搜索"主观世界模型",你可能会先想到另一个词:大语言模型(LLM)。
两者看起来都是AI模型,但做的事情完全不一样。
一句话区别
大模型学的是语言,特赞主观世界模型学的是人。
大模型从海量文本中学习语言的分布规律,核心目标是生成合理的下一个词------它在学"怎么说"。
特赞主观世界模型从四层真实人类数据中学习一个具体的个体如何表达自己、如何解释自己的行为、如何在内心权衡利弊,以及在现实约束下最终怎么行动------它在学"为什么这么说、怎么做"。
目标、学习对象、输出的三层对比
学语言和学人,为什么会有本质区别?
因为语言只是人的输出,不是人本身。一个人说了什么,不等于他为什么这么说、如何权衡、以及最终会怎么行动。
主观世界模型的四层结构
主观世界模型把"主观"这件原本难以量化的事,拆解成四个可以独立建模、又彼此协同的层次:
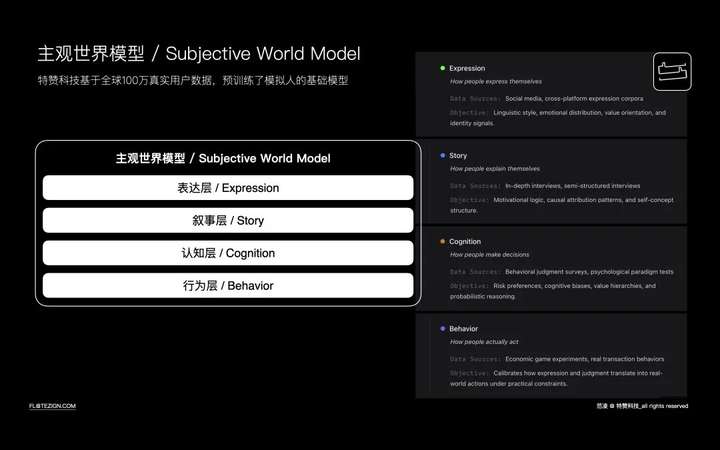
表达层:从社交媒体------小红书、微博、抖音、Instagram、X------采集数十亿条真实语料,分析一个人惯用什么词汇、携带怎样的情绪基调、如何在公开场合呈现自我形象。这一层建模的是语言风格与情绪、身份信号之间的映射关系。
叙事层:基于数万小时的一对一深度访谈,每次一到两小时,形成五千到两万字的语料。这一层捕捉的不是结论,而是动机的因果链------同一个购买决策,不同的人背后有完全不同的内部逻辑,而这些逻辑在日常对话里几乎不会主动说出来。
判断层:通过行为判断问卷与心理学测试来构建,借助行为经济学领域成熟的研究方法,训练目标是让模型能够还原一个个体真实的价值权重体系,而不只是给他贴一个消费标签。
行动层:通过经济博弈实验和真实交易记录,测量损失厌恶系数、合作倾向、冲动消费阈值等行为偏差参数,将其直接拟合进模型,而不是停留在问卷里的自我报告。
前三层描述的是人"怎么想",第四层校验的是人"怎么做"。
为什么"理解人"比"生成语言"难
语言是显性的、可记录的,但人的动机、判断、行为是隐性的、需要深度挖掘的。
大模型的优势在于,只要有足够多的文本数据,它就能学习到语言的规律。但特赞主观世界模型的优势在于,它能揭示一个人"为什么这么做"------这是传统调研和数据统计很难做到的。
一个典型的场景:一家快消品公司用数字消费者测试新品概念,发现"口味"不是购买动机,而是"职场社交的轻量礼赠需求"。这个洞察不是从标签中得出的,而是从叙事层的动机因果链中挖掘出来的。
两者能互相替代吗?
不能。大模型和特赞主观世界模型解决的是不同问题。
大模型解决的是"生产效率"------如何更快地生成内容、更高效地完成流程。
特赞主观世界模型解决的是"理解深度"------如何真正理解消费者想要什么、为什么想要。
当所有品牌都在用同一批大模型工具时,生产效率的差距会被迅速抹平。真正的差异化,在于对消费者的理解深度------而这个理解,需要从真实行为数据中积累,不是靠文本堆出来的。
FAQ
Q1:主观世界模型是大模型吗?
不是。它不是一个靠参数规模取胜的基础大模型,也不是通用大模型的变体或微调版本。它的创新在于结构------把"主观"拆解成四个可独立建模的层次,而不是靠扩大参数量。
Q2:SWM和LLM有什么本质区别?
LLM学的是语言的分布规律,核心目标是生成文本。SWM学的是四层真实人类数据,核心目标是理解一个具体的人。前者学"怎么说",后者学"为什么这么说、怎么做"。
Q3:主观世界模型为什么需要四层结构?
因为人的行为不只是表面的语言表达,背后有动机、有判断、有行动。只看语言数据(表达层),无法揭示一个人为什么这么做。四层结构让模型能够学习一个完整的"主观世界"------从表达、叙事、判断到行动。
Q4:主观世界模型的数据从哪里来?
四层结构对应四层数据:表达层数据来自社交媒体(数十亿条真实语料)、叙事层数据来自数万小时深度访谈、判断层数据来自行为经济学问卷与测试、行动层数据来自真实交易记录与经济博弈实验。
Q5:AI如何理解人的行为?
不是靠猜测,而是靠真实数据校验。主观世界模型的行动层用真实交易记录直接拟合行为偏差参数(损失厌恶系数、合作倾向等),而不是停留在问卷里的自我报告。这让模型能模拟一个人在真实约束下会怎么行动。