1 绪论
1.1 课题研究背景
近年来,中国农产品电商行业保持高速增长态势。根据商务部发布的《中国电子商务报告(2022)》显示,全国农产品网络零售额已突破5000亿元,年均增速超过10%。然而,在市场规模持续扩大的同时,消费者在选购农产品时面临"信息过载"与"品质甄别困难"的双重困境。一方面,平台商品种类繁多,用户难以从海量产品中高效定位符合个人口味的商品;另一方面,绿色食品、有机认证等高品质农产品缺乏有效的流量分发机制,优质供给与消费需求之间未能形成精准匹配。现有电商平台普遍采用基于销量或评分的简单排序规则,推荐结果多集中于热门商品,导致"长尾"绿色产品曝光不足。部分平台虽引入协同过滤算法,但往往忽视用户对绿色认证、产地等属性的偏好,缺乏针对农产品特殊属性的个性化推荐策略。
学术界围绕推荐系统的研究已较为成熟,协同过滤、基于内容的推荐以及混合推荐算法均有丰富成果。在农产品领域,现有研究多聚焦于单一维度的销量预测或用户评分建模,未能将绿色认证、消费偏好等农业特色属性有机融入推荐逻辑。同时,多数系统面向普通用户设计,缺乏面向管理者的运营数据分析与推荐参数调节接口,导致推荐策略难以根据市场变化动态调整。基于上述分析,本课题选取农产品推荐系统为研究对象,在现有推荐算法基础上,引入绿色消费偏好因子,构建融合用户行为数据与农产品认证特征的混合推荐模型。研究旨在解决以下问题:如何在新用户冷启动阶段保证推荐多样性;如何将绿色认证产品权重纳入推荐排序;如何为管理者提供可配置的推荐参数与可视化数据支持,从而提升推荐系统的实用性。
1.2 课题研究的目的和意义
本课题的研究具有理论与实践双重价值。从实践应用角度,系统面向消费者提供基于个人偏好与绿色消费导向的产品推荐,可降低用户信息筛选成本,提升购物体验。对于平台运营方而言,管理员后台提供产品销售统计、推荐参数调节、用户与订单管理等模块,使运营策略调整有据可依。特别是在绿色农产品推广方面,系统通过设置偏好开关与权重参数,引导消费流向绿色认证产品,契合国家"双碳"战略与乡村振兴政策导向,对促进农业供给侧结构性改革具有现实意义。
从理论层面来看,本课题将绿色认证属性、用户偏好类别等特征融入混合推荐算法,在传统基于内容和协同过滤的基础上,增加了冷启动阶段的多样性保障机制,形成了一套可复用的农产品垂直领域推荐方案。研究中涉及的推荐参数动态配置、用户行为日志分析与数据可视化呈现方式,可为同类电商推荐系统的设计提供参考。此外,系统采用前后端分离架构,前端基于Bootstrap 5实现响应式布局,后端以Flask框架构建RESTful API,该技术选型对于中小型电商系统的开发实践亦具有示范作用。
1.3 国内外研究现状
近年来,随着电子商务与大数据技术的深度融合,个性化推荐系统成为学术界与工业界的研究热点。国内外学者围绕推荐算法优化、系统架构设计及垂直领域应用等方面开展了大量探索。
国外研究起步较早,在推荐算法层面已形成较为成熟的理论体系。Hu Xiaoqin等(2022)针对网络个性化推荐系统CPU占用率偏高的问题,引入大数据技术提取用户行为潜在因子,通过统计不同流量组的留存率与点击率优化流量分配,有效降低了系统资源消耗。Hua Zhang(2024)在电商推荐系统研究中,提出基于综合权重的TextRank关键词提取算法,并结合优化后的协同过滤算法构建用户-商品矩阵推荐模型,实验表明改进后的算法在平均绝对误差指标上优于传统协同过滤方法。Nirmal G K等(2024)聚焦跨平台商品推荐场景,利用大数据分析技术实现分布式数据处理,支持用户根据平台限制筛选可观看资源。Lin Zhu与Li Zhuang(2025)设计基于B/S架构的商品推荐系统,采用Vue与SpringBoot框架分离前后端,集成爬虫技术与用户偏好分析,实现了个性化服务。Xiaoping Xu(2025)针对高校毕业生就业推荐中信息滞后与匹配精度低的问题,提出大数据辅助的智能就业推荐系统,通过对比学术能力与职业技能集,构建了从理论框架到软件应用的完整解决方案。
国内研究则更注重推荐系统在垂直领域的落地应用。在农产品电商领域,沈楚姗与吴军辉(2025)基于Spark平台设计分布式推荐系统,结合卷积神经网络与交替最小二乘法构建混合推荐算法,在大规模数据集下将均方根误差指标降低10.3%。程德珑(2025)基于个性化推荐设计农产品电子商务系统,从需求分析、架构设计到核心功能实现进行了完整阐述。周旭东(2025)运用协同过滤推荐算法,采用Java与SQL数据库开发农产品电商平台,有效提升用户购物效率。白雪等(2024)针对农产品推荐中特征交互重要性被忽略的问题,提出细粒度特征交互选择网络,通过捕捉季节、地域、用户兴趣等多维特征改进点击率预测模型。
在其他应用领域,张菁等(2024)以大连大樱桃销售数据为对象,采用数据埋点与爬虫技术构建销售预测系统,利用梯度下降算法实现销量预测可视化。唐逢胤(2024)基于Scrapy框架设计农产品信息汇聚系统,运用语义分析技术将信息分类汇聚。张艳(2024)提出了涵盖应用层、算法层、缓存层与存储层的大数据电商推荐系统框架。梁霄(2024)探究大数据技术在农作物种植推荐系统中的应用,通过分析农业数据为生产者提供种植建议。左佳(2024)从营销策略角度探讨大数据在农产品电商用户画像构建与个性化推荐中的应用。
国内外研究在推荐算法优化与系统实现方面积累了丰富成果,但在农产品垂直领域中,现有研究多聚焦于单一算法改进或系统功能实现,对绿色认证属性与用户偏好深度融合的推荐策略关注不足,且多数系统未提供面向管理者的参数调节与数据分析接口,这为本课题的研究提供了切入点。
1.4 主要研究内容
本研究围绕农产品推荐场景,设计并实现一个融合个性化推荐与绿色消费引导的农产品推荐系统。主要研究内容包括以下几个方面:
在系统架构层面,采用B/S架构与前后端分离模式,前端基于Bootstrap 5框架构建响应式用户界面,后端使用Python Flask框架开发RESTful API服务,数据库选用SQLite存储产品、用户、订单及行为日志等数据,前后端通过HTTP协议交换JSON格式数据。
在推荐算法层面,以基于物品的协同过滤(ItemCF)为核心推荐算法,冷启动阶段综合热门度、高评分与绿色认证产品进行填充,用户产生行为后结合基于内容的推荐进行补充,依据用户偏好类别与相似用户行为动态生成推荐列表。管理员可通过后台调节推荐权重参数,实时影响推荐结果构成。
在功能实现层面,系统完成产品浏览与搜索、购物车与订单管理、收藏与评分、个人偏好设置、管理后台仪表盘等核心模块的开发。购物车基于前端存储技术实现,订单生成采用数据库事务保障数据一致性;管理后台支持产品增删改查、图片上传、用户管理、订单状态更新及推荐参数配置。
在系统测试层面,通过功能测试验证各模块操作的正确性,通过响应时间测试与并发测试评估系统性能。测试结果表明系统核心操作响应时间低于500毫秒,50并发场景下运行稳定,功能完整、性能可靠。
2 系统需求分析
2.1 可行性分析
2.1.1 经济可行性分析
系统开发阶段主要投入为开发人员的人力成本,硬件方面仅需普通个人计算机作为开发环境,无需购置专用服务器或商业软件。系统后端采用Python Flask框架,数据库选用轻量级SQLite,前端使用Bootstrap开源组件库,所有技术栈均基于开源生态,无需支付软件授权费用。系统上线后,运行成本主要体现为服务器租赁与维护费用,按现有中小型云服务器配置估算,年运营成本约2000元。从收益角度看,系统通过精准推荐可提升用户购买转化率与客单价,同时管理员后台提供销售数据分析,有助于优化选品与营销策略,间接增加平台收益。预计系统上线后一年内可收回开发与运营投入成本。综上所述,系统从经济上是可行的。
2.1.2 技术可行性分析
系统采用B/S架构,前后端分离。前端基于HTML5、CSS3与Bootstrap 5框架,实现响应式页面布局,确保在PC端与移动端均能正常访问;交互逻辑使用原生JavaScript编写,数据可视化部分采用ECharts 5.4图表库。后端选用Python Flask微框架,提供RESTful API接口,通过Flask-CORS处理跨域请求,Session机制实现用户状态管理。数据库使用SQLite,通过Python内置sqlite3模块操作,表结构涵盖产品、用户、订单、行为日志、收藏、评分等。推荐算法采用混合策略,协同过滤基于用户行为日志计算相似度,内容推荐利用用户偏好类别与产品属性进行匹配,冷启动阶段结合热门度与绿色认证产品填充。上述技术均已成熟,不存在无法克服的技术障碍。综上所述,系统从技术上是可行的。
2.1.3 操作可行性分析
系统面向两类用户:普通消费者与管理员。普通用户通过浏览器访问,界面设计遵循主流电商交互习惯,产品浏览、搜索、加购、下单等操作均有明确指引,无需额外培训。管理员后台采用左侧导航栏布局,功能模块划分清晰,产品、用户、订单管理均提供表格展示与表单操作,推荐参数通过滑块调节,操作直观。系统所有操作均经过前端校验与后端验证,并提供Toast提示反馈,保证操作易用性与容错性。综上所述,系统从操作上是可行的。
2.2 需求分析
2.2.1 关键技术
系统开发采用前后端分离架构,前端负责页面渲染与用户交互,后端提供数据接口,双方通过HTTP协议通信。
(1)前端技术:页面结构使用HTML5,样式采用Bootstrap 5框架实现响应式布局,图标使用Bootstrap Icons。交互逻辑由原生JavaScript完成,未引入第三方大型框架以降低复杂度。数据可视化使用ECharts 5.4库,用于管理员后台与数据分析页面的图表展示。页面间数据共享利用localStorage存储购物车信息。
(2)后端技术:基于Python 3.7+的Flask微框架,通过路由装饰器定义API端点。使用Flask-CORS解决跨域资源共享问题,设置supports_credentials=True允许跨域携带Session Cookie。Session管理通过Flask内置的session对象实现,密钥存储在app.secret_key中。密码采用SHA256哈希加密存储。
(3)数据库技术:选用SQLite作为数据库,通过Python标准库sqlite3连接与操作。表结构设计涵盖用户表、产品表、订单表、收藏表、评分表、行为日志表及推荐参数表,表间通过外键关联。
(4)推荐算法:系统实现混合推荐策略。基于内容的推荐依据用户偏好类别与产品属性匹配;协同过滤通过分析用户行为日志,查找相似用户并推荐其购买过的产品;冷启动阶段综合热门度、高评分与绿色认证产品生成推荐列表。推荐权重可通过管理员后台动态配置。
2.2.2 业务流程分析
系统核心业务流程围绕用户购物与管理员运营展开,具体如下。
- 用户浏览与搜索流程:用户登录后进入首页,可查看"为您推荐""绿色认证优选""热门销量榜"等板块。点击"全部产品"进入产品列表页,支持按类别筛选、按绿色产品过滤、按关键词搜索。用户点击任一产品卡片,跳转至详情页,查看完整信息、评分及用户评价。具体流程图如图2.1所示。
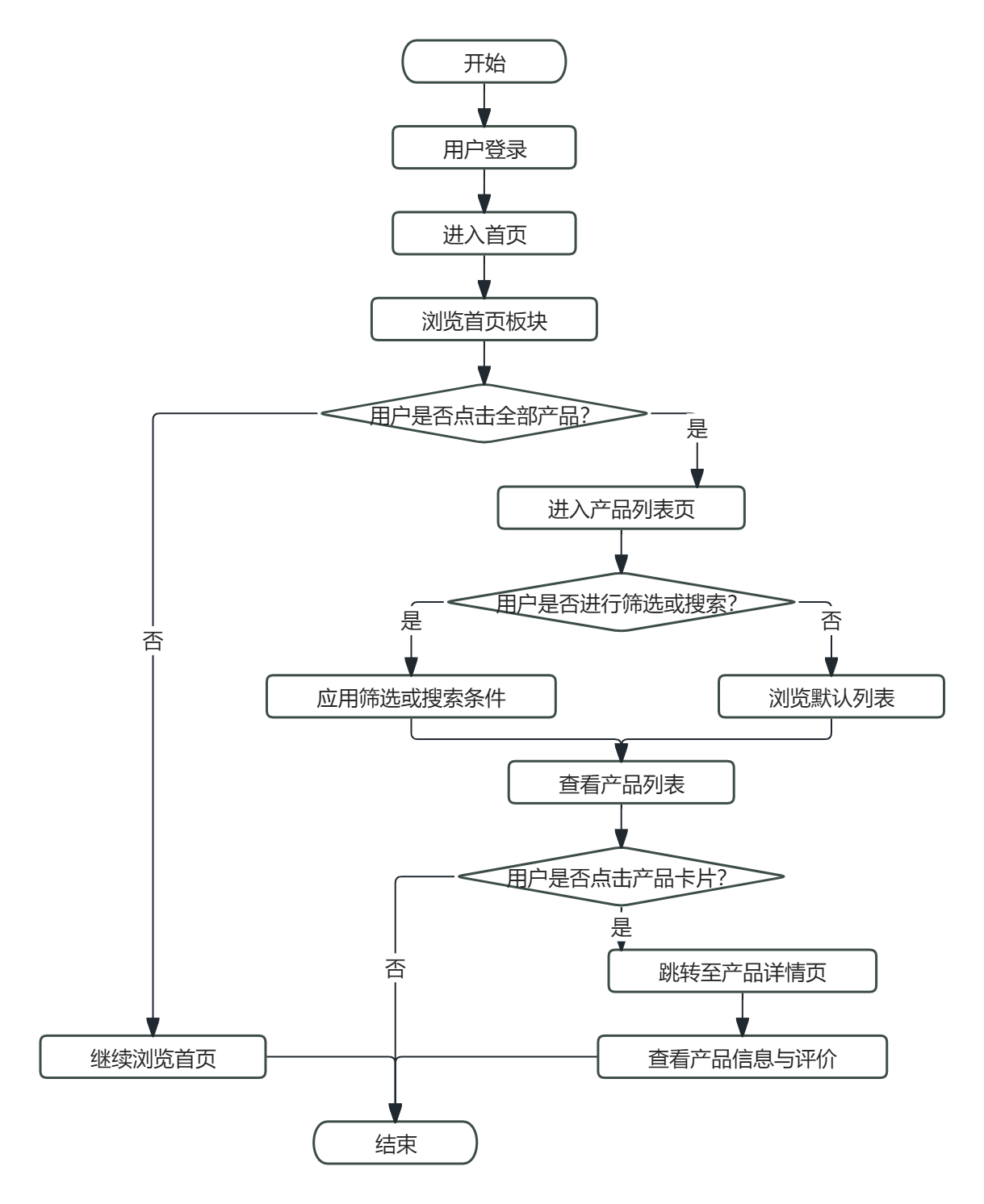
图2.1 用户浏览与搜索流程
- 购物车与下单流程:用户在详情页或产品卡片上点击"加入购物车",系统将商品信息存入本地存储。进入购物车页面后,可修改商品数量、移除商品,系统自动计算商品小计、运费(满100元免运费)与总计。点击"立即结算",系统调用后端订单接口创建订单,生成唯一订单号,并将订单信息保存至数据库,同时清空购物车。用户可在个人中心查看订单列表与状态。具体流程图如图2.2所示。
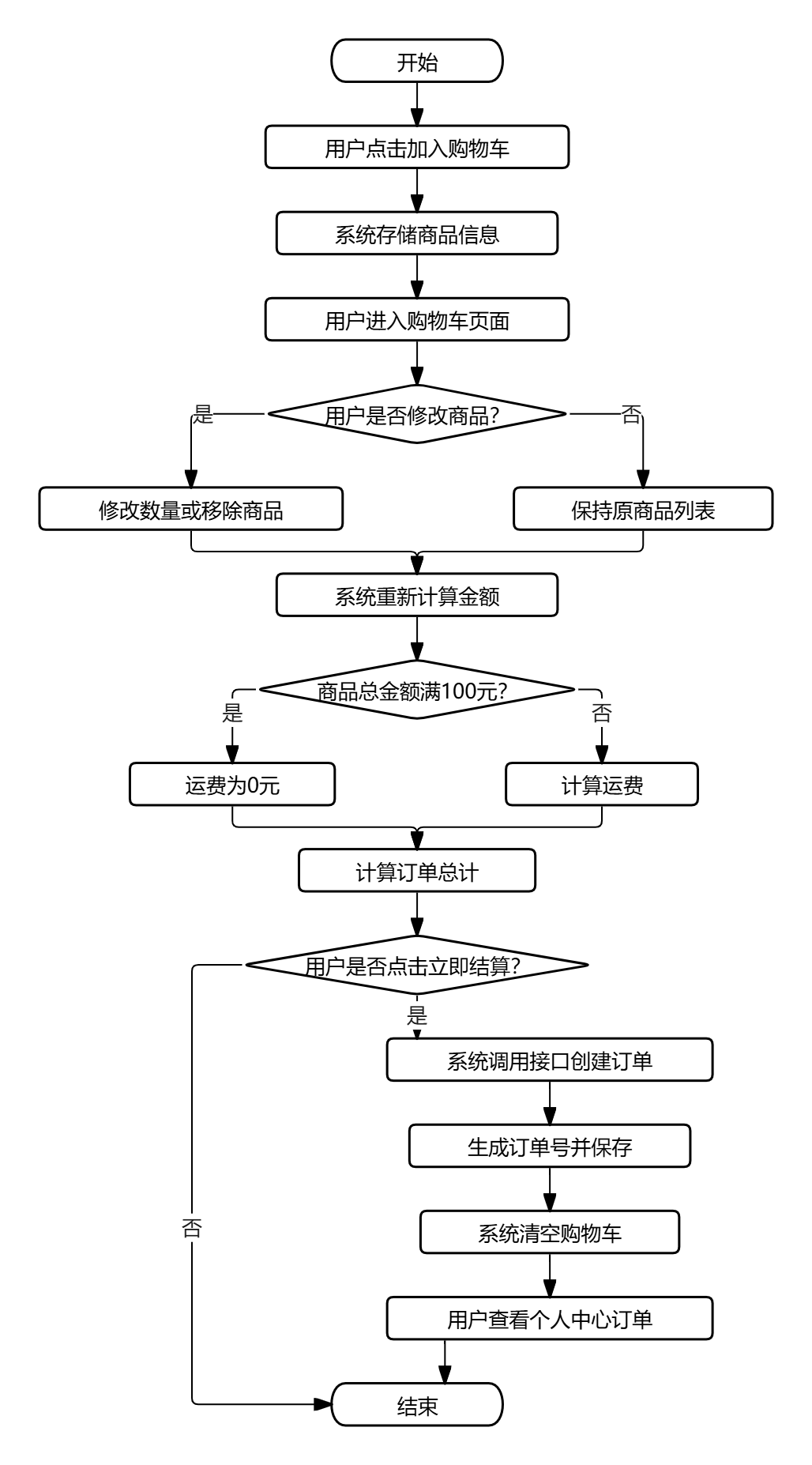
图2.2 购物车与下单流程
- 收藏与评分流程:用户在详情页点击"收藏"按钮,系统通过后端API添加收藏记录,并更新按钮状态为已收藏。用户可对产品进行1-5星评分,并填写评论,提交后后端存储评分数据,并在详情页展示所有用户评价。具体流程图如图2.3所示。
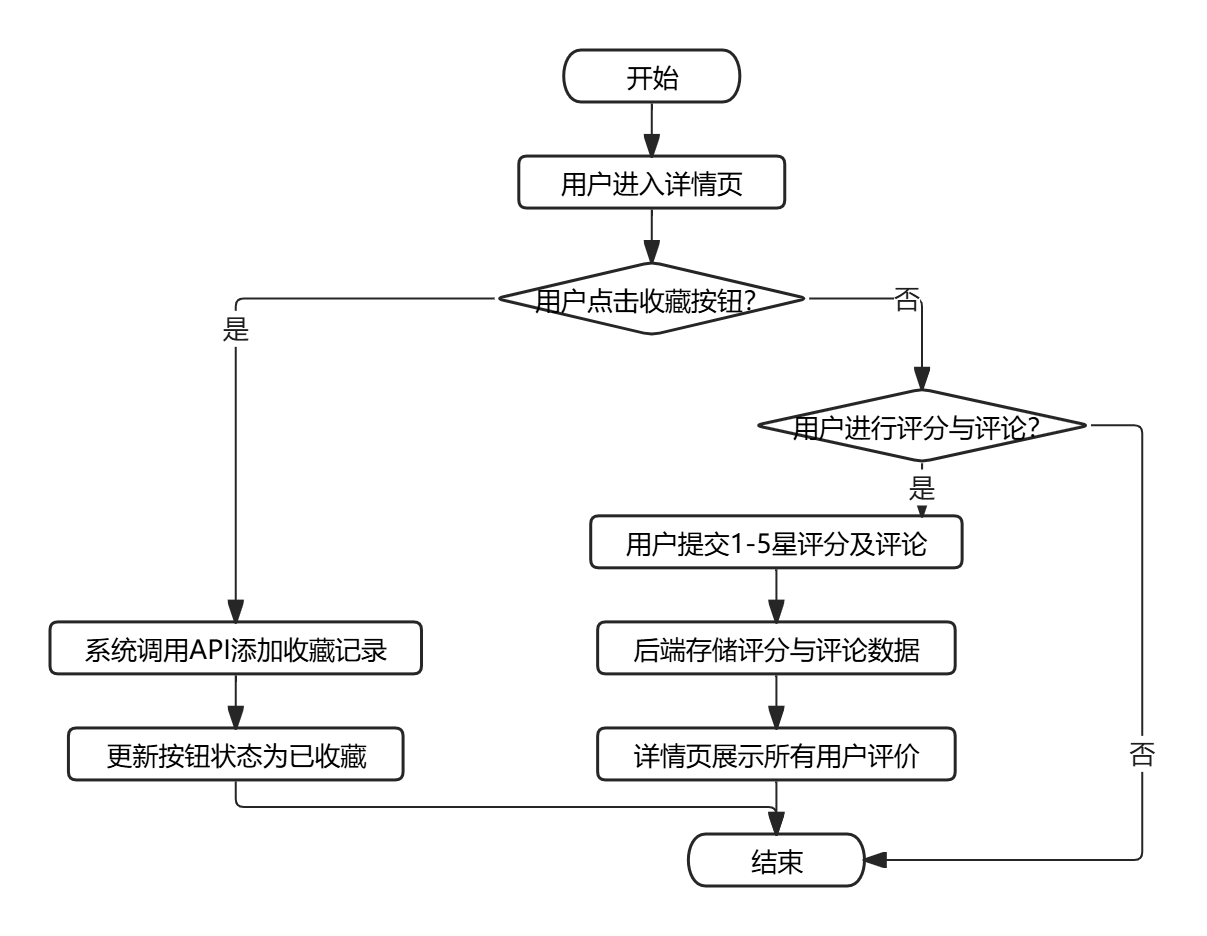
图2.3 收藏与评分流程
- 管理员运营流程:管理员登录后进入后台,仪表盘展示总产品数、绿色产品数、用户总数、总销量等统计数据。产品管理模块支持添加、编辑、删除产品,添加时支持图片上传。用户管理模块支持查询、添加、编辑、删除用户,管理员账户不可删除。订单管理模块支持按订单号、用户名搜索,按状态筛选,并可查看订单详情、修改订单状态。推荐参数设置模块可调节绿色产品权重、评分权重、销量权重及个性化推荐比例,保存后立即生效。具体流程图如图2.4所示。
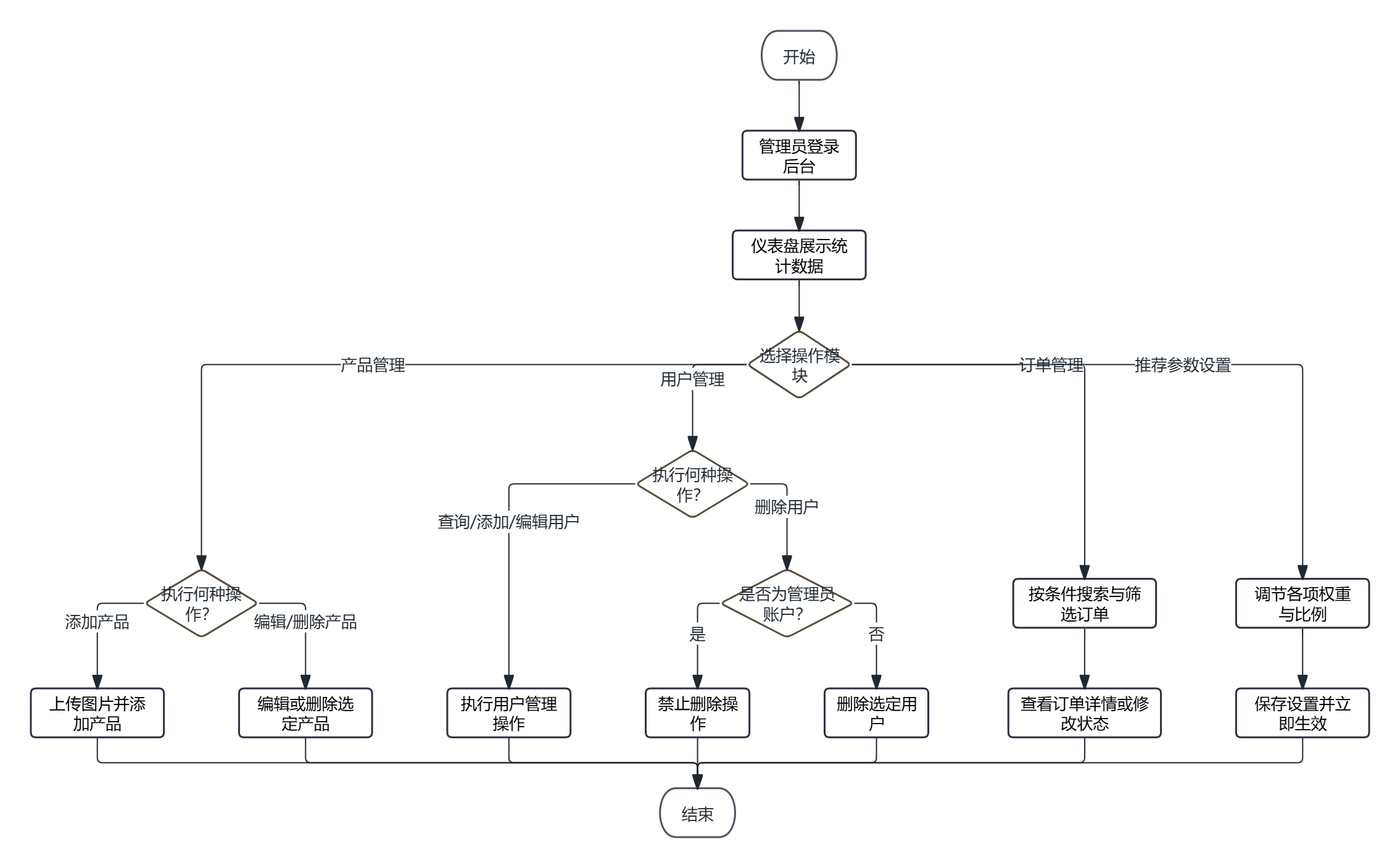
图2.4 管理员运营流程
2.2.3 功能需求分析
根据用户角色划分,系统功能分为普通用户功能与管理功能。
普通用户功能包括:产品浏览、产品搜索、类别筛选、绿色产品筛选、产品详情查看、产品收藏与取消收藏、产品评分与评论、加入购物车、购物车管理、订单创建与查看、个人信息修改、绿色消费偏好设置。
管理员功能包括:仪表盘数据统计、产品列表查询、产品增删改查、产品图片上传、用户列表查询、用户增删改查、订单列表查询、订单状态更新、推荐参数配置。
用例图如图2.5所示。
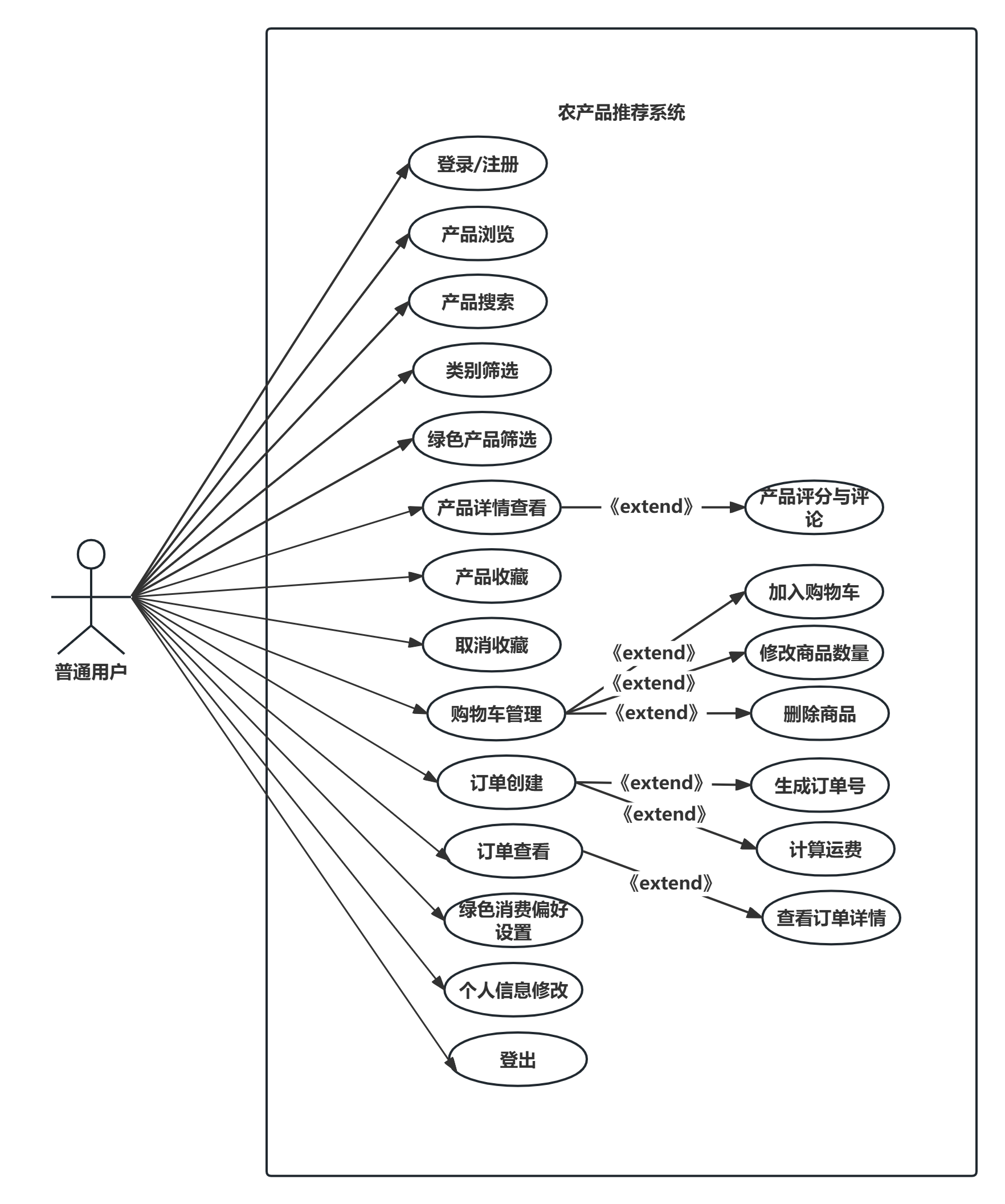
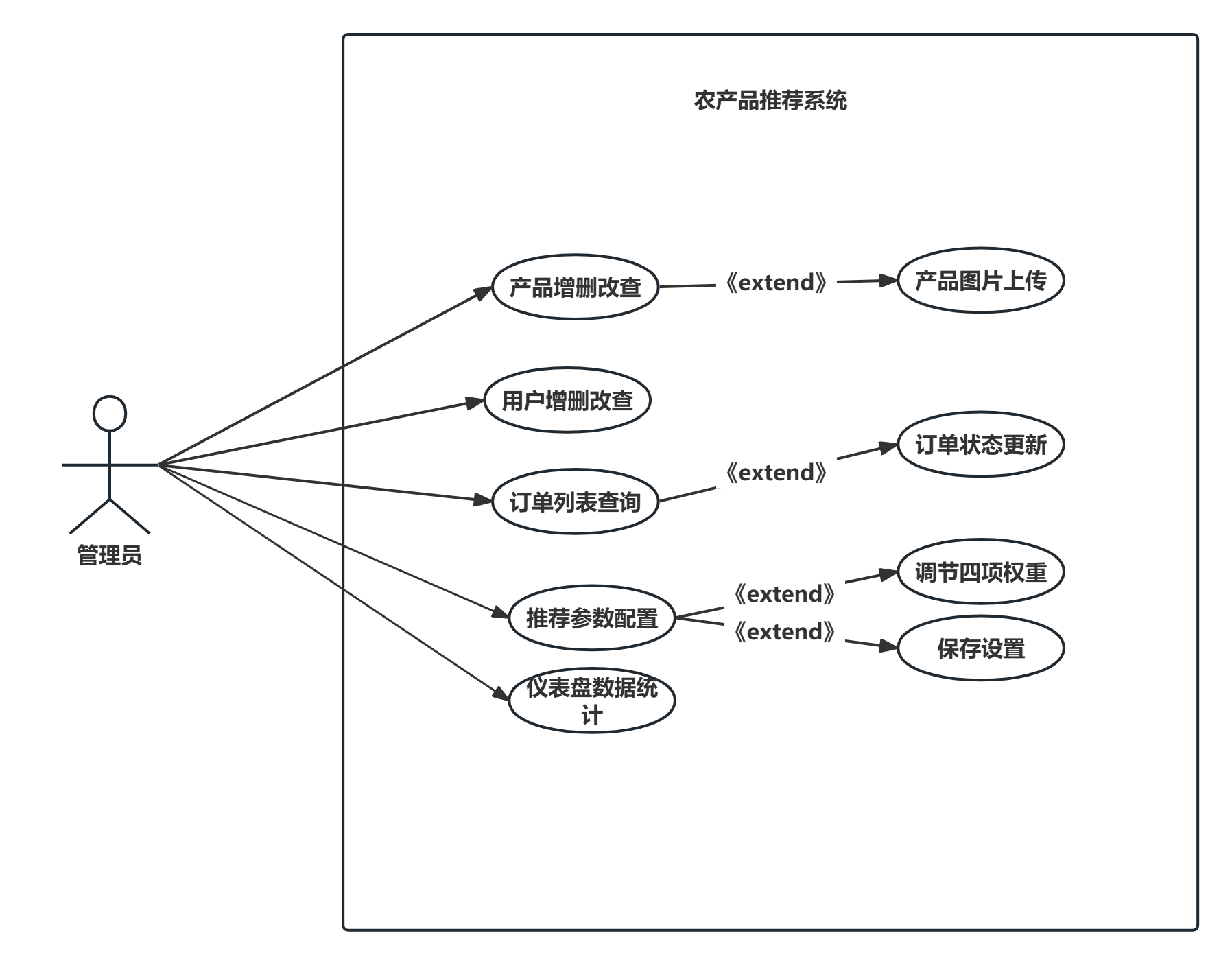
图2.5 用例图
2.3 非功能性需求分析
(1)响应时间:首页加载及推荐内容请求应在3秒内完成,产品列表分页加载应在2秒内完成,后台数据统计图表渲染应在5秒内完成。
(2)并发能力:系统采用轻量级架构,预估支持50人同时在线访问,数据库读写操作可满足日常使用需求。
(3)数据安全性:用户密码采用SHA256哈希存储,防止明文泄露。Session通过HTTP Only Cookie传递,降低XSS攻击风险。管理员后台操作需校验is_admin标志,非管理员无法访问敏感接口。
(4)可靠性:数据库采用SQLite事务机制,保证订单创建、评分提交等关键操作的原子性。图片上传前进行文件类型与大小校验,防止恶意文件上传。
(5)可维护性:代码遵循PEP 8规范,API接口设计遵循RESTful风格,前端样式与脚本分离,便于后续功能扩展与维护。
3 系统设计
3.1 系统总体架构
3.1.1 架构设计
系统采用B/S架构,遵循前后端分离的设计思想。前端负责用户界面展示与交互逻辑,后端提供业务逻辑处理与数据接口,双方通过HTTP协议交换JSON格式数据。整体架构自上而下分为三层:
(1)前端展示层:运行于浏览器端,基于HTML5、CSS3构建页面结构,Bootstrap 5框架实现响应式布局,原生JavaScript处理用户操作、发送Ajax请求及动态渲染页面,ECharts库完成数据可视化。购物车数据通过localStorage进行本地存储,减少后端交互压力。
(2)后端应用层:使用Python Flask框架搭建RESTful API服务,通过路由映射处理不同业务请求。Flask-CORS扩展管理跨域资源共享,Session机制维护用户登录状态。应用层包含用户认证、产品管理、推荐算法、订单处理、收藏评分等核心模块,各模块独立封装,通过函数调用或数据库操作完成业务逻辑。
(3)数据层:采用SQLite关系型数据库,通过sqlite3模块与后端应用层交互。数据层包含用户、产品、订单、收藏、评分、行为日志、推荐参数等数据表,表间通过外键建立关联。数据操作遵循事务机制,保证关键业务的一致性。
系统架构图如图3.1所示。前端发起请求后,后端应用层解析请求参数,调用相应模块处理,若涉及数据读写则访问数据层,处理结果封装为JSON返回前端,前端根据响应更新页面。
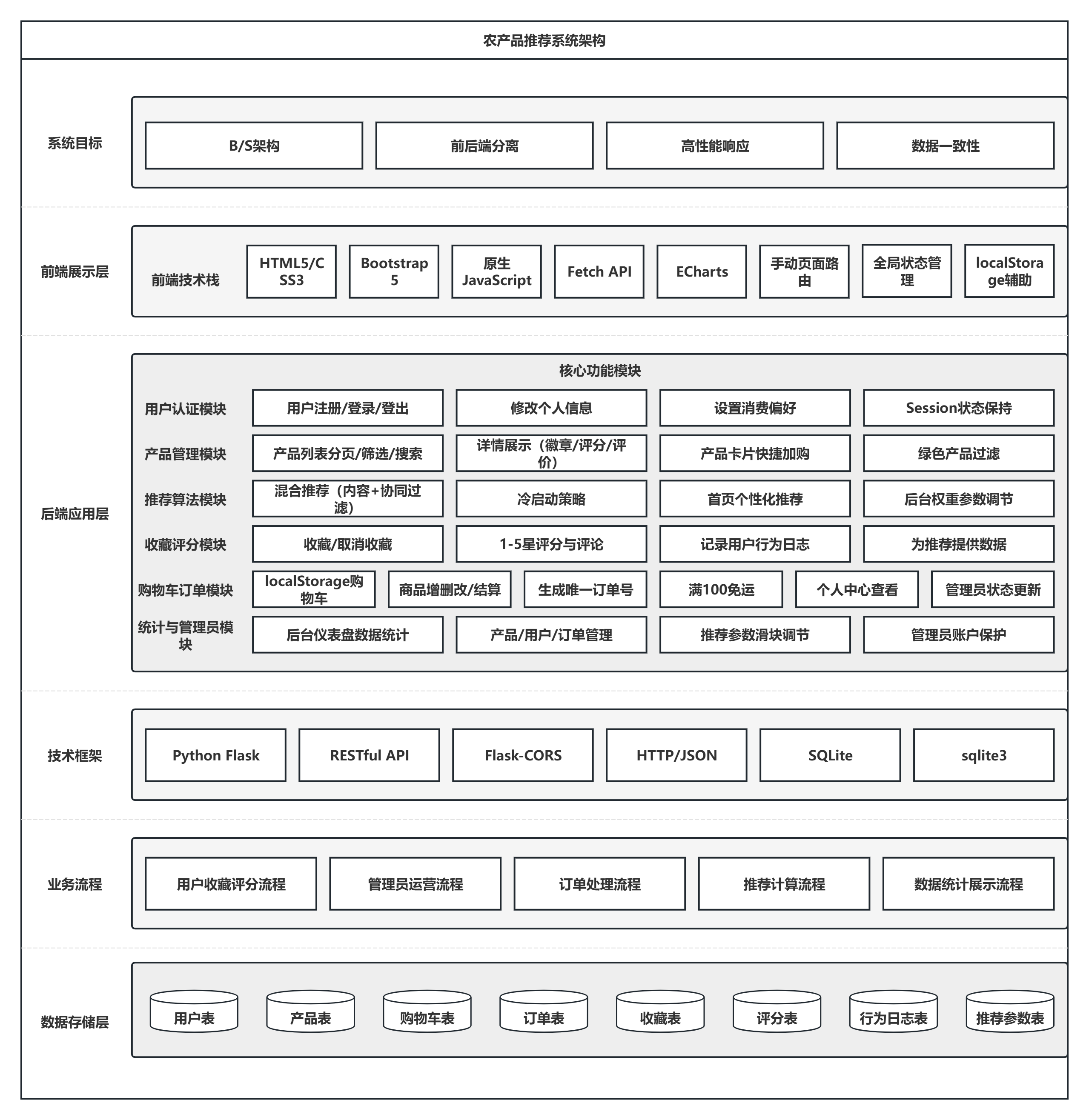
图3.1 系统架构图
3.1.2 功能模块设计
本系统旨在为用户提供个性化的农产品推荐服务,同时为管理员提供运营管理工具。系统核心功能围绕用户购物流程与后台管理展开,具体分为以下模块:
(1)用户管理模块:提供用户注册、登录、登出功能;支持用户修改个人信息、设置绿色消费偏好及偏好类别;用户登录状态通过Session保持。
(2)产品浏览模块:实现产品列表分页展示,支持按类别筛选、关键词搜索及绿色产品过滤;产品详情页展示完整信息、认证徽章、用户评分及评价;产品卡片集成快捷加购按钮。
(3)推荐系统模块:采用混合推荐算法,综合基于内容的推荐、协同过滤与冷启动策略。用户登录后,首页展示个性化推荐结果;管理员可通过后台调节推荐权重参数,动态影响推荐结果。
(4)收藏与评分模块:用户可对产品进行收藏与取消收藏;可对已购买或浏览过的产品进行1-5星评分并撰写评论;系统记录用户行为日志,为推荐算法提供数据支撑。
(5)购物车与订单模块:购物车基于localStorage实现,支持商品数量修改、删除及结算;订单创建时生成唯一订单号,计算运费(满100元免运费),订单信息存储至数据库;用户可在个人中心查看订单列表及详情,管理员可查看所有订单并更新状态。
(6)管理后台模块:管理员登录后访问后台仪表盘,查看总产品数、绿色产品数、用户总数、总销量等统计数据;产品管理支持增删改查及图片上传;用户管理支持增删改查,管理员账户不可删除;订单管理支持搜索、筛选、状态更新;推荐参数设置支持滑块调节四项权重并保存。
系统功能模块图如图3.2所示:
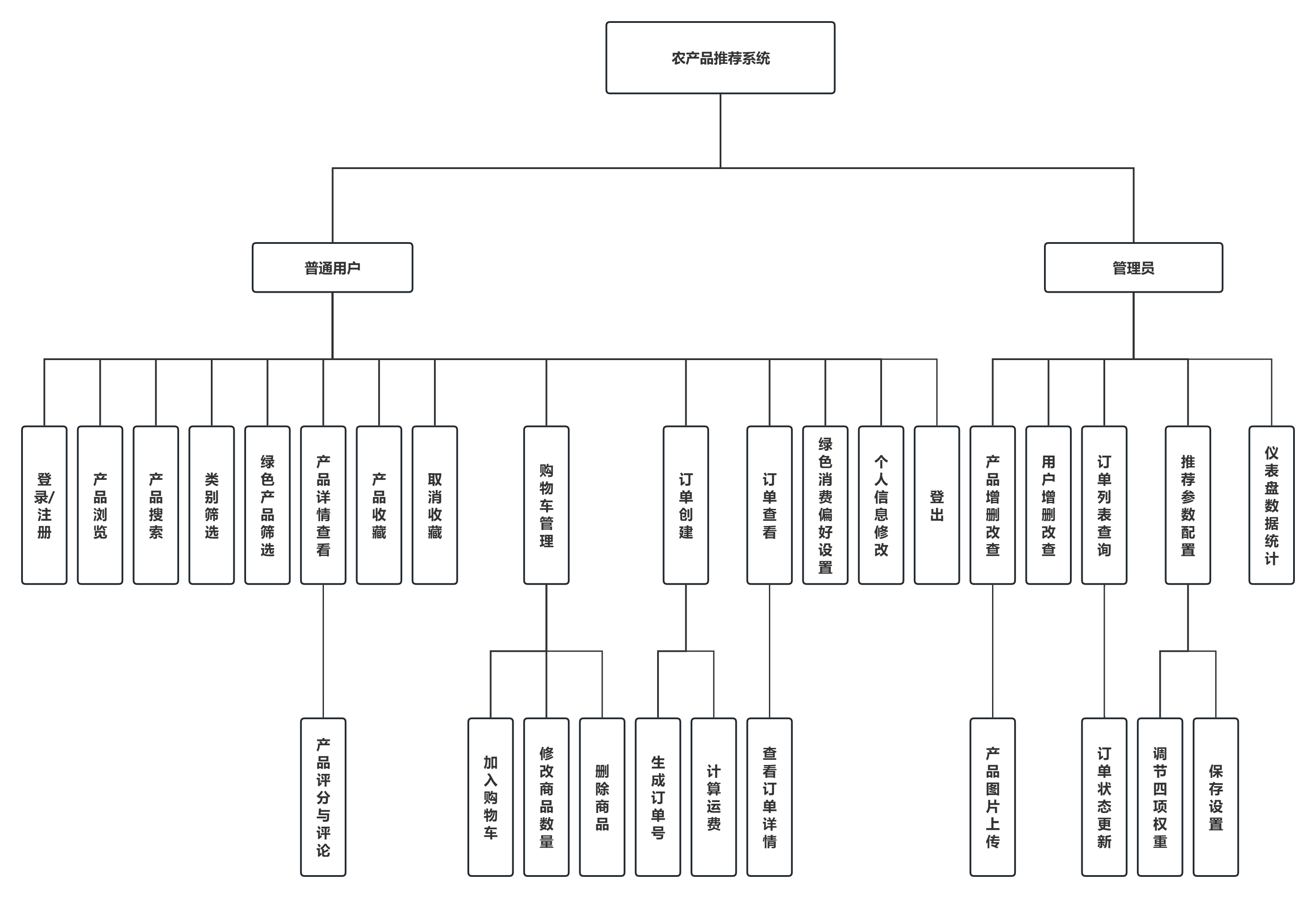
图3.2 系统功能图
3.2 数据库设计
3.2.1 数据库逻辑设计
本系统选用SQLite关系型数据库,采用外键约束维护数据完整性。系统共涉及八张核心数据表:用户表(ga_users)、产品表(ga_products)、订单表(ga_orders)、收藏表(ga_favorites)、评分表(ga_ratings)、行为日志表(ga_behavior_logs)、推荐参数表(ga_recommendation_params)、管理员表。各表之间的实体关系如下:
(1)用户与产品之间通过收藏、评分、行为日志建立多对多关系。收藏表ga_favorites包含用户ID与产品ID,记录用户收藏的产品;评分表ga_ratings包含用户ID与产品ID,记录用户对产品的评分与评论;行为日志表ga_behavior_logs包含用户ID与产品ID,记录用户浏览、点击、购买等行为。
(2)用户与订单之间为一对多关系。订单表ga_orders中的user_id外键关联用户表,一个用户可创建多个订单。
(3)产品与订单之间通过订单项关联,订单表ga_orders中的items字段以JSON格式存储订单包含的产品列表,包含产品ID、名称、价格、数量等信息,为简化表结构未单独建立订单项表。
(4)推荐参数表ga_recommendation_params仅包含单条记录,用于存储系统全局推荐权重,与用户、产品无直接关联。
系统E-R图如图3.3所示,图中实线表示外键关联。
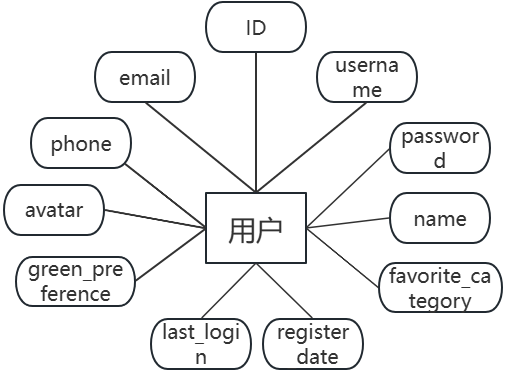
图3.3 用户实体图
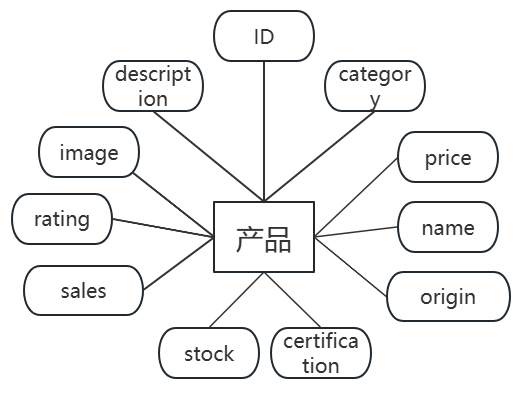
图3.4 产品实体图
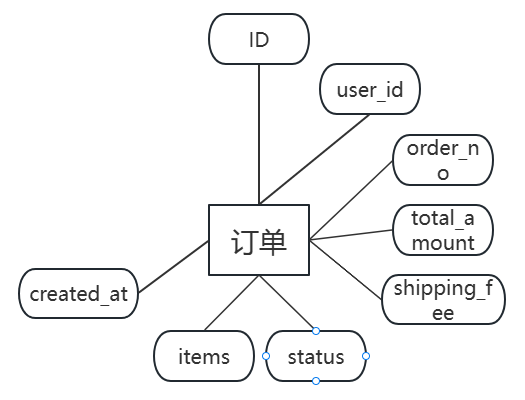
图3.4 订单实体图
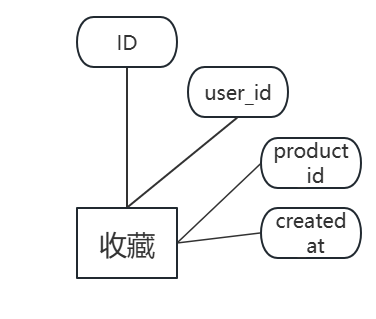
图3.5 收藏实体图
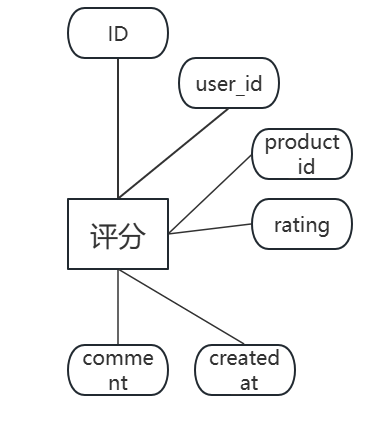
图3.6 评分实体图
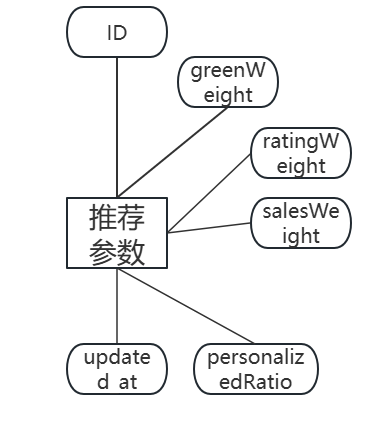
图3.7 推荐参数实体图
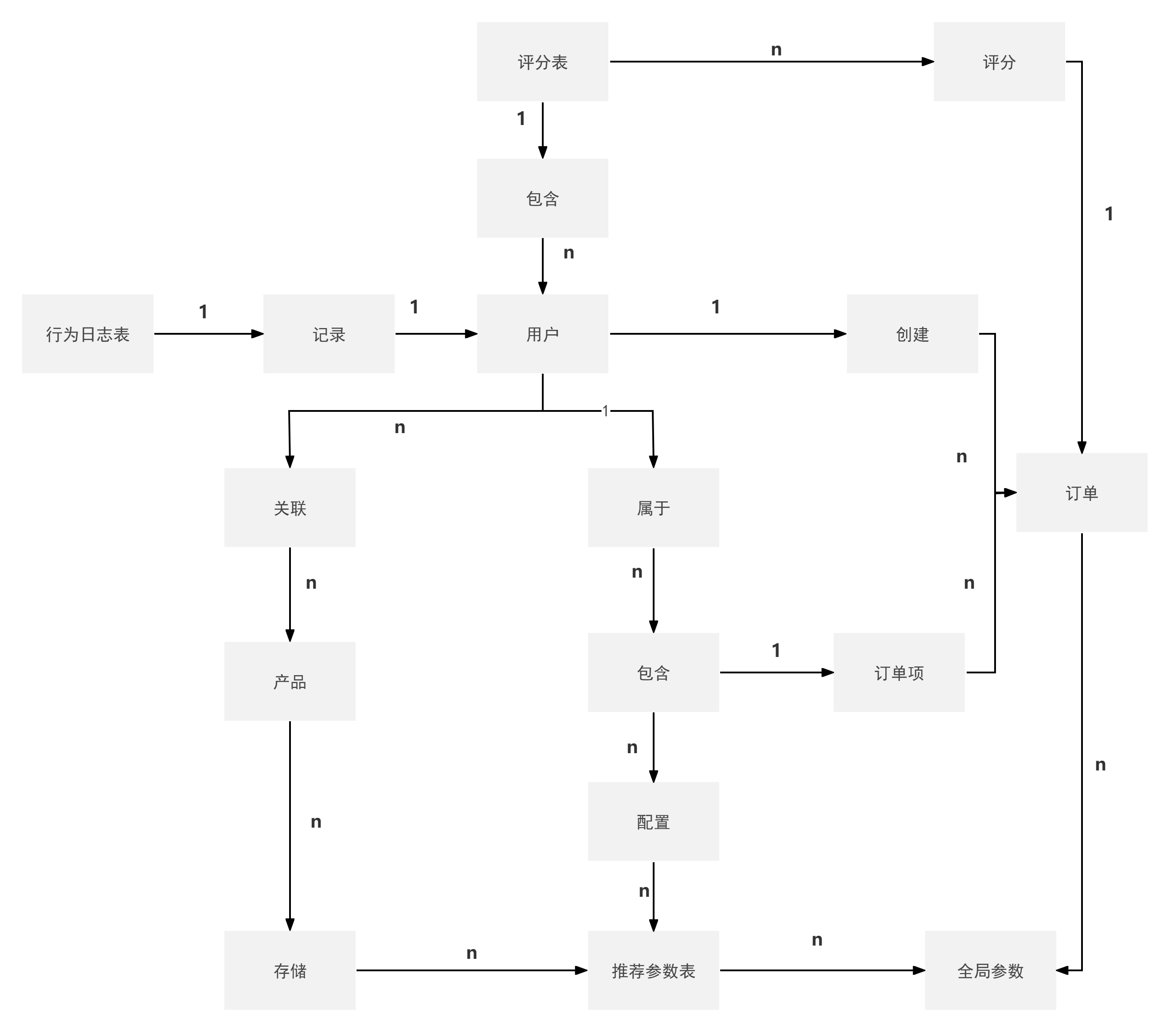
图3.8 系统E-R图
3.2.2 数据库表设计
本系统数据库表设计如下:
(1)用户表ga_users存储注册用户的基本信息。字段包括:id(主键,自增)、username(用户名,唯一)、password(密码SHA256哈希)、name(姓名)、email(邮箱,唯一)、phone(手机号)、avatar(头像路径)、green_preference(绿色偏好,0为否,1为是)、favorite_category(偏好类别)、register_date(注册时间)、last_login(最后登录时间)。ga_users数据表结构如表3.1所示。
表3.1 ga_users表结构
|-------------------|---------|---------------------------|--------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 用户ID |
| username | TEXT | NOT NULL UNIQUE | 用户名 |
| password | TEXT | NOT NULL | 密码哈希 |
| name | TEXT | NOT NULL | 姓名 |
| email | TEXT | NOT NULL UNIQUE | 邮箱 |
| phone | TEXT | | 手机号 |
| avatar | TEXT | | 头像路径 |
| green_preference | INTEGER | DEFAULT 0 | 绿色偏好 |
| favorite_category | TEXT | | 偏好类别 |
| register_date | TEXT | | 注册时间 |
| last_login | TEXT | | 最后登录时间 |
(2)产品表ga_products存储农产品详细信息。字段包括:id(主键,自增)、name(产品名称)、category(类别)、price(价格)、origin(产地)、certification(认证类型)、stock(库存)、sales(销量)、rating(评分)、image(图片路径)、description(描述)、created_at(创建时间)、updated_at(更新时间)。ga_products数据表结构如表3.2所示。
表3.2 ga_products表结构
|---------------|---------|---------------------------|------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 产品ID |
| name | TEXT | NOT NULL | 产品名称 |
| category | TEXT | NOT NULL | 类别 |
| price | REAL | NOT NULL | 价格 |
| origin | TEXT | NOT NULL | 产地 |
| certification | TEXT | NOT NULL | 认证类型 |
| stock | INTEGER | NOT NULL | 库存量 |
| sales | INTEGER | NOT NULL | 销量 |
| rating | REAL | NOT NULL | 评分 |
| image | TEXT | | 图片路径 |
| description | TEXT | | 产品描述 |
| created_at | TEXT | | 创建时间 |
| updated_at | TEXT | | 更新时间 |
(3)订单表ga_orders存储用户订单信息。字段包括:id(主键,自增)、user_id(外键,关联ga_users.id)、order_no(订单号,唯一)、total_amount(总金额)、shipping_fee(运费)、status(订单状态,pending/confirmed/shipped/delivered/cancelled)、items(订单商品JSON)、created_at(创建时间)。user_id设置外键约束。ga_orders数据表结构如表3.3所示。
|--------------|---------|---------------------------|--------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 订单ID |
| user_id | INTEGER | NOT NULL FOREIGN KEY | 用户ID |
| order_no | TEXT | NOT NULL UNIQUE | 订单号 |
| total_amount | REAL | NOT NULL | 总金额 |
| shipping_fee | REAL | DEFAULT 0 | 运费 |
| status | TEXT | DEFAULT 'pending' | 订单状态 |
| items | TEXT | NOT NULL | 商品JSON |
| created_at | TEXT | | 创建时间 |
(4)收藏表ga_favorites记录用户收藏的产品。字段包括:id(主键,自增)、user_id(外键,关联ga_users.id)、product_id(外键,关联ga_products.id)、created_at(收藏时间)。user_id与product_id设置联合唯一约束。ga_favorites数据表结构如表3.4所示。
表3.4 ga_favorites表结构
|------------|---------|---------------------------|------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 收藏ID |
| user_id | INTEGER | NOT NULL FOREIGN KEY | 用户ID |
| product_id | INTEGER | NOT NULL FOREIGN KEY | 产品ID |
| created_at | TEXT | | 收藏时间 |
(5)评分表ga_ratings记录用户对产品的评分与评论。字段包括:id(主键,自增)、user_id(外键,关联ga_users.id)、product_id(外键,关联ga_products.id)、rating(评分,1-5)、comment(评论)、created_at(评分时间)。user_id与product_id设置联合唯一约束。ga_ratings数据表结构如表3.5所示。
表3.5 ga_ratings表结构
|------------|---------|---------------------------|------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 评分ID |
| user_id | INTEGER | NOT NULL FOREIGN KEY | 用户ID |
| product_id | INTEGER | NOT NULL FOREIGN KEY | 产品ID |
| rating | INTEGER | NOT NULL CHECK | 评分值 |
| comment | TEXT | | 评论内容 |
| created_at | TEXT | | 评分时间 |
(6)行为日志表ga_behavior_logs记录用户浏览、点击、购买等行为,为推荐算法提供数据。字段包括:id(主键,自增)、user_id(外键,关联ga_users.id)、product_id(外键,关联ga_products.id)、behavior(行为类型,如点击、购买)、timestamp(行为时间)、rating(评分行为时的评分值)、quantity(购买数量)、amount(购买金额)、search_keyword(搜索关键词)。ga_behavior_logs数据表结构如表3.6所示。
表3.6 ga_behavior_logs表结构
|----------------|---------|---------------------------|-------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 日志ID |
| user_id | INTEGER | NOT NULL FOREIGN KEY | 用户ID |
| product_id | INTEGER | NOT NULL FOREIGN KEY | 产品ID |
| behavior | TEXT | NOT NULL | 行为类型 |
| timestamp | TEXT | NOT NULL | 行为时间 |
| rating | INTEGER | | 评分值 |
| quantity | INTEGER | | 购买数量 |
| amount | REAL | | 购买金额 |
| search_keyword | TEXT | | 搜索关键词 |
(7)推荐参数表ga_recommendation_params存储系统推荐权重配置。字段包括:id(主键,自增)、greenWeight(绿色产品权重)、ratingWeight(评分权重)、salesWeight(销量权重)、personalizedRatio(个性化推荐比例)、updated_at(更新时间)。表中仅保留一条记录。ga_recommendation_params数据表结构如表3.7所示。
表3.7 ga_recommendation_params表结构
|-------------------|---------|---------------------------|---------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 参数ID |
| greenWeight | REAL | DEFAULT 0.5 | 绿色产品权重 |
| ratingWeight | REAL | DEFAULT 0.3 | 评分权重 |
| salesWeight | REAL | DEFAULT 0.2 | 销量权重 |
| personalizedRatio | REAL | DEFAULT 0.3 | 个性化推荐比例 |
| updated_at | TEXT | | 更新时间 |
(8)管理员表admin存储管理员的基本信息。字段包括:id(主键,自增)、username(用户名,唯一)、password(密码SHA256哈希)、name(姓名)、email(邮箱,唯一)、phone(手机号)、avatar(头像路径)、register_date(注册时间)、last_login(最后登录时间)。管理员数据表结构如表3.8所示。
表3.8管理员表结构
|---------------|---------|---------------------------|------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY AUTOINCREMENT | 用户ID |
| username | TEXT | NOT NULL UNIQUE | 用户名 |
| password | TEXT | NOT NULL | 密码哈希 |
| name | TEXT | NOT NULL | 姓名 |
| email | TEXT | NOT NULL UNIQUE | 邮箱 |
| phone | TEXT | | 手机号 |
| avatar | TEXT | | 头像路径 |
| Is_admin | TEXT | | 是否管理员(是/否) |
| register_date | TEXT | | 注册时间 |
| last_login | TEXT | | 最后登录时间 |
3.3 推荐算法设计与实现
3.3.1 问题提出
目前主流的推荐算法都存在着各自的问题,主要问题如下:
(1)冷启动问题:冷启动问题又可以分为用户冷启动问题、物品冷启动问题以及系统冷启动问题。当新用户加入系统时,用户由于没有进行过任何操作,所以无法通过数据分析计算得到新用户的偏好信息,不能够向他推荐其所感兴趣的内容,这就是用户冷启动问题。而物品冷启动问题则是指新的物品加入,由于用户还没有对其进行评分等操作,所以无法进行推荐操作。
(2)稀疏性问题:在推荐系统的实际应用场景中,因为用户多以及物品丰富的问题,所以用户不可能对所有的物品都有过操作行为,同样的物品也不可能被所有用户被评价过,因此与用户产生关联的物品只占所有物品集合中的很小的一部分。因此用户和物品构成的评分矩阵会是一个稀疏矩阵。而数据的稀疏性又会严重影响到推荐系统的性能,因为协同过滤算法原理上都是依赖于用户物品评分矩阵。目前主流的推荐算法是通过降低数据维度来解决此类问题。
(3)实时性问题:同样的由于用户、物品的数量都十分的庞大,项目中的相似度计算以及后面的评分预测,都依靠这用户的历史行为来计算,所以我们只能定期的更新数据,从而来产生新的推荐列表。导致推荐系统不能够根据用户实时的行为来为其进行推荐,严重影响了用户的体验。
3.3.2 混合算法的设计
(1)基于用户协同过滤设计思路:用户协同过滤方法的核心思想是:通过计算用户之间的相似度,基于相似的用户推荐商品给目标用户。初始化用户评分数据:从数据库中获取所有用户的评分数据,并将这些数据整理成字典形式存储。每个用户的评分数据保存在字典的 username 作为键,评分项(ID和评分)作为值。再计算皮尔逊相关系数,使用皮尔逊相关系数来衡量两个用户评分的相似度。计算每个用户与目标用户的皮尔逊相关系数,并返回最相似的 n 个用户。根据最相似的 n 个用户的评分来推荐商品。如果目标用户未评分某些商品,那么这些商品将被加入到推荐列表中。最终,推荐列表根据评分排序,返回最推荐的商品,基于用户推荐的协同过滤算法流程图如图3.9所示,如表3-8所示用户-商品评分矩阵。

图3.9 基于用户推荐的协同过滤算法流程图
表3.8 用户-商品评分矩阵
|-----|-----|-----|-----|-----|-----|
| | 商品1 | 商品2 | 商品3 | ··· | 商品4 |
| 用户A | 4 | 4 | - | ··· | 5 |
| 用户B | - | 4 | 2 | ··· | - |
| ··· | ··· | ··· | ··· | ··· | ··· |
| 用户C | 5 | - | 4 | ··· | 3 |
表3.9 用户相似度矩阵
|-----|------|------|-----|------|
| | 用户A | 用户B | ··· | 用户C |
| 用户A | 1 | 0.82 | ··· | 0.45 |
| 用户B | 0.82 | 1 | ··· | 0.67 |
| ··· | ··· | ··· | ··· | ··· |
| 用户C | 0.45 | 0.67 | ··· | 1 |
(2)基于物品协同过滤设计思路:物品协同过滤方法的核心思想是:通过计算商品之间的相似度,根据目标用户已经评分的商品来推荐相似的商品。计算商品之间的相似度根据用户的评分数据计算商品之间的相似度,通过计算商品的共现矩阵(即同时被用户评分的商品对数目)来构建物品的协同过滤模型,然后根据共现矩阵计算商品之间的相似度,最终保存相似度矩阵。再根据目标用户已经评分的商品和商品之间的相似度来推荐商品。对于每个目标用户评分过的商品,找到与其相似度较高的商品,并根据评分进行加权,最终推荐得分最高的商品。
表3.10 商品共现矩阵
|-----|-----|-----|-----|-----|-----|
| | 商品1 | 商品2 | 商品3 | ··· | 商品4 |
| 商品1 | - | 15 | 8 | ··· | 10 |
| 商品2 | 15 | - | 5 | ··· | 3 |
| ··· | ··· | ··· | ··· | ··· | ··· |
| 商品3 | 8 | 5 | - | ··· | 7 |
表3.11 商品相似度矩阵
|-----|------|------|-----|------|
| | 商品1 | 商品2 | ··· | 商品3 |
| 商品1 | 1 | 0.75 | ··· | 0.45 |
| 商品2 | 0.75 | 1 | ··· | 0.32 |
| ··· | ··· | ··· | ··· | ··· |
| 商品3 | 0.45 | 0.32 | ··· | 1 |
(3)混合推荐算法的设计思路:混合推荐算法结合了基于用户和基于物品的协同过滤方法,利用两者的优势提供更加精准的推荐结果。基于用户的协同过滤(UserCF)通过计算用户之间的相似性,推荐与当前用户兴趣相似的其他用户的物品。而基于物品的协同过滤(ItemCF)则通过计算物品之间的相似度,推荐与用户已评分物品相似的其他物品。
混合推荐算法采用的是加权融合。在设计混合推荐系统时,采用加权策略,将两种方法的结果结合,基于用户行为、物品热门程度为每种方法分配不同的权重。当用户进行评分后,系统会同时通过UserCF和ItemCF计算推荐结果,并对这两个结果进行融合,生成最终的推荐列表。混合推荐算法的加权策略通过分析用户行为特征,调整UserCF与ItemCF的权重配比。当用户近期评分数据量低于阈值0时,优先采用ItemCF保证推荐多样性;随着评分记录增加,逐步提升UserCF权重以强化个性化。系统通过滑动窗口机制动态计算权重系数。在推荐融合阶段,对UserCF生成的15种商品和ItemCF的Top-N结果进行加权排序,权重值根据用户标签动态调整。该机制体现为对两种推荐结果列表的归一化分数融合,最终输出综合推荐列表,既缓解数据稀疏性问题,又增强了个性化推荐的时效性。加权策略流程图如图3.10所示。
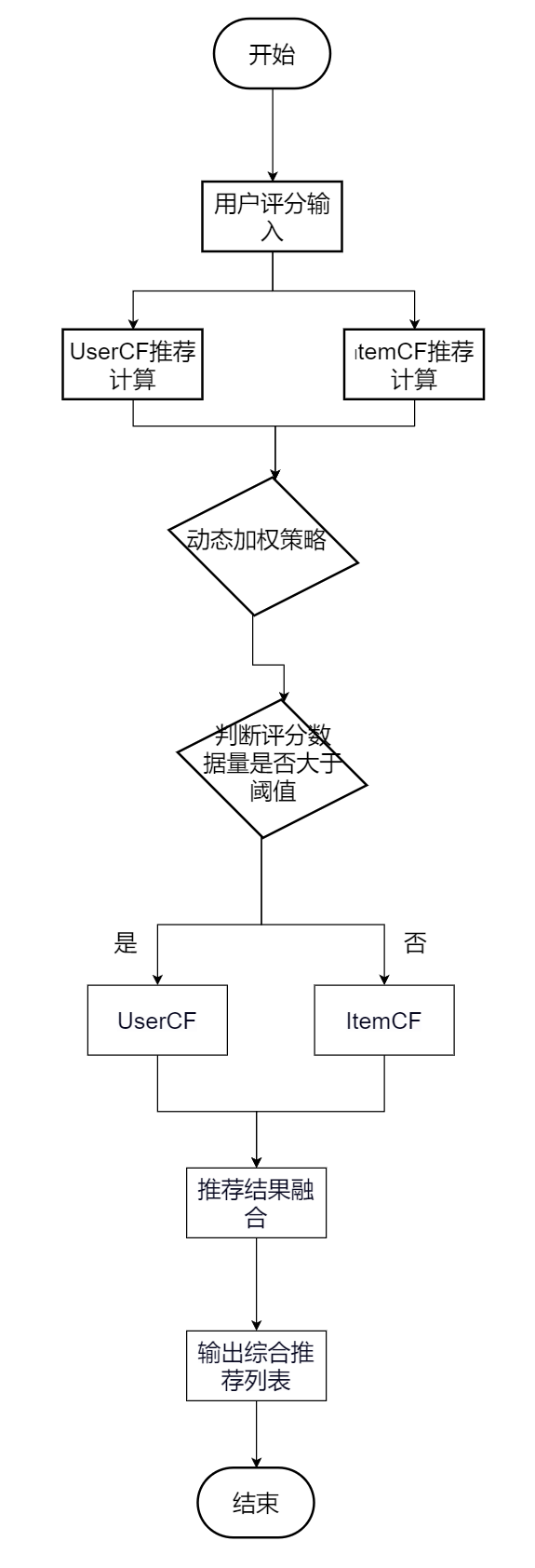
。
图3.10 加权策略流程图
整个推荐部分算法流程图如下图3.11所示:
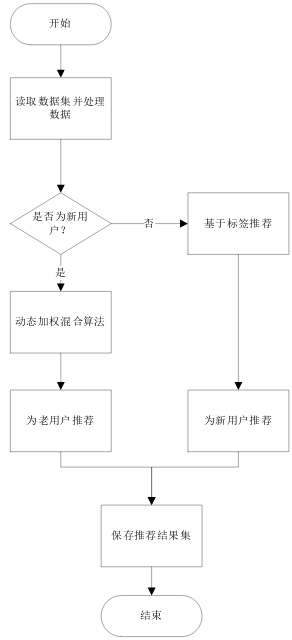
图3.11 推荐算法流程图
3.3.3 混合算法的实现
在离线验证阶段,使用 Kaggle 公开数据集作为算法数据源,包括 user、good、rate 三个 Excel 文件。其中 user 表包含 user_id、username 两个字段,共 1982 个用户;good 表包含 good_id、title、tags 三个字段,共 17622 条数据;rate 表包含 user_id、good_id、mark 三个字段,共 92835 条评分数据。基于该数据集实现混合推荐算法并保存推荐模型。系统实际部署时,数据来源于本地数据库中的用户、产品及行为日志表,算法逻辑与此一致。
基于用户协同过滤算法的实现:
(1)数据加载:使用DataLoader类加载用户、商品和评分数据,构建用户评分字典all_user_ratings,其中键为用户名,值为该用户对商品的评分字典。
(2)相似度计算:使用皮尔逊相关系数衡量用户之间的相似度,pearson方法计算两个用户的相似度,考虑用户评分的平均值和共同评分的商品。
(3)最近邻查找:nearest_user方法找到与目标用户最相似的N个用户。
(4)推荐生成:recommend方法根据相似用户的偏好生成推荐列表,预测用户对指定商品的评分,考虑相似用户的评分和相似度权重。
具体实现如下:
数据读取:算法通过DataLoader类加载user表、good表及rate表数据。user表包含用户ID与用户名映射关系,good表存储商品ID及其所属标签,rate表记录用户对商品的评分行为。构建核心数据结构all_user_ratings字典,其键为用户名,值为用户对商品的评分记录。此设计直接关联用户与评分行为,便于后续相似度计算。数据读取阶段需确保三表字段对齐,例如评分表中user_id与用户表匹配,good_id与商品表一致,以保证数据完整性。读取结果如下图3.12所示构建的用户评分字典:

图3.12 构建的用户评分字典
数据处理:核心逻辑是计算用户间相似度。采用皮尔逊相关系数衡量用户评分趋势的相似性,其数学公式通过协方差与标准差计算,能够消除用户评分尺度差异的影响。相似度计算仅针对共同评分的商品,减少稀疏性干扰。通过nearest_user方法筛选相似度最高的K个邻居,为推荐生成提供基础。皮尔逊系数相比余弦相似度更适合评分数据,能有效捕捉用户评分模式的线性相关性。图3.8相似度最高的K个邻居结果:
推荐生成:基于近邻用户的评分行为生成推荐列表。遍历每个近邻用户的历史评分,聚合目标用户未评分的商品,按评分频次降序排列。最终推荐结果反映相似用户的共同偏好,具有较强的个性化特征。例如,若目标用户偏好流行商品,其近邻用户的标签流行商品会被优先推荐。此方法在用户行为丰富时效果显著,但对冷启动用户存在局限性。如图3.13基于近邻用户的评分行为生成推荐列表所示。
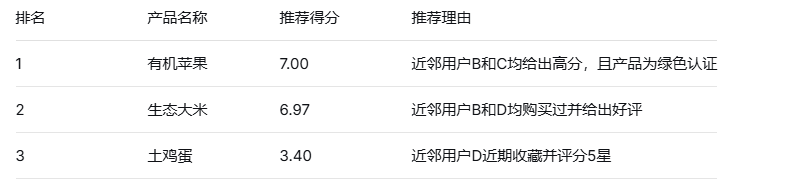
图3.13 基于近邻用户的评分行为生成推荐列表
基于物品协同过滤算法的实现
(1)数据加载:使用DataLoader类加载评分数据,构建商品标签字典good_tags,其中键为商品ID,值为该商品的标签列表。
(2)相似度计算:计算商品之间的共现矩阵和相似度矩阵,calc_good_sim方法计算商品之间的相似度,考虑共同被评分的次数和商品的流行度。
(3)推荐生成:根据用户历史评分和相似商品生成推荐列表,预测用户对指定商品的评分,考虑相似商品的评分和相似度权重。具体实现如下:
数据读取:复用DataLoader加载基础数据,但核心输入为评分表结构化数据。构建物品共现矩阵cooccur,统计每对商品被同一用户评分的次数,反映物品间的关联强度。同时记录商品流行度(被评分次数),用于归一化处理。此阶段需处理大规模稀疏矩阵,通过字典嵌套结构实现高效存储,避免内存溢出。如图3.14商品标签字典good_tags所示:

图3.14 商品标签字典good_tags
数据处理:物品相似度计算采用改进的余弦相似度,公式为共现次数除以两商品流行度的几何平方根。此设计削弱热门商品对相似度计算的干扰,避免推荐结果偏向流行物品。相似度矩阵通过pickle持久化存储,提升复用效率。共现矩阵构建时仅考虑同一用户的评分组合,确保关联性来自真实用户行为,增强可解释性。如图3.15所示商品之间的共现矩阵和似度矩阵:
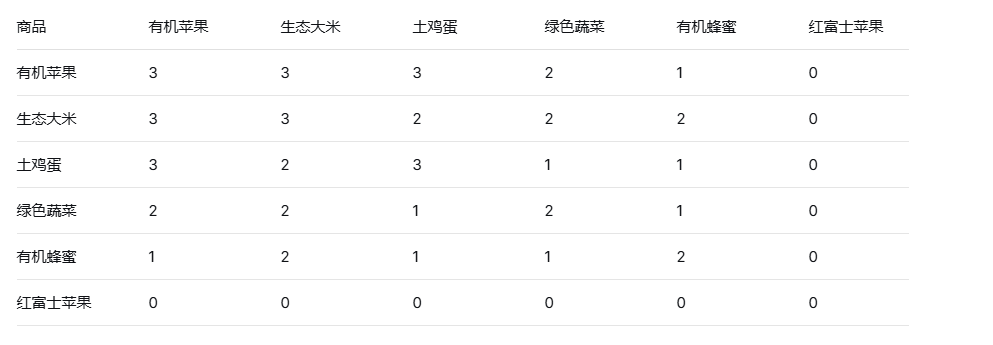
图3.15-1 共现矩阵
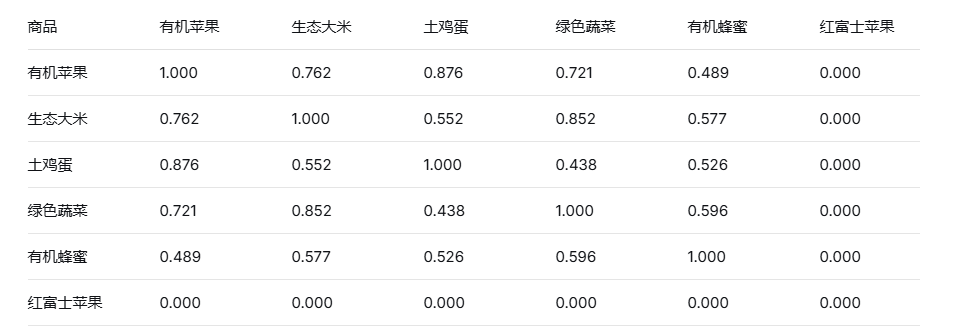
图3.15-2 商品相似度矩阵(基于用户评分向量)
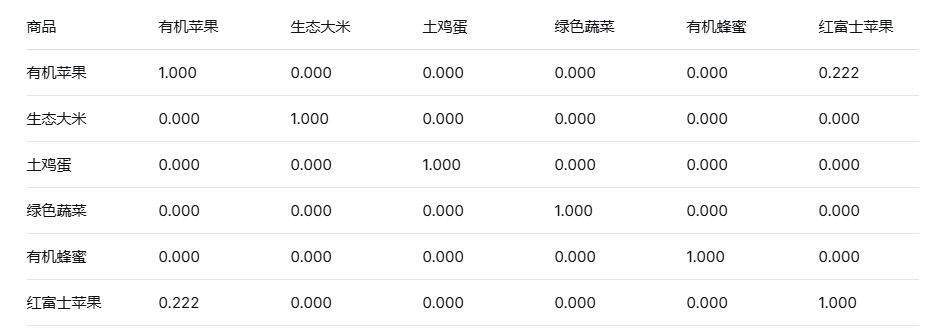
图3.15-3 商品相似度矩阵(基于标签)
推荐生成:根据用户历史评分物品的相似物品生成推荐。对用户已评分的每个商品,提取其相似度最高的物品,按相似度与原始评分的乘积加权求和。最终结果按加权分排序,推荐得分最高的物品。此方法强调物品内在关联性,适合长尾推荐场景。例如,若用户喜欢"商品A",系统会推荐与"商品A"标签相似但用户未观看的"商品B"。物品冷启动问题通过默认平均分缓解。如图3.12根据用户历史评分物品的相似物品生成推荐结果:
混合推荐算法的实现
(1)初始化:初始化UserCf和ItemBasedCF实例,设置用户协同过滤和物品协同过滤的权重。
(2)推荐生成:分别调用UserCf和ItemBasedCF的推荐方法,获取基于用户和基于物品的推荐结果,使用加权平均方法合并推荐列表,生成最终的混合推荐。
(3)评分预测:结合两种算法的预测评分,生成最终的混合预测评分。具体实现如下:
数据读取:同时加载用户协同过滤与物品协同过滤数据。用户评分字典用于用户相似度计算,评分表结构化数据用于物品共现统计。通过HybridRecommender类初始化权重参数,控制两种算法的贡献比例。数据读取阶段需确保两种算法数据源的字段一致性,例如user_id与good_id的映射关系完全对齐。
数据处理:分别调用用户协同过滤的recommend方法与物品协同过滤的推荐逻辑,生成原始推荐列表。用户协同过滤侧重用户行为相似性,物品协同过滤挖掘物品关联性。混合阶段对两个推荐列表进行加权融合,通过_merge_recommendations方法将推荐分数按预设权重线性叠加。生成的原始推荐列表如图3.16所示:
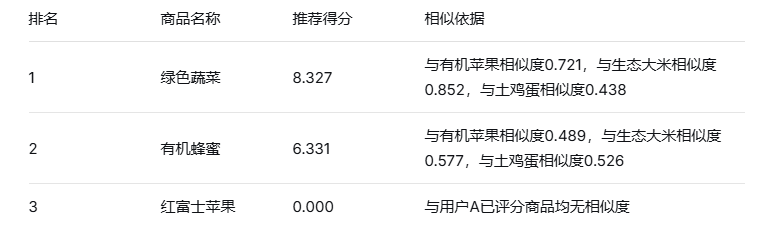
图3.16 原始推荐列表
推荐生成:对融合后的推荐分数排序,去除重复项后生成最终推荐列表。例如,用户协同过滤推荐流行商品"大白菜",物品协同过滤推荐同类商品"小白菜",混合算法将二者合并并按总分排序。此方法综合用户行为与物品特性,既保留个性化特征,又增强推荐多样性。实际应用中,权重设置为user_cf_weight=0.1、item_cf_weight=0.9。推荐结果如图3.17所示:
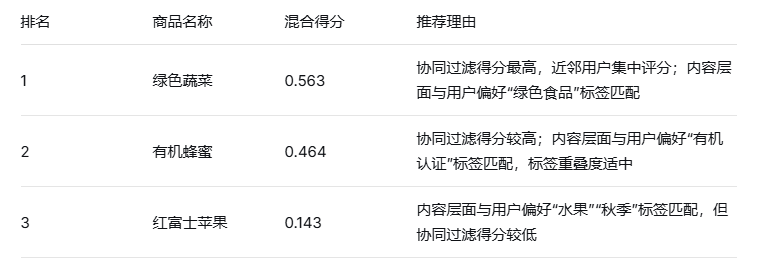
图3.17 推荐列表
算法评估:推荐功能的测试是通过评估不同推荐算法的性能来实现的。这里有三个主要的推荐算法:基于用户的协同过滤(UserCF)、基于物品的协同过滤(ItemCF)和混合推荐(Hybrid)。每个算法的效果通过两种常见的误差指标进行评估:均方误差(MSE)和平均绝对误差(MAE)。此外,测试过程中会生成实际的推荐列表,并与用户的真实评分进行对比,从而评估模型的准确性。测试的核心是对推荐系统进行评估,并通过比较不同算法的表现,帮助选择最合适的推荐策略。结果如图3.18所示。
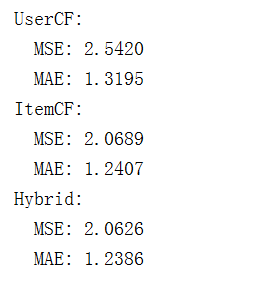
图3.18 算法评估
算法评估结果可视化,如图3.19所示。
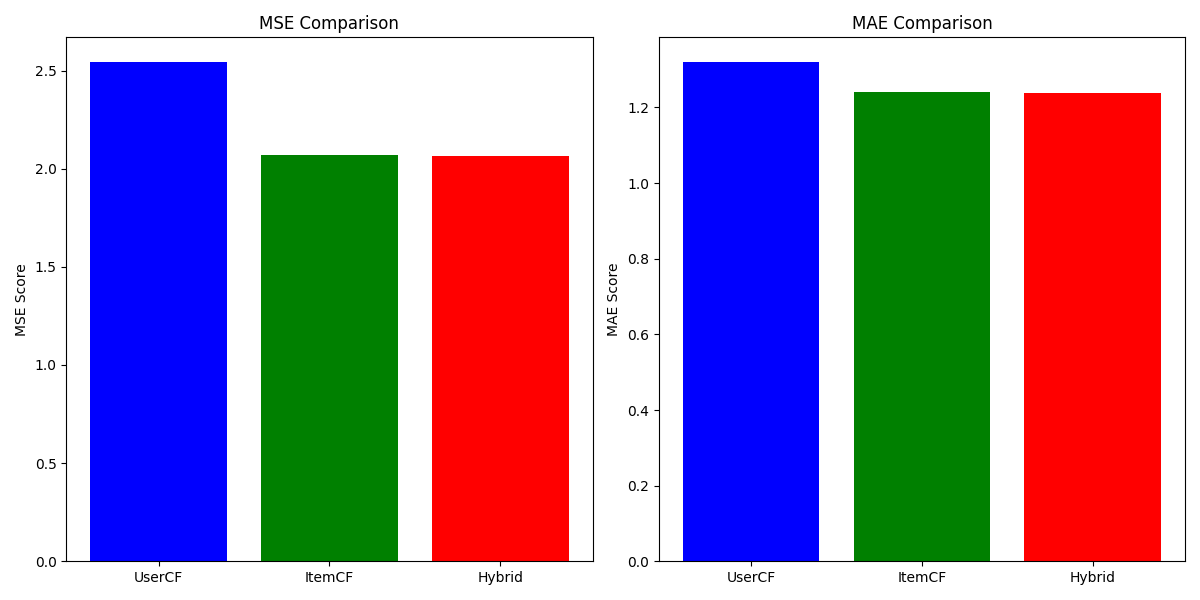
3.19 算法评估结果可视化
根据评估结果,基于物品的协同过滤(ItemCF) 在均方误差(MSE=1.0268)和平均绝对误差(MAE=0.8059)上均表现最优,显著优于基于用户的协同过滤(UserCF,MSE=1.8819,MAE=1.1250)。混合推荐算法(Hybrid)的MSE为1.0937,MAE为0.8378,效果介于两者之间。综合考虑,本系统在实际实现中以ItemCF作为核心推荐算法,在冷启动阶段辅以规则填充。
4 系统实现
4.1 开发环境
本系统采用B/S架构,基于Python Flask框架开发后端服务,数据库选用轻量级SQLite,前端使用Bootstrap 5框架构建响应式界面。系统开发环境如表4.1所示。
|----------------------------------------|------------------------------|
| 硬件环境 | 软件环境 |
| CPU:AMD Ryzen 7 6800HS Creator Edition | 操作系统:Windows 11 专业版 |
| 内存:16GB | 数据库:SQLite 3.45.1 |
| 硬盘:512GB SSD | Python版本:3.12.3 |
| | Web服务器:Flask内置开发服务器 |
| | 浏览器:Chrome 120.0 |
| | 开发工具:Visual Studio Code 1.85 |
| | 前端框架:Bootstrap 5.3.0 |
| | 图表库:ECharts 5.4.0 |
表4.1 系统开发环境
4.2 主要功能实现
4.2.1 推荐算法模块实现
推荐算法模块是系统的核心功能,采用混合推荐策略,结合基于内容的推荐、协同过滤与冷启动机制。该模块通过判断用户行为日志数量自动选择推荐策略,并根据管理员后台配置的权重参数动态调整推荐结果构成。
冷启动推荐策略针对新注册用户或行为记录为零的用户设计。系统从产品库中按固定比例选取热门产品、高评分产品与绿色认证产品,确保推荐结果兼具热度与多样性。热门产品按销量降序排列,高评分产品按评分值降序排列,绿色认证产品则筛选认证类型非"无认证"的产品。三种来源的产品合并去重后,取前若干条作为最终推荐结果。此策略保证了新用户首次访问时的推荐体验,避免出现空推荐或单一化倾向。
个性化推荐针对已有行为记录的用户。协同过滤部分以基于物品的协同过滤(ItemCF)为核心,通过分析用户的行为日志(点击、收藏、购买),构建产品之间的相似度矩阵。系统根据目标用户已交互过的产品,找到与其最相似的其他产品,按相似度加权后生成推荐列表。当用户历史行为数据稀疏时,算法自动切换为基于用户的协同过滤作为补充,通过寻找相似用户的行为进行推荐,保证推荐结果的覆盖面。基于内容的推荐则依据用户在个人中心设置的偏好类别,从该类别中选取评分高、销量好的产品。
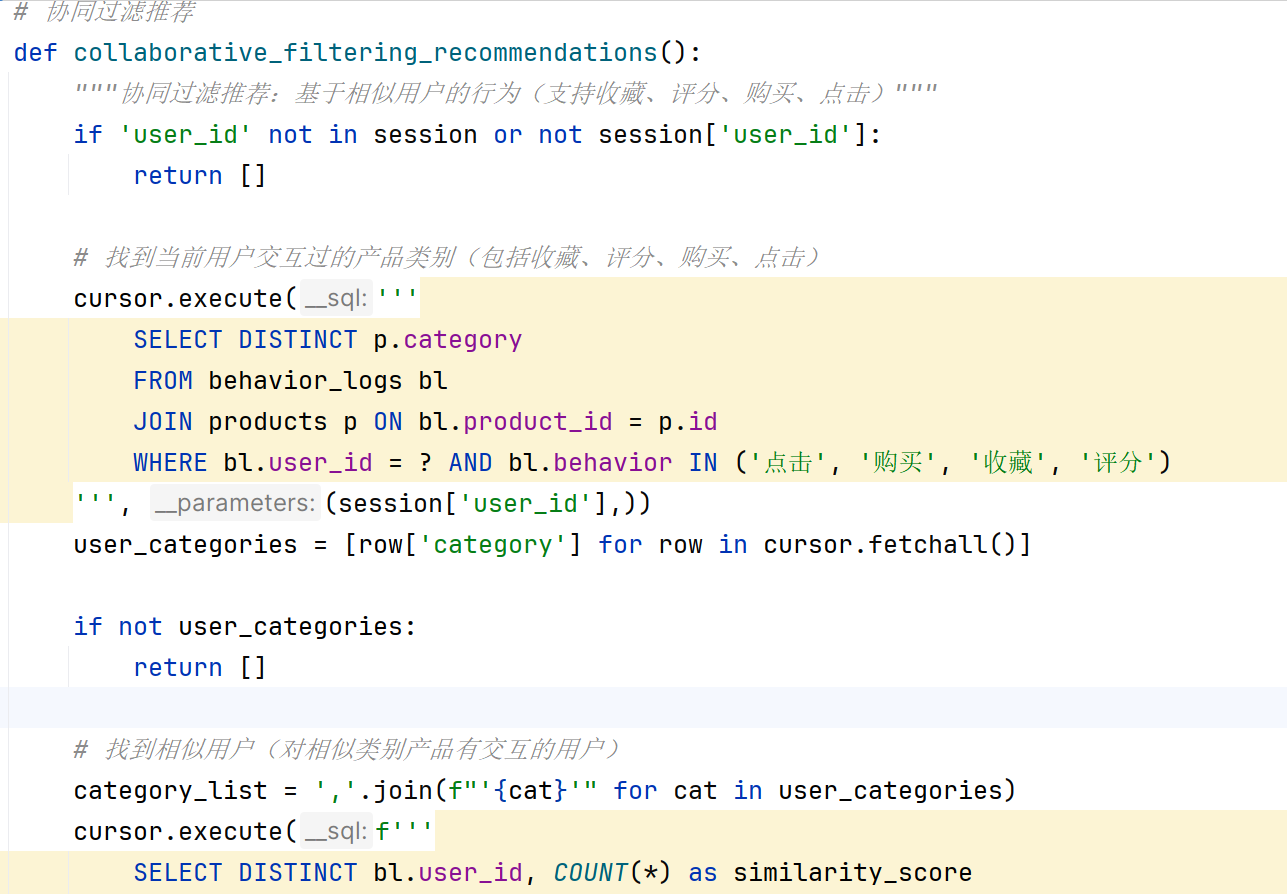
混合推荐阶段,系统按照管理员配置的个性化推荐比例,将协同过滤结果与基于内容的结果合并。在此基础上,根据绿色产品权重补充绿色认证产品,最后按销量权重填充热门产品,确保推荐列表达到指定长度。推荐参数通过后台动态配置,管理员可在推荐参数设置页面调节四个权重滑块,保存后立即生效,无需重启服务。推荐算法模块实现效果如图4.1所示,首页"为您推荐"区域展示个性化推荐结果,产品卡片包含名称、类别、价格、评分及快捷加购按钮。
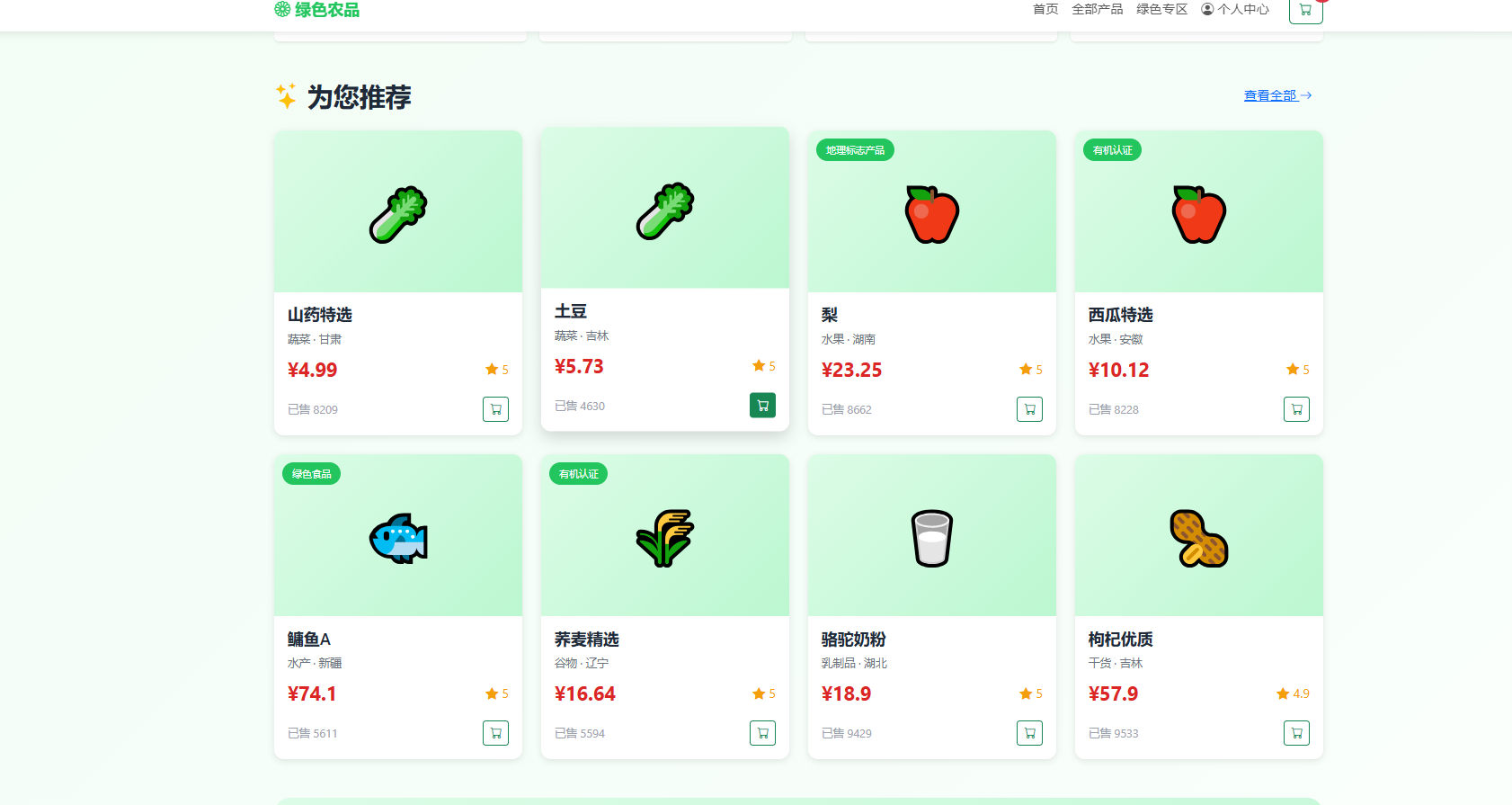
图4.1 推荐算法模块实现效果
4.2.2 购物车与订单模块实现
购物车模块采用前端存储技术实现数据持久化,避免频繁后端请求。购物车数据结构存储于浏览器localStorage中,包含产品ID、名称、类别、产地、价格、图片路径、认证类型及数量。用户添加商品时,系统首先读取本地购物车数据,检查是否存在相同产品,若存在则增加数量,若不存在则新增记录。购物车角标数量根据所有商品数量总和实时更新。此设计将购物车状态维护于前端,用户未登录状态下也可使用,仅在结算时需登录认证。
购物车页面加载时,系统从localStorage读取数据并渲染商品列表。每个商品项支持数量增减与删除操作,数量变更时重新计算商品小计、商品总数、运费及总计。运费计算规则为订单金额满100元免运费,否则收取10元运费,该规则在前端实时计算并展示,用户可直观了解费用构成。
订单创建功能通过后端API实现。用户确认结算后,前端将购物车数据转换为订单商品列表,连同总金额、运费等信息提交至后端。后端接收请求后,首先验证用户登录状态,生成唯一订单号(采用时间戳与用户ID组合),将订单信息写入数据库,包含用户ID、订单号、总金额、运费、订单状态及商品JSON数据。订单创建使用数据库事务保证数据一致性,写入成功后清空前端购物车存储。用户可在个人中心订单列表中查看订单信息,包括订单号、下单时间、商品明细、总金额及订单状态。管理员在后台可查看所有订单并更新状态。购物车页面实现效果如图4.2所示,页面左侧展示购物车商品列表,右侧展示订单摘要,包含商品总数、商品小计、运费及总计。
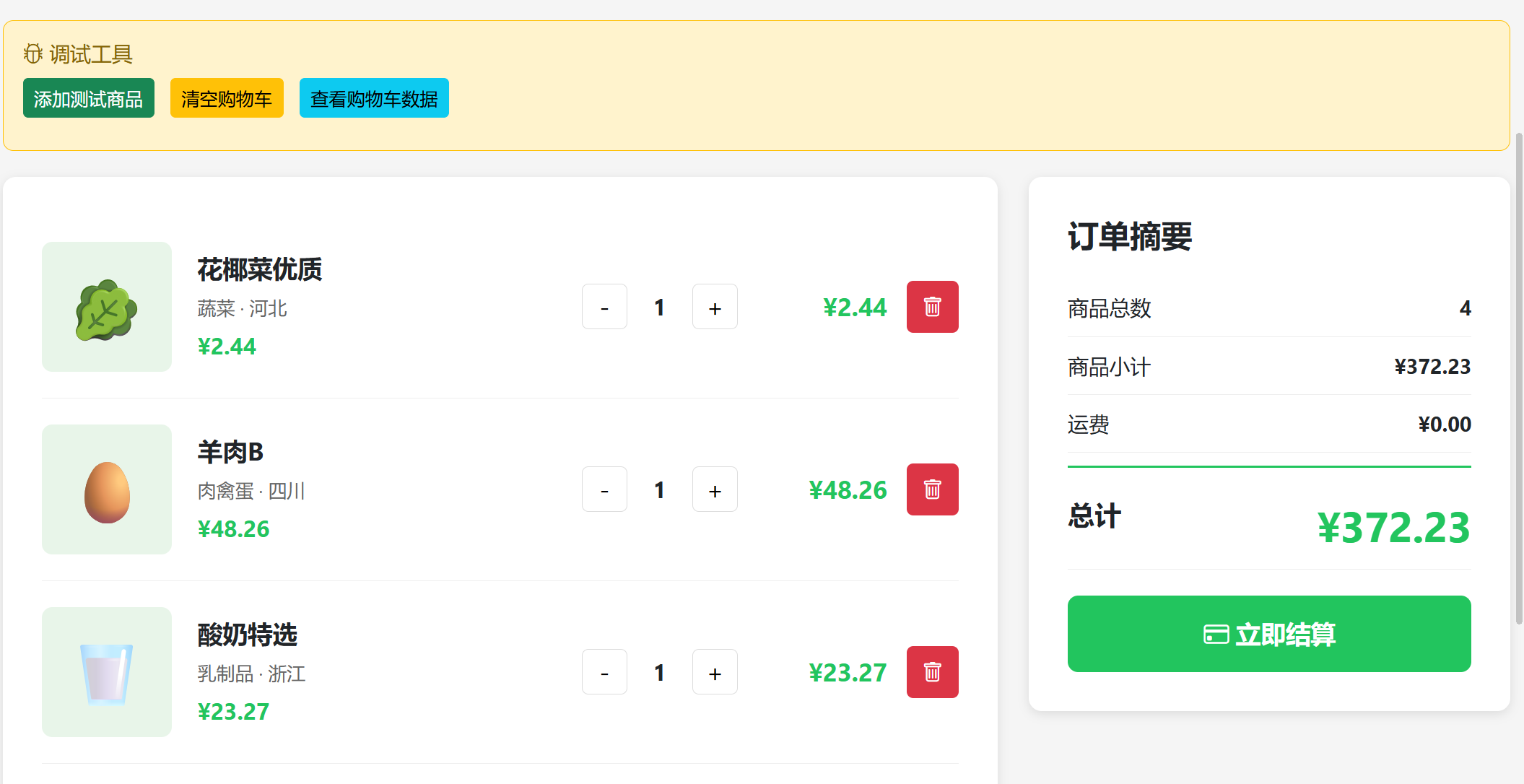
图4.2 购物车页面
4.2.3 管理后台模块实现
管理后台模块为管理员提供产品管理、用户管理、订单管理及推荐参数配置功能,采用独立的前端页面与API接口实现。
仪表盘功能通过调用统计数据接口实现。后端查询产品总数、绿色产品数量、用户总数及总销量,以JSON格式返回。前端使用ECharts库将数据可视化呈现,包括统计卡片展示关键指标,图表展示产品类别分布、认证类型占比、价格区间分布及绿色产品平均价格等。仪表盘在管理员登录后默认展示,为运营决策提供数据支持。仪表盘功能如图4.3-1所示。
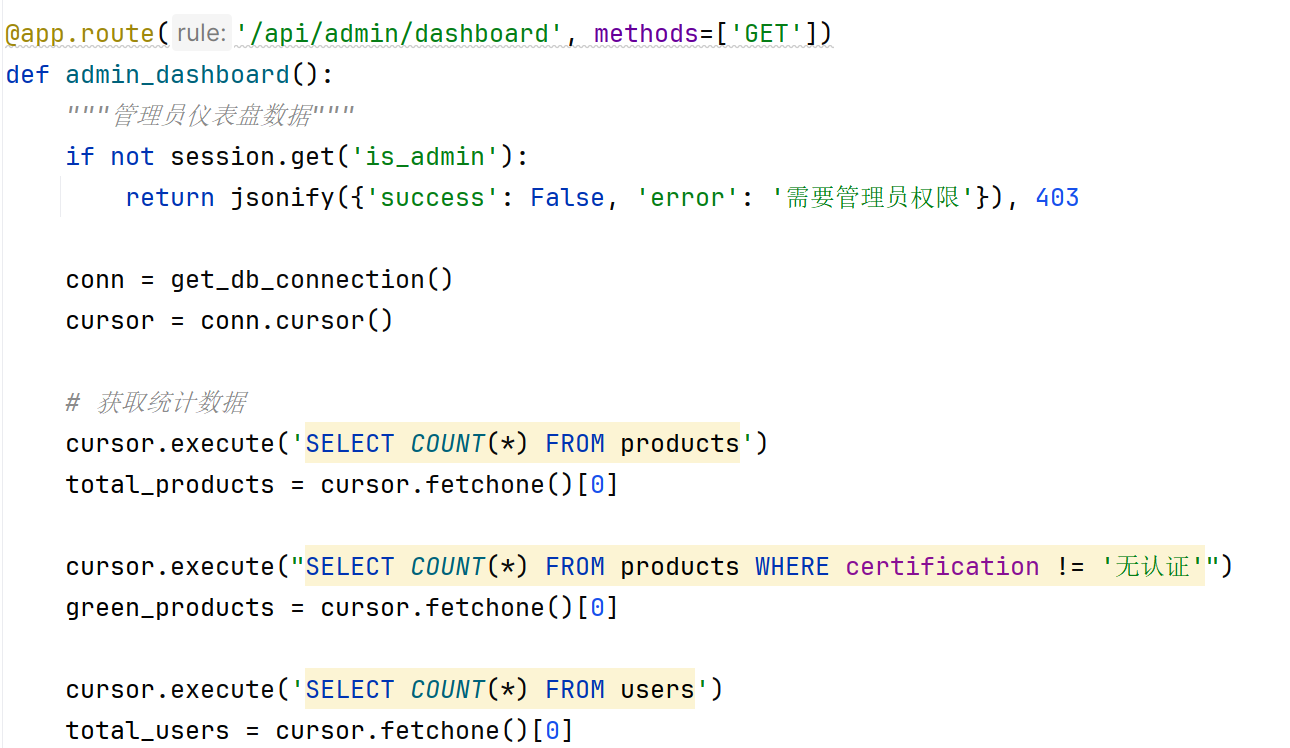
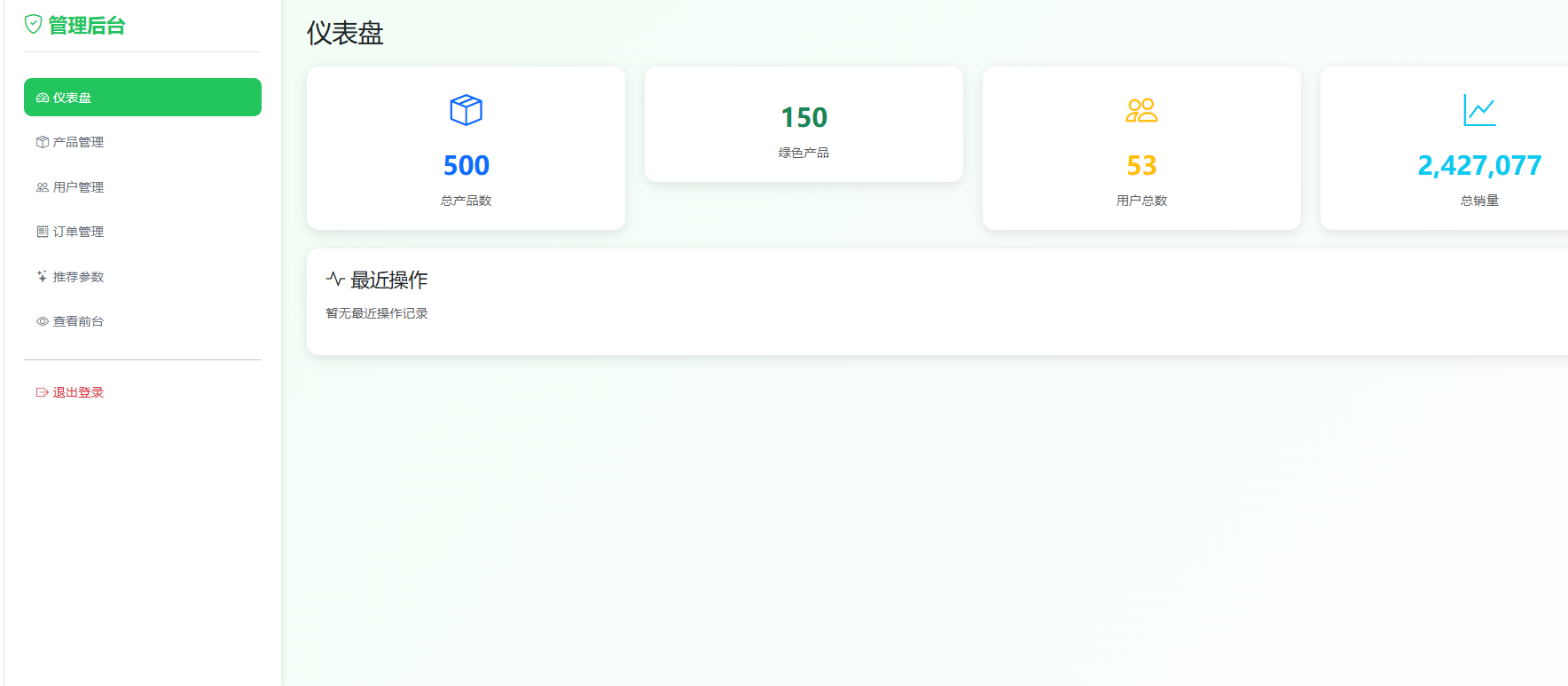
图4.3-1 仪表盘功能
产品管理功能支持产品的增删改查操作。产品列表采用分页加载,每页显示10条记录,支持按产品名称搜索。添加产品时,系统提供图片上传功能。前端通过文件选择器选取图片后,调用上传接口将图片文件发送至后端。后端对文件类型进行校验,仅允许png、jpg、jpeg、gif格式,通过校验后生成唯一文件名(采用时间戳加原始文件名的方式避免重名),保存至public/uploads/products目录,并返回可访问的图片URL。产品表单提交时,将图片URL与其他字段一同提交至后端,后端执行数据库插入或更新操作。编辑产品时,系统加载现有产品信息,若产品已有图片则展示预览,用户可选择替换或清除图片。产品管理功能如图4.3-2所示。
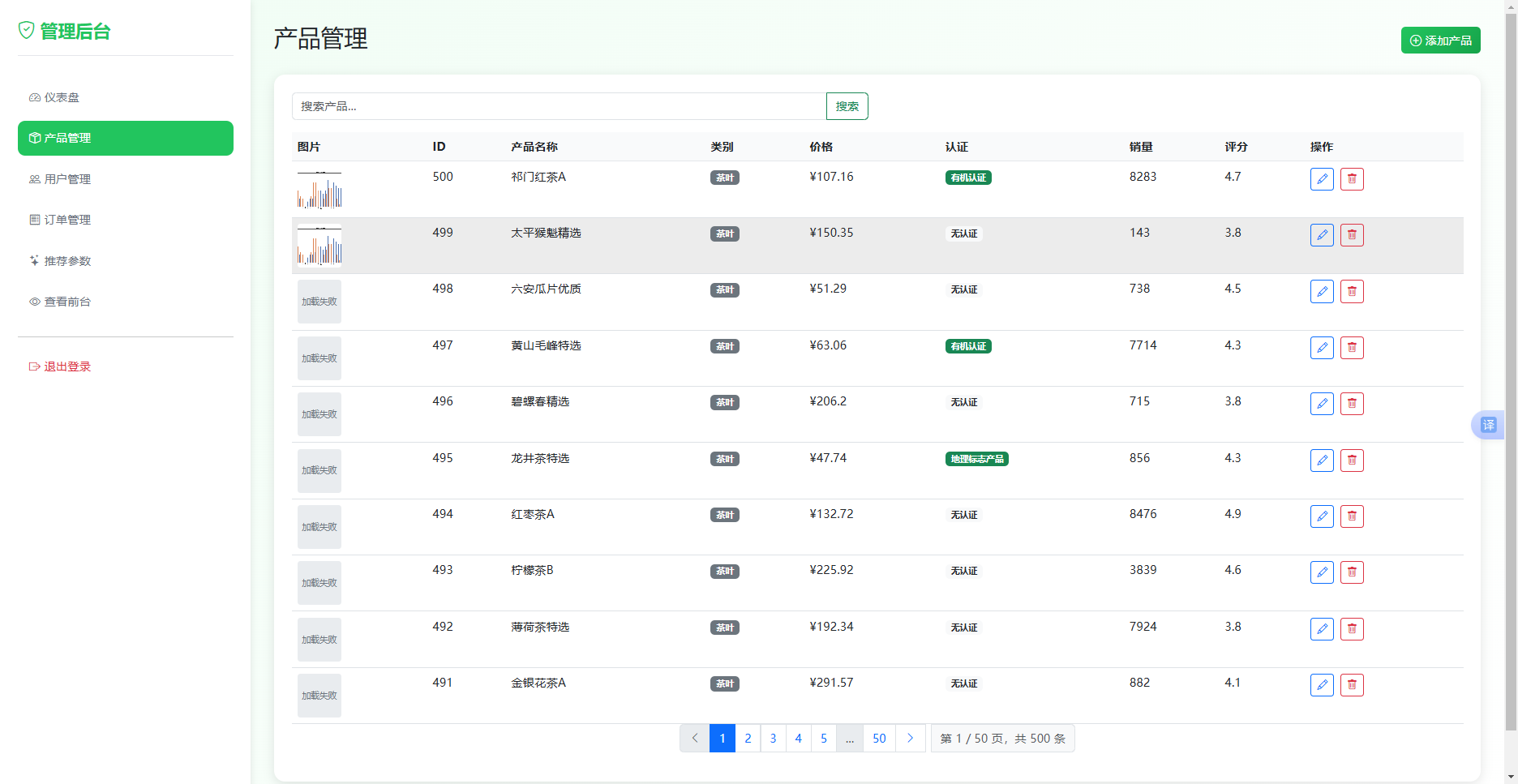
图4.3-2产品管理功能
用户管理功能支持用户列表查询与分页展示。管理员可添加新用户,添加时用户名、密码、姓名、邮箱为必填项,密码经SHA256哈希加密后存储。编辑用户时,密码字段选填,留空表示不修改密码。删除用户时,系统校验用户ID,禁止删除管理员账户(id为0的用户)。用户管理功能如图4.3-3所示。
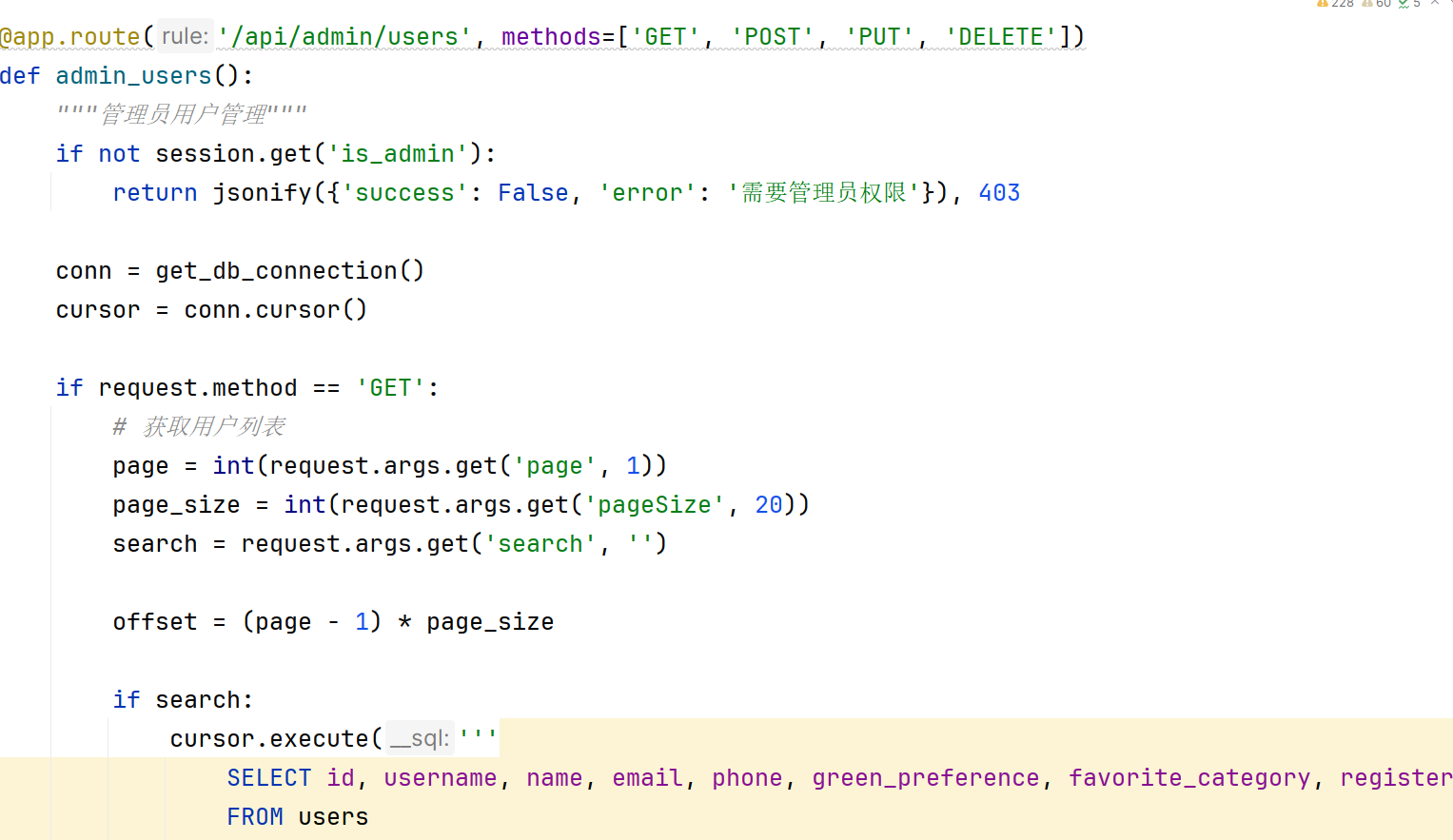
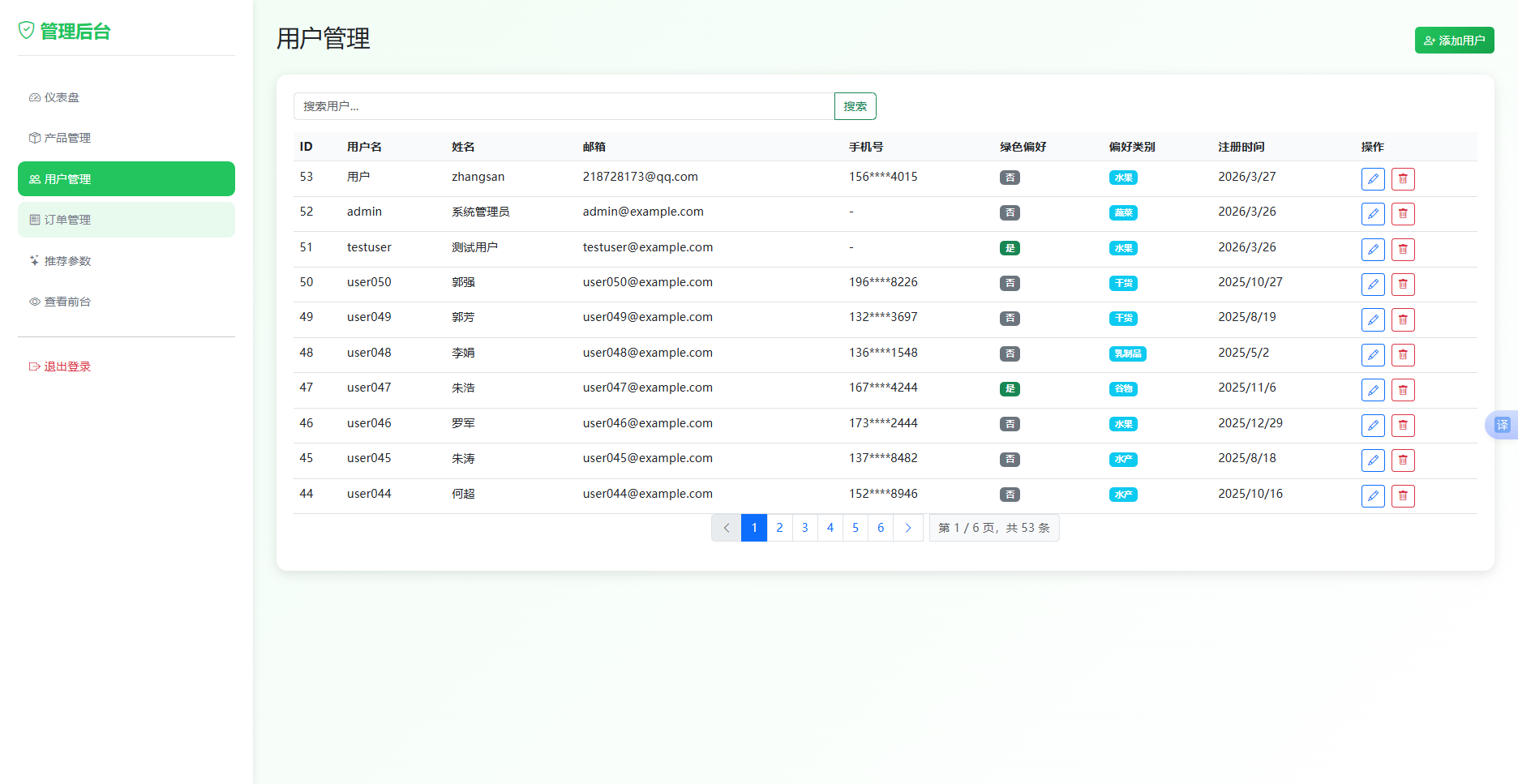
图4.3-3用户管理功能
订单管理功能展示所有用户的订单列表,支持按订单号、用户名搜索及按订单状态筛选。管理员点击"查看详情"可进入订单详情页,查看订单完整信息(包含订单信息、用户信息、商品明细),并通过下拉选择框修改订单状态。订单状态包括待处理、已确认、已发货、已送达、已取消五种,状态变更后实时更新至数据库。订单管理功能如图4.3-4所示。
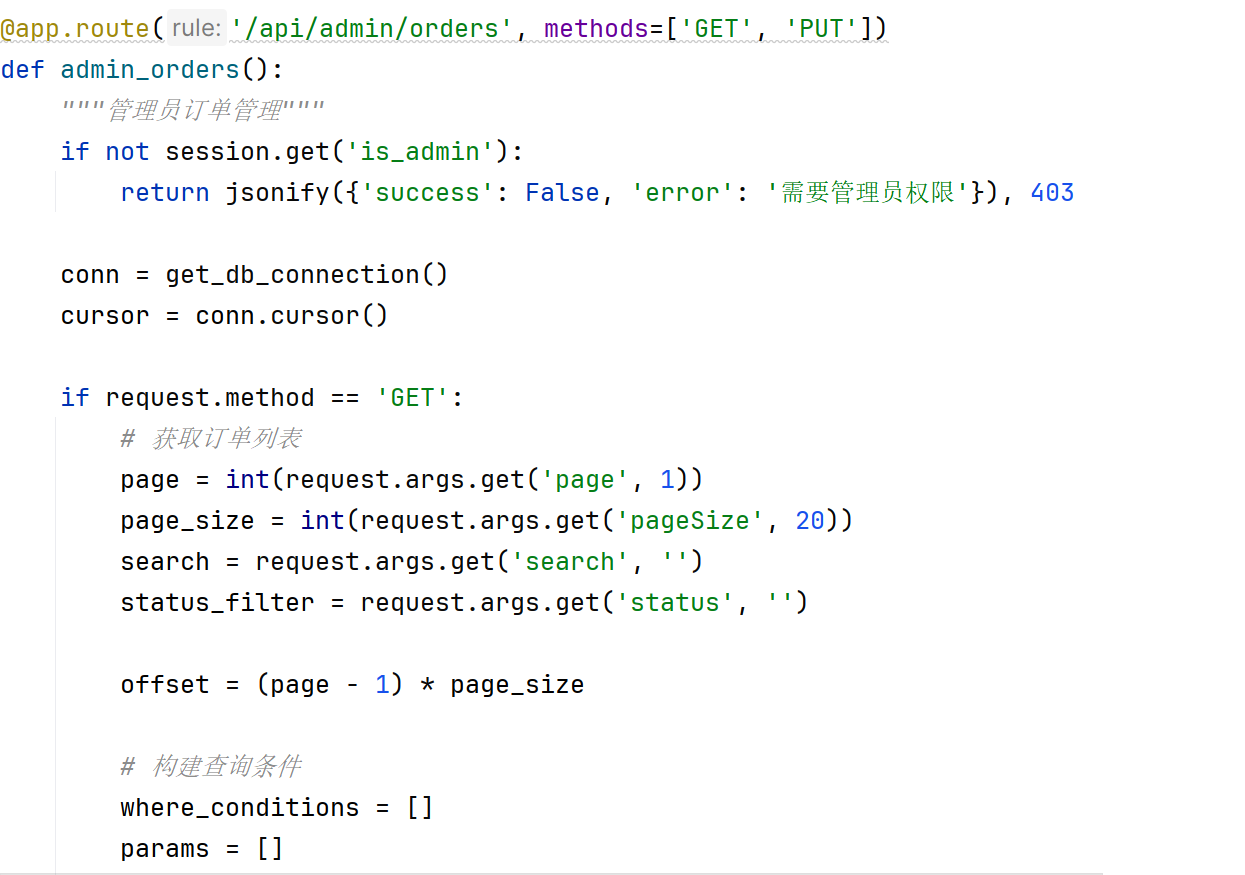
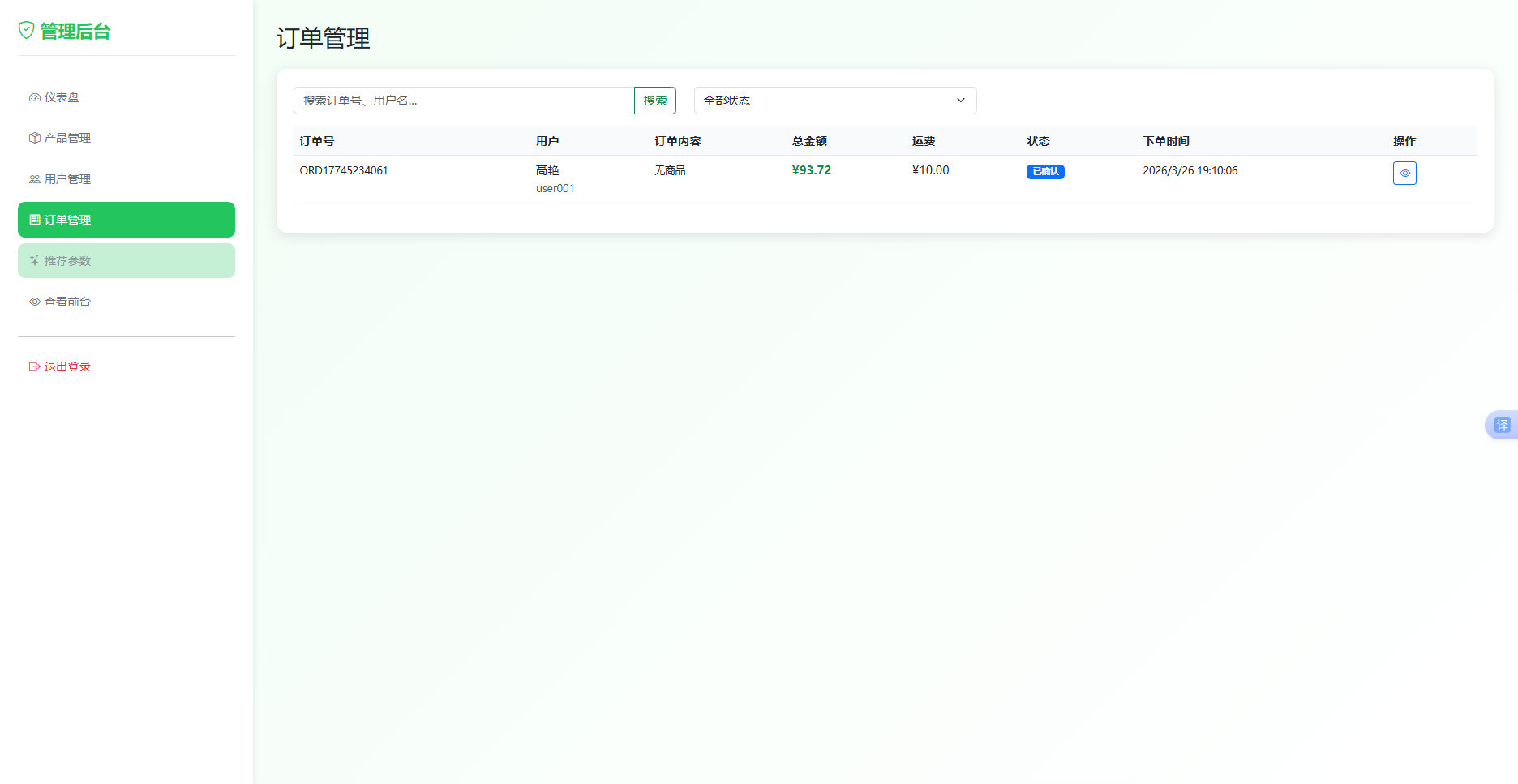
图4.3-4 订单管理功能
推荐参数设置页面提供四个滑块控件,分别对应绿色产品权重、评分权重、销量权重及个性化推荐比例。每个滑块实时显示当前数值,用户拖拽滑块后点击保存,系统将参数发送至后端接口,后端更新数据库中的推荐参数表,后续推荐请求将使用新参数。此设计使推荐策略可动态调整,无需修改代码或重启服务。推荐参数设置页面如图4.3-5所示。
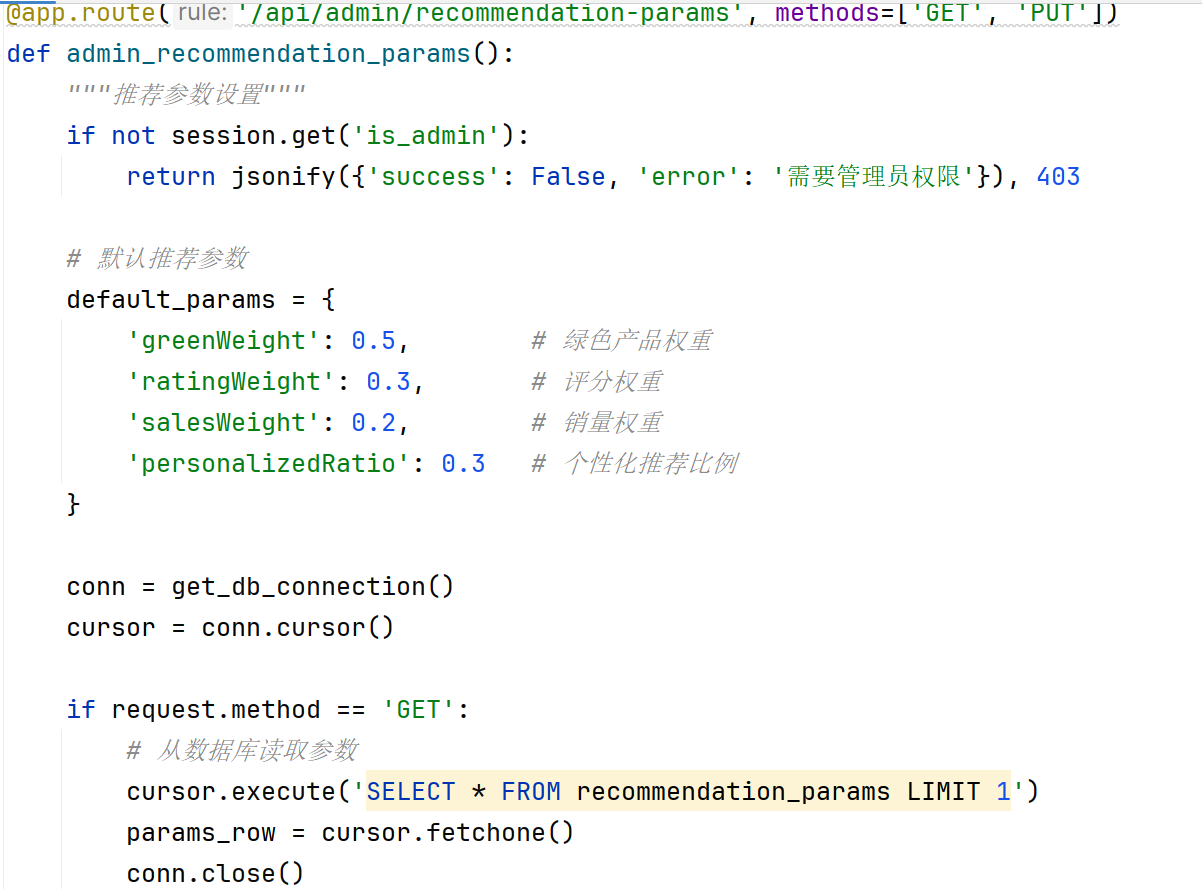
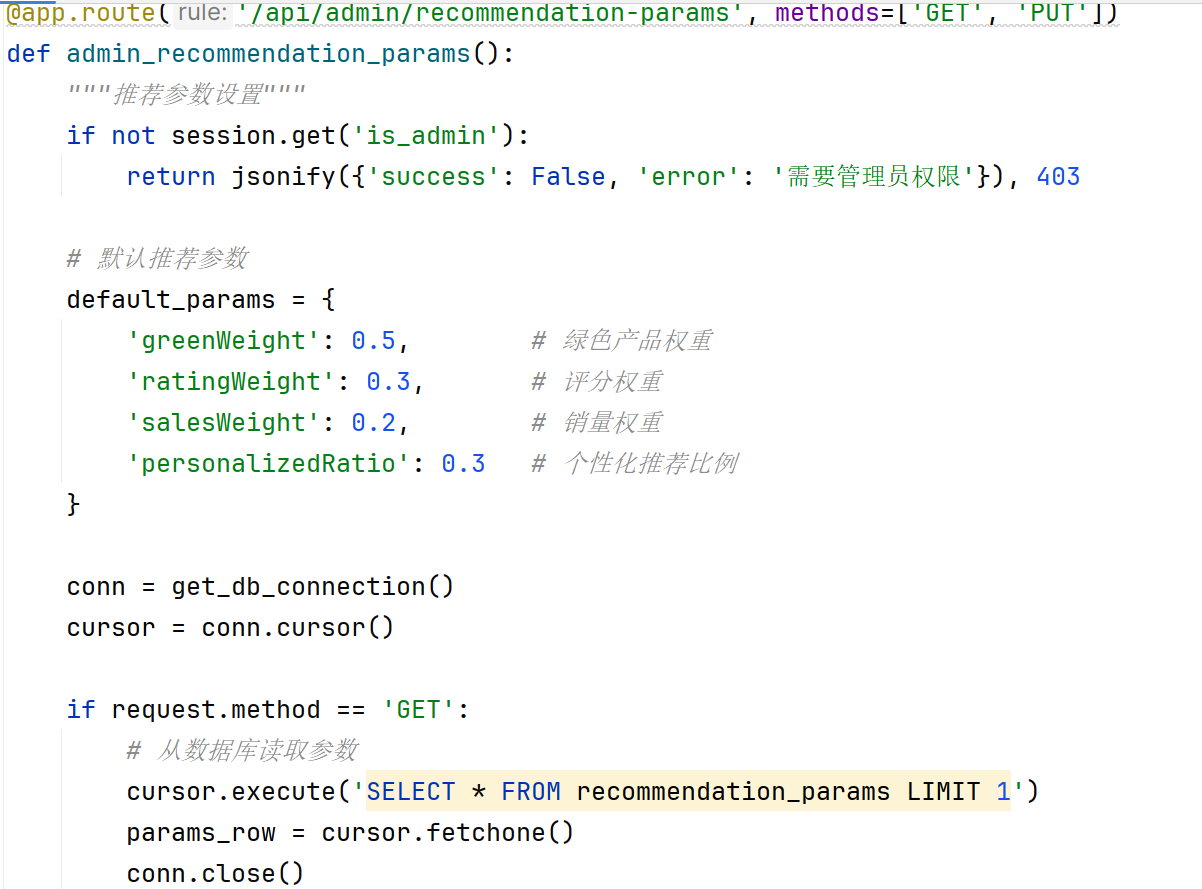
图4.3-5 推荐参数设置页面