 @bit::Shadow
@bit::Shadow
✧(≖ ◡ ≖✿
目录
[缺页异常(Page Fault)](#缺页异常(Page Fault))
线程是什么?
进程:内存资源分配的基本单位。
线程:CPU调度的基本单位。
先前的篇章中已详细讲解,进程创建时每新增一个进程就会新增一个task_struct { 与 struct page { 页表 划分与映射物理内存区域。
内核下的线程
多/单线程,维护区域的本质是基于PCB下mm_struct的小块区域管理者
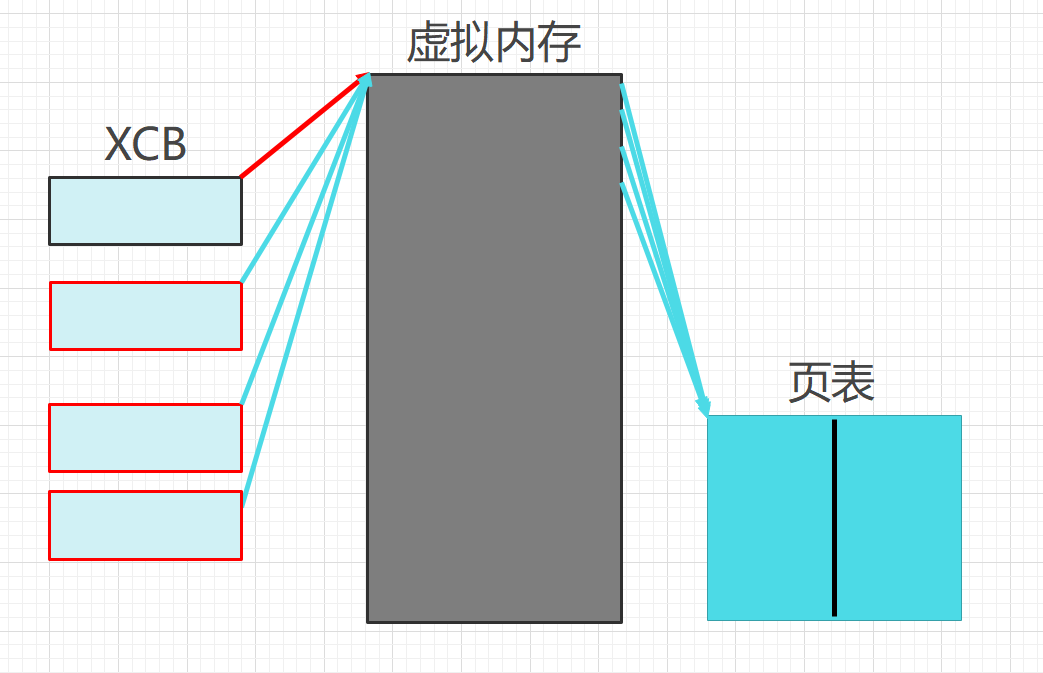
对进程的承接
线程是共享资源(虚拟地址)下的调度,称先前的进程为:只具有一个线程的单进程。
*Win与Linux下对于线程处理的平台差异
Win下以线程、进程分离,分别构建算法、结构等等。
Linux下线程融于进程内部,进程的O(1)算法、结构等等被线程同样使用。
CPU视角下的调度模块
核心概念:CPU是运算器+控制器为构成元素,CPU加载定址执行计算等。
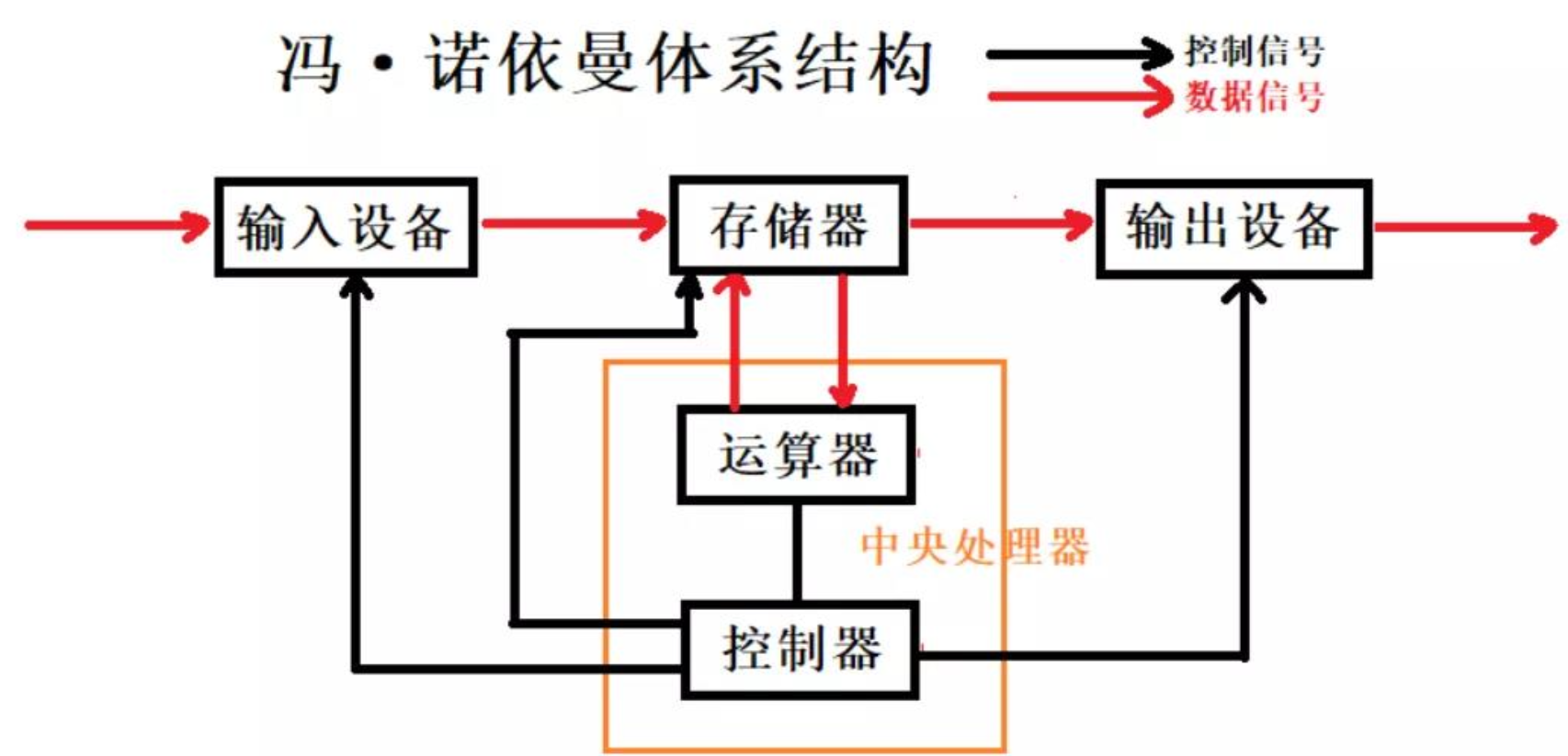
从CPU的角度来看,进程是"资源容器" ,线程是"执行单元"。CPU根本不关心进程,它只认识线程(即Linux下的"轻量级进程")。
执行流数 <= 进程数 ,线程才是CPU真正的执行指令的载体。CPU的PC指针(Program Counter程序计数器)指向的是线程的代码段,寄存器例装载的是线程的运行状态。
☆线程/轻量级进程图解
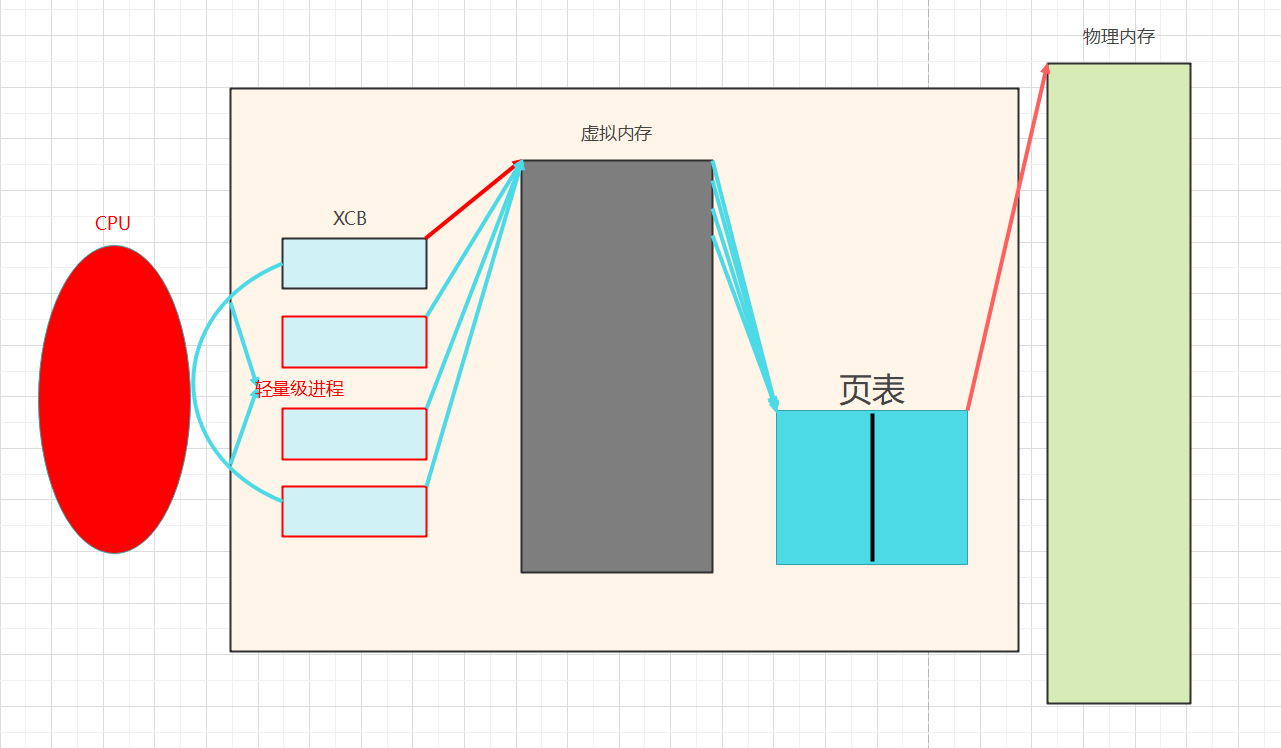
☆线程逻辑图解
回顾进程间通信的System V模式就是因为虚拟内存表间的独立,使得匿名管道int pipe(int fds2);命名管道int mkfifo(const char* pathname, mode_t mode);的产生。
因为线程间用于共用同一块虚拟内存表,所以线程间对话(访问资源)十分的简单。
进程 VS 线程(轻量级进程)通信
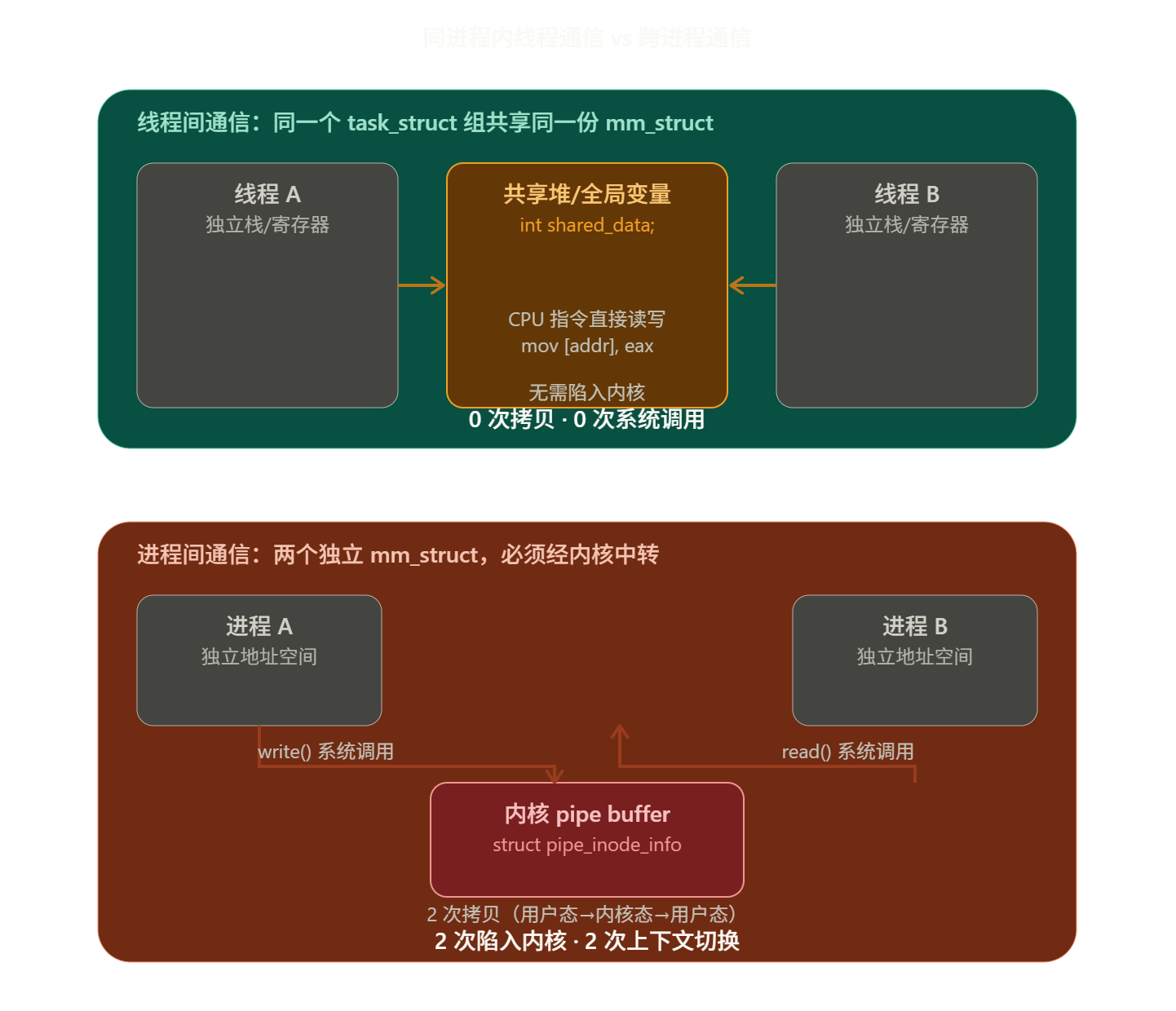
通信实例
//无锁 共享全局变量、函数 分别打印
cpp
#include<iostream>
#include<pthread.h>
int gval = 3;
int Add(const int& a, const int& b)
{
return a+b;
}
void* Routine(void* arg)
{
std::string name = static_cast<const char*>(arg);
std::cout << "global val:" << gval << std::endl;
std::cout << "gFunc_Add(1,3)" << Add(1,3) << std::endl;
return nullptr;
}
int main()
{
//无锁 共享全局变量、函数 分别打印
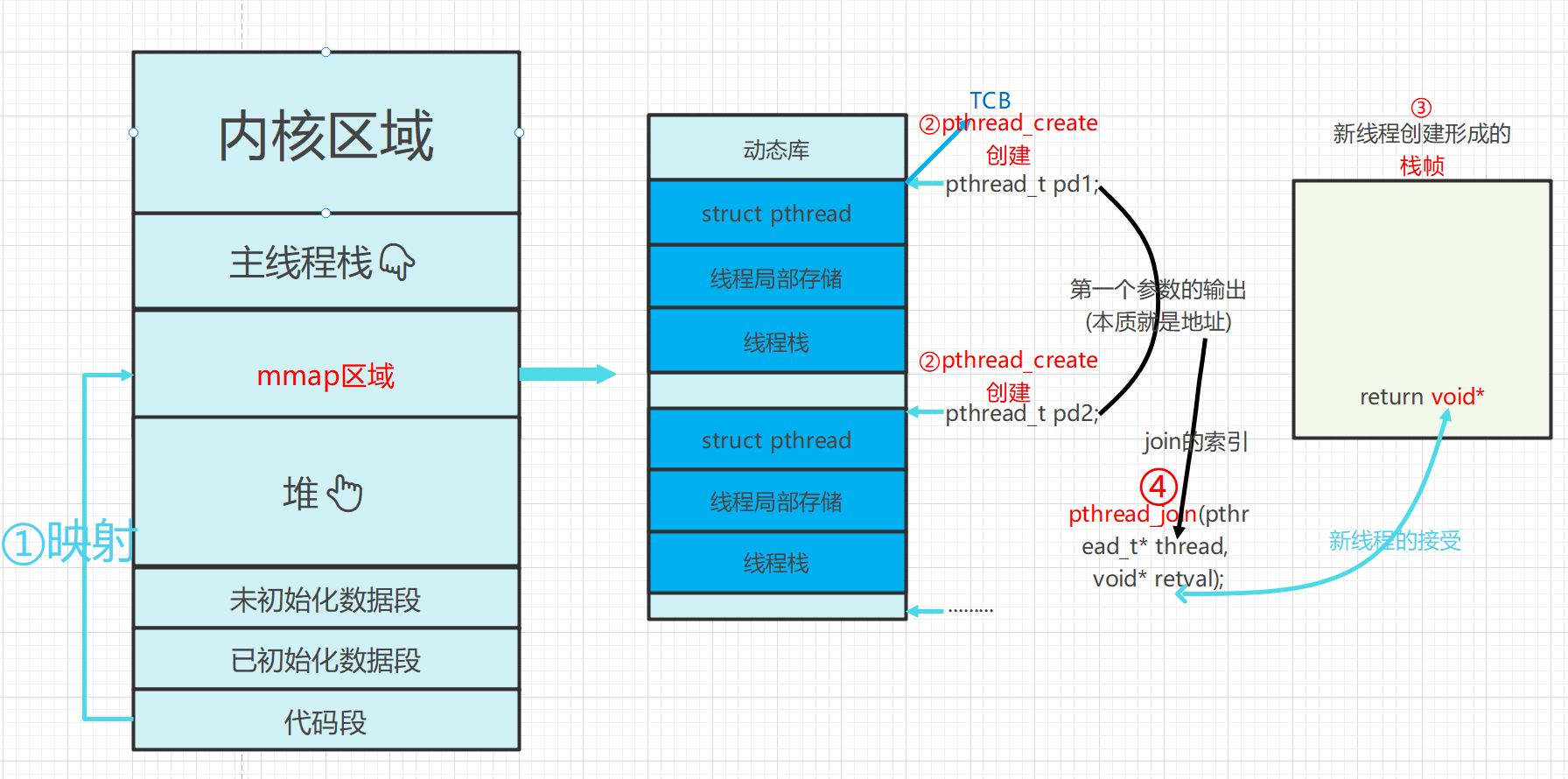
pthread_t pd;
pthread_create(&pd, nullptr, Routine,(void*)"Thread_1");
//阻塞等待回收♻️
pthread_join(pd,nullptr);//第二个参数是二级指针!!
return 0;
}虚拟到物理内存,页表相关,部分内存管理
磁盘内是均以4KB为基本单位进行内存管理的,相应的物理内存也以4KB为基本块。假设4GB物理内存,那么划分为4KB的块数有4GB/4KB = 1048576块。
例:物理内存页的写时拷贝,ELF文件的的section段合并为segment段均是以4KB为基础单位。
多级(二级)页表管理
使用标志位unsigned flags; 32位来定址.
前十位(一级页)索引页目录(共用,单个)中特定下标,内部存储页表项(多个页表单中间十位)的起始地址,页表单内均为4KB块各块分别用于索引物理内存块的起始地址,访问时使用后12位作偏移量,精细到字节访问。
两级页表的地址转换:
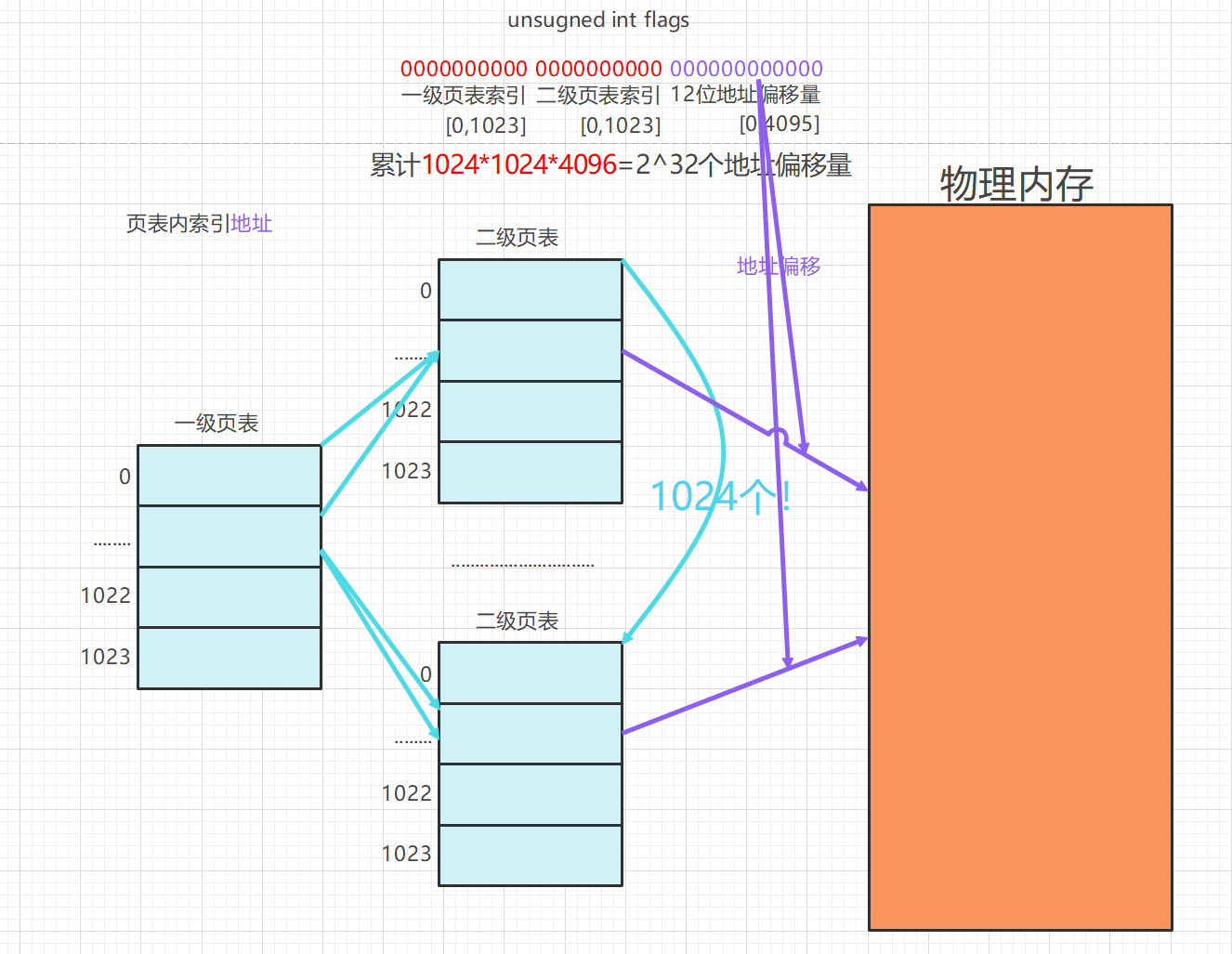
反向映射(从物理地址到虚拟地址)的原理:物理地址划分于32位位图的下12位中,相应的高位自然对应该物理内存块的各级页。
单级页表与多级页表
单级页表 下查表相对更快,但需要大量存储/被大量连续内存区存储。
多级页表下查表速度变慢,但提高了内存利用率。
页表相关概念
页框:是一个存储区域。
页:一个数据块,可以存放在任何页框或磁盘中。
CPU的内部细节行为
- CPU 发出虚拟地址 0x7fff1234
↓
- MMU 收到地址,先查 TLB(缓存/"快表")
↓
- MMU 读取 CR3 寄存器
(CR3 存物理内存中的起始地址)
↓
- MMU 根据 CR3 找到页表,逐级遍历
↓
- 得到物理地址 → 访问内存
↓
- (可选) 将这次映射缓存到 TLB 中,下次加速
TLB:快表、后备缓冲器
TLB(Translation Lookaside buffer),后备缓冲器(其实就是缓存)也称"快表"。TLB暂存最近的虚拟地址到物理地址的映射关系。(常用词汇速查手册)
缺页异常(Page Fault)
缺页异常是CPU对于MMU提供的虚拟地址-在TLB和页表内都没有找到对应的物理页,而发生的一种逻辑异常,它是由一个硬件中断触发的不一定可以自动由软件逻辑纠正的异常类型。
如何理解new与malloc?
new与malloc申请内存并非直接挂接到物理内存上,而是在真正就要使用这块申请的内存时才触发缺页中断(Page Fault)真正挂接。
线程的优点
大型I/O互不干扰,支持计算密集型算法逻辑(像:GPU、显示器的支持)。
☆线程创建越多越好吗?
此问题需分情况讨论,以线程的主要应用分析。(I/O与计算密集型)
I/O型
由于I/O的等待机制,常常是越多越好。
计算密集型
线程是CPU调度的基本单位,多线程下当需要频繁高强度计算时,++线程间切换也需要消耗++。因此在面对计算密集型时要有适量的线程数量,非"越多越好"。
线程间切换的主要消耗点是什么?
CPU内相应存储数据上下文必须切换,扰乱了"CPU的缓存机制"。CPU内拥有TLB、硬件、cache 等空间存储的缓存。当线程切换时,"这些预处理好的"支持高效访问的中间件会直接失效,切换导致的结果就是这些中间件必须重新热加载。
线程与进程对比
进程是++资源分配的基本单位++ ,线程是++CPU调度++ 的基本单位。
进程大部分资源是共享 的,线程大部分资源是私有 的。
进程间访问不同的虚拟内存表 通信困难,使用的页表的非系统调用区的映射分立。
线程间访问同一虚拟内存表 通信非常简单,使用的页表是同一个。
☆线程是操作系统调度的基本单位,CPU 中对应的寄存器组赋予了线程独立的"上下文",使其能够被独立调度
☆各个线程有自己独立的栈结构,用于维护私有数据,确保调用函数与局部变量互不干扰。
感谢支持,持续更新
欢迎关注
