前言
做 Agent 的都知道,让大模型读文档,第一步是"把纸变成字"。这一步看起来很简单------OCR 发展了二十年,字符识别率早就过了 95%。
但是当你拿到一张真实的财务底稿:合并单元格里藏着父子隶属关系,跨页长表的续接信号弱得像页脚的水印,嵌套表格里套着另一张子表------OCR 把每个字都认对了,但输出的字符串像被洗牌机搅过,列对不上、行挂错、表头飘到了正文里。Agent 拿到这堆"无主数字",引用时错得理直气壮,你还挑不出它哪一步算错了。今天我们来讲一讲如何判断一份解析结果到底能不能用------先看清"认字"和"懂表"之间差了什么,再立起一把三层标准去量它,最后把三款主流工具拉到同一张真实样表上跑一遍。
这里写目录标题
- 前言
- [一、从"认字"到"懂表":OCR 迈不过的那道坎](#一、从"认字"到"懂表":OCR 迈不过的那道坎)
- [二、测评设计:三个维度, 一张表说清楚](#二、测评设计:三个维度, 一张表说清楚)
- 三、实测结果与结论
-
- [3.1 结构对不对: 一眼能看到的"变形"](#3.1 结构对不对: 一眼能看到的"变形")
- [3.2 关系对不对: 需要对比原文的"归属检查"](#3.2 关系对不对: 需要对比原文的"归属检查")
- [3.3 内容对不对: 必要时的精度抽查](#3.3 内容对不对: 必要时的精度抽查)
- [四、xParse 详解:从使用到原理](#四、xParse 详解:从使用到原理)
-
- [4.1 使用方法](#4.1 使用方法)
- [4.2 工作原理:xParse 的 5 步流水线](#4.2 工作原理:xParse 的 5 步流水线)
- [4.3 能力边界:xParse 能解决什么](#4.3 能力边界:xParse 能解决什么)
- 五、结论
一、从"认字"到"懂表":OCR 迈不过的那道坎
OCR 这门技术,拿它扫个标准三线表,准确率能到 99%。但你要是拿它去扫一张财务底稿------合并单元格、跨页长表、嵌套子表、密集小字------翻车率能到 30% 以上。
问题不在字符识别,而在"字段级归属" 。OCR 输出的是字符串,Agent 真正需要的是带 schema 的结构化数据。从"字符"到"结构"之间,有一道几乎所有通用 OCR 都跨不过去的鸿沟------OCR 认字 ≠ 表格可用。
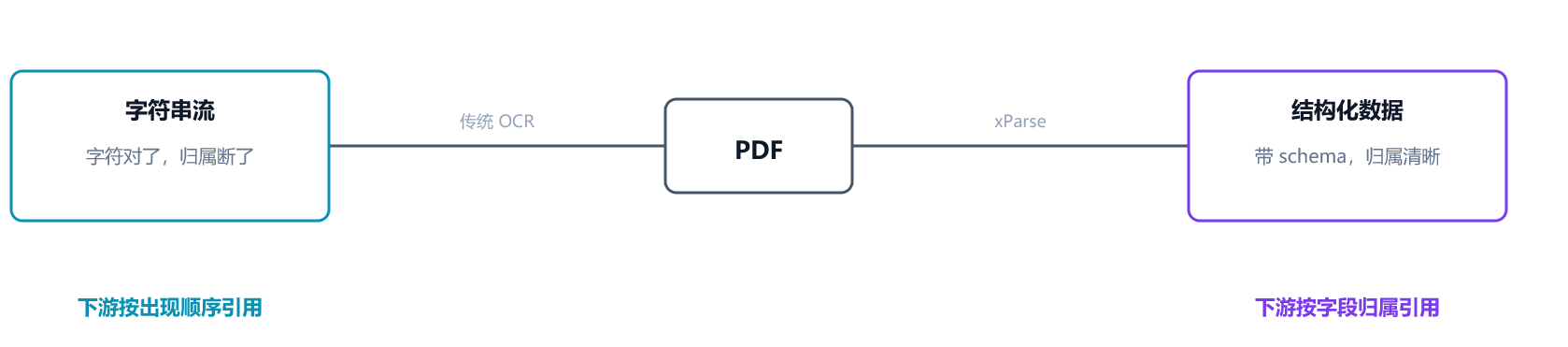
跨过去,Agent 才能正确引用;跨不过去,Agent 拿到的就是一堆无主数字------按出现顺序引用,错得理直气壮。
正好,最近体验了合合信息TextIn xParse复杂表格解析能力,我用了一段时间发现,它跟传统 OCR 根本不在一个赛道。OCR 做"文档→字符串",xParse 做"文档→结构化数据"。这个区别,决定了它能不能接住真实业务里那些"结构复杂到让人头疼"的表格。
下面我们按 3 步走:先把尺子立起来(3 层检查标准),让 3 款主流工具(xParse / PaddleOCR / MinerU)各跑一遍真实样表;再把表现对症的 xParse 拆开看------内部怎么走、配置怎么拧、能力边界在哪。
二、测评设计:三个维度, 一张表说清楚
对开发工程师来说, 在没有 ground truth、也没有专用评测工具的前提下, 最省事的做法就是扫一遍输出: 看起来是表格结构、文字没缺漏, 就暂且认为解析完成。
但问题在于,"扫一眼"查的是 "有没有缺东西",而复杂表格真正要命的错不在"缺",在"错位"------内容一个不少、关系却全挂错了。这种错不会自己跳出来告警,扫一眼根本拦不住。所以光靠肉眼判断"能不能用"靠不住,得换一套能逐项核对的检查方法。
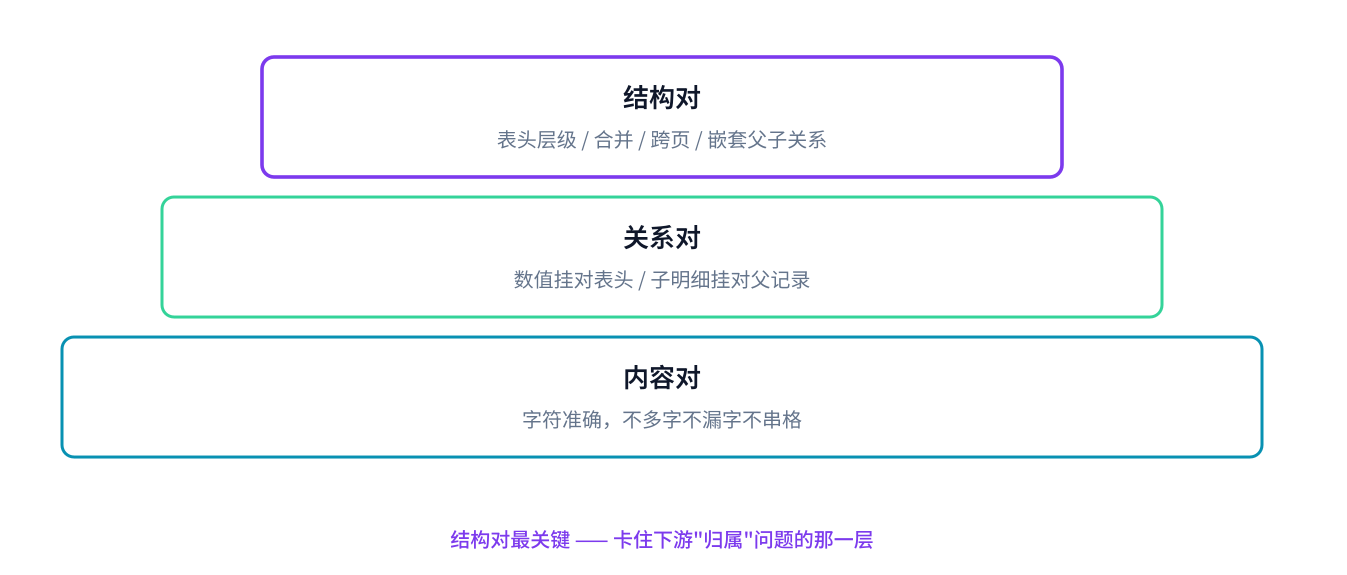
那有没有一套可操作的检查清单, 能在拿到结果的 5 分钟内判断它"能不能用"? 下面,本章节将把判定标准拆成 3 个层次------结构对不对、关系对不对、内容对不对 ------并用 3 款主流工具 (xParse / PaddleOCR / MinerU) 各跑一遍真实业务样表, 看它们在这 3 层下的真实表现,每层用"✅ 完整还原 / ⚠️ 部分还原 / ❌ 严重丢失"三档打分。
| 检查维度 | 核心问题 | 对应错误类型 |
|---|---|---|
| 结构对不对 | 拿到的是一张完整的表吗? | 合并范围丢失、跨页断裂、嵌套被拍平、行列多拆 |
| 关系对不对 | 字段都挂对位置了吗? | 数值归属错位、父表头丢失、注释脱钩 |
| 内容对不对 | 字字都对得上吗? | 漏字、错字、幻觉补全、串行串列 |
三、实测结果与结论
3.1 结构对不对: 一眼能看到的"变形"
结构是表格解析的第一关。这一层的问题几乎都能在原表和解析结果并排对比时一眼看出, 不需要逐格核对。围绕 4 个问题展开:
- 表格区域画对了吗 ------ 解析结果里有没有多出不属于表格的内容 (标题、页眉、印章被混入), 有没有少了本该属于表格的内容 (表头注释被截断, 一张完整的表被切成多块)?
- 行列数量对吗 ------ 数一下原表有几行几列, 再数解析结果。常见错误: 多了一列 (把空列也算进去)、少了一行 (小计行漏掉)、一列被拆成两列。
- 合并单元格还在吗 ------ 原表里跨行或跨列的合并区域, 在解析结果里被还原为一个大格, 还是被拆散成多个重复内容的小格? 合并单元格通常表达分组关系, 一旦被拆散, 数据的业务归属就丢了。
- 跨页表接上了吗 ------ 如果原表跨了多页, 解析结果是一张完整的表, 还是被拆成多张独立表? 续表是否继承了第一页的表头? 跨页拼接错误常见于长清单、审计底稿、资产台账等场景。
如果有一项没通过, 解析结果就不可用, 后面的关系和内容检查可以先放一放。结构是表格解析的第一道门槛。
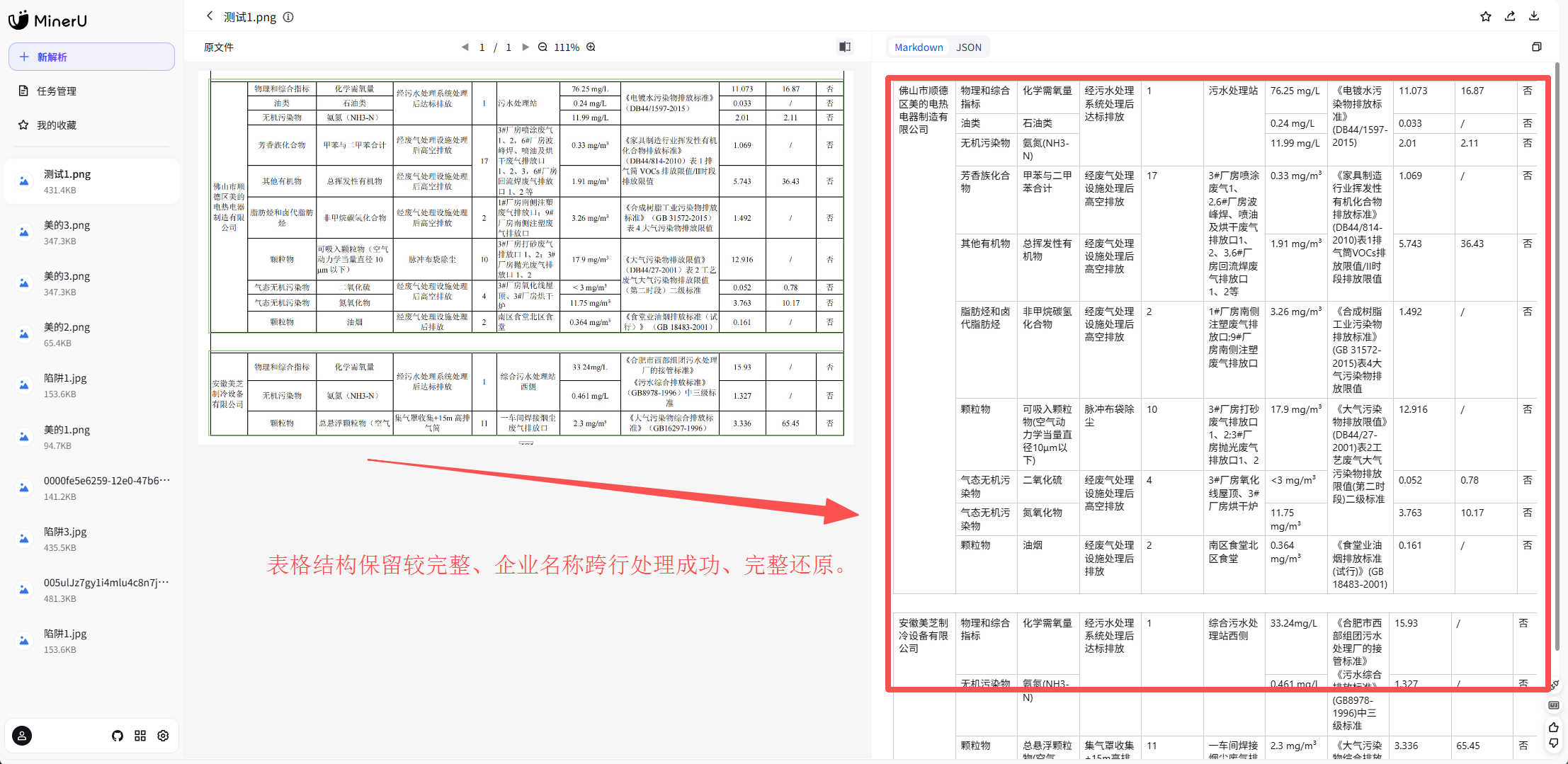
打头阵的案例是是一份企业污染物排放监测表。
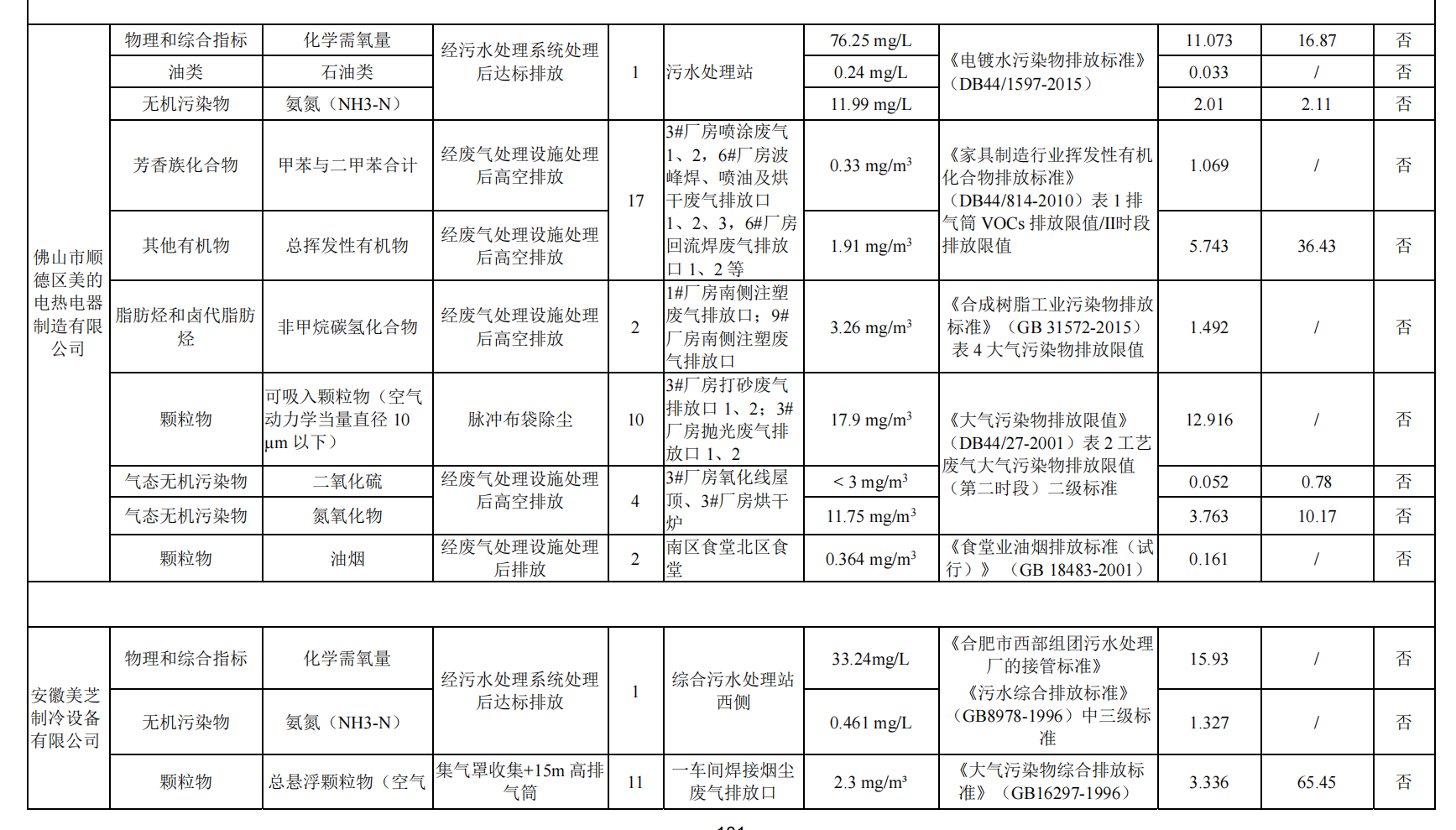
这是一张上下拼接、总计约 13 行 × 10 列的工业环保数据表------列字段横跨企业名称、污染物大类、污染物名称、处理方式、排放口数量、排放口位置、排放浓度、执行标准、年排放量、是否达标。10 列 + 大面积合并单元格 + 单元格内多行文本 + 标准名称与编号混排,结构复杂度极高。表格区域识别是传统解析的基本功,但合并单元格一旦拆散,同一污染物的业务归属就彻底丢失;而跨企业拼接时若未正确继承表头,上下两张子表的关系也会断裂。
三个产品的测评结果如下:
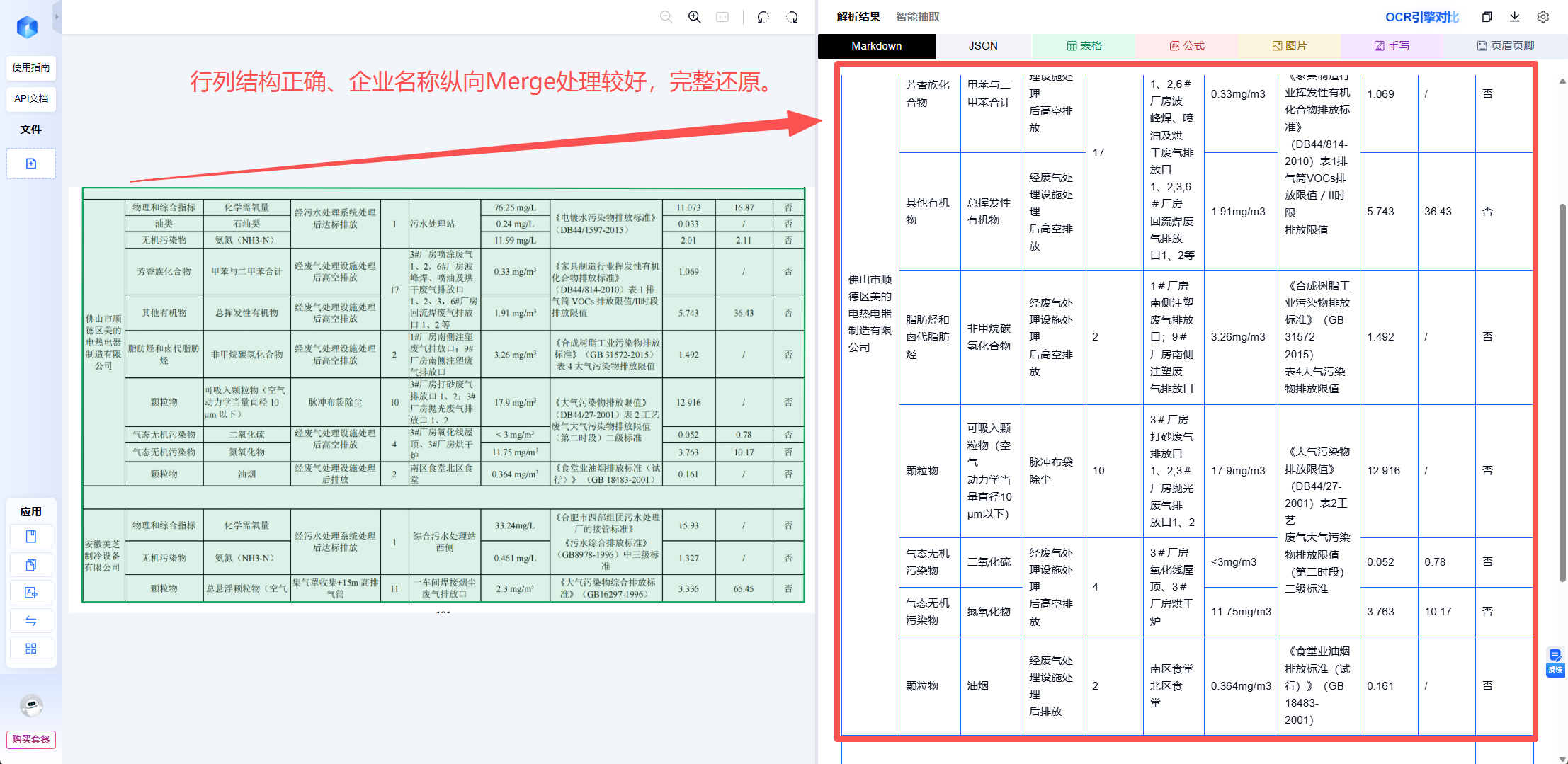
- 合合信息TextIn xParse
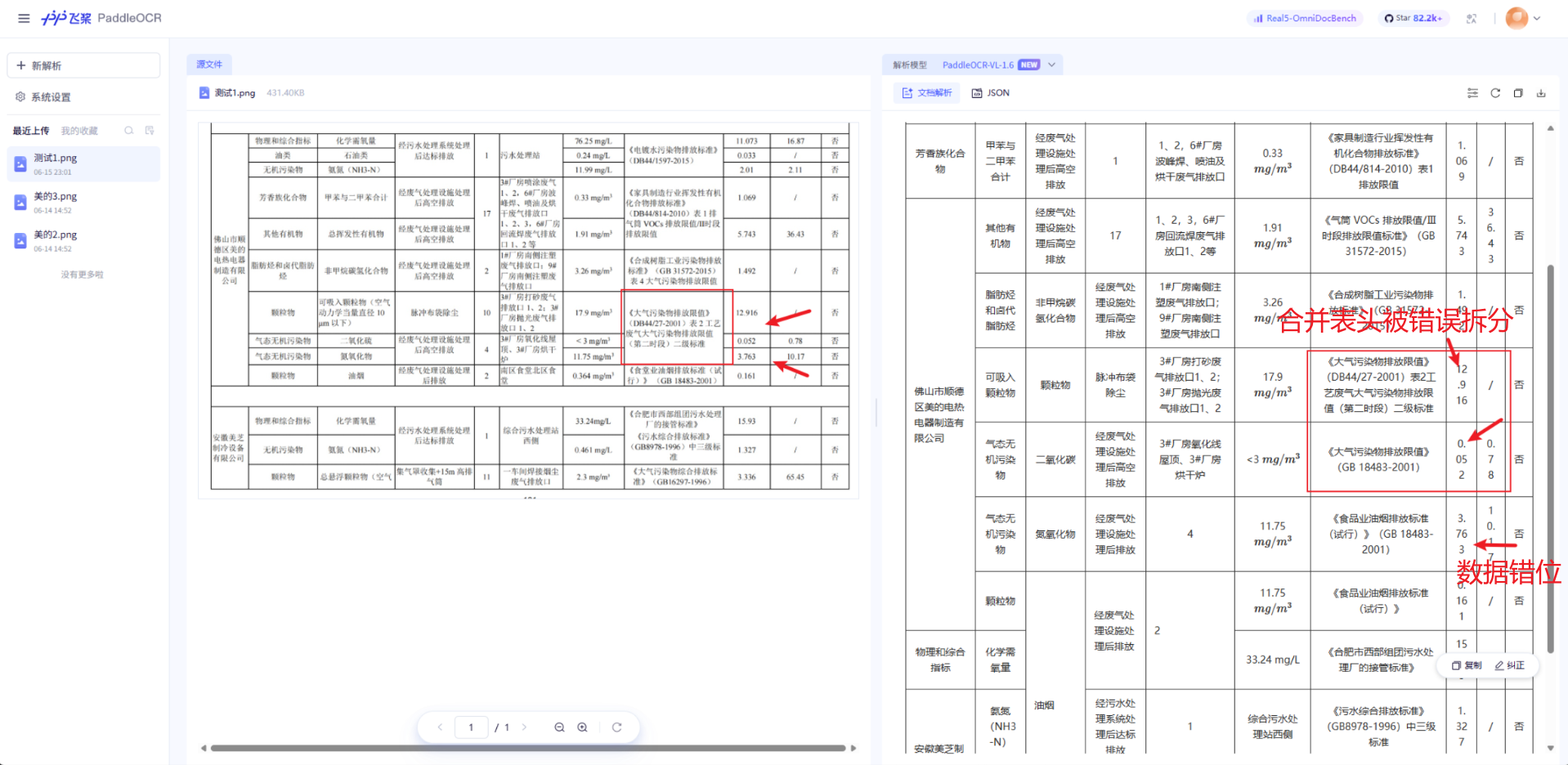
- 飞桨 PaddleOCR
- MinerU
3.2 关系对不对: 需要对比原文的"归属检查"
这一层更隐蔽, 但直接影响数据的业务含义。关系自查不需要逐格做, 抽检关键字段即可------如果抽检发现归属错误, 就可以判断解析结果不可靠。围绕 3 个问题展开:
- 表头和数据挂对了吗 ------ 挑几个数据行, 对应到原文, 确认每个数值的列名归属是否正确。尤其关注多层表头------同一列名 (如 Q2) 是否挂到了正确的父表头下。典型例子: 表格有"收入"和"成本"两个父表头, 各自下挂 Q1、Q2 两列; 如果解析结果把两组 Q2 拍平, 某个 Q2 数值就分不清属于收入还是成本------这就是归属错误。
- 嵌套表格的父子关系还在吗 ------ 如果原表某个单元格内嵌了子表 (比如客户信息表里内嵌了订单明细), 输出结果是保留了"主记录→子表"的层级结构, 还是子表被拍平成了独立表格? 父子关系一旦丢失, 明细数据就成了无主数据。
- 注释、单位、上下文还跟着表格吗 ------ 原表上方的单位说明 (如"单位: 百万元")、下方的注释是被保留并与表格主体关联, 还是被当作独立段落甚至丢弃? 缺少这些上下文, 下游模型可能拿到正确的数字但做出错误的解读。
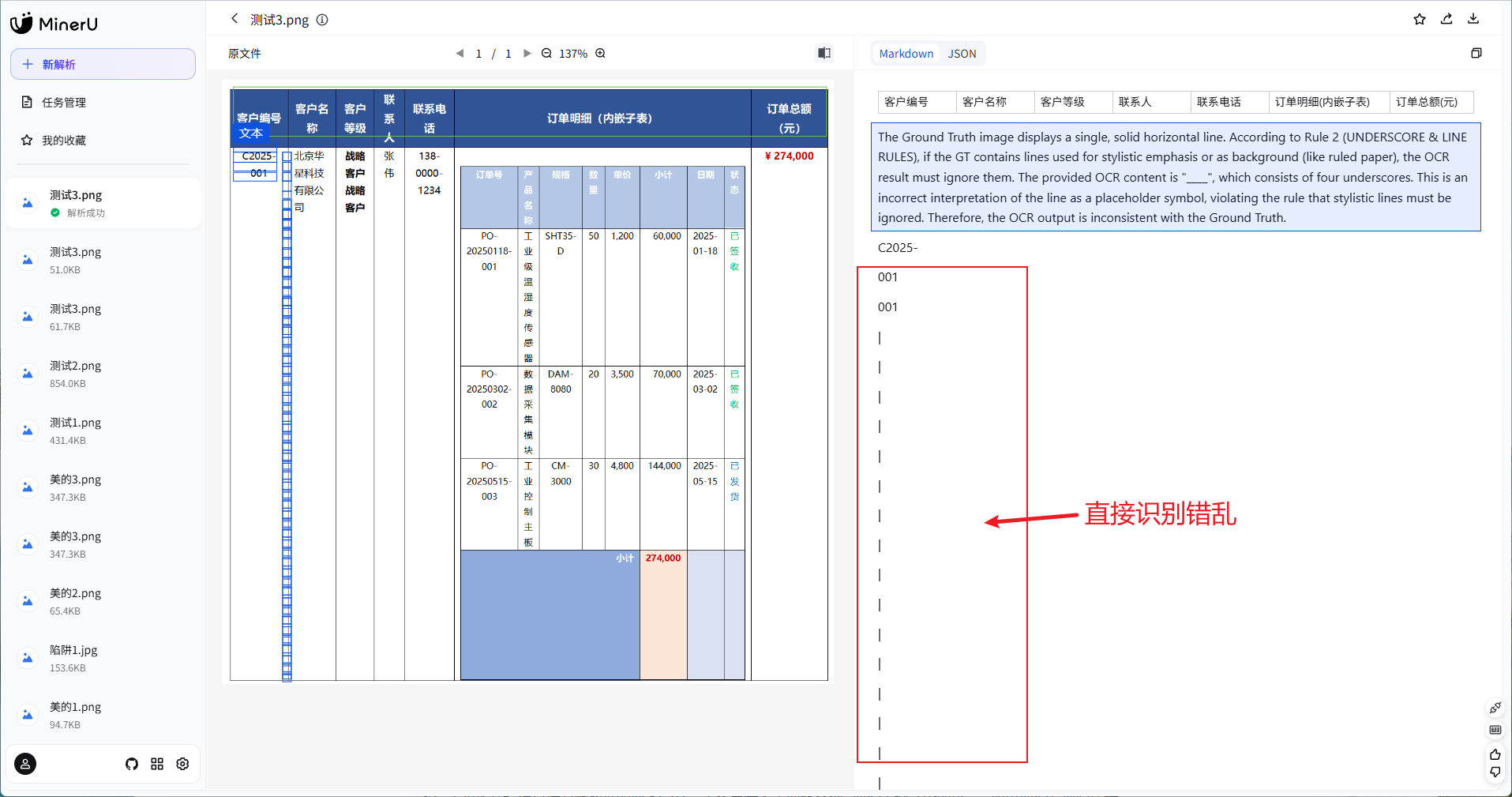
第二道关是一份订单明细表。
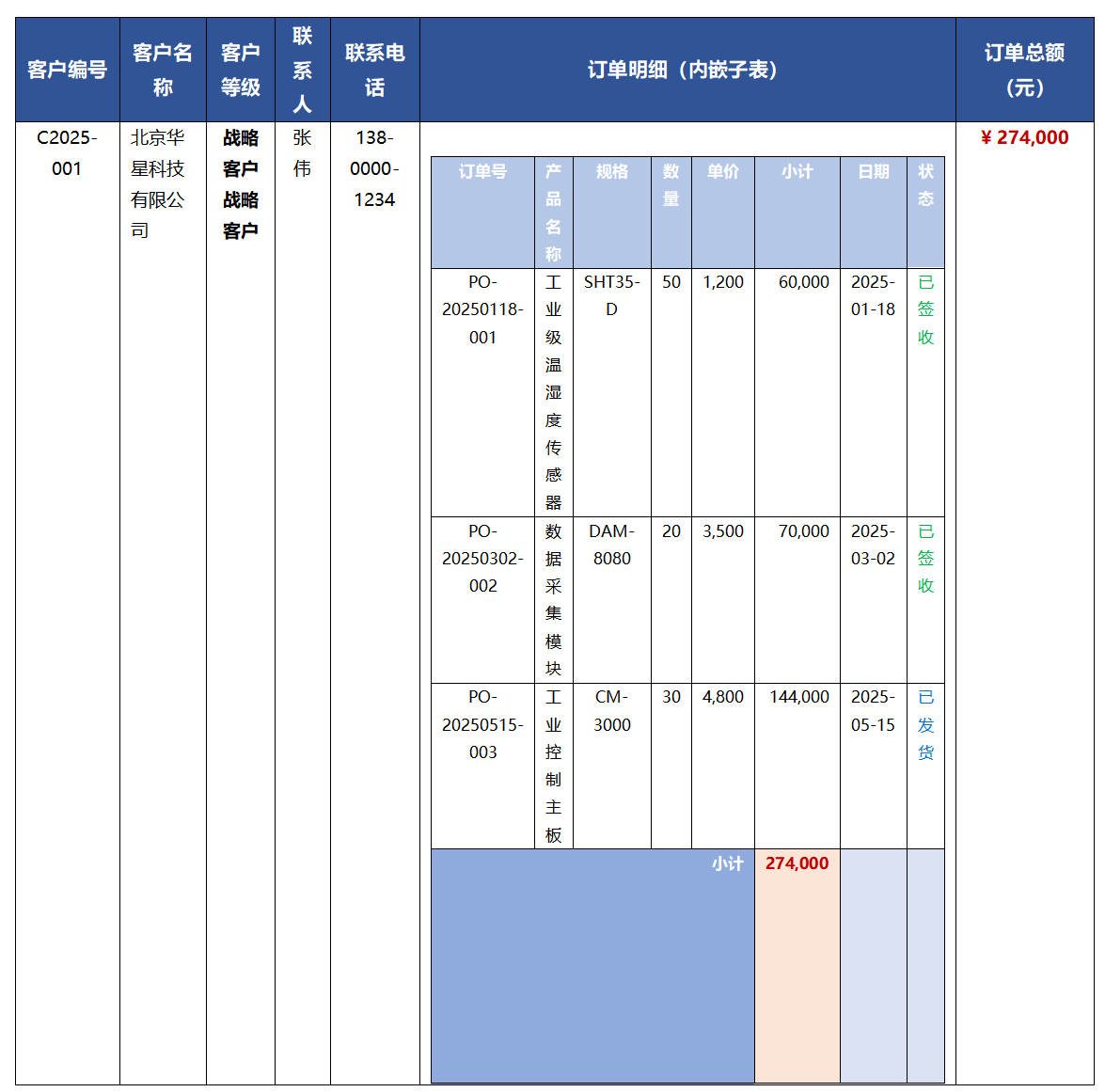
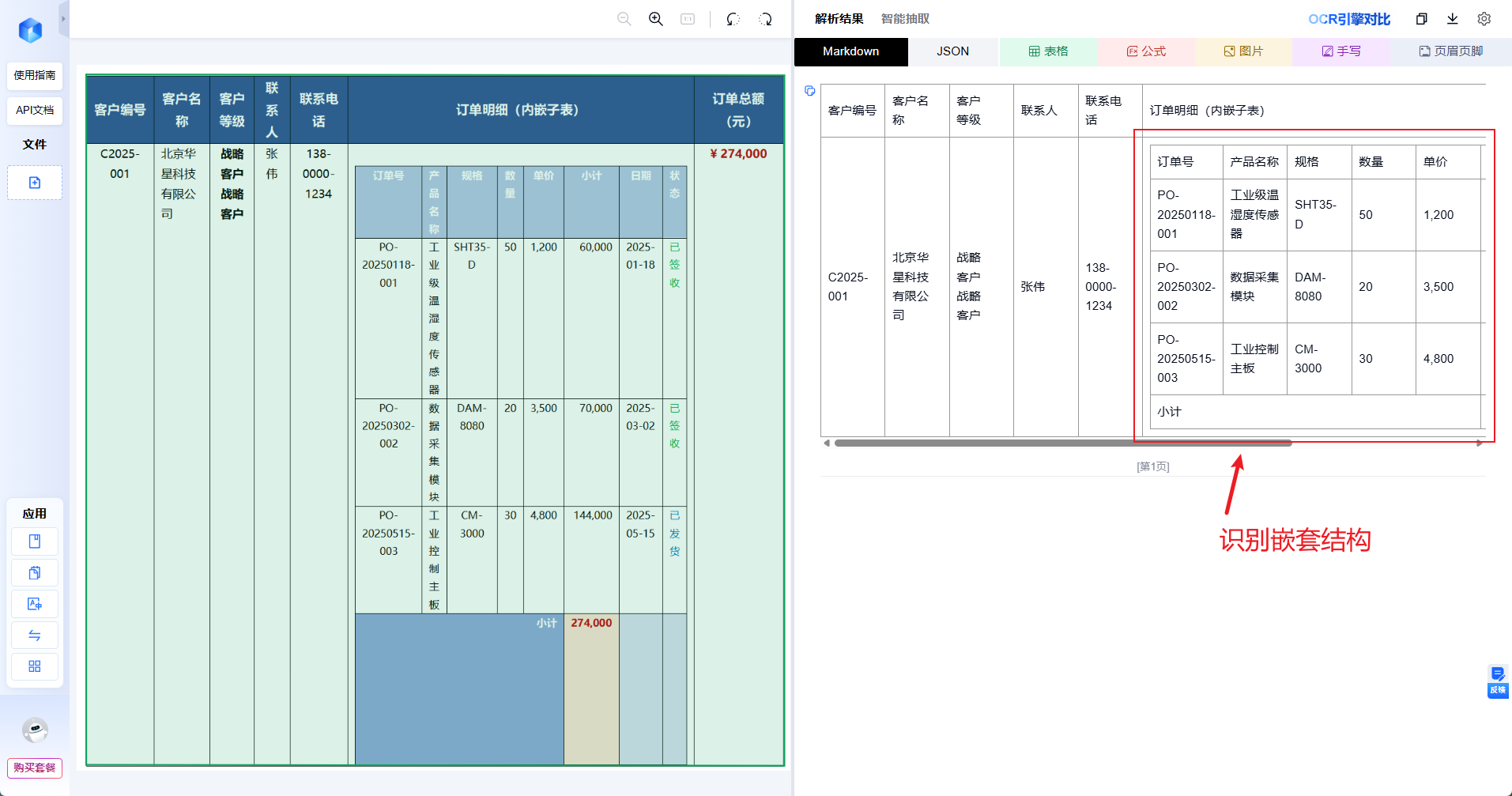
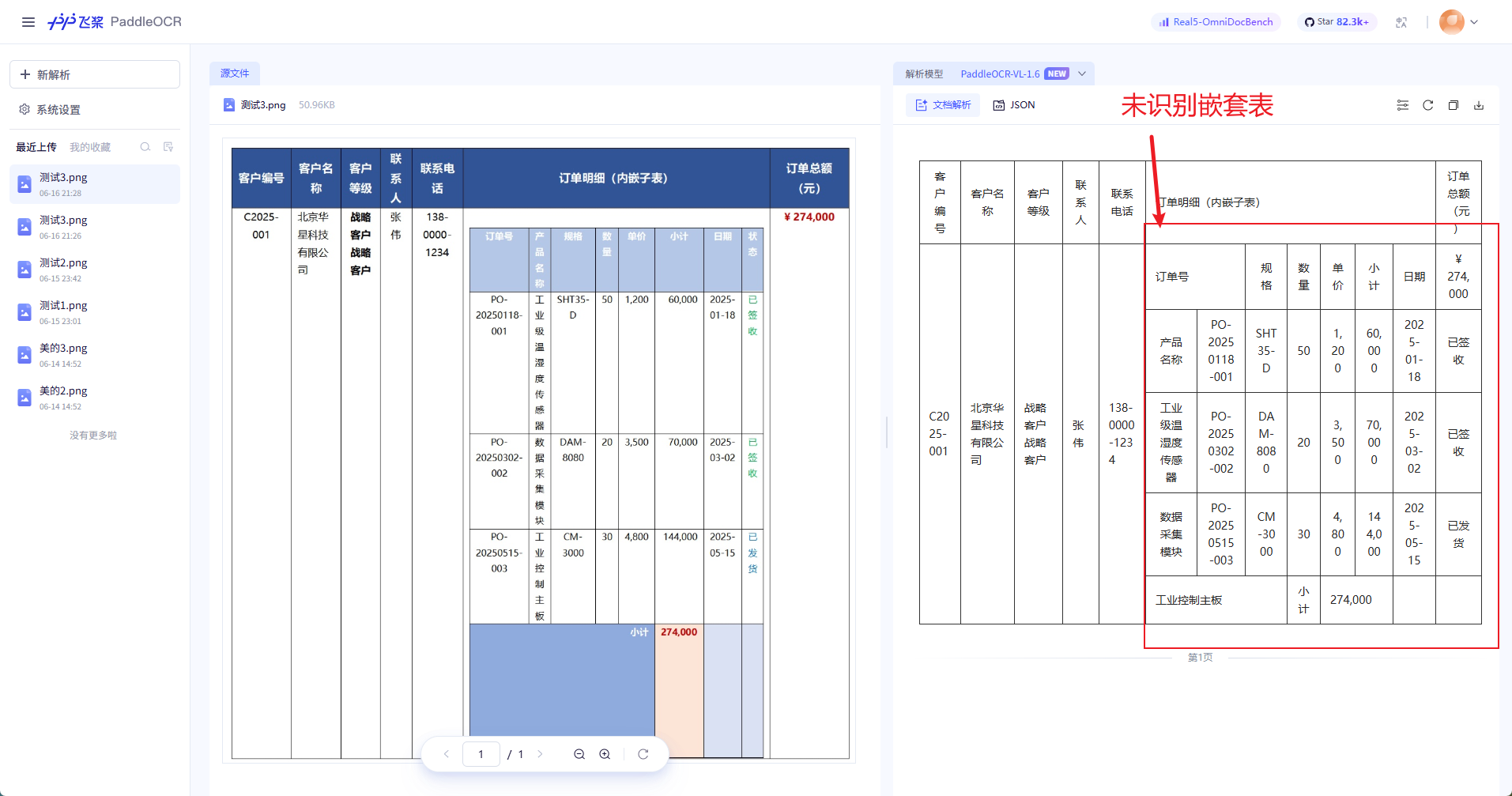
这是一页客户信息主表 + 嵌套订单明细子表的复合文档,左侧纵向排列客户编号、客户名称、客户等级、联系人及联系电话,中部嵌入一张 3 行 × 8 列 的订单明细追踪表,给文档解析带来很大的困难。
3.3 内容对不对: 必要时的精度抽查
内容层是最基础也最耗时的检查。对于大多数场景, 如果结构和关系已经通过, 内容错误属于低概率事件。不需要全表逐格核对, 重点抽查以下高风险区域:
- 密集数字区域 ------ 小数点、负号、百分号是否丢失。密集小字表是这类错误的高发区, 模型在分辨率不足时容易"猜"错数字。
- 小字或低对比度文字区域 ------ 扫描件里的浅色文字、表格底部的注释小字容易被漏掉。
- 手写或印章覆盖区域 ------ 手写内容压在表格线上、印章遮盖了关键数字, 这类区域字符识别容易出错。
如果抽查未发现内容问题, 这张表在内容层基本可用。如果发现多处问题, 说明解析精度不达标, 需要更换方案或引入人工复核。
第二道关是美的 2024 年报第七节里的「前 10 名股东持股情况」表。
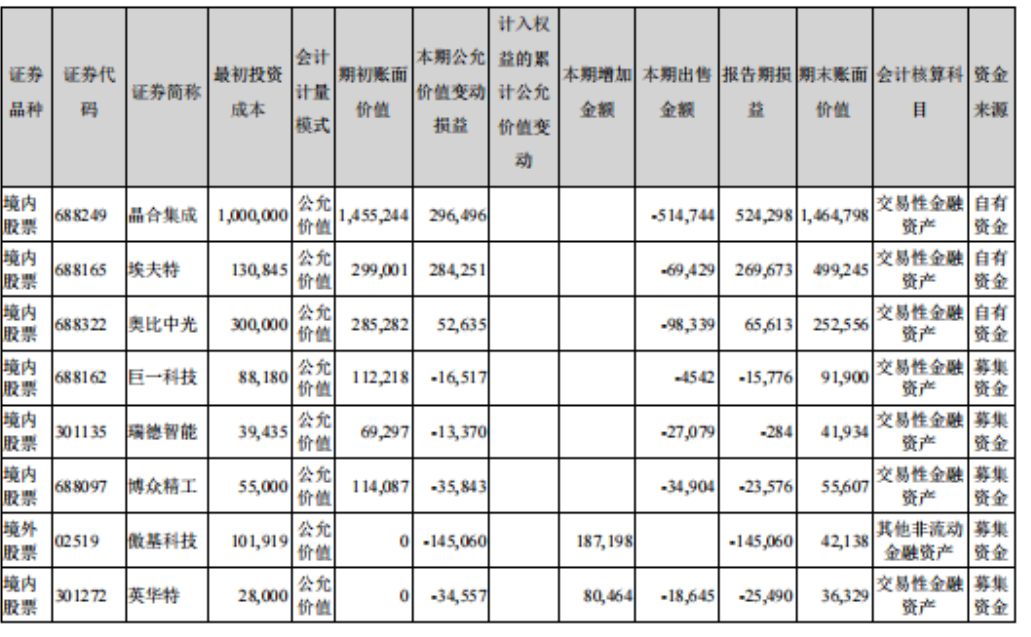
这是一张 10 行 × 13 列的密集表------列字段横跨证券品种、证券代码、证券简称、最初投资成本、会计计量模式、期初账面价值、本期增加、期末账面价值、减值准备、持股比例、质押或冻结、会计核算科目、资金来源。多行 + 多值并存,密度较高到极致。字符识别是传统 OCR 的基本功,但密集场景下 LLM 的幻觉式补全风险高。
三个产品的测评结果如下:
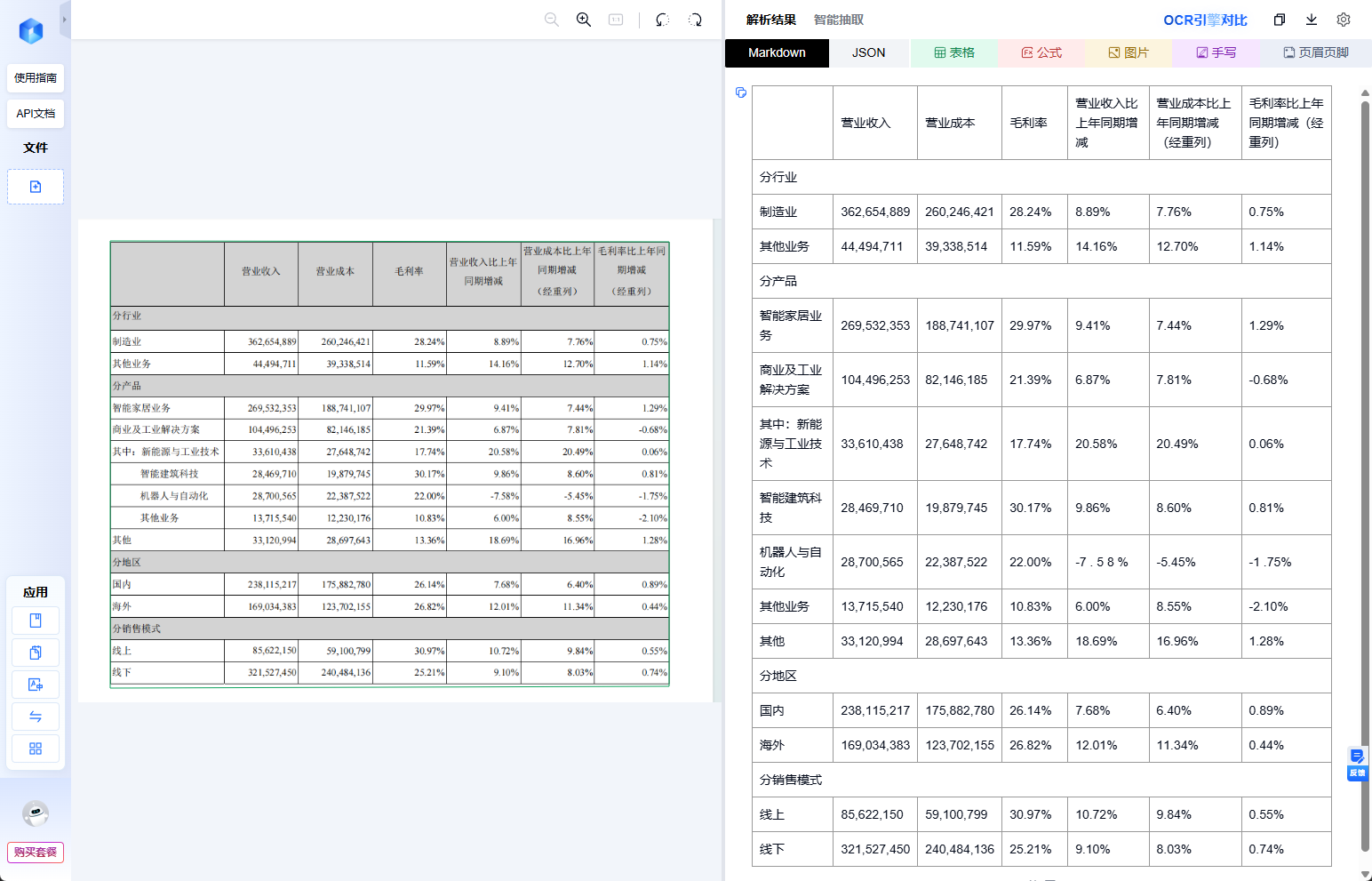
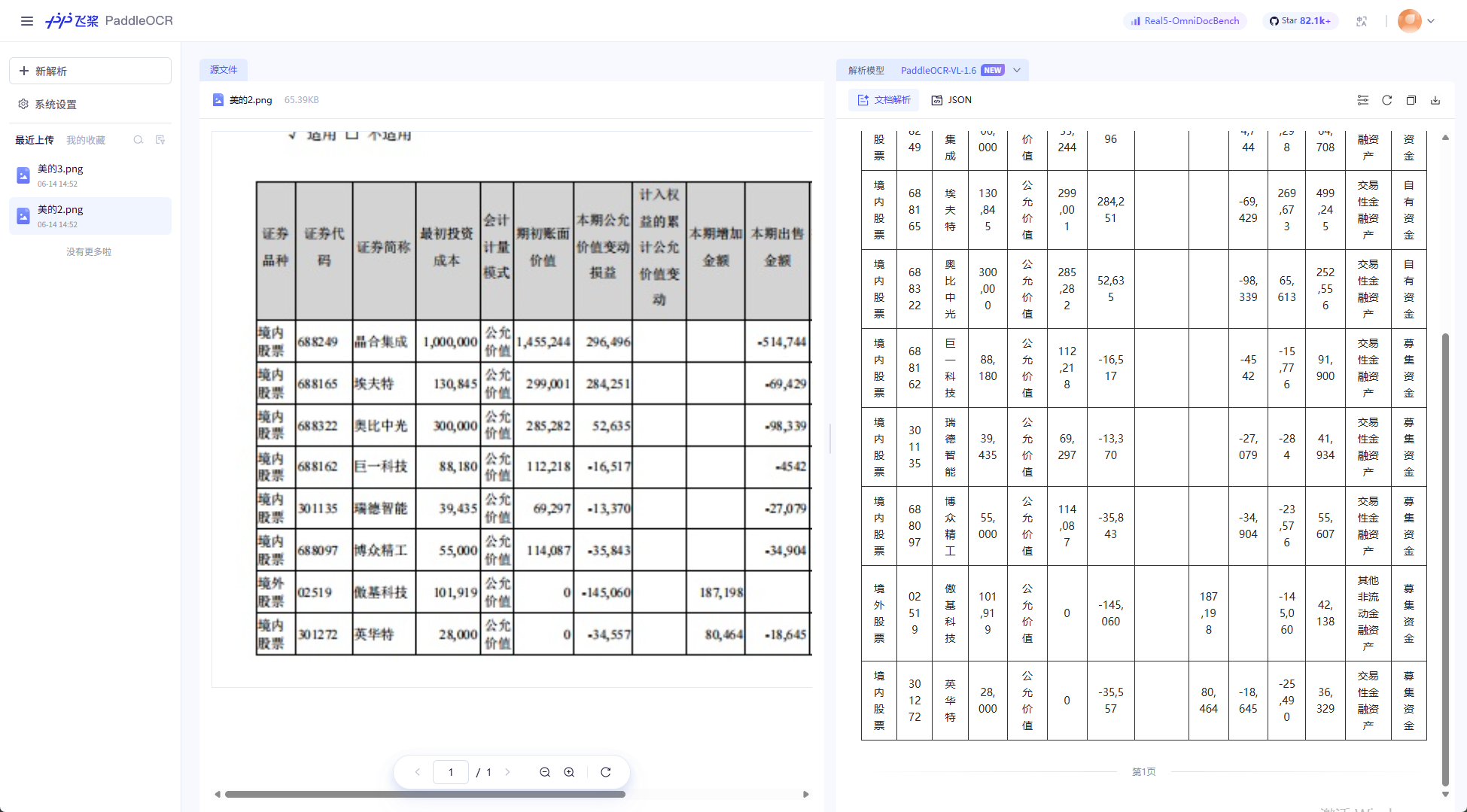
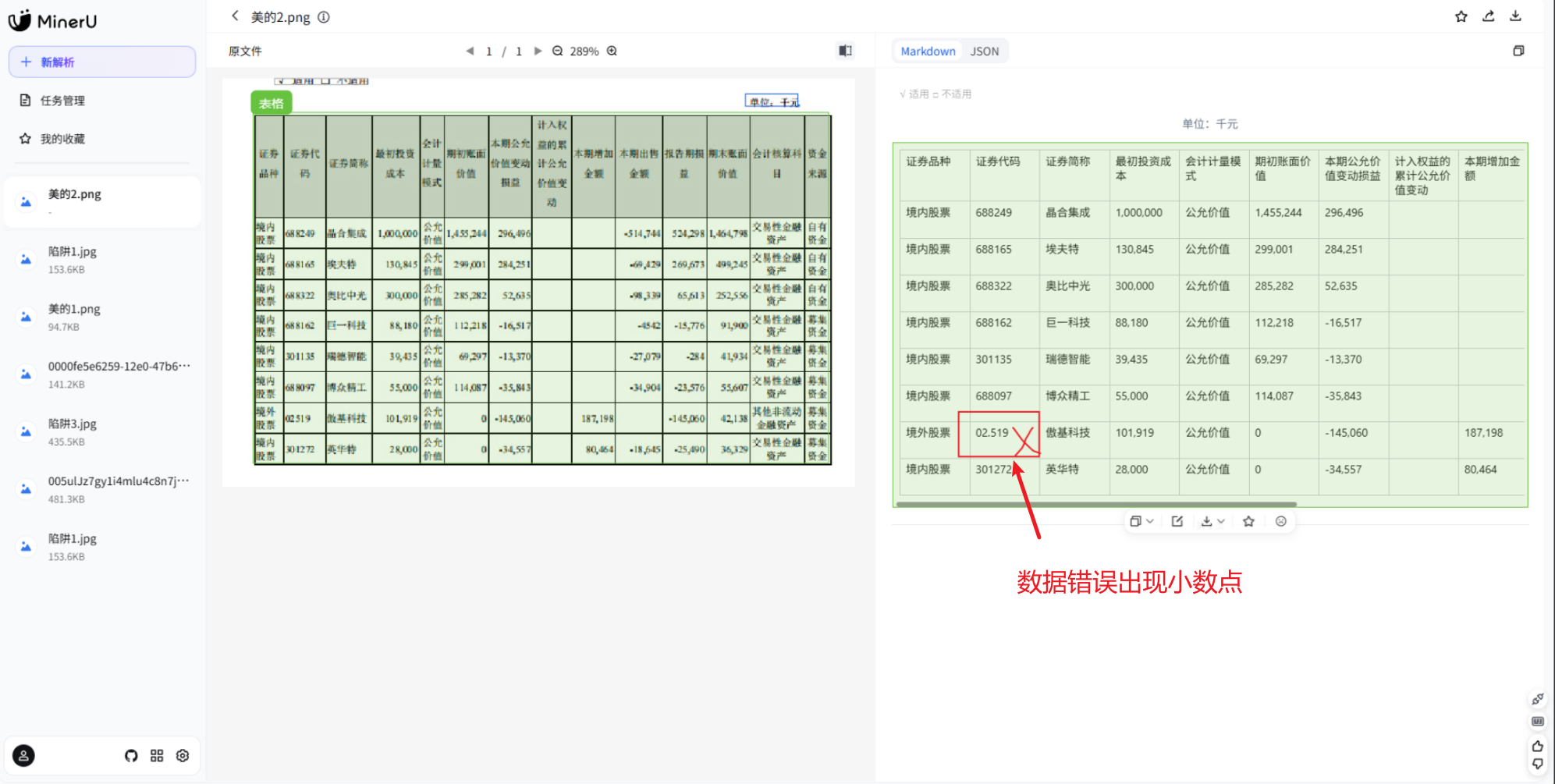
最终完整的测评结果如下:
| 样表 | xParse | PaddleOCR | MinerU |
|---|---|---|---|
| 结构对不对 | ✅** 完整还原** | ⚠️** 部分还原** | ✅** 完整还原** |
| 关系对不对 | ✅** 完整还原** | ❌** 严重丢失** | ❌** 严重丢失** |
| 内容对不对 | ✅** 完整还原** | ✅** 完整还原** | ⚠️** 部分还原** |
3 张样表、3 层标准跑下来,xParse 是这一轮里唯一一款在"结构对 + 关系对"两关都拿到完整还原的工具。下面把它拆开看。
四、xParse 详解:从使用到原理
4.1 使用方法
Xparse的使用方法很简单,首先登录**xParse:****https://www.textin.com/register/code/ZCNN7V**注册登录,进入控制台后可以看到这个界面。
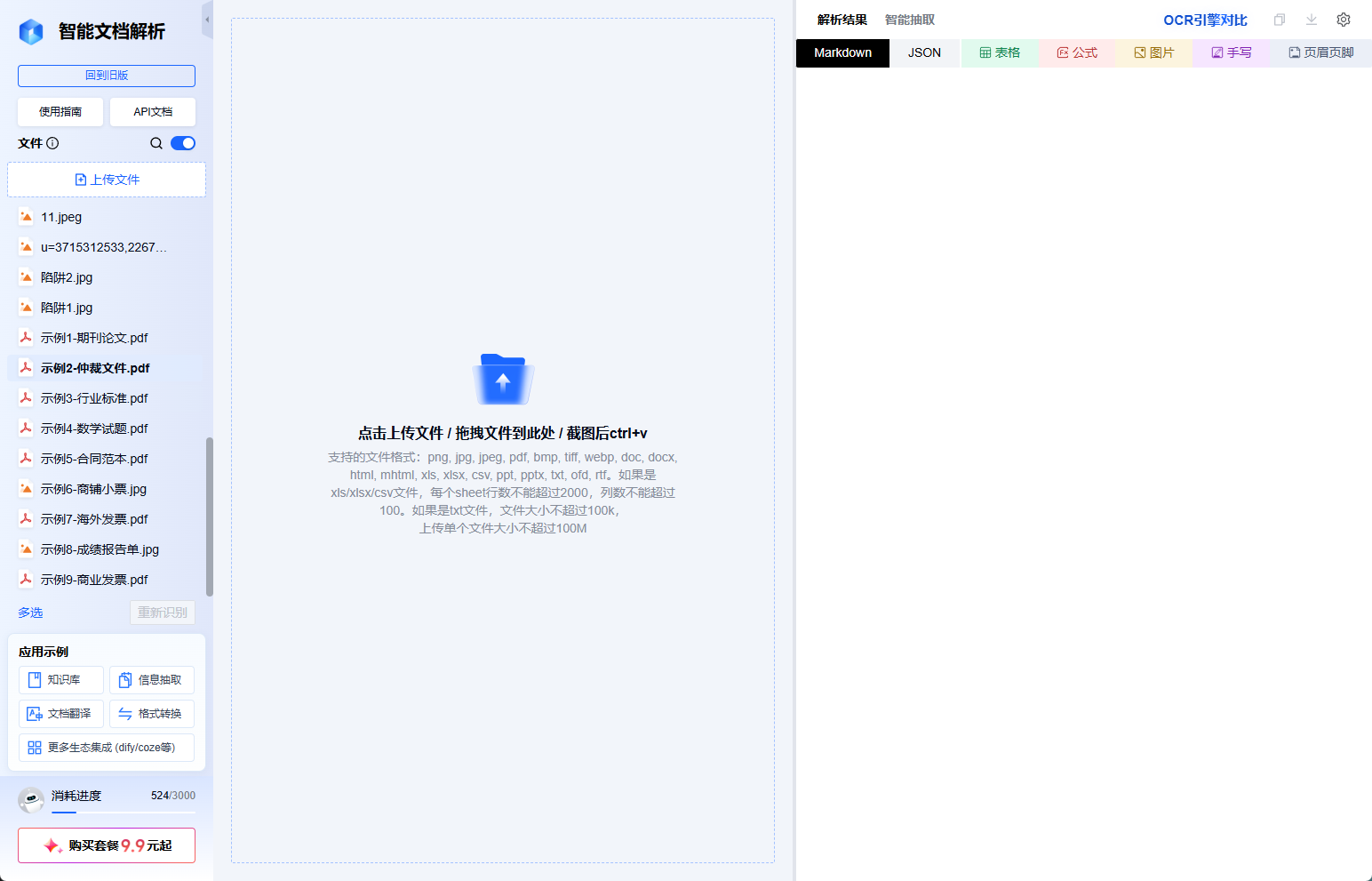
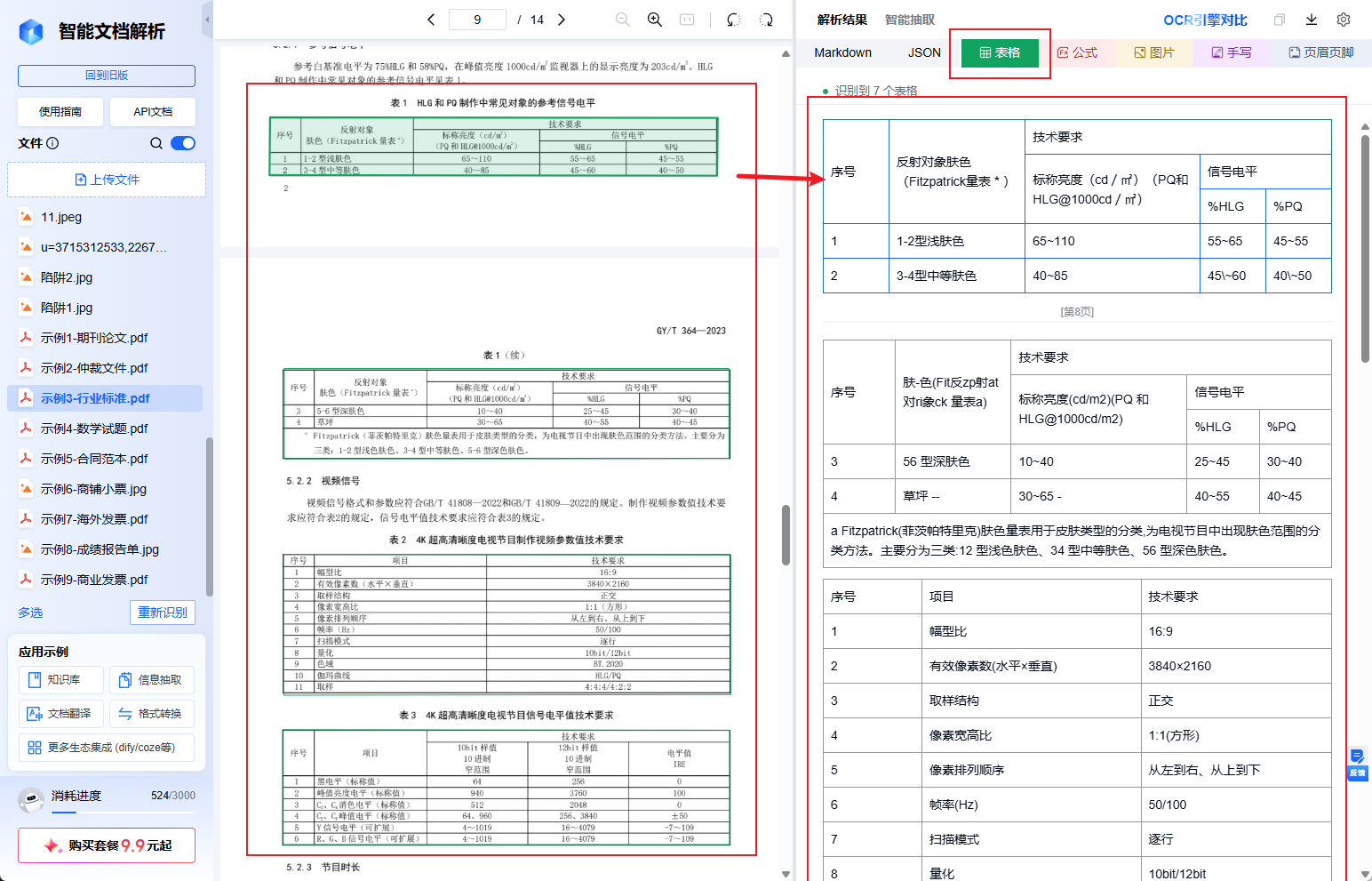
左边是文件栏,中间是上传区,右边是结果展示区。其中文件支持的格式很全,PDF、Word、Excel、PPT、图片、HTML、OFD、RTF、CSV、TXT 都能吃。传完的文件会留在左边栏,随时点随时重新解析,不用反复上传。
解析完看右边。Markdown 标签是给 LLM 看的,带格式带层级;JSON 标签是给程序用的,元素类型、坐标、父子关系、续接关系全在里面;表格标签把文档里的表单独抽出来,方便你快速核对。上面还有公式、图片、手写、页眉页脚几个过滤按钮,只想看某类元素的时候点一下就行。
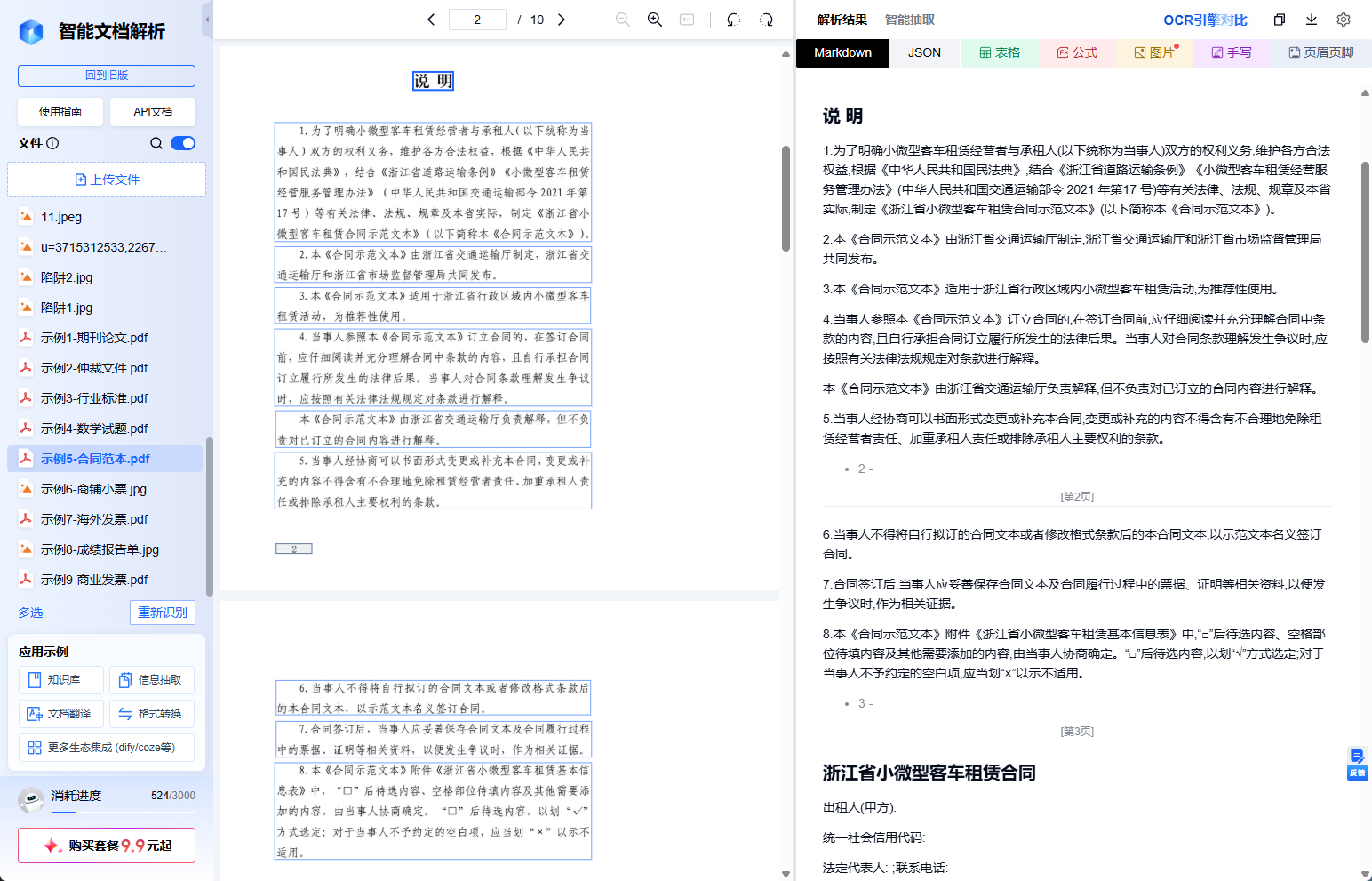
整个流程就是:扔文件进去,看结果,切引擎对比。复杂表格的解析效果,肉眼并排比一比,比听任何宣传都实在。
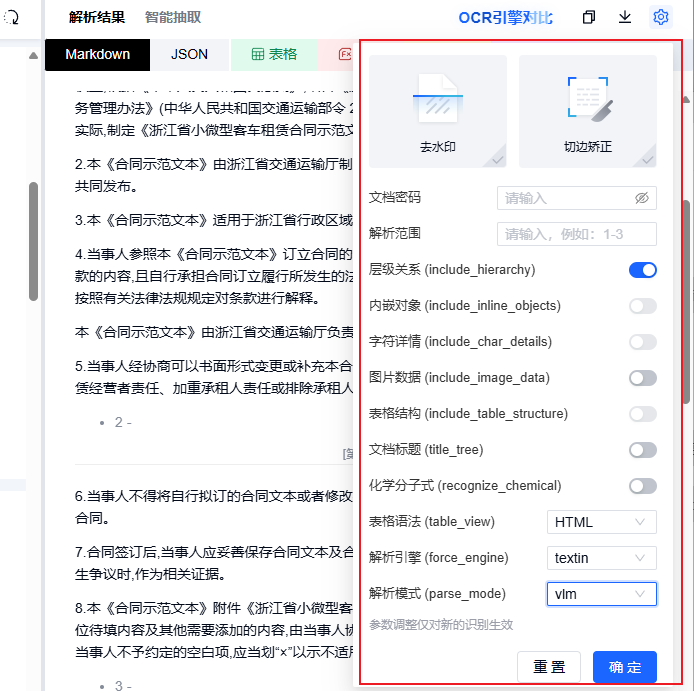
右上角有个配置项需要注意,这里分为了这几类:
- 预处理:倾斜矫正、去水印限时免费,扫描件/水印档必开;原生电子档别开,反而可能画蛇添足。
- 输出内容:识别文档标题默认开,长文档自动生成层级目录,左边能展开树状结构跳转;获取页面元素默认开,左右双向定位靠它;获取文本行详情平时关,做精细排版还原时再开。
- 解析模式:一般用vlm模式最好。
4.2 工作原理:xParse 的 5 步流水线
xParse 内部不是黑箱,文档从进去到出来要走 5 步,每一步都有明确的活儿:
- 输入校验:先验货,支持 PDF、Word、Excel、PPT、图片、HTML、OFD 等 10 余种格式,单文件上限 500MB。传文件或甩 URL 均可,但 file 和 file_url 只能二选一,同时传会报错。
- 预处理:扫描件和拍照件建议开去水印、切边矫正------专治客户发来的带"机密"大红章的扫描件,或者边缘歪得像比萨斜塔的手机拍照件。
- 版面分析:决定"从哪开始读、按什么顺序读"。比如双栏排版的 PDF,OCR 按行从左扫到右会把左右两栏搅成一锅粥,xParse 会先把版面结构理清楚,再按人类阅读顺序往下走。
- 元素识别:把页面拆成 16+ 种元素(标题、段落、列表、表格、图片、公式、化学式、页眉页脚等)。拆得越细,后面结构化越准------连"化学式"都单独拆一类,说明确实被医药、材料行业的文档毒打过。
- 结构化:这是 xParse 跟传统 OCR 真正分野的地方。不是输出一堆散落的元素就完事,而是要建立元素之间的关系网,直接决定下游 Agent 能不能正确引用。没有它们,Agent 拿到的是"孤儿数据",猜都猜不对。
4.3 能力边界:xParse 能解决什么
五步流水线跑完,输出的东西能用在哪?先看输入面:PDF、Word、Excel、PPT、图片、HTML、OFD、RTF、CSV、TXT 等 10 余种格式通吃,单文件上限 500MB,传文件或甩 URL 都行。
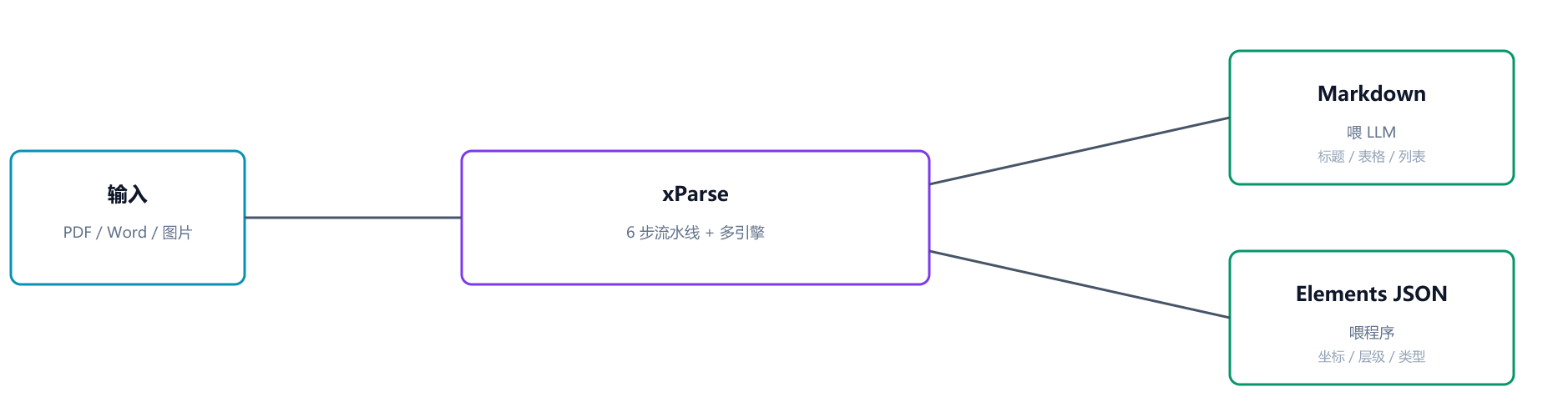
再看输出面,xParse同时给两种格式:输出给两种产物:
- Markdown:给 LLM 读的,人类可读,带格式
- Elements JSON:给程序用的,带坐标、带关系、带类型标签
典型场景集中在财务、审计、法务、供应链这几条线------财报、底稿、流水、合同、发票、对账单、采购清单、SKU 流水都在射程内。
用法、原理、能力边界都过了一遍,我们回到那张尺子上重新量一量。
五、结论
从父列与三子列的层级关系,到密集小字的边界识别,再到跨页长表中断行文本的续接归属------三张样表、三类场景、三层标准测下来,差距不是纸面上的参数对比,而是Agent拿到数据后能不能"理直气壮"地正确引用。
总结来看,有三个观察值得落笔:
第一,选型要分层看。 OCR把字认对早已不稀奇,结构对、关系对、内容对三层缺一不可。这次摸完3款工具,xParse在"结构对+关系对"上目前看起来最为对症------它把"层级结构"当头等大事,不只是把字符认全就交差;PaddleOCR在"工程化和生态"上仍是国内开源标杆------生态集成和硬件适配是它的看家本领;MinerU在"端到端VLM"上有独特价值------但精度和成本不可控。选型的本质,是把业务复杂度映射到工具能力边界上。
第二是没有万能工具。 嵌套场景 xParse 理论上大胜,跨页场景 PaddleOCR 跟 xParse 理论上持平甚至偶尔更优,密集小字三家都勉勉强强。用真实业务样表去验,比看官方宣传强。
第三是能复用就别手写。 xParse 把解析能力做成 API + 多引擎切换,调用方一行命令切引擎做横评------重复造轮子的事,少干。
带一张你最棘手的复杂表格,去 xParse跑一次 ------同一张表、不同的解析方案并排对比,差异比听任何承诺都有说服力。
试用链接(注册送1000页免费体验额度):https://www.textin.com/register/code/ZCNN7V
