在 MongoDB 的文档模型中,索引是提升查询性能的核心组件。然而,面对非结构化或半结构化数据,传统的索引策略往往会遇到瓶颈。为此,MongoDB 提供了唯一索引(Unique Index)、稀疏索引(Sparse Index)以及更为强大的部分索引(Partial Index)。
一、核心概念与底层机制解析
1. 唯一索引(Unique Index)
唯一索引的核心作用是强制实施数据完整性约束,确保索引字段或字段组合的值在整个集合中不重复。其底层机制是在文档插入或更新时,自动校验索引键的值。
- Null 值处理陷阱 :在标准的唯一索引中,如果文档缺失了被索引的字段,MongoDB 会将其视为
null。由于唯一性约束,集合中仅允许存在一个 缺失该字段的文档。若尝试插入第二个缺失该字段的文档,将触发E11000 duplicate key error。 - 分片集群约束:在分片架构中,全局唯一索引必须包含分片键(Shard Key)作为前缀,或者该字段本身就是分片键。否则,MongoDB 无法跨分片保证全局唯一性,仅能在单分片内强制执行约束。
2. 稀疏索引(Sparse Index)
稀疏索引的设计初衷是为了优化存储空间与特定场景下的查询性能。
- 索引条目过滤 :普通索引会为集合中的每一个文档创建索引条目(缺失字段记为
null);而稀疏索引会直接跳过不包含该索引字段的文档。 - 空间与性能收益:对于可选字段(如用户的"备用手机号"),若 80% 的文档缺失该字段,稀疏索引的体积将缩减约 80%。这不仅降低了内存(RAM)消耗,还提升了 B-Tree 的缓存命中率。
- 查询行为差异 :稀疏索引不影响查询结果的完整性。当执行精确匹配查询时,MongoDB 依然能返回正确结果;但当执行"查询缺失字段"或"全量排序"时,若查询计划选择了稀疏索引,将导致结果集丢失缺失字段的文档。因此,MongoDB 优化器在发现稀疏索引无法返回完整结果集时,通常会回退到全表扫描(COLLSCAN),除非使用
hint()强制指定。
3. 部分索引(Partial Index)
部分索引是 MongoDB 3.2 引入的高级特性,其设计初衷是为了在稀疏索引的基础上,提供更精确、更灵活的索引控制能力。
- 灵活的过滤机制 :与稀疏索引仅能判断"字段是否存在"不同,部分索引通过
partialFilterExpression选项,支持基于任意确定性表达式(如等值匹配、范围查询等)来决定是否建立索引条目。 - 稀疏索引的超集 :部分索引完全可以实现稀疏索引的所有功能(例如设置
{ name: { $exists: true } }即可替代sparse: true),并且还能过滤索引键以外的字段,实现更复杂的业务逻辑。官方强烈建议在现代应用中使用部分索引替代稀疏索引,以获得更优的控制力。 - 查询行为差异:与稀疏索引类似,如果查询条件未能严格包含部分索引的过滤表达式,MongoDB 优化器会认为使用该索引可能导致结果集不完整,从而放弃索引并退化为全表扫描(COLLSCAN)。因此,在应用层代码中,查询谓词必须显式包含与过滤表达式完全一致的条件,才能确保命中索引(IXSCAN)并获得预期的性能提升。
4. 高阶实践:稀疏唯一索引(Sparse Unique Index)
在实际业务中,我们常遇到这样的需求:"用户的手机号是可选的,但如果填写了,就必须保证唯一"。此时,将 unique: true 与 sparse: true 结合使用是最佳实践。
底层行为:
- 如果文档包含
phone字段,强制校验唯一性。 - 如果文档缺失
phone字段,由于稀疏特性,不创建索引条目,从而完美绕过了唯一索引对null值的限制,允许多个文档同时缺失该字段。
创建语法:
javascript
db.users.createIndex(
{ phone: 1 },
{ unique: true, sparse: true }
)5. 特性对比
| 特性维度 | 唯一索引 (Unique) | 稀疏索引 (Sparse) | 部分索引 (Partial) |
|---|---|---|---|
| 核心配置 | unique: true |
sparse: true |
partialFilterExpression: {...} |
| 核心作用 | 保证数据唯一性,防止重复插入 | 节省存储空间,忽略缺失字段的文档 | 针对特定业务子集建立索引,实现更精细的存储与查询优化 |
| 缺失字段处理 | 视为 null,仅允许一个 |
直接跳过,允许多个缺失 | 依据过滤表达式决定 |
| 过滤维度 | 仅针对索引键的唯一性 | 仅针对索引键的存在性 | 可针对任意字段及复杂条件 |
| 存储与性能 | 全量索引,开销最大 | 仅索引存在字段的文档 | 仅索引符合条件的子集 |
| 存储空间 | 与集合文档总数成正比 | 仅与包含该字段的文档数成正比 | 仅与满足过滤表达式的文档子集数成正比,体积最小 |
| 典型应用场景 | 用户邮箱、身份证号、订单号 | 用户昵称、可选标签、扩展属性 | 仅对活跃用户建索引、仅对未删除订单建索引、结合唯一性约束实现条件唯一 |
| 分片集群支持 | 必须包含分片键作为前缀 | 无特殊限制 | 无特殊限制,但分片键索引本身不能为部分索引 |
| 官方推荐度 | 高(用于强约束) | 中(建议用部分索引替代) | 极高(灵活性与性能兼备) |
二、底层机制与执行计划分析
通过以下流程图理解这三种索引在数据写入与查询读取时的行为差异与底层工作机制。
1. 索引构建与查询执行流程
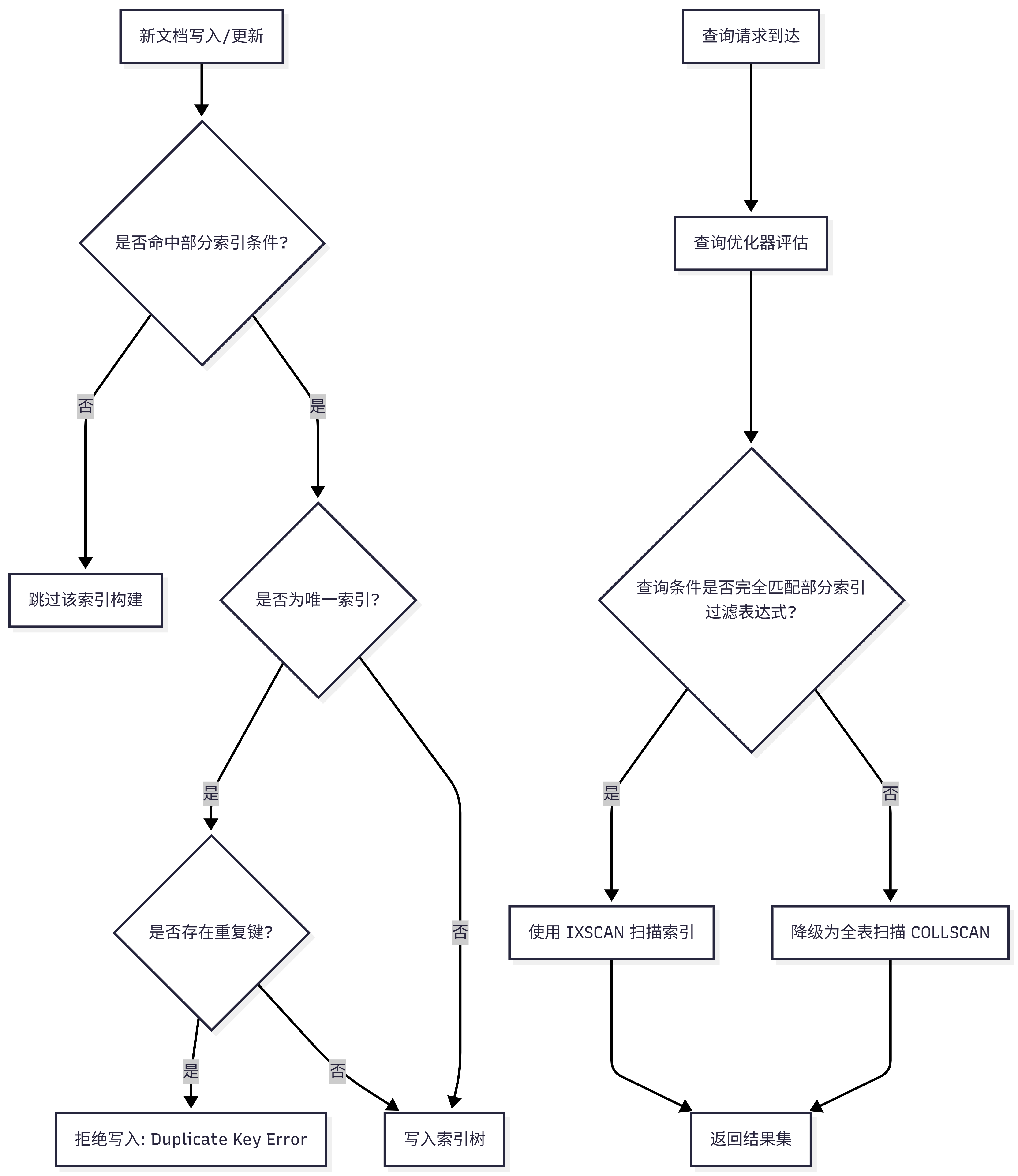
执行计划(Execution Plan)解析 :
当查询条件未能严格包含部分索引的过滤表达式时,MongoDB 优化器会认为使用该索引可能导致结果集不完整,从而放弃索引,退化为 COLLSCAN(全表扫描)。因此,在应用层代码中,查询谓词必须显式包含与 partialFilterExpression 完全一致的条件,才能确保命中 IXSCAN 并获得预期的性能提升。
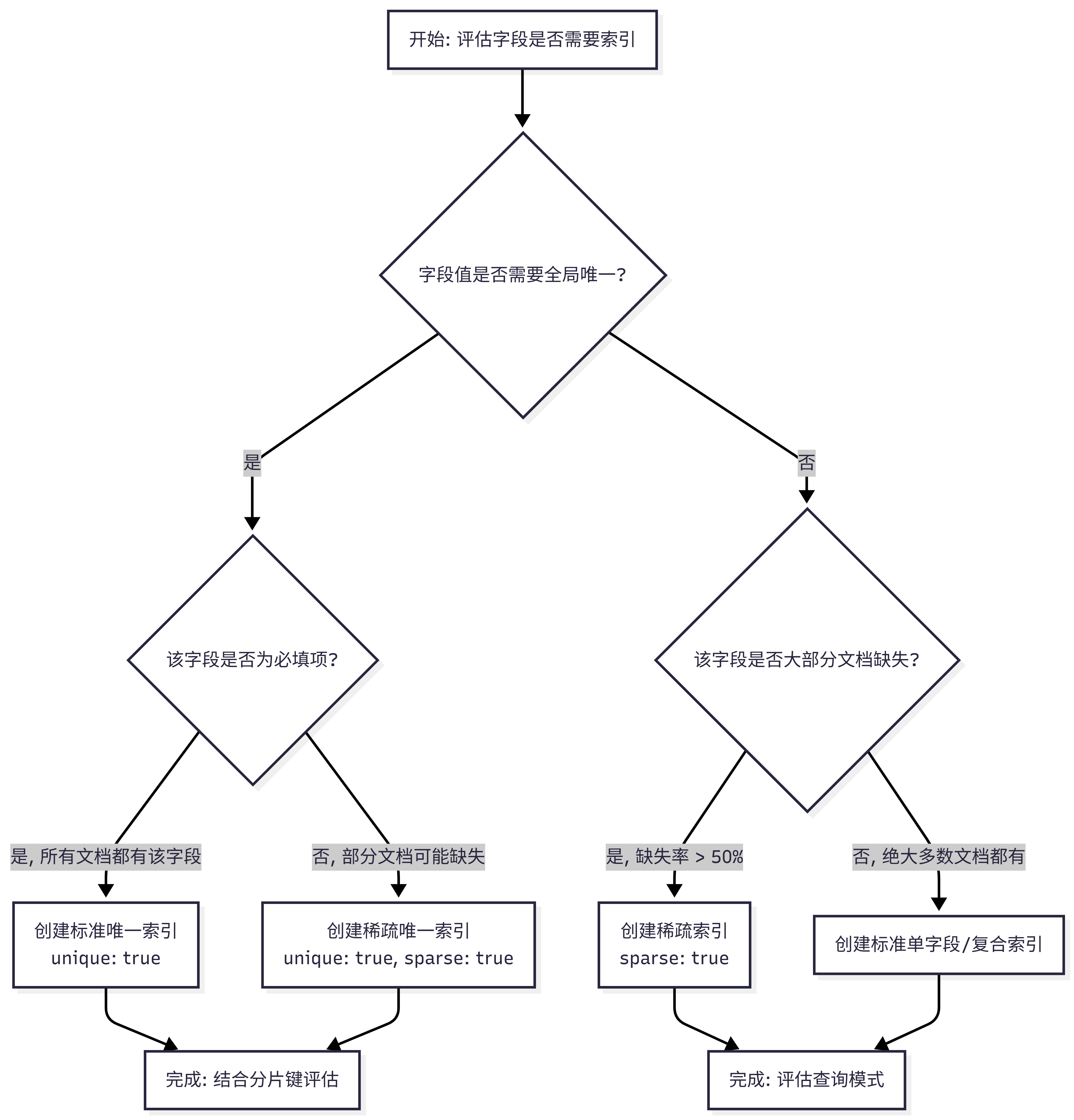
2. 索引是否创建决策流程
在系统架构设计阶段,面对一个需要建立索引的字段,架构师应遵循以下决策链路:
三、生产环境实战演示与避坑指南
1. 实战演示:电商订单系统的索引设计
场景 :在包含 5000 万条记录的订单集合中,仅有约 10 万条订单包含 productTags(商品标签)字段。业务需要高频查询带有标签的订单。
错误示范(普通复合索引):
javascript
db.orders.createIndex({ deliveryTime: 1, productTags: 1 })痛点 :索引体积庞大,包含大量无用的 null 值键。查询时优化器仍需遍历海量无效索引项,导致 totalDocsExamined 极高。
最佳实践(部分索引):
javascript
db.orders.createIndex(
{ deliveryTime: 1, productTags: 1 },
{ partialFilterExpression: { productTags: { $exists: true } } }
)收益 :索引仅包含 10 万条有效记录,体积极小,内存友好。查询时 totalDocsExamined 降低 99% 以上,响应时间从秒级降至毫秒级。
2. 性能与存储避坑指南
- 低基数字段陷阱 :对于
status、is_deleted等基数极低的字段,单独建立普通索引毫无意义。优化器评估后大概率仍会选择全表扫描。应结合部分索引,仅对高区分度子集(如status: "active")建立索引。 - 写放大效应:唯一索引在每次插入和更新时都需要进行 B-Tree 查找以校验唯一性,这会导致写入性能下降约 15%-30%。应避免在高频更新的字段上滥用唯一索引。
- 复合多键索引限制 :在复合索引中,最多只能包含一个数组字段。若查询数组内多个条件,务必使用
$elemMatch确保匹配同一元素,否则索引可能失效。
3. 数据一致性与架构避坑指南
- 分片集群唯一性约束:在分片集群中,唯一索引必须包含分片键(Shard Key)。若业务要求非分片键字段全局唯一,需在应用层通过分布式锁或独立唯一性校验服务来保障。
- 部分索引的查询强绑定:部分索引不是"建了就用"的银弹。开发人员在编写查询时必须显式带上过滤条件。建议在代码审查(Code Review)阶段将部分索引的匹配条件作为检查项,防止因漏传条件导致的慢查询。
4. 覆盖查询(Covered Query)的限制:
- 由于稀疏索引不包含缺失字段的文档,因此它无法 用于覆盖查询。如果查询条件包含
{ field: { $exists: false } },MongoDB 必须回表查询,无法仅通过索引返回结果。
为了让你更直观地掌握这些索引的底层行为,我为你准备了一套可直接在 mongosh 中运行的实战演练脚本。我们将通过模拟真实的业务场景,观察 MongoDB 在处理数据时的具体表现。
四、实战演练
实战一:唯一索引的"Null 值陷阱"
业务场景 :创建一个用户集合,要求 email 字段全局唯一。
演练目标:验证缺失字段时的唯一性约束行为。
javascript
// 1. 清空集合并创建标准唯一索引
db.users.drop();
db.users.createIndex({ email: 1 }, { unique: true });
// 2. 插入第一个缺失 email 字段的文档(成功)
db.users.insertOne({ name: "User_A" });
// 3. 尝试插入第二个缺失 email 字段的文档(失败!)
// 报错: E11000 duplicate key error dup key: { email: null }
db.users.insertOne({ name: "User_B" }); 标准唯一索引会将缺失字段视为 null。在实际开发中,如果该字段是可选的,强烈建议加上 sparse: true。
实战二:稀疏索引与查询结果丢失
业务场景 :为文章集合建立 tags 字段的稀疏索引,以节省空间。
演练目标:观察强制使用稀疏索引时的数据丢失现象。
javascript
// 1. 准备测试数据
db.articles.drop();
db.articles.insertMany([
{ title: "Article 1", tags: ["MongoDB"] },
{ title: "Article 2", tags: ["Redis"] },
{ title: "Article 3" } // 无 tags 字段
]);
// 2. 创建稀疏索引
db.articles.createIndex({ tags: 1 }, { sparse: true });
// 3. 正常查询(MongoDB 优化器评估后,为保证完整性会回退到 COLLSCAN)
db.articles.find({ tags: { $ne: "MongoDB" } }).explain().queryPlanner.winningPlan;
{
stage: 'COLLSCAN',
filter: { tags: { '$not': { '$eq': 'MongoDB' } } },
direction: 'forward'
}
products> db.articles.find({ tags: { $ne: "MongoDB" } })
[
{
_id: ObjectId('6a39f9d6f8b8299d23c1c18f'),
title: 'Article 2',
tags: [ 'Redis' ]
},
{ _id: ObjectId('6a39f9d6f8b8299d23c1c190'), title: 'Article 3' }
]
// 结果中显示 stage: "COLLSCAN",返回 2 条数据(包含 Article 3)
// 4. 强制使用稀疏索引(危险操作!)
db.articles.find({ tags: { $ne: "MongoDB" } }).hint({ tags: 1 });
// 结果仅返回 Article 2,Article 3 被直接丢弃!永远不要在复杂的过滤查询(如 $ne, $exists: false)中盲目 hint() 稀疏索引,否则会导致严重的业务数据丢失。
实战三:稀疏唯一索引(最佳实践)
业务场景 :用户的 phone 字段是可选的,但一旦填写,必须保证唯一。
演练目标:验证稀疏与唯一属性的完美融合。
javascript
// 1. 创建稀疏唯一索引
db.profiles.drop();
db.profiles.createIndex({ phone: 1 }, { unique: true, sparse: true });
// 2. 允许多个文档缺失 phone 字段(成功)
db.profiles.insertMany([
{ username: "alice" },
{ username: "bob" }
]);
// 3. 插入包含 phone 的文档(成功)
db.profiles.insertOne({ username: "charlie", phone: "13800000000" });
// 4. 尝试插入重复的 phone(失败!)
// 报错: E11000 duplicate key error dup key: { phone: "13800000000" }
db.profiles.insertOne({ username: "david", phone: "13800000000" });这是解决"可选字段唯一性"的标准答案。它既保证了有值时的绝对唯一,又赋予了无值文档的自由度。
实战四:部分索引(Partial Index)的降维打击
业务场景 :电商订单集合,要求只有当 status 为 "active" 时,order_no 才必须唯一。
演练目标:展示比稀疏索引更灵活的约束控制。
javascript
// 1. 创建部分索引
db.orders.drop();
db.orders.createIndex(
{ order_no: 1 },
{
unique: true,
partialFilterExpression: { status: "active" }
}
);
// 2. 插入激活状态的订单
db.orders.insertOne({ order_no: "ORD001", status: "active" });
// 3. 尝试插入重复的激活订单(失败!)
// 报错: E11000 duplicate key error
db.orders.insertOne({ order_no: "ORD001", status: "active" });
// 4. 插入相同单号的已取消订单(成功!)
// 因为 status != "active",不在索引约束范围内
db.orders.insertOne({ order_no: "ORD001", status: "cancelled" });从 MongoDB 3.2 开始,partialFilterExpression 是替代稀疏索引的终极武器。它不仅支持"字段是否存在"的判断,还支持 $gt, $eq 等条件过滤,是构建精细化数据约束的首选。
总结
在真实的生产环境中,建议在执行上述 createIndex 操作时,加上 { background: true } 选项(注:MongoDB 4.2+ 默认在后台构建)。这能确保在百万级、千万级数据量下建立索引时,不会阻塞线上的读写业务。
五、高频面试题
1. 问:为什么 MongoDB 官方推荐使用部分索引(Partial Index)替代稀疏索引(Sparse Index)?
答 :稀疏索引仅能根据"索引字段是否存在"来决定是否建立索引,功能非常局限。而部分索引是稀疏索引的超集,它通过 partialFilterExpression 支持任意确定性表达式(如等值匹配、范围查询、$exists 等)。部分索引不仅能实现稀疏索引的所有功能,还能针对特定业务子集(如仅索引活跃用户、仅索引未删除订单)进行精准优化,在存储效率和查询性能上都更具优势。
2. 问:在唯一索引下,如果插入多个缺失该字段的文档会发生什么?如何解决?
答 :MongoDB 会将缺失字段的文档视为 null。由于唯一索引不允许重复键,集合中只允许存在一个缺失该字段的文档,再次插入将抛出 E11000 duplicate key error。
解决方案 :若业务允许字段缺失且需保持唯一性,应使用"唯一稀疏索引"({ unique: true, sparse: true }),或者更推荐的做法是使用"唯一部分索引"({ unique: true, partialFilterExpression: { field: { $exists: true } } })。这样既能保证存在该字段时的唯一性,又允许多个文档缺失该字段。
3. 问:创建了部分索引后,发现查询并没有走索引(Execution Plan 显示 COLLSCAN),可能的原因是什么?
答 :MongoDB 的部分索引具有严格的匹配机制。只有当查询谓词(Query Predicate)包含与 partialFilterExpression 完全一致(或为其子集)的条件时,优化器才会使用该索引。如果查询条件缺失了过滤表达式中的字段,或者条件不够严格(例如使用了 $ne、$regex 等非确定性操作符),优化器会认为使用该索引可能导致结果集不完整,从而拒绝使用并退化为全表扫描。
4. 问:在分片集群(Sharded Cluster)中创建唯一索引有什么特殊限制?
答:在分片集群中,为了保证跨分片的数据一致性,唯一索引必须包含分片键(Shard Key)。这意味着 MongoDB 只能保证"分片键 + 唯一字段"的组合在集合中是唯一的。如果业务需求是某个非分片键字段在整个集群中全局唯一,MongoDB 无法在数据库层面直接支持,必须通过应用层的分布式锁、唯一性校验微服务,或者使用单独的辅助集合来实现。
5.问:集合中已经存在重复数据,能否直接创建唯一索引?
答:不能。创建唯一索引时,MongoDB 会扫描现有数据进行校验,如果发现重复值,索引创建将直接失败并报错。正确的做法是:先通过聚合管道(Aggregation Pipeline)找出重复数据,根据业务逻辑删除或合并冗余文档后,再执行 createIndex。
6.问:为什么在稀疏索引上执行 db.collection.find().sort({ sparseField: 1 }) 可能会丢失数据?
答 :因为稀疏索引只包含存在该字段的文档。当执行全量排序且没有指定 limit 时,MongoDB 优化器为了保证返回结果的完整性,通常会放弃使用稀疏索引而选择全表扫描(COLLSCAN)。但如果通过 hint() 强制指定了该稀疏索引,或者查询带有 limit,MongoDB 将仅对索引中存在的文档进行排序并返回,导致缺失该字段的文档被丢弃。