一句话概括:通过 ftrace 拦截 read 系统调用,在内核空间把不想让人看到的日志行"吃掉",让用户空间拿到的永远是"干净"的数据。
一、这篇文章到底在讲什么?
想象这样一个场景:你写了一个内核模块(LKM),加载进系统后,内核会在日志里留下一条记录,比如"加载了一个未签名的模块"。这条记录会被 dmesg 命令和 /dev/kmsg 设备文件暴露出来。对于做安全研究的人来说,这条记录就像黑夜里的手电筒------太显眼了。
本文要探讨的就是:怎么让这条记录从 dmesg 和 /dev/kmsg 里"消失",但又不影响系统正常运行。
重要前提:这个技巧无法 隐藏
journalctl -k里的日志(那是 systemd-journald 管的),也无法 隐藏已经写入/var/log/kern.log的日志(那是 rsyslog 持久化到磁盘的)。它的目标很明确------只针对dmesg和/dev/kmsg这两个实时读取接口。
二、为什么偏偏盯上 dmesg 和 /dev/kmsg?
先搞清楚它们的关系:
/dev/kmsg是一个字符设备文件,内核日志的"水龙头"。你cat /dev/kmsg或者程序open()它再read(),就能拿到内核环形缓冲区里的日志。dmesg命令本质上就是打开/dev/kmsg,一行一行读出来展示给你看。
所以只要控制住 /dev/kmsg 的读取出口,就等于同时控制住了 dmesg 的输出口。这是一个"打一处、控两处"的巧妙设计。
三、核心思路:在 read 系统调用上"搭个收费站"
整个方案的核心就一句话:
拦截
read()系统调用 → 判断读的是不是/dev/kmsg→ 如果是,先读全部内容,在内核空间过滤掉敏感行,再把"干净"的数据返回给用户。
听起来简单,但实现起来涉及几个关键技术点,下面逐一拆解。
四、ftrace:不用改内核源码就能"劫持"函数
4.1 传统 Hook 的痛点
以前想 Hook 内核函数,常见做法是直接修改系统调用表(sys_call_table),把函数指针换成自己的。但这种方式有几个问题:
- 系统调用表地址不固定,需要动态查找
- 现代内核有写保护(CR0.WP),得先关闭再恢复
- 容易被检测到,稳定性差
4.2 ftrace 的优势
ftrace 是 Linux 内核自带的一个动态追踪框架 ,原本是给性能分析用的。它的厉害之处在于:可以在不修改内核源码、不重启系统的情况下,在任意函数入口处插入一个"跳板",把执行流跳转到你自己的函数。
而且 ftrace 是内核"官方"提供的机制,用起来比直接改内存安全得多,兼容性好,从老内核到新内核都能用。
4.3 怎么让 ftrace 帮你 Hook?
大致分三步:
| 步骤 | 做什么 | 对应代码 |
|---|---|---|
| 找地址 | 用 kallsyms_lookup_name() 查目标函数的内存地址 |
fh_resolve_hook_address() |
| 设过滤 | 用 ftrace_set_filter_ip() 告诉 ftrace 要盯哪个地址 |
fh_install_hook() |
| 注册Hook | 用 register_ftrace_function() 正式生效 |
fh_install_hook() |
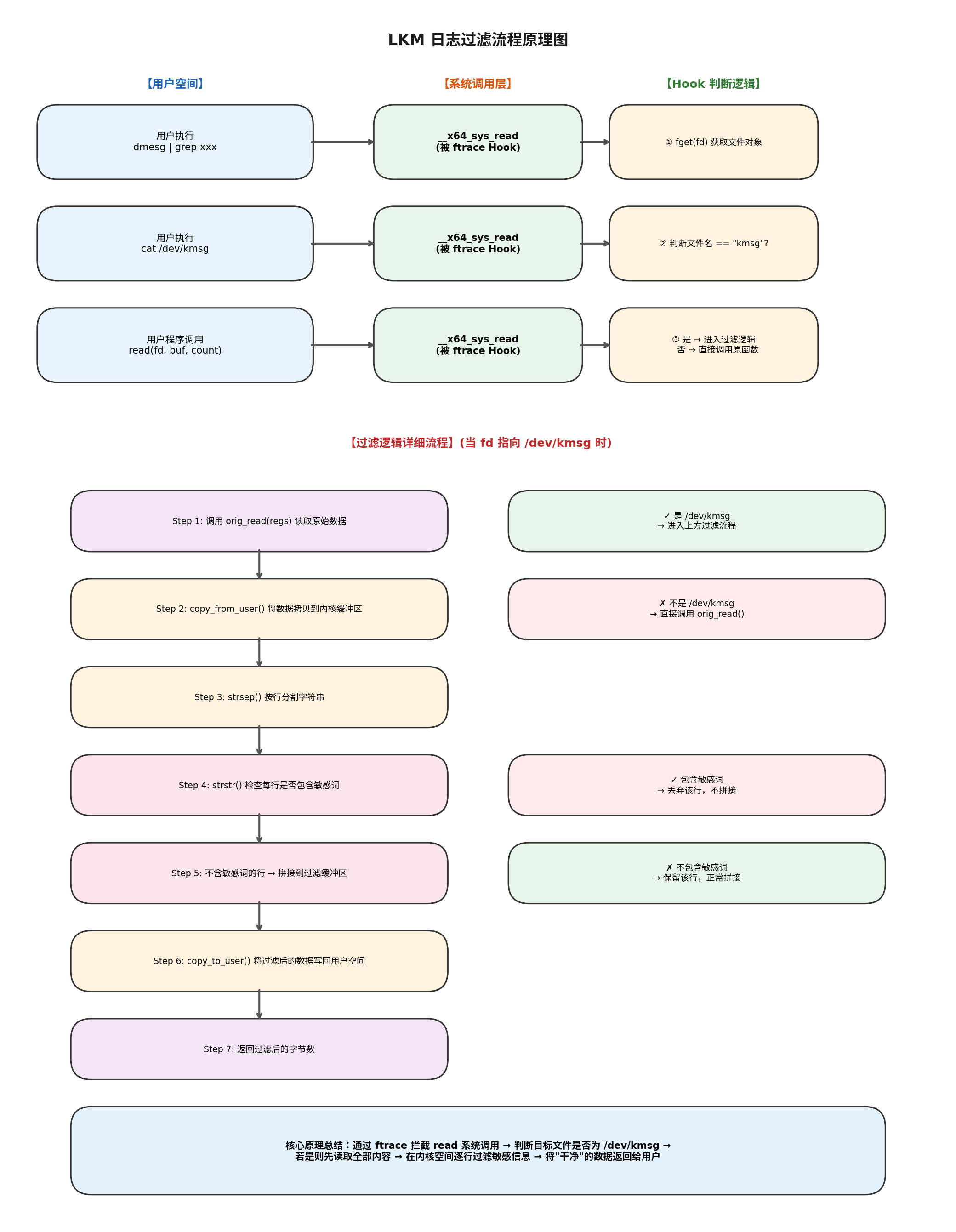
上图展示了完整的流程:左边是模块加载时的"安装"阶段,右边是运行时的"拦截"阶段。关键数据结构 struct ftrace_hook 把函数名、Hook 函数、原始函数地址打包在一起,通过 HOOK 宏定义方便地初始化。
三个关键标志位必须同时设置:
FTRACE_OPS_FL_SAVE_REGS:保存寄存器,因为我们要改指令指针($rip)FTRACE_OPS_FL_RECURSION:关闭 ftrace 内置的防递归(因为我们要自己控制)FTRACE_OPS_FL_IPMODIFY:允许修改指令指针,这是跳转到 Hook 函数的关键
注意:关闭内置防递归后,必须自己实现防递归逻辑。代码里用
within_module(parent_ip, THIS_MODULE)检查调用来源,如果是自己模块发起的调用就直接放行,避免死循环。
五、Hook 函数的逻辑:过滤器的"心脏"
当 ftrace 成功把 read() 系统调用拦截下来后,控制权交到了 hook_read() 函数手里。这个函数是整个方案最核心的部分。
5.1 整体流程图
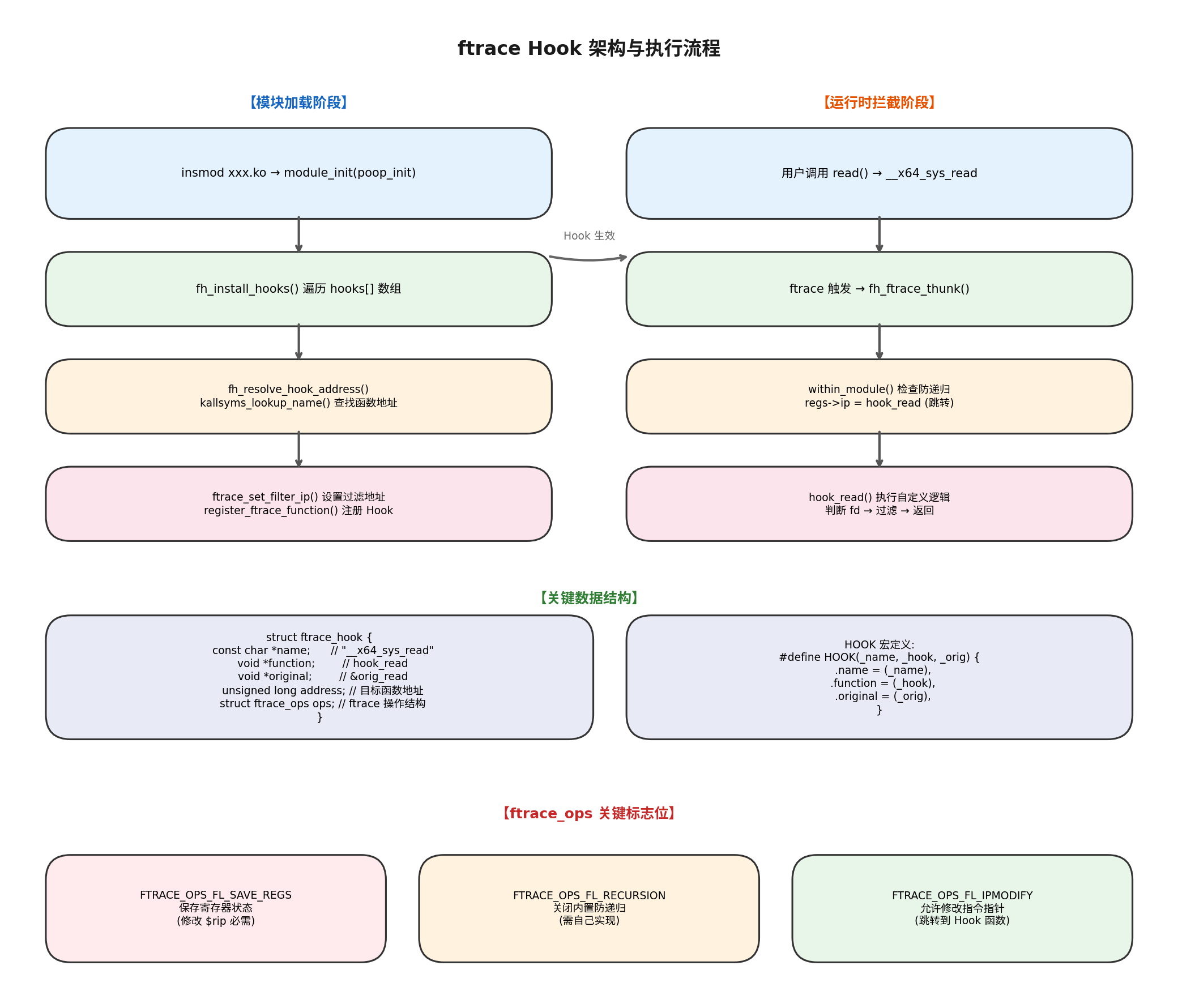
If you need the complete source code, please add the WeChat number (c17865354792)
5.2 逐行解读核心逻辑
c
static asmlinkage ssize_t hook_read(const struct pt_regs *regs) {
int fd = regs->di; // x86_64 调用约定:第一个参数在 rdi 寄存器
char __user *user_buf = (char __user *)regs->si; // 第二个参数:用户缓冲区
size_t count = regs->dx; // 第三个参数:读取字节数这里用 pt_regs 结构体直接读取寄存器值来获取系统调用参数。在 x86_64 架构上,系统调用参数依次放在 rdi、rsi、rdx 等寄存器里。
c
file = fget(fd); // 根据文件描述符拿到文件对象
if (file && strcmp(file->f_path.dentry->d_name.name, "kmsg") == 0) {这一步是整个判断的关键 :通过 fget(fd) 拿到 struct file,再顺着 file->f_path.dentry->d_name.name 拿到文件名,跟 "kmsg" 比对。如果匹配,说明用户在读 /dev/kmsg,进入过滤逻辑;不匹配就直接调用原始 read() 放行。
c
bytes_read = orig_read(regs); // 先调用原始 read,拿到真实数据
copy_from_user(kernel_buf, user_buf, bytes_read); // 拷贝到内核空间这里有个"反直觉"的操作:数据已经从内核写到用户空间了(orig_read 干的),现在又要 copy_from_user() 拷贝回内核。为什么?
因为我们要在内核空间做字符串处理(分割、匹配),而用户空间的地址在内核里直接访问是不安全的。 copy_from_user() 会做地址合法性检查,防止用户传入恶意地址导致内核崩溃。
c
t = strsep(&kernel_buf, "\n"); // 按换行符分割
while (t) {
if (!strstr(t, "敏感词")) { // 不包含敏感词的行保留
strncat(filtered_buf, t, B_F - filtered_len - 1);
}
t = strsep(&kernel_buf, "\n");
}逐行过滤的核心逻辑 :用 strsep() 把日志按行拆开,每行用 strstr() 检查是否包含敏感关键词。不包含的就拼到 filtered_buf 里,包含的就直接跳过(相当于"吃掉"了)。
strsep()是内核空间推荐的字符串分割函数,比strtok()线程安全,而且内核里不能用strtok()。它的工作方式是:在字符串中查找分隔符,替换成\0,返回当前段指针,同时更新原指针指向下一段。
c
copy_to_user(user_buf, filtered_buf, filtered_len); // 写回用户空间
return filtered_len; // 返回过滤后的长度最后把"干净"的数据拷贝回用户缓冲区,返回过滤后的字节数。用户程序(比如 dmesg)拿到的是已经被处理过的数据,完全不知道自己"丢"了几行。
六、数据流向全解析
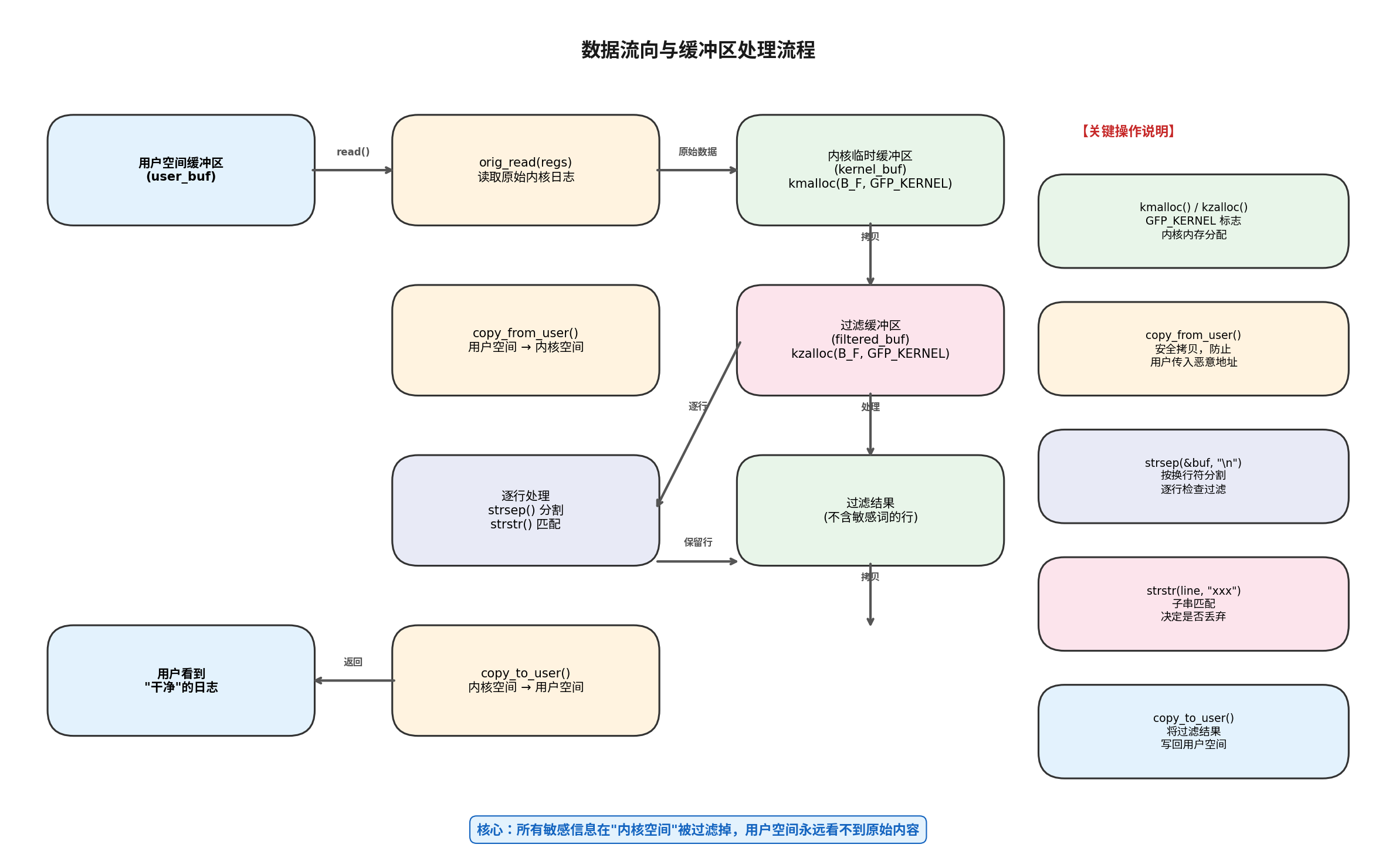
上图展示了数据在内核和用户空间之间的完整流动路径,有几个关键点值得注意:
6.1 内存分配策略
代码里用了 kmalloc() 和 kzalloc():
kmalloc(B_F, GFP_KERNEL):分配临时缓冲区,GFP_KERNEL表示可以睡眠等待内存(标准分配方式)kzalloc(B_F, GFP_KERNEL):分配过滤缓冲区,并且自动清零(避免残留旧数据)
为什么要分配两块缓冲区?
kernel_buf:存放从用户空间拷贝回来的原始数据(会被strsep()修改,因为它会插入\0)filtered_buf:存放过滤后的结果,保持独立,避免污染
6.2 错误处理
代码里对每一步都做了错误检查:
kmalloc失败 → 返回-ENOMEM(内存不足)orig_read返回负数 → 直接返回错误码copy_from_user失败 → 返回-EFAULT(非法地址)copy_to_user失败 → 同样返回-EFAULT
这种"防御式编程"在内核模块里尤为重要,因为内核崩溃会导致整个系统宕机。
6.3 资源释放
每个 kmalloc 都有对应的 kfree,每个 fget 都有对应的 fput。这是内核编程的基本纪律------申请的资源必须释放,否则就是内存泄漏。
七、涉及的知识领域总结
这个 Demo 虽然代码量不大,但横跨了多个 Linux 内核的核心领域:
7.1 系统调用机制
- x86_64 的系统调用参数传递约定(
pt_regs结构体) read()系统调用的内核入口__x64_sys_read- 文件描述符(fd)与
struct file的映射关系
7.2 ftrace 动态追踪
ftrace_ops结构体的配置与标志位ftrace_set_filter_ip()和register_ftrace_function()的使用- 防递归机制的设计(
within_module()检查)
7.3 内核内存管理
kmalloc()/kzalloc()与GFP_KERNEL标志- 内核空间与用户空间的数据拷贝(
copy_from_user()/copy_to_user()) - 内核缓冲区的生命周期管理
7.4 内核字符串处理
strsep()的用法与注意事项(会修改原字符串)strstr()子串匹配strncat()的安全拼接(带长度限制)
7.5 内核日志子系统
/dev/kmsg设备文件的工作原理dmesg命令与/dev/kmsg的关系- printk 日志环形缓冲区的读取机制
7.6 内核模块编程
module_init()/module_exit()生命周期MODULE_LICENSE()、MODULE_AUTHOR()等元数据- 内核模块的编译与加载(
insmod/rmmod)
7.7 安全与对抗
- 内核模块加载时的"痕迹"问题
- 日志过滤作为隐藏手段的原理与局限
- 不同日志接口(
dmesg、journalctl、rsyslog)的独立性
八、设计思路的"巧"与"拙"
8.1 巧妙之处
- "打一处、控两处" :只 Hook
read()系统调用,同时控制了dmesg和cat /dev/kmsg的输出,因为它们的底层都是read()。 - 在内核空间过滤:数据还没回到用户空间就被"清洗"了,用户程序完全无感知。
- ftrace 的合法性:利用内核官方机制做 Hook,比直接改内存稳定得多,跨内核版本兼容性也好。
8.2 局限之处
- 只影响实时读取 :已经写入
/var/log/kern.log或 journal 的日志无法回溯删除。 - 字符串匹配简单粗暴 :用
strstr()做子串匹配,如果日志内容里正常出现了敏感词(比如某个文件名恰好包含),也会被误杀。 - 单线程假设 :代码没有处理并发读取
/dev/kmsg的情况,多个进程同时读可能会有竞态条件。 - 性能开销 :每次读
/dev/kmsg都要额外做一次内存分配、拷贝、分割、匹配,高频读取时会有一定性能损耗。
九、测试运行
先制造一条包含敏感词的日志:
bash
# 用 root 权限往 /dev/kmsg 写一条测试日志
sudo bash -c 'echo "<1>This is a taint message for testing" > /dev/kmsg'验证日志存在(加载模块前):
bash
sudo dmesg | grep -i taint
# 应该能看到输出加载模块:
bash
sudo insmod matheuz.ko再次查看 dmesg(敏感词应该被过滤了):
bash
sudo dmesg | grep -i taint
# 应该没有任何输出!但其他正常日志还在:
bash
sudo dmesg | tail -5
# 能看到最新的日志,只是没有包含 "taint" 的行测试 /dev/kmsg:
bash
sudo cat /dev/kmsg | grep -i taint
# 同样没有输出卸载模块:
bash
sudo rmmod matheuz卸载后再测试:
bash
sudo dmesg | grep -i taint
# 现在又能看到之前的敏感词了(因为 dmesg 有缓存,新读 /dev/kmsg 会重新过滤)九、总结
这个小 Demo 展示了一种"中间人攻击"思路在内核层面的应用:不破坏日志的生成和存储,只在"出口"处做过滤。它的技术含量不在于代码有多复杂,而在于对内核机制的理解深度 ------知道 dmesg 读的是 /dev/kmsg,知道 read() 是系统调用,知道 ftrace 能 Hook 函数,知道内核空间怎么安全地处理用户数据。
对于做安全研究、内核调试或者想深入理解 Linux 内核的人来说,这个案例是个很好的切入点。它把系统调用、ftrace、内存管理、字符串处理、日志子系统这些知识点串在了一条线上,读完代码再对照流程图走一遍,基本上就能摸清门道了。
最后提醒:这类技术主要用于安全研究和防御学习,了解攻击原理是为了更好地做防护。在实际生产环境中,任何对内核的修改都应该慎之又慎。
Welcome to follow WeChat official account【程序猿编码】