PyTorch计算机视觉(1)------计算机视觉的数学工具
-
- [0. 前言](#0. 前言)
- [1. 概率与香农熵](#1. 概率与香农熵)
- [2. Kullback--Leibler 散度与交叉熵](#2. Kullback–Leibler 散度与交叉熵)
- [3. 条件概率与联合熵](#3. 条件概率与联合熵)
- [4. 詹森不等式](#4. 詹森不等式)
- [5. 最大似然估计与过拟合](#5. 最大似然估计与过拟合)
- [6. 期望最大化算法在寻找 PDF 中的应用](#6. 期望最大化算法在寻找 PDF 中的应用)
- 小结
0. 前言
本节介绍了计算机视觉项目的数学工具。将介绍信息熵、统计概率分布函数、Kullback-Leibler 散度、Jensen 不等式以及非线性回归中的过拟合问题等数学概念。
计算机视觉研究的目标是使计算机具备类人的感知能力。机器学习是人工智能 (Artificial Intelligence, AI) 的一个分支,致力于算法和统计模型的开发。它使计算机能够从数据中"学习",而无需进行显式编程。在机器学习中,基于算法的模型在数据集上进行训练,以发现数据中的模式,从而预测新数据。机器学习有多种类型,包括监督学习、无监督学习、半监督学习和强化学习,每种类型都有其独特的算法和方法集。
图像由像素组成,即屏幕上的微小点。当大量像素以特定构型(模式)排列时,便形成图像。图像的分辨率取决于其包含的像素数量。更高的图像分辨率能带来更清晰、更细致的视觉呈现。通过图像像素在空间中的分布模式或概率,我们可以生成新的图像。
为了开启我们的计算机视觉研究,掌握统计学概念,尤其是概率,至关重要。利用贝叶斯概率定理和香农信息熵理论,我们可以推导出用于模型训练的损失函数。这些模型将足够智能,它们不仅能判断图像中是否有猫或狗,还能根据我们的文本提示生成逼真的图像/视频。
1. 概率与香农熵
对于一枚均匀硬币,投掷时,其"正面"和"反面"朝上的概率相同(均为 50%)。在这个硬币系统中,我们有一个定义在{'正面', '反面'}空间中的离散随机变量 X X X,其概率质量函数 (probability mass function, PMF) 为 P ( X ) = { 1 / 2 , 1 / 2 } P(X) = \{1/2, 1/2\} P(X)={1/2,1/2}。
若一枚硬币不均匀,其正面朝上的概率 p = 0.45 p = 0.45 p=0.45,我们抛掷这枚硬币十次 ( n = 10 n = 10 n=10),那么恰好出现四次正面 ( x = 4 x = 4 x=4) 的概率是多少?这个非均匀硬币系统的离散随机变量 X X X 定义在 { 0 , 1 , ... , 10 } \{0, 1, ..., 10\} {0,1,...,10} 空间中,且服从二项分布函数。将上述参数代入以下公式,即可得到答案:23.8%。
P ( X = x ) = n ! x ! ( n − x ) ! p x ( 1 − p ) n − x P(X=x)=\frac {n!}{x!(n-x)!}p^x(1-p)^{n-x} P(X=x)=x!(n−x)!n!px(1−p)n−x
我们身体的身高变量 ( X X X) 是一个符合高斯分布函数的连续随机数,该分布是机器学习中最重要的概率密度函数 (probability density function, PDF)。尽管许多图像数据集的概率密度函数过于复杂而无法明确写出,但我们仍可尝试使用高斯分布函数来近似它们。
P ( X = x ) = N ( x ; μ , σ 2 ) = 1 2 π σ 2 e − 1 2 ( x − μ σ ) 2 P(X=x)=N(x;\mu,\sigma^2)=\frac 1{\sqrt{2\pi\sigma^2}}e^{-\frac 1 2(\frac{x-\mu}{\sigma})^2} P(X=x)=N(x;μ,σ2)=2πσ2 1e−21(σx−μ)2
在以上公式中,μ是X的均值或期望值, σ σ σ 是 X X X 的标准差, σ 2 σ^2 σ2 是X的方差。对于任何具有已知概率密度函数的随机变量 X X X,其期望值 E p X E_pX EpX 和方差 E p ( X − μ ) 2 E_p(X-μ)\^2 Ep(X−μ)2 为:
μ = ∑ i = 1 n x i p ( x i ) or ∫ − ∞ ∞ x p ( x ) d x \mu=\sum_{i=1}^nx_ip(x_i) \text{ or } \int^\infin_{-\infin}xp(x)dx μ=i=1∑nxip(xi) or ∫−∞∞xp(x)dx
σ 2 = ∑ i = 1 n ( x i − μ ) 2 p ( x i ) or ∫ − ∞ ∞ ( x − μ ) 2 p ( x ) d x \sigma^2=\sum_{i=1}^n(x_i-\mu)^2p(x_i) \text{ or } \int^\infin_{-\infin}(x-\mu)^2p(x)dx σ2=i=1∑n(xi−μ)2p(xi) or ∫−∞∞(x−μ)2p(x)dx
信息的香农"熵"是指一个随机变量所包含的"信息量",或者说是对一个系统信息进行编码所需的最小比特数。
H ( p ) = − ∑ i = 1 n p i l o g 2 ( p i ) or ∫ − ∞ ∞ p ( x ) l o g 2 p ( x ) d x H(p)=-\sum_{i=1}^np_ilog_2(p_i) \text{ or } \int^\infin_{-\infin}p(x)log_2p(x)dx H(p)=−i=1∑npilog2(pi) or ∫−∞∞p(x)log2p(x)dx
一个均匀硬币系统的熵是 H ( p ) = − 2 1 2 log 2 1 2 = 1 H(p) = -2\frac{1}{2} \log_2 \frac{1}{2} = 1 H(p)=−221log221=1 比特,而一个均匀骰子系统的熵是 H ( p ) = − 6 1 6 log 2 1 6 = 2.585 H(p) = -6\frac{1}{6} \log_2 \frac{1}{6} = 2.585 H(p)=−661log261=2.585 比特。为了数学上的便利,在机器学习中我们通常使用自然对数,此时熵的单位为"nit"。硬币的熵和骰子的熵分别为 0.69 nits 和 1.79 nits。
2. Kullback--Leibler 散度与交叉熵
当同一个随机变量 X X X 存在两个分布函数 p p p 和 q q q 时,它们的对数似然比是一个函数 f ( x ) = l n p ( x ) q ( x ) f(x) = ln\\frac{p(x)}{q(x)} f(x)=lnq(x)p(x)。该对数似然比的期望值称为 Kullback--Leibler (KL) 散度( D K L D_{KL} DKL):
D K L ( p ∣ ∣ q ) = E p l n p ( X ) q ( X ) = ∑ i = 1 n p ( x i ) l n p ( x i ) q ( x i ) D_{KL}(p||q)=E_pln\\frac {p(X)}{q(X)}=\sum_{i=1}^np(x_i)ln\frac{p(x_i)}{q(x_i)} DKL(p∣∣q)=Eplnq(X)p(X)=i=1∑np(xi)lnq(xi)p(xi)
D K L D_{KL} DKL 用于衡量同一随机变量X的系统的两个概率密度函数(或概率质量函数)之间的差异。如果p和q相同,则 D K L = 0 D_{KL} = 0 DKL=0。交叉熵是量化两个 PDF 之间差异的另一个指标,在机器学习中常用作损失函数。
H ( p , q ) = − ∑ i = 1 n p ( x i ) l n ( q ( x i ) ) = D K L ( p ∣ ∣ q ) + H ( p ) H(p,q)=-\sum_{i=1}^np(x_i)ln(q(x_i))=D_{KL}(p||q)+H(p) H(p,q)=−i=1∑np(xi)ln(q(xi))=DKL(p∣∣q)+H(p)
以下场景有助于我们理解这些公式:假设在抛硬币场景中,游戏开始时,要验证硬币是否均匀,目标概率质量函数是 P ( X ) = { 1 / 2 , 1 / 2 } P(X) = \{1/2, 1/2\} P(X)={1/2,1/2}。在抛掷硬币 10000 次后,发现真实的 PMF 是 Q ( X ) = { 0.65 , 0.35 } Q(X) = \{0.65, 0.35\} Q(X)={0.65,0.35}。这两个分布的 D K L D_{KL} DKL 为 D K L = 0.5 l n ( 0.5 / 0.65 ) + 0.5 l n ( 0.5 / 0.35 ) = 0.047 D_{KL} = 0.5ln(0.5/0.65) + 0.5ln(0.5/0.35) = 0.047 DKL=0.5ln(0.5/0.65)+0.5ln(0.5/0.35)=0.047;交叉熵则为 H ( p , q ) = − 0.5 l n ( 0.65 ) − 0.5 l n ( 0.35 ) = 0.740 H(p,q) = -0.5ln(0.65) - 0.5ln(0.35) = 0.740 H(p,q)=−0.5ln(0.65)−0.5ln(0.35)=0.740。
对于均匀硬币,其熵 H ( p ) = 0.693 n i t s H(p) = 0.693\ nits H(p)=0.693 nits。当系统的两个分布相同时,它们的交叉熵取得最小值 H ( p ) H(p) H(p)。这就是为什么交叉熵可以在机器学习模型训练中作为损失函数使用。
K\L 散度不具有对称性: D K L ( p ∥ q ) ≠ D K L ( q ∥ p ) D_{KL}(p \parallel q) \neq D_{KL}(q \parallel p) DKL(p∥q)=DKL(q∥p),并且它是一个非负数: D K L ( p ∥ q ) ⩾ 0 D_{KL}(p \parallel q) ⩾ 0 DKL(p∥q)⩾0。第一个性质是显而易见的,第二个性质可以通过在 x ⩾ 0 x ⩾ 0 x⩾0 条件下使用不等式 ( x − 1 ) ⩾ l n ( x ) (x-1) ⩾ ln(x) (x−1)⩾ln(x) 来证明。基于该不等式,我们可以得到 q ( x ) / p ( x ) − 1 ⩾ l n q ( x ) / p ( x ) q(x)/p(x)−1 ⩾ lnq(x)/p(x) q(x)/p(x)−1⩾lnq(x)/p(x),或者等价地 − l n q ( x ) / p ( x ) ⩾ − q ( x ) / p ( x ) − 1 -lnq(x)/p(x) ⩾ -q(x)/p(x)-1 −lnq(x)/p(x)⩾−q(x)/p(x)−1,进而推导出:
D K L ( p ∥ q ) = − ∫ x p ( x ) l n ( q ( x ) p ( x ) ) d x ⩾ − ∫ x p ( x ) ( q ( x ) p ( x ) − 1 ) d x = 0 D_{KL}(p \parallel q)=-\int_xp(x)ln(\frac{q(x)}{p(x)})dx⩾-\int_xp(x)(\frac{q(x)}{p(x)}-1)dx=0 DKL(p∥q)=−∫xp(x)ln(p(x)q(x))dx⩾−∫xp(x)(p(x)q(x)−1)dx=0
Jensen--Shannon (JS) 散度 ( D J S D_{JS} DJS) 是对称的散度。可以通过以下公式计算发现的那枚不均匀硬币的 D J S D_{JS} DJS (使用离散求和而非积分),显然, D J S ( p ∣ ∣ q ) D_{JS}(p||q) DJS(p∣∣q) 满足 0 ≤ D J S ( p ∣ ∣ q ) ≤ l n ( 2 ) 0 ≤ D_{JS}(p||q) ≤ ln(2) 0≤DJS(p∣∣q)≤ln(2)。通过在下述公式中将 p / ( p + q ) p/(p+q) p/(p+q) 和 q / ( p + q ) q/(p+q) q/(p+q) 均替换为 1.0,可以证明这一点,因为这两个分数实际上均小于 1.0:
D J S ( p ∥ q ) = 1 2 ∫ ( p ( x ) l n ( 2 p ( x ) p ( x ) + q ( x ) ) + q ( x ) l n ( 2 q ( x ) p ( x ) + q ( x ) ) ) d x D_{JS}(p \parallel q)=\frac 12\int(p(x)ln(\frac{2p(x)}{p(x)+q(x)})+q(x)ln(\frac{2q(x)}{p(x)+q(x)}))dx DJS(p∥q)=21∫(p(x)ln(p(x)+q(x)2p(x))+q(x)ln(p(x)+q(x)2q(x)))dx
我们已经熟悉了单变量高斯分布。在计算机视觉项目中,我们还需要使用多元正态分布来生成仿真图像。为数学处理方便,我们仅讨论包含三个独立随机变量 x 1 x_1 x1、 x 2 x_2 x2 和 x 3 x_3 x3 的多元正态分布系统,它们的均值分别为 μ 1 μ_1 μ1、 μ 2 μ_2 μ2 和 μ 3 μ_3 μ3,标准差分别为 σ 1 σ_1 σ1、 σ 2 σ_2 σ2 和 σ 3 σ_3 σ3。它们的方差构成一个对角矩阵 Σ Σ Σ,其逆矩阵为 Σ − 1 Σ^{-1} Σ−1。
X = x 1 x 2 x 3 Σ = σ 1 2 0 0 0 σ 2 2 0 0 0 σ 3 2 Σ − 1 1 σ 1 2 0 0 0 1 σ 2 2 0 0 0 1 σ 3 2 ∣ Σ ∣ 1 / 2 = ( σ 1 2 σ 2 2 σ 3 2 ) 1 / 2 p ( X = x ) = Π i = 1 3 N ( x i ; μ i , σ i 2 ) = 1 ( 2 π ) 3 / 2 ∣ Σ ∣ 1 / 2 e − 1 2 ( x − μ ) t Σ − 1 ( x − μ ) X=\begin{bmatrix}x_1\\x_2\\x_3\end{bmatrix} \ \ Σ=\begin{bmatrix}\sigma_1^2&0&0\\0&\sigma^2_2&0\\0&0&\sigma_3^2\end{bmatrix}\ \ Σ^{-1}\begin{bmatrix}\frac1{\sigma_1^2}&0&0\\0&\frac1{\sigma^2_2}&0\\0&0&\frac1{\sigma_3^2}\end{bmatrix}\ \ |Σ|^{1/2}=(\sigma_1^2\sigma_2^2\sigma_3^2)^{1/2}\\ p(X=x)=\Pi_{i=1}^3N(x_i;\mu_i,\sigma_i^2)=\frac1{(2\pi)^{3/2}|Σ|^{1/2}}e^{-\frac12(x-\mu)^tΣ^{-1}(x-\mu)} X= x1x2x3 Σ= σ12000σ22000σ32 Σ−1 σ121000σ221000σ321 ∣Σ∣1/2=(σ12σ22σ32)1/2p(X=x)=Πi=13N(xi;μi,σi2)=(2π)3/2∣Σ∣1/21e−21(x−μ)tΣ−1(x−μ)
若存在另一个多元正态分布 q ( X = x ) q(X = x) q(X=x),其均值为零且 Σ Σ Σ 矩阵是一个 3 × 3 的单位矩阵 I I I,那么利用以上所有信息来求解 D K L ( p ∣ ∣ q ) D_{KL}(p||q) DKL(p∣∣q) 并不困难。
D K L ( p ∣ ∣ q ) = 1 2 ∑ i = 1 3 μ i 2 + σ i 2 − 1 − l n ( σ i 2 ) D_{KL}(p||q)=\frac 12\sum_{i=1}^3\\mu_i\^2+\\sigma_i\^2-1-ln(\\sigma_i\^2) DKL(p∣∣q)=21i=1∑3μi2+σi2−1−ln(σi2)
3. 条件概率与联合熵
有时一个系统中存在两个或更多的随机变量,每个变量都有其自身的概率分布函数 (PDF)。这些变量共同作用,形成了一个联合概率分布函数。例如,有一枚均匀的硬币和一个均匀的骰子,且它们彼此独立。骰子的点数变量为 X X X,其概率质量函数为均匀分布 P ( X ) = { 1 / 6 , 1 / 6 , 1 / 6 , 1 / 6 , 1 / 6 , 1 / 6 } P(X) = \{1/6, 1/6, 1/6, 1/6, 1/6, 1/6\} P(X)={1/6,1/6,1/6,1/6,1/6,1/6};关于硬币正反面的变量为 Y Y Y,其概率质量函数为另一个均匀分布 P ( Y ) = { 1 / 2 , 1 / 2 } P(Y) = \{1/2, 1/2\} P(Y)={1/2,1/2}。硬币和骰子的联合概率分布函数同样是一个均匀分布 P ( X , Y ) P(X,Y) P(X,Y),共有十二种状态,任何单一状态的概率均为 1 / 12 1/12 1/12,如下表所示。
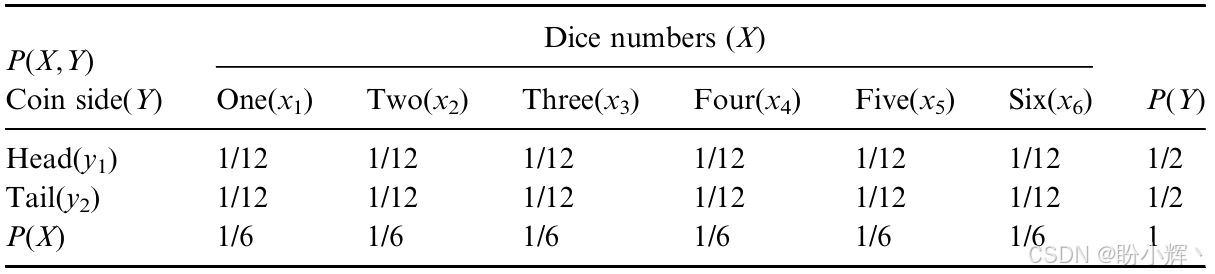
在标有 " H e a d ( y 1 ) Head(y_1) Head(y1)" 的第一行中,六个联合概率 p ( x i , y 1 ) p(x_i, y_1) p(xi,y1) 的总和等于 p ( y 1 ) = 1 / 2 p(y_1) = 1/2 p(y1)=1/2;在标有 " T a i l ( y 2 ) Tail(y_2) Tail(y2)" 的第二行中,其余六个联合概率 p ( x i , y 2 ) p(x_i, y_2) p(xi,y2) 的总和等于 p ( y 2 ) = 1 / 2 p(y_2) = 1/2 p(y2)=1/2,其中 i = 1 , 2 , ... , 6 i = 1,2,...,6 i=1,2,...,6。硬币的概率质量函数 P ( Y ) P(Y) P(Y) 由一个一维数组中的这两个数字构成: P ( Y ) = { p ( y 1 ) , p ( y 2 ) } P(Y) = \{p(y_1), p(y_2)\} P(Y)={p(y1),p(y2)}。在标有 " o n e ( x 1 ) one(x_1) one(x1)" 的列中,概率总和为 p ( x 1 ) = 1 / 6 p(x_1) = 1/6 p(x1)=1/6。其余五列中每一列的总和也等于 p ( x i ) = 1 / 6 p(x_i) = 1/6 p(xi)=1/6,其中 i = 2 , 3 , ... , 6 i = 2, 3, ..., 6 i=2,3,...,6。骰子的概率质量函数 P ( X ) P(X) P(X) 由一个一维数组中的这六个数字构成: P ( X ) = { p ( x 1 ) , p ( x 2 ) , ... , p ( x 6 ) } P(X) = \{p(x_1), p(x_2), ..., p(x_6)\} P(X)={p(x1),p(x2),...,p(x6)}。全部 12 个联合概率 p ( x i , y j ) p(x_i, y_j) p(xi,yj) 的总和、骰子的六个概率 p ( x i ) p(x_i) p(xi) 的总和以及硬币的两个概率 p ( y j ) p(y_j) p(yj) 的总和都等于 1 ( i = 1 , 2 , ... , 6 , j = 1 , 2 i = 1,2,...,6, j = 1,2 i=1,2,...,6,j=1,2)。这里的 P ( X ) P(X) P(X) 和 P ( Y ) P(Y) P(Y) 称为边缘概率。
事件 Y Y Y 的条件概率是指在骰子事件 X X X 已经发生或已知的情况下,硬币事件发生的概率。这记作 P ( Y ∣ X ) P(Y|X) P(Y∣X),表示给定 X X X 时 Y Y Y 的概率。例如,假设骰子已投掷并显示数字五,随后将投掷硬币。此时硬币的条件概率仍然各为一半: p ( y 1 ∣ x i = 5 ) = 1 2 p(y_1|x_i=5) =\frac 12 p(y1∣xi=5)=21 且 p ( y 2 ∣ x i = 5 ) = 1 2 p(y_2|x_i=5) =\frac 12 p(y2∣xi=5)=21,如下表所示。条件概率表 P ( Y ∣ X ) P(Y|X) P(Y∣X) 可以通过分别将上表(联合概率 P ( X , Y ) P(X,Y) P(X,Y) 表)中的六列,各自除以其底部对应的 P ( X ) P(X) P(X) 元素(即边缘概率)进行归一化而得到。下表的 P ( Y ∣ X ) P(Y|X) P(Y∣X) 表中,所有 12 个元素的值都相同: 1 2 \frac 12 21。

同样,条件概率表 P ( X ∣ Y ) P(X|Y) P(X∣Y) 可以通过分别将联合概率 P ( X , Y ) P(X,Y) P(X,Y) 表中的两行,各自除以其右侧对应的 P ( Y ) P(Y) P(Y) 元素(即边缘概率)进行归一化而得到。下表的 P ( X ∣ Y ) P(X|Y) P(X∣Y) 表中,所有 12 个元素的值也都相同: 1 6 \frac 16 61,如下表所示。根据贝叶斯定理, p ( x , y ) p(x,y) p(x,y)、 p ( x ∣ y ) p(x|y) p(x∣y)、 p ( y ∣ x ) p(y|x) p(y∣x)、 p ( x ) p(x) p(x) 和 p ( y ) p(y) p(y) 这些元素之间的关系由以下公式确立。
p ( y ∣ x ) = p ( x , y ) p ( x ) = p ( x ∣ y ) p ( x ) p ( y ) p(y|x)=\frac{p(x,y)}{p(x)}=\frac{p(x|y)}{p(x)}p(y) p(y∣x)=p(x)p(x,y)=p(x)p(x∣y)p(y)

在上述公式中, p ( x ) p(x) p(x) 和 p ( y ) p(y) p(y) 是边缘概率或先验概率, p ( x ∣ y ) p(x∣y) p(x∣y) 是给定 y y y 时 x x x 的似然度,而 p ( y ∣ x ) p(y|x) p(y∣x) 是给定 x x x 时 y y y 的后验概率。接下来,我们使用以下示例解释这些概念。
在一团体中, 55 % ( = p ( x 1 ) ) 55\%(=p(x_1)) 55%(=p(x1)) 是女性, 45 % ( = p ( x 2 ) ) 45\%(= p(x_2)) 45%(=p(x2)) 是男性。在这些女性中, 10 % ( = p ( y 1 ∣ x 1 ) ) 10\% (= p(y_1∣x_1)) 10%(=p(y1∣x1)) 是运动员;在男性中, 30 % ( = p ( y 1 ∣ x 2 ) ) 30\%(= p(y_1∣x_2)) 30%(=p(y1∣x2)) 是运动员。运动员和非运动员的变量分别为 y 1 y_1 y1 和 y 2 y_2 y2。假设我们知道有个人是运动员。那么,这位运动员是女性的概率是多少?
根据这个似然度 P ( Y ∣ X ) P(Y|X) P(Y∣X) 子表,我们可以构建出联合概率子表 P ( X , Y ) P(X,Y) P(X,Y),如下表中间三列所示。 P ( X , Y ) P(X,Y) P(X,Y) 表中四个单元格的数值是根据公式 p ( x , y ) = p ( y ∣ x ) p ( x ) p(x,y) = p(y|x)p(x) p(x,y)=p(y∣x)p(x) (即以上公式的变形)计算得到的。现在我们知道,这群人中,女性运动员有 5.5%;男性运动员有 13.5%;女性非运动员有 49.5%;男性非运动者有 31.5%。运动员和非运动员的边缘概率 p ( y 1 ) p(y_1) p(y1) 和 p ( y 2 ) p(y_2) p(y2) 分别为 19% 和 81%。
利用这个联合概率子表,我们可以计算后验概率 P ( X ∣ Y ) P(X|Y) P(X∣Y) (如下表右侧所示)中四个单元格的数值。这些计算同样基于以上公式的变形 p ( x ∣ y ) = p ( x , y ) / p ( y ) p(x|y) = p(x,y)/p(y) p(x∣y)=p(x,y)/p(y)。例如,一位运动员是女性的概率为 p ( x 1 ∣ y 1 ) = p ( x 1 , y 1 ) / p ( y 1 ) = 5.5 % / 19 % ≈ 28.9 % p(x_1∣y_1) = p(x_1, y_1) / p(y_1) = 5.5\%/19\% ≈ 28.9\% p(x1∣y1)=p(x1,y1)/p(y1)=5.5%/19%≈28.9%。
即使对于这个仅涉及四个变量(男性、女性、运动员、非运动员)的简单问题,上述关于后验概率计算的解释也显得非常复杂。利用可获取数据中的信息以及贝叶斯定理,我们可以推断出整个系统的信息。
在上述例子中,联合概率表 P ( X , Y ) P(X,Y) P(X,Y) 是关于相对于总人数的概率。先验概率表 P ( Y ∣ X ) P(Y|X) P(Y∣X) 来自于我们的调查或探索,它涉及每个子群体的概率:男性和女性。后验概率表 P ( X ∣ Y ) P(X|Y) P(X∣Y) 中的信息是从先验概率表和联合概率表推导出来的,涉及每个子群体的概率:运动员和非运动员。
实际上,并不需要构建下表中所示的三个子表。根据贝叶斯定理,我们可以直接计算: p ( x 1 ∣ y 1 ) = p ( y 1 ∣ x 1 ) p ( x 1 ) / p ( y 1 ) = p ( y 1 ∣ x 1 ) p ( x 1 ) / p ( y 1 ∣ x 1 ) p ( x 1 ) + p ( y 1 ∣ x 2 ) p ( x 2 ) ≈ 28.9 p(x_1|y_1) = p(y_1|x_1)p(x_1) / p(y_1) = p(y_1|x_1)p(x_1) / p(y_1∣x_1)p(x_1) + p(y_1\|x_2)p(x_2) ≈ 28.9% p(x1∣y1)=p(y1∣x1)p(x1)/p(y1)=p(y1∣x1)p(x1)/p(y1∣x1)p(x1)+p(y1∣x2)p(x2)≈28.9
先验概率或似然度是已知数据,而后验概率是从这些已知数据推断出来的。

根据上表中的概率,我们可以使用以下公式计算联合熵 H ( X , Y ) H(X,Y) H(X,Y)、先验条件熵 H ( X ∣ Y ) H(X|Y) H(X∣Y)、后验条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X) 和互信息 I ( X , Y ) I(X,Y) I(X,Y):
H ( X , Y ) = − ∑ i = 1 2 ∑ j = 1 2 p ( x i , y j ) l n ( p ( x i , y j ) ) = 1 H ( X ∣ Y ) = − ∑ i = 1 2 ∑ j = 1 2 p ( x i , y j ) l n ( p ( x i ∣ y j ) ) = 0 H ( Y ∣ X ) = − ∑ i = 1 2 ∑ j = 1 2 p ( x i , y j ) l n ( p ( y i ∣ x j ) ) = 0.454 I ( X , Y ) = I ( Y , X ) = ∑ i = 1 2 ∑ j = 1 2 p ( x i , y j ) l n ( p ( y i , x j ) p ( y i ) p ( x j ) ) = 0.032 H ( X ) = − ∑ j = 1 2 p ( x j ) l n ( p ( x j ) ) = 0.688 H ( Y ) = − ∑ j = 1 2 p ( y j ) l n ( p ( y j ) ) = 0.486 H ( X , Y ) = H ( X ) + H ( Y ∣ X ) = H ( Y ) + H ( X ∣ Y ) = 1.142 H(X,Y)=-\sum_{i=1}^2\sum_{j=1}^2p(x_i,y_j)ln(p(x_i,y_j))=1\\\ H(X|Y)=-\sum_{i=1}^2\sum_{j=1}^2p(x_i,y_j)ln(p(x_i|y_j))=0\\ H(Y|X)=-\sum_{i=1}^2\sum_{j=1}^2p(x_i,y_j)ln(p(y_i|x_j))=0.454\\ I(X,Y)=I(Y,X)=\sum_{i=1}^2\sum_{j=1}^2p(x_i,y_j)ln(\frac {p(y_i,x_j)}{p(y_i)p(x_j)})=0.032\\ H(X)=-\sum_{j=1}^2p(x_j)ln(p(x_j))=0.688\\ H(Y)=-\sum_{j=1}^2p(y_j)ln(p(y_j))=0.486\\ H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y)=1.142 H(X,Y)=−i=1∑2j=1∑2p(xi,yj)ln(p(xi,yj))=1 H(X∣Y)=−i=1∑2j=1∑2p(xi,yj)ln(p(xi∣yj))=0H(Y∣X)=−i=1∑2j=1∑2p(xi,yj)ln(p(yi∣xj))=0.454I(X,Y)=I(Y,X)=i=1∑2j=1∑2p(xi,yj)ln(p(yi)p(xj)p(yi,xj))=0.032H(X)=−j=1∑2p(xj)ln(p(xj))=0.688H(Y)=−j=1∑2p(yj)ln(p(yj))=0.486H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)=1.142
如果随机变量 X X X 和 Y Y Y 不是相互独立的,那么它们的互信息 I ( X , Y ) I(X, Y) I(X,Y) 将为一个正数。通过观察以上各表,会发现由均匀硬币和均匀骰子构成的装置中,其互信息 I ( X , Y ) I(X, Y) I(X,Y) 等于零。
4. 詹森不等式
若函数 g ( x ) g(x) g(x) 在区间 x ∈ X x∈X x∈X 上是一个凸函数,且 E g ( X ) Eg(X) Eg(X) 与 g E ( X ) gE(X) gE(X) 均为有限值,则该函数在区间内取值的平均值,大于或等于函数在 X X X 平均值处的函数值: E g ( X ) ⩾ g E ( X ) Eg(X) ⩾ gE(X) Eg(X)⩾gE(X)。其中 x x x 的概率密度函数可以是正态分布或其他类型的分布。
- 例子 01:考虑凸函数 g ( x ) = x 2 g(x) = x^2 g(x)=x2,定义域为 x ∈ − 1 , 1 x∈-1, 1 x∈−1,1,其概率密度函数为 p ( x ) = 1 / 2 p(x) = 1/2 p(x)=1/2
μ = E P X = X ‾ = ∫ − 1 1 x p ( x ) d x = 0 , g ( E p X ) = ( μ ) 2 = 0 E p g ( X ) = X 2 ‾ = ∫ − 1 1 x 2 p ( x ) d x = 1 3 , E p g ( X ) ≥ g ( E p X ) \mu=E_PX=\overline X=\int_{-1}^1xp(x)dx=0,\ g(E_pX)=(\mu)^2=0\\ E_pg(X)=\overline {X^2}=\int_{-1}^1x^2p(x)dx=\frac 13,\ E_pg(X)\geq g(E_pX) μ=EPX=X=∫−11xp(x)dx=0, g(EpX)=(μ)2=0Epg(X)=X2=∫−11x2p(x)dx=31, Epg(X)≥g(EpX) - 例子 02:考虑另一个凸函数 g ( x ) = − l n ( x ) g(x) = -ln(x) g(x)=−ln(x),定义域为 x ∈ 0.5 , 4.5 x∈0.5, 4.5 x∈0.5,4.5,其概率密度函数为 p ( x ) = 1 / 4 p(x) = 1/4 p(x)=1/4
μ = E P X = ∫ 0.5 4.5 x p ( x ) d x = 5 2 , g ( E p X ) = − l n ( μ ) = − l n ( 5 2 ) = − 0.92 E p g ( X ) = − ∫ 0.5 4.5 l n ( x ) p ( x ) d x = − 0.78 , E p g ( X ) ≥ g ( E p X ) \mu=E_PX=\int_{0.5}^{4.5}xp(x)dx=\frac 52,\ g(E_pX)=-ln(\mu)=-ln(\frac 52)=-0.92\\ E_pg(X)=-\int_{0.5}^{4.5}ln(x)p(x)dx=-0.78,\ E_pg(X)\geq g(E_pX) μ=EPX=∫0.54.5xp(x)dx=25, g(EpX)=−ln(μ)=−ln(25)=−0.92Epg(X)=−∫0.54.5ln(x)p(x)dx=−0.78, Epg(X)≥g(EpX)
5. 最大似然估计与过拟合
在机器学习中,我们需要了解数据集的概率密度函数 (probability density function, PDF) 进行图像生成。通过数据集的 PDF,我们可以生成新的数据(图像)。然而在大多数情况下,我们仅拥有数据(图像),那么如何找出数据集中隐藏的 PDF 呢?
最大似然估计 (maximum likelihood estimation, MLE) 是一种方法,当我们在拥有数据集 x i {x_i} xi (其中 i = 1 , 2 , ... , n i = 1, 2, ..., n i=1,2,...,n )的情况下,能够找出数据集中的 PDF。例如,假设数据集是关于学生身高的,且其中的数据服从高斯分布 N ( x ; μ , σ ) N(x; μ, σ) N(x;μ,σ)。通过使用 MLE,我们将找到该 PDF 的参数: μ μ μ 和 σ σ σ。
"似然"是指在一个未知 PDF 下,某个已发生事件的概率。学生的身高 x i x_i xi 是从似然函数 N ( x ; μ , σ ) N(x; μ, σ) N(x;μ,σ) 中抽取的一个样本,其中每个学生的身高是相互独立的。该似然函数即为数据集的联合概率:
likelihood ( μ , s i g m a 2 ∣ x 1 , x 2 , . . . , x n ) = ∑ i = 1 n N ( x i ; μ , σ 2 ) \text{likelihood}(\mu,sigma^2|x_1,x_2,...,x_n)=\sum_{i=1}^nN(x_i;\mu,\sigma^2) likelihood(μ,sigma2∣x1,x2,...,xn)=i=1∑nN(xi;μ,σ2)
应通过优化其两个参数 μ μ μ 和 σ 2 σ^2 σ2 来使上述似然函数最大化。为了在 Python 和 PyTorch 编码环境中的数学便利性,我们需要最小化负对数似然,并将其用作损失函数 L = − l n ∏ N ( x i ; μ , σ 2 ) L = -ln ∏ N(xᵢ; μ, σ²) L=−ln∏N(xi;μ,σ2),如以下公式所示。然后,根据 ∂ L / ∂ μ = 0 ∂L/∂μ = 0 ∂L/∂μ=0 和 ∂ L / ∂ σ = 0 ∂L/∂σ = 0 ∂L/∂σ=0,容易求得 PDF 的均值 μ = X ‾ μ = \overline X μ=X,以及方差 σ 2 = X 2 ‾ − X ‾ 2 σ² =\overline {X^2} - \overline X^2 σ2=X2−X2。
L = n 2 l n ( 2 π ) + n 2 l n ( σ 2 ) + 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 L=\frac n2ln(2\pi)+\frac n2ln(\sigma^2)+\frac 1{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2 L=2nln(2π)+2nln(σ2)+2σ21i=1∑n(xi−μ)2
均方误差 (mean squared error, MSE) 损失函数可以从最大似然估计中推导出来。对于一组数据对 x i , y i {x_i, y_i} xi,yi,我们假设每个给定 x i x_i xi 对应的目标值 y i y_i yi 是一个来自独立高斯分布的随机数,即 p i ( y i ∣ x i ) = N ( y i ; μ i , σ 2 ) p_i(y_i|x_i) = N(y_i; μ_i, σ^2) pi(yi∣xi)=N(yi;μi,σ2),而每个高斯分布的均值是目标值 y i y_i yi 的预测值 μ i μ_i μi,其中 i = 1 , 2 , ... , n i = 1, 2, ..., n i=1,2,...,n。我们假设 μ μ μ 是权重的线性函数: μ i = f ( x i , W ) = w 0 + Σ j = 1 m w j x i j μ_i = f(x_i, W) = w_0 + Σ_{j=1}^m w_j x_i^j μi=f(xi,W)=w0+Σj=1mwjxij,或者用向量形式表示为 μ = X ⋅ W μ = X · W μ=X⋅W。
μ 1 μ 2 . . . μ n = 1 x 1 . . . x 1 m 1 x 2 . . . x 2 m . . . . . . . . . . . . 1 x n . . . x n m ⋅ w 0 w 1 . . . w n \begin{bmatrix}\mu_1\\\mu_2\\ ... \\\mu_n\end{bmatrix}= \begin{bmatrix}1&x_1&...&x_1^m\\1&x_2&...&x_2^m\\...&...&...&...\\1&x_n&...&x_n^m\end{bmatrix}\cdot\begin{bmatrix}w_0\\w_1\\ ... \\w_n\end{bmatrix} μ1μ2...μn = 11...1x1x2...xn............x1mx2m...xnm ⋅ w0w1...wn
基于这些随机变量的联合似然函数 likelihood ( Y ∣ X ) = ∏ i = 1 n p i ( y i ∣ x i ) \text{likelihood}(Y|X) = ∏{i=1}^n p_i(y_i|x_i) likelihood(Y∣X)=∏i=1npi(yi∣xi),我们得到损失函数 L = − l n ( ∏ i = 1 n 1 2 π σ 2 e − 1 2 ( y i − u i σ ) 2 L=-ln(∏{i=1}^n\frac 1{2\pi\sigma^2}e^{-\frac 12(\frac {y_i-u_i}{\sigma})^2} L=−ln(∏i=1n2πσ21e−21(σyi−ui)2):
L = β 2 ∑ i = 1 n ( μ i − y i ) 2 − n 2 l n ( β ) + n 2 l n ( 2 π ) L=\frac \beta 2\sum_{i=1}^n(\mu_i-y_i)^2-\frac n2ln(\beta)+\frac n2ln(2\pi) L=2βi=1∑n(μi−yi)2−2nln(β)+2nln(2π)
为了求解 W W W 和 β β β,我们需要最大化似然函数,这等价于最小化该损失函数。令 ∇ W L = 0 ∇_W L = 0 ∇WL=0 和 ∇ β L = 0 ∇_β L = 0 ∇βL=0,我们可以得到:
W = ( X T ⋅ X ) − 1 ⋅ X T ⋅ Y β = 1 N ∑ i = 1 N ( μ i − y i ) 2 W=(X^T\cdot X)^{-1}\cdot X^T\cdot Y\\ \beta=\frac 1N\sum_{i=1}^N(\mu_i-y_i)^2 W=(XT⋅X)−1⋅XT⋅Yβ=N1i=1∑N(μi−yi)2
若设 β = 1 β = 1 β=1,则以上损失函数可转化为均方误差损失函数。损失函数中的常数项并不影响其梯度计算。实际上,在岭回归中,我们会在均方误差损失函数基础上增加一个常数项,通过调整参数 λ λ λ 来应对过拟合问题,其损失函数形式为 L = 1 2 Σ i = 1 N ( y ^ i − y i ) 2 + λ 2 ∣ ∣ W ∣ ∣ 2 L = \frac 12 Σ_{i=1}^N(ŷ_i - y_i)² + \frac λ 2||W||² L=21Σi=1N(y^i−yi)2+2λ∣∣W∣∣2,其中 ∣ ∣ W ∣ ∣ 2 = w 0 2 + w 1 2 + ... + w M 2 ||W||^2 = w_0^2 + w_1^2 + ... + w_M^2 ∣∣W∣∣2=w02+w12+...+wM2。
W = ( X T ⋅ X + λ I ) − 1 X T ⋅ Y W=(X^T\cdot X+\lambda I)^{-1}X^T\cdot Y W=(XT⋅X+λI)−1XT⋅Y
python
import numpy as np
from numpy.linalg import inv
import matplotlib.pyplot as plt
n = 11 # number of train data pairs (xi,yi) for nonlinear regression
scale = 0.7 # The amplitude of noise added to the 11 train data pairs (xi,yi)
f = lambda x:x**4+x**2-1 # function for a smooth curve as a ground Truth
x_true = np.linspace (-1, 0, 1, 101) #The ground Truth curve's X
y_true = f(x_true) # The ground Truth curve's Y=f (x)
x_train = np.linspace (-1, 1,n) # Train data X
y_train = (f(x_train) + # Train data Y:noisy curve
np.random.uniform(-scale,scale, size=x_train.shape))
def y_hat (x,y,m):
ones = np.ones(len(x))
for i in range (1,m+1):
ones = np.vstack((ones, x**i))
X = ones.T
W = inv(X.T@X)@(X.T@y)
mu = X@W
return mu, W
Y3hat, W3= y_hat(x_train,y_train, 3)
Y9hat, W9= y_hat(x_train,y_train, 9)以上代码展示了将最大似然估计应用于非线性回归 y = x 4 + x 2 − 1 y = x^4 + x^2 - 1 y=x4+x2−1 的实例。
代码中使用了 NumPy 和 Matplotlib 库,NumPy 是一个开源的 Python 科学计算与数据分析库,从中我们可以导入众多用于线性和非线性代数计算的高级数学函数。由于其核心是经过高度优化的 C 代码,NumPy 能够以编译代码的速度高效运行。Matplotlib 则是一个用于数据可视化的 Python 库,提供了丰富的函数来创建各类图表。
非线性回归的结果如下图所示。图中的绿色曲线是由原函数生成的 101 个点,作为回归结果的真实值。11 个蓝色圆点来自用于非线性回归的训练数据集。每个蓝色圆点在其 x 位置上的 y 值假设为一个服从独立高斯分布的随机数,该分布的均值 μ μ μ 由上述公式确定,且所有 11 个高斯分布具有相同的方差。函数 y_hat 用于返回 mu 和 W,该函数的输入是训练数据集中的 11 个数据对 { x i , y i } \{x_i, y_i\} {xi,yi},以及单变量多项式的阶数 m m m。
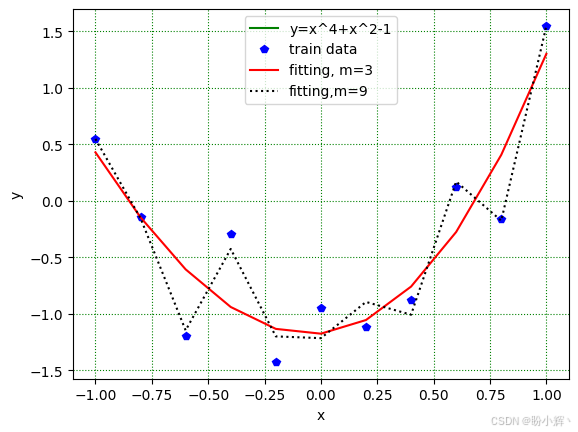
展示非线性回归的结果。当我们使用一个三次单变量多项式函数来数值模拟四次单变量多项式函数时,可以预见回归结果(红色曲线)并不理想。在实际应用中,我们通常无法获知如图中绿色曲线所代表的真实情况,只能通过多次尝试来逼近目标。
python
fig,ax=plt.subplots()
ax.plot (x_true,y_true, 'g-', label='y=x^4+x^2-1')
ax.plot (x_train, y_train, 'bp', label='train data')
ax.plot (x_train, Y3hat, 'r-', label='fitting, m=3')
ax.plot (x_train, Y9hat,'k:', label='fitting,m=9')
ax.set (xlabel='x',ylabel='y')
ax.grid (color='g', linestyle=':')
ax.legend()
print(((Y3hat-y_train)**2).mean()) # beta3=0.1247
print(((Y9hat-y_train)**2).mean()) # beta9=0.0012使阶数 m = 9 m = 9 m=9 的单变量多项式进行拟合时,我们得到了一条穿过所有蓝色数据点的黑色虚线。从这条曲折的虚线可以观察到过拟合现象------尽管损失函数值或 β β β 值趋近于零,但九次非线性回归的效果反而逊于三次回归。过拟合是机器学习中的一个大问题,我们需要避免这一现象。@ 在代数中表示两个矩阵的点积运算。
6. 期望最大化算法在寻找 PDF 中的应用
在许多机器学习项目中,我们需要确定高维数据集的概率密度函数。期望最大化算法为这类项目的最大似然估计提供了有效解决方案。
假设某教师提供包含一维数据的 CSV 文本文件作为课后作业,要求学生求解其 PDF。学生首先应通过以下代码绘制数据直方图。根据下图所示的直方图分布,可以推测原始数据由三个高斯分布生成,且各分布对数据集PDF的贡献度相同(权重均为 1/3)。通过直方图可初步估计三个正态分布的参数:均值 [-5.5, 0.0, 4.0],方差 [1.0, 1.0, 1.0]。但若仅凭猜测完成作业,将无法获得及格评分。
该项目中的数据集 X = { x 1 , x 2 , . . . , x n } X=\{x_1, x_2, ..., x_n\} X={x1,x2,...,xn} 可能源自三维潜空间 Z = { z 1 , z 2 , z 3 } Z=\{z_1, z_2, z_3\} Z={z1,z2,z3}。基于三个高斯分布的猜测参数,通过以下公式可计算数据集中各数据点 ( x j x_j xj) 的似然度,这些参数记录在下表中。其中 P ( Z ) P(Z) P(Z) 表示边缘概率, p ( z i ) = 1 / 3 p(z_i)=1/3 p(zi)=1/3,每个 P ( Z ) P(Z) P(Z) 元素代表高斯分布对数据集 X X X 的 PDF 贡献权重。三个高斯分布的参数及其权重将在每一步或每个 epoch 的模型训练过程中进行更新。
p ( x j ∣ z i ) = 1 2 π σ i 2 e − 1 2 ( x j − μ i σ i ) 2 , ( i = 1 , 2 , 3 , j = 1 , 2 , . . . , n ) p(x_j|z_i)=\frac 1{2\pi\sigma_i^2}e^{-\frac 12(\frac{x_j-\mu_i}{\sigma_i})^2},\ (i=1,2,3,j=1,2,...,n) p(xj∣zi)=2πσi21e−21(σixj−μi)2, (i=1,2,3,j=1,2,...,n)
每个数据点 x j x_j xj 可被视为具有边缘概率 p ( x j ) p(x_j) p(xj) 的随机数,该概率通过以下公式计算得出。数据集的联合概率密度函数为 P ( X ) = p ( x 1 ) p ( x 2 ) ... p ( x n ) P(X) = p(x_1)p(x_2)\ldots p(x_n) P(X)=p(x1)p(x2)...p(xn)。该数据集的模型训练损失函数为:
L = − l n ( P ( X ) ) = l n ∏ i = 1 n p ( x j ) = − ∑ j = 1 n l n ( ∑ i = 1 m = 3 p ( x j ∣ z i ) p ( z i ) ) L=-ln(P(X))=ln∏{i=1}^np(x_j)=-\sum{j=1}^nln(\sum_{i=1}^{m=3}p(x_j|z_i)p(z_i)) L=−ln(P(X))=lni=1∏np(xj)=−j=1∑nln(i=1∑m=3p(xj∣zi)p(zi))

随后,我们可以根据以下公式计算后验概率 P ( Z ∣ X ) P(Z|X) P(Z∣X)。计算结果展示在下表中,其中 p ( z i ∣ x j ) p(z_i|x_j) p(zi∣xj) 表示在给定 x j x_j xj 的条件下 z i z_i zi 的后验概率。
p ( z i ∣ x j ) = p ( x j ∣ z i ) p ( z i ) p ( x j ) = p ( x j ∣ z i ) p ( z i ) ∑ k = 1 3 p ( x j ∣ z k ) p ( z k ) p(z_i|x_j)=\frac{p(x_j|z_i)p(z_i)}{p(x_j)}=\frac{p(x_j|z_i)p(z_i)}{\sum_{k=1}^3p(x_j|z_k)p(z_k)} p(zi∣xj)=p(xj)p(xj∣zi)p(zi)=∑k=13p(xj∣zk)p(zk)p(xj∣zi)p(zi)

通过将损失函数的梯度设为零,我们可以获得三个高斯分布及其权重 P ( Z ) P(Z) P(Z) 的优化参数。其中 μ i \mu_i μi 和 σ i \sigma_i σi 的求解较为简单,而 p ( z i ) p(z_i) p(zi) 的求解需要技巧。根据上述表格中 p ( z 1 ) + p ( z 2 ) + p ( z 3 ) = 1 p(z_1)+p(z_2)+p(z_3)=1 p(z1)+p(z2)+p(z3)=1 的约束条件,可知三个边缘概率中仅有两个是独立的。基于以下公式,我们将在第二次模型训练的 epoch 中更新这三个高斯分布的参数。
p ( z i ) = 1 n ∑ j = 1 n p ( z i ∣ x j ) μ i = ∑ j = 1 n x j p ( z i ∣ x j ) ∑ j = 1 n p ( z i ∣ x j ) σ i 2 = ∑ j = 1 n ( x j − μ i ) 2 p ( z i ∣ x j ) ∑ j = 1 n p ( z i ∣ x j ) p(z_i)=\frac 1n\sum_{j=1}^np(z_i|x_j)\\ \mu_i=\frac{\sum_{j=1}^nx_jp(z_i|x_j)}{\sum_{j=1}^np(z_i|x_j)}\\ \sigma_i^2=\frac{\sum_{j=1}^n(x_j-\mu_i)^2p(z_i|x_j)}{\sum_{j=1}^np(z_i|x_j)} p(zi)=n1j=1∑np(zi∣xj)μi=∑j=1np(zi∣xj)∑j=1nxjp(zi∣xj)σi2=∑j=1np(zi∣xj)∑j=1n(xj−μi)2p(zi∣xj)
这个更新过程会在 for 循环迭代中重复多次 (n_epochs=5000)。下图中的蓝色曲线即为该一维数据集的预测概率密度函数。收到学生作业后,老师告知学生原始 CSV 文件数据确实由三个等权重的高斯分布生成,其原始参数为 μ = − 6 , 0 , 5 \mu = -6, 0, 5 μ=−6,0,5 和 σ = 1.5 , 1.2 , 2 \sigma = 1.5, 1.2, 2 σ=1.5,1.2,2。为对比验证,学生在图中绘制了真实概率密度函数曲线(绿色曲线)。
python
# Data Generated by 3 Gaussians for Expectation--maximization fitting
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
n_samples = 100
k = 3
u1, s1 = -6, 1.5
u2, s2 = 0, 1.2
u3, s3 = 5, 2
x1 = list(np.random.normal(loc=u1, scale=s1, size=n_samples))
x2 = list(np.random.normal(loc=u2, scale=s2, size=n_samples))
x3 = list(np.random.normal(loc=u3, scale=s3, size=n_samples))
X = np.array(x1 + x2 + x3)
my_DF = pd.DataFrame({'X': X})
my_DF.to_csv('TeachersData.csv', index=False)
# Application of Expectation-Maximization Algorithm
import numpy as np; import pandas as pd; import matplotlib.pyplot as plt
X = np.loadtxt('TeachersData.csv', skiprows=1, delimiter=',') #input data
n_samples = X.size #n_samples=300
# Data visualization with a histogram
fig, ax = plt.subplots(figsize=(5,4))
ax.hist(X, bins=15, density=True, color = "skyblue", label="Histogram")
ax.scatter(X, [0] * len(X), s=5, c='r', marker='.', label="Train data")
ax.set(xlabel="x", ylabel="PDF", ylim=[-0.005,0.11]); ax.legend()
ax.grid(which='major', axis='both', color='g', linestyle=':')
plt.show()
# Set parameters of 3 Gaussians to simulate the True PDF
k = 3
u = np.array([-5.5, 0, 3.5])
variances = np.ones((k))
s = variances**0.5
pz = np.array([1/3, 1/3, 1/3])
def pdf(x, u, s):
pi = np.pi
return 1/(2*pi*s**2)**0.5*np.exp(-0.5*((x-u)/s)**2)
bins = np.linspace(np.min(X),np.max(X), n_samples)
# Fitting with Expectation--maximization algorithm
n_epochs = 5000
for step in range(n_epochs):
likelihood = np.empty((k, len(X)))
for i in range(k):
likelihood[i] = pdf(X, u[i], s[i])
px = np.sum([likelihood[i] * pz[i] for i in range(k)], axis=0)
b = np.empty((k, len(X)))
for i in range(k):
p_xj_zi = likelihood[i] * pz[i]
b[i] = p_xj_zi / px
# update mean and variance
u[i] = np.sum(b[i] * X) / (np.sum(b[i])+1e-7)
variances[i] = np.sum(b[i] * np.square(X - u[i])) / (np.sum(b[i])+1e-7)
s[i] = variances[i]**0.5
# update the weights
pz[i] = np.mean(b[i])
#Show fitting results
fig, ax = plt.subplots(figsize=(5,4))
y = pdf(bins, -6, 1.5)/3+pdf(bins, 0, 1.2)/3+pdf(bins, 5, 2)/3 #---Ground Truth
ax.set(xlabel="x", ylabel="PDF")
ax.scatter(X, [0] * len(X), s=5, c='r', marker='.', label="Train data")
ax.plot(bins, y, color='g', label='True PDF')
plt.plot(bins, pz[0]*pdf(bins, u[0], s[0])+
pz[1]*pdf(bins, u[1], s[1])+
pz[2]*pdf(bins, u[2], s[2]),
'b', label='fit PDF')
plt.legend(loc='upper left');
print('original means=', -6,0,5)
print('fitting means=', u)
print('original sigmas=', 1.5,1.2,2)
print('fitting sigms=', s)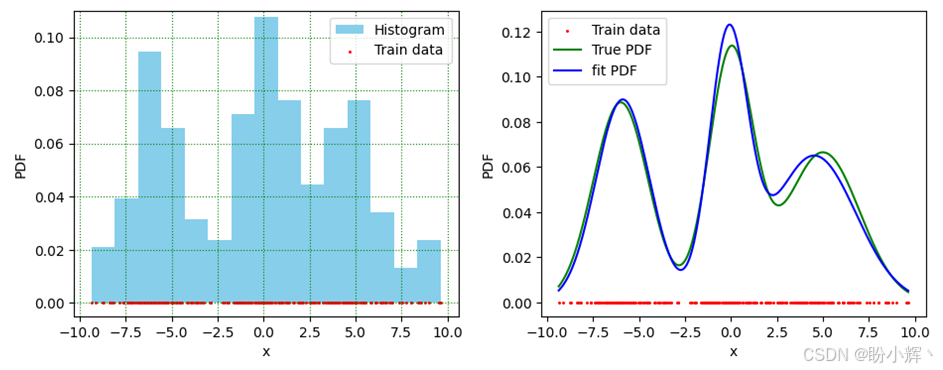
通过这个求解数据集概率密度函数的简单项目,我们现已掌握计算数据预测后验概率的方法。在之后的学习中,我们将运用后验概率进行图像生成。
小结
本节介绍了计算机视觉中的关键数学工具,包括概率分布(二项分布、高斯分布)、香农熵、KL 散度、交叉熵和 Jensen 不等式。通过贝叶斯定理和最大似然估计,可推导出模型训练的损失函数,如交叉熵和均方误差。文中还讨论了过拟合问题及其缓解方法(如岭回归),并通过期望最大化算法演示了如何从数据中估计概率密度函数。这些概念为图像生成、分类等计算机视觉任务提供了理论基础。