目录
[1. 企业管理案例表](#1. 企业管理案例表)
[2. 单表查询的局限性](#2. 单表查询的局限性)
[1. 基本原理与笛卡尔积](#1. 基本原理与笛卡尔积)
[2. 连接条件](#2. 连接条件)
[3. 跨表实战案例](#3. 跨表实战案例)
[1. 为员工表追加字段](#1. 为员工表追加字段)
[2. 自连接概念及原理](#2. 自连接概念及原理)
[3. 自连接使用案例](#3. 自连接使用案例)
[1. 定义与执行过程](#1. 定义与执行过程)
[2. 子查询与多表查询](#2. 子查询与多表查询)
[3. 单行子查询的特征与操作符](#3. 单行子查询的特征与操作符)
[4. 单行子查询案例](#4. 单行子查询案例)
[4.1 基于动态基准线的范围筛选](#4.1 基于动态基准线的范围筛选)
[4.2 利用等值子查询取代显式跨表](#4.2 利用等值子查询取代显式跨表)
[5. 注意事项](#5. 注意事项)
[1. 多行操作符及其运算逻辑](#1. 多行操作符及其运算逻辑)
[2. 多行子查询案例](#2. 多行子查询案例)
[2.1 IN 操作符案例](#2.1 IN 操作符案例)
[2.2 ANY 操作符案例](#2.2 ANY 操作符案例)
[2.3 ALL 操作符案例](#2.3 ALL 操作符案例)
[3. NOT IN 的空值问题](#3. NOT IN 的空值问题)
[六、多列子查询与 FROM 中的子查询](#六、多列子查询与 FROM 中的子查询)
[1. 多列子查询的概念](#1. 多列子查询的概念)
[2. 多列子查询案例](#2. 多列子查询案例)
[3. FROM 子句中的子查询](#3. FROM 子句中的子查询)
[4. 派生表使用案例](#4. 派生表使用案例)
[1. 合并查询概念](#1. 合并查询概念)
[2. UNION 与 UNION ALL](#2. UNION 与 UNION ALL)
[3. 合并查询案例](#3. 合并查询案例)
[3.1 使用 UNION ALL 进行无差异堆叠](#3.1 使用 UNION ALL 进行无差异堆叠)
[3.2 使用 UNION 进行去重规整](#3.2 使用 UNION 进行去重规整)
[4. 注意事项](#4. 注意事项)
[实战OJ:获取所有非 manager 的员工 emp_no](#实战OJ:获取所有非 manager 的员工 emp_no)
一、为什么需要复合查询
在之前的学习中,我们所有的操作,都建立在单张表的维度上。无论是过滤、排序,还是分组聚合,我们始终没有跳出那张特定的表
但在现实项目中,根据数据库设计的三范式规范,为了消除数据冗余、防止插入异常,数据会被拆分到不同的专业表里
这就带来了一个巨大的矛盾:高内聚的业务数据被物理拆分,而跨领域的商业决策又需要全局视图。 要打破单表查询的局限,我们必须掌握复合查询
1. 企业管理案例表
为了更好地演示查询效果,本文采用全新的案例表:
sql
-- 1. 创建部门表
CREATE TABLE dept (
dept_id INT PRIMARY KEY COMMENT '部门名称ID',
dept_name VARCHAR(50) NOT NULL COMMENT '部门名称',
location VARCHAR(100) COMMENT '办公地点'
) COMMENT '部门信息表';
-- 2. 创建员工表
CREATE TABLE emp (
emp_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '员工工号',
name VARCHAR(50) NOT NULL COMMENT '姓名',
age INT COMMENT '年龄',
job_title VARCHAR(50) COMMENT '职位名称',
salary DECIMAL(10, 2) COMMENT '月薪',
dept_id INT COMMENT '所属部门ID'
) COMMENT '员工信息表';
-- 3. 插入基础演示数据
INSERT INTO dept VALUES
(101, '研发部', '北京·中关村'),
(102, '市场部', '上海·陆家嘴'),
(103, '财务部', '深圳·南山区'),
(104, '暂缺人员部', '广州·天河区');
INSERT INTO emp (name, age, job_title, salary, dept_id) VALUES
('齐天大圣', 32, '架构师', 35000.00, 101),
('天蓬元帅', 35, '产品经理', 22000.00, 101),
('卷帘大将', 29, '后端开发', 16000.00, 101),
('金蝉子', 40, '市场总监', 28000.00, 102),
('白龙马', 25, '市场专员', 10000.00, 102),
('高翠兰', 27, '财务会计', 12000.00, 103),
('神秘萌新', 22, '实习生', 4500.00, NULL); -- 注意:该员工暂无部门2. 单表查询的局限性
假设有一个非常简单的报表需求:把所有员工的姓名、薪资 以及所在部门的办公地点取出
当你打开 emp 表时,你会发现一个问题:emp 表里虽然有名字和薪资,但关于办公地点,只有 dept_id(如 101)。具体的地点存放在 dept 表里
如果坚持用单表查询,你的后端程序就必须:
-
先查出 emp 表的记录
-
提取出 dept_id,在后端写一个 for 循环。
-
循环内部不断调用 SELECT * FROM dept WHERE dept_id = ... 语句
警惕循环查库引发的 N + 1 问题
循环查库是导致线上系统性能崩溃的典型反模式。这种在循环体内频繁查询数据库的操作会产生以下严重后果:
- 产生大量网络I/O请求
- 快速耗尽数据库连接池资源
- 造成显著的查询性能劣化
什么是复合查询
复合查询 是指将多张表的数据、或者多次查询的结果,在数据库内部通过多表联查 、嵌套子查询、集合合并等,合并为一个单一的结果集返回给上层应用
它让数据搬运和组装的工作完全闭环在数据库底层,是编写高效、高并发系统必不可少的硬核技能
二、多表查询
多表查询是构建复杂查询的基础操作。当我们需要同时查询两张表时,若不了解其底层执行机制,极易导致数据量呈指数级爆炸现象
1. 基本原理与笛卡尔积
如果我们不做任何约束,只是单纯地在 FROM 后面排布两张表,会发生什么?
sql
SELECT * FROM emp, dept;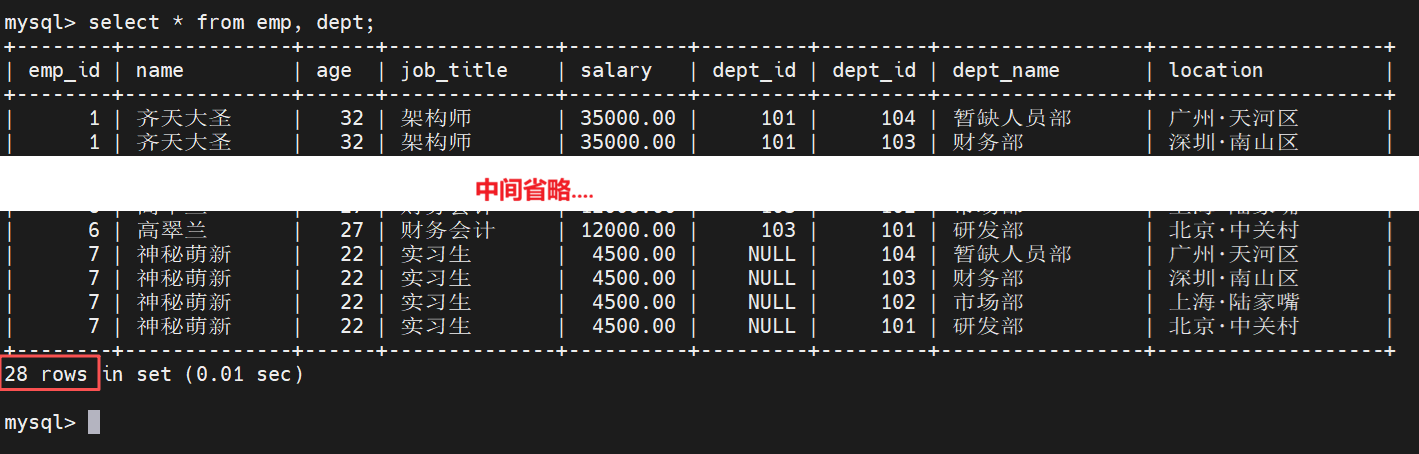
可以看到,原本只有 7 个员工、4 个部门,最终却吐出了 28 条 记录
什么是笛卡尔积
这是关系型数据库在进行多表操作时的底层物理实现机制。在没有任何过滤条件的前提下,MySQL 会将第一张表(emp)中的每一行记录,无差别地与第二张表(dept)中的每一行记录进行交叉组合
- 最终产出的行数 = emp 表的行数 (7) * 表的行数 (4) = 28 行
在这 28 条数据中,包含了大量诸如 "研发部的架构师 齐天大圣 坐在 财务部(深圳·南山区)" 这种完全牛头不对马嘴的垃圾数据
2. 连接条件
为了在笛卡尔积中筛选出有价值的正确行,我们必须加上连接条件(即告诉 MySQL,只有当员工的 dept_id 与 部门的 dept_id 完全对得上时,这行组合才有效)
sql
-- 利用 WHERE 显式指定连接条件
SELECT emp.name, emp.salary, dept.dept_name, dept.location
FROM emp, dept
WHERE emp.dept_id = dept.dept_id;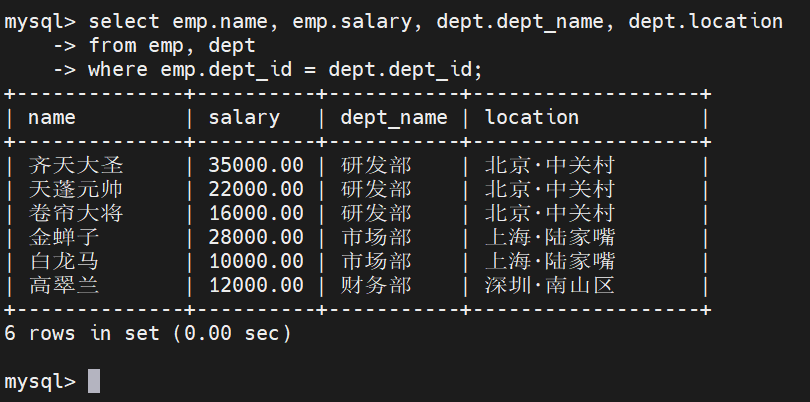
-
过滤机制: 此时,MySQL 相当于在 28 行的笛卡尔积中进行过滤,只有
emp.dept_id = dept.dept_id 的 6 条记录被保留了下来
-
那个没有部门的 "神秘萌新"(dept_id 为 NULL),以及没有人的 "暂缺人员部"(dept_id 为 104),因为无法触发等号成立,在最终的结果集中被排除掉了
3. 跨表实战案例
在写多表查询时,由于不同表可能会有相同的列名(如 dept_id),为了防止系统混淆,强烈建议为表起别名,让代码变得更加严密
跨表多维过滤
业务需求: 找出研发部里,月薪高于 20000 元的员工姓名、职位以及他们的办公地点
sql
SELECT
e.name AS 员工姓名,
e.job_title AS 职位,
e.salary AS 月薪,
d.dept_name AS 部门,
d.location AS 办公地点
FROM emp AS e, dept AS d -- 1. 在这里为表定义简短的别名 e 和 d
WHERE e.dept_id = d.dept_id -- 2. 铁律:先写连接条件,干掉笛卡尔积
AND d.dept_name = '研发部' -- 3. 业务过滤条件A
AND e.salary > 20000.00; -- 4. 业务过滤条件B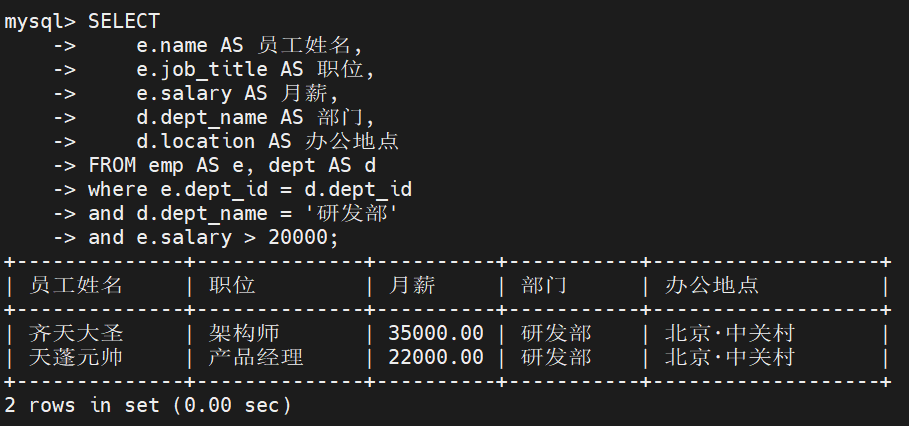
案例总结
-
别名铁律: 一旦在 FROM 子句中为表指定了别名(如 FROM emp AS e),那么在整个 SELECT、WHERE、ORDER BY 子句中,必须全部强制换用别名 e,如果再用原名 emp.name,MySQL 会抛出 Unknown column 错误
-
连接条件数量: 如果你同时联查 N 张表,WHERE 子句中至少需要包含 N-1 个有效的连接条件。比如查 3 张表,就必须有两个 A.id = B.id AND B.uid = C.uid 链接
三、自连接
在多表查询时,我们通常习惯在 FROM 子句中关联不同的数据表。然而,某些看似需要跨表查询的关系数据,其实就隐藏在单张表的内部结构中
例如:社交平台中的 "用户 A 推荐了用户 B ",企业架构里的 "员工 A 向员工 B 汇报"。这种表内数据间的自引用关系,就需要运用复合查询中的自连接来实现高效查询
1. 为员工表追加字段
为了让接下来的案例足够真实,我们注意到刚才建立的 emp 表里虽然有职位和薪资,但并没有体现出谁是谁的上级
在切入正题前,我们先为 emp 追加一个 manager_id(上级工号)字段,并重构公司的汇报线:
sql
-- 1. 追加上级工号字段
ALTER TABLE emp ADD manager_id INT COMMENT '直属上级工号';
-- 2. 重构汇报线(齐天大圣和金蝉子是核心管理层,没有上级)
-- 让 齐天大圣(1) 成为 天蓬元帅(2) 和 卷帘大将(3) 的直属上级
UPDATE emp SET manager_id = 1 WHERE emp_id IN (2, 3);
-- 让 金蝉子(4) 成为 白龙马(5) 的直属上级
UPDATE emp SET manager_id = 4 WHERE emp_id = 5;2. 自连接概念及原理
什么是自连接
自连接并不是 MySQL 物理层面的新语法,它是一种逻辑设计借位 。它是指一张表自己与自己进行连接查询
自连接实现原理
面对同一张表,MySQL 怎么进行交叉对比?答案全靠起别名
我们可以通过起两个完全不同的别名,在内存中强行把这一张物理表克隆出两张虚拟表。一张充当员工表(worker),另一张充当领导表(boss)
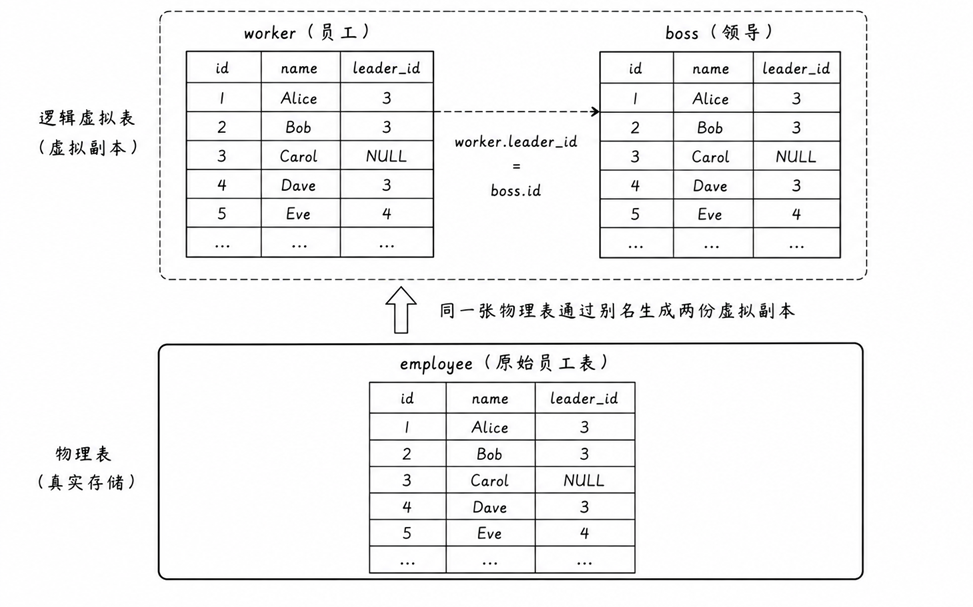
使用别名
在跨表查询中,别名通常用于简化代码;而在自连接时,别名则不可或缺
如果不加别名,直接写:
sql
SELECT * FROM emp, emp WHERE emp.manager_id = emp.emp_id;
MySQL 抛出 Not unique table/alias: 'emp' 报错。因为在同一个作用域下出现了两个一模一样的表名,查询优化器根本无法分清等号左边的 emp 和右边的 emp
3. 自连接使用案例
业务需求: 运营部需要导出一份 "公司组织架构汇报关系白皮书",要求展示:员工的姓名、职位,以及对应的直属上级的姓名和职位
拆解推导公式
-
我们将 emp 虚拟化为两张表:w(代表员工)和 b(代表老板)
-
寻找连接:员工的 "上级工号" 必须等于老板的 "员工工号" 。
即:w.manager_id = b.emp_id
sql
-- 标准自连接解法
SELECT
w.name AS 员工姓名,
w.job_title AS 员工职位,
b.name AS 直属上级,
b.job_title AS 上级职位
FROM emp AS w, emp AS b -- 核心:同一张表,起两个不同的别名
WHERE w.manager_id = b.emp_id; -- 连接条件:员工的上级ID = 老板的个人ID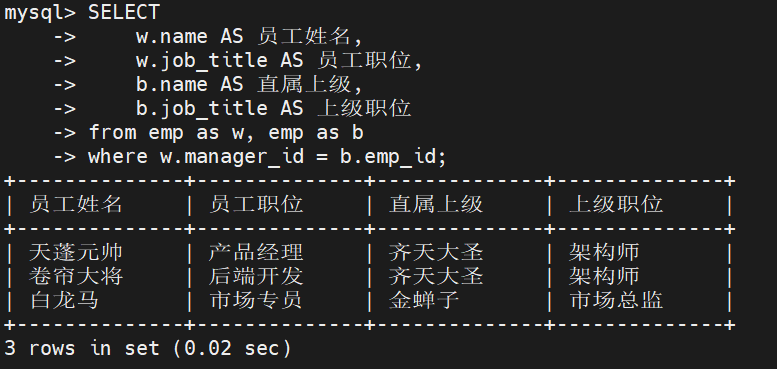
结果分析
不难发现最终的结果集里只有 3 条记录
-
在查询结果中,manager_id 为 NULL 的 "齐天大圣" 和 "金蝉子" 由于无法匹配等值条件,未被包含在内
-
对于没有下属的员工,因为无人视其为上级,在右侧的 "直属上级" 列中也不会显示
在多表联合查询中,这种因等值条件不成立而导致 NULL 值行被自动过滤的连接方式被称为内连接。自连接同样遵循这一底层特性
四、子查询概述与单行子查询
在处理多表之间的关联数据时,除了显式地使用连接查询之外,另一种重要且的组合手段是子查询
本段将合并解析子查询的基础运行原理,并探讨最基础的子查询形态------单行子查询
1. 定义与执行过程
什么是子查询
子查询是指嵌套在其他 SQL 语句内部的 SELECT 查询语句。在 SQL 标准中,子查询也被称为内层查询,而包含它的外部查询语句则被称为外层查询或主查询
子查询的本质是:利用内层查询生成的中间计算结果,作为外层查询的过滤条件或数据源
子查询的执行过程
在最常见的独立子查询中,MySQL 的执行引擎通常遵循自内向外的执行序列:
-
首先执行: 剥离出最内层的子查询语句,在数据库中独立运行
-
生成结果: 内层查询执行完毕后,在内存中产生一个临时的数据结果(可能是一个数值、一列数据或一张虚拟表)
-
替代传参: 将该结果作为常量或条件,替换掉外层查询中的嵌套部分
-
最后执行: 外层主查询接收参数后,执行最终的数据检索
2. 子查询与多表查询
在开发过程中,很多业务需求既可以通过多表联查实现,也可以通过子查询实现。理解它们之间的技术边界有助于写出更优的代码
-
子查询的优势(可读性与解耦): 子查询的逻辑非常符合业务思维。它将一个复杂的、跨表的大问题拆解为 "先查出 A,再根据 A 查 B" 的串行步骤,代码结构分明,不需要显式管理表与表之间的笛卡尔积
-
多表查询的优势(执行效率): 现代关系型数据库的查询优化器对 JOIN 的优化非常成熟(如支持 Hash Join 或 Index Nested-Loop Join)。在数据量极大的情况下,连接查询往往比部分未经优化的嵌套子查询具备更好的性能表现
3. 单行子查询的特征与操作符
什么是单行子查询
单行子查询是指内层子查询的执行结果有且仅返回 "一行一列" 单个标量值
例如,查询 "公司里最高薪资是多少",该查询只会返回一个具体的数值(如 35000.00),这种子查询就属于单行子查询
适用的比较操作符
由于内层只返回一个绝对值,因此外层主查询的 WHERE 子句中可以使用标准的数学比较操作符进行等值或范围判定:
| 操作符 | 含义 | 操作符 | 含义 |
|---|---|---|---|
| = | 等于 | > | 大于 |
| >= | 大于等于 | < | 小于 |
| <= | 小于等于 | <> 或 != | 不等于 |
4. 单行子查询案例
下面我们基于现有的 emp 表与 dept 表,通过两个标准的行政与财务审批需求,演练单行子查询的编写规范
4.1 基于动态基准线的范围筛选
业务需求: 人力资源部需要筛选出公司里哪些员工的月薪高于全公司的平均月薪,并输出这些员工的姓名、职位和薪资
步骤拆解
-
内层查询(寻找基准线): 先算出全公司的平均薪资
sqlSELECT AVG(salary) FROM emp; -
外层查询(范围过滤): 筛选出薪资大于该平均值的员工
完整嵌套
sql
SELECT name, job_title, salary
FROM emp
WHERE salary > (SELECT AVG(salary) FROM emp); -- 嵌套单行子查询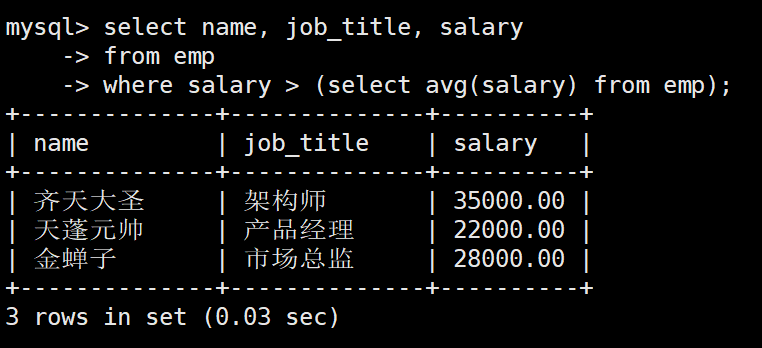
4.2 利用等值子查询取代显式跨表
业务需求: 财务部需要调整薪资,要求查询所有与 "天蓬元帅" 处于同一个部门的员工详细信息
步骤拆解
-
内层查询: 获取天蓬元帅的 dept_id
sqlSELECT dept_id FROM emp WHERE name = '天蓬元帅'; -- 执行结果为 101 -
外层查询: 寻找所有 dept_id = 101 的员工
完整嵌套
sql
SELECT emp_id, name, job_title, dept_id
FROM emp
WHERE dept_id = (SELECT dept_id FROM emp WHERE name = '天蓬元帅');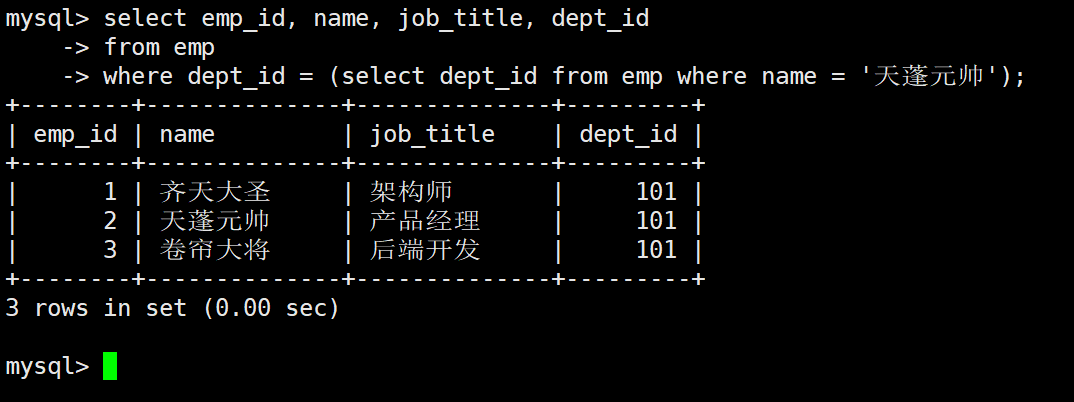
5. 注意事项
在编写单行子查询时,必须确保内层查询的返回结果在逻辑上永远是 "单一稳定" 的,否则会引发以下两种常见的运行期错误:
子查询无匹配数据返回
如果子查询的 WHERE 条件未匹配到任何数据,子查询会返回 NULL
sql
-- 错误示范:由于找不到名为'灭霸'的员工,内层返回 NULL,导致外层最终查不到任何数据
SELECT * FROM emp WHERE dept_id = (SELECT dept_id FROM emp WHERE name = '灭霸');内层返回了多行数据
这是最容易犯的语法错误。单行比较操作符(如 =)的右侧绝对不允许出现多行数据
sql
-- 错误示范:如果研发部(101)里有多名员工,内层会返回多个薪资值
SELECT * FROM emp WHERE salary = (SELECT salary FROM emp WHERE dept_id = 101);-
系统响应: MySQL 会直接中断执行,抛出明确的错误拦截

-
解决方案: 面对内层返回多行结果的场景,必须升级使用下一章将要讲解的多行子查询操作符(如 IN、ANY、ALL)
五、多行子查询
在上一章中,我们探讨了内层查询仅返回 "一行一列" 标量值的单行子查询。然而在实际业务中,内层查询返回的结果往往是一个包含多个数值的集合(即 "多行一列")
当内层结果的基数由 "单个值" 演变为 "结果集" 时,外层主查询若继续使用 =、> 等单行比较操作符,数据库将会抛出语法错误。此时,必须引入专门处理集合关系的选择器------多行子查询操作符
1. 多行操作符及其运算逻辑
MySQL 提供了三个核心的多行操作符:IN、ANY 以及 ALL。它们专门用于处理外层字段与内层集合之间的逻辑包含关系
| 操作符 | 语法形态 | 核心逻辑释义 | 等价替换关系 |
|---|---|---|---|
| IN | WHERE column IN (子查询) | 主查询的字段值只要存在于子查询的结果集中,即判定为真 | 等价于多个 = 条件通过 OR 相互连接 |
| ANY | WHERE column <ANY (子查询) | 主查询的字段值只要与子查询集合中的任意一个值满足比较关系,即判定为真 | > ANY 大于集合的最小值; < ANY 小于集合的最大值 |
| ALL | WHERE column > ALL (子查询) | 主查询的字段值必须与子查询集合中的所有值都满足比较关系,方可判定为真 | > ALL 大于集合的最大值; < ALL 小于集合的最小值 |
备注:SOME 关键字在 MySQL 中的运算行为与 ANY 完全一致,二者可以互换使用
2. 多行子查询案例
下面沿用 emp 表与 dept 表,通过具体的行政与财务统计场景,解析这三个操作符的规范写法
2.1 IN 操作符案例
业务需求: 运营管理层需要获取属于研发部或市场部的所有员工的姓名、职位及其所属部门 ID
-
内层查询(动态获取部门 ID 集合):
sqlSELECT dept_id FROM dept WHERE dept_name IN ('研发部', '市场部'); -- 执行结果返回集合: {101, 102} -
**外层主查询:**利用 IN 匹配上述集合
sql
SELECT name, job_title, dept_id
FROM emp
WHERE dept_id IN (
SELECT dept_id
FROM dept
WHERE dept_name IN ('研发部', '市场部')
);执行结果:
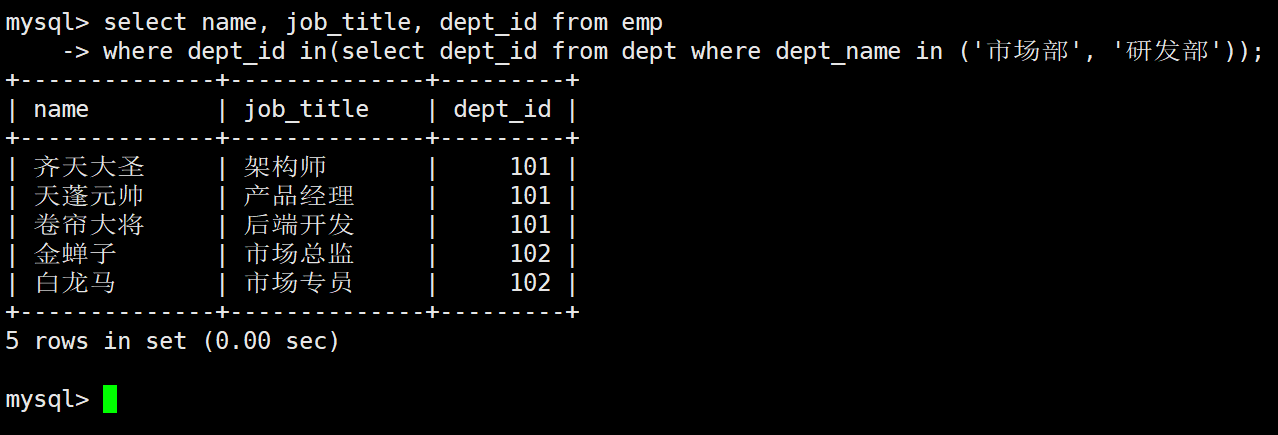
2.2 ANY 操作符案例
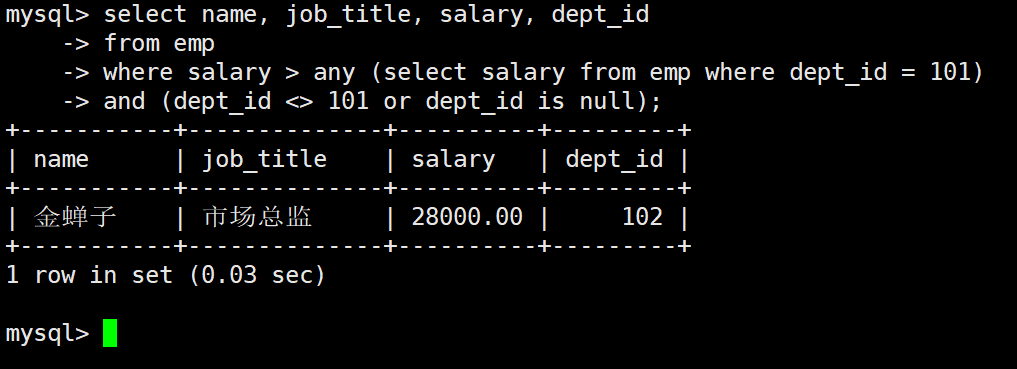
业务需求: 人力资源部需要查出所有非研发部 成员中,薪资高于研发部任意一名员工的员工信息
-
内层查询(获取研发部的薪资集合):
sqlSELECT salary FROM emp WHERE dept_id = 101; -- 执行结果返回集合: {35000.00, 22000.00, 16000.00} -
外层主查询: 条件设定为 > ANY (35000, 22000, 16000)。只要大于其中的最小值,该行数据即符合条件
sql
SELECT name, job_title, salary, dept_id
FROM emp
WHERE salary > ANY (
SELECT salary
FROM emp
WHERE dept_id = 101
)
AND (dept_id <> 101 OR dept_id IS NULL); -- 排除研发部自身及无部门人员的干扰执行结果:
2.3 ALL 操作符案例
业务需求: 财务部需要评估低薪资区间的员工分布,要求查询薪资低于研发部所有员工的非研发部员工信息
-
内层查询(获取研发部的薪资集合):
sqlSELECT salary FROM emp WHERE dept_id = 101; -- 执行结果返回集合: {35000.00, 22000.00, 16000.00} -
外层主查询: 条件设定为 < ALL (35000, 22000, 16000)。主查询的薪资必须低于该集合中的绝对最小值(16000.00)才能被检索出来
sql
SELECT name, job_title, salary, dept_id
FROM emp
WHERE salary < ALL (
SELECT salary
FROM emp
WHERE dept_id = 101
)
AND (dept_id <> 101 OR dept_id IS NULL);执行结果:
sql
SELECT * FROM dept
WHERE dept_id NOT IN (SELECT dept_id FROM emp);3. NOT IN 的空值问题
在多行子查询中,NOT IN 操作符隐藏着一个隐蔽且致命的漏洞。一旦子查询的结果集中包含一个 NULL 值,整个外层查询将会导致全面失效(即返回空结果集)
漏洞复现
假设有一项业务需要找出目前没有员工所属的部门。编写的 SQL 如下:
sql
SELECT * FROM dept
WHERE dept_id NOT IN (SELECT dept_id FROM emp);在我们的样本数据中,emp 表包含一条 "神秘萌新" 的数据,其 dept_id 为 NULL。此时,上层的 SQL 在底层会被优化器展开为类似如下的逻辑
sql
SELECT * FROM dept
WHERE dept_id <> 101
AND dept_id <> 102
AND dept_id <> 103
AND dept_id <> NULL; -- 关键漏洞点逻辑失效原理
在 SQL 标准中,任何运算与 NULL 进行逻辑比较(如 dept_id <> NULL),其结果既不是 TRUE 也不是 FALSE,而是 UNKNOWN。 由于 AND 运算符要求所有子条件必须同时为 TRUE,因此只要末尾混入了 AND UNKNOWN,整个 WHERE 子句的最终判定结果将锁定为 FALSE。这会导致数据库无法吐出任何一行数据
解决方案
面对 NOT IN 场景,必须在内层子查询中显式地剔除 NULL 值的干扰,以确保外层集合比对的严密性:
sql
SELECT * FROM dept
WHERE dept_id NOT IN (
SELECT dept_id
FROM emp
WHERE dept_id IS NOT NULL -- 强制过滤空值
);六、多列子查询与 FROM 中的子查询
在前述章节中,我们接触的子查询不论返回单行还是多行,其投影的核心都在于单列数据。然而在错综复杂的数据校验中,过滤条件往往需要多个维度(多列)同时精确匹配。此外,子查询不仅可以嵌套在 WHERE 子句中作为过滤器,还能直接嵌入 FROM 子句中扮演 "临时虚拟表" 的角色
1. 多列子查询的概念
多列子查询是指内层子查询的 SELECT 列表中包含了多个字段。对应地,外层主查询的 WHERE 子句中也必须使用括号将多个对应的列强行捆绑,与内层返回的数据结构进行矩阵式的等值或范围匹配
其语法形态通常表现为:
sql
WHERE (column1, column2, ...) = (SELECT col1, col2, ... FROM ...)
-- 或者配合多行操作符
WHERE (column1, column2, ...) IN (SELECT col1, col2, ... FROM ...)2. 多列子查询案例
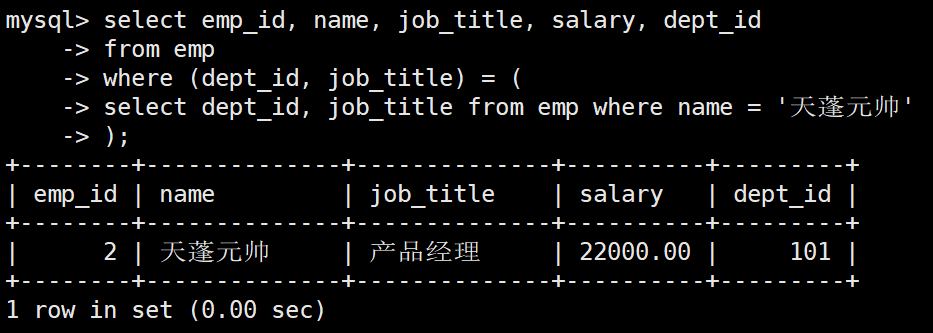
业务需求: 公司进行岗位合规性审查,需要找出与 "天蓬元帅" 处于同一个部门且职位完全相同的所有员工的详细信息(包含天蓬元帅本人)
1) 传统拆解做法(多层嵌套)
如果不使用多列子查询,通常需要编写两个独立的单列子查询,并用 AND 逻辑运算符进行拼接:
sql
-- 传统做法:代码较长,且需要扫描两次索引/表
SELECT * FROM emp
WHERE dept_id = (SELECT dept_id FROM emp WHERE name = '天蓬元帅')
AND job_title = (SELECT job_title FROM emp WHERE name = '天蓬元帅');2) 高阶多列组合写法
利用多列子查询,可以让代码在逻辑上具备极高的凝聚力,数据库优化器也只需对内层目标数据进行一次精准捕获:
sql
SELECT emp_id, name, job_title, salary, dept_id
FROM emp
WHERE (dept_id, job_title) = (
SELECT dept_id, job_title
FROM emp
WHERE name = '天蓬元帅'
);执行结果:
思维扩展: 如果全公司有多个叫 "天蓬元帅" 的员工或者需要匹配多名员工,只需将中间的 = 操作符改为 IN,多列子查询依然能够稳健地进行批量矩阵匹配
3. FROM 子句中的子查询
派生表的概念与运行本质
在 SQL 的标准执行生命周期中,FROM 关键字后面紧跟的并不一定非要是实体表。任何一个合法的 SELECT 查询结果集,在逻辑上都是一个由行和列构成的二维关系矩阵
当我们将一个子查询放置于 FROM 子句中时,MySQL 会将该子查询的临时输出结果当作一张局部的虚拟表来对待。在数据库理论中,这种由子查询动态生成的、仅在当前 SQL 语句生命周期内有效的虚拟表,被称为派生表
派生表的使用原则:必须为派生表明确指定别名
在 FROM 子句中使用子查询时,存在一条绝对原则:必须为派生表指定一个唯一的表别名
如果你编写了如下 SQL:
sql
SELECT * FROM (SELECT emp_id, name FROM emp WHERE dept_id = 101);MySQL 会直接报错:Error Code: 1248. Every derived table must have its own alias
**原因分析:**外部的主查询需要通过 "表名.列名" 的路径来检索和引用字段。如果没有别名,外部查询的 SELECT 和 WHERE 子句将失去物理定位
4. 派生表使用案例
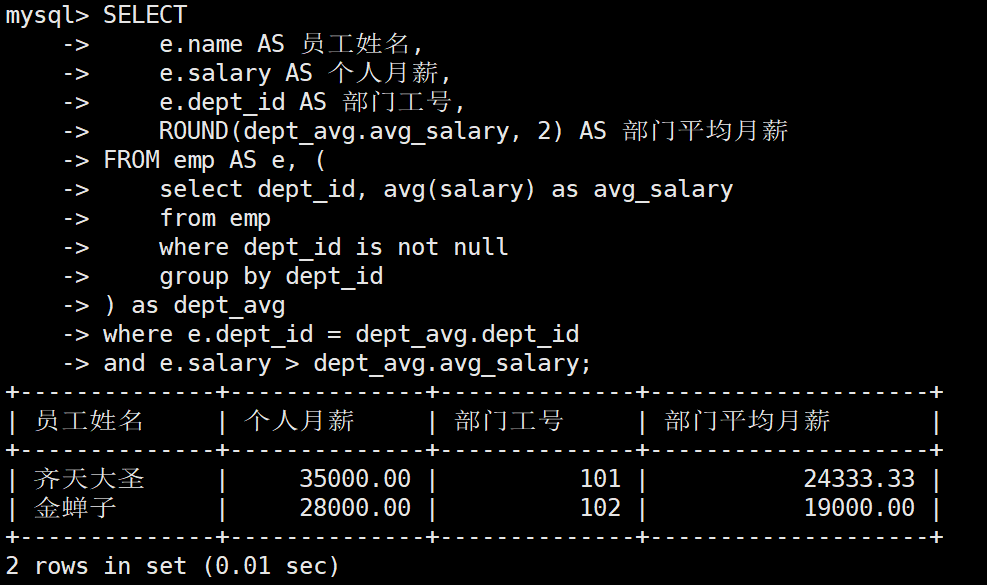
业务需求: 财务部需要进行跨部门薪资架构分析,要求找出公司里哪些员工的个人月薪高于其所在部门的平均月薪
1) 核心痛点与思维阻碍
我们往往会本能地尝试编写如下的错误 SQL:
sql
SELECT name, salary, dept_id FROM emp
WHERE salary > AVG(salary) GROUP BY dept_id;由于 WHERE 的执行时机远远早于 GROUP BY 和聚合计算,这种写法属于逻辑越界
2) 派生表思路
-
第一步: 编写一个独立的分组统计查询,计算出每个部门的平均薪资,将其固化为一个部门均薪中间表
-
第二步: 将该查询放入 FROM 子句作为派生表(命名为 dept_avg),然后通过 dept_id 与原员工表(命名为 e)进行跨表等值连接
-
第三步: 此时,部门平均薪资已经退化为派生表中的一个普通标量字段,可以直接在外部主查询的 WHERE 中与员工个人薪资进行大小比对
sql
-- 标准派生表解法
SELECT
e.name AS 员工姓名,
e.salary AS 个人月薪,
e.dept_id AS 部门工号,
ROUND(dept_avg.avg_salary, 2) AS 部门平均月薪
FROM emp AS e, (
-- 内层子查询:按部门分组计算平均薪资
SELECT dept_id, AVG(salary) AS avg_salary
FROM emp
WHERE dept_id IS NOT NULL
GROUP BY dept_id
) AS dept_avg -- 核心:必须为派生表指定别名 dept_avg
WHERE e.dept_id = dept_avg.dept_id -- 连接条件:将员工与其所在部门的均薪数据绑定
AND e.salary > dept_avg.avg_salary; -- 过滤条件:个人薪资高于部门均薪执行结果:
通过引入 FROM 子句中的派生表,我们成功打破了聚合函数无法直接参与底层行过滤的限制,在数据库内部完成了一次高内聚的多维动态横向对比
七、合并查询
1. 合并查询概念
在实际的报表汇总或历史数据规整中,存在另一种纵向维度的物理操作需求:将多个独立查询的结果集,在垂直方向上拼接组合成一个统一的结果集输出。 在 SQL 标准中,这种操作被称为合并查询或集合操作
合并查询不同于连接查询。连接查询是通过关联字段将两张表的列强行拉展合并;而合并查询则是直接将第二个查询的结果集追加到第一个查询结果集的下方,实现行数的堆叠
MySQL 为合并查询提供了两个核心操作符:UNION 和 UNION ALL
2. UNION 与 UNION ALL
UNION ALL(全集拼接)
-
运算逻辑: 简单高效。它直接将两个 SELECT 语句检索出来的行进行物理合并,不做任何后置审查
-
数据特征: 如果第一个查询与第二个查询的数据中存在完全相同的重复行,UNION ALL 会完整保留这些重复记录,不进行任何干预。
UNION(去重合并)
-
运算逻辑: 在完成基础的物理合并后,MySQL 会在内存中对最终的结果集进行隐式的去重(DISTINCT)与排序(Filesort)操作
-
数据特征: 最终输出的结果集中,所有重复的行都会被剔除,仅保留唯一的记录
两者的关键区别
在生产环境的架构设计中,选择 UNION 还是 UNION ALL 往往对数据库的 CPU 与内存消耗有决定性的影响
| UNION | UNION ALL | |
|---|---|---|
| 去重行为 | 自动剔除结果集中的重复行 | 完整保留所有行,包括重复行 |
| 底层机制 | 需要进行全集对比、排序与去重 | 直接进行数据堆叠,无后置处理 |
| 执行效率 | 较低(消耗内存与 CPU 资源) | 高(接近线性物理追加) |
| 首选场景 | 明确需要合并且要求结果集唯一的场景 | 确信数据无交集,或业务需要保留完整痕迹的场景 |
3. 合并查询案例
为了清晰展示两者的行为差异,我们设计一个跨多维度的运营检索场景
业务需求: 人力资源部需要抽取一份特定的员工名录进行盘点,名录包含两部分人群:
-
所属部门为市场部(dept_id = 102)的员工
-
个人薪资高于 25000.00 元的高管层员工
基础子集数据
在执行合并前,我们先看这两个单独条件所覆盖的底层数据:
-
市场部成员(2人):金蝉子(28000.00)、白龙马(10000.00)。
-
高薪资成员(2人):齐天大圣(35000.00)、金蝉子(28000.00)。
-
**重叠交集:**金蝉子同时满足这两个条件
3.1 使用 UNION ALL 进行无差异堆叠
sql
-- 查询A:市场部员工
SELECT name, job_title, salary, dept_id FROM emp WHERE dept_id = 102
UNION ALL
-- 查询B:高薪员工
SELECT name, job_title, salary, dept_id FROM emp WHERE salary > 25000.00;执行结果:
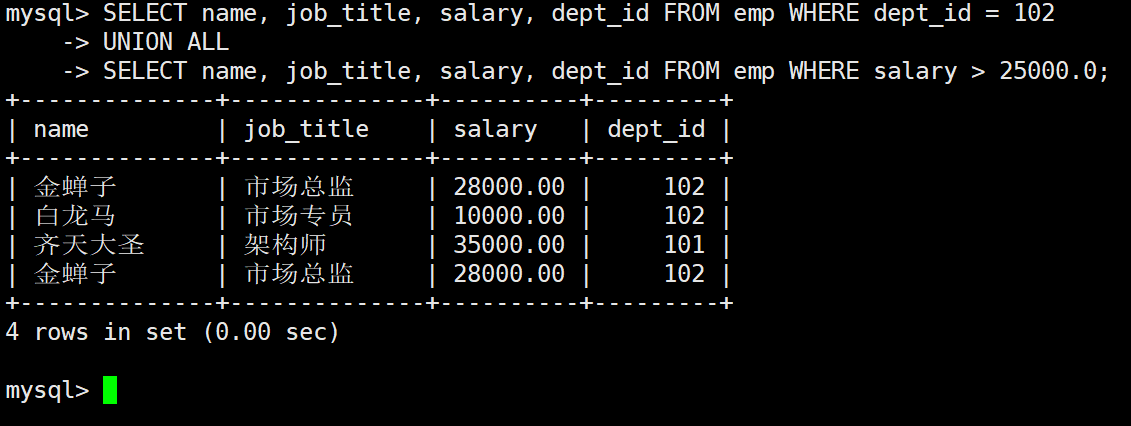
输出分析: 由于没有去重机制,同时满足两个条件的金蝉子在最终结果集中被打印了两次
3.2 使用 UNION 进行去重规整
sql
-- 查询A:市场部员工
SELECT name, job_title, salary, dept_id FROM emp WHERE dept_id = 102
UNION
-- 查询B:高薪员工
SELECT name, job_title, salary, dept_id FROM emp WHERE salary > 25000.00;执行结果:
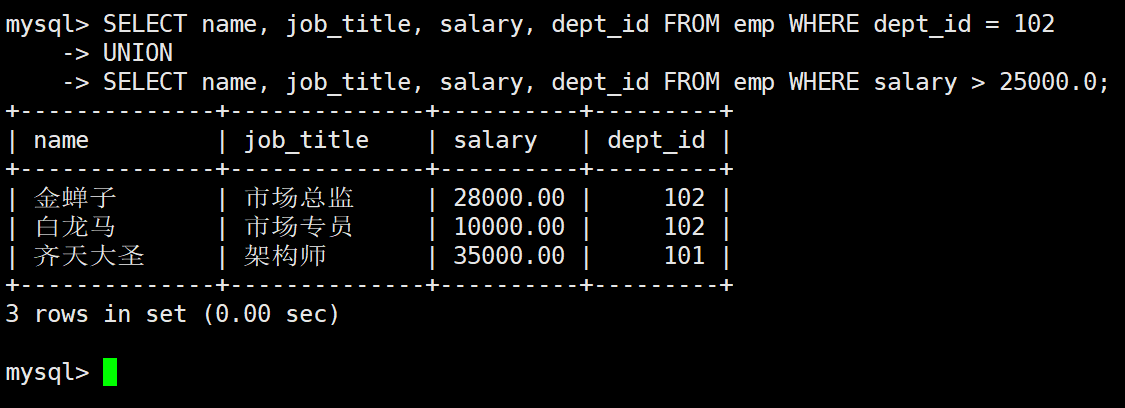
**输出分析:**经过去重,重复的金蝉子记录被精简为一行,结果集符合严格的集合唯一性标准
4. 注意事项
合并查询并不是可以将任意两张表随意拼接,它在底层要求参与合并的多个 SELECT 语句必须满足以下三个原则,否则 MySQL 会抛出编译期语法错误:
-
列数必须绝对一致: 第一个 SELECT 语句投影了 4 个字段,第二个 SELECT 语句也必须且只能投影 4 个字段
-
数据类型必须兼容: 对应位置的列,其数据类型应当相同或能够实现隐式转换。例如第一个查询的第一列是 INT,第二个查询的第一列也应当是数值类型,不能是 TEXT 或 DATETIME
-
列名以第一个查询为准: 最终合并后的结果集,其字段名称由第一个 SELECT 语句中的列名或别名决定。即便第二个查询使用了不同的别名,也会被第一个查询的表头强制覆盖
实战OJ:获取所有非 manager 的员工 emp_no
**题目要求:**从 employees 表中找出所有不是部门领导的员工编号 emp_no。部门领导信息存放在 dept_manager 表中
员工表 employees 简况如下:
|--------|------------|------------|-----------|--------|------------|
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
部门领导表 dept_manager 简况如下:
|---------|--------|------------|------------|
| dept_no | emp_no | from_date | to_date |
| d001 | 10002 | 1996-08-03 | 9999-01-01 |
| d002 | 10003 | 1990-08-05 | 9999-01-01 |
SQL:
sql
select emp_no
from employees
where emp_no not in (
select emp_no
from dept_manager
);思路解析:
sql
select emp_no from dept_manager先查出所有 manager 的员工编号,然后:
sql
where emp_no not in (...)总结
综上所述,我们学习了 MySQL 中的复合查询技术,包括多表查询、自连接、子查询以及合并查询等内容,并通过多个实际案例体会了它们在复杂业务场景中的应用方式
通过复合查询,我们已经能够突破单表查询的限制,将多个表中的数据关联起来进行分析和处理。同时,子查询的引入也使得 SQL 具备了嵌套求解的能力,大大增强了查询语句的表达能力
不过,在前面的多表查询过程中,我们实际上一直在使用一种特殊的连接方式:只有满足连接条件的数据才会被保留下来
那么问题来了:
如果某张表中存在没有匹配关系的数据怎么办?能否将这些没有匹配成功的数据也查询出来?数据库又是如何处理这种情况的?
这就引出了数据库中另一组非常重要的概念------连接查询(Join)
因此,在下一篇中,我们将正式学习内连接(Inner Join)、左外连接(Left Join)、右外连接(Right Join)等连接方式,深入理解多表数据关联背后的实现逻辑
