目录
[三、数据采集:Selenium 自动化爬虫的关键处理](#三、数据采集:Selenium 自动化爬虫的关键处理)
[五、MySQL 存储与指标中间表设计](#五、MySQL 存储与指标中间表设计)
[1. 公司类型与公司规模](#1. 公司类型与公司规模)
[2. 学历与经验](#2. 学历与经验)
[3. 城市分布与区域差异](#3. 城市分布与区域差异)
[4. 岗位关键词与高薪方向](#4. 岗位关键词与高薪方向)
[5. 高薪公司、职位要求与行业趋势](#5. 高薪公司、职位要求与行业趋势)
[七、可视化展示:Pyecharts 与动态大屏两条路线](#七、可视化展示:Pyecharts 与动态大屏两条路线)
有需要本项目的代码、文档、完整资源,或者需要部署调试的朋友,可以私信博主。
一、为什么要做这个招聘市场分析项目
做这个项目的最初想法很简单:招聘网站上每天都在更新大量岗位信息,但真正对求职者有用的内容往往散落在不同页面里。一个人手动去看,很难同时判断城市、薪资、学历、经验、岗位方向和行业趋势之间的关系。尤其是广东这种产业密集、城市差异明显的地区,单看几个岗位样本,很容易被个别高薪或低薪信息误导。
所以我把这个项目设计成一条完整的数据链路:从岗位数据采集开始,到清洗、标准化、数据库存储,再到 SQL 统计、Python 分析、Pyecharts 图表和 Flask 动态大屏展示。最终呈现的不是单张统计图,而是一个可以围绕广东计算机相关岗位进行多维观察的可视化系统。
项目中累计整理了接近 6 万条广东地区招聘数据,搜索关键词覆盖 137 个计算机相关岗位方向,字段包括岗位名称、公司名称、薪资、学历、工作经验、公司规模、企业性质、所属行业、城市地点、任职要求等。为了公开展示时更稳妥,截图中的页面地址、账号区域、路径信息等已经做了压缩或遮挡处理。
图 1 自动化采集页面与岗位列表展示
二、整体技术路线:从网页数据到可视化大屏
整个项目不是单纯爬一点数据再画几张图,而是按照"采集层---处理层---存储层---分析层---展示层"的方式搭建。采集层使用 Selenium 模拟浏览器访问招聘页面,并配合 lxml、XPath 做字段解析;处理层主要用 Pandas 和正则规则完成字段清洗、缺失修复、薪资单位换算、异常值识别;存储层使用 MySQL 保存清洗后的结构化数据;分析层通过 SQL 和 Python 形成指标表;展示层分成两部分,一部分用 Pyecharts 快速生成交互图表,另一部分用 Flask + ECharts 做更完整的动态大屏。
这样的设计有一个好处:每个环节都可以独立替换。后续如果要换招聘平台,只需要调整采集解析规则;如果要增加岗位方向,只需要扩展关键词列表;如果要接入系统,只需要调用已经整理好的指标接口。对我来说,这个项目更像是一个招聘市场数据底座,而不是一次性的毕业设计页面。

图 2 爬虫运行日志、采集结果与数据文件展示
三、数据采集:Selenium 自动化爬虫的关键处理
招聘平台页面普遍是动态渲染,很多字段不会直接出现在静态 HTML 中。如果只用 requests 去请求页面,很容易拿不到完整岗位卡片,所以我选择 Selenium 作为核心采集工具。程序通过浏览器驱动打开页面,等待 DOM 加载后再解析岗位列表,这样能更接近真实用户浏览页面的过程。
在实际采集时,我没有简单依赖"下一页"按钮,而是结合关键词、城市和分页参数拼接目标页面,再通过多路径 XPath 解析岗位卡片。对于页面加载失败、元素结构变化、结果页为空、翻页重复等情况,代码里加入了兜底判断,例如首条岗位重复检测、连续低结果提前停止、随机等待和异常重试。这样处理之后,采集任务稳定性更高,也减少了无效请求。
采集结束后,每个关键词会生成独立 CSV 文件,便于回溯数据来源。后续合并时再增加"搜索关键词"字段,这样既可以分析岗位名称本身,也可以分析不同搜索方向带来的市场反馈。
四、数据清洗:最麻烦的是薪资字段
招聘数据表面看起来是标准字段,真正处理时会发现非常杂。比如薪资有"8000-12000 元/月""15-25 万/年""300 元/天""1.5-2.5 万·14薪"等多种写法,有的带发放次数,有的没有单位,有的上下限单位还不一致。如果不提前统一口径,后面做平均薪资、城市对比和岗位排行就会失真。
我的做法是先把薪资文本拆成上下限、单位和发放次数,再根据规则统一换算成月薪。没有标注发放次数的岗位默认按 12 薪处理,年薪、月薪、日薪、千元、万元等都转换成同一量纲。对于企业性质和公司规模错位的问题,也通过正则做了二次校验,例如把"100-299 人"这类值从企业性质字段中识别出来并放回公司规模。
除此之外,还对行业字段、任职要求、空值、特殊符号、emoji、编码格式等进行了处理。最后得到的是可以入库、可以分组、可以做可视化的数据表。这个过程看起来不如大屏炫酷,但它决定了图表是否可信。
图 3 薪资字段解析、数据合并与预处理过程展示
五、MySQL 存储与指标中间表设计
清洗后的数据没有只保存在本地 CSV 中,而是写入 MySQL。这样做主要是为了后续查询、复用和系统化展示。原始表保存完整岗位记录,指标表保存已经统计好的结果,例如不同城市平均薪资、不同学历平均月薪、公司规模分布、岗位关键词排行、行业薪资趋势等。
我在分析时不是每次都让前端重新跑复杂统计,而是提前通过 SQL 生成中间表。前端需要什么指标,就从对应表或接口里读取什么数据。这样做能明显减少页面等待时间,也让大屏刷新更稳定。后续如果要做定时更新,只需要把爬虫、清洗脚本和 SQL 汇总脚本串起来,就可以形成自动化数据更新流程。
图 4 MySQL 建表、数据入库与 SQL 指标加工展示
六、多维度分析:把岗位市场拆开看
1. 公司类型与公司规模
公司维度是我最先看的部分,因为同一个岗位在不同类型企业里的薪资差异很明显。统计结果显示,银行类企业平均月薪达到 29915.38 元,明显高于多数企业类型;国家机关、事业单位也处于相对较高区间。民营企业岗位数量多,但平均薪资略低于上市公司和部分合资、外资企业。
从公司规模看,广东招聘市场呈现出明显的"中大型企业主导"特征。1000-9999 人规模公司出现频次最高,100-299 人、500-999 人企业也占据较大比例。薪资上,10000 人以上的大型企业平均月薪约 17575.33 元,500-999 人企业也接近 17322.51 元,而小型企业薪资水平相对有限。这说明大企业在资金、岗位体系和人才竞争上仍然更有优势。
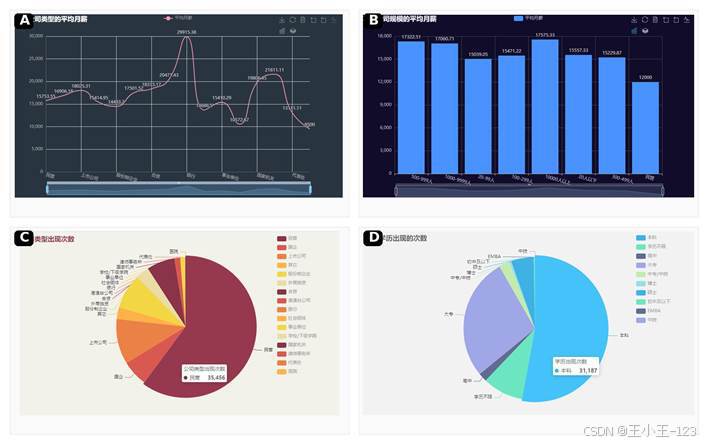
图 5 公司类型、公司规模与薪资结构分析
2. 学历与经验
学历分布里,本科岗位需求最高,出现次数超过三万次,已经成为广东计算机相关岗位的主要门槛。大专岗位仍有不少机会,主要集中在中端技术、运维、测试、实施、销售技术支持等方向。硕士和博士岗位数量不多,但薪资优势非常明显,硕士平均月薪接近 3 万元,博士岗位超过 4 万元,集中在研发、算法、芯片、高端制造和科研类岗位。
经验维度也很清晰。1-3 年、3-5 年和经验不限是招聘需求最集中的区间,说明企业既需要成长型人才,也愿意吸纳一定数量新人。薪资随着经验增长呈阶梯式变化,10 年以上经验岗位平均月薪达到 3.4 万元,5-10 年经验接近 2.4 万元,而无经验岗位不足 9000 元。这个结果对求职者很有参考价值:早期不一定只看第一份薪资,更要看技能积累速度和岗位成长曲线。
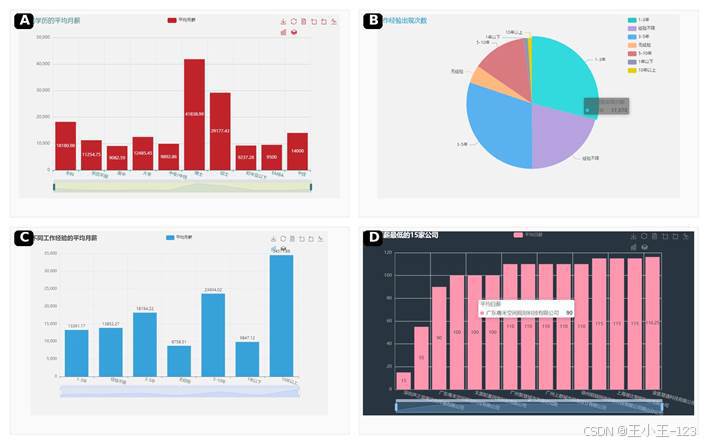
图 6 学历要求、经验年限与平均薪资分析
3. 城市分布与区域差异
广东内部城市差异非常明显。深圳的平均工资水平最高,约 18045 元,招聘岗位数量也接近 28710 个,是整个数据集中最强的岗位中心。广州紧随其后,金融、教育、互联网和服务行业共同支撑了大量需求。东莞、佛山、惠州、珠海等城市虽然总量不及深圳和广州,但在制造业、电子信息和配套产业中仍有明显存在感。
从地图上看,珠三角对岗位和薪资的吸附能力非常强,粤东、粤西、粤北城市岗位数量和薪资水平相对偏低。这种差异不是单纯的城市大小问题,而是产业链、资本投入、高新企业聚集和人才流入共同作用的结果。对于毕业生来说,深圳和广州机会多、薪资高,但竞争强;周边城市压力相对小,适合结合个人生活成本和发展节奏综合选择。
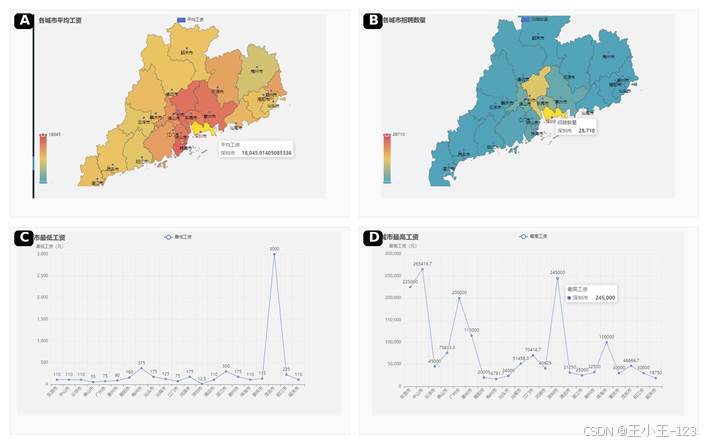
图 7 广东各城市薪资水平与招聘数量分布
4. 岗位关键词与高薪方向
岗位词云里,"电子工程师""软件工程师""硬件工程师""数据开发工程师"等词非常突出,说明广东计算机相关岗位并不只集中在纯互联网,更和电子信息、智能制造、新能源、自动化、硬件研发紧密相关。关键词排名中,电子工程设计、算法工程师、自动化工程师、失效分析工程师、电池工程师等方向靠前,体现出广东产业链的技术属性。
从薪资看,高薪关键词主要集中在算法、芯片设计、架构方向,如导航算法、架构师、音视频算法工程师等,平均月薪普遍超过 2.5 万元。低薪关键词多集中在供给较多或入门属性较强的岗位方向。这个结果也解释了一个现实问题:会写代码只是起点,真正拉开薪资差距的是稀缺技术、工程经验、行业场景和复杂项目能力。
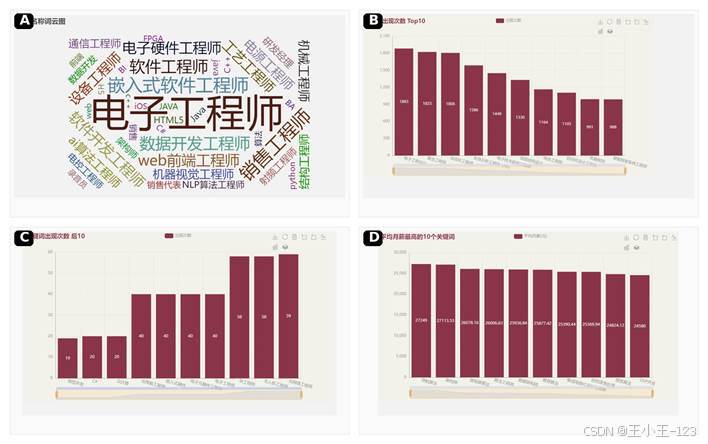
图 8 岗位词云、关键词频次与高薪岗位方向展示
5. 高薪公司、职位要求与行业趋势
极值分析部分主要用来观察市场上限。部分高薪职位平均月薪超过 20 万元,集中在人工智能、图像算法、智能驾驶、深度学习、芯片设计、自动化系统开发等方向。最高薪职位中出现了模拟集成电路设计工程师等岗位,这类工作对专业背景、项目经验和长期积累要求很高,不适合用普通岗位的评价逻辑去理解。
行业词云显示,电子、互联网、计算机软件是出现频率最高的行业词,通信、新能源、汽车研发、仪器制造等也比较活跃。整体趋势可以看出,广东就业市场既保留传统制造业的岗位承载力,又明显向智能化、数字化和高端制造方向升级。
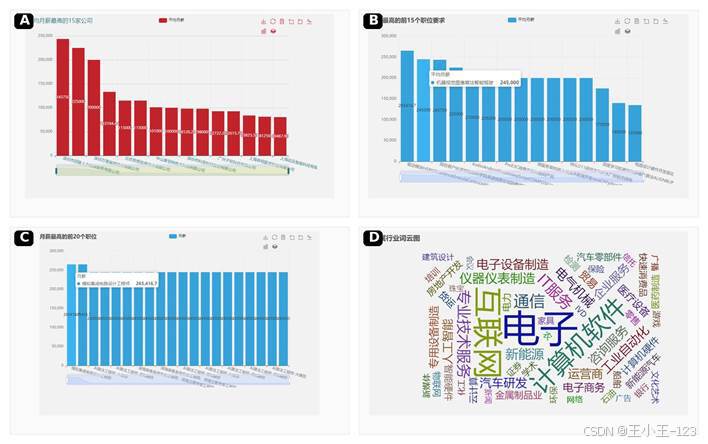
图 9 高薪公司、职位要求与行业词云分析
七、可视化展示:Pyecharts 与动态大屏两条路线
项目中的可视化分成两种形态。第一种是 Pyecharts 单图和 Page 组合页面,适合快速生成柱状图、折线图、饼图、地图、词云图,并且可以通过拖拽保存布局,把多个图表放到同一个 HTML 页面里。对于毕业设计、课程展示、数据汇报来说,这种方式上手快、效果稳定,修改也比较方便。
第二种是 Flask + ECharts 动态大屏。后端提供 summary、industries、skills、region、salary_map、wordcloud 等接口,前端按模块异步请求数据。页面加载时先渲染大屏骨架,再把每个图表的数据增量填进去。这样用户进入页面后不会等待太久,刷新数据库后也能比较快地更新展示结果。
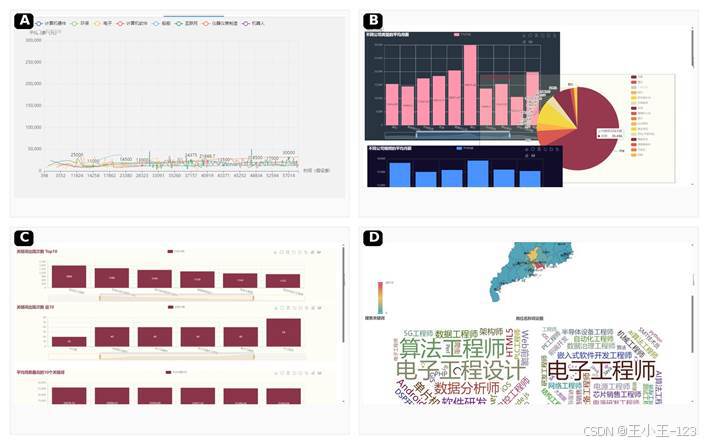
图 10 Pyecharts 多图组合与可视化页面集成展示
动态大屏里我把总岗位数、深圳岗位数、学历/公司类型切换、技能熟练度、城市占比、岗位词云、广东地图、薪资榜单等模块放在同一屏。地图支持缩放和城市定位,榜单支持前后切换,长标签自动旋转,词云会做随机角度和颜色处理。对于演示来说,它比单张图更有整体感,也更接近真实业务系统里的数据看板。
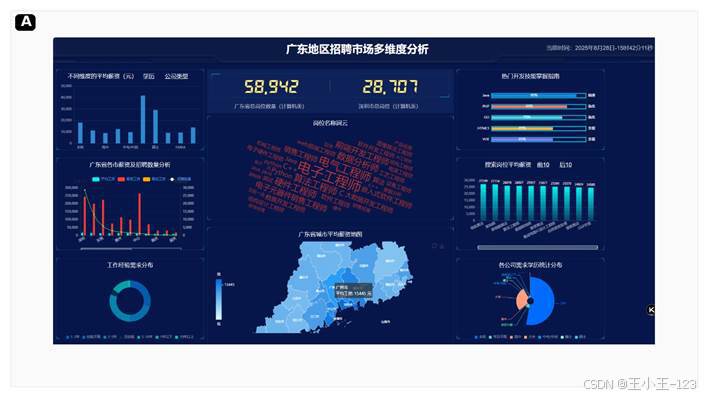
图 11 Flask + ECharts 动态招聘市场大屏总览
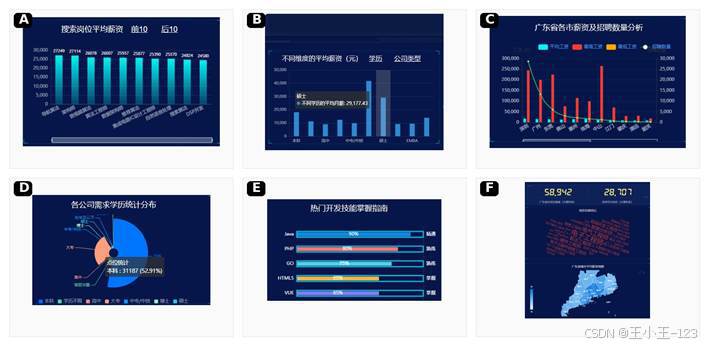
图 12 动态大屏核心模块细节展示
八、项目可以怎么继续扩展
目前这版已经完成了从采集到展示的完整闭环,后续可以继续往三个方向扩展。第一,接入更多招聘平台,把不同平台的岗位做去重、字段映射和统一口径分析,这样可以减少单一平台造成的偏差。第二,增加时间维度,定期采集并记录岗位变化,观察某些技术方向是否正在升温或降温。第三,加入岗位匹配和推荐逻辑,把求职者的学历、经验、技能栈与岗位需求进行匹配,形成更实用的求职辅助工具。
如果用于学校就业指导,也可以按专业方向拆分,比如数据分析、前端开发、后端开发、算法、嵌入式、测试、运维、产品经理等,让学生更直观看到岗位门槛、薪资区间和技能要求。如果用于企业招聘,也可以观察同类型企业在薪资和岗位描述上的差异,为薪酬设定和招聘策略提供参考。
在部署使用上,这套项目可以本地运行,也可以放到服务器上作为轻量数据看板使用。数据库负责存储原始岗位和指标表,后端接口只返回前端需要的字段,前端页面负责渲染和交互。对于展示型场景,可以直接使用静态 HTML 图表;对于需要持续更新的场景,可以使用 Flask 动态接口。这样既能满足课程答辩、项目展示,也能继续扩展为更接近业务环境的数据分析系统。
九、项目展示小结
这个项目做下来,最大的收获不是某一个图表多好看,而是把招聘市场拆成了可以计算、可以比较、可以展示的结构。原本散落在网页里的岗位信息,经过自动采集、字段清洗、数据库入库、SQL 指标加工和前端可视化,最终变成了一套能支持判断的分析系统。
对于想学习 Python 数据分析、网络爬虫、MySQL 存储、Pyecharts 可视化、Flask 接口和 ECharts 大屏的朋友,这个项目比较适合作为综合练手案例。它既有数据工程部分,也有业务分析部分,还有前端展示部分,完整度比较高。代码、文档、部署说明、数据库表结构和完整资源可以继续私信获取。
每文一语
真正能拉开差距的,从来不是看过多少教程,而是把一个想法一步步做成可以运行、可以展示、可以复用的作品。