网络传播模型
输入层最上面的节点标记为 1,这个节点叫做偏置单元 ,它并不是真实的数据特征,而是为了简化偏置项的数学表达而人为添加的一个特殊节点。如果不加这个偏置单元,隐藏层神经元的计算需要写成:,其中
b 是偏置项,需要单独处理。为了把偏置也统一纳入矩阵乘法,我们引入了一个技巧:在输入层额外添加一个恒等于 1 的节点 ,然后让这个节点也连接到隐藏层的每个神经元,对应的权重就是偏置值。这样计算就变成,其中
w₀ 就是原来的偏置 b。现在所有参数都变成了权重,可以用统一的矩阵乘法来计算,不再需要单独处理偏置项。
这里 我们使用  来表示第 k 层 的参数,其中下标j 表示第 k+1 层 的第 j 个神经元 ,i 表示第 k 层 的第 i 个神经元。
来表示第 k 层 的参数,其中下标j 表示第 k+1 层 的第 j 个神经元 ,i 表示第 k 层 的第 i 个神经元。
同样的隐藏层最上面的节点也标记为 1,这和输入层的 1 是完全相同的原理。
接下来为了好理解我将使用具体例子来进行计算:
输入数据:
| 节点 | 值 |
|---|---|
| 偏置单元 | 1 |
| x₁ | 2 |
| x₂ | 3 |
| x₃ | 1 |
输入层到隐藏层的权重:
| 权重 | 值 | 含义 |
|---|---|---|
| θ₁₀⁽¹⁾ | 0.5 | 偏置单元 → a₁⁽²⁾ |
| θ₁₁⁽¹⁾ | 1.0 | x₁ → a₁⁽²⁾ |
| θ₁₂⁽¹⁾ | 2.0 | x₂ → a₁⁽²⁾ |
| θ₁₃⁽¹⁾ | 3.0 | x₃ → a₁⁽²⁾ |
| θ₂₀⁽¹⁾ | -0.5 | 偏置单元 → a₂⁽²⁾ |
| θ₂₁⁽¹⁾ | -1.0 | x₁ → a₂⁽²⁾ |
| θ₂₂⁽¹⁾ | 0.5 | x₂ → a₂⁽²⁾ |
| θ₂₃⁽¹⁾ | 1.5 | x₃ → a₂⁽²⁾ |
隐藏层到输出层的权重:
| 权重 | 值 | 含义 |
|---|---|---|
| θ₁₀⁽²⁾ | 0.3 | 偏置单元 → a₁⁽³⁾ |
| θ₁₁⁽²⁾ | 1.5 | a₁⁽²⁾ → a₁⁽³⁾ |
| θ₁₂⁽²⁾ | -2.0 | a₂⁽²⁾ → a₁⁽³⁾ |
计算隐藏层第一个神经元 a₁⁽²⁾:,得到结果为:
,再经过激活函数(sigmoid)
,结果≈
计算隐藏层第二个神经元a₂⁽²⁾:,得到结果为:
,再经过激活函数(sigmoid)
,结果≈
最后计算输出层a₁⁽³⁾:现在隐藏层的输出 [1, a₁⁽²⁾, a₂⁽²⁾] = [1, 0.999989, 0.622459] 作为输出层的输入,,得到结果≈
,再经过激活函数(sigmoid)
,结果≈
。表示模型预测该样本属于类别 1 的概率约为 63.52%
- 如果这是一个二分类问题,阈值设为 0.5,那么预测结果为 类别 1
- 如果真实标签是 1,说明预测方向正确,但还有优化空间
- 如果真实标签是 0,说明预测错误,需要通过反向传播调整权重
计算过程只是为了更直白看到正向传播过程,如果具体使用代码实现推荐使用向量化,计算更快。
首先随机初始化参数矩阵 :
:


再计算隐藏层的每个神经元激活值:


即:

最后计算输出层的每个神经元激活值:

即:

反向传播
反向传播是神经网络训练过程中最核心的算法,它的作用是在前向传播计算出预测结果和损失之后,从输出层开始逐层向输入层方向计算每个参数对总损失的贡献程度,也就是计算损失函数对每个权重和偏置的梯度,从而为后续的参数更新提供方向。具体来说,反向传播首先会计算输出层的误差,也就是预测值与真实标签之间的差距,然后根据链式法则把这个误差逐层向前传递,计算每一层每个神经元的误差项,最后利用这些误差项计算出每一层权重矩阵的梯度。链式法则是反向传播的数学基础,它允许我们把复杂的复合函数求导分解成多个简单步骤的乘积,从而高效地计算每一层的梯度。
在计算过程中,输出层的误差直接由损失函数对输出的导数得到,而隐藏层的误差则需要结合下一层的误差和当前层到下一层的权重来计算,这就是为什么误差是从后向前传递的。当所有层的梯度都计算完成后,就可以使用梯度下降算法来更新权重,让损失函数的值逐渐减小,模型的预测能力逐步提升。反向传播和前向传播是神经网络训练中不可分割的两个部分,前向传播负责生成预测,反向传播负责找到改进方向,两者交替进行,直到模型收敛。
在介绍反向传播的计算步骤之前,我们先引入一个概念:除输入层外 每个神经元节点的损失 , 表示第k 层第j 个神经元的损失。输出层的误差
表示第k 层第j 个神经元的损失。输出层的误差 δ₁⁽³⁾ 是损失函数对输出层线性组合 z₁⁽³⁾ 的导数。对于 Sigmoid 激活函数配合交叉熵损失函数,这个导数有一个非常简洁的形式:,假设真实标签
y = 1,而之前计算的 a₁⁽³⁾ = 0.635310:
δ₁⁽³⁾ = 0.635310 - 1 = -0.364690这个误差表示预测值比真实值小了,需要增大输出。隐藏层的误差不能直接计算,需要通过输出层的误差反向传递得到。核心公式是,其中 ⊙ 表示逐元素相乘。
对于 Sigmoid 函数,导数有一个很好的性质,这意味着我们不需要额外计算导数,直接用前向传播得到的激活值就能算出来,所以计算隐藏层误差:
,
a₁⁽²⁾ 非常接近 1,所以它的导数非常小,接近于 0。这说明第一个隐藏层神经元已经"饱和"了,它的输出对误差的敏感度很低。
先取出去掉偏置列的部分(即第 2 列和第 3 列),然后转置:
,
,
,
再与输出层误差相乘:
,
,第一个隐藏层神经元几乎不产生误差信号,因为它已经饱和了,第二个隐藏层神经元承担了大部分误差,需要重点调整。
有了各层的误差,就可以计算损失函数对每个权重的梯度了,输出层权重梯度:
,其中 Ab(2) 是隐藏层添加偏置单元后的输出:
,所以计算过程如下:
,
接下来是隐藏层的权重梯度:
,计算过程如下:
,
梯度下降的更新公式为:,假设学习率 α=0.1。
,
,
下图是更新前后的对比:
| 权重 | 更新前 | 更新后 | 变化方向 |
|---|---|---|---|
| θ10(2) | 0.3 | 0.336469 | 增大(偏置调高) |
| θ11(2) | 1.5 | 1.536469 | 增大(a1(2) 权重提高) |
| θ12(2) | -2.0 | -1.977301 | 增大(a2(2) 负权重减弱) |
| θ20(1) | -0.5 | -0.517141 | 减小 |
| θ21(1) | -1.0 | -1.034282 | 减小 |
| θ22(1) | 0.5 | 0.448578 | 减小 |
| θ23(1) | 1.5 | 1.482859 | 减小 |
可以把反向传播想象成"追责"的过程:
- 输出层被追责:预测值 0.635310 和真实值 1 差了 0.365,这个差距就是输出层的"责任"
- 责任向下分配:输出层把责任按照权重比例分配给隐藏层的两个神经元,第二个神经元分到了大部分责任(0.171),第一个几乎没分到(因为它已经饱和了)
- 继续向下追责:隐藏层的神经元再把责任分配给输入层的各个特征
- 根据责任调整:每个权重根据自己承担的责任大小进行调整,责任大的调得多,责任小的调得少
经过成千上万次这样的"追责"和调整,模型的预测就会越来越准确。
常见模型
卷积神经网络(CNN)
卷积神经网络是一种专门用来处理具有网格结构数据的神经网络,最常见的应用就是图像识别。你可以把一张图片想象成由很多小方块组成的矩阵,每个小方块就是一个像素点,而卷积神经网络的核心思想就是用一个叫做卷积核的小窗口在图片上滑动,每次只看图片的一小块区域,提取这一小块区域的特征,比如边缘、纹理、颜色等,然后通过多层卷积逐步组合这些简单特征,最终形成对整张图片的理解。这种局部感受野的设计让卷积神经网络能够高效地处理高维图像数据,同时参数数量比全连接网络少得多,因为它不需要每个像素都连接到每个神经元,而是共享同一个卷积核的权重。随着网络层数加深,前面几层可能只检测到线条和边缘,中间层能识别出眼睛、鼻子等局部部件,最后几层则能组合出完整的物体概念,比如人脸或汽车。卷积神经网络在图像分类、目标检测、人脸识别、医学影像分析等领域都取得了巨大成功,是现代计算机视觉的基础。
循环神经网络与 Transformer
循环神经网络是一种专门用来处理序列数据的神经网络,比如一句话、一段语音或者股票价格的时间序列,它的特点是网络内部存在循环连接,使得信息可以在时间步之间传递,从而让模型具有记忆能力,能够理解上下文关系。你可以把循环神经网络想象成一个人在读一本书,每读到一个新词时,他都会结合之前读到的内容来理解当前这个词的含义,而不是孤立地看待每个词。循环神经网络的核心是一个隐藏状态,这个状态会随着每个时间步的输入不断更新,既包含了当前输入的信息,也保留了之前所有输入的历史信息。不过传统的循环神经网络存在长期依赖问题,当序列很长时,早期的信息容易被遗忘,因此后来发展出了长短期记忆网络和门控循环单元等改进版本,通过引入门控机制来控制信息的流动,让模型能够更好地记住重要信息、忘记无关信息。循环神经网络在自然语言处理、语音识别、机器翻译、音乐生成等任务中都有广泛应用,是处理时序数据的重要工具。
Transformer 是一种完全基于注意力机制的神经网络架构,它彻底改变了自然语言处理领域,也是现在大语言模型如 ChatGPT 的核心基础。与循环神经网络逐词处理序列不同,Transformer 可以一次性看到整个输入序列的所有位置,然后通过注意力机制计算每个位置与其他所有位置之间的关联程度,从而直接捕捉长距离依赖关系。你可以把注意力机制理解为在阅读一篇文章时,不是按顺序逐字阅读,而是能够一眼扫过全文,然后自动把注意力集中在与当前理解最相关的那些词上,比如看到"他"时,模型会自动关联到前面提到的具体人名。Transformer 由编码器和解码器两部分组成,编码器负责理解输入内容,解码器负责生成输出内容,两者都大量使用自注意力层和前馈神经网络层。由于 Transformer 摒弃了循环结构,可以高度并行化计算,训练速度比循环神经网络快很多,同时能够处理更长的序列,这使得它成为现代自然语言处理、机器翻译、文本生成等任务的首选架构,并且其影响力已经扩展到图像、音频等其他领域。
实例展示
NumPy 实现双层神经网络
python
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def sigmoid_derivative(a):
return a * (1 - a)
def relu(z):
return np.maximum(0, z)
def relu_derivative(z):
return (z > 0).astype(float)
def initialize_parameters(n_x, n_h, n_y):
np.random.seed(1)
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
return {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
def forward_propagation(X, parameters):
W1, b1 = parameters["W1"], parameters["b1"]
W2, b2 = parameters["W2"], parameters["b2"]
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
cache = {"Z1": Z1, "A1": A1, "Z2": Z2, "A2": A2}
return A2, cache
def compute_cost(A2, Y):
m = Y.shape[1]
cost = -1/m * np.sum(Y * np.log(A2) + (1-Y) * np.log(1-A2))
return np.squeeze(cost)
def backward_propagation(parameters, cache, X, Y):
m = X.shape[1]
W2 = parameters["W2"]
A1, A2 = cache["A1"], cache["A2"]
dZ2 = A2 - Y
dW2 = 1/m * np.dot(dZ2, A1.T)
db2 = 1/m * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.dot(W2.T, dZ2) * relu_derivative(cache["Z1"])
dW1 = 1/m * np.dot(dZ1, X.T)
db1 = 1/m * np.sum(dZ1, axis=1, keepdims=True)
return {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
def update_parameters(parameters, grads, learning_rate=0.01):
for key in parameters:
parameters[key] -= learning_rate * grads["d" + key]
return parameters
def nn_model(X, Y, n_h=4, num_iterations=10000, learning_rate=0.01):
n_x, n_y = X.shape[0], Y.shape[0]
parameters = initialize_parameters(n_x, n_h, n_y)
for i in range(num_iterations):
A2, cache = forward_propagation(X, parameters)
cost = compute_cost(A2, Y)
grads = backward_propagation(parameters, cache, X, Y)
parameters = update_parameters(parameters, grads, learning_rate)
if i % 1000 == 0:
print(f"Cost after iteration {i}: {cost:.6f}")
return parameters
# 使用示例
# X = np.random.randn(2, 100)
# Y = np.random.randint(0, 2, (1, 100))
# params = nn_model(X, Y, n_h=4)PyTorch 实现 MNIST 手写数字识别
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义网络结构
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
# 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 初始化
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = NeuralNetwork().to(device)
criterion = nn.CrossEntropyLoss() # 内部包含 SoftMax
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练
def train(epochs=5):
model.train()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch: {epoch}, Batch: {batch_idx}, Loss: {loss.item():.6f}')
# 训练模型
# train()PyTorch 实现卷积神经网络(CNN)
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.dropout = nn.Dropout(0.25)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 28x28 -> 14x14
x = self.pool(F.relu(self.conv2(x))) # 14x14 -> 7x7
x = x.view(-1, 64 * 7 * 7) # 展平
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# 使用方式与上面的 PyTorch 示例相同
# model = CNN().to(device)
# criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model.parameters(), lr=0.001)PyTorch 实现 Transformer 编码器
python
import torch
import torch.nn as nn
import math
class TransformerEncoder(nn.Module):
def __init__(self, d_model=512, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.pos_encoder = PositionalEncoding(d_model, dropout)
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
self.d_model = d_model
def forward(self, src, src_mask=None):
src = self.pos_encoder(src)
output = self.transformer_encoder(src, src_mask)
return output
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
# 使用示例
# model = TransformerEncoder(d_model=512, nhead=8, num_layers=6)
# src = torch.randn(32, 100, 512) # batch=32, seq_len=100, d_model=512
# output = model(src)