一、数据存储格式
Spark SQL支持多种文件存储格式,主要分为行式存储 和列式存储两大类。
1. 行式存储:数据按行组织,同一行的所有字段值在物理上连续存放。
以一张用户表为例(ID, Name, Age, City):
sql
行1:| 1 | 张三 | 28 | 北京 |
行2:| 2 | 李四 | 35 | 上海 |
行3:| 3 | 王五 | 22 | 广州 |在磁盘上,它会被存成:
sql
[1,张三,28,北京][2,李四,35,上海][3,王五,22,广州]...主要特点:
-
写入非常快:新增一行直接追加在末尾即可,无需重组数据。
-
整行读取效率高 :适合
SELECT *或需要大部分字段的查询。 -
压缩率较低:一行内不同字段的数据类型、值分布差异大,压缩算法难以发挥作用。
-
列查询代价大 :如果只计算平均年龄
SELECT AVG(Age),仍必须扫描所有行的全部字段,I/O浪费严重。
适用场景:
-
OLTP (在线事务处理):频繁的增删改,或者需要查询全部字段的情况。
-
流式数据写入:数据源逐条到达,快速追加到文件,如Kafka消息落盘成 Avro 文件。
1.1 CSV文本行式
CSV是纯文本表格数据,读写简单,通用性极强,但无内建类型和索引。字段用逗号/制表符等分隔,不包含 Schema,解析开销大,压缩后不可拆分。适用于用户手工文件上传落表等情况。
sql
CREATE TABLE user_csv (
id INT,
name STRING,
age INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' -- 指定按逗号分隔
STORED AS TEXTFILE
-- 使用gzip压缩,数据量不大的情况,也可以删除该行不使用压缩
TBLPROPERTIES ('compression'='gzip');1.2 JSON半结构化文本行式
JSON是一种轻量化的数据交换格式,广泛应用于Web应用和分布式系统之间的数据交互。相比CSV来说,支持复杂嵌套结构。
Spark 2.2+ 可直接使用 JSONFILE:
sql
CREATE TABLE user_json (id INT, name STRING, age INT)
STORED AS JSONFILE
TBLPROPERTIES ('compression'='gzip');或老版本用 Hive SerDe:
sql
CREATE TABLE user_json (id INT, name STRING, age INT)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;1.3 Avro二进制行式
Apache Avro 是一个基于 Schema 的、与语言无关的二进制数据序列化系统 。它不像 JSON 那样是纯文本,也不像 Parquet 那样是列式分析格式。Avro 的核心使命是:让数据在分布式系统的不同组件之间高效、安全地流动,同时允许数据结构随时间自由演化。适用于流处理、Schema 频繁演化的数据落地,比如基于Kafka的数据管道。
核心设计:Schema 与数据分离
-
Schema 用 JSON 定义
描述数据的字段名、类型、默认值等,人类可读。
-
数据以紧凑二进制存储
序列化后的记录不携带字段名和结构信息,只是按 Schema 顺序紧密排列值。这带来了极小的体积和极快的解析速度。
-
读取必须拥有 Schema
写入时的 Schema(写 Schema)与读取时的 Schema(读 Schema)可以不同,Avro 会自动按照字段名进行匹配和转换------这正是 Schema 演化的基石。
-
Schema 演化:向后与向前兼容( 双 Schema 解析)
Avro 数据文件中存储的是 Writer Schema 编码的二进制数据。读取时,若提供不同的 Reader Schema,Avro 解析器会根据字段名映射和默认值规则自动转换数据,而非直接报错。
sql
CREATE TABLE user_avro (
id INT,
name STRING,
age INT
) STORED AS AVRO
TBLPROPERTIES ('avro.compress'='snappy');1.4 SequenceFile二进制键值对行式
Hadoop的键值对二进制格式,常用于Hadoop 中间数据传递(Spark SQL较少直接使用),适用于MapReduce 中间结果、数据合并、小文件归档的情况。
2. 列式存储:数据按列组织,同一列的所有值在物理上连续存放。
同样用用户表举例,磁盘布局会变成:
sql
ID列: [1,2,3,...]
Name列: [张三,李四,王五,...]
Age列: [28,35,22,...]
City列: [北京,上海,广州,...]主要特点:
-
分析查询极快:列裁剪(只读需要的列),极大减少I/O。
-
压缩率极高:同一列数据类型一致,值域往往相近,非常适合游程编码(Run-Length Encoding, RLE)、字典编码(Dictionary Coding,如LZW)等,存储空间通常只有行式的1/3~1/10。
-
谓词下推与向量化:列存文件内部通常包含列块统计信息(min/max等),可以快速跳过不满足条件的整块数据;向量化引擎能一次处理一批列值,CPU效率高。
-
写入较慢:需要将行数据拆分成列并缓冲成列块后才能写入,内存和计算开销较大。
-
单行更新昂贵:如果要修改一行中的某个字段,可能需要重写整个列块,不适合频繁随机更新。
适用场景:
-
OLAP 在线分析查询:大宽表上只对少数列做聚合、分组、过滤。
-
数据仓库 / 数据湖:海量历史数据存储,追求高压缩比和扫描效率。
2.1 Parquet
Apache Parquet 是一种开源的列式存储文件格式,专为大数据处理和分析场景设计。
一个Parquet文件的内容由Header、Data Block和Footer三部分组成。在文件的首尾各有一个内容为PAR1的Magic Number,用于标识这个文件为Parquet文件。
Header部分就是开头的Magic Number。
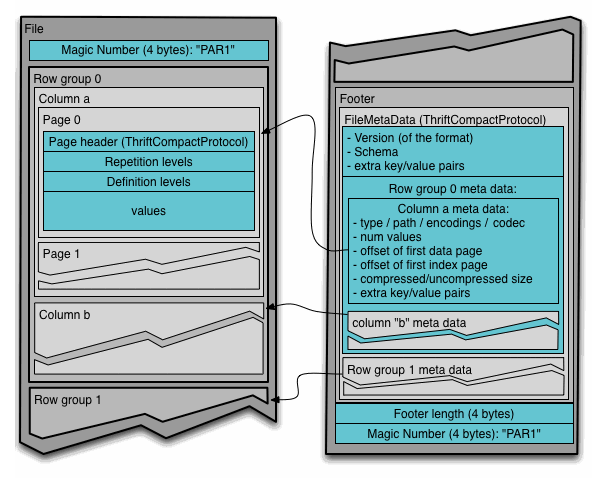
Data Block是具体存放数据的区域,由多个Row Group组成,具体概念内容如下:
- Row Group(行组) :数据集的水平切片。Parquet 将整张表按行数水平划分为N个 Row Group。每个 Row Group 包含该组内 所有列 的数据,是一个独立的并行处理单元。默认大小为128 MB(与HDFS Block一致),由于一个Map Task一般处理一个Block的数据,这样设置可以增大任务执行并行度。
sql
Row Group 0: 包含第 1 ~ 200,000 行的所有列数据
Row Group 1: 包含第 200,001 ~ 400,000 行的所有列数据
...
Row Group 4: 包含第 800,001 ~ 1,000,000 行的所有列数据这样划分的好处:每个 Row Group 可被不同的 Spark Task 并行读取;Row Group 级别的统计信息(Footer 中)能让我们直接跳过整个不相关的 Row Group。
- Column Chunk(列块) :一个 Row Group 内某一列的所有数据,被组织成多个 Page。
sql
Row Group 0
├── Column Chunk for "id" (200,000 个整数)
├── Column Chunk for "name" (200,000 个字符串)
├── Column Chunk for "age" (200,000 个整数)
└── Column Chunk for "city" (200,000 个字符串)每个 Column Chunk 在 Footer 中都会记录自己的元数据:
- 统计信息 :
min_value,max_value,null_count等 - 编码与压缩信息:用了什么编码(如 Dictionary + RLE)、压缩算法(Snappy)
- 物理偏移量:该 Column Chunk 的起始位置和大小
这些统计正是 谓词下推 的依据。例如 city 列的 Column Chunk 统计显示 min_value = 'Baoding', max_value = 'Shanghai',如果查询条件 WHERE city = 'Zhengzhou',这个 Row Group 的 city 值范围完全不包含 'Zhengzhou',整个 Row Group 就可以被跳过。
-
Page(页):最小的 I/O 和编码单位。包含三种类型:
-
数据页 (Data Page):存储列的实际值,经过编码和压缩。
-
字典页 (Dictionary Page):如果该 Column Chunk 使用了字典编码,会有一个字典页记录所有唯一值及其映射,后面的数据页则只存储整数索引。
-
索引页:Page 级别的偏移量索引(可选)。
-
sql
Column Chunk: city (Row Group 0)
├── Dictionary Page: [0->'Beijing', 1->'Shanghai', ..., 19->'Hangzhou']
├── Data Page 0: (行 1~20,000 的 city 索引) → [0,1,5,0,0,...] (RLE 压缩)
├── Data Page 1: (行 20,001~40,000 的索引)
└── Data Page 2: (行 40,001~60,000 的索引)
...如果查询需要 city = 'Beijing',Parquet 读取器会先加载字典页,将过滤条件转化为索引 0,然后在每个 Data Page 内查找是否包含 0。Page 级别的索引(Parquet Page Index,2.0+ 版本)还能记录每个 Page 内的 min/max 索引,帮助直接跳过不包含索引 0 的 Page,进一步提升效率。
Footer 部分用来存储整个文件的元数据,由File Metadata、Footer Length和Magic Number三部分组成。
- **FileMetaData:**记录文件元数据信息,包括Schema和每个Row Group的Metadata。每个Row Group的Metadata又由各个Column的Metadata组成,每个Column Metadata包含了其Encoding、Offset、Statistic信息等等。
sql
FileMetaData {
version : int (格式版本,如 1 或 2)
schema : list<SchemaElement> (表结构的完整描述)
num_rows : long (文件总行数)
row_groups : list<RowGroup> (每个 Row Group 的元数据)
key_value_metadata : optional list<KeyValue> (自定义属性)
created_by : optional string (生成该文件的库与版本,如 "parquet-mr version 1.12.2")
column_orders : optional list<ColumnOrder> (列的排序规则)
}-
**Footer Length:**4 字节有符号整数,用于标识Footer部分的大小,帮助找到Footer的起始指针位置
-
**Magic Number:**再次 "PAR1"
2.2 ORC
与 Parquet 相比,ORC 的 Header/Footer 架构更显"重索引"------它把部分索引从中心元数据下放到 Stripe 内部,牺牲了一点简单性,换取了在 Hive 数仓场景下更锐利的点查询和范围过滤性能。
二、压缩格式
| 压缩格式 | 压缩比 | 压缩速度 | 解压速度 | 是否可拆分(文件级) | 典型应用场景 |
|---|---|---|---|---|---|
| Snappy | 较低 | 极快 | 极快 | 否(但容器内部可拆分) | Parquet/ORC内部默认压缩,追求速度与平衡 |
| Gzip | 高 | 慢 | 中等 | 否(文本gzip整体不可拆分) | 长期归档、需要高压缩比的文本/CSV |
| Zstd | 高(可调) | 快 | 极快 | 可实现(需特定容器支持) | 新一代平衡选择,Parquet/ORC的理想压缩 |
| LZ4 | 低 | 极快 | 极快 | 否 | Shuffle数据、临时中间结果压缩 |
| Bzip2 | 很高 | 极慢 | 慢 | 是(块边界可拆分) | 极低存储要求的归档,几乎不用 |
| LZO | 中等 | 快 | 快 | 需建立索引后支持拆分 | Hadoop生态老旧场景,需额外安装库 |
三、补充:Parquet 在查询执行时的全流程
假设我们要在 Spark SQL 中执行:
sql
SELECT AVG(age) FROM users WHERE city = 'Beijing';1. 读取 Footer,获取全局元数据
Spark 首先读取文件尾部 Footer,得到:
-
Schema:4 个字段及其类型
-
所有 Row Group 的列表,以及每个 Row Group 内每个 Column Chunk 的统计信息(min/max/null)
2. 基于统计信息跳过 Row Group(谓词下推)
针对 city 列,Footer 显示每个 Row Group 的统计:
-
Row Group 0:
citymin='Baoding', max='Shanghai' → 包含 'Beijing',需要读取 -
Row Group 1:
citymin='Chengdu', max='Wuhan' → 不包含 'Beijing',整个跳过 -
Row Group 2: min='Anshan', max='Beijing' → 包含 'Beijing',需要读取
-
Row Group 3: min='Nanjing', max='Zhengzhou' → 不包含,跳过
-
Row Group 4: min='Beijing', max='Shenzhen' → 包含,需要读取
最终只需读取 Row Group 0, 2, 4,I/O 立即减少约 40%。
3. 列裁剪:只读需要的列
在每个需要读取的 Row Group 内,Spark 只读取涉及的两列:
-
city(用于过滤) -
age(用于聚合)
id 和 name 的 Column Chunk 完全不被访问,再次大幅减少 I/O。
4. 在 Row Group 内部,通过 Page 精确读取
以 Row Group 0 的 city 列为例:
-
先读取 字典页,将 'Beijing' 转换成索引 0。
-
扫描
city的各个 Data Page(可配合 Page Index 跳过不含索引 0 的页),找出所有city = 'Beijing'的行号。 -
根据这些行号,到
age列的 Column Chunk 中读取对应行的年龄值。因为age也是列式存储且同步分页,Parquet 可以只读取包含这些目标行的agePage。
5. 向量化计算
读取出的 age 值以批处理(向量化)的方式送入 CPU,计算平均值,最终返回结果。
整个过程,Parquet 将全表扫描优化成了:只读部分 Row Group + 只读两列 + 只读满足过滤条件的少数 Page,性能提升可达数十甚至上百倍。
四、补充:Parquet的Row Group、Column Chunk 的元数据信息
sql
RowGroup {
total_byte_size : long (该 Row Group 总字节数)
num_rows : long (该 Row Group 包含的行数)
columns : list<ColumnChunk> (每列的 Chunk 元数据)
file_offset : optional long (Row Group 在文件中的起始偏移,Parquet 2.0+)
total_compressed_size : optional long
sorting_columns : optional list<SortingColumn>
}
sql
ColumnChunk {
file_path : string (如果文件是集合中的一个,通常为 null)
file_offset : long (该 ColumnChunk 在文件中的起始偏移量)
meta_data {
type : Type (列的数据类型)
encodings : list<Encoding> (使用的编码,如 PLAIN_DICTIONARY, RLE)
path_in_schema: list<string> (列在 Schema 树中的路径,如 ["users", "name"])
codec : CompressionCodec (压缩算法,SNAPPY, GZIP 等)
num_values : long (该 Chunk 中值的数量)
total_uncompressed_size : long
total_compressed_size : long
key_value_metadata : optional list<KeyValue>
/** 统计信息,用于谓词下推 **/
statistics : Statistics {
max : binary (最大值,编码后的形式)
min : binary (最小值)
null_count: long
distinct_count: long (可选,唯一值大约数量)
max_value : binary (Parquet 2.0+ 增强统计)
min_value : binary
}
}
offset_index_offset : optional long (Page 索引位置,2.0+)
offset_index_length : optional long
column_index_offset : optional long (列索引位置,2.0+)
column_index_length : optional long
}