Codebase-Memory MCP:用知识图谱重构 AI 代码理解
一句话总结:一个开源的代码智能引擎,通过 Tree-Sitter 构建持久化知识图谱,让 AI 编程 Agent 用 1/120 的 Token 完成代码理解任务。GitHub 今日 Star 数 2300+,arXiv 论文验证,支持 158 种语言。
一、为什么需要 Codebase-Memory?
1.1 AI 编程 Agent 的「近视眼」问题
2026 年的 AI 编程助手已经能写出相当不错的代码片段,但在理解大型代码库这件事上,它们依然是「近视眼」。
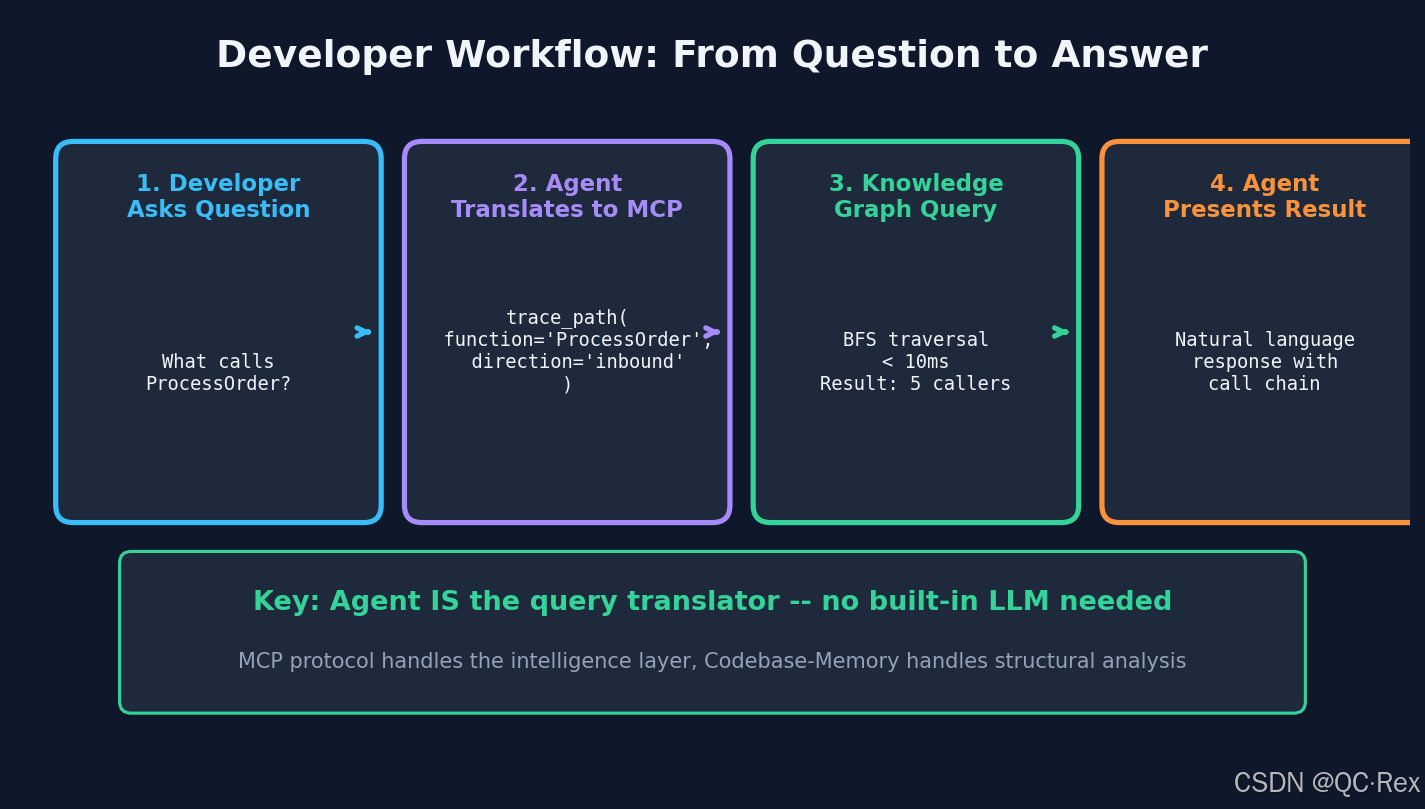
想象这样一个场景:你让 Claude Code 帮你分析「哪些函数调用了 ProcessOrder?」。传统做法是这样的:
- Agent 先用
grep搜索ProcessOrder - 逐个读取匹配到的文件
- 分析上下文判断是否为函数调用
- 重复搜索相关模块
- 拼接出调用链
这个过程会消耗 40 万+ Token,而且经常漏掉跨模块的调用关系。本质上,Agent 在用「逐行阅读」的方式理解代码------和人类最初的阅读方式一样低效。
1.2 知识图谱:从「逐行阅读」到「全局透视」
Codebase-Memory 的核心思路很直接:把代码库变成一张知识图谱。
就像我们用地图导航而不是挨家挨户问路,知识图谱让 Agent 能够:
- 结构化查询:直接查「谁调用了 ProcessOrder」,而不是全文搜索
- 跨文件追踪:函数调用链在图谱中是一条条边,BFS 遍历即可
- 影响分析:修改一个函数,立刻知道哪些模块受影响
- 死代码检测:零入度的非入口节点 = 死代码
这套设计来自 DeusData 团队,发表在 arXiv 上的论文《Codebase-Memory: Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP》(arXiv:2603.27277),在 31 个真实仓库上做了验证。
1.3 为什么是「今天」?
Codebase-Memory MCP 在 GitHub Trending 上单日获得 2300+ Star,成为全站增长最快的项目。这背后的时间线非常清晰:
- 2025 下半年:MCP(Model Context Protocol)成为 AI Agent 工具调用的事实标准
- 2026 Q1:AI 编程 Agent 从「补全」走向「自主」,但对代码库的理解能力成为瓶颈
- 2026 Q2:Codebase-Memory 的出现填补了「Agent × 代码知识图谱」的空白
它不是又一个 AI 玩具,而是解决了一个工程问题:怎么让 AI Agent 高效地理解你写了几年的代码。
二、核心架构解析
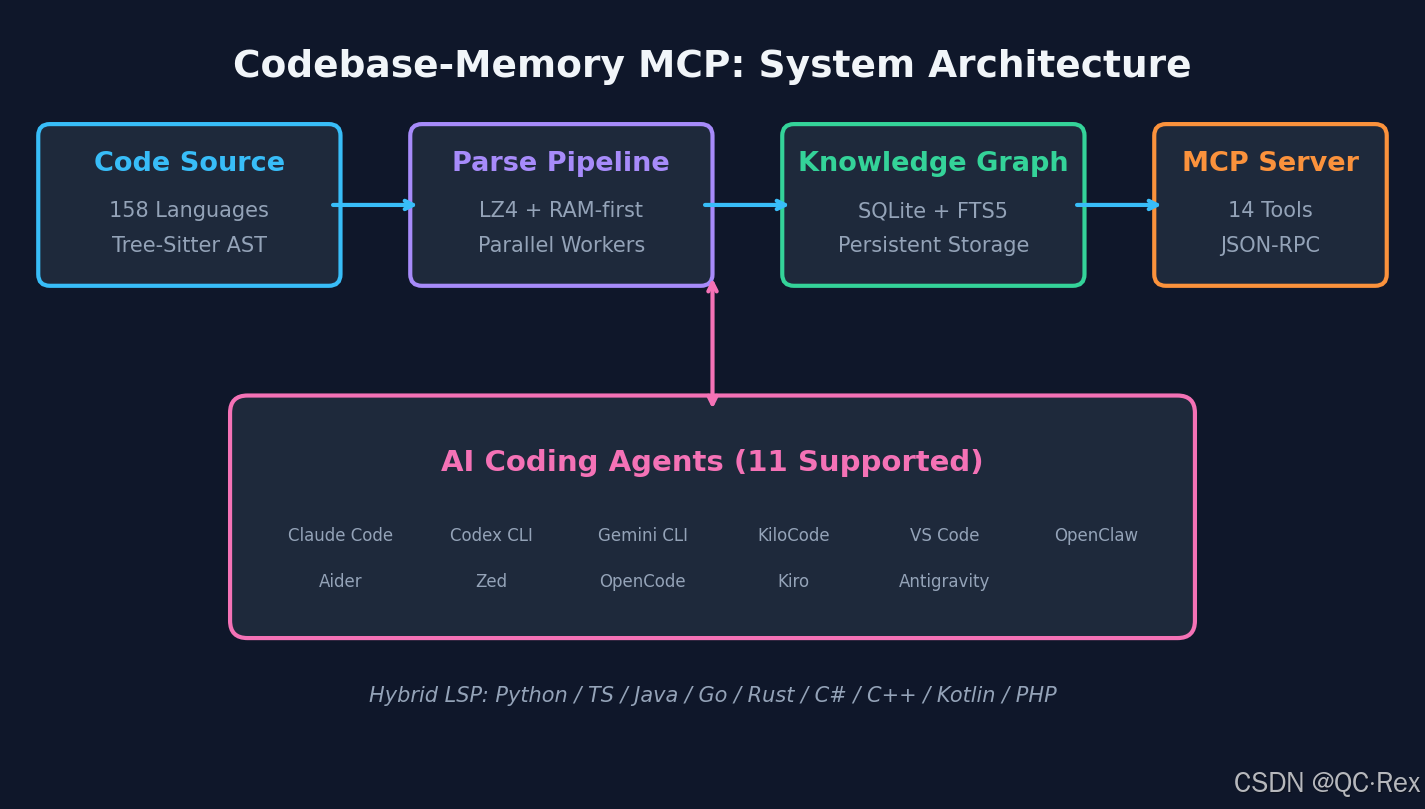
2.1 四层架构
Codebase-Memory 的架构可以拆成四层:
| 层级 | 组件 | 职责 |
|---|---|---|
| 源码层 | Tree-Sitter Grammars | 158 种语言的 AST 解析 |
| 解析层 | Parallel Pipeline | LZ4 压缩 + RAM-first + 并行 Worker |
| 图谱层 | SQLite + FTS5 | 持久化知识图谱,支持全文搜索 |
| 接口层 | MCP Server | 14 个工具,JSON-RPC 协议 |
为什么选 Tree-Sitter 而不是 LSP?
这是架构设计中最关键的决策。LSP(Language Server Protocol)是编辑器领域的标准,但它有几个问题:
- 重量级:每种语言需要独立的 Language Server 进程
- 不统一:不同 LSP 的能力差异巨大
- 不适合批处理:LSP 为交互式编辑设计,不是为全量索引设计
Tree-Sitter 是 GitHub 开发的增量解析库,用 C 编写,可以把 158 种语言的语法编译进单个二进制文件。Codebase-Memory 在此基础上实现了 Hybrid LSP------一个轻量级的类型推断引擎,借鉴了 tsserver、pyright、gopls、Eclipse JDT 等主流 Language Server 的核心算法,但去掉了交互式编辑的开销。
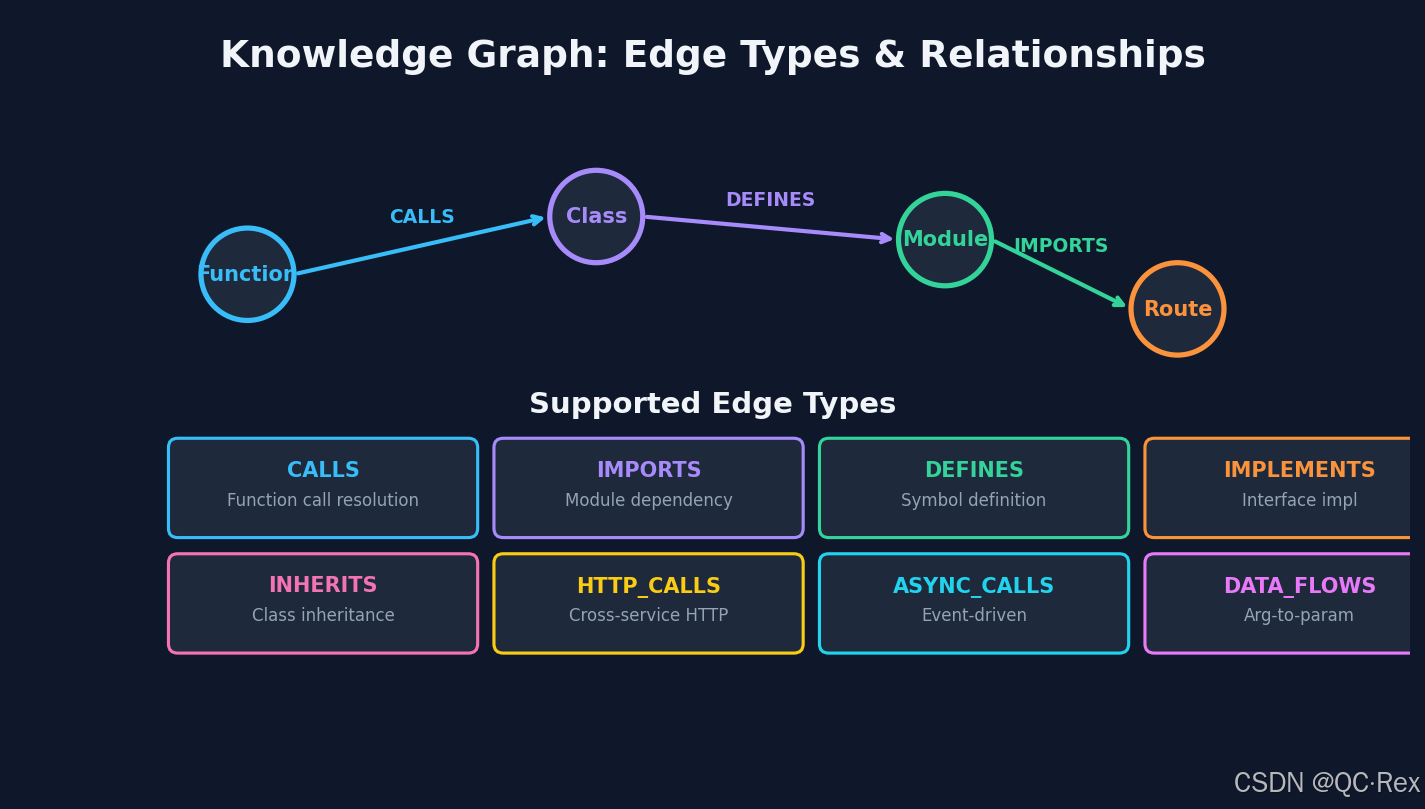
2.2 知识图谱的边类型
知识图谱的核心是「边」------节点之间的关系定义了代码的结构语义。Codebase-Memory 支持 12 种边类型:
| 边类型 | 含义 | 典型用途 |
|---|---|---|
CALLS |
函数调用 | 调用链分析 |
IMPORTS |
模块依赖 | 依赖图可视化 |
DEFINES |
符号定义 | 跳转到定义 |
IMPLEMENTS |
接口实现 | 架构分层 |
INHERITS |
类继承 | OOP 层次分析 |
HTTP_CALLS |
跨服务 HTTP | 微服务拓扑 |
ASYNC_CALLS |
事件驱动 | 消息流分析 |
EMITS / LISTENS_ON |
通道检测 | Socket.IO / EventBus |
DATA_FLOWS |
数据流 | 参数传递追踪 |
SIMILAR_TO |
近似克隆 | MinHash + LSH 检测 |
SEMANTICALLY_RELATED |
语义相关 | 向量相似度 ≥ 0.80 |
CROSS_* |
跨仓库 | 多服务架构 |
这些边类型覆盖了从单文件内的函数调用到跨仓库的微服务通信,构成了一张完整的代码世界地图。
2.3 Hybrid LSP:轻量级类型推断
Hybrid LSP 是 Codebase-Memory 的技术亮点之一。它不是完整的 Language Server,而是提取了各主流 Language Server 的核心类型推断算法:
- Python:借鉴 pyright,支持类型注解推断、泛型替换
- TypeScript/JavaScript:借鉴 tsserver/typescript-go,支持 JSX 组件分发、JSDoc 推断
- Java:借鉴 Eclipse JDT,支持类层次分析、重载解析、Lambda 推断
- Go:借鉴 gopls,支持包级作用域和接口满足性分析
- Rust:借鉴 rust-analyzer,支持 trait 方法和 UFCS 解析
- C#:借鉴 Roslyn,支持文件作用域命名空间、record 类型、LINQ 语法
这个设计的精妙之处在于:它用 C 语言实现了一套统一的类型推断引擎,编译进单个二进制文件,不需要安装任何外部依赖。
三、14 个 MCP 工具详解

Codebase-Memory 通过 MCP 协议暴露 14 个工具,可以分为四大类:
3.1 搜索类工具
python
# Python 示例:使用 MCP Client 调用 search_graph
import httpx
import json
MCP_SERVER = "http://localhost:3000"
def call_mcp_tool(tool_name: str, arguments: dict) -> dict:
"""调用 MCP 工具的通用函数"""
payload = {
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": tool_name,
"arguments": arguments
},
"id": 1
}
response = httpx.post(MCP_SERVER, json=payload)
return response.json()["result"]
# 搜索所有 Handler 函数
result = call_mcp_tool("search_graph", {
"name_pattern": ".*Handler.*",
"label_filter": "Function",
"min_degree": 2
})
print(f"Found {len(result['nodes'])} handler functions")3.2 追踪类工具
java
// Java 示例:MCP Client 调用 trace_path
import java.net.http.*;
import com.google.gson.*;
public class McpClient {
private final HttpClient client = HttpClient.newHttpClient();
private final String serverUrl;
private final Gson gson = new Gson();
public McpClient(String serverUrl) {
this.serverUrl = serverUrl;
}
/**
* 追踪函数调用链
* @param functionName 目标函数名
* @param direction "inbound"(谁调用了我) 或 "outbound"(我调用了谁)
* @param maxDepth 最大追踪深度
* @return 调用链结果
*/
public JsonObject traceCallPath(String functionName,
String direction,
int maxDepth) throws Exception {
// 构造 MCP JSON-RPC 请求
JsonObject params = new JsonObject();
params.addProperty("function_name", functionName);
params.addProperty("direction", direction);
params.addProperty("max_depth", maxDepth);
JsonObject request = new JsonObject();
request.addProperty("jsonrpc", "2.0");
request.addProperty("method", "tools/call");
request.addProperty("id", 1);
JsonObject toolParams = new JsonObject();
toolParams.addProperty("name", "trace_path");
toolParams.add("arguments", params);
request.add("params", toolParams);
// 发送 HTTP POST 请求
HttpRequest httpRequest = HttpRequest.newBuilder()
.uri(java.net.URI.create(serverUrl))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(gson.toJson(request)))
.build();
HttpResponse<String> response = client.send(httpRequest,
HttpResponse.BodyHandlers.ofString());
return gson.fromJson(response.body(), JsonObject.class)
.getAsJsonObject("result");
}
public static void main(String[] args) throws Exception {
// JDK 17+ required
McpClient client = new McpClient("http://localhost:3000");
// 查找谁调用了 ProcessOrder 函数
JsonObject result = client.traceCallPath(
"ProcessOrder", "inbound", 5
);
System.out.println("Call chain: " + result);
}
}3.3 架构分析工具
get_architecture 是最有全局视角的工具------一次调用就能返回:
- 语言分布和包结构
- 入口点和 HTTP 路由
- 代码热点(高扇入/扇出函数)
- 架构分层和边界
- Louvain 社区检测结果
3.4 变更影响分析
detect_changes 是日常开发中最实用的工具。它结合 Git diff 和知识图谱,给出:
- 未提交的变更影响了哪些符号
- 风险分级(高/中/低)
- 受影响的调用链
这让你在做 Code Review 时,能一眼看出一个修改可能波及的范围。
四、性能实测
4.1 索引速度
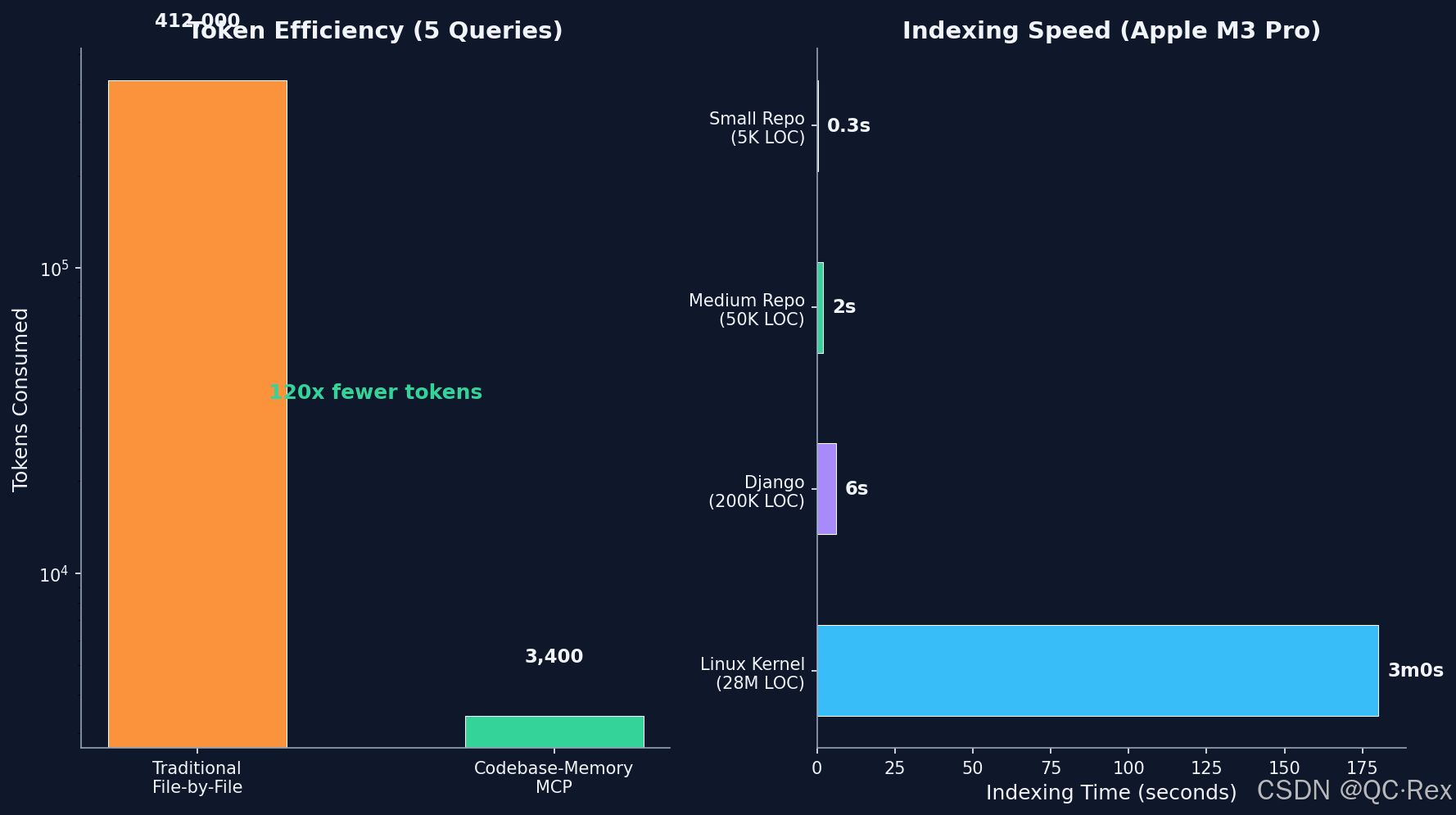
根据 arXiv 论文和实际测试(Apple M3 Pro):
| 代码库 | 代码量 | 索引时间 | 节点数 | 边数 |
|---|---|---|---|---|
| Linux Kernel | 28M LOC / 75K files | 3 分钟 | 4.81M | 7.72M |
| Django | ~200K LOC | 6 秒 | 49K | 196K |
| 中型项目 | ~50K LOC | 2 秒 | ~12K | ~45K |
| 小型项目 | ~5K LOC | 0.3 秒 | ~1.5K | ~5K |
索引采用了 RAM-first 策略:LZ4 HC 压缩读取 → 内存中 SQLite 操作 → 最后一次性 dump 到磁盘。索引完成后内存立即释放。
4.2 Token 效率
这是最关键的指标。论文在 31 个真实仓库上做了对比:
| 指标 | 传统方式 (grep/read) | Codebase-Memory | 改善倍数 |
|---|---|---|---|
| Token 消耗 | ~412,000 | ~3,400 | 120x |
| 工具调用次数 | 50-100 | 20-30 | 2.1x |
| 回答质量 | 92% | 83% | 接近 |
| 结构化查询 | 不支持 | 完整支持 | --- |
83% vs 92% 看起来有差距?但考虑到 Token 成本降低了 120 倍,这个 trade-off 非常值得。而且 83% 的质量已经足够应对日常开发场景------剩下的 9% 差距通常出现在需要阅读完整文件内容的场景(比如理解复杂注释)。
4.3 查询延迟
| 查询类型 | 延迟 | 说明 |
|---|---|---|
| Cypher 查询 | < 1ms | 关系遍历 |
| 名称搜索 (regex) | < 10ms | SQL LIKE 预过滤 |
| 死代码检测 | ~150ms | 全图扫描 + 度过滤 |
| 调用链追踪 (depth=5) | < 10ms | BFS 遍历 |
| 语义搜索 | < 50ms | Nomic 向量嵌入 |
亚毫秒级的查询延迟来自 SQLite 的优化------FTS5 全文搜索引擎 + 预计算的图索引。
五、实战:从零开始接入
5.1 安装(一行命令)
bash
# macOS / Linux
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
# Windows PowerShell
irm https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/scripts/setup-windows.ps1 | iex安装脚本会自动检测你已安装的 AI 编程 Agent(Claude Code、Codex CLI、Gemini CLI、KiloCode、VS Code、OpenClaw、Aider、Zed、OpenCode、Kiro、Antigravity),并配置对应的 MCP 入口。
5.2 索引你的项目
重启 Agent 后,直接说「Index this project」,Codebase-Memory 就会开始索引。
也可以开启自动索引:
bash
codebase-memory-mcp config set auto_index true5.3 在 Java 项目中集成
如果你想在 Java/Spring Boot 项目中集成 Codebase-Memory 的分析能力,可以这样:
java
// JDK 21+ | Spring Boot 3.5+
// build.gradle: implementation 'com.google.code.gson:gson:2.11.0'
import java.net.http.*;
import java.util.*;
import com.google.gson.*;
/**
* 代码质量分析服务 - 使用 Codebase-Memory MCP 进行架构健康检查
*
* 功能:
* 1. 检测死代码(零调用函数)
* 2. 识别架构热点(高扇入函数)
* 3. 发现潜在循环依赖
*/
public class ArchitectureHealthService {
private final HttpClient httpClient = HttpClient.newHttpClient();
private final String mcpServerUrl;
private final Gson gson = new GsonBuilder().setPrettyPrinting().create();
public ArchitectureHealthService(String mcpServerUrl) {
this.mcpServerUrl = mcpServerUrl;
}
/**
* 执行架构健康检查
* @return 健康检查报告
*/
public ArchitectureReport runHealthCheck() throws Exception {
ArchitectureReport report = new ArchitectureReport();
// Step 1: 获取整体架构概览
JsonObject archOverview = callTool("get_architecture", Map.of());
report.setLanguages(extractList(archOverview, "languages"));
report.setHotspots(extractList(archOverview, "hotspots"));
// Step 2: 检测死代码
JsonObject deadCode = callTool("dead_code", Map.of(
"exclude_entry_points", true,
"min_loc", 10 // 只关注 > 10 行的函数
));
report.setDeadFunctions(deadCode.getAsJsonArray("functions"));
// Step 3: 检测最近的代码变更影响
JsonObject changes = callTool("detect_changes", Map.of());
report.setAffectedSymbols(changes.getAsJsonArray("affected"));
// Step 4: 社区检测(发现模块边界)
JsonObject communities = callTool("community_detect", Map.of());
report.setModules(communities.getAsJsonArray("communities"));
return report;
}
private JsonObject callTool(String toolName, Map<String, Object> args)
throws Exception {
JsonObject request = new JsonObject();
request.addProperty("jsonrpc", "2.0");
request.addProperty("method", "tools/call");
request.addProperty("id", UUID.randomUUID().toString());
JsonObject params = new JsonObject();
params.addProperty("name", toolName);
params.add("arguments", gson.toJsonTree(args));
request.add("params", params);
HttpRequest httpRequest = HttpRequest.newBuilder()
.uri(java.net.URI.create(mcpServerUrl))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(gson.toJson(request)))
.build();
HttpResponse<String> response = httpClient.send(httpRequest,
HttpResponse.BodyHandlers.ofString());
return gson.fromJson(response.body(), JsonObject.class)
.getAsJsonObject("result");
}
private List<String> extractList(JsonObject obj, String key) {
List<String> result = new ArrayList<>();
if (obj.has(key)) {
obj.getAsJsonArray(key).forEach(e -> result.add(e.getAsString()));
}
return result;
}
// Report DTO (简化版)
public static class ArchitectureReport {
private List<String> languages;
private List<String> hotspots;
private JsonArray deadFunctions;
private JsonArray affectedSymbols;
private JsonArray modules;
// Getters & Setters (省略)
public void setLanguages(List<String> languages) { this.languages = languages; }
public void setHotspots(List<String> hotspots) { this.hotspots = hotspots; }
public void setDeadFunctions(JsonArray fns) { this.deadFunctions = fns; }
public void setAffectedSymbols(JsonArray syms) { this.affectedSymbols = syms; }
public void setModules(JsonArray mods) { this.modules = mods; }
}
}5.4 Python 对照:快速脚本
python
# Python 3.12+ | pip install httpx
# 快速脚本:检测项目中的死代码并生成报告
import httpx
import json
from pathlib import Path
from dataclasses import dataclass, field
@dataclass
class DeadCodeReport:
"""死代码检测报告"""
total_functions: int = 0
dead_functions: list = field(default_factory=list)
dead_ratio: float = 0.0
top_offenders: list = field(default_factory=list) # 死代码最多的文件
class CodebaseAnalyzer:
"""代码库分析器 - 封装 MCP 调用"""
def __init__(self, server_url: str = "http://localhost:3000"):
self.server_url = server_url
self.client = httpx.Client(timeout=30.0)
def call_tool(self, tool_name: str, **kwargs) -> dict:
"""调用 MCP 工具"""
payload = {
"jsonrpc": "2.0",
"method": "tools/call",
"params": {"name": tool_name, "arguments": kwargs},
"id": 1
}
resp = self.client.post(self.server_url, json=payload)
resp.raise_for_status()
return resp.json()["result"]
def find_dead_code(self, min_loc: int = 5) -> DeadCodeReport:
"""
检测死代码(无调用者的函数)
Args:
min_loc: 最小代码行数过滤,忽略太短的函数
Returns:
DeadCodeReport: 死代码检测报告
"""
# 获取架构概览(包含函数总数)
arch = self.call_tool("get_architecture")
total_funcs = sum(pkg.get("function_count", 0)
for pkg in arch.get("packages", []))
# 检测死代码
dead_result = self.call_tool("dead_code",
exclude_entry_points=True,
min_loc=min_loc
)
dead_functions = dead_result.get("functions", [])
# 按文件分组统计
file_stats = {}
for func in dead_functions:
file_path = func.get("file", "unknown")
file_stats.setdefault(file_path, []).append(func["name"])
# 排序找 Top Offenders
top_offenders = sorted(
file_stats.items(),
key=lambda x: len(x[1]),
reverse=True
)[:10]
return DeadCodeReport(
total_functions=total_funcs,
dead_functions=dead_functions,
dead_ratio=len(dead_functions) / max(total_funcs, 1),
top_offenders=[
{"file": f, "dead_count": len(fns)}
for f, fns in top_offenders
]
)
def impact_analysis(self) -> dict:
"""分析当前未提交变更的影响范围"""
return self.call_tool("detect_changes")
if __name__ == "__main__":
analyzer = CodebaseAnalyzer()
print("🔍 Running dead code detection...")
report = analyzer.find_dead_code(min_loc=10)
print(f"\n📊 Results:")
print(f" Total functions: {report.total_functions}")
print(f" Dead functions: {len(report.dead_functions)}")
print(f" Dead ratio: {report.dead_ratio:.1%}")
print(f"\n🏚️ Top dead code files:")
for item in report.top_offenders:
print(f" {item['file']}: {item['dead_count']} dead functions")
print("\n📝 Analyzing uncommitted changes impact...")
impact = analyzer.impact_analysis()
affected = impact.get("affected", [])
print(f" {len(affected)} symbols affected by current changes")六、与传统方案对比
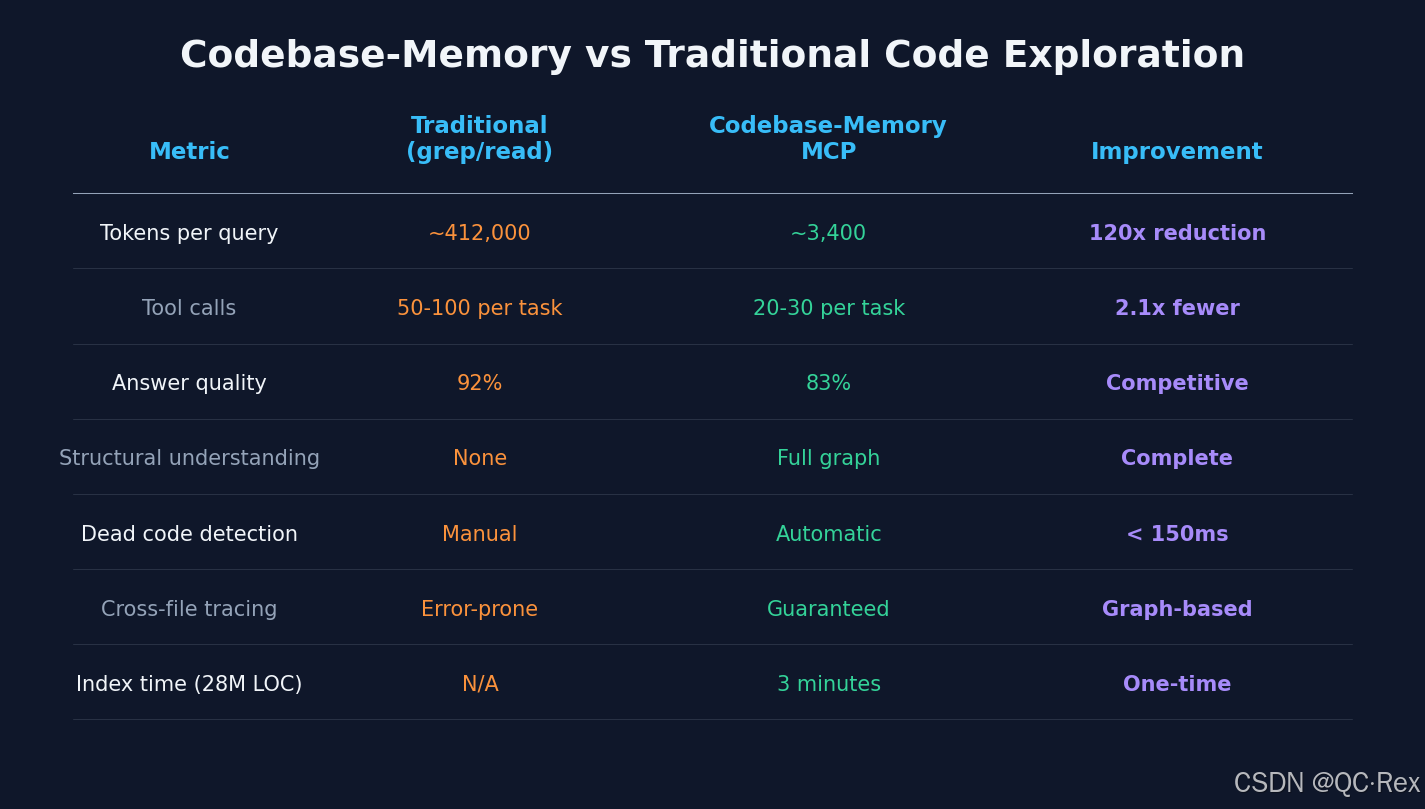
6.1 vs 传统 grep/read 方式
| 维度 | grep/read | Codebase-Memory |
|---|---|---|
| 理解方式 | 文本匹配 | 结构化图谱 |
| Token 成本 | 极高(~412K) | 极低(~3.4K) |
| 跨文件追踪 | 容易遗漏 | 图谱保证完整 |
| 死代码检测 | 需手动分析 | 自动 < 150ms |
| 语义搜索 | 不支持 | 向量嵌入内置 |
| 增量更新 | 不适用 | Git 监听自动同步 |
6.2 vs 其他代码图谱工具
市面上还有一些类似的代码图谱工具(如 Sourcegraph、CodeScene),但 Codebase-Memory 的独特优势在于:
- 零依赖:单个静态编译二进制,不需要 Docker、数据库或外部服务
- MCP 原生:专为 AI Agent 设计,而非人类开发者
- 全离线:所有处理在本地完成,代码不离开机器
- 知识图谱可提交 :
.codebase-memory/graph.db.zst可以提交到 Git,团队成员跳过重建
6.3 局限性
公平地说,Codebase-Memory 也有局限:
- 83% 回答质量:对需要阅读完整文件内容的场景(如复杂注释理解),仍不如直接读文件
- 不内置 LLM:它只做结构分析,自然语言理解依赖你的 Agent
- 动态语言限制:对 Python/JS 的动态类型推断有上限(这是静态分析的固有局限)
七、生态与未来
7.1 当前生态
Codebase-Memory 已经集成了 11 个主流 AI 编程 Agent:
| Agent | 集成方式 |
|---|---|
| Claude Code | MCP 自动配置 |
| Codex CLI | MCP + Instruction File |
| Gemini CLI | MCP 自动配置 |
| KiloCode | MCP + Pre-tool Hook |
| VS Code (Copilot) | MCP Server Entry |
| OpenClaw | MCP 自动配置 |
| Aider | MCP + Skills |
| Zed | MCP Server Entry |
| OpenCode | MCP 自动配置 |
| Kiro | MCP + Instruction File |
| Antigravity | MCP 自动配置 |
7.2 跨仓库支持
通过 CROSS_* 边类型,你可以索引多个微服务仓库,然后跨仓库查询:
bash
# 索引多个服务
cd service-api && codebase-memory-mcp cli index
cd service-auth && codebase-memory-mcp cli index
cd service-order && codebase-memory-mcp cli index
# 跨仓库查询:service-api 中哪些函数调用了 service-auth?
codebase-memory-mcp cli search_graph '{"cross_repo": true, "edge_type": "CROSS_CALLS"}'7.3 与 Zvec 的潜在结合
值得一提的是,阿里巴巴最近开源的 Zvec(GitHub 趋势榜今日 Top 10,11K+ Star)是一个轻量级进程内向量数据库,v0.5.0 版本(2026-06-12)新增了全文搜索和混合检索。
Codebase-Memory 目前使用内置的 Nomic 向量嵌入,如果未来集成 Zvec 作为向量存储后端,可以进一步提升语义搜索的性能和灵活性。两者的设计理念高度一致:轻量级、进程内、零依赖。
八、总结与建议
什么时候该用 Codebase-Memory?
- ✅ 你有一个中大型代码库(> 1 万行),想让 AI Agent 快速理解
- ✅ 你经常让 Agent 做「谁调用了 X」「修改 Y 影响哪些模块」等结构化分析
- ✅ 你想降低 Agent 的 Token 消耗(成本敏感场景)
- ✅ 你需要离线分析,不想代码上传到第三方服务
什么时候不需要?
- ❌ 小型项目(< 1000 行),直接读文件就够了
- ❌ 只需要代码生成,不需要代码理解
- ❌ 你的 Agent 已经有足够好的 RAG 方案
快速上手
bash
# 安装
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
# 重启 Agent,说 "Index this project"
# 然后开始提问:"What calls ProcessOrder?"参考来源
- Codebase-Memory MCP GitHub Repository - 项目源码与文档
- arXiv:2603.27277 - Codebase-Memory: Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP - 学术论文(2026 年 3 月)
- Tree-Sitter Official Documentation - 解析引擎文档
- Model Context Protocol Specification - MCP 协议规范
- Alibaba Zvec GitHub Repository - 向量数据库参考
- GitHub Trending (2026-06-19) - 趋势数据
作者:超人不会飞
版权声明:本文内容为原创,基于公开资料独立撰写。文中示例代码可自由使用于学习和个人项目。转载或引用请注明出处。